基于联邦学习和差分隐私的文本分类模型研究
2023-12-05盛雪晨陈丹伟
盛雪晨 陈丹伟
(南京邮电大学计算机学院、软件学院、网络空间安全学院 南京 210023)
随着互联网上文本数据的爆发式增长,未分类的数据难以提取有用信息,也浪费了网络资源.为了处理这些庞大的数据,适用于高度分布式和面向数据的新型计算框架应运而生.文本分类作为文本处理的重要技术之一,广泛应用于各自然语言处理任务中.
许多现实的NLP服务严重依赖用户的本地数据(如文本消息、文档及其标签、问题和选定答案等),这些数据可以存储于个人设备上,也可以位于组织的大型数据仓库中.根据许多数据隐私规定,这些本地数据通常被视为高度隐私,因此他人都无法直接访问;这使得很难训练高性能模型来造福用户,并且传统的分布式机器学习已经不能处理隐私泄露风险问题.
联邦学习[1]是一项突破性的技术,旨在解决分布式机器学习中的隐私问题,特别适用于需要保护隐私的应用场景.联邦学习和分布式机器学习都是拥有不同训练数据的多个训练方共同执行一个深度学习任务.但联邦学习是每个客户端拥有数据,在本地训练模型,而不需要上传数据.而分布式机器学习需要将每个客户端的数据收集到一起,在服务器训练最终模型.因此,联邦学习被视为降低攻击和泄露风险、降低数据移动的难度和成本以及满足隐私相关数据存储法规的一个重要研究方向.
2017年,McMahan等人[1]提出了一种新的联邦学习优化算法——联邦平均算法(FedAvg).不同于联邦随机梯度下降(FedSGD)方法,FedAvg在本地完成多个回合训练后返回最终的模型参数,而不是训练得到的梯度.这种方式大大降低了联邦学习的交流成本,提高了系统效率.同年,Bonawitz等人[2]为联邦学习机制设计了安全聚合协议,用于提高系统鲁棒性.Smith等人[3]提出了新型的联邦学习优化方法MOCHA,使用多任务学习的思想来应对联邦学习中的统计挑战.但仅仅依靠联邦学习是无法充分保护用户隐私的,因为攻击者可以通过伪造客户端数据或者修改模型更新等方式攻击全局模型,而参与方是联邦学习系统中最大的脆弱点[4].为了解决这些问题,差分隐私作为一种隐私保护技术被广泛应用于联邦学习隐私保护领域.Jayaraman等人[5]提出的隐私保护方法是在服务器聚合全局模型时添加拉普拉斯噪声,以保护客户端数据的隐私.Geyer等人[6]提出的方法是通过添加高斯噪声实现差分隐私,但在每个轮次结束时重新计算隐私损失可能会导致信息泄露,并且在对梯度进行裁剪时会消耗一部分隐私预算.
针对上述问题,本文提出一种基于隐私的文本分类系统,将BERT与差异隐私相结合,在基于FL的设置上,探索不同的隐私预算,以调查隐私效用权衡,希望客户端的整个数据集受到保护,免受来自其他客户端的差异攻击.以解决现有分布式框架在训练模型时出现的特征暴露和无法保护隐私的问题.
1 背景知识
1.1 联邦学习
1) 联邦学习介绍.
联邦学习是一种分布式的机器学习框架,McMahan等人[4]在2016年首次提出联邦学习技术,允许用户在机器学习过程中既可以保护用户隐私,又能够无需源数据聚合而形成训练数据共享.
根据数据在特征和样本ID空间中的各方之间的分布情况,将联邦学习分为横向联邦学习、纵向联邦学习和联邦迁移学习.
其中横向联邦学习是指各方的数据集拥有相同的特征集合,但是样本标签不同.适用于各方数据分布相同、各方的目标任务也相同的情况.例如,多家医院的患者存在小部分相同,但针对同一类型的疾病却有着相似的病症.即不同地区的相同类型机构的用户群体在横向上差别很大,但在数据特征维度上有着很强的相似性.
