基于双注意力引导特征级联的显微影像深度估计方法
2023-11-23付攀李桢韦柄廷王杰王爽边桂彬
付攀,李桢,韦柄廷,王杰,王爽,3,边桂彬*
(1.北京信息科技大学自动化学院,北京 100192; 2.中国科学院自动化研究所,北京 100190;3.北方工业大学机械与材料工程学院,北京 100144)
基于深度学习的深度估计方法通过预测二维图像中每个像素相对于观察相机的深度值,实现对原场景三维结构的估计。在显微外科手术中,数字影像能够为医生提供实时的高清晰度术野,并可以从中提取关键的信息,例如病灶位置、大小和形态等,来辅助医生做出更加精准的手术决策[1-3]。当前,深度学习方法在医学影像领域被广泛应用于三维重建、手术规划和病理分析等方面[4-5],但很少有对于显微术中影像深度估计的研究,主要是由于显微手术场景中存在目标尺度微小、特征模糊、多镜面反射等难点。因此,进一步研究和改进深度估计方法以克服这些挑战并提高其推理精度,有助于在术中更精准地判断手术器械和软组织的空间位置关系,为新手医生提供关键的决策信息、缩短其学习曲线,从而为改善患者预后作出贡献。
当前常用的深度估计方法主要分为3类。基于视差的方法利用对应点间的视差或结构光中相位的差异来计算深度信息[6],例如经典的双目视觉算法和基于结构光的三维重建方法,还包括基于光场等模态图像的深度估计方法[7]等。基于图像语义信息的方法利用神经网络从图像中提取语义线索,例如进行物体检测和分割,进而推理更加精准的深度信息[8-9]。基于运动信息的方法则通过分析连续帧之间的运动变化推断场景中深度分布[10-11],如使用SLAM(simultaneous localization and mapping)技术,可以将实时的影像信息映射到三维模型中,用于场景重建和虚拟现实[12-14]。这些方法从平面图像中恢复了深度信息,有助于增强计算机视觉应用如智能驾驶、机器人导航中的场景理解能力。
深度估计技术在医学影像中的应用也越来越受到关注。其中,深度卷积神经网络(convolutional neural networks,CNN)和Transformer是两种最常用的深度学习基础架构。在胸外科领域,深度估计技术被用于辅助使用支气管镜的活检导航[15]。通过使用周期一致性生成对抗网络直接从支气管镜图像中生成深度图,并将深度图注册到术前CT(computed tomography)上,获得了较高的准确性。在结肠镜检查中,深度估计技术被用来从单一图像中重建结肠表面的地形[16-17],在开发的内窥镜相机模型渲染得到的合成图像上训练,并最终集成到现有内窥镜系统中对肠道地形进行在线估计。这些研究表明,深度估计技术在医学影像领域的应用前景广阔,可以为医生提供更加精准的诊断和治疗方案。
然而,在常见的深度估计策略中,基于密集特征匹配的方法[18-19]在多软组织和目标尺度微小的手术影像中容易受特征点模糊和漂移影响而发生性能退化。在基于深度编解码架构的神经网络中,考虑到算力资源限制,难以保持原始图像高分辨率进行深层处理。往往采用连续的下采样和上采样以在网络深层提高感受野并减少计算量,却容易因此带来细小特征丢失、深度边界模糊等性能衰减。尽管已提出一系列方法如跳跃连接、残差连接等用于保留下采样和上采样过程中的细节信息,但仍然在许多具有挑战性的任务,如显微手术场景中的微小器械深度估计方面存在明显局限性。此外,由于显微手术场景中器械软组织存在复杂交互,且临床上难以采集高质量的真值数据,因此仍然缺乏高精度的深度估计方法。
为了从二维术野彩色图像中更精准地恢复场景中各语义对象的深度,现从以下3个方面提出了解决方案。一是利用多层次跳级连接聚合模块传递编码器中的上下文信息到解码器中,从而更好地保留带有局部细节的隐层空间特征;二是提出基于通道选择和分支优化的双重注意力特征融合机制,优化解码过程的精度。此外,提出一种迭代式点云融合策略,通过结合自动化的结构光扫描实现多视角点云配准和重建高精度深度数据,以获得稠密的深度真值。通过上述策略,实现显微手术场景的端到端高精度深度估计,有效解决推理的深度图中关键细节信息丢失的问题。
