基于SMOTE和随机森林的变压器故障诊断研究
2023-11-29李龙飞韩雪峰刘洪顺
刘 磊,李龙飞,韩雪峰,王 冠,刘洪顺
(1.国网新疆电力有限公司电力科学研究院,新疆 乌鲁木齐 830011;2.新疆输变电设备极端环境运行与检测技术重点实验室,新疆 乌鲁木齐 830013;3.山东省特高压输变电技术与装备重点实验室(山东大学),山东 济南 250061)
0 引言
近年来,我国经济的高速增长带来社会对电能需求的激增,因此保证电网安全稳定地向用户输送电能具有重要的现实意义。变电作为输变电过程不可或缺的一环,其关键部件电力变压器的正常运行与否关系着电网能否可靠地运行,因此需要及时、准确地识别出变压器的故障,从而制定相应的检修计划[1]。局部放电检测[2]、测量绝缘电阻[3]、油中溶解气体分析[4](dissolved gas analysis,DGA)等方法均可用于对变压器故障进行检测和诊断,其中DGA 凭借较为简单的操作、完整且便于处理分析的数据以及不受外界电磁场影响等优势被广泛应用于电力变压器的状态监测与故障诊断领域[5-6]。
目前国内外基于DGA 的变压器故障诊断技术大致可分为两大类:传统比值诊断法和与人工智能相结合的智能诊断技术。比值法因阈值和边界的设定简单而在实际应用中得以广泛使用,然而在识别某些故障类型时,这类方法界限过于绝对、编码不完备等问题逐渐显露,不能全面反映变压器的故障状况。智能诊断技术方面,文献[7]使用基于粒子群算法(particle swarm optimization,PSO)对数据进行处理后,结合支持向量机(support vector machine,SVM)模型利用油中溶解气体数据来判别故障类型;文献[8]建立了选择性贝叶斯分类器模型对变压器进行故障诊断,不仅保留了贝叶斯网络处理不确定性问题较强的能力,还提升了收敛速度,在应用中取得理想效果;黄新波等[9]人采用遗传算法对装袋分类回归树组合算法进行优化,进一步提高了变压器故障诊断模型的泛化能力;重庆大学胡青等[10]人基于核主成分分析(kernel principle component analysis,KPCA)和随机森林算法构建一套故障诊断系统,利用KPCA将故障样本映射到高维的核空间,使用随机森林在高维核空间对故障分类器进行训练,提高了抗干扰能力和诊断的正确率。这些模型虽简单易行,但是需要大量数据支撑模型训练[11],在处理不平衡数据集时,易偏向多数类样本的参数更新而忽略少数类样本的正确分类[12],从而导致变压器故障分类的失败。
变压器油色谱故障数据集属于不平衡数据集,采样方法被广泛应用于不平衡数据集的预处理中,主要包括欠采样、过采样与混合采样。欠采样通过减少多数类样本的数量使其与少数类样本达到平衡,过采样则是增加少数类的样本数量使数据平衡[13]。文献[14]使用欠采样方法使每种类型的样本数量达到平衡,但若数据集规模不大,则可能丢失重要信息;文献[15]通过聚类的方法尽可能提取具有代表性的少数类样本特征,虽然包含了更全面的特征,但是欠采样方法所具有的特征丢失缺点仍然存在;赵月爱等[16]人对简单复制少数类样本的随机过采样进行了研究,虽也可到达数据均衡的效果,但是存在明显的过拟合问题。Chawla等[17]人提出的经典合成少数类过采样技术(synthetic minority oversampling technique,SMOTE)算法具有改善过拟合问题的优点,受到研究学者青睐。因油色谱故障数据集中各类样本数量较少,故不宜使用欠采样方法对数据集进行预处理,否则可能会丢失部分潜在信息,使诊断结果不准确,故可考虑使用SMOTE 算法对数据进行扩充,但其与性能优异的随机森林模型结合使用进行故障诊断的效果有待进一步研究。