2) 联邦学习算法.
横向联邦学习的基本算法流程如下:
① 模型初始化.服务器初始化模型参数w.
② 下发模型.服务器同步模型将参数w给所有的客户端,确保初始化的权重一致.
③ 本地训练.客户端基于共享的模型参数,在本地使用私有数据集进行模型训练,并更新模型参数为w′.
④ 模型聚合.服务器收集参与方更新的权重,并根据需求使用相应的聚合算法计算新的权重,如FedAvg[1],FedProx[7].
⑤ 更新全局模型.服务器根据计算结果更新全局模型参数.
重复上述过程,直到算法收敛.
1.2 差分隐私
定义1.(ε,δ)-带松弛的差分隐私.对于随机化机制M,其定义域为D,值域为R.如果任意2个相邻输入d,d′∈D,以及任何输出的子集S⊆,满足:
Pr[M(d)∈S]≤exp(ε)Pr[M(d′)∈S]+δ,
(1)
则称随机化机制M满足(ε,δ)-差分隐私[8].
其中ε表示隐私预算,δ表示错误概率.通常来说,ε越小差分隐私保护效果越好,但是加入的噪声也会越大,导致数据可用性下降.当δ=0时,表示严格的差分隐私.由于严格差分隐私的保护过于苛刻,因此本文采用的是带松弛机制的近似差分隐私.
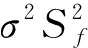
定义2.高斯噪声:
(2)

本文差分隐私是指对数据的训练以及对隐私的保护过程全部在客户端实现.即保护整个客户的数据集.这种差分隐私机制的优点在于用户可以全权掌握数据的使用与发布,无需借助中心服务器,最有潜力实现完全意义上的去中心化联邦学习.
1.3 BERT
本文方法是基于BERT模型构建的.BERT的主要模型是Transformer,而Transformer的主要模块就是self-attention. BERT[10]是第1个基于微调的表示模型,它在大量句子级和令牌级任务上实现了最先进的性能,优于许多特定于任务的体系结构.
BERT主要有2个主要步骤,即预训练(pre-training)和微调(fine-tuning),这2个步骤如图1所示:
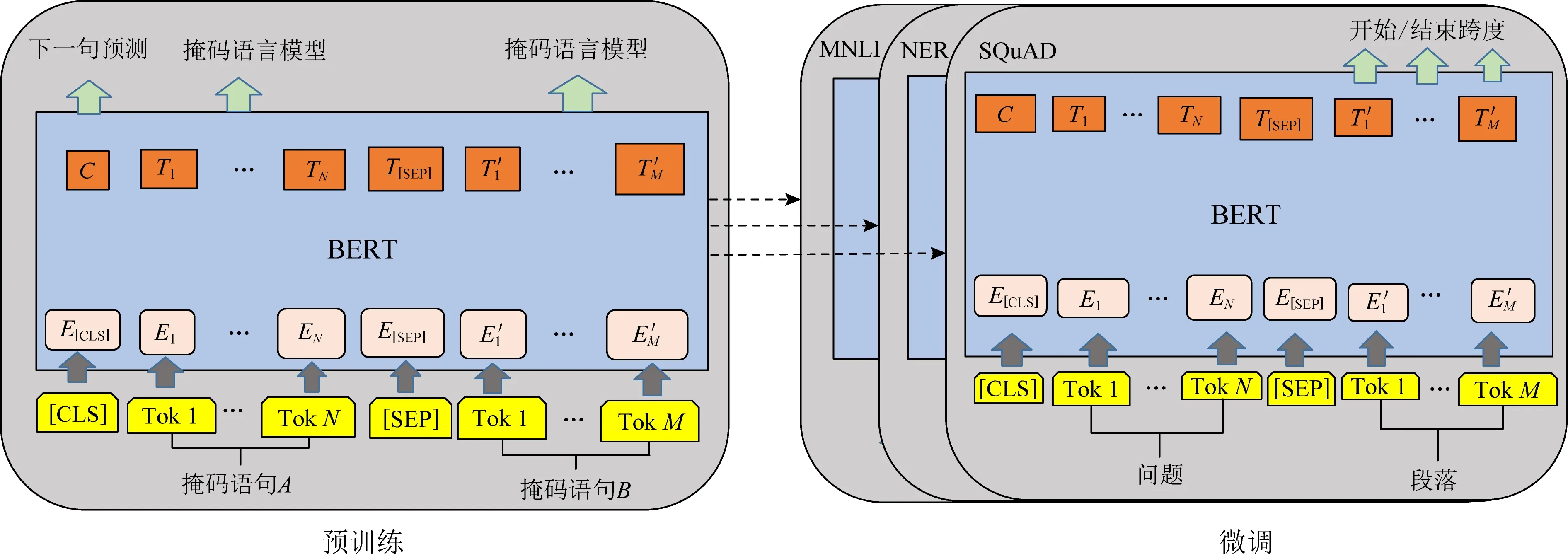
图1 BERT的预训练和微调程序
2 方法设计
2.1 问题描述
