面向VVC相同编码参数的视频重压缩取证方法
2023-12-04公衍超杨楷芳林庆帆王富平刘伯阳
公衍超,吴 晗,杨楷芳,刘 颖,林庆帆,5,王富平,刘伯阳
(1.西安邮电大学 通信与信息工程学院,陕西 西安 710121;2.西安邮电大学 陕西省法庭科学电子信息实验研究中心,陕西 西安 710121; 3.西安邮电大学 陕西省无线通信与信息处理技术国际联合研究中心,陕西 西安 710121;4.陕西师范大学 计算机科学学院,陕西 西安 710119;5.新加坡XsecPro公司,新加坡 787820)
视频安全是信息安全、网络安全的重要体现[1],以检测视频内容篡改信息为目的的视频取证技术是视频安全的重要保障[2]。近年来,随着视频编辑软件功能的日益强大和深度篡改技术的飞速发展[2],篡改者很容易对视频进行“视觉不可察觉”的篡改,这对视频取证技术提出了新的要求。在当前大部分视频应用中,视频信号依次要经过采集、编码/压缩、传输、存储、解码及显示等操作,并且在编码/压缩、传输、存储和解码操作中是以视频码流的形式表达视频内容[3-4]。篡改者通常在传输与存储的过程中对视频内容进行篡改,并且篡改后视频内容必须要经过再次编码压缩后才能生成包含篡改信息的视频码流,完成整个篡改操作。因此,编码压缩次数成为判定原始视频是否被篡改的一个必要条件。以检测视频编码压缩次数为目的技术被称为视频重压缩取证技术,其在刑事侦查、法庭科学领域有着重要应用。
当前一些高效的视频重压缩取证技术已经被提出。由于不同视频编码标准采用不同的编码技术,直接影响了压缩码流的语法语义及篡改遗留痕迹,因此视频重压缩取证技术都有其具体的适用标准。面向MPEG-2、MPEG-4及H.264/AVC标准,分别提出了有效的视频重压缩取证方法[5-11]。He等[5]基于局部运动矢量场计算预测残差,可以得到重压缩的痕迹。文献[6]将块效应强度和宏块量化信息相结合,可以有效地防止有损压缩引起的误差。Vazque等[7]采用帧内模式宏块和跳过模式宏块的数量变化信息构造重压缩特征。Li等[8]将解压缩的视频帧视为静止图像,提取像素邻接矩阵差,采用半监督学习框架基于高斯密度的单分类器可以提高分类器的鲁棒性。文献[9]提取离散余弦变换系数特征基于卷积神经网络在帧内定位双压缩区域,但这种方法计算复杂度较高。文献[10]将宏块类型和运动矢量信息构造为宏块统计特征,然后计算两次连续压缩之间不同宏块特征的数量,随着压缩次数的增加,不同宏块特征的数量减少的趋势趋于平缓。文献[11]在文献[10]的基础上又考虑I帧的宏块统计特征。文献[5-9]是面向不同编码参数重压缩的情况,而文献[10-11]则是面向相同编码参数重压缩的情况。相比于不同编码参数,使用相同编码参数重压缩的视频,其压缩痕迹通常更小,重压缩取证难度更大[11-12]。
