融合多教师模型的知识蒸馏文本分类*
2023-12-04胡校飞孙姝娅张呈龙刘龙辉
苑 婧,周 杨,胡校飞,孙姝娅,张呈龙,刘龙辉
(1.战略支援部队信息工程大学,河南 郑州 450001;2.华北水利水电大学,河南 郑州 450000)
0 引言
文本分类为舆情监控、广告推送、挖掘社交媒体用户的时空行为、追踪敏感信息发挥了重要作用,其主要任务是根据文本内容或主题自动识别其所属类别。目前文本分类主要有机器学习[1]、深度学习[2]和预训练模型,其中预训练模型分类准确率最高。
深度学习模型通过捕捉文本的上下文特征完成文本分类任务,包括卷积神经网络(Convolutional Neural Network,CNN)[3]、循环神经网络(Recurrent Neural Net‐work,RNN)[4]、长短期记忆网络(Long and Short Term Memory,LSTM)[5]、门控循环单元(Gated Recurrent Unit GRU)[6]等。结合不同的模型可以有效提高模型的性能,例如Sandhya 结合长LSTM 和RNN 对文本文档进行特征提取[7],陈可嘉[8]使用BiGRU-CNN 模型结合自注意力机制进行文本分类,均全面提取了文本的局部和整体特征,提高了模型的准确性。
预训练文本分类模型模型使用大量无标注语料,在多个自然语言处理任务中有着良好的效果[9],包括Bert[10]、ELMo[11]、XLNet[12]等。翟剑峰使用Bert 模型用于用户画像[13],王浩畅使用ELMo 模型用于机器翻译[14],李东金使用XLNet 模型用于情感分析[15]。但是预训练模型参数量大、结构复杂、运行时间长,在实际生产环境直接使用难度较大,因此需在保证准确率的前提下对模型进行压缩。
合理的模型压缩可以在保证准确率的前提下有效降低模型参数量和内存以提高实际应用的时间效率[16],常见的模型压缩方法包括网络剪枝[17]、参数量化、知识蒸馏[18]等。叶榕使用知识蒸馏的方法结合Bert 和CNN模型用于新闻文本分类[19],杨泽使用知识蒸馏的方法改进网络问答系统[20],都在不影响准确率的前提下,大大缩短了运行时间。
本文提出了一种多教师模型知识蒸馏的方法,在不显著降低性能的前提下,减小模型了的复杂度。结合预训练模型XLNet 和BERT-wwm-ext 输出的概率分布融合作为软标签,在训练过程中指导学生模型BiGRU-CNN网络,提高了模型的泛化能力。
1 基础原理
1.1 预训练模型
预训练模型包含大量参数,分类准确率较高。本文教师模型采用BERT-wwm-ext 和XLNet 预训练模型。