提出SMOTE 和随机森林相结合的诊断方法,即在使用随机森林进行诊断之前,利用SMOTE 算法对变压器油色谱故障数据集的少数类故障样本进行扩充,结果表明,使用SMOTE 对不平衡变压器油色谱故障数据集进行扩充后再进行故障诊断可以显著提高故障诊断的准确率。
1 基于SMOTE的变压器油色谱故障数据集的扩充
1.1 变压器油色谱故障数据集特征
不平衡数据集是指各个类别的样本量极不均衡的数据集。变压器在使用过程中通常出现故障的次数较少,并且发生各类故障的频率差异较大,导致监测设备最终检测到的总数据较少且不同故障类型对应的数据量有明显差别,本文使用的原变压器油色谱故障数据集的数据分布如图1所示。由图1可知,在原变压器油色谱故障数据集中,高能放电故障样本数为48,远远多于其他几类故障的样本数,因此变压器油色谱故障数据集满足不平衡数据集的条件,属于不平衡数据集。而现有的变压器故障诊断模型大多要求输入的数据是均衡的,故需要对变压器油色谱故障数据集中的少数类样本进行扩充,以平衡各类故障样本的数量。
1.2 变压器油色谱故障数据集的归一化处理
数据归一化是一种通过无量纲的处理手段,将具有波函数性质的物理数值变成具有某种相对关系的相对值,缩小量值之间落差的有效方法[18]。H2、CH4、C2H6、C2H4、C2H2、CO、CO27 种气体为变压器油中溶解气体的主要成分,本文选取H2、CH4、C2H6、C2H4、C2H25种特征气体作为算法的输入,但这几种气体数据量值差别较大,为了均衡随机森林分类器对各类数据的敏感性,对收集到的数据进行归一化处理,使各指标处于同一数量级。
为降低个别数据数值过大或过小对故障诊断结果的影响,对变压器油色谱故障数据集进行归一化处理,即为:
部分油色谱故障数据如表1所示。

表1 部分油色谱故障数据(体积分数)Table 1 Partial oil chromatography fault data
由表1可得,原故障中5种特征气体的数据量值差别较大,如CH4和C2H6之间,经过归一化处理之后,所有数据均处于(0,1)之间,各个数据指标的数量级达成一致,有利于后续的故障诊断。
1.3 变压器油色谱故障数据集扩充的具体实施
SMOTE 算法增加少数类样本的方法不是对其进行简单复制粘贴,而是对少数类样本进行分析,采用线性插值的方法在两个少数类样本间合成新的样本添加到数据集中,以增加少数类的样本数量,达到数据平衡的目的。扩充原理如图2 所示。图2 中,五角星代表变压器少数类故障的样本数据,搜索其最邻近的k个少数类样本,按照数据集的向上采样倍率n从k个样本中随机抽取n个样本,关联xi和这n个样本,进行随机插值,得到图中表示为正方形的新的少数类样本xnew。重复以上步骤,通过多次的随机插值实现对每一类少数样本的多维扩充,即对每一少数故障类型的5 种特征气体数据均进行扩充。

图2 SMOTE算法插值说明Fig.2 Illustration of SMOTE algorithm interpolation
利用SMOTE 算法对变压器油色谱故障数据集进行扩充的步骤如下。
1)在一个不平衡数据集中,从少数类样本中选取一个样本xi,该样本便作为根样本进行新样本的合成。
2)根据式(3),计算每种少数类故障类型中选为根样本的数据到相应的少数类样本集中所有样本的距离d,得到每个根样本k(k一般为奇数)个邻近的同类别的样本。