MPEG-2、MPEG-4及H.264/AVC都是2003年之前发布的标准。2003年之后视频快速向高清化发展,高清视频及设备被大量普及。相应地,国际电信联盟电信标准化部门(International Telecommunication Union-Telecommunication Standardization Sector,ITU-T)和国际标准化组织(International Organization for Standardization,ISO)/国际电工委员会(International Electrotechnical Commission,IEC)于2013年共同发布了首个面向高清视频的国际视频编码标准—高效视频编码(High Efficiency Video Coding,HEVC)标准。面向HEVC标准,大量有效视频重压缩取证方法被提出[12-20]。文献[13-17]针对不同编码参数情况提出了重压缩取证方法。具体地,文献[13-14]是考虑使用不同量化参数(Quantization Parameter,QP)重压缩的情况,文献[15-17]则是考虑不同图像组(Group of Picture,GOP)结构的重压缩情况。文献[12,18-20]针对相同编码参数的情况提出了重压缩取证方法。
近年来,视频除了继续向高清/超高清化发展之外,也在朝着高帧率、高色彩分量采样深度、高动态范围及360度全景等方向发展,包括HEVC在内的早期视频编码标准的编码效率已经很难满足现实需求。相应地,由ITU-T和ISO/IEC联合制定的通用视频编码[21](Versatile Video Coding,VVC)标准应运而生。VVC是于2020年发布的最新一代国际视频编码标准,其压缩效率大约是HEVC的2倍,是H.264/AVC的4倍[21],并且同时满足超高清、屏幕内容、高动态/宽色域及360度全景等视频内容的编码需求。凭借着优异的压缩效率及显著的通用性,VVC具有广阔的市场应用前景。
VVC采用了大量先进的编码技术,不仅显著提高了视频编码效率,同时也改变了压缩码流的语法语义与压缩痕迹[21],使得当前提出的视频重压缩取证技术[5-20]不能有效地适用于VVC标准。因此,为了提升面向VVC标准重压缩取证效率,拟提出面向VVC标准相同编码参数的视频重压缩取证方法。将VVC压缩视频中与压缩次数有密切关系的基础码流特征,通过建模得到高级码流特征,将其与QP级联作为支持向量机的输入,从而得到取证结果。为了验证所提方法的性能,在算法准确度、帧删除视频的重压缩检取证、算法复杂度方面进行验证。
1 基础码流特征分析
VVC仍然采用基于块的混合编码框架,视频图像被分割为编码树状单元(Coding Tree Unit,CTU)。VVC标准摒弃了HEVC标准采用的预测单元、变换单元概念,而是统一使用编码单元(Coding Unit,CU),CU是VVC中进行帧内预测的基本单元。帧内预测利用相邻CU的重建像素值为当前编码CU中的原始像素值寻找最优预测值,并将原始像素值与预测值相减得到残差,残差是后续变换模块的输入。帧内预测技术可以有效消除原始像素间的空余冗余,显著提高视频编码效率。
在帧内预测中CU划分类型和最优预测值获取是两个关键步骤。前者决定了CU的大小与形状,影响帧内预测的输入,后者决定了最终预测残差的特性,影响帧内预测的输出。VVC中与上述两个关键步骤密切相关的技术是CU划分技术、帧内预测模式选择和多参考行(Multiple Reference Line,MRL)技术。下面逐一介绍这些技术,并分析获得上述技术中与视频压缩次数密切相关的基础码流特征。
