Multi‐granularity re‐ranking for visible‐infrared person re‐identification
2023-12-01YadiWangHongyunZhangDuoqianMiaoWitoldPedrycz
Yadi Wang | Hongyun Zhang| Duoqian Miao | Witold Pedrycz
1Department of Computer Science and Technology,Tongji University,Shanghai,China
2Key Laboratory of Embedded System and Service Computing,Ministry of Education,Shanghai,China
3Department of Electrical and Computer Engineering, University of Alberta, Edmonton,Alberta, Canada
4System Research Institute, Polish Academy of Sciences,Warsaw,Poland
Abstract Visible-infrared person re-identification (VI-ReID) is a supplementary task of singlemodality re-identification, which makes up for the defect of conventional reidentification under insufficient illumination.It is more challenging than singlemodality ReID because, in addition to difficulties in pedestrian posture, camera shooting angle and background change, there are also difficulties in the cross-modality gap.Existing works only involve coarse-grained global features in the re-ranking calculation,which cannot effectively use fine-grained features.However, fine-grained features are particularly important due to the lack of information in cross-modality re-ID.To this end,the Q-center Multi-granularity K-reciprocal Re-ranking Algorithm (termed QCMR) is proposed, including a Q-nearest neighbour centre encoder (termed QNC) and a Multigranularity K-reciprocal Encoder (termed MGK) for a more comprehensive feature representation.QNC converts the probe-corresponding modality features into gallery corresponding modality features through modality transfer to narrow the modality gap.MGK takes a coarse-grained mutual nearest neighbour as the dominant and combines a fine-grained nearest neighbour as a supplement for similarity measurement.Extensive experiments on two widely used VI-ReID benchmarks, SYSU-MM01 and RegDB have shown that our method achieves state-of-the-art results.Especially, the mAP of SYSUMM01 is increased by 5.9% in all-search mode.
K E Y W O R D S computer vision, recognition
1 | INTRODUCTION
Person re-identification aims at matching individual pedestrian images in a probe set from a large gallery set.Because of different body poses, shooting angles and environmental conditions, ReID becomes a challenging job.Many works are mainly suitable for RGB images captured by visible cameras and have achieved great success.However,visible cameras can only capture high-quality images under good illumination conditions, such as daytime.With the development of hardware devices, the dual-mode camera has been widely used for public security.The dual-mode camera can switch the day to night mode according to the light intensity or the predefined time point in the system.The visible camera is used to capture RGB images of three channels in the day mode, while the infrared camera is used to capture infrared images of the single channel in the night mode.Hence, visible-infrared person reidentification (VI-ReID) makes up for the single modality ReID under night and indoor conditions which lack light.
At present,the existing researches mainly focus on how to map the two modalities' features to the same feature space in the training stage.Due to the heterogeneity of data,the feature difference of the same pedestrian in different modalities is often greater than that of different pedestrians in the same modality, causing difficulty in matching.However, there are few studies on the re-ranking phase of cross-modality tasks,which greatly improves the matching effect and is also a very important part in the ReID process.
At the same time,due to the modality specificity in the VIReID task, the modality-shared features will lack some information.For example, the color information of the visible modality cannot be used in the matching process with the infrared modality,so it is particularly important to pay attention to the local details.Depending on the particularity of the human body structure, the distribution of various parts of the human body in the monitoring picture is relatively fixed.In the person re-ID, PCB architecture is often used to divide the extracted features horizontally to obtain the fine-grained features of the corresponding location.However, most networks use global features and fine-grained features in the training stage and only use global features for similarity measurement in the testing stage.To make effective use of the fine-grained characteristics of samples in the testing stage, this paper proposes a re-ranking algorithm based on multi-granularity for cross-modality person re-identification.
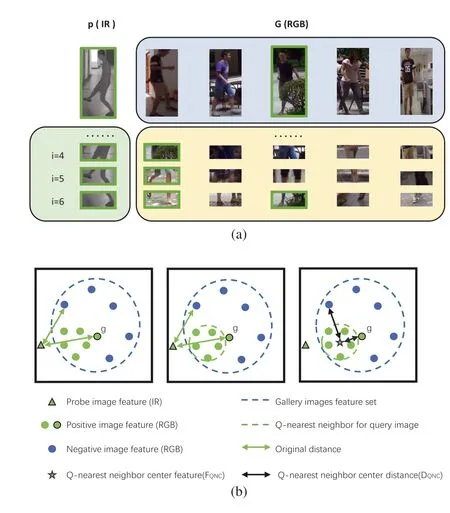
F I G U R E 1 (a) The similarity ranking obtained by global features and different local feature blocks for re-ranking.The images in the green box are the local feature block of the probe images;The images in the blue box is the similarity ranking calculated by the global feature; The images in the yellow box are the similarity ranking calculated by local feature blocks(The more images in the front column, the higher the similarity); The images with the green edge has the same identity as the probe image.(b)Measure the cross-modality similarity by Q-nearest neighbour center encoding(QNC).
