基于深度学习的恶意行为检测与识别模型研究
2023-12-05张明明李贤慧许梦晗顾颖程张见豪程环宇
张明明 刘 凯 李贤慧 许梦晗 顾颖程 张见豪 程环宇
1(国网江苏省电力有限公司信息通信分公司 南京 210024) 2(江苏瑞中数据股份有限公司 南京 210012) 3(国网电力科学研究院有限公司 南京 211106)
随着智能设备(如电力物联网)及其在电子商务、娱乐等领域的应用不断普及,新的通信模式、流量类型得到持续的发展和演变.但这也间接促进了因通信便捷性而引起的网络犯罪增加.为此,服务提供商必须拥有更为深入的防御策略.除了需要实施认证、授权和访问控制(如使用防火墙)外,还需配置入侵检测系统(intrusion detection system, IDS)识别网络内的恶意活动.但值得注意的是,随着恶意软件技术不断进步,绕过传统的IDS变得更为容易[1].因此,亟需对IDS的设计进行再审查,确保其能够对抗日益复杂的网络异常行为.
设计高效的基于异常的IDS面临诸多挑战,主要原因是网络中正常流量与恶意流量的比例存在差异,攻击者尝试掩盖恶意流量,使其看起来像正常流量;同时,不断变化的应用需求(如AR/VR、在线游戏等)可能导致检测结果出现误报.因此,在开发入侵检测模型之前,IDS的设计首先必须精心选择特征.通过对KDD CUP99和NSL-KDD数据集的初步研究表明,网络流量包含不同的格式且有大量噪声.因此,高效的特征选择方案是基于异常的IDS的必要组件.对同一数据集的后续研究显示,恶意流量模式与常规流量存在差异,每种攻击流量都有自己的模式,可在检测到异常后进行区分.因此,除了识别和报告异常外,还可以对攻击进行分类.网络管理员和安全分析师可以立即采取行动,对识别的攻击进行缓解,这对于大规模网络至关重要.然而,现有的基于异常的IDS方法支持此类攻击的自动化分类处理[2].
文献[3]提出使用统计流特征的集成IDS来保护IoT设备的网络流量,使用UNSW-NB15和NIMS僵尸网络数据集为IoT网络生成36个统计特征.之后,基于提取的特征设计一个集成学习模型(堆叠),使用3种不同的分类器识别IoT网络中的恶意流量,对单个分类器的实验结果显示,决策树(DT)对于DNS和HTTP数据源都达到更高的准确率和检测率.文献[4]在SDN环境中应用深度学习方法进行基于流的异常检测,且只使用从NSL-KDD数据集的41个特征中提取的6个基本特征.文献[5]提出了一种使用循环神经网络(RNN)进行入侵检测的深度学习方法.文献[6]使用深度神经网络作为不同类型入侵攻击的分类器,并与支持向量机(SVM)进行了比较研究.文献[7]提出了一种NSL-KDD数据的图像转换方法,并通过二元类分类实验评估了该图像转换方法的性能.
本文提出了一种基于混合深度学习模型的入侵检测方法CNN-BiLSTM(convolutional neural network-bidirectional long short-term memory),由卷积神经网络(CNN)和双向长短时记忆(BiLSTM)网络组成,其中CNN部分包含卷积和池化层,用于生成特征映射,这个过程不仅降低了特征的维度,还基于原始特征同时生成新的映射.该过程可有效帮助系统保持较少的参数,并自动消除冗余和稀疏的特征.通过对比实验证明了CNN-BiLSTM模型的有效性.
本文的主要贡献如下:
1) 提出一种特征选择方案,通过消除高度相关的值来提取重要特征,以生成更多信息的特征向量.
2) 提出一种基于CNN和BiLSTM的混合深度学习模型.该模型可以有效地提取特征图来学习异常行为的特征.通过这种方式,可以检测到恶意模式,然后根据结果对主要攻击和子攻击进行分类.
3) 在评估标准中,使用2个最先进的网络异常检测数据集(NSL-KDD和KDD CUP99)对所提出的方法进行综合性能评估.这2个流行的数据集包含各种恶意实例以及从实时网络流量数据收集的正常样本.该模型的性能基于3个不同的阶段进行评估,包括恶意行为检测阶段、主攻击分类阶段和子攻击类别分类.
1 CNN-BiLSTM模型
本文提出的恶意行为检测和识别IDS框架主要包括网络数据预处理模块和和检测分类模块2部分.
