基于FPGA 的HEVC 熵编码语法元素硬件加速设计
2023-11-24林志坚黄萍郑明魁陈平平
林志坚 黄萍 郑明魁 陈平平
(福州大学 物理与信息工程学院,福建 福州 350108)
随着智能手机和短视频的普及,视频在全网数据流量占比已接近70%。2013年,为了满足人们对视频更高质量的要求,国际电联(ITU)正式批准通过了高效视频编码(HEVC/H.265)标准,该标准较高级视频编码(AVC/H.264)标准的编码效率大约提高50%[1]。编码效率的提升,降低了对视频传输和存储的带宽要求[2],因此HEVC 可以支持4 k 和8 k的分辨率[3]。熵编码是HEVC 的最后一个环节,可以很大程度压缩视频的熵冗余。相较于AVC/H.264,HEVC 保留了唯一的熵编码方式——上下文自适应二进制算术编码(CABAC),用于编码片数据(Slice data)。虽然CABAC 具有编码效率的优势,但其复杂度也成倍增加[4]。
目前,普遍的CABAC 硬件设计1 个时钟周期可以处理1个语法元素,而一些语法元素的上下文索引计算规则复杂[4],导致语法元素的生成通常不止1 个时钟周期。因此语法元素作为CABAC 的输入,其生成速度落后于CABAC 的处理速度,导致CABAC 模块的空闲,使得该部分的设计成为了提高熵编码实际吞吐量的瓶颈。近年来,CABAC 作为熵编码的核心模块备受广大研究者关注,涌现了大量关于优化CABAC 硬件结构和提高其吞吐量的研究。文献[5]将熵编码的硬件架构分成数据预处理模块、二值化模块、上下文建模模块和算术编码模块,其中数据预处理模块用于产生语法元素(SE)。该架构可以采用三路并行架构同时进行编码树单元(CTU)的编码,极大提高了熵编码的吞吐量。但该架构熵编码吞吐量的提高并没有针对语法元素的生成结构进行优化,而是通过巨大的电路资源消耗换取。文献[6]针对熵编码的数据依赖性强的特点,提出了预归一化、大概率符号和小概率符号并行等方案,该方案每个时钟平均可以处理4.2个字符。文献[7]中提出的四路残差语法元素方案可以提高残差语法元素的速度,但是设计复杂,并且没有考虑到语法元素的存储消耗问题。文献[8]中通过查找表的方式确定系数组(CG)的扫描位置,解决了对角扫描的复杂变换问题。文献[9]中提出基于乒乓结构的残差编码控制结构,但该结构没有考虑到全零CG 块的问题。高吞吐量熵编码器的实现需要有足够的语法元素输入,以确保熵编码器能够持续工作。因此,文中针对加快语法元素产生提出了多种电路优化方案,以减少熵编码模块整体的时间。首先,通过对高效视频编码(HEVC)标准码流信息的分析,提出了预头信息编码、上下文模型初始化和编码单元(CU)结构优化策略,可以加快语法元素的产生,以供自适应二进制算术编码器使用。其次,大多数残差语法元素计算较为复杂,对硬件电路很不友好,而文中提出的高效残差编码架构和部分上下文索引流水计算方案,在保证高吞吐量的同时,可以减少由复杂计算带来的路径延迟,提高工作频率。本文提出的设计充分考虑到各个模块的特性,可以在增加很小硬件面积的情况下,提高熵编码的吞吐量。
1 熵编码概述
1.1 HEVC的码流结构