In this study, we propose an innovative re-ranking algorithm for the person VI-ReID, which considers features at different granularities both globally and locally.As shown in Figure 1a, in some cases, the ranking calculated by local features is more accurate than that calculated by global features.At the same time, because some fine-grained features under one modality may be unavailable under another modality in the cross-modality task, it is necessary to pay attention to other available fine-grained features.Fine-grained features should only be complementary, and the ranking list still needs to be dominated by global features.Therefore an improved multigranularity k-reciprocal re-ranking algorithm (MGK) is proposed to make the measurement pay more attention to special features by modifying the calculation process of reciprocal neighbour.Specifically, the coarse and fine-grained features used in the calculation can be simultaneously obtained from one two-stream feature extraction network containing the PCB structure.
Although the feature extraction network aims to map the features of two different modalities into the same feature space, due to the difference between the two modalities, the features extracted from images with the same modality are more clustered even through the feature extraction network.As the left part of Figure 1b,the distance between the directly extracted probe image feature and the gallery set imagegwith the same identifier may be far.Thus, we introduce Q-nearest neighbuor centre encoding (QNC), which mitigates the difference of two modalities feature spaces in cross-modality samples.As the middle and right parts of Figure 1b, finding the Q-nearest neighbours with the same identity in another modality, and representing the probe central feature by the mean of neighbours' features.Therefore, the image feature encoder with the same identity as the probe is more similar to the probe's feature encoder, while the image feature encoder with different identity as the probe is more distinguishable from the probe's feature encoder.
We conduct extensive experiments to demonstrate the effectiveness of our proposed method.The contributions of this paper are three-fold:
• We propose a novel multi-granularity k-reciprocal re-ranking(MGK) algorithm for VI-ReID to enhance the comprehensiveness of measurement by aggregating local and global characteristics.
• We introduce a cross-modality feature approximation scheme(QNC)to extract the person similarity matrix,which smoothens the re-ranking and reduces the modality gap.
• The proposed method effectively improves the re-ranking performance in person VI-ReID on the two mainstream benchmark datasets SYSU-MM01 and RegDB in both rank one and mAP.
2 | RELATED WORK
2.1 | Person Re‐identification
Person Re-identification aims at finding the matching with probe images in the gallery set.The matched pedestrians with the same identifier may be taken by different cameras or taken by the same camera at different times.Common ReID methods can be divided into two categories:methods based on representation learning and methods based on metric learning.After extracting pedestrian features,the former regard ReID as a multi-classification problem and takes each pedestrian ID as a category; the latter calculates the similarity between two pedestrians and judge whether they have the same pedestrian ID.
The research scope of person ReID is very wide, it is divided into single modality ReID and cross-modality Re-ID.At present, the supervised single modality ReID research has achieved encouraging results.Some methods,such as ABD[1],SONA [2], VAL [3], whose experimental performance on public datasets is close to or even better than the manual matching performance.Therefore, lots of researches have shifted to cross-modality Re-ID, such as text-image Re-ID[4, 5], RGB-Depth Re-ID [6, 7] and VI Re-ID.
2.2 | Visible‐infrared person Re‐identification
Visible-infrared person Re-identification aims at matching individual pedestrian images in a probe set from a large gallery set, which consists of pictures taken by the other modality camera.Wu et al.[8]create the first large-scale RGB-IR person ReID dataset named SYSU-MM01 and propose a zeropadding network to finish the cross-modality person ReID task.To reduce the cross-modality difference, Dai et al.[9]propose cmGAN that extracts the feature vector by the generator and map it to the corresponding pedestrian identity.Many scholars deal with the difference between the two modes by improving the cross-modality loss function in the network.Ye et al.[10] propose Dual-Constrained Top-Ranking that considers both cross-modality and intra-modality variability.Hao et al.[11]propose DFE that constrains two modal feature distributions by JS divergence.HC loss [12] is proposed to achieve modality alignment by constraining the heterogeneous modality feature centre.
