基于随机森林和支持向量机的古代玻璃制品成分分析与鉴别
2023-12-05李公全林旭旭周里琼
李公全,林旭旭,彭 梅,周里琼
(湖南科技学院,湖南 永州 425199)
玻璃是代表东西方工艺技术的产品,沿着“一带一路”贸易往来传播,见证了东西方贸易文化的交流。古代玻璃极易受埋藏环境的影响而风化。在风化过程中,内部元素与环境元素进行大量交换,导致其成分比例发生变化,从而影响对其类别的正确判断。为了对古代玻璃制品进行更加准确的分类和保护,分析文物样品表面风化前后化学成分含量的变化规律,探究高钾玻璃、铅钡玻璃的分类规律并对其进行亚类划分是至关重要的。目前很多学者对古代玻璃的研究重点放在了玻璃的出土地、制造技术等方面[1-4],对类别未知的古代玻璃进行正确分类研究较少。因此本文建立随机森林和支持向量机算法对古代玻璃的成分进行分析和鉴别,从而对玻璃正确分类。模型充分联系实际,具有很好的通用性和推广性。
1 数据预处理
本文采用的数据来源于“全国大学生数学建模竞赛”官网,官网提供了58 个我国古代玻璃制品的表面风化情况,考古工作者通过专业的技术手段已经给出了这些文物样品的14 种化学成分含量比例和玻璃类型。现有未知类别的一批玻璃文物相关特性和基本信息,拟对该批玻璃进行鉴别,确定其所属类别。数据见表1。

表1 玻璃文物的基本信息
由于这些数据的特点是成分性,即各成分比例的累加和应为100%,但因检测手段等原因可能导致其成分比例的累加和非100%的情况。本文将成分比例累加和介于85%~105%之间的数据视为有效数据,并对不位于这个比例的数据进行删除。
2 基于随机森林的分类模型建立
2.1 随机森林基本概述
决策树是一种基于if-then-else 规则的有监督学习算法,是一种树形结构。随机森林是由很多决策树构成的,且不同决策树之间没有关联,其随机森林算法基础结构如图1 所示。

图1 随机森林模型
当利用该算法做分类任务时,每输入一个新样本,森林中的每一棵决策树就会对其进行判别和分类,且每个决策树都会得到一个自己的分类结果,决策树的分类结果中哪一个分类最多,那么这个分类就会被随机森林作为最终结果返回。
2.2 表面未风化玻璃文物的分类规律
首先对玻璃文物表面未风化的样本随机取样训练对应的决策树。该玻璃文物表面未风化数据集共有35个样本,将这些数据进行有放回的随机抽取,训练得到多个不同决策树。然后分别计算训练出的决策树的决定系数,最终选取决定系数R2得分接近1.0 的前5个决策树构成随机森林。
对于表面未风化的玻璃,根据玻璃分类规律建立的随机森林中训练出的7 个决策树分类特征为:SiO2、PbO、K2O、P2O5、BaO、Fe2O3和CaO,即上述7 个化学成分含量是区分表面未风化的高钾玻璃和铅钡玻璃的重要指标依据。
2.3 表面风化玻璃文物的分类规律
首先对玻璃文物表面风化的样本随机取样训练对应的决策树。该玻璃文物表面风化数据集共有32 个样本,将这些数据进行有放回的随机抽取,训练得到多个不同决策树。然后分别计算训练出的决策树的决定系数R2,最终选取决定系数R2得分接近1.0 的前5 个决策树构成随机森林。
对表面风化的玻璃,根据玻璃分类规律建立的随机森林中训练出的7 个决策树分类特征为:SiO2、PbO、K2O、P2O5、BaO、Fe2O3和CaO,即上述7 个化学成分含量为区分表面风化的高钾玻璃和铅钡玻璃的重要指标依据。
3 基于聚类分析的玻璃文物亚分类模型建立
对高钾玻璃和铅钡玻璃选择合适的化学成分对其进行亚类划分,为保证结果的合理性,本文选用数据为表面未风化数据。
3.1 高钾玻璃亚分类模型建立
将高钾玻璃且表面未风化的样本数据提出,对其进行系统聚类。依据2.2 可知,高钾玻璃分类规律建立的随机森林中训练出的5 个决策树分类特征为:SiO2、PbO、K2O、P2O5、BaO、Fe2O3和CaO。因玻璃亚类划分是在玻璃分类规律基础上进行的,故将这7 个化学成分作为系统聚类指标变量。根据SPSS 得到高钾玻璃未风化样本数据谱系图,如图2 所示。