在网络数据预处理模块中,有效分析包含大量原始网络数据的网络流量包,以便提取有用的数据;它传达了网络特征的潜在特性.检测分类模块CNN-BiLSTM是网络异常检测系统的关键部分,其模型框架如图1所示,负责识别恶意实例并对行为进行异常类型分类.

图1 CNN-BiLSTM模型框架
1.1 数据预处理模块
特征提取不仅是机器学习系统中的关键环节,而且通常是一个既重要又耗时的过程.
在此阶段,当处理多维特征数据集(如NSI-KDD),需将其所有数值调整至一个指定区间,使其在保持统计特征不变的同时,去除原始网络数据中的潜在偏差.
Min-Max标准化是一个用于特征值标准化的线性转换函数.通过确定特征的最大值和最小值,可以将特征值转化为[0,1]范围内,如式(1)所示:
(1)

在网络安全领域,所有执行标准活动的用户都被分到一个类别(即“正常行为”),而网络中的异常行为则被划分为不同类型的攻击.从实际的网络流量中收集了41项不同角度的特征,包括流量特征、基本特征、内容特征、时间特征和附加特征.这些特征包含了多种定性和定量的数据类型,其中有38项整数特征和4项字符串特征.为了将这些数据整理成一种适当且标准的形式,即为神经网络提供的包含数值数据的向量,必须将所有非整数类型的数据转换成整数形式,以便于机器处理.例如,在提取的特征向量中,涵盖了多种类型的名义数据,如arp,esp,icmp,igmp,ospf,rtp,tcp,udp,udt.为每种协议分配一个数字等价物,如arp为1,esp为2,icmp为3,igmp为4,ospf为5,rtp为6,tcp为7,udp为8,udt为9.同样地,其他类型的数据也可以被转换成数值.
1.2 基于CNN和BiLSTM的检测分类模块
本节描述基于CNN和LSTM组合深度学习模型的检测分类模块结构.它提供了一种强大且稳健的技术,可有效地区分恶意行为和正常用户;同时,该技术还能够分类主要的攻击类型以及攻击子类.
如预处理步骤中所述,网络数据(特征)被标准化到一个标准区间.在这里,使用了Min-Max标准化函数放大/缩小特征值.标准化过程对模型非常有益,因为它可以加速特征值的收敛,并减少过度拟合.
1) 卷积层.特征标准化后,被分批输入CNN的第1层卷积层,使用核滤波器生成特征映射.输出特征数量,如式(2)所示:
(2)
其中fin是输入特征数,k是核尺寸,p是填充大小,s是步长.使用ReLU激活函数f(x)=max(0,x)处理特征图,以减少过拟合并传递到池化层.卷积层通过减少数据维度并识别关键特征来提高模型效率.
2) 池化层.池化层在CNN模型中通过合并卷积层识别的特征,降低特征图的维数以防止过拟合.常用的池化函数包括最大池化和平均池化,分别选取滤波器覆盖区域的最大值和平均值.
3) BiLSTM是LSTM[8]的变体,它通过双向连接学习时间序列数据中的长期依赖关系,从而优于标准LSTM模型.在处理步骤中,池化层输出的特征图输送至BiLSTM进行时间序列分析,有效解决反向传播过程中的梯度消失问题.LSTM单元包含输入门、遗忘门、细胞状态和输出门,这些组件共同实现序列数据的学习.
遗忘门负责识别和保留关键信息,同时忽略不相关数据.它结合当前输入xt和前一隐藏状态ht-1决定保留哪些信息.通过Sigmoid激活函数σh处理,遗忘门输出介于0~1之间的值,其中接近1的值标识为重要信息.在时间t的遗忘门ft计算如式(3)所示:
ft=σh(Wf·[ht-1,xt]+bf),
(3)
其中Wf是权重矩阵,ht-1是前一隐藏状态,xt是当前输入,bf是偏置项.遗忘门输出的值通过Sigmoid函数确定,从而决定每个状态下哪些信息被保留或遗忘.
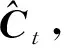
it=σh(Wi·[ht-1,xt]+bi),
(4)
(5)
其中Wi是通过Sigmoid激活函数生成的输入和遗忘门的加权矩阵值,WC是通过激活函数tanh生成的输入和遗忘门的加权矩阵值,bi和bC都是偏置值.
在输出门之前需要处理细胞状态,细胞状态Ct计算如下:
(6)

在LSTM架构中,输出门Ot是最后一个门,其作用是确定哪些信息将从细胞状态传递到下一个LSTM单元.输出门将当前输入和前一个隐藏状态的信息结合起来,并通过一个Sigmoid激活函数进行处理.同时,从细胞状态Ct产生的输出信息通过一个激活函数tanh进行处理.最终,这2个激活函数的结果进行逐点相乘,产生最终的输出,然后传递到下一个LSTM单元.