Other methods are based on modality transition, focusing on converting one modality image into the other modality image as real as possible.Wang et al.[13] first propose AlignGAN to transform the infrared images into RGB images by CycleGAN.D2RL [14] is proposed to exploit variational autoencoders (VAEs) for style disentanglement, which is followed by GANs to generate another modality images.Choi et al.[15]propose Hi-CMD that automatically disentangles IDdiscriminative factors for cross-modality matching.JSIA-ReID[16]propose set-level alignment,which distinguishes modalityspecific features and mode invariant features, which is more conducive to judgment.However, modality transition only realises the one-to-one generation from the IR image to RGB image,but in fact,the same IR image may correspond to RGB images of multiple colours.Simultaneously it destroys part of the original information and leads to a certain degree of noise.
2.3 | Re‐ranking for person Re‐ID
Re-ranking aims at making the correctly matched images higher ranks after obtaining an initial ranking list.Le et al.[17]proposed Common Near-Neighbor Analysis, which extracts new features in the matching stage, and both consider the relative information and direct information of sample pairs.DCIA [18] was proposed to suppress the interference of context information in the sample and emphasise the function of content information.The correct search results in the gallery set should be similar, so the method based on the nearest neighbour is also widely used.Ye et al.[19] proposed a rank aggregation method that combines the result of the globalbased rank method and local-based rank method by crossed k-nearest neighbours.Then they proposed the united similarity ranking aggregation method and dissimilarity ranking aggregation method, which also calculate quasi-dissimilar sets independently.Zhong et al.[20] proposed k-reciprocal encoding which considers not only the nearest neighbour relationship between the probe and gallery set but also the nearest neighbor relationship between the gallery set and probe set and add Jaccard distance to revise the initial rank list.However, the above methods are pointed at the re-ranking method under the single modality,and there is less research on cross-modality at present.Compared to the single modality, cross-modality analysis requires considering the modality gap caused by heterogeneous data characteristics.Jia et al.[21] proposed a similarity inference metric for VI-ReID that makes up intramodality k-reciprocal neighbours by cross-modality k-nearest neighbours and adding the similarity graph reasoning as an auxiliary.
3 | PROPOSED METHOD
Given a RGB probe imagep, and a gallery setG={gi|i=1,2,…,NG} withNginfrared person images, VI-ReID reranking aims to obtain a new matching sequence forpaccording to the similarity.
3.1 | Two‐stream feature extractor
VI-ReID method based on feature fusion often uses a onestream feature extraction network or a two-stream feature extraction network as the backbone.The difference is that the first one uses the network layer with the same structure and same parameters for feature extraction,while the next one uses the network layer with the same structure with different parameters which trained separately according to the modalities.As shown in Figure 2a, the first two convolution blocks of ResNet are independent for extracting the specific features of the two modalities, and the last three convolution blocks parameters are shared to map the different modality features to the same feature space.In the preprocessing stage, the single infrared channel repeats three times to ensure the consistency of the input image in two modalities.Different feature extraction branch networks have the same structure and different parameters.The two-stream feature extraction network extracts global featuresFgand then PCB segments local features.Firstly,the feature is horizontally divided intoCfeature blocksFL,reducing dimension for each feature block by global average pooling and 1×1 convolution layer.
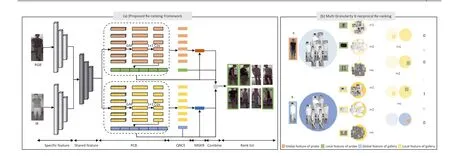
F I G U R E 2 (a)The proposed Re-ranking Framework.RGB and IR images obtain initial features through different feature extraction networks,adopt QNC encoding and multi-granularity k-reciprocal encoding and calculate the ranking list after combination.(b)The partial visualisation process of multi-granularity kreciprocal re-ranking.To judge whether gi belongs to the k-reciprocal set of p,first find the local and global nearest neighbour sets and then judge whether the corresponding part is in the other's nearest neighbour set,such as i=c.If any part satisfies the reciprocal neighbor condition,gi is in the reciprocal neighbor set of p.