1.1.1 BERT-wwm-ext
BERT 模型利用海量语料使用自监督学习的方法在无标注的数据上完成了预训练[21],只需要根据特定任务进行模型微调,无需大量修改模型结构体系。
BERT 使用Transformer 模型编码器来提取特征,同时处理整个文本序列,充分挖掘语义信息的同时进一步加深自然语言模型的处理深度。自注意力机制[22]是Transformer 中最主要基本结构,计算公式如下:
其中,Q、K、V为权重向量矩阵。
BERT 使用多头注意力机制,通过关联句子中文本的位置来识别句子的语义,公式如下:
BERT-wwm-ext 模型结构与BERT 相同,由12 层Transformer 构成[23],如图1 所示。该模型基于全词掩码,使用百科、问答、新闻等大量中文语料用于预训练,更适用于针对中文的自然语言文本处理。

图1 BERT 模型结构
1.1.2 XLNet
XLNet[24]是一种广义的自回归语言模型,采用重排列语言模型(Permutation Language Model,PLM)句子随机排列,使用自回归方法训练,使用双流注意力机制[25]学习标签之间的关联,并引入transformer-xl[26]模型思想,从而实现双向信息的学习。
PLM=将序列x=[x1,x2,…,xt]所有可能的排列定义为ZT,对的预测序列Z中所有序号小于t的元素,可表示为:
XLNet 模型计算长度为T的序列x目标函数的公式如下:
双流自注意力机制结构如图2 所示。

图2 双流自注意力模型结构
Transformer-xl 模型中的片段循环机制和相对位置编码降低了长序列文本的影响。
1.2 BiGRU-CNN
CNN[3]可快速准确地提取文本的局部关键特征;GRU[6]可提取文本的上下文信息及语义特征。本文学生模型采用的BiGRU-CNN 结合了二者优势,分为BiGRU层 和CNN 层[8]。
GRU 计算过程包括以下4 步:首先使用复位门选择在前一时刻放弃哪些信息,接下来通过更新门选择并更新当前时刻的信息,然后计算候选内容,最后根据上述结果计算输出。计算过程如下:
其中,Wr、Ur、Wz、Uz、W、U为权重信息,ht-1为前一时刻的输入,Br、Bz、B为偏置量,⊙表示逻辑运算。
CNN 输入BiGRU 层的输出结果,通过卷积和池化计算来捕捉文字中的局部特征。卷积层通过不同大小的卷积核提取不同层次的语义信息[27]。
卷积层的计算步骤如下。将BiGRU 层的输出的词向量作为卷积层的输入,ci,j表示问题中第i个词到第j个词的词向量拼接。
