大数据发展对我国县域碳排放的影响机理研究
2023-12-04孙光林汪琳琳艾永芳
孙光林, 汪琳琳, 艾永芳
(1.南京财经大学 金融学院,江苏 南京 210023; 2.中国社会科学院 工业经济研究所,北京 100006; 3.大连外国语大学 商学院,辽宁 大连 116044)
推进碳达峰碳中和是我国高质量发展的内在要求。国家互联网信息办公室公布的《数字中国发展报告(2022年)》显示,我国大数据产业规模已达1.57万亿元,同比增长18%,大数据技术与传统产业的深度融合,能够提高生产运营效率,减少能源与资源消耗[1],这为降低碳排放提供了新的路径。然而,大数据自身也会产生大量的二氧化碳,《中国数字基建的脱碳之路:数据中心与5G减碳潜力与挑战(2020-2035)》报告显示,2020年我国数据中心碳排放量高达9 484万t,5G基站碳排放量高达2 799万t,未来仍将保持快速增长。因此,大数据发展对我国碳排放既有机遇又有挑战,探究大数据发展与碳排放之间的关系具有重要的理论和现实意义。
围绕碳排放影响因素的研究产生了大量理论与实证文献。在宏观经济因素方面,包括经济增长、人口、城镇化[2]、能源结构[3]、绿色创新[4]、产业绿色转型[5]、产业结构升级[6]等。在制度因素方面,Ma等[7]认为碳排放权交易体系建设有助于减少城市碳排放;江三良等[8]认为环境规制有利于深化产业内部分工,提升区域碳排放效率。
近年来,数字经济和碳排放存在怎样的关系引起了学术界的关注。一些学者认为数字经济和碳排放之间存在线性关系。数字经济发展能够降低城市碳排放[9],通过提升地区产业数字化和数字产业化水平[10]、促进绿色技术创新[11]、提高能源消费效率和优化能源消费结构[12]等降低碳排放。另一些学者认为,数字经济与碳排放之间呈现先促进后抑制的倒U型关系[13-14]。葛立宇等[15]认为我国数字经济发展和碳排放之间遵循环境库兹涅茨曲线(EKC)。此外,还有一些学者探究了数字金融与碳排放之间的关系,发现数字金融能够通过优化产业结构[16]、提高区域创新和创业水平[17]、降低人均能源消耗和提高人均GDP[18]来降低区域碳排放;甚至有学者认为数字金融对碳排放的影响在总体上呈现出倒U型关系[19]。