联邦学习的主要创新性在于提供了一种具有隐私保护特性的分布式机器学习框架,并且能够以分布式的方式针对某个特定机器学习模型进行迭代训练[1].然而联邦学习过程依然存在一定的安全问题.在联邦学习场景中,攻击行为不但可以由不受信任的服务器发起也可能由恶意用户发起[11].目前常见的联邦学习应用的参与方都是个人用户,个人用户的防护措施薄弱,攻击成本低,与聚合服务器相比更容易受到隐私攻击.为此,需要对联邦学习过程提供额外的隐私保护机制.本文将差分隐私和联邦学习相结合,应用于文本分类场景,保护了本地用户的文本数据隐私同时仍可保证较高的模型准确率.
2.2 模型设计
由于中央服务器是诚实且好奇的,客户端可以信任来自中央服务器的广播,但不应向其暴露未受保护的信息.因此,传输梯度上的噪声添加和差分隐私计算是在客户端执行的,而不是在中央服务器上[12].
本文重新制定了差分隐私联邦学习过程,从而保护客户端数据集的隐私不受中央服务器和其他服务器的影响.在客户端服务器上累积的本地更新被发送到中央服务器之前,噪声被添加到这些本地更新中.
具体的算法思想是首先聚合服务器初始化参数并下载模型,将参数下发到客户端,客户端接收参数后在本地训练模型,在训练的过程中引入差分隐私机制,即在本地添加噪声进行扰动,训练完结果再发送给聚合服务器.服务器接收完所有客户端的参数后根据聚合算法重新计算参数,再将结果发送给客户端.这样一直迭代下去,直到达到迭代轮次或者损失函数收敛.本文方法的模型架构如图2所示:
2.3 算法模型
本文算法由Server层算法和Client层算法组成.
1) 通过剪裁每个示例的梯度范数限制每个示例的敏感度;
2) 将噪声添加到模型参数.
算法1.差分隐私的联邦学习算法.
PROCEDURE(Server Execution)
输入:联邦学习客户端数量N、联邦学习采样率q、联邦学习总轮次T.
① 服务器下载模型,并初始化w0;
② FORt∈{1,2,…,T} DO
③ 以采样率q从N个用户中选择k个参与方;
④ 遍历k个参与方;

⑦ 计算本次迭代模型准确率Acc并打印输出;
⑧ END FOR
END PROCEDURE
FUNCTIONClientUpdate(w,k)
输入:上一轮训练所得模型参数wt、客户端模型迭代次数E、客户端数据集大小y、随机梯度下降中每批次选择的训练集大小D、学习率γ、参与方模型损失函数L(w)、梯度裁剪阈值C、差分隐私机制隐私参数εi,δi.