1 基于双注意力引导特征级联网络模型
如图1所示,所提出的跨层级特征级联网络模型的数据流主要由多层编解码器架构定义。网络以RGB通道彩色图作为输入,以单通道深度图作为输出。网络主要组成结构包含逐层下采样的分窗特征编码模块、逐层上采样的双重注意力引导特征融合解码模块。提出跨层级级联特征传递模式,将早期编码阶段中具有更丰富局部细节的特征图逐级采样到每一个更低分辨率的目标等级。在目标等级将来自各编码阶段的重采样特征进行选择性融合和投影,使得初始低分辨率解码特征在上下文信息引导下渐进优化到原始分辨率,从而缓解细节信息在深层传递过程中的丢失,提高算法的深度估计精度。

图1 网络结构基本框图
1.1 特征编码模块
对输入的三通道特征图进行归一化后,将其划分为P个图像块XP,每个块的大小为C×B×B,其中B表示块的边长,C为通道数。将每个块XP按照其位置p转换成位置信息嵌入块ep,公式为
ep=LN[MLP(XP)+PosEmb(p)]
(1)
式(1)中:MLP(multilayer perceptron)为多层感知机;PosEmb为位置嵌入;LN为层归一化。以此获得了一个维度为P×d的嵌入矩阵E,其中d为嵌入维度。
为了充分提取各分块中的局部细节信息,将嵌入矩阵E传入多层堆叠的Swin Transformer模块中[20],每个模块的输出都是一个维度为P×d的矩阵。Swin Transformer的编码过程为
(2)
式(2)中:ST为Swin Transformer块;L为编码器的深度。最终得到维度为P×d的潜在特征表示HL,将图像的全局信息编码为一个固定长度的向量。
采用预训练的large Swin Transformer模型作为编码器主干网络,并设置窗口大小为7。对于不同层级的隐层特征图,编码器的初始嵌入维度为192,深度为[2,2,18,2],注意力头数为[6,12,24,48],通道数为[192,384,768,1 536]。这些参数遵循了该模型在大规模图像分类预训练任务上的设置。
1.2 跨层级特征级联模块
传统编解码器交互方式往往只在同层特征之间进行信息传递,尽管深层低分辨率特征一定程度上携带了浅层高分辨率特征,却未能充分利用其丰富的信息。因此,设计了一种新的编解码器信息传递策略。设编码器和解码器都有L层,分别为E1,E2,…,EL和D1,D2,…,DL,其中特征图分辨率随层数递减。传统连接是从编码器的第i层到解码器的第i层,如Ei~Di。提出的跨层特征级联模块在编码器第i层同时连接到解码器的第i~L层,如Ei到Di,Di+1,…,DL。具体来说,对于解码器的第i层,i∈[1,L-1],其特征图先与来自编码器的Ei连接,再与来自编码器的Ei+1,…,EL连接,即输入为:Di,Ei,Ei+1,…,EL,输出为
D′i=Wiconcat(Di,Ei,…,EL)+bi
(3)
式(3)中:D′i为第i层解码器输出;Wi和bi为可学习的参数。对于解码器的最后一层DL,其只与来自编码器的EL连接,即输入为DL、EL,输出为
D′L=WLconcat(DL,EL)+bL
(4)
1.3 双注意力引导解码模块
1.3.1 通道注意力机制
通道注意力机制是一种在深度学习中广泛应用的技术,旨在优化网络中特征的选择和利用。通道注意力机制的常见方法之一是全局平均池化,通过该操作获取每个通道的全局特征响应作为对应的权重。然后使用一个多层感知机对每个通道进行权重调整,以加强重要通道的影响,同时抑制不重要通道的响应。
利用通道注意力机制以减少编码器大体量输出特征的冗余,并促使输出到解码器的特征具有更高效的嵌入表示。首先,在级联特征后使用通道注意力机制进行特征选择,并对加权后的特征图执行通道缩减,以此有效减少网络中的参数数量,提高模型的效率和性能。其次,在最底层编码器的特征传输到解码器作为输入特征时,使用通道注意力机制和通道重投影来增强最低分辨率特征的信息密度,为解码器输入一个高效的编码特征表示,从而提高了解码器的预测能力和精度。所采用的通道注意力实现机制为