视频编解码器共同遵守一套编码结构,以确保解码器可以将码流正确解码,恢复视频。为了提高压缩效率和网络适应性,HEVC 设计了新的语法分层处理架构[10]。从概念上讲,HEVC 被分成视频编码层(VCL)和网络抽象层(NAL)[11]。VCL描述了74个低级语法元素,主要可以分成4 大类:四叉树划分、帧内和帧间预测、变换、量化和环路滤波[12]。NAL 层将压缩的视频数据封装到NAL 单元中,增加了HEVC 应用的灵活性[11]。CABAC 将根据这些语法元素来准备要存储或者传输的码流[12]。图1是HEVC 的码流结构,首先,整个码流前端是参数集相关头信息,包括视频参数集(VPS)、序列参数集(SPS)和图片参数集(PPS);其次,每个片(Slice)由片头(Slice Header)和片数据(Slice Data)构成,其中,片数据由1个或多个CTU 信息构成。每个CTU信息包含环路滤波(LP)参数信息和多个编码单元(CU)信息。每个CU 信息包含CU 头信息、预测单元(PU)信息和变换单元(TU)信息。

图1 HEVC的码流结构Fig.1 Stream structure of HEVC
1.2 CABAC流程
CABAC 熵编码器的作用是对视频压缩的早期阶段产生的语法元素数据进行无损压缩。在实际编码中,因为每个字符是不可预测的,CABAC 采用二进制算术编码方法统计每个输入字符的变化特性,可为每个字符提供精准的上下文模型,从而达到较高的压缩效率。CABAC 的基本框架如图2 所示,包括二值化、上下文建模和二进制算术编码3个步骤。
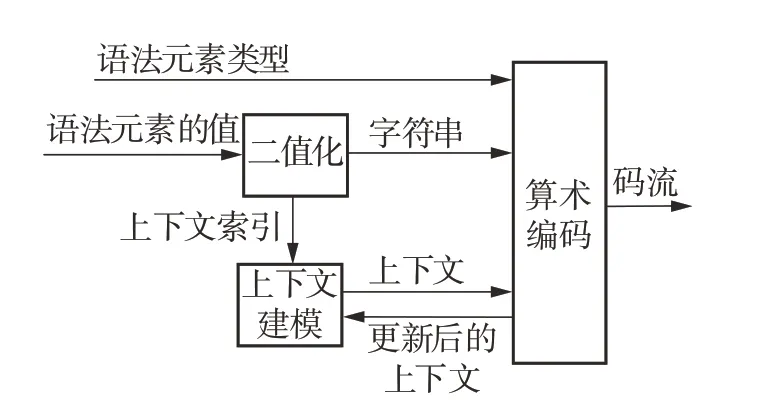
图2 CABAC的基本框架Fig.2 Basic framework of CABAC
二值化是将非二进制语法元素的值转换成二进制字符串。在HEVC 中使用了4 种不同的二值化方法,包括:一元码、截断一元码、K阶指数哥伦布二值化和定长编码[8]。HEVC 为每个语法元素都指定了对应的二值化方法,可以在不增加传输比特的条件下正确解码[7]。
上下文建模是根据已编码字符的统计特性来估计当前字符的概率[5]。在HEVC 中,不同语法元素或者同一语法元素不同位置的字符,都有不同的上下文模型。根据HEVC 提供的初始值、量化参数(QP)和片类型可以得到每个字符的初始上下文模型。在编码的过程中,根据输入字符的上下文索引进行查表可以得到相应的上下文模型,并在算术编码结束后,更新对应的上下文模型。
算术编码是根据递归区间划分的。在递归的过程中保留编码区间Range 和区间下限Low。算术编码包含3 种模式:常规编码、旁路编码和结尾编码[10]。其中常规编码是基于自适应的概率模型进行编码,需要不断读写概率状态表更新概率状态;而旁路编码是使用等概率的方式进行算术编码,概率状态无需更新[10]。虽然常规编码相较于旁路编码其编码结构更复杂,但是具有更高的编码效率。
2 加快语法元素方案分析
2.1 预编码头信息方案
头信息包括参数集头信息和片头信息。参数集头信息包括视频参数集(VPS)、序列参数集(SPS)和图片参数集(PPS)。片头信息主要包括当前Slice的配置参数。如图3 所示,在文献[13]的设计中,熵编码模块启动后,需要等待片头信息编码完成后再开始CTU信息编码。而在对视频的第1个CTU信息进行编码之前,不仅需要等待片头信息编码,还需要等待参数集片头信息编码完成后才能启动CTU信息编码。本文提出的预编码头信息方案如图4所示,可以节省等待编码头信息的时间。具体的预编码头信息方案如下:针对参数集头信息,在启动编码器后,可以马上对参数集头信息进行编码。针对片头信息,第1个片头信息的编码是在参数集信息编码完成后进行的,而其它片头信息与CTU信息同时进行编码。因此本文的熵编码模块启动后,都可以马上启动CTU信息的编码。