式中:xi为每个少数类样本集中的根样本;yi为每个少数类样本集中除根样本以外的样本;m为少数类样本集中除根样本以外的样本的数量。经计算可得,本文中k=5。
3)计算变压器油色谱故障数据集中多数类与少数类间的不平衡程度,即计算高能放电与局部放电、低能放电、中低温过热、高温过热之间的不平衡程度,根据计算出的不平衡程度,根据式(4)选取相应的向上采样倍率n,即从xi的k个邻近样本中随机选取n个样本作为辅助样本记为y1,y2,…,yn。
式中:f(·)为对四舍五入运算函数;IL为不平衡程度。
4)在变压器少数类故障类型的根样本xi和随机选择的辅助样本yi之间进行随机插值,如式(5)所示。分别合成n个对应的少数类变压器故障样本pi,以实现对变压器故障类型少数类样本的扩充,并且进行的均是多维扩充,即对每一少数故障类型的5种特征气体数据都进行了扩充,达到数据平衡的目的。
式中:r为一个(0,1)内的随机数。
SMOTE 算法的采样是在少数类数据样本点xi与其最邻近数据样本的连线上进行随机插值操作,这种方法可看作是直线插值,是按照一定的数学规则有目的地进行数据构造,能够有效避免盲目性和局限性,进而改善随机过采样导致的过拟合问题。SMOTE算法扩充前后变压器油色谱故障数据集分布如图3所示。
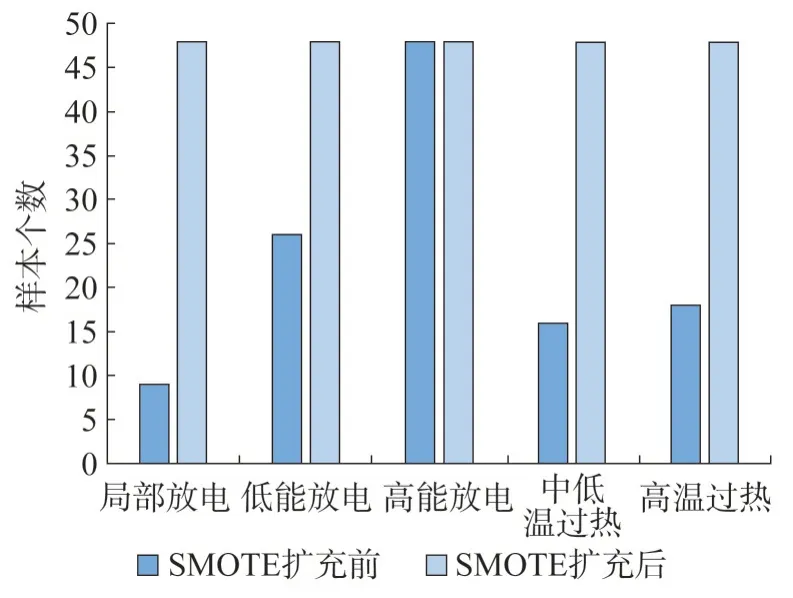
图3 SMOTE扩充前后变压器油色谱故障数据集的分布对比Fig.3 Comparison of the distribution of transformer oil chromatographic fault datasets before and after SMOTE expansion
由图3 可知,SMOTE 扩充前的原变压器油色谱故障数据集中,高能放电故障样本数远远多于其他几类故障的样本数,因此变压器油色谱故障数据集属于不平衡数据集,高能放电故障作为多数类样本,无须对其进行扩充,其他几类故障类型为少数类样本,需要进行扩充。SMOTE 扩充后,5 种故障类型的样本数均达到48 个,各故障类型样本数一致,达到样本均衡,可避免因各故障类型样本数量差距过大影响变压器故障诊断结果。
2 基于随机森林故障诊断的SMOTE扩充效果分析
2.1 基于随机森林的变压器故障诊断
决策树是随机森林的基本单元,构建合适准确的决策树是实现随机森林算法的基础。常用的量化指标有信息增益、基尼指数和均方差3 种,其中信息增益、基尼指数是作为分类问题的构建指标,而均方差则是用在回归问题中,另外本研究中选择分类指标时应考虑原故障数据集为不平衡数据集这一特点,避免信息增益率偏好取值类别较少特征的问题[19],故将选取基尼指数这一指标作为决策树节点分类的标准。
随机森林是以决策树为估计器的Bagging 算法,是多个决策树分类模型的组合。使用随机森林对变压器进行故障诊断的流程如图4 所示。具体过程为:
1)参数选取。针对研究问题选取随机森林参数,包括决策树数量100、节点分裂评价准则为基尼指数、叶子结点的最大数量50。
2)随机化抽取。使用bootstrap 抽样方法,从划分为训练集的变压器油色谱故障数据集中随机地、有放回地选取部分特征量样本形成h个特征子样本集,并且选取出的每个特征子样本集的样本容量与原训练集相同,即若原训练集含有N个样本,则h个特征子样本集中的每一个数据集所含样本数均为N个。
2.2 故障诊断结果准确率分析