深层特征由3 个不同的卷积核提取,其中f为双曲正切函数,W为权值信息,m为卷积核宽度,b为偏置向量:
然后对卷积结果进行拼接:
并使用最大池化方法提取关键特征,只留下最关键的特征,以减小训练中的过拟合:
最后,将池化结果拼接,作为整个卷积层的输出,其中n为卷积结果的个数,j为卷积核的个数:
BiGRU-CNN 模型结构如图3 所示。

图3 BiGRU-CNN 模型结构
2 基于多教师模型的知识蒸馏方法
2.1 知识蒸馏原理
知识蒸馏模型采用教师-学生框架,核心思想是利用教师模型输出概率分布生成的软标签和真实模型构成的硬标签来共同训练学生模型,学生模型同时学习真实标签和教师模型的预测概率分布[28]。教师模型和学生模型通过损失函数连接,公式如下:
其中,Lhard为表示学生模型输出与硬标签之间差异硬标签损失函数;Lsoft为软标签损失函数,表示学生模型输出与软标签的差距;α为平衡参数。
2.2 本文模型框架
为了从多个教师模型中学习知识,本文的教师模型结合了BERT-wwm-ext 和XLNet 预训练模型,通过知识蒸馏的方法将预训练模型中的知识迁移到学生模型BiGRU-CNN 网络中。
本文在计算软标签时将两个模型输出的概率向量p1和p2结合计算软标签,具体方式如下:
其中,λi为权重系数,由教师模型输出的概率向量与硬标签的相关系数计算:
其中,h为硬标签,pit为教师模型输出的矩阵。
本文使用交叉熵损失函数计算学生模型输出的概率分布yp与真实标签yt的差距即硬标签误差:
使用均方差函数计算yp与软标签的差距即软标签误差:
本文的知识蒸馏结构如图4 所示。
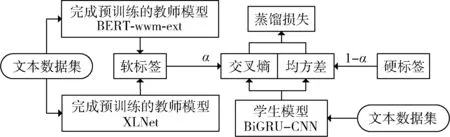
图4 知识蒸馏模型结构
2.3 知识蒸馏模型的实现过程
知识蒸馏模型实现的步骤如下:
(1)使用文本数据集分别训练教师模型BERT-wwmext 和XLNet,计算两个模型输出的概率矩阵;
(2)使用两个模型输出的概率矩阵计算软标签;
(3)使用软标签和硬标签训练学生模型,使损失函数值达到最小。
3 实验及结果分析
3.1 实验数据集
本文使用以下3 个数据集作为实验数据:
(1)今日头条数据集:由今日头条客户端下载。本文选取十个类别,包括民生、文化、教育、军事、国际、游戏、体育、房产、汽车、科技,每个类别各10 000 条,保存在一个JOSN 文件中,内存量为8.1 MB。