图3 文献[13]的编码头信息方案Fig.3 Encoding header information scheme in literature [13]

图4 本文的预编码头信息方案Fig.4 Pre-encoding header information scheme in this paper
参数集和第1个Slice的头信息不需要计算,可以从配置信息中获取。因此,可以在第1个CTU的待编码信息传入前,提前完成头信息编码。由于每个Slice 的压缩数据是独立的,Slice 的头信息无法从前1个Slice的头信息推断得到[10],所以在对每个Slice 信息进行编码之前编码端都需要编码片头信息。其中,片头信息相关语法元素的编码方式都不是CABAC,不需要使用上下文模型,所以片头信息可以和CTU 信息并行编码。因此,本文把不是第1 个片的其它片头信息和CTU 的信息并行编码,通过码流控制模块选择对应的码流输出,可以节约等待编码片头信息的时间,避免二进制算术编码模块的空闲。
图5 是本文熵编码器状态机转换图,一共有7个状态,分别是原始状态(IDLE)、编码高级语法元素状态(High_Syntax)、编码片头信息状态(Slice_Header)、上下文模型初始化状态(Context Model_Init)、编码CTU 状态(CTU)、清空编码器缓存状态(Slice_End)和生成cabac_init_flag 状态(Determine)。当检测到编码器启动标志coder_start_i的上升沿时,将启动高级语法元素和片头信息的编码,并分别对3个Slice进行上下文模型初始化;头信息编码和上下文模型初始化结束后,回到原始状态,并将header_cm_done置为高电平,表示上下文模型初始化和头信息编码已经完成,下个Slice 的首个CTU进来时,无需进行头信息编码和上下文模型初始化。当检测到start_i信号并且条件1为真时,即表示该CTU 为非第1帧的首个CTU,将同时启动片头信息编码、上下文模型初始化和CTU 编码进程。当检测到start_i 为高电平并且图5 中的条件1为假时,则会进入编码CTU 的状态,若该CTU 不是Slice 的最后一个CTU,则CTU 编码结束后直接进入原始状态,等待下一个CTU数据的到来,否则end_of_slice_flag 置为高电平,进入Slice_End 状态清空算术编码器的缓存,接着进入Determine 状态计算cabac_init_flag,该标志决定下一个Slice 的B Slice和P Slice的上下文模型是否互换。

图5 本文熵编码器状态机转换图Fig.5 Entropy encoder state machine conversion diagram in this paper
2.2 上下文模型初始化方案
上下文模型初始化是为每个字符提供唯一的初始概率模型[10]。每个Slice 不能跨越它的边界进行预测,因此在熵编码之前需要进行上下文模型初始化。根据QP、Slice Type 和HEVC 为各个字符提供的InitValue 可以计算出每个字符的初始上下文模型。在文献[13]设计中,每次编码新的Slice时,都需要重新计算上下文初始值。而本文提出的上下文模型初始化方案在编码器启动时,将分别计算B Slice、P Slice 和I Slice 的上下文模型并存储到对应存储器中,以供每个Slice 的上下文模型初始化直接读取,避免重复进行上下文模型初始化。