分别将未经SMOTE 扩充的原变压器油色谱故障数据集和经SMOTE 扩充后的变压器油色谱故障数据集按照7:3 的比例划分为训练集和测试集,使用训练集对随机森林模型进行训练,然后使用测试集验证模型的准确率。
图5、图6 分别为使用未经SMOTE 扩充的原数据集作为输入和使用经SMOTE 扩充后的数据集作为输入的故障诊断混淆矩阵热力图。矩阵的每一行代表实际的类别,每一列代表预测的类别,对角线上的数字代表正确预测的结果。

图5 使用未经SMOTE扩充的原数据集作为输入的故障诊断混淆矩阵热力图Fig.5 Fault diagnosis confusion matrix thermodynamic diagram using original dataset without using expanded by SMOTE as input

图6 使用SMOTE扩充后的原数据集作为输入的故障诊断混淆矩阵热力图Fig.6 Fault diagnosis confusion matrix thermodynamic diagram using SMOTE expanded original datset as input
由图5 可知,随机森林对未经SMOTE 扩充的原变压器油色谱故障数据集5 种故障类型诊断结果的准确率分别为100%、84.2%、93.9%、72.7%、76.9%,对训练集诊断结果的总准确率为86.6%,测试集为88.6%。
由图6 可知,随机森林对经过SMOTE 扩充后的原变压器油色谱故障数据集5 种故障类型诊断结果的准确率分别为100%、97.1%、97.1%、88.2%、93.9%,对训练集诊断结果的总准确率为95.2%,测试集为93.1%。
通过对比分析可知,与未经SMOTE 扩充的原变压器油色谱故障数据集相比,使用经SMOTE 扩充后的变压器油色谱故障数据集作为随机森林模型的输入可以明显提高各个故障类型诊断结果的准确率,因此使总体的准确率也得到大幅提升。可见,使用SMOTE 算法对不平衡的变压器油色谱故障数据集进行扩充,达到数据平衡后再使用随机森林模型进行故障诊断,有利于提高诊断结果的准确率。
2.3 其他故障诊断模型
为进一步验证使用SMOTE 算法对不平衡的变压器油色谱故障数据集进行扩充有利于提高变压器故障诊断模型的准确率这一结论,同时直观地展现使用随机森林进行变压器故障诊断的优势,介绍另外几种变压器故障诊断的模型,并分别对未经SMOTE 扩充的原变压器油色谱故障数据集和经SMOTE 扩充后的变压器油色谱故障数据集进行故障的识别,然后分析和比较几种模型的诊断结果。
2.3.1 朴素贝叶斯网络
贝叶斯分类方法以统计学为基础,根据已有的样本数据实例,利用先验信息对事件的后验概率进行预测[20]。使用朴素贝叶斯网络对未经SMOTE 扩充的原变压器油色谱故障数据集和经SMOTE 扩充后的变压器油色谱故障数据集进行故障诊断,结果如图7所示。

图7 朴素贝叶斯网络故障诊断混淆矩阵热力图Fig.7 Fault diagnosis confusion matrix thermodynamic diagram using naive bayesian network
朴素贝叶斯网络对未经SMOTE 扩充的原变压器油色谱故障数据集5 种故障类型诊断结果的准确率分别为83.3%、84.2%、90.9%、81.8%、84.6%,训练集诊断结果的总准确率为86.6%,测试集为82.9%;对经过SMOTE 扩充后的原变压器油色谱故障数据集5 种故障类型诊断结果的准确率分别为93.9%、91.2%、88.2%、88.2%、87.9%,训练集诊断结果的总准确率为89.9%,测试集为91.7%。
