基于TX2 的微型SAR 实时成像信号处理技术
2023-12-04李和平白浩琦
姚 森,李和平,白浩琦
(1.中国科学院空天信息创新研究院,北京 100190;2.中国科学院大学 电子电气与通信工程学院,北京 100049)
0 引言
合成孔径雷达(Synthetic Aperture Radar,SAR)凭借其全天时、全天候、穿透能力强和探测距离远等优点,在灾害监测、民用勘探、应急救援等多个领域得到了广泛应用。相比传统的机载SAR,微型合成孔径雷达(Min‐iature Synthetic Aperture Radar,Mini-SAR)使用无人机平台,这使其整体体积远小于传统机载SAR,因此它具有使用更加灵活、成本更低的优点,是一种高效的信息获取平台[1-2]。Mini-SAR 技术已经成为现阶段雷达研究的热点之一。
微型SAR 的数据处理主要分为两类:一类是离线处理,即将微型SAR 只采集数据而不作处理,将采集的数据储存到硬盘中[3-5],待采集结束后将数据导入到电脑进行数据处理,这种方式在生成图像过程中不考虑体积、功耗、时间等问题,可以采用高性能处理器进行批量处理,处理速度较快。但是这种处理方式不能实时查看雷达成像结果,如果雷达系统运行过程中出现故障,容易造成回波数据错误,而这种错误不能立即被发现。另一类处理方式是实时处理,雷达回波数据不仅储存在硬盘中,还通过实时成像处理器实时处理回波数据,并将处理后的图像通过Wi-Fi 或者无线链路传输到地面站。文献[6]最早设计了适用于无人驾驶飞行器(Unmanned Aerial Ve‐hicle,UAV)的SAR 实时成像处理板卡,该板卡使用现场可编程门阵列(Field Programmable Gate Array,FPGA)和数字信号处理器(Digital Signal Processor,DSP)实现,使用波数域算法(Wavenumber Domain Al‐gorithm,WKA)处理SAR 图像数据,峰值功耗为15 W。文献[7]使用FPGA 和DSP 设计了重量为700 g、功耗小于16 W 的微型SAR 实时成像与数据采集系统,该系统能够实时生成800 m 测绘带范围的图像。文献[8-9]使用Xilinx V7 FPGA 设计实现了SAR 实时成像处理系统,处理8k×4k 采样点的图像数据需要5.1 s。文献[10]使用Jetson TK1 设计实现了实时成像处理器,处理4k×4k 点的SAR 图像数据需要3 104.84 ms。文献[11]使用NVIDIA Jetson TX2 设计了实时成像SAR 处理器,通过该处理器可以获得10 m 分辨率的SAR 图像。文献[12]设计了基于FWCM 的低成本微型SAR,使用NVIDIA Jetson Nano 生成场景大小为120 m×100 m 的SAR 图像,并通过5 GHz Wi-Fi 链路将图片传送到地面站。
本文基于NVIDIA Jetson TX2 设计了用于微型SAR的实时成像处理器。本文首先分析了无人机平台对于硬件选择与算法选择的要求,然后研究了成像算法在GPU 中的实现,最后给出了试验结果。
1 系统设计
SAR 成像的最理想条件是平台进行匀速直线运动,但是由于无人机平台重量轻、惯性小、稳定性差,SAR 实时成像性能受到了限制。此外,无人机平台负载能力差,安装空间有限,无法安装高精度的惯导系统来补偿飞机的运动误差,也无法安装大尺寸天线,导致合成孔径长度长,飞行速度慢,合成孔径时间长,一个孔径内运动误差积累更加严重,这进一步限制了无人机载SAR 实时成像系统的性能。因此,要在无人机上实现SAR 实时成像,需要补偿无人机平台的运动,补偿复杂的运动误差以及实时成像处理需要大量计算,就需要适用于无人机的高性能数据处理硬件。