3.2 | Multi‐granularity K‐reciprocal Re‐ranking
A person needs to pay attention to both coarse-grained global pedestrian features(such as body shape)and fine-grained local pedestrian features (such as shoes, backpacks, etc.).Especially among similar samples, local features are particularly important.Therefore,we improve the k-reciprocal neighbour loss in the single modality and propose a multi-granularity kreciprocal re-ranking method that depends on both local and global information, as shown in Figure 2b.Firstly, the initial distancedc(p,gi) between the probe imagepand the gallery imagegiis defined as Mahalanobis distance:
where Σ is the covariance matrix.Through the standardisation of the feature vector, Σ can be regarded as an identity matrix.Sorted bydc(p,gi),we definenlas theknearest neighbours of the sampleqcomputed from the corresponding local feature block at the same location:
The k-nearest neighbour of the sample calculated from all the local feature and global feature can be defined asNl(p,k)andNg(p,k) respectively:
wherecis the number of local feature blocks divided in PCB.glis the local block feature through the samplegk, andggis the global feature.According to the previous description, we can define local k-nearest neighbours for a block as
Accordingly, we can define local and global k-reciprocal neighbours respectively as
Considering both global and local features can enhance the robustness of matching.As shown in Figure 1a, due to the influence of the shooting angle and light, the global characteristics of pedestrians with the same identity may be different,but their local characteristics may be similar.Therefore, we defineR′as the union of the global k-nearest neighbour and multiple local k-nearest neighbours based on multi-granularity.
wherek1is the number of global nearest neighbours,andk2is the number of local nearest neighbours.According to the single-modality K-reciprocal encoding definition [20], extendingR′toR″ can strengthen the robustness of the algorithm and help to supplement the matching samples missed in the initial ranking.In order to reduce the computation, we only traverse the global nearest neighbour.

where |⋅| denotes the number of candidates in the set.In the subsequent implementation, theR″ sets are represented as vectors according to the original k-reciprocal neighbor implementation, and the original distance between the two samples dominated by global features is used as the initial vector weight.Therefore, the overall reordering result is still dominated by global features, and local features are only used as supplements.
3.3 | Q‐nearest neighbor center encoding
Due to the large difference between the two modalities, the feature extraction network may not be able to map them to the same feature space.For example, in Figure 3b, the distance between the feature vectors of different pedestrians in the same modality may be smaller than that of the same pedestrian in different modality.Therefore, we use the Q-nearest neighbour feature instead of the original feature representationF.The basic idea is that the characteristics of a modality samplepcan be represented by the characteristics of the other modality samples, which are close top.We define the Q-nearest neighbour centre encoding in the other modality forpasFQNC.According to the transformation,the influence of crossmodality on feature measurement can be determined.

F I G U R E 3 Parametric Analysis on SYSU-MM01.(a) Different k2 in MGK.(b) Different q in QNC.
whereFQNC(p,q) is the Q-nearest neighbour centre encoding for imagep.N(p,q)is the q-nearest neighbor set ofpcontainsqimages from gallery set.According to the previous definition,N(p,q)is determined by Mahalanobis distance.The Q-nearest neighbour centre distance betweenpandgican be defined as
According to Equation (10), the Q-nearest neighbour centre distance instead of the original distance as a measure can reduce the modality gap.

Algorithm 1 QCMR Algorithm Input: Probe set global feature FP,g, probe set local feature FP,l, gallery set global feature FG,g, gallery set localimages/BZ_231_1404_1290_1473_1374.pngture FG,l 1: Calculate dc(p, gi) as Equation (1)2: Initializs q-nearest neighbour centre encoding F′P,g and F′P,l,F′G,g,F′G,l as Equation (10)3: Calculate dqnc(p, gi) as Equation (1)4: for each p,g in P,G do 5: Calculate k1 nearest neighbours Ng F′g and k2 nearest neighbors Ng with F′l as Equations (2) and (3).6: Calculate global k1 reciprocal neighbours Rg and local k2 reciprocal neighbours Rl as Equations(4)and(5)7: Calculate multi-granularity kreciprocal R′ as Equation (6)8: end for 9: for each p,g in P,G do 10: Calculate extended neighbours multigranularity k-reciprocal R″ as Equation (7)11: end for 12: for each p in P do 13: Calculate Jaccard distance dJ as Equation (8)14: end for 15: Calculate final distance d′ as Equation (11)Output: Distance between each probe and gallery set d′
3.4 | Q‐center multi‐granularity K‐reciprocal Re‐ranking
The proposed Q-center Multi-granularity k-reciprocal Reranking method (QCMR) can thus be derived by combining QNC and MGK.To more comprehensively measure the distance between different features, we jointly aggregate Jaccard distance,Q-nearest neighbour centre distance and the original distance as the final distanced′,
whereλ1andλ2donate the trade-off parameter fordQNCanddC, making the model more flexible.dQNCanddCare measured only by global features.Algorithm 1 provides the detailed description of our proposed re-ranking method and inference metric.