⑨ FORe∈{1,2,…,E} DO
⑩ 训练集D中的每个数据d;
END FUNCTION
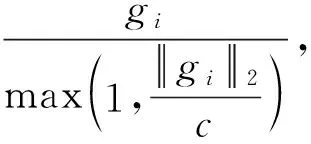
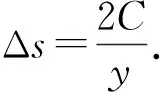
在本文实验中,根据平衡数据集上的模拟实验,给定采样率q和参与方数量N,进行一系列实验以使用不同的ε在BERT模型和DistilBERT模型上验证测试精度.其中DistilBERT[14]是一种小型、快速、廉价和轻量级的Transformer模型,其参数比Bert-base-uncased 少40%.
3 实验与分析
3.1 实验设置
3.1.1 实验环境
本节对本文方法的有效性进行评估,并设计对比实验.实验平台操作系统为Ubuntu20.04.1,编程语言为Python 3.8,采用BERT模型和DistilBERT模型训练文本分类.其中BERT模型编码器层数为12,隐藏层大小为768,自注意力头个数为12;DistilBERT模型编码器层数为6,隐藏层大小为768,自注意力头个数为12.批次大小为16,最大序列长度为128,学习率为1E-4,联邦学习迭代轮次为20.
3.1.2 实验数据集
本文使用的数据集是20Newsgroup,是用于文本分类、文本挖掘和信息检索研究的国际标准数据集之一.数据集收集了18846条新闻组文档,分为20个不同主题的新闻组集合.其中训练集为11314条数据(60%),测试集为7532条数据(40%),不包含重复文档和新闻组名.
3.2 结果分析
为了验证本文方法的优越性,选择不同的联邦算法,即FedAvg,FedOPT和FedProx进行对比,使用准确率评估方法的性能.准确率(Acc)是指分类正确的样本占总样本数的比例,定义为
(3)
使用20Newsgroup数据集,联邦学习迭代轮次round=20.探究隐私预算对准确率的影响,在采样率q=1、参与方N=100的情况下,分别设置隐私预算ε=1,ε=5,ε=10,结果如图 3所示.