1.1 编码单元划分
为了适应更加丰富的视频内容及更多的视频类型,VVC采用了更灵活的CU划分技术以支持更多的CU形状及更大的块大小。VVC不再使用单一的四叉树CU划分方式,而是使用在四叉树的基础上嵌套了二叉树和三叉树的多类型树(Multi-Type Tree,MTT)划分方式。具体地,VVC中的CTU首先按照四叉树方式划分成不同的CU,然后四叉树的叶子节点CU再按照MTT方式进行划分。
VVC中帧内预测(Intra-prediction,I)帧亮度分量支持的CU类型,如表1所示。VVC采用拉格朗日率失真优化方法[3,21-22]为每一个CTU选择一组最优的CU划分类型,即在满足CTU总码率受限的情况下,选择一组CU划分类型,使得CTU的总失真最小。
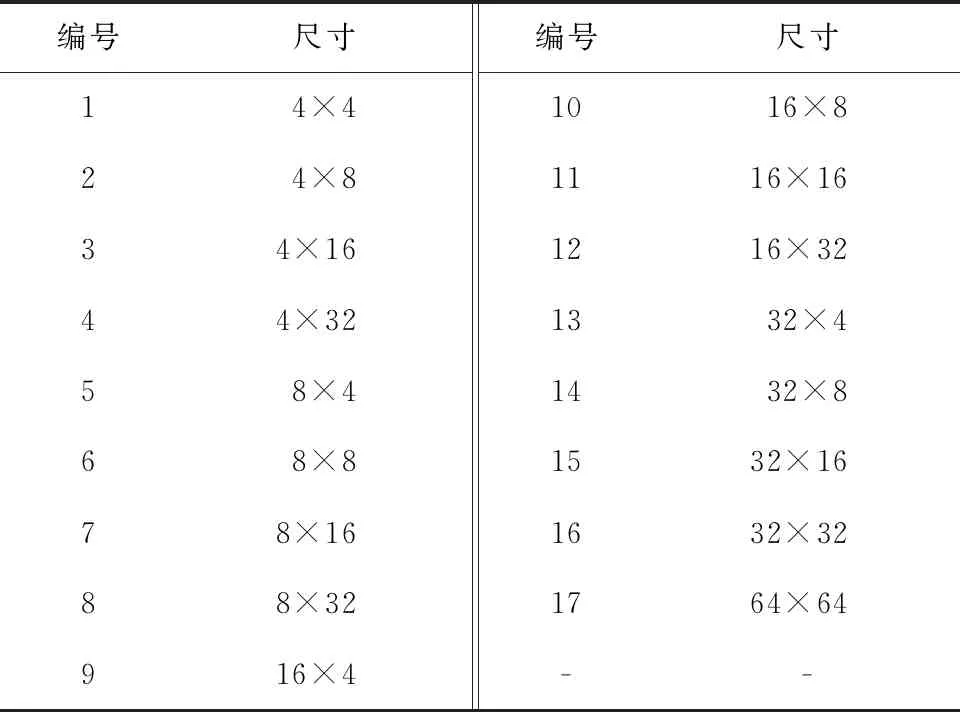
表1 VVC中I帧亮度分量支持的CU划分类型
最优CU划分类型信息经熵编码后会被写入到视频码流的头信息中,因此,CU划分类型属于基础码流特征。下面进一步分析CU划分类型与视频压缩次数的关系。理论上,首先,基于量化多对一的映射原理,使用VVC有损编码模式编码同一个视频内容时,随着压缩次数的增加解码视频内容会越来越模糊,即视频内容越来越简单。其次,基于帧内预测去相关原理,CU划分类型与输入编码视频的内容复杂度具有密切关系,即视频内容越简单则对应选择大尺寸CU划分类型的概率越高。基于以上两方面原因,理论上,CU划分类型与视频压缩次数具有密切关系,即随着压缩次数增加,视频码流中大尺寸CU类型的比例会升高。下面通过实验进一步验证上述分析。
采用VVC测试模型VTM11.0[23]编码标准测试视频 Night,视频的颜色空间及空间分辨率分别为YCbCr4∶2∶0及720P。档次为main_10,编码结构为LDP,QP为37,其他编码参数参照配置文件encoder_lowdelay_P_vtm.cfg中的默认设置。按照包含的像素数,将表1所示的CU类型分为小尺寸CU和大尺寸CU两类,小尺寸CU包括编号为1-7、9、10、13的CU,其他编号CU属于大尺寸CU。Night序列所有I帧大尺寸和小尺寸CU占比随着压缩次数的变化如图1所示。

图1 Night中I帧CU划分类型占比随压缩次数的变化
由图1可以看出,随着压缩次数的增加,大尺寸CU的占比逐渐升高,小尺寸CU的占比逐渐降低。Night序列第1帧图像第1次和第2次压缩视频码流中对应的CU 划分类型如图2所示。图2中不同大小的矩形块表示不同划分类型的CU,为了清楚地观察CU划分类型随压缩次数的变化,将左图中方框区域放大如右图。

图2 Night序列第1帧图像对应的CU划分类型
由图2可以验证图1得出的结论,即随着压缩次数的增加,视频码流中大尺寸CU划分类型的占比会升高。
1.2 帧内预测模式