学术界从不同方面对大数据进行了定义。Fosso等[20]认为大数据的特征是数量大、种类多、速度快、真实性强、价值高。张叶青等[21]将“大数据应用”定义为“企业收集、处理与利用的海量、高速、多样化的数据要素或资产”。史丹和孙光林[1]将“大数据发展”定义为大数据发挥作用依赖的制度条件和市场条件。史丹和孙光林[1]对大数据发展的定义为本文开展研究奠定了基础。事实上,大数据会给经济发展带来诸多机遇,有利于提高制造业企业绿色竞争力[22]和制造业全要素生产率[1],而且设立大数据试验区能够激发创业活力,促进人力资本积累及城市经济高质量发展[23]。然而,却较少有文献涉及大数据发展对碳排放的影响及其内在作用机理。
因此,与已有研究文献相比,本文创新点主要体现在以下两个方面:一是本文基于我国2015—2018年县域面板数据,从直接效应和作用机制两个方面考察大数据发展对碳排放的影响,能够为后续相关研究提供借鉴;二是在我国数字经济快速发展与实施双碳战略的时代背景下,本文系统性探讨大数据发展与碳排放之间的内在机制,研究结论对于发展大数据产业,以及赋能双碳战略,都具有重要的参考价值。
1 理论框架与研究假说
1.1 大数据发展影响碳排放的直接效应
大数据作为数字时代的新兴产业,为我国低碳化发展提供了新路径和新机遇。
首先,大数据通过与制造业、电力、交通等传统高排放产业深度融合,能够优化资源配置[23],提升能源资源使用效率,从而降低碳排放[24]。
其次,大数据具有强大的信息搜寻与数据处理能力,能够降低市场供给双方的信息不对称程度,使企业能够精准分析消费者的喜好及使用习惯,及时捕捉到用户对产品的反馈以及市场对新产品的偏好,能够减少因需求和供给不匹配所造成的资源浪费,从而有助于降低碳排放。
再次,大数据发展能够重塑居民的生产生活方式,“视频会议”、“线上购物”、“线上课程”以及“远程医疗”等的广泛应用,能够减少交通工具的使用,从而降低碳排放。
最后,大数据的监测功能,可以帮助政府分析处理庞大的碳排放相关数据,有利于提升碳减排政策的精准度。
此外,在节能产品领域,大数据发展不仅有利于推动节能产品创新升级,而且借助于大数据技术的宣传推广功能,可以提升节能产品在居民生活的应用范围,引导居民的生活方式向绿色节能转变,进一步降低整个经济社会的碳排放水平。因此,基于以上理论分析,本文提出基本研究假说H1。