(2)THUCNews 新闻数据集:由Graviti 公开数据集网站下载。本文选取十个类别,包含金融、地产、股票、教育、科学、社会、政治、体育、游戏和娱乐,每个类别各10 000 条,每条数据分别保存在一个txt 文件中,内存总量为21.8 MB。
(3)微博数据集:使用Python 爬虫爬取,包括军事、文学、运动、疫情、美食、美妆、旅游、校园、心理学、二十大十个主题,每个类别各10 000 条,保存在一个SQL 文件中,内存量为13.9 MB。
每组数据集采用随机抽取的方式,选取50%用于训练模型,其余作为测试数据集。
3.2 评价指标
实验评价指标采用准确率P、召回率R、F1。
准确率Pi表示类别i的文本被正确判断的数量TPi与该类别文本实际数量的比例,其中FPi为类别i的文本被错误判断的数量,P表示所有类别准确率的平均值:
召回率Ri表示TPi与被判断为该类别文本数量的比例,其中FNi为被错误判断为类别i的文本数量,R表示所有类别准确率的平均值:
F1值为结合准确率与召回率的综合指标:
3.3 实验参数
本文实验两个教师模型的参数设置见表1,学生模的参数设置见表2,知识蒸馏蒸馏平衡参数α分别设置为0.2、0.3、0.5 进行对比。
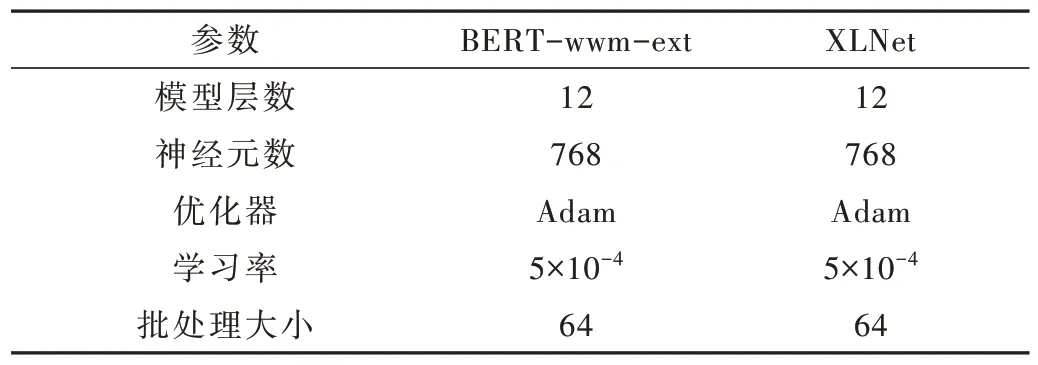
表1 教师模型参数设置

表2 学生模型参数设置
3.4 对比试验
未验证本文模型的有效性,本文使用CNN、BiGRU、BiGRU-CNN、BERT-wwm-ext、XLNet、单教师模型知识蒸馏(教师模型分别为BERT-wwm-ext 和XLNet、α=0.2)、不同学生模型的知识蒸馏(学生模型分别为CNN、BiGRU)、不同参数知识蒸馏(在α值分别为02、0.3、0.5 时)进行对比。
3.5 实验结果分值析
3.5.1 准确率对比分析
(1)深度学习模型对比
深度学习模型CNN、BiGRU、BiGRU-CNN 在不同数据集中的实验结果见表3。
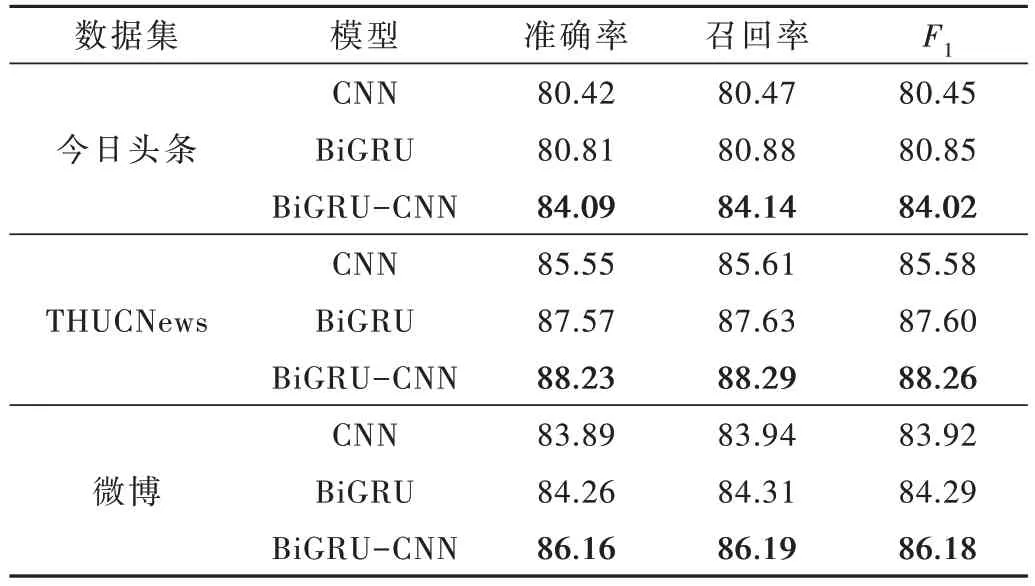
表3 深度学习模型实验结果对比 (%)
从表3 的实验结果可以看出,BiGRU-CNN 模型的准确率较CNN 和BiGRU 提高了3%左右,原因是BiGRUCNN 模型可同时捕捉文本的局部和整体特征,信息提取更全面。
(2)预训练模型对比
预训练模型BERT-wwm-ext 和XLNet 在不同数据集中的实验结果见表4。
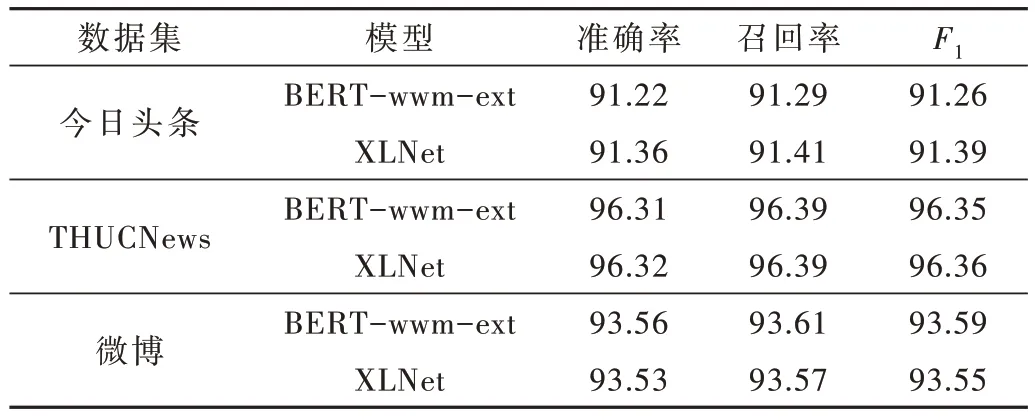
表4 预训练模型实验结果对比 (%)