首先,上下文自适应二进制算术编码(CABAC)中的上下文建模过程需要使用上下文初始化模型,所以上下文模型初始化不可以与CABAC并行。其次,HEVC中每种Slice约有200种字符上下文模型,初始化需要消耗一定的时间,这将造成CABAC 模块的空闲。因此,本文提出的上下文模型初始化方案避免了等待上下文模型初始化的过程,从而提高了熵编码的编码效率。
熵编码器状态机转换图如图5所示,头信息编码完成后,将启动上下文模型初始化电路。当对视频首个CTU 进行编码时,header_cm_done 等于1,表示头信息编码和上下文模型初始化工作已经完成,可以直接进入CTU 编码的工作;当编码其他Slice 的首个CTU 时,将并行对片头信息和CTU 进行编码及对上下文模型进行初始化。
图6是本研究的上下文模型初始化电路图。其中,context_init_B、context_init_P 和context_init_I用来分别存储B、P 和I Slice 的初始上下文模型;context_update 用作编码器实时更新的上下文模型。该模块启动时,控制模块将控制上下文模型初始化电路产生3个Slice的上下文模型,分别存储到context_init_B、context_init_P、context_init_I 中。值得一提的是,在视频编码中,第1个Slice是独立编码的,所以该Slice一定是I Slice。根据这个特点,本文初始化过程中将contex_update 初始化为context_init_I,这样编码第1个Slice时,可以跳过上下文模型初始化直接进入编码CTU状态。此后的上下文模型初始化过程只需要1 个时钟周期,context_update 根据Slice 类别(Slice_type_i)选择对应的context_init即可。

图6 上下文模型初始化电路图Fig.6 Context model initialization circuit diagram
2.3 CU结构优化策略
因为CABAC 对数据依赖性强,熵编码模块必须按照HEVC 的编码顺序将语法元素依次送入CABAC 编码。由于语法元素产生速度与CABAC 编码速度不匹配,所以本文将产生的语法元素存放在先进先出模块(FIFO)中,以供CABAC读取。
进入CU 层编码时,需要依次编码CU 层、PU层和TU 层的语法元素。计算帧内语法元素时,构建最可能模式(MPM)列表需要消耗较多的时间;计算变换块的语法元素时,变换块的扫描和残差语法元素上下文复杂的计算等都会导致语法元素信息产生速度变慢,从而导致CABAC 的空闲;进一步,针对QP 较大的TU 块,包含较多的全零CG 块,编码信息较少,残差四叉树的遍历同样会导致CABAC 模块的空闲。因此,本文在CU 层增加2 个FIFO 分别用于存储PU 和TU 层产生的语法元素信息,这样可以缓冲等待生成PU层和TU层语法元素的时间,减少CABAC 的空闲时间,提高熵编码的实际吞吐量。
图7 是CU 层级的设计框图。语法元素的信息来源主要分成3 个部分:CU 层语法元素、PU 层语法元素和TU 层语法元素,而具体输出哪一部分的语法元素信息是通过CU 层的状态机输出的state_o来决定的。

图7 CU层级的设计框图Fig.7 Design block diagram of the CU hierarchy
2.4 残差编码架构设计