H1:大数据发展对碳排放具有抑制作用。
1.2 大数据发展影响碳排放的理论机理
1.2.1电力消费中介理论机理
大数据发展对电力消费具有提升作用,表现在以下两个方面。
1) 大数据产业是以通信技术的发展为基础的,而通信技术发展会消耗大量电力;同时,我国数字化发展遵循“先硬件、后软件”的规律[25],在大数据发展初期,需要大力推进 5G基站、数据中心等数字基础设施建设,会增大电力需求。
2) 数据中心在数据处理、存储、传输等过程中发挥着重要作用,其日常运营过程中会消耗大量电力。然而,并不能仅从数字基础设施单方面考虑大数据发展与电力消耗之间的关系,也应当考虑大数据发展推动产业数字化过程中产生的价值增量。
产业数字化有利于大数据产业与传统产业的深度融合,提升传统产业生产和运营效率,降低传统产业电力消耗。与此同时,随着电力大数据、智能电网等的广泛应用,大数据的实时监测功能和预测功能将更好地发挥作用,解决电力消费不合理问题,从而优化用电结构,提升电网和电力设备运行效率,降低单位产值耗电量。因此,随着传统产业数字化的不断推进,大数据发展对传统产业的节能边际贡献会逐渐超过自身发展所增加的电力消耗,用电效率将会明显提升。
从清洁电力角度来看,大数据发展有利于提升清洁电力占比,从而降低碳排放。可再生能源(如风电、水电和光伏等)受气候因素影响较大,发电过程的间歇性和不稳定性已经成为制约其发展的重要因素。大数据技术能够优化能源管理,实现对发电端、用户端和输配电整个流程实时数据的监控和采集,有助于提升电力系统对新能源发电的消纳能力,从而使可再生能源供需达到更佳的状态,提高清洁电力消费占比,降低碳排放。因此,基于以上理论分析,本文提出基本研究假说H2a和H2b。
H2a:大数据发展与电力消费之间存在倒U型关系,且大数据发展会通过电力消费对碳排放产生间接影响。
H2b:大数据发展可以通过提高清洁电力占比来降低碳排放。
1.2.2绿色创新中介理论机理
大数据发展能够通过促进绿色创新而降低碳排放。大数据发展对绿色创新的促进作用表现在以下几个方面。
首先,大数据能够跨越时空限制打破“信息孤岛”,降低信息不对称程度,使各绿色创新主体之间的合作更加紧密。