图2 高钾玻璃未风化样本数据谱系图
可将高钾玻璃聚类为3 个亚类。其中,第21 号为第一类,第18 号、第3 号(部分1)、第3 号(部分2)为第二类,其他样本为第三类。
根据样本各个化学成分含量数据,找出这3 类化学成分含量具有明显差异的化学成分,即SiO2、CaO、Al2O3,最终划分结果见表2。
3.2 铅钡玻璃表面未风化亚分类
将铅钡玻璃且表面未风化的样本数据提出,对其进行系统聚类。根据SPSS 得到铅钡玻璃未风化样本数据谱系图,如图3 所示。
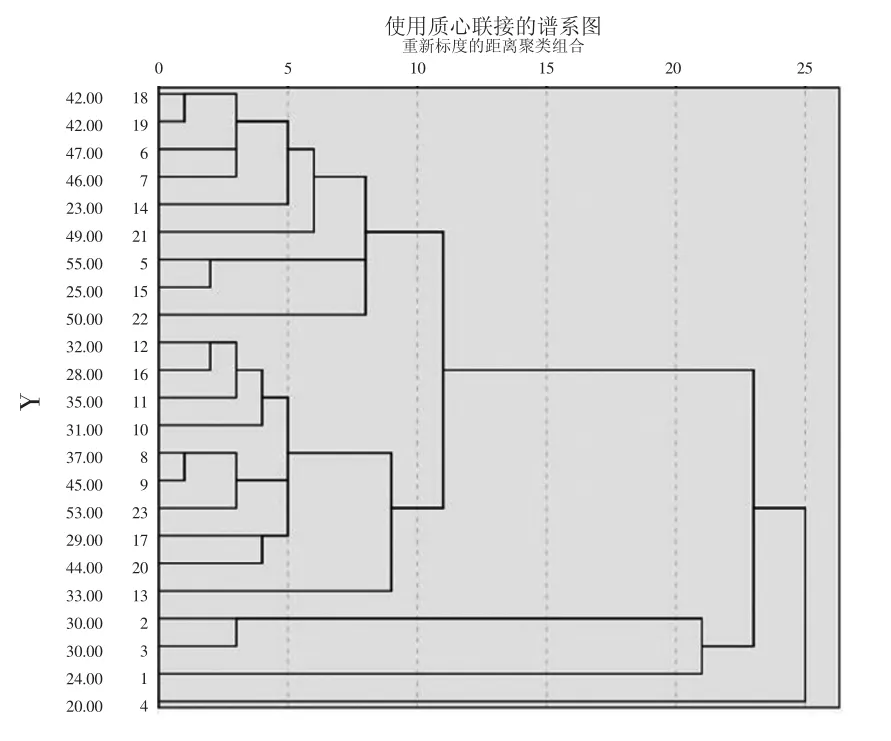
图3 铅钡玻璃未风化样本数据谱系图
通过分析谱系图,将铅钡玻璃聚类为3 个亚类。第一类包括:24、30(部分1、部分2),第二类包括:55、47、46、37、23、25、42(部分1、部分2)、49、50,剩下样本为第三类。分类结束后,将20 号相关化学成分与分完类的化学成分进行比较,比较与哪一类相近则归为哪一类,最终归为第二类。
根据样本各个化学成分含量数据,找出这3 类具有明显差异的化学成分,即SiO2、PbO 和BaO,其最终划分结果见表3。