4 | EXPERIMENTS
4.1 | Experimental setting
Datasets.SYSU-MM01 is the first large-scale dataset in VIReID, which includes IR images from two infrared cameras and RGB images from four visible cameras.There are 491 pedestrians with different identities in total, including 296 for training,99 for verification and 96 for testing.There are 30071 RGB images and 15792 IR images.The shooting scenes include indoor and outdoor.RegDB contains images captured by dual camera systems(one visible camera and one infrared camera).It contains a total of 412 pedestrians with different identities,and 10 RGB images and 10 IR images were taken for each person.The dataset was randomly divided into two halves, one for training and the other for testing.The procedure was repeated in 10 trials and stable results were obtained according to the average value.
Evaluation protocols.We use standard Cumulative Matching Characteristics curve,mean Average Precision(mAP)and mean inverse negative penalty(mINP)to evaluate the crossmodality person re-identification models.The difference from single modality and the images of one modality are regarded as probe samples, and the images of the other modality are regarded as gallery samples.
Implementation details.We implement the proposed method in PyTorch.The Resnet50 is adopted as the backbone network for feature extraction.We adopt the two-stream parameter shared feature extraction network [33] as the baseline, in which the feature extraction part mainly includes two-stream backbone network with partial parameter sharing and part-level feature extraction block, as shown in Section 3.1.The training loss includes hetero-center triplet loss and identity softmax loss for local features, and hetero-center triplet loss for global features.As the setting for Ref.[33], the first two convolution block parameters are independent, and the last three convolution block parameters are shared to extract modal specificity and modal sharing features, respectively.The training algorithm is optimised with SGD for 60 epochs with a learning rate of 0.1, adopting the warmup strategy for the first 10 epochs and decaying 10 times at 20 and 50 epochs.
4.2 | Comparison with state‐of‐the art methods
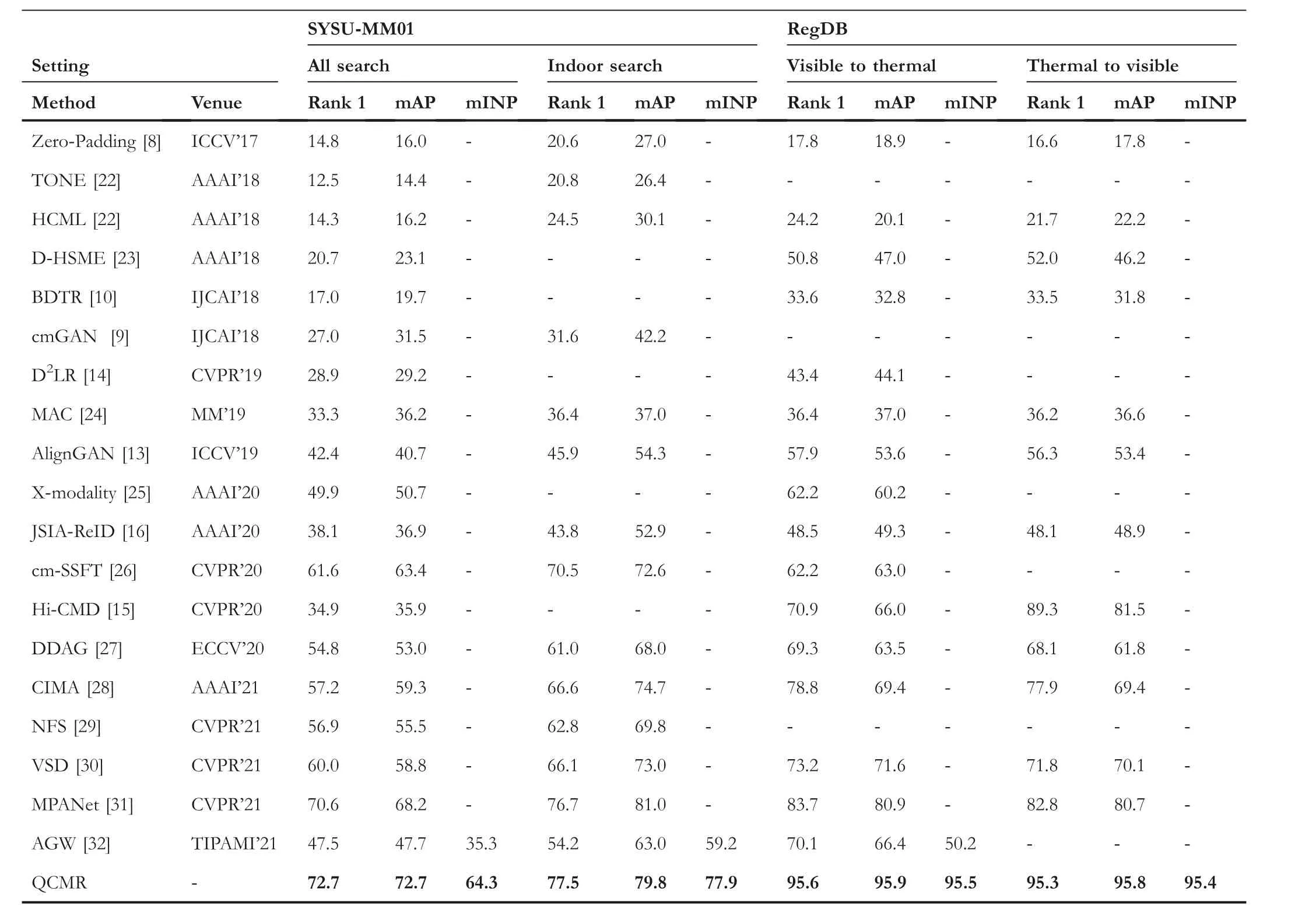
For a more comprehensive evaluation, our method is compared with a large number of existing VI-ReID methods,including methods based on feature mapping(such as TONE,BDTR and AWG) and methods based on modality transformation (such as AlignGAN, JSIA-ReID and Hi-CMD).Table 1 shows the performance on the SYSU-MM01 and RegDB.For SYSU-MM01,we test the performance on the allsearch model and indoor-search model under a single shot.For RegDB, we test the performance on the visible-to-thermal model and thermal-to-visible model.Our method has a competitive performance in all metrics, including Map, Rank1 and mInp.Because the PCB structure can be flexibly transplanted to various training networks,we can easily obtain local features and global features at the same time,which is the basis of our method.Essentially, the QCMR is a post-processing procedure.Therefore, it can achieve better results when applied to a better feature extraction network.