其次,由于绿色创新比传统创新资金投入规模更大,获利周期更长,融资约束会更加严峻[26]。对金融机构而言,大数据的深度应用可以帮助金融机构实现对企业的精准画像,更加全面地评估企业的财务经营状况和发展前景,缓解企业融资约束,从而为企业绿色创新提供资金支持。
最后,大数据发展能够推动企业与需求方之间形成协同演化关系,降低企业绿色创新研发风险,从而推动企业绿色创新[24]。
进一步来看,绿色创新有利于降低碳排放[27]。首先,在生产和消费端,绿色创新是引导社会生产向绿色低碳转型的重要推动力,不仅能够引导消费者绿色消费,还可以引导企业提高绿色生产能力,扩大绿色低碳产品供给。其次,绿色创新有助于淘汰落后产业,促进低附加值产业向高效率、低污染环保型、高附加值产业转型升级,降低碳排放。最后,绿色创新的“节能效应”有助于提升传统化石能源的清洁高效利用,减少能源消耗,降低生产成本和单位GDP能耗。因此,本文提出基本假设H3。
H3: 大数据发展可以通过促进绿色创新降低碳排放。
2 研究设计
2.1 数据来源
本文使用的县域碳排放数据来源于国泰安数据库,且完整的县域碳排放数据只更新到2018年。考虑到我国大数据发展战略始于2014年,本文借鉴史丹和孙光林[1]的做法,选择2015-2018年数据构建大数据发展指数(考虑到数据的可获得性与可比性,剔除西藏和港澳台地区的数据)。具体指标如表1所示。本文所使用的专利数据来源于国家知识产权局,其它数据主要来源于Wind数据库、中国能源数据库、《中国县域统计年鉴》与国家统计局网站。值得注意的是,本文构建面板数据集进行回归分析是将县域与其所在省域进行匹配研究。
2.2 变量说明
2.2.1被解释变量:碳排放
由于县域碳排放量数值较大,为了消除潜在异方差的影响,本文对碳排放数据取对数处理,用lco2表示。
2.2.2核心解释变量:大数据发展
借鉴史丹和孙光林[1]的做法,对我国省域层面大数据发展进行测度,其中,制度条件包括大数据政策力度、大数据试点创新等4个二级指标,市场条件包括电子商务发展指数、科技投入等6个二级指标,具体指标参见表1。最后,本文使用熵值法对大数据发展Dbigdata进行测度。

表1 大数据发展指标评价体系Tab.1 Index evaluation system of big data development