为了适应更加丰富的视频内容,VVC采用了更多的帧内预测模式,包括传统的DC模式和Planar模式,以及多达65种的角度预测模式[21],具体如图3所示。图3中实线箭头表示VVC和HEVC都采用的33种角度预测模式,虚线箭头表示VVC新增加的32种角度预测模式,角度方向从45°至-135°。另外,VVC支持矩形的CU,为了给矩形CU找到最优的参考像素,VVC新增加了宽角度帧内预测技术,使得矩形块对应的角度模式被扩展为93种,扩展模式如图3点线箭头所示。

图3 VVC采用的帧内预测模式
VVC也是采用拉格朗日率失真优化方法[3,21-22]为每一个CU选择最优的帧内预测模式。最优帧内预测模式选择思路与最优CU划分选择思路类似。并且CU的最优帧内预测模式信息也会经熵编码后写入视频码流的头信息中,因此CU预测模式也属于基础码流特征。下面进一步分析CU预测模式与视频压缩次数的关系。
如图3所示,当使用角度预测模式时,CU像素的预测值由其对应角度方向的参考像素值得到,理论上各种角度模式适用于对应纹理方向的区域。当使用DC模式时,CU像素的预测值是其左侧和上方所有参考像素的平均值,因此理论上DC模式适用于大面积的平坦区域。当使用Planar模式时,CU像素的预测值可以看成是水平和垂直两个角度方向预测值的平均值,理论上Planar模式适用于像素值渐变的区域。基于量化多对一的映射原理,使用VVC有损编码模式编码同一个视频内容时,随着压缩次数的增加,解码视频内容会变的越来越简单,视频内容方向性信息会逐渐模糊,平坦与渐变区域逐渐增多。最终导致角度预测模式的比例会逐渐降低,而DC与Planar模式的比例会逐渐升高。下面通过实验进一步验证上述分析。
使用VTM11.0编码Night序列,其他编码设置与上述描述的设置一致。Night序列所有I帧CU预测模式占比随压缩次数的变化情况具体如图4所示。由图4中数据可以看出,随着压缩次数的增加,视频码流中DC与Planar模式CU的占比逐渐增加,而其他角度预测模式CU的占比逐渐降低。通过Night序列第1帧第1次和第2次压缩视频码流中CU 预测模式的变化情况,分析视频压缩次数影响CU预测模式的选择,具体情况如图5所示,图中不同灰度表示不同的预测模式。为了清楚地观察CU预测模式随压缩次数的变化,将左图中方框区域放大如右图所示。
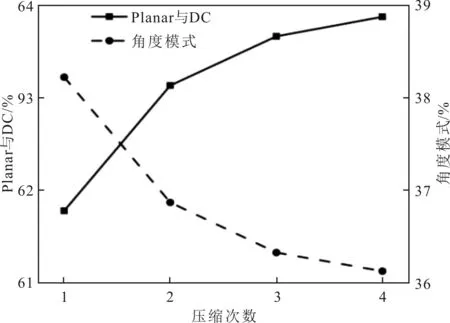
图4 Night中I帧CU预测模式占比随压缩次数的变化

图5 Night序列第1帧图像对应的CU预测模式
1.3 多参考行
VVC新采用的MRL技术显著影响CU预测值的获得。参考行的选择不再只是相邻行,具体如图6所示。图6中A~F段表示当前编码CU可选的参考像素位置,在为当前编码CU选择参考像素时,包括HEVC在内的之前标准只支持从已编码CU最临近参考行中选择,即图6中所示的参考行0。为了适应更广泛的视频内容,为当前CU选择最优的预测值,VVC标准支持从已编码CU临近3行中为当前编码CU选择参考像素,即图6所示的参考行0、1、3。使用参考行0、1是因为其与当前编码CU最近,具有更强的相关性。参考行3距离当前编码CU比较远,相比于参考行0、1,其可以补充提供其他有效参考信息。而参考行2很难提供额外的有效参考信息,同时权衡编码复杂度,VVC不支持参考行2的使用[24]。