WKA 算法首先进行二维FFT 将信号从时域变换到频域,在频域对回波信号一致压缩与Stolt 插值,最后进行FFT 逆变换将信号从频域变换到时域获得雷达图像。WKA 算法在其理论推导过程中没有做近似处理,是一种精确的成像算法,通过在二维频域完成插值,将方位向与距离向解耦,具有对宽孔径以及大斜视角的数据处理能力,因此适合无人机载SAR 平台的数据处理。
SAR 实时成像处理基于高性能嵌入式GPU 实现。NVIDIA Jetson TX2 嵌入式GPU 具有8 个CPU 核心,256个Pascal 架构的CUDA 核心,运算速度可达1.33 TFLOPS,8 GB LPDDR4 公用内存,可以同时被CPU 和GPU 使用[13]。丰富的硬件资源与计算能力十分适合搭载在轻小型平台上使用。
2 成像算法的GPU 实现
整个成像过程的流程如图1 所示。输入数据包含原始雷达回波数据与辅助数据,首先对回波数据进行脉冲压缩,并在辅助数据中提取无人机运动信息进行运动误差估计,然后依次进行第一阶运动补偿、二维FFT、一致压缩、Stolt 插值、距离向IFFT、方位向Scaling、方位向IFFT、第二阶运动补偿、PGA 估计、方位压缩等处理,最后将处理得到的SAR 图像储存到硬盘。
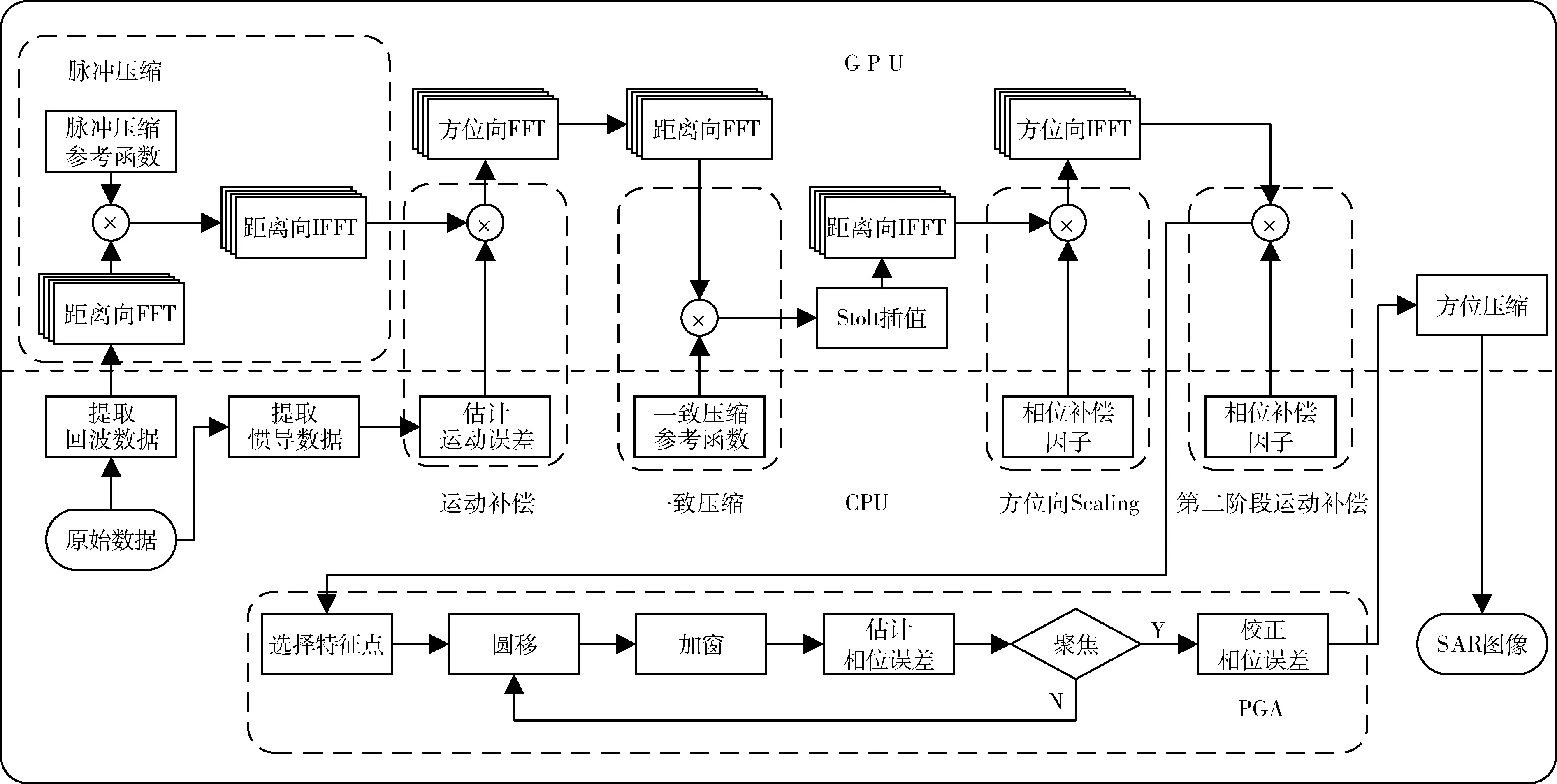
图1 结合运动补偿的WKA 算法流程图
本文将SAR 中WKA 算法在NVIDIA Jetson TX2 上进行了并行化处理。通常在桌面GPU 中,主机内存与设备内存是独立的,主机内存位于CPU 端,设备内存位于GPU 端,为了隐藏主机内存与设备内存之间数据传输的延迟,常使用流技术将数据处理与数据传输分配到不同的流中,重叠数据传输与处理时间以达到加速效果。但是TX2 与传统桌面GPU 不同,TX2 的主机内存与设备内存在同一块物理内存中,如果按照桌面GPU 的内存使用方式分配主机内存与设备内存,不仅浪费空间,内存复制也会产生额外开销。对于这种情况,CUDA 提供了统一内存与零拷贝内存两种内存使用方式。其中统一内存的方式使用更简便,但是在TX2 上由于I/O 一致性需要通过软件维护,并且软件维护的I/O 一致性并不可靠[14],因此本设计中采用了零拷贝内存方式,零拷贝内存使用固定内存,共用同一物理内存的TX2 在访问固定内存时不需要经过PCIe 总线,因此可以达到较高的访问效率。
需要处理的原始数据包括原始回波数据与辅助数据。对原始数据首先进行距离压缩,先对距离向数据与参考函数求取FFT,如式(1)所示,将计算结果进行共轭复乘,再计算IFFT 即可完成距离压缩。每一条距离向数据实现距离压缩包含两次FFT 计算(包括IFFT)和一次复数乘法计算。
脉冲压缩完成后做第一阶运动补偿,需要先从辅助数据中提取惯导数据,计算无人机的偏离位置,根据偏离位置计算误差补偿因子,误差补偿因子如式(2)所示,将误差补偿因子与脉冲压缩结果相乘完成第一阶运动补偿。提取惯导数据、计算误差补偿因子在CPU 中完成,而相乘计算在GPU 中完成。
第一阶运动补偿后,需要进行二维FFT,即先后进行方位向FFT 和距离向FFT。二维FFT 之后是一致压缩,一致压缩参考函数在CPU 中计算完成,式(3)是一致压缩参考函数,与二维FFT 计算结果相乘。