2.2.3机制变量
1) 电力消费。电力消费为省域层面电力消费规模,考虑到数据潜在存在的异方差问题,对该变量lec取对数处理。
2) 清洁电力占比。使用各省市区清洁电力使用占总电力消费的比例来衡量,用pce表示。
3) 绿色创新。本文借鉴艾永芳和孔涛[24]的做法,分别使用绿色专利申请总数ngreen1、绿色发明专利申请总数ngreen2衡量绿色创新。
2.2.4控制变量
由于碳排放受到多种因素的影响,为了更精确地检验大数据发展对碳排放的影响程度,本文选取以下控制变量:经济规模Esize、产业结构Is、城镇化水平Lurb、外商直接投资ifdi、能源消费结构Ies、区域经济发展Dlmgdp、环境治理投入ieg这7个变量作为控制变量,具体计算方式如表2所示。
2.3 模型构建
2.3.1基准回归模型
本文通过构建普通面板固定效应回归模型考察大数据发展对县域碳排放的直接影响,如式(1)所示。
lco2,i,j,t=β0+β1Dbigdata,i,t+βX+γj+θt+ε
(1)
式中:lco2,i,j,t表示i省市j县(市)t时期的二氧化碳排放量;β0表示常数项;Dbigdata表示大数据发展;X为控制变量向量;β表示控制变量系数值向量;ε表示随机扰动项;系数值β1反映了大数据发展对碳排放的影响程度,是本文重点关注的参数;γj表示县域固定效应,控制县域虚拟变量是为了控制县域层面一些不随时间变化的特征,如地理位置和文化等;θt表示时间固定效应,控制时间虚拟变量是为了控制一些时间效应特征,如年度经济形势变化等。
2.3.2机制回归模型
借鉴史丹和孙光林的做法[1],本文构建的机制回归模型如下所示:
Vmedia,i,t=α0+α1Dbigdata,i,t+
βX+γj+θt+ε
(2)
lco2,i,j,t=δ0+δ1Dbigdata,i,t+δ2Vmedia,i,t+
βX+γj+θt+ε
(3)
式中:α1表示大数据发展对机制变量的影响程度,α0为常系数。
模型(3)是将机制变量和大数据发展同时纳入回归方程。δ1和δ2是本文重点关注的参数,若二者均显著则表明机制变量在大数据发展影响碳排放的过程中存在显著的中介效应。

表2 变量定义Tab.2 Variable definitions
3 实证结果分析