输出门Ot和最终的LSTM输出ht的计算公式如下:
Ot=σ(WO·[ht-1,xt]+bO),
(7)
ht=Ot·tanh(Ct),
(8)
其中σ是Sigmoid激活函数,WO是输出门权重矩阵,Ct是细胞状态信息.
1.3 恶意行为检测阶段
评估系统的网络恶意行为检测能力时,需考虑系统识别恶意活动的程度及其与用户正常行为的区分能力.传统安全系统仅在登录阶段验证用户名和密码,一旦黑客获取用户凭证,入侵检测系统难以察觉黑客的系统内活动.因此,关键在于识别已登录用户的行为是否正常.系统管理员需对异常行为或潜在恶意行为的用户进行监控与响应.本文提出的系统能够在用户会话期间持续监控网络流量,并分析任何级别的证据和行为.当恶意行为检测系统发现输入实例与训练数据的相似性时,基于NSL-KDD和KDD CUP数据集的模型,CNN-BiLSTM安全机制将记录用户的访问信息.
1.4 识别阶段
检测异常行为后可明确其异常类型.恶意行为在特征向量结构中得以自动记录,并被精准归类为不同攻击类型,涉及行为异常的多类别分类.攻击性质在此处是核心考量.识别阶段一旦探测到恶意行为,将依据攻击类别判定异常种类.
本文简述了利用NSL-KDD数据集攻击分布进行异常分类的技术.识别过程是一项多类别分类任务,输入观测值(即特征向量)被划分为NSL-KDD数据集中的4种攻击类型之一.训练阶段,建议的模型基于数据集中的模式进行学习,从而使系统掌握异常行为(攻击)的关键特征知识.
2 实验结果与评价
2.1 评价指标
对以机器学习技术为中心的方法其性能评估,取决于计算混淆矩阵以评估分类器系统的性能;在恶意行为检测问题中,通常会检测到恶意观测值相对于正常观测值.常见评估指标如精度(precision)、召回率(recall)和F-measure.
2.2 评价目标
恶意行为识别模块有3个阶段:检测阶段、主攻击分类阶段和攻击子类别的分类,因此,本节基于以下研究问题对各阶段进行实验性评估:
1) 本文提出的CNN-BiLSTM技术在区分恶意观察与正常观察方面的准确性是研究的主要关注点.研究问题1(RQ1)专注相对于正常活动检测恶意行为的能力.在安全监控层面,确认当前登录用户是否为授权用户是关键所在.在此环节,系统管理员的职责是识别并响应展现异常或潜在恶意行为的用户.
2) 检测到的恶意行为被准确划分为NSL-KDD和KDD CUP数据集中定义的多种攻击类别.研究问题2(RQ2)探究了在NSL-KDD数据集中不同异常行为之间的相似性及其分类的准确性;重点是识别不同的攻击类型.识别阶段若检出恶意行为,则异常类型将根据列出的攻击种类进行分类.
3) 在系统的附加分类阶段,研究探讨了所提出技术在准确划分不同类型攻击子类别方面的效能.