4.3 | Ablation study
Our method consists of two components.All experiments are based on the same feature extraction network and the same weight.In all ablation experiments, we only trained the network once,and other experiments related to re-ranking are loaded with the same weight.Table 2 and Table 3 report the resultant rank 1, mAP and mINP values on the all-search SYSU-MM01 and thermal-to-visible RegDB dataset by adding one component at a time.The baseline follows the setting in Ref.[33] and is ranked only by cosine similarity.The baseline* obtains the ranking list by the raw k-reciprocal encoding(KR).Without the k-reciprocal neighbour encoding,the direct cosine similarity measurement of QNC will reduce the r1 value by about 6%, but the other two evaluation indicators will be improved.It is ineffective to directly calculate the cosine distance by the QNC,because we cannot guarantee the complete correctness of the initial sorting.Instead, the amount of information will be lost due to the modal transition,thus leading to a drop in rank 1.Therefore, the QNC can only be supplemented in the re-ranking stage as a supplement, and we prefer to regard MGK and QNC as a whole.Our multigranularity k-reciprocal re-ranking method is better than the k-reciprocal re-ranking method in every index, especially mINP increased by 7%.The MGK extends some locally similar samples that are not originally in the neighbour nodes into the calculation of the Jaccard distance, which facilitates a more comprehensive measurement.Furthermore, since the Gaussian kernel of the pairwise distance is used to form a vector in the actual operation, the number of neighbour intersections between samples is implicitly represented in the calculation process.In other words, the similarity of global features is regarded as a measure of the number of local neighbours.So we do not count the number of neighboursbetween samples, but simply judge whether the two are neighbours, whether locally or globally.
T A B L E 1 Performance of the proposed method compared with state-of-the-arts

T A B L E 2 Ablation study on the SYSU-MM01
When the two components are all used,mAP can increase by 5%, and mINP is even able to increase by 12%.Although rank 1 is down by 0.5% compared to MGK only, it is still an improvement compared to the baseline.Therefore, the two components reinforce each other.