在一致压缩之后需要进行Stolt 插值,Stolt 插值是本设计中计算量最大的部分,这一步骤需要使用8 点sinc插值,插值计算需要计算待插值点与加权因子,每次插值需要8 次乘法和7 次加法。在实现过程中插值点与插值加权因子不变,插值点与插值加权因子可以提前计算,使用查表方式调用计算结果从而提高程序运行速度。
插值结束后进行距离向IFFT,此时场景中心目标已经完成聚焦,偏离场景中心位置可以通过式(4)进行方位向Scaling 操作补偿多普勒历程。此步骤包含计算参考函数以及数据相乘操作。完成方位向Scaling 与方位向IFFT 后就可以进行第二阶段运动补偿,第二阶段运动补偿目的是补偿距离向空变相位误差,提高微型SAR 的分辨率,与第一阶运动补偿类似,需要在CPU 计算相位补偿因子,然后在GPU 进行复数乘法计算。
为了得到高分辨率图像,在第二阶段运动补偿后还需要补偿高阶相位误差,这里采用PGA 估计补偿高阶相位误差,PGA 估计需要先在图像中选择强散射点,然后使用对每个散射点圆移并加窗,接着计算每个点的相位误差并校正,直到整幅图像完成聚焦。PGA 算法实现过程涉及大量逻辑判断迭代过程,不适合在GPU 中运行。
最后一个步骤是将聚焦图像进行方位压缩,方位压缩的参考函数如式(6)所示,此步骤与距离压缩类似,每一条方位向数据方位压缩实现过程包含两次FFT 计算(包括IFFT)和一次复数乘法计算。
通过分析WKA 算法的实现流程,可以将算法中的计算主要分为FFT 和复数乘法两种。其中FFT 计算可以使用CUDA 提供的cufft 库函数实现;复乘算法需要编写核函数实现,复数乘法的执行效率直接影响成像效率。本设计使用的零拷贝内存方式没有使用到缓存,这会影响计算效率,由于单个复数乘法数据量少,只需要输入4 个float 类型数据,因此可以通过声明局部变量的方式将输入数据储存到访存速度最快的寄存器中,从而加快复数乘法数据访问速度。
3 试验和结果
本系统在NVIDIA 公司推出的TX2 开发板上进行了SAR 实时成像处理算法验证,实验平台如图2 所示,开发板中白色模块为TX2,开发板将TX2 模块接口引出,右侧为SATA 硬盘,SAR 雷达原始数据储存在SATA 硬盘中,通过SSH 连接GPU 并控制成像程序运行。

图2 TX2 开发板
原始数据的参数如表1 所示。

表1 系统主要参数
将成像算法移植到TX2 中对数据进行处理,处理结果如图3 所示,实时成像处理后的最终结果为16k×8k(2 km×1 km)的图像,由于图像沿距离向两侧较暗,对图像裁剪后大小为8k×8k 点(1 km×1 km),图像左右为距离向,上下为方位向,分辨率为0.3 m,成像结果地物清晰,细节丰富,聚焦质量良好。从原始数据进入到图像开始输出的处理时间为18.5 s,在重叠率为50% 的情况下每隔51 s 可以输出一帧图像。

图3 实测数据成像结果
4 结论
本文从WKA 算法入手,结合GPU 的特点设计算法实现步骤,并通过实际数据测试验证了实时成像处理系统的性能。NVIDIA 公司推出了新款工业级嵌入式GPU,硬件资源更加丰富,处理性能更强,同时解决了TX2 I/O 一致性的问题。经过对实际数据测试,当飞机姿态出现较大偏差时,图像可能会局部出现散焦,下一步可以在该GPU 上使用更加精确的运动补偿算法,从而获得更高质量的SAR 图像。