图6 多参考行示例
参考行与帧内预测模式共同决定了参考像素的来源,决定了最终预测值。因此,在VVC中最优参考行的选择是被整合到最优预测模式选择过程中。CU的最优参考行信息经熵编码后会被写入视频码流的头信息中,CU参考行信息也属于基础码流特征。如前所述,随着压缩次数的增加,解码视频内容会越来越模糊、越来越简单。此时,临近行对应的相关性会增强,远离行提供有效额外补充信息的几率会降低。最终导致选择参考行0的CU占比会增加,而选择其他参考行CU的占比会降低。下面通过实验进一步验证上述分析。
使用VTM11.0编码Night序列,其他编码设置与上述描述的设置一致。具体的Night序列所有I帧CU参考行占比随压缩次数的变化情况如图7所示。由图7可以看出,随着压缩次数的增加,视频码流中参考行0的CU的占比逐渐增加,其他参考行CU的占比逐渐降低。通过图8更加直观地分析Night序列第1帧第1次和第2次压缩视频码流中CU 参考行信息的变化情况。图8中,不同灰度表示不同参考行信息。为了清楚地观察CU参考行随压缩次数的变化,将左图中方框区域放大如右图。由图8可以看出,视频压缩次数影响CU参考行的选择。
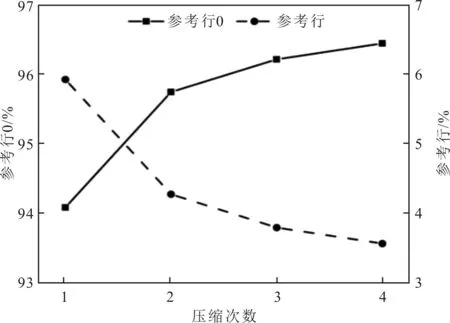
图7 Night中I帧CU参考行占比随压缩次数的变化

图8 Night序列第Ⅰ帧图像对应的CU参考行
2 高级码流特征构建
前一部分已经分析确定了与视频压缩次数相关的基础码流特征,即CU划分类型、帧内预测模式及参考行。此部分将基于这些特征构建高级码流特征。高级码流特征是后续支持向量机(Support Vector Machines,SVM)检测视频压缩次数的输入。
2.1 不同属性CU占比
根据CU划分类型、帧内预测模式及参考行计算不同属性CU占比。定义第n次压缩视频第i个I帧第x列第y行CU的属性矩阵为
Cn,i,x,y=[tn,i,x,y,mn,i,x,y,rn,i,x,y]
(1)
其中,
tn,i,x,y∈{1,2,3,…,Nt}mn,i,x,y∈{1,2,3,…,Nm}rn,i,x,y∈{1,2,3,…,Nr}
式中:n为压缩视频次数序号,n∈{1,2,3,…,Nd},Nd为视频压缩总次数;i为I帧序号,i∈{1,2,3,…,Nn,I},Nn,I为第n次压缩视频包含的I帧数量;x、y分别为第i个I帧在水平及垂直方向上包含的CU的序号,其中,x∈{1,2,3,…,w}、y∈{1,2,3,…,h},w、h分别为包含的CU最大数量;tn,i,x,y、mn,i,x,y、rn,i,x,y分别为第n次压缩视频第i个I帧第x列第y行CU选择的划分类型、预测模式及参考行编号;Nt、Nm、Nr分别为VVC标准支持的可选CU划分类型、预测模式及参考行总数量。
当同一个I帧中相同空间位置CU相邻两次压缩选择的划分类型、预测模式及参考行信息相同时,即定义其为相同属性CU,反之则为不同属性CU。相同属性CU判别式为
Cn,i,x,y=Cn+1,i,x,y
(2)