Parametric Analysis in MGK.Figure 3a shows the results for differentk2in the local reciprocal neighbour computation.As the value ofk2continues to increase, the model performance will continue to improve and reach the optimal value whenk2= 27.

T A B L E 3 Ablation study on the RegDB
Parametric Analysis in QNC.Figure 3b shows the results for differentqin the cross-modality feature centre computation which tested on the baseline.We speculate that mAP rises first and then falls because the highqvalue causes some sample features which differ from the probe image identity as neighbours,resulting in a centre shift.In particular,q=0 means that the original feature is directly adopted instead of the QNC feature.
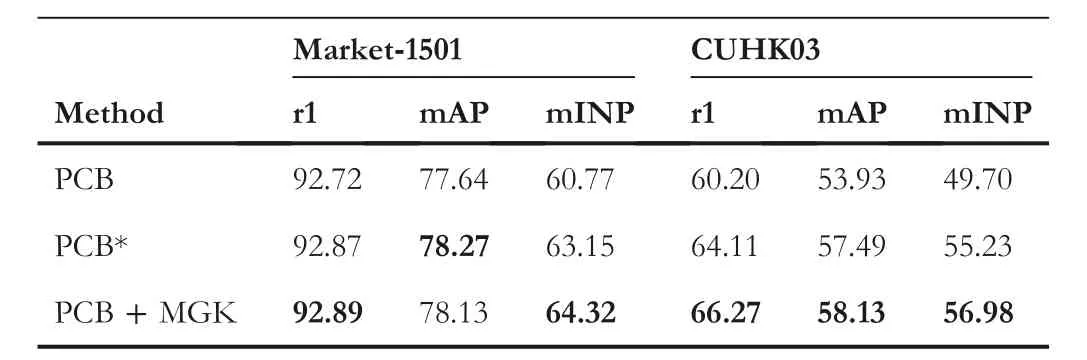
MGK on single‐modality ReID.In the singlemodality ReID task, there is also the problem that local feature ranks better.Therefore, we try to apply the MGK method to two widely used single-modality datasets to verify the generalisation of our method.As shown in the Table 4, MGK can also improve some indicators of the single-modality dataset, but the effect is not as significant as that of the VI-ReID.We speculate that due to the different causes of the local feature ranking better problem,and most of the local features are available in the singlemodality task.
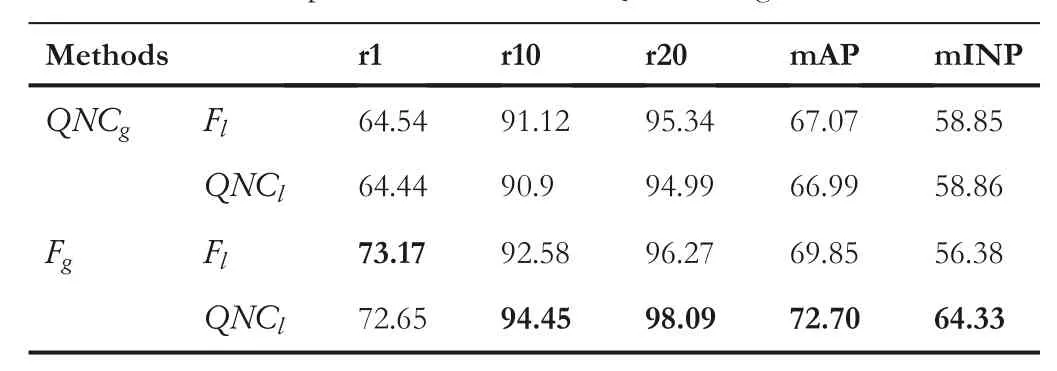
Parametric Analysis in QCMK.When applying both components at the same time, the utilisation position of the QNC is very important.We tested the nearest-neighbor modality transformation for global and local features separately and both simultaneously as Table 5.Only performing a neighbour transformation on local feature blocks achieves better results.Since the transformed features have more advantages in the neighbors' calculation, however, completely replacing the original features leads to information loss.Global features dominate the nearest neighbor statistics, while local features are complementary.Therefore, modality transformation only on local features effectively narrows the modality gap with less information reduction, leading to better results.
Besides,the results show that QNC improves mINP in all situations.Because the transformed features in the same modality pull into the distance between samples with the same identity,this makes difficult samples more likely to have higher rankings.