由文献[14]可知,与变换系数有关的语法元素占总语法元素的65%~72%,因此变换系数的编码在熵编码中占举足轻重的地位。1 个变换块的变换系数经过扫描可以获得一组一维的变换系数,该组变换系数可以通过最后非零系数位置和幅值信息完全表示[10]。最后非零系数位置表示经扫描后的第1 个非零系数的位置。在HEVC 中,通过对最后非零系数位置和幅值信息进行CABAC 编码,可以达到压缩的目的。
变换块将被划分成若干个4×4 大小的CG 块,并按照一定的扫描顺序,依次对每个CG进行编码。由于扫描顺序中的对角扫描规律和部分残差语法元素的上下文索引计算过程都较为复杂,在硬件架构的设计上会造成时延高的问题。文献[9]中将数据准备和CG 编码设计成乒乓结构,以节省等待数据准备的时间,但是没有对数据的扫描进行流水线处理。本文将残差编码架构设计成如图8 所示的4 级流水线模式,该架构在保证高吞吐量的同时能实现较低延时。

图8 残差编码流水架构Fig.8 Residual code pipeline architecture
第1级流水线中,根据残差系数块的扫描方式和大小,通过查表确定CG的位置。本文将每个CG块的位置信息和CG块的跳转都记录在表里。因此,只需要一个时钟(clk)就可以实现CG 位置的获取和CG 的跳转。第2 级流水线中,向顶层传递CG 的位置,查询该CG 的残差系数,该过程消耗2 个clk。第3 级流水线中,根据CG 的残差系数和扫描方式计算最后非零系数的位置,该过程消耗1 个clk。第4级流水线中,为了减少由语法元素上下文索引复杂计算带来的多路径延迟,本文将该部分独自划分1 个模块,只有当CG 的残差系数不全为零才进入该模块进行CG编码。4级流水线的设计可以保证CG 编码模块的持续工作,持续输出语法元素的同时减少了关键路径的延迟,提高了熵编码模块的工作频率。
2.5 上下文索引计算
经扫描得到CG 的一维残差后,HEVC 并不是直接将残差送给熵编码模块进行编码,而是进行一番分析和处理后,形成最合适的变换系数表示残差,交由熵编码处理。其中表示位置信息的语法元素sig_coeff_flag(SIG)和表示幅值信息的语法元素coeff_abs_level_greater1_flag(GR1)的上下文索引计算规则复杂并且数量占比大[14],因此如何快速计算SIG 和GR1 的上下文索引成了加快CG 编码的关键问题。文献[7]中使用多时钟域,每个时钟处理4 个位置的所有语法元素,不仅会消耗大量的硬件资源,而且会导致工作频率的极大下降。为解决该问题,本文对残差语法元素的特性进行分析,使用3 级流水线计算SIG 和GR1 的上下文索引,可以减少等待上下文索引的计算过程,满足每个时钟编码1个SE,在增加较少的硬件资源的基础上,提高了工作频率。
SIG 表示该像素点的系数是否为零,1个CG 中最多编码16次SIG。GR1表示该像素点的系数是否大于1,1个CG中最多编码8次GR1[10]。SIG和GR1的上下文索引由像素点的位置、YUV分量、变换块的大小和相邻CG 的语法元素coded_sub_block_flag(CSBF)的值决定。其中,在编码过程中,像素点的位置是实时变化的,因此本文使用3级流水线计算SIG和GR1的上下文索引,可以缩短等待上下文索引的计算过程,满足每个时钟编码1 个SE。第1 级流水线中,根据扫描类型和像素点的索引Res_idx,查找像素点所在的位置。同样,本文将16 个像素点的位置和Res_idx 记录在表内。第2 级流水线中,由像素点的位置、相邻CG 的CSBF 和TU 的大小计算上下文基础索引Sig_Base_Ctx 和Gr1_Base_Ctx。第3 级流水线中,由YUV 分量和基础索引计算上下文索引增量Sig_Icr_Ctx 和Gr1_Base_Ctx 并编码。图9 是SIG 和GR1 的上下文索引流水计算架构。