式中,Cn+1,i,x,y为第n+1次压缩视频第i个I帧第x列第y行CU的属性矩阵。Cn+1,i,x,y与Cn,i,x,y的定义类似,只是将式(1)中的n换成n+1,这里不再赘述。
第n次压缩视频第i个I帧第x列第y行CU的属性标记为
(3)
式中,z为CU划分类型编号,z∈{1,2,3,…,Nt}。最终第n次压缩视频所有I帧中选择第z种CU划分类型的不同属性CU占比Pn,z,u[12]为
(4)
式中,Nn,i,z为第n次压缩视频第i个I帧选择第z种CU划分类型的CU数量。
2.2 CU划分类型占比及量化参数
定义CU划分类型占比作为第二个高级码流特征。第n次压缩视频所有I帧中选择第z种CU划分类型的CU占比Pn,z为
(5)
式中,Nn,i,c表示第n次压缩视频第i个I帧包含的CU总数量。
选择QP作为第三个特征。QP是VVC量化模块中包含的重要编码参数,其取值经熵编码后会被记录到视频码流中。另外,使用VVC压缩视频时选择的QP越大则视频会越模糊,会显著影响CU划分类型、预测模式及参考行的选择。使用VTM11.0编码Night序列,QP分别为27和47,其他编码设置与上述描述的设置一致。Night序列第1帧图像在不同QP下编码对应的CU信息情况如图9所示。可以看出,随着QP取值的变化,CU划分类型、预测模式与参考行信息都发生了明显变化。

图9 不同QP下Night序列第1帧对应的CU信息
3 视频重压缩检测方法
基于构建的高级码流特征,使用SVM提出面向VVC标准相同编码参数的视频重压缩取证方法(Video Recompression Forensics for VVC,VVC-VRF)。视频重压缩取证问题是一个典型的二分类问题,包括1次压缩视频和多次压缩视频两类。SVM适合于二分类问题[25- 26],且SVM对硬件的需求也比较低[26]。SVM原理是将线性不可分特征向量映射到高维空间以寻找用于分类的超平面, VVC-VRF中的特征向量具体指的是由Pn,z,u、Pn,z、QP级联得到的多维高级码流特征向量。VVC-VRF采用的是支持向量机库[25](Library for Support Vector Machines,LIBSVM),评估函数H(·)为
H(Fset)=sgn(ωTG(Fset)+b)
(6)
式中:ω和b分别为SVM的系数;sgn(·)为符号函数;Fset为多维的特征向量;G(·)为将Fset映射到高维空间的函数,采用径向基核函数。提出的VVC-VRF方法框架如图10所示。

图10 VVC-VRF方法框架
VVC-VRF方法的具体实施步骤如下。
步骤1在视频通信系统中,编码后的视频都以视频码流的形式存储。因此,视频重压缩取证的输入是经过n次压缩后的视频码流bn。首先从bn中提取QP、CU的划分类型、预测模式及参考行信息。
步骤2根据式(1)确定bn对应的CU属性矩阵Cn,i,x,y,根据式(5)计算bn对应的Pn,z。
步骤3使用VVC解码器解码bn为YCbCr格式视频Yn,然后使用VVC编码器在相同参数下再次压缩Yn1次并获得对应的视频码流bn+1。