3.1 基准回归结果
由表3的A列回归结果可知,大数据发展对县域碳排放影响的系数为-0.084,在1%的水平下显著,说明大数据发展有利于降低碳排放;由表3的B列可知,在加入经济规模、产业结构、城镇化水平等7个控制变量后,大数据发展的系数值在1%的置信水平上显著为负,再次说明大数据发展对县域碳排放具有抑制作用。
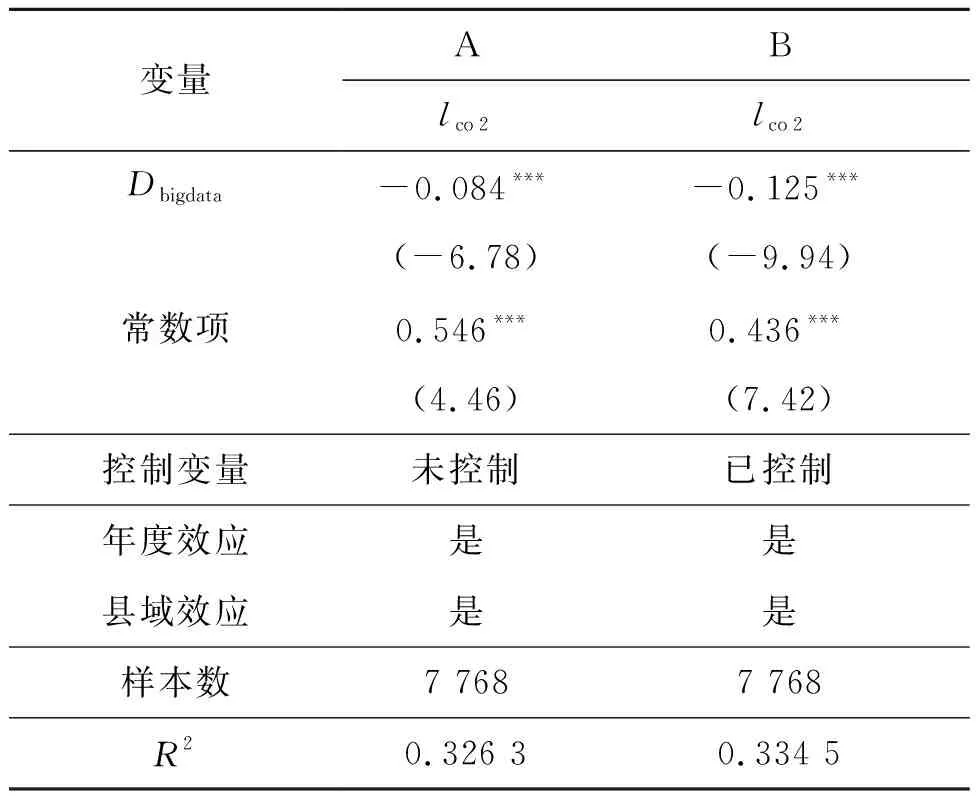
表3 大数据发展对碳排放量的影响Tab.3 Impact of big data development on carbon emissions
3.2 作用机制分析
3.2.1基于电力消费的作用机制检验
由表4中A列回归结果可知,大数据发展的一次项回归系数值在5%的置信水平下显著为正,大数据发展的二次项回归系数值在5%的置信水平下显著为负,表明大数据发展与电力消费之间存在着显著的倒U型关系,即大数据发展前期会增加用电量,但随着大数据发展红利的不断显现,大数据发展会提升用电效率。由表4中B列回归结果可知,大数据发展对碳排放的影响在1%的置信水平上显著为负,电力消费对碳排放的影响在1%的置信水平上显著为正,说明电力消费在大数据发展影响县域碳排放的过程中具有非线性中介效应。
表4中C列使用大数据发展一次项对电力消费进行回归,大数据发展的系数值在1%的置信水平上显著为正,表明当前大数据发展对电力消费的影响处于提升阶段,这一结果与“倒U型”结论并不矛盾,主要原因是当前我国大数据发展水平仍然较低,数字基础设施的大规模扩张、设备运行能耗较高等增大了电力消费。因此,大数据发展对电力消费的影响表现为正[1]。
在表4的D列和E列引入清洁电力占比pce变量,由D列可知,大数据发展对清洁电力占比的回归系数在1%的置信水平上显著为正,表明大数据发展能够提升清洁电力占比。E列回归结果表明,大数据发展和清洁电力占比的系数值均在1%的置信水平上显著为负,说明清洁电力占比的中介效应显著,即大数据发展可以通过提升清洁电力占比降低碳排放。因此,基本研究假设H2b得到验证。
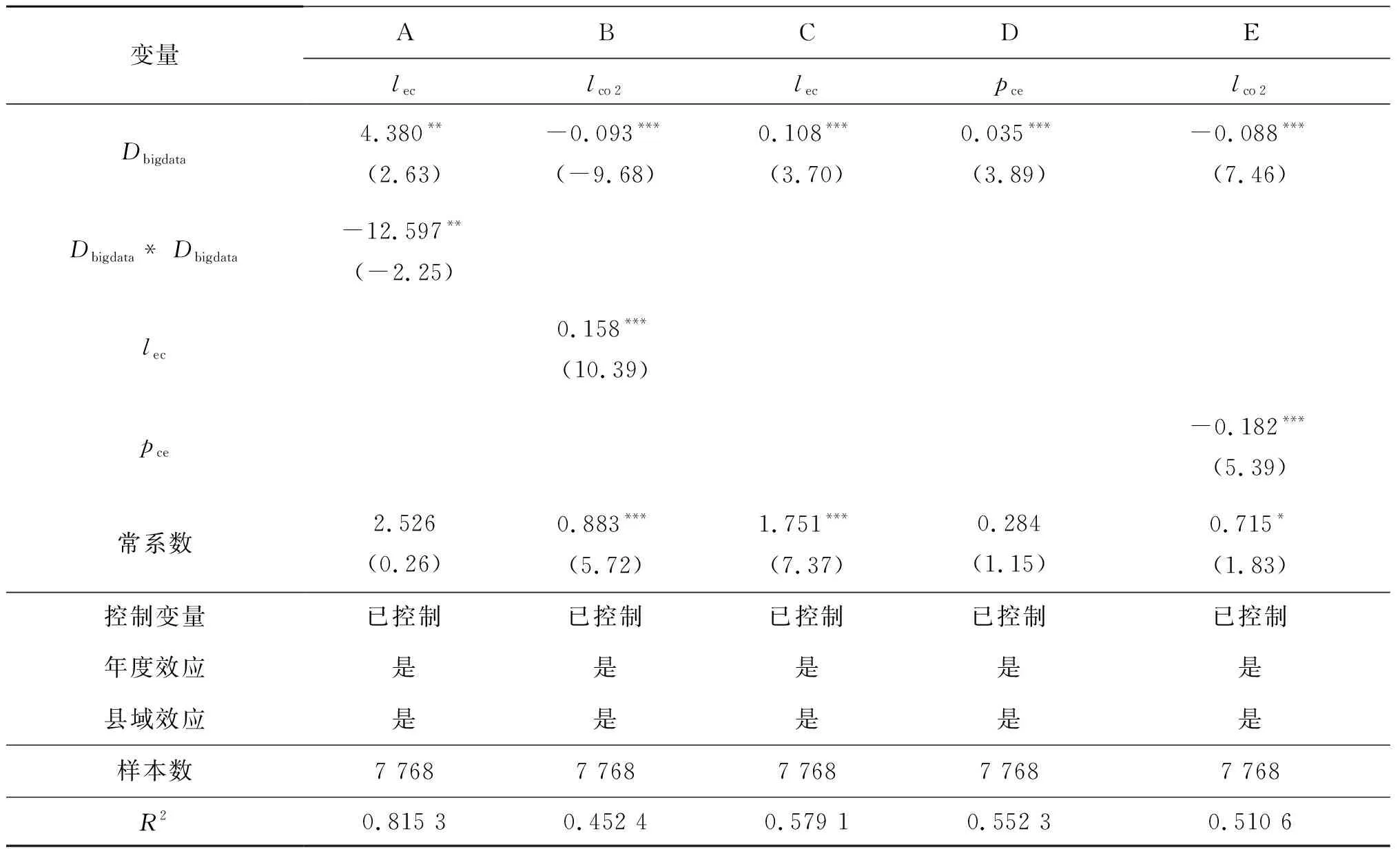
表4 基于电力消费的中介效应检验Tab.4 Mediation effect test based on electricity consumption