2.3 评价结果
为了评估CNN-BiLSTM技术在NSL-KDD数据集上的性能和效果,基于前面的评估指标,在NSL-KDD数据集上进行了实验.在检测性能的评估中,考虑了正常和恶意2个类别.用于训练CNN-BiLSTM模型的测试数据集共包含44556个实例,其中正常模式有23117个,恶意模式有21439个.采用本文提出的技术,生成一个包含2000个样本(包括正常和恶意模式)的测试数据集.NSL-KDD数据集中RQ1性能测量结果如表1所示:

表1 NSL-KDD数据集中RQ1的性能测量结果
为评估本文提出的CNN-BiLSTM技术在分类NSL-KDD数据集中4种主要攻击类型方面的能力.本文实验首先分析了NSL-KDD数据集中的71463个恶意样本,以此构建用于评估CNN-BiLSTM技术的训练数据集.随后,从该数据集中挑选出所有恶意实例(21439个样本)作为测试集.基于CNN-BiLSTM技术在NSL-KDD数据集上的性能,结果如表2所示:

表2 NSL-KDD数据集中主要攻击类别的性能结果
2.4 方法对比
本节将提出的模型与当前最先进的网络恶意行为检测技术进行对比.对比的维度包括:1)识别特定攻击或多种恶意行为的能力;2)仅检测恶意行为还是同时具备分类行为异常类型的能力.基于检测率(DR)、误报率(FAR)、精度(precision)和F-measure等指标,对比本文算法与其他算法的性能.近10年的研究表明,许多技术仅能检测特定类型的攻击.如:文献[9-11]中的技术只能检测DoS攻击,无法识别其他类型的恶意行为;文献[12]的研究仅能检测勒索软件;文献[13]提出的技术专注于僵尸网络的检测.实际上,检测技术若仅针对单一类型的攻击,这将成为安全系统的一个显著缺陷.具体对比结果如表3所示:
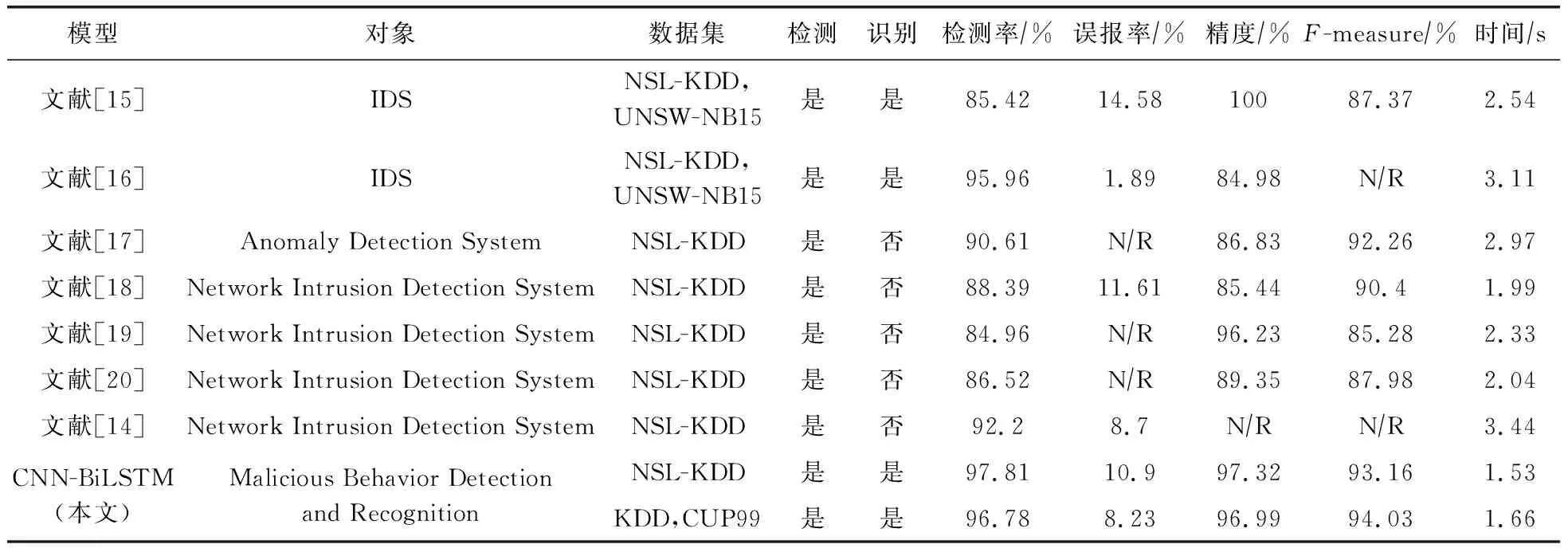
表3 与先进的网络异常检测技术对比结果
本文提出的技术能够检测并分类多种恶意行为,相较于文献[14-20]中的方法,在识别和分类检测到的威胁方面更为有效.本文模型不仅能检测恶意行为,还能根据NSL-KDD数据集中的攻击类型对异常进行分类,使得针对不同攻击(如DoS,Probe或R2L)的响应更加精确.然而,由于某些攻击(如间谍攻击)高度模仿正常行为,可能干预检测正常模式的准确性.表3的性能比较显示,本文模型在区分恶意行为和正常行为方面相较于其他入侵检测模型具有显著优势.
3 结 语
本文提出了一种基于机器学习的方法,用于有效检测和区分恶意与正常实例,并在NSL-KDD数据集上识别及分类多种攻击类型.采用结合CNN和BiLSTM网络的深度学习技术,对数据集中的正常和恶意模式进行训练.在模型的第1阶段(检测阶段),系统能够准确识别大量的正常行为中的恶意行为.第2阶段(攻击分类)中,检测到的恶意行为按相关攻击类型进行分类.实验结果显示,本文提出的检测和分类系统在性能上显著优于现有对比方法.