步骤4进一步从bn+1中提取CU的划分类型、预测模式及参考行信息,确定bn+1对应的CU属性矩阵Cn+1,i,x,y,并结合步骤2获得的Cn,i,x,y,根据式(2)—式(4)计算得到Pn,z,u。
步骤5将QP、Pn,z、Pn,z,u级联并构造高级码流特征Fset=[Q,Pn,1,u,…,Pn,Nt,u,Pn,1,…,Pn,Nt],其中Q为量化参数。
步骤6将Fset输入SVM得到分类结果,判定bn是1次压缩视频码流还是多次压缩视频码流。特别地,SVM模型在使用前还需要经过训练。
4 验证结果及分析
4.1 实验设置
选择29个标准的包含不同内容特征的视频序列构建原始视频数据集。视频的颜色空间和分辨率分别为YCbCr4∶2∶0和720P。为了进一步增加原始视频序列的样本数量,将每个原始视频序列裁剪成视频片段,每个视频片段包含100帧,最终获得117个原始视频片段用于编码压缩。采用VTM-11.0编码原始视频片段和解码对应的视频码流。编码档次为main_10,编码结构为低时延编码结构中的LDP和LDB。QP选择标准[27]规定的4组取值,即22、27、32、37,并在此基础上再增加42和47两组取值代表中低码率下的应用场景。其他编码参数分别参照配置文件encoder_lowdelay_P_vtm.cfg和encoder_lowdelay_vtm.cfg中的默认设置。
将经过1次编码生成的视频码流标记为正样本,经过2次编码生成的视频码流标记为负样本。然后分别从正样本和负样本中随机提取60%的样本组成训练集,其他40%的样本组成测试集。训练集用于VVC-VRF方法中SVM模型的训练,测试集用于最终的性能测试。视频重压缩取证准确度As[12]定义为
(7)
式中,Ak、Aj分别为测试集正样本和负样本对应的重压缩取证准确度。
4.2 重压缩取证的准确度
文献[12]提到的帧内预测单元预测模式(Intra Prediction Unit Prediction Mode,IPUPM)代表了当前视频重压缩取证领域先进水平。因此,将VVC-VRF方法与IPUPM方法进行对比,两种方法对应的重压缩取证准确度如表2所示。
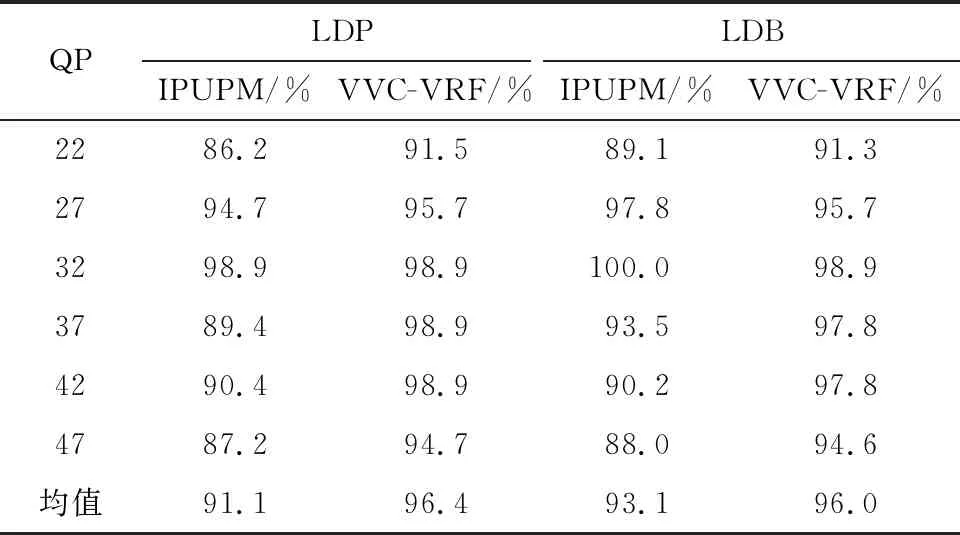
表2 视频重压缩取证准确度As
针对LDP结构,VVC-VRF方法与IPUPM方法的重压缩取证准确度分别为96.4%和91.1%,针对LDB结构,VVC-VRF与IPUPM方法的重压缩取证准确率分别为96.0%和93.1%。相比于IPUPM方法,VVC-VRF方法取证准确度更高。VVC-VRF具有更高取证准确度的主要原因是其考虑了VVC支持的更多更丰富的CU划分类型、预测模式及参考行信息,而IPUPM 方法只使用了部分CU划分类型及预测模式信息。
4.3 帧删除视频的重压缩检取证
帧删除是一种常见的视频篡改手段,篡改者删除原始视频中包含敏感信息的一些帧达到掩盖或混淆真相的目的。由于VVC编码框架中帧间预测等技术的使用,使得相邻帧的编解码信息具有很强的参考依赖。因此,将原始视频做帧删除处理后,必须将剩余的帧重新压缩才能形成完整的视频码流供后续传输或存储。视频重压缩取证也适用于帧删除篡改视频的取证场景。