2.3.2 SVM模型
SVM 仍然是使用数学中的统计学思想对电力变压器故障类型进行识别和判断的一种分类器模型。使用SVM 对未经SMOTE 扩充的原变压器油色谱故障数据集和经SMOTE 扩充后的变压器油色谱故障数据集进行故障诊断,结果如图8所示。


图8 SVM故障诊断混淆矩阵热力图Fig.8 Fault diagnosis confusion matrix thermodynamic diagram using SVM
由图8 可见,SVM 对未经SMOTE 扩充的原变压器油色谱故障数据集5 种故障类型诊断结果的准确率分别为83.3%、89.5%、93.9%、72.7%、84.6%,训练集诊断结果的总准确率为87.8%,测试集为80%;对经过SMOTE 扩充后的原变压器油色谱故障数据集5种故障类型诊断结果的准确率分别为97%、94.1%、85.3%、91.2%、90.9%,训练集诊断结果的总准确率为91.7%,测试集为92.4%。
使用随机森林、朴素贝叶斯网络、支持向量机模型对未经SMOTE 扩充的原变压器油色谱故障数据集和扩充后的变压器油色谱故障数据集进行故障诊断,结果如表2所示。

表2 3种模型故障诊断准确率汇总Table 2 Comparision of fault diagnosis accuracy of three models 单位:%
由表2 可知,对3 种故障诊断模型,使用经SMOTE 扩充后的变压器油色谱故障数据集作为模型输入所得诊断结果的准确率,无论从单个故障类型还是整体角度都比使用未经SMOTE 扩充的原数据集有较为明显的提高,进一步验证了使用SMOTE算法对不平衡的变压器油色谱故障数据集进行扩充后再进行故障诊断的准确率高于扩充前。
同时可以看出,对未扩充前的不平衡数据,3 种模型诊断准确率大致相同,但是对于扩充后的平衡数据集,使用随机森林对变压器进行故障诊断的准确率远高于其他两种模型,由此可知随机森林模型在变压器故障诊断中具有较高的准确率。同时其又具有缓解局部最小值、过拟合等问题的优点,因此,使用随机森林对变压器进行故障诊断是一个较为理想的选择。
3 结论
针对现有故障诊断技术存在处理不平衡数据集过拟合、准确率低等问题,首先对原变压器油色谱故障诊断数据集进行预处理,然后通过比较选择一个故障诊断准确率较高的模型对变压器的故障进行识别与诊断,并对SMOTE扩充有效性进行验证。
1)变压器油色谱故障诊断数据集属于不平衡数据集,而目前所使用的基于油中溶解气体分析的变压器故障智能诊断技术,在处理不平衡数据集时,为了达到最高的准确率,易对数据量少的变压器故障类型出现误判,从而导致故障类型识别的失败。因此采用SMOTE 算法通过随机插值对归一化后的变压器油色谱故障数据中的少数类样本进行扩充,平衡了各个故障类型样本的数量,为故障诊断打下良好的基础。
2)利用处理好的数据采用随机森林分类器对变压器进行故障诊断,通过对未经扩充的原数据和经SMOTE 扩充后的数据的诊断结果准确率的对比分析,验证使用SMOTE 对不平衡变压器油色谱故障数据集进行扩充后再进行故障诊断,可以显著提高故障诊断的准确率。
3)使用其他两种诊断模型对SMOTE 扩充有效性进行验证,并通过与随机森林诊断准确率的对比,确定随机森林分类器是3 种故障诊断模型中诊断准确率最高的模型,为变压器故障诊断提供方法选择。