图9 上下文索引流水计算架构Fig.9 Context index for pipeline calculation architecture
3 设计验证与结果分析
本文提出的熵编码架构包含熵编码的所有模块,已通过Verilog RTL 实现,并基于官方参考软件HM16.7,已经通过不同QP、分辨率和视频序列的测试。图10 是本文方案的测试框图。测试过程如下:首先,将HM16.7中熵编码模块的输入数据和输出码流打印出来;接着,将打印出来的HM16.7 中编码的输入数据作为本文设计的输入。最后,将本文设计的输出码流与HM16.7的输出码流进行一致性对比。

图10 测试框图Fig.10 Test block diagram
本文对HEVC官方提供的视频序列进行仿真测试,统计了在全I 帧情况下编码1 个CTU 所需要的时间,如表1所示。根据结果可知,本文方案应用在QP较大的序列中效果更佳。在预料之中,QP越小,残差系数语法元素所占的比重越大,本文提出的预编码头信息和上下文模型初始化方案的优势将减弱。从表1 中可以得到,QP 为22 时,每个CTU节省了23.1%~32.8%的时间;QP 为37 时,每个CTU节省了45.2%~51.2%的时间。平均每个全I帧的CTU节省了38.2%的周期数。

表1 全I帧下不同QP和序列的1个CTU时钟数节省情况Table 1 Number of 1 CTU clocks saved for different QPs and sequences at full I-frame
与同类型文献进行比对的结果如表2所示。该表列出了我们所关心的参数,包括硬件工艺、逻辑门个数、最高主频和最高吞吐量,其中硬件工艺是指所选芯片的制造工艺,用栅长长度表示,栅长越短,则可以在相同的硅片上集成更多的晶体管。文献[15]中虽然提出了流水线HEVC熵编码架构,但使用了较多的逻辑门;本文在最高主频达到200 M的同时,使用的逻辑门数比文献[9]减少了61.7%;文献[16]中对残差系数编码中上下文模型的选择算法提出了改进,但无法实现完全流水,本文的残差系数控制方案可以实现完全流水,而且逻辑门个数节约了61.83%;文献[5]中虽然提出了高吞吐量的三路CTU并行编码方案,但其资源消耗是本文设计的6.22倍。
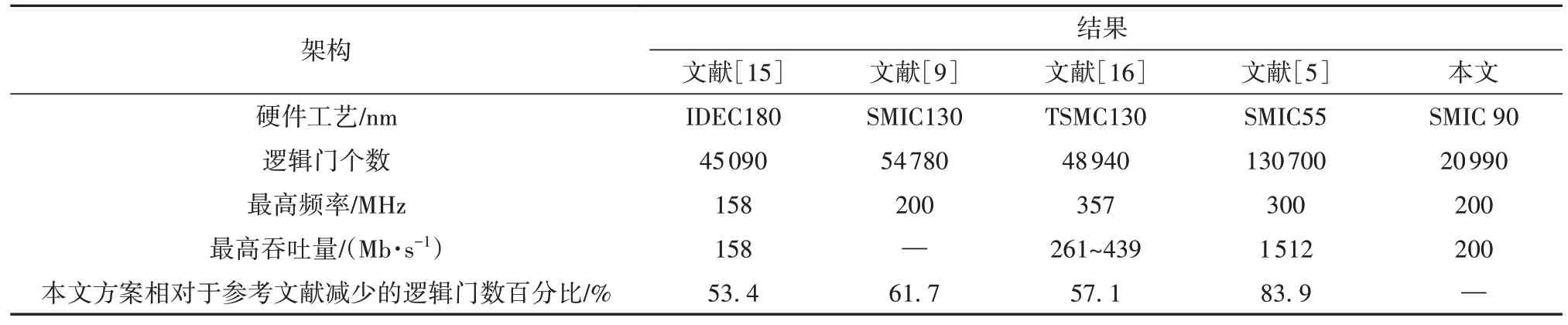
表2 硬件结果对比Table 2 Comparison of hardware results
4 结语
随着CABAC 吞吐量的提高,语法元素作为CABAC 的输入,其生成速度成为熵编码实际吞吐量的瓶颈。因此,本文主要针对加快语法元素生成展开工作,并基于官方参考软件HM16.7做了原型验证。结果表明在编码全I帧时,不同QP和序列的1个CTU 平均可以节省38.2%的周期数。统计分析指出,残差语法元素信息是构成码流的关键。随着QP 减小,残差语法元素的占比增加。通过实验分析可知,随着QP 的减小,本文方案的优势降低。因此,笔者将继续优化其他残差语法元素的计算,以确保小QP时CABAC有足够的语法元素输入。