从表4 的实验结果可以看出,两个预训练模型的准确率较为接近,模型性能相似。与深度学习模型相比,准确率有了较大的提高。原因是教师模型相比较学生模型有大量的参数和较深的网络层次,从原始数据中学习的大量知识的能力更强。
(3)多教师知识蒸馏与单教师知识蒸馏实验对比
从表5 的实验结果可以看出,多教师模型相对单教师模型准确率提高了0.15%左右,原因是多教师模型知识蒸馏可以从不同预训练模型中学习更全面的知识。对比两个单教师模型可以看出,教师模型的准确率越高,知识蒸馏模型的准确率越高。

表5 不同教师模型实验结果对比 (%)
(4)不同学生模型实验结果对比
从表6 可以看出,BiGRU-CNN 为学生模型时,准确率较高,原因是BiGRU-CNN 模型参数量相对较大,学习能力较强。
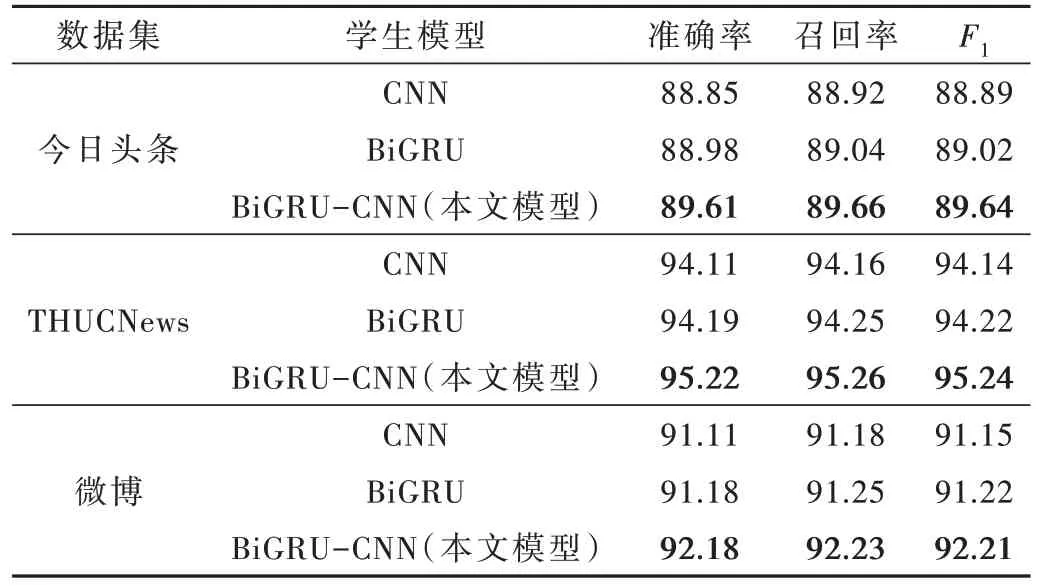
表6 不同学生模型实验结果对比 (%)
(7)不同参数实验对比
从表7 可以看出,α=0.2 时,准确率最高。

表7 不同参数实验结果对比 (%)
(8)教师模型学生模型实验结果对比
从表8 可以看出,本文提出的知识蒸馏模型结构简单,分类效果与教师模型有一定差距,在平衡参数α=0.2 时准确率最高,在3 组数据集中准确率较学生模型分别提高了5.52%、6.99%、6.02%,可以看出教师模型准确率越高,对知识蒸馏后学生模型精度的提高比例越大。
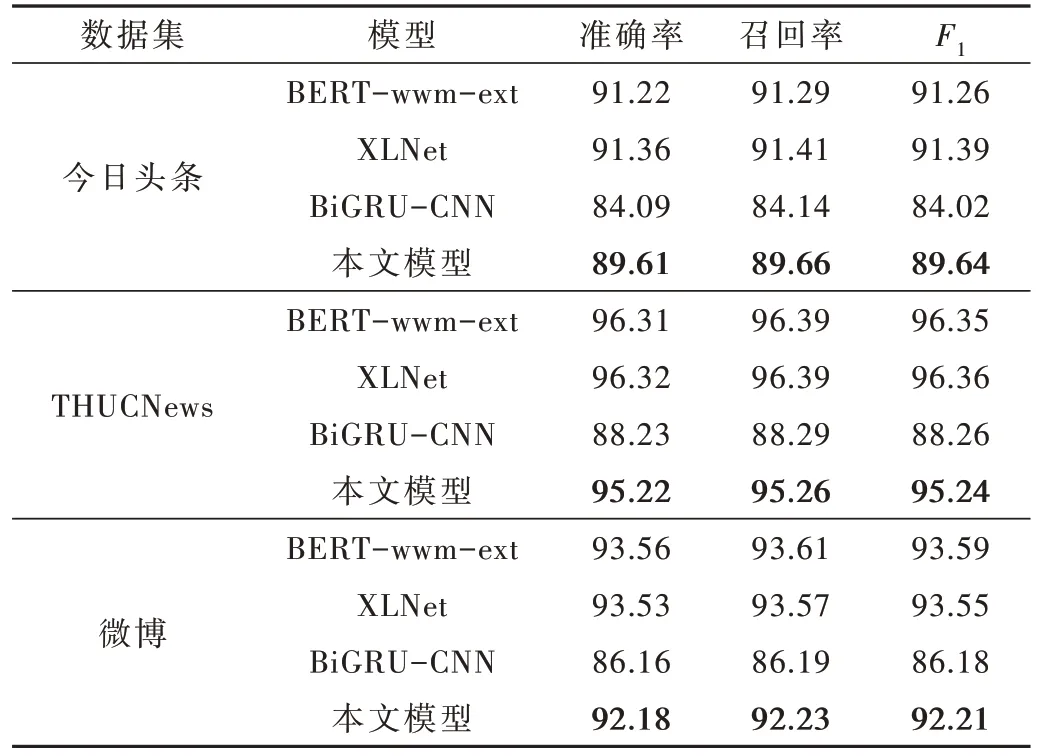
表8 模型与学生模型的对比 (%)
3.5.2 运行时间对比分析
教师模型和学生模型的运行时间见表9。

表9 运行时间对比 (s)
从表9 可看出,在今日头条、微博数据集、THUC‐News 3 个数据集中,知识蒸馏模型的消耗时间分别约为教师模型的56%、49%、40%,学生小于教师模型。且数据量越大,知识蒸馏模型与教师模型运行时间的比值越小。
4 结论
本文基于简单的文本分类结构正确率较低,预训练模型分类正确率高但是占用内存量大、运行时间长的情况,提出了融合两个教师模型BERT-wwm-ext 和XLNet 预训练模型、学生模型BiGRU-CNN 网络的知识蒸馏模型,将两个教师模型预测的概率分布矩阵通权重分配的方法结合作为软标签指导BiGRU-CNN 网络的训练。在学生模型真实标签的同时学习预训练模型的预测结果,提高了模型的泛化能力。实验结果表明,知识蒸馏模型在准确率接近预训练模型的前提下,大大缩短了运行时间,更适用于实际的生产环境。本文提出的多教师知识蒸馏模型与单教师知识蒸馏模型相比,准确率略有提升,因此多教师知识蒸馏可以提高模型准确率。