We also experimented with the values ofλ1andλ2as Figure 4.By the grid search method with a gradient of 0.025,whenλ1andλ2are both 0.05,the best mAP and rank 1 can be obtained.Too highλ1orλ2will reduce the overall performance of the model.Therefore, we speculate that MGKE plays a leading role, and the other two only play a complementary role.
Validity of Different Divisions in PCB.Figure 5 is the testing results of QCMK effectiveness for different local feature block divisions(p)in PCB,where the gray dotted line is the baseline with k-reciprocal re-ranking.At any value ofp,bothq= 1 andq= 2 achieve better results than the baseline,especially on mAP and mINP, which demonstrates the robustness of our method.
Smallerq-values lead to better results,which may be due to the excessiveqleading to additional negative samples.What's more,with smallerpin PCB,the more obvious performance is improved.We deduce that this is because fewer feature block division easily makes it difficult for the two different modalities to map to the same space, so it is more necessary to perform modality feature transformation with QNC to narrow the modality gap.
Our method is easier to achieve better results on mAP and mINP metrics.Adding local features enriches the nearestneighbour representation,which ensures that the original positive samples that are not in the Jaccard distance metric are included in the calculation.However, we still use the original features for distance measurement, which results in that the newly added positive samples cannot be ranked higher than the original positive samples in the nearest-neighbour set, thus making it difficult to improve rank 1.However, adding these positive samples that were not originally involved in the calculation has a positive contribution to the significant improvement of mAP.Although the samples added by our method cannot surpass the original best-matched samples, modality transformation can optimise the similarity of the original lower-ranked positive samples,resulting in an improvement in mINP.
T A B L E 4 MGK on single-modality ReID

F I G U R E 4 Different λ1 and λ2 in QCMK.(a)Grid search results of λ1 and λ2.(b) Test of λ1 (λ2 = 0.05).(c) Test of λ2 (λ1 = 0.05).
T A B L E 5 Comparison with different QNC strategies

F I G U R E 5 Different Number of Local Feature Divisions for SYSU-MM01.(a)mAP(p=2).(b)r1(p=2).(c)mINP(p=2).(d)mAP(p=3).(e)r1(p=3).(f) mINP(p = 3).(g) mAP(p = 6).(h) r1(p = 6).(i) mINP(p = 6).(j) mAP(p = 9).(k) r1(p = 9).(l) mINP(p = 9).
5 | CONCLUSION
In this study, we propose an innovative re-ranking algorithm for cross-modality person re-identification, which utilises the local features and reduces the modality gap.Adding local reciprocal neighbours to the reciprocal neighbour set effectively supplements the differences between pedestrians with the same identity caused by the changes of the viewing angle,illumination and modality.Modal transformation improves the ranking of positive samples and enhances the robustness of the algorithm.Extensive experiments demonstrate that our proposed method brings significant improvements over the baseline.At present, our method mainly acts on mAP and mINP,but the improvement of rank one is weak.In the future,our research can focus more on how to improve the rank one in VI-ReID.
ACKNOWLEDGEMENT
This paper is partially supported by the National Natural Science Foundation of China (Serial No.61976158 and No.62076182), and the Jiangxi “Double Thousand Plan”.
CONFLICT OF INTEREST
The authors declare that there is no conflict of interest that could be perceived as prejudicing the impartiality of the research reported.
DATA AVAILABILITY STATEMENT
[SYSU-MM01]The data that support the findings of this study are openly available at http://isee.sysu.edu.cn/project/RGBIRReID.htm.[RegDB]The authors confirm that the data supporting the findings of this study are available at http://dm.dongguk.edu/link.html.
ORCID
Hongyun Zhanghttps://orcid.org/0000-0001-9781-5078
杂志排行

CAAI Transactions on Intelligence Technology的其它文章
- Fault diagnosis of rolling bearings with noise signal based on modified kernel principal component analysis and DC-ResNet
- Short‐time wind speed prediction based on Legendre multi‐wavelet neural network
- Iteration dependent interval based open‐closed‐loop iterative learning control for time varying systems with vector relative degree
- Thermoelectric energy harvesting for internet of things devices using machine learning: A review
- An embedded vertical‐federated feature selection algorithm based on particle swarm optimisation
- An activated variable parameter gradient-based neural network for time-variant constrained quadratic programming and its applications