3.2.2基于绿色创新的作用机制检验
由表5的A列可知,大数据发展对绿色创新影响的系数值为0.847,在1%的水平上显著为正,说明大数据发展有利于绿色创新。由表5的B列可知,大数据发展和绿色创新的系数值均在1%的置信水平上显著为负,说明大数据发展和绿色创新均有助于降低碳排放,绿色创新的中介效应显著,大数据发展可以通过提升绿色创新水平降低碳排放,即存在“大数据发展→促进绿色创新→碳排放水平降低”的作用机制。由表5的C和D列可知,当将绿色创新衡量指标更改为ngreen2以后,绿色创新中介效应回归结果仍然显著。
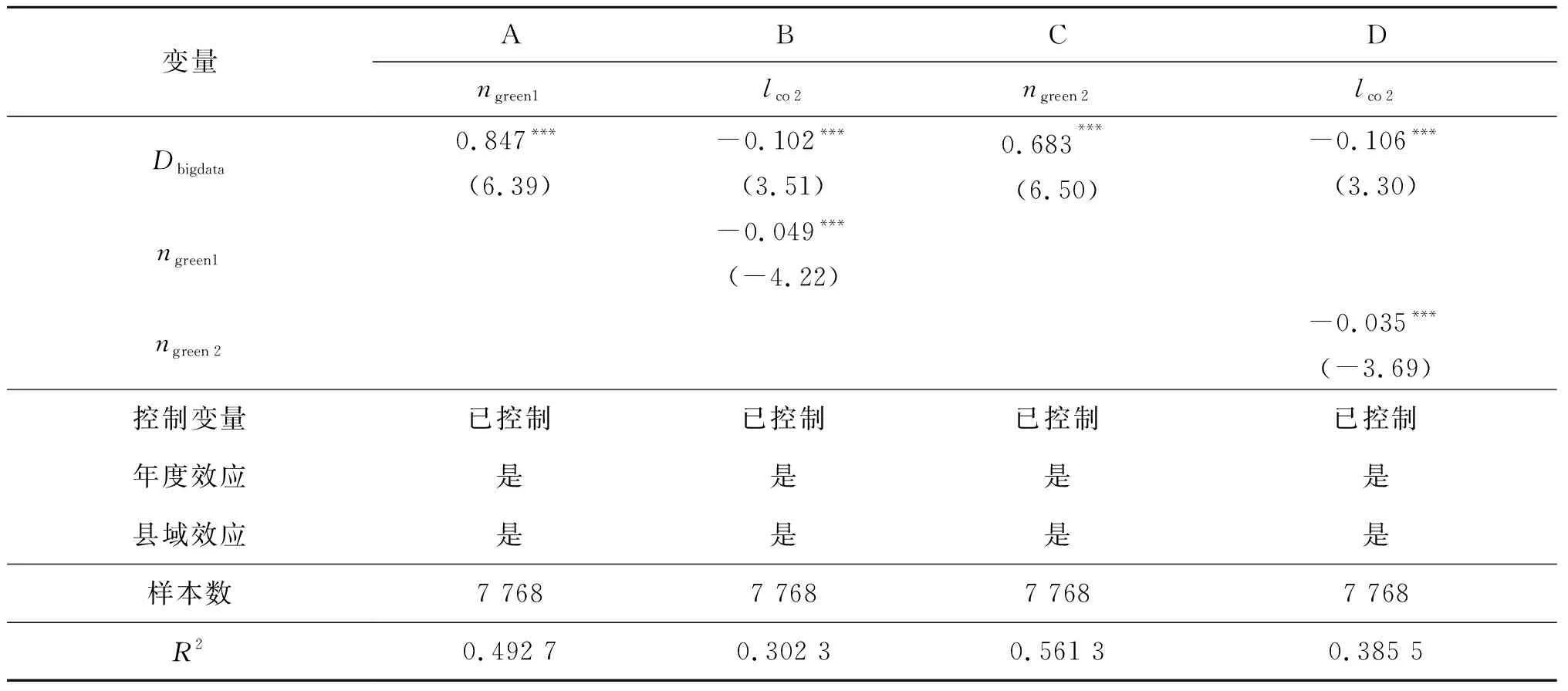
表5 基于绿色创新的中介效应检验Tab.5 Mediation effect test based on green innovation
3.3 稳健性检验
本文采用以下方式进行稳健性检验。首先,改变核心变量的测度方式。借鉴史丹和孙光林[1]的做法,使用算术平均值法测度大数据发展,回归结果如表6的A列所示,大数据发展系数值的显著性和符号方向均未发生明显变化。第二,去除极端值的影响。由于贵州率先发展大数据产业,其大数据发展水平普遍高于其他省市区,因此,本文去除贵州省样本后重新进行回归,回归结果如表6的B列所示,与基准回归结果相比,并未发生显著变化,说明基准回归结果是稳健的。
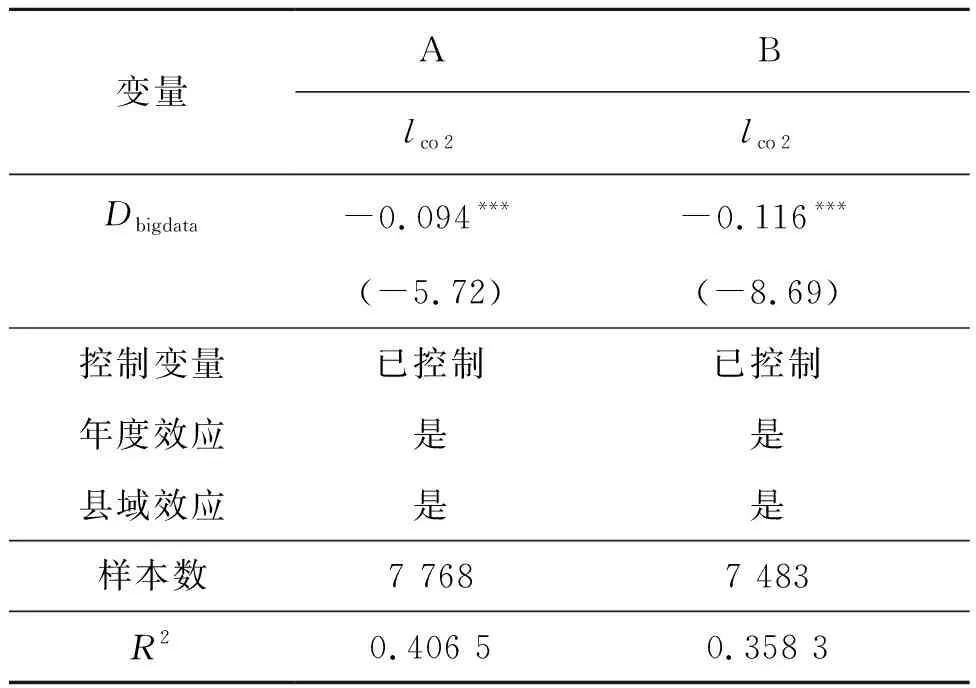
表6 稳健性检验Tab.6 Robustness test
3.4 内生性讨论
首先,为了降低双向因果关系对回归结果的影响,在表7的A列中,本文将大数据发展滞后一期进行回归。回归结果表明,与表3中基准回归结果相比,大数据发展的系数值和显著性并未出现明显差异。其次,考虑到使用大数据发展滞后期进行回归并不能完全消除内生性问题导致的估计偏误,为此,本文借鉴施炳展和李建桐[28]的做法,使用新中国成立初期(1953-1956年)人均函件数量作为本文核心变量的工具变量。一方面,人均函件数量能够反映该省市对通信的偏爱程度,这种对传统通信的偏爱会延伸到数字技术媒介,有利于积累更丰富的数据信息,促进大数据发展。因此,人均函件数量与大数据发展存在密切关系。