表3 铅钡玻璃亚类结果
3.3 敏感性分析
为了验证划分方法及其结果是否稳定,需要对其结果进行敏感性检验,从而验证该划分方法的可行性。对高钾玻璃未风化样本的SiO2、CaO、Al2O3相关数据先分别进行白噪声处理,对铅钡玻璃未风化样本的SiO2、PbO、BaO 分别进行白噪声处理。处理后化学成分的新数据替换处理前的数据后,进行同样操作的聚类分析,得到一个新的谱系图,接着将这个谱系图与之前的谱系图进行对比,若聚类结果几乎没有差异,则说明其具有敏感性,反之则不具有敏感性。
1)高钾玻璃中,将SiO2、CaO、Al2O3进行白噪声处理后重新对样品分类。
对比处理前后的谱系图,发现高钾玻璃的聚类结果几乎一致,因此该划分方法具有可行性。
2)铅钡玻璃中,对SiO2、PbO、BaO 进行白噪声处理后重新对样品分类,对比处理前后的谱系图,发现铅钡玻璃的聚类结果几乎一致,因此该划分方法具有可行性。
4 基于支持向量机的鉴别模型
4.1 支持向量机SVM 概述
SVM 是一种有监督学习的算法,在实际分类训练中,将实例表示为空间中的点,以求解能够正确划分数据集并且几何间隔最大距离超平面为目标。除了线性分类,SVM 可以采用内核有效地对高维的特征空间进行非线性分类。支持向量机结构示意如图4 所示。
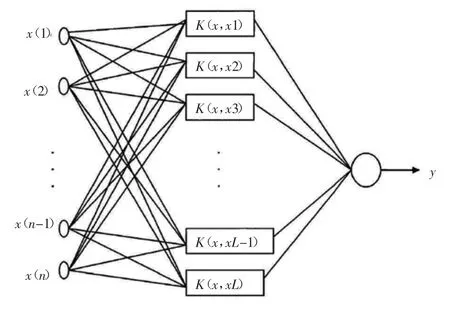
图4 支持向量机结构示意图
其中输入层视为存贮出入数据,并不做任何加工运算;中间层是通过对样本集的学习,选择K(x,xn),n=1,...,L;最后一层局势构造分类函数
式中:bn为非负Langrange 系数,yn为输入数据对应的输出指标,这个过程等价于特征空间中构造一个最优超平面。
4.2 玻璃类型的二分类
对表1 的数据分析发现,玻璃文物表面风化与未风化的数据各有4 个。若要去判别每个玻璃文物是高钾玻璃还是铅钡玻璃,需分别对风化与未风化进行进一步研究。将样本数据分别输入到2.2 和2.3 建立的表面未风化和风化随机森林模型进行判别,判别结果见表4。

表4 待判别文物所属类别结果
4.3 表面未风化文物的亚分类
基于前面的分析得到:高钾玻璃亚类划分的依据是SiO2、CaO 和Al2O3的含量比例;铅钡玻璃亚类划分的依据是SiO2、PbO、BaO 的含量比例。基于此,对每个类型表面未风化样本依据化学成分含量进行SVM 训练,其中对高钾玻璃选取10 个样本作为训练样本,训练出分类模型,2 个样本作为测试样本,检验该分类模型效果;对铅钡玻璃则选取20 个样本作为训练样本,训练出分类模型,2 个样本作为测试样本,检验该分类模型效果。检验结果如图5 和图6 所示。

图5 高钾玻璃未风化训练模型图

图6 铅钡玻璃未风化训练模型
由图5 和图6 可知,2 种玻璃训练出的分类模型效果均较好,则高钾玻璃、铅钡玻璃的亚类划分模型确定。接下来将高钾未风化样本A1 输入高钾玻璃亚类划分模型,得到亚类划分结果见表5。

表5 玻璃表面无风化玻璃亚类结果
4.4 表面风化文物的亚分类
表面风化玻璃部分化学成分含量发生改变,若直接对其进行亚类划分,结果受多种因素的影响,导致结果有较大差异性。首先根据已知的风化的化学成分相关数据,将风化前的各个化学成分预测出来。
将分别求出高钾和铅钡玻璃风化前后各成分相对含量均值差Δξmean,并通过风化后成分加上均值差的方法预测该部位风化前的成分的相对含量
式中:ξerode为风化后的相对成分数据;ξepredict是预测后的数据。
预测出来后,将数据带入上一步建立的表面未风化亚类划分模型,得到分类结果见表6。

表6 玻璃表面风化玻璃亚类结果
5 结论
本文围绕古代玻璃成分分析与鉴别问题,通过对古代玻璃各种成分数据进行分析,建立了基于随机森林的古代玻璃成分分析和亚分类的模型、基于支持向量机的古代玻璃的鉴别模型,并进行了合理性检验,科学论证了其有效性,模型能够对古代玻璃文物的分析与鉴别提供依据,对古代玻璃进行更好的保护。