由图3可知:

图3 BERT模型下不同隐私预算的准确率
1) 在采样率q、差分隐私被破坏概率δ和参与方数量N不变的情况下,随着ε的增加全局准确率也会增加.因此可以适当调整ε的大小提高模型准确率.
2) 在round=20之后模型准确率趋于稳定.
探究本文方法与其他3种联邦学习方法FedAvg,FedOpt[15],FedProx全局准确率的对比情况.设置参与方数量N=100,采样率q=1,总体隐私预算ε=10,图4分别展示了4种方法在BERT模型和DistilBERT模型上的全局准确率随迭代轮次的变化情况:
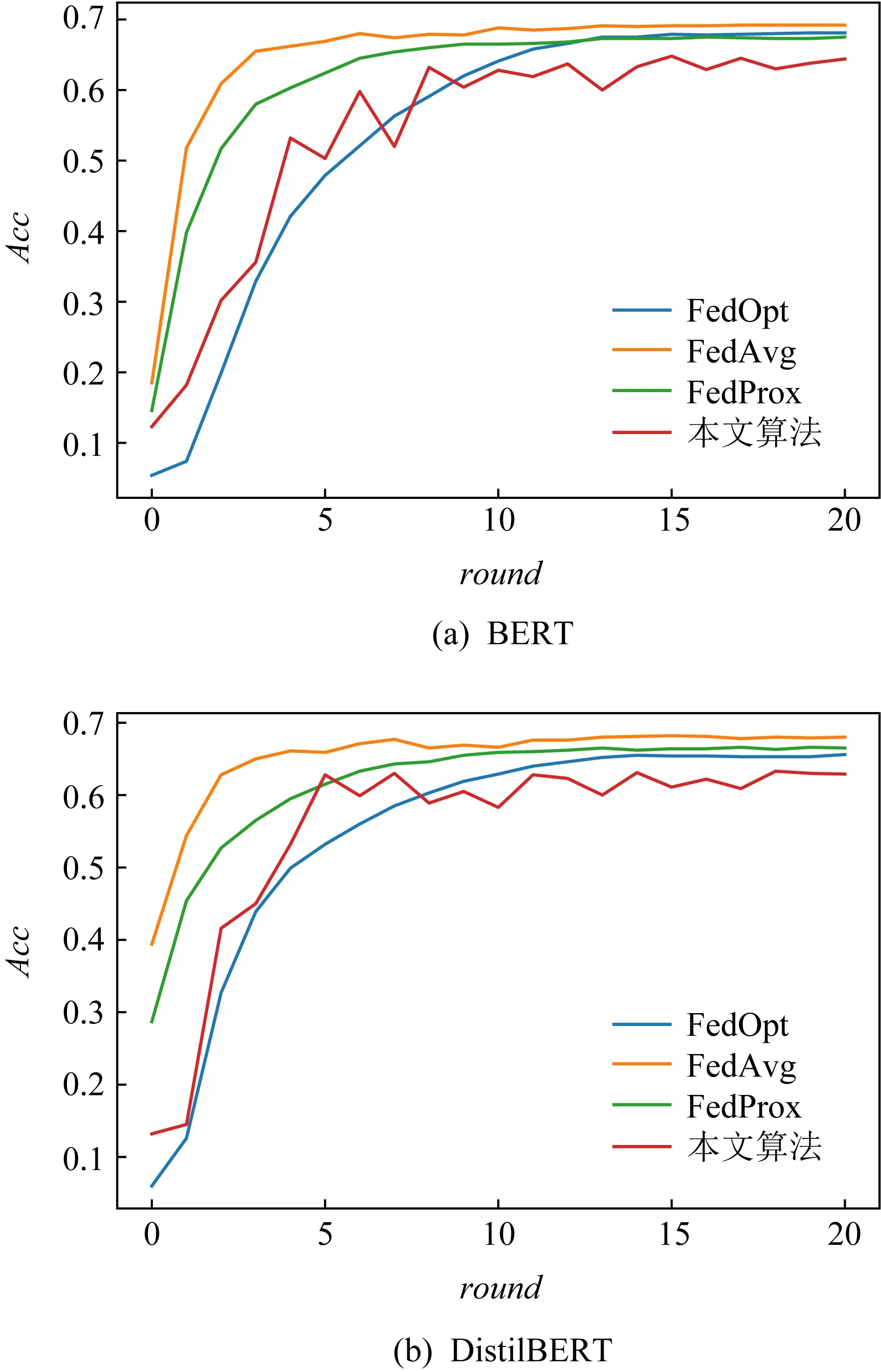
图4 4种方法在BERT模型和DistilBERT模型上的全局准确率
观察图4可知:
1) 在参与方数量相同的情况下,引入差分隐私后全局准确率在2种模型上均略低于其他3种方法,说明与无噪声方法相比,引入噪声机制会对联邦学习模型的准确率造成影响.
2) 虽然准确率略低于FedOpt,但很接近.即在保护隐私的同时还能保证可观的准确率.通过对比,BERT比DistilBERT的准确率更好,具有更好的性能,其模型尺寸更大.尽管BERT基础实现了更好的性能,但DistilBERT的性能并没有显著下降.
4 结 语
随着联邦学习的快速发展和广泛应用,联邦学习模型的安全和隐私问题吸引了许多学者的关注,产生了不少瞩目的研究成果,但目前相关的研究还处于初级阶段,尚有许多关键问题亟待解决.本文在充分调研和深入分析的基础上,对联邦学习在隐私领域存在的问题进行了描述,从而将差分隐私与联邦学习相结合,并应用于文本分类场景.通过实验表明,在客户层面上的差异隐私是可行的,当涉及足够多的参予方时可以达到较高的模型精度;在DP+FL的环境下,随着ε的增加,模型表现出更好的性能以及显示出很大的保护功能.未来可优化的方向包括减少通信次数、如何克服联邦学习的Non-IID问题,并研究这些场景下如何在保证隐私安全的同时提高模型的全局准确率.