另一方面,新中国成立初期的人均函件数量并不会对当前碳排放产生直接影响,满足工具变量相对外生的要求。工具变量t值为4.73,一阶段F值为126.83,大于10,说明工具变量的回归结果是有效的。由表7的B列可知,大数据发展的系数值为-0.166,在1%的置信水平上显著,再次说明大数据发展有利于降低碳排放。

表7 内生性检验Tab.7 Endogenous test
4 结论与建议
1) 本文选取2015—2018年我国县域层面(西藏和港澳台地区数据除外数据)碳排放数据,通过构建大数据发展指数,从理论和实证双重角度考察大数据发展对县域碳排放的直接影响与作用机制。得到的研究结论如下:第一,大数据发展会抑制碳排放,该研究结论在经过稳健性检验和内生性检验之后仍然成立;第二,大数据发展与电力消费之间存在显著的倒U型关系,会通过电力消费这一中介变量对碳排放水平产生间接影响,且大数据发展可以通过提高清洁电力占比降低碳排放;第三,绿色创新的中介效应显著,大数据发展可以通过促进绿色创新对碳排放产生抑制作用。
2) 持续推进“新基建”建设,拓宽大数据应用的深度和广度。目前我国大部分地区的大数据产业仍然处于初级发展阶段。因此,要完善大数据产业相关领域的政策法规,加大对大数据发展的资金支持,持续推进数据中心、5G基站等新型数字基础设施建设,注重培育大数据领域人才队伍,为大数据产业提供安全有利的发展环境;另外,要拓宽大数据在社会经济各领域应用的深度和广度。政府要致力于引导传统产业运用大数据技术实现数字化、智能化转型升级,完善数据要素市场,促进数据交易,实现数据共通共享,打破各行业间的“信息孤岛”效应,进一步催生大数据应用新图景,提升资源配置效率,助力实现“双碳”目标。
3) 因地制宜实施大数据发展战略。由于我国各区域经济发展水平、资源禀赋、大数据发展现状等存在较大差异,因此,要因地制宜地制定大数据发展战略。对于经济欠发达地区,要做好支持大数据产业发展的顶层设计,积极推进数字基础设施建设,努力破除由于地理环境因素所导致的大数据产业发展缓慢问题,更加注重大数据产业与第一产业、第二产业的深度融合,进一步降低碳排放;对于发达地区大数据发展水平和政务应用水平较高,具备良好的创新基础,要注重发挥大数据产业的创新示范引领作用。