选择LDP结构下编码的视频进行帧删除操作以验证VVC-VRF方法与IPUPM方法的取证准确度。具体地,对LDP编码结构下第1次压缩后的解码视频随机删除5帧,然后再将删帧后的视频重新编码。其他编码设置及过程与前面设置描述的一致,实验结果如表3所示。
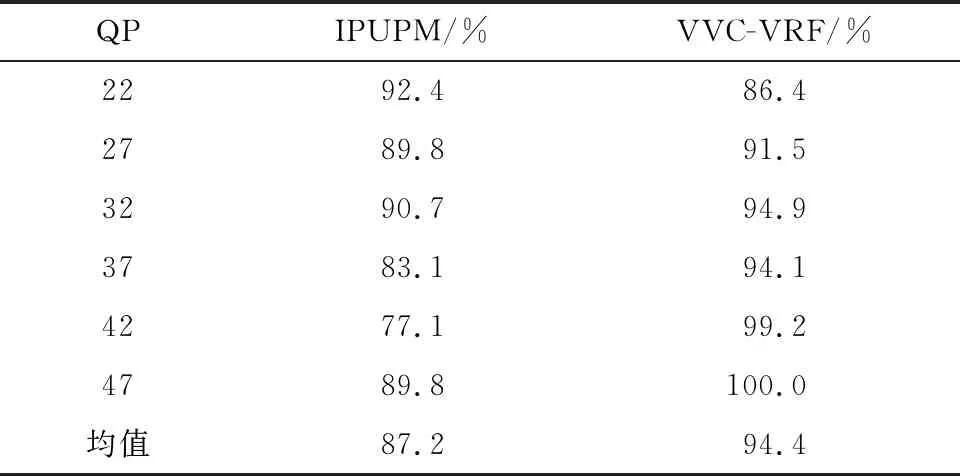
表3 帧删除视频的重压缩取证准确度As
VVC-VRF方法与IPUPM方法面向帧删除视频的重压缩取证准确度平均分别为94.4%和87.2%,VVC-VRF方法提高了帧删除视频的重压缩取证准确度。对比表2和表3可以看出,VVC-VRF方法与IPUPM方法在面对帧删除视频时,其重压缩取证准确度都有所下降,这主要是因为帧删除操作会显著改变后续重压缩面向视频的内容特性,例如帧数量减少及帧序号对应关系被打乱等,会影响基础码流特征与压缩次数的关系,最终导致重压缩取证准确度下降。
4.4 算法的复杂度
实用的重压缩取证方法除了具有更高取证准确度外,更低的取证复杂度也是必要的。从算法复杂度角度可以将VVC-VRF方法和IPUPM方法分为编码和其他步骤两部分。相比于其他步骤,编码操作非常耗时,占了取证的大部分时间。另外,编码是计算机独立运行的操作,没有人为干预。因此,选择对比VVC-VRF方法与IPUPM方法中包括的编码时间以消除人为操作步骤对取证运行时间的干扰,从而尽量客观公正地对比方法复杂度。
在同一台服务器上完成VVC-VRF方法与IPUPM方法中的编码操作。服务器主要配置为Win10操作系统,CPU为AMD Ryzen Threadripper 3960X 24-Core Processor,主频基准速度为3.80 GHz,内存256 G,具体实验结果如表4所示。

表4 视频重压缩取证中的编码时间
对于所有测试视频,VVC-VRF方法与IPUPM方法对应的平均编码时间分别为5 239 s和10 114 s,VVC-VRF方法可以节省48.20%的编码时间,显著降低了重压缩取证复杂度。这是因为VVC-VRF方法取证步骤中只包含1次编码操作,而IPUPM方法取证步骤中则包含了2次编码操作。
5 结语
面向VVC标准相同编码参数情况,提出了一种有效的视频重压缩取证方法。提取与视频编码次数密切相关的CU划分类型、帧内预测模式及参考行信息作为基础码流特征,基于基础码流特征得到不同属性CU占比、CU划分类型占比和QP,完成高级码流特征的选取。然后将高级码流特征输入SVM,得到重压缩取证结果。实验结果表明,与IPUPM方法相比,VVC-VRF方法可以有效提高相同编码参数下视频重压缩取证的准确度,并且在帧删除的情况下VVC-VRF方法的取证准确度仍然较高。另外,与IPUPM方法相比,由于VVC-VRF方法的取证过程包含更少的编码次数,因此VVC-VRF方法可以明显降低视频重压缩取证的时间。通过以上分析可以看出,VVC-VRF方法在重压缩取证准确度及复杂度上都具有优异的性能。后续将在探索更有效的基础码流特征,构建更有效的高级码流特征及重压缩取证技术实际工程应用转化及方法结构适配等方面展开研究。