CA(x)=σ{Wc2Relu[Wc1avgpool(x)]}
(5)
式(5)中:Wc1和Wc2为全连接网络的参数;σ为Sigmoid函数;avgpool为自适应平均池化操作;Relu为激活函数;x为输入张量;CA为通道注意力函数。
1.3.2 分支注意力机制
分支注意力机制可以让网络动态地调整不同分支特征的权重,从而提高网络的性能和泛化能力。其常见实现方法是通过将多个分支特征进行拼接,然后通过一系列的卷积和非线性激活操作,生成多个注意力图。这些注意力图将用于对不同分支的特征进行加权,以实现最终的特征融合。
利用分支注意力机制,对每一层的解码环节中的两类输入做加权融合,包括:来自通道选择和重投影后的级联编码器特征、来自上层解码器的特征或底层编码器输出特征,所采用的分支注意力实现方式描述如下。
attn=σ(Wb3h3+bb3)
(6)
h3=ReLU(Wb2h2+bb2)
(7)
h2=ReLU[Wb1concat(xdec,xenc)+bb1]
(8)
out=xdec⊙attn1+xenc⊙attn2
(9)
式中:attn为注意力计算结果;ReLU为激活函数;concat为维度拼接操作;xdec为来自上层解码器特征;xenc为来自编码器的特征;h2为第一层卷积的输出特征图;h3为第二层卷积的输出特征图;⊙为按位相乘;Wbi和bbi分别为第i层卷积的权重和偏置项;out为融合后特征。
1.3.3 解码器网络结构
通过上述双重注意力机制的引导,本文的解码器可在渐进将低分辨率特征图细化到高分辨率同时,使用通道注意力块来保留重要的特征信息,使用分支特征融合模块将来自浅层和深层的特征图进行合并,从而有效恢复细节信息。
在解码器初始部分,使用通道注意力块来选择输入特征图的重要信息,并使用1×1卷积块压缩通道的数量,以提高计算效率。然后,使用卷积层对输入特征图进行上采样,并使用3个层叠的特征融合模块将来自不同层级的特征图进行合并。在每个特征融合模块中,将来自浅层和深层的特征图在通道维度连接起来,并通过堆叠的卷积和归一化操作来学习不同特征之间的权重。在最后一层,使用上采样层将特征图恢复到原始分辨率,并生成最终的深度估计结果。解码器的主要网络结构如表1所示,从编码器底层输入的特征尺寸为36 pixel×36 pixel。

表1 解码器网络结构
1.4 损失函数设计
深度估计中最常用的损失函数为尺度不变深度损失[21],考虑了深度值的标度不变量和人类对深度感知的对数性质,通过在对数域对深度真值和预测值计算差值并对其均值和方差进行加权,可以有效均衡不同尺度的深度损失。其计算公式为
(10)
为了加强网络对局部深度边缘尤其是器械与组织之间的深度梯度的感知,分别对深度真值和预测值计算深度梯度图,并作为加权项计入最终损失,其计算公式为
(11)
式(11)中:∇表示梯度算子,由对离散图像差分实现。
最终损失函数通过上述二者的加权和得到,以同时优化网络在绝对深度估计精度、全局估计一致性以及深度边缘一致性的性能,计算公式为

(12)
2 多视角深度采集与融合
从真实的手术场景中采集深度信息非常困难,但从模拟手术场景中可以采集到相似的数据。提出了一种自动化的数据采集流程和迭代式点云配准方法,实现高效采集高精度的模拟深度数据。
2.1 数据采集
通过将结构光扫描仪安装在机械臂的末端可以实现灵活的运动和定位。数据采集前,使用手眼标定方法可以将运动的扫描仪自身坐标系转换到机器人远端TCP(tool center point)坐标系。从而可以进一步利用TCP相对于机械臂基座的实时位姿转换到基坐标系,获得较好的三维点云配准初始值,有效提高点云配准效率。具体而言,固定标定板于特定平面,操控机械臂携带扫描仪从多个不同方位捕获关键帧。每次扫描中同时记录机械臂TCP在其基坐标系下的位姿参数和标定板上关键角点在扫描仪坐标系下的坐标。将每组点对应信息转化为矩阵Mi,通过奇异值分解求解手眼标定矩阵Mhand-eye,实现扫描仪坐标系到机器人TCP坐标系的转换。
数据采集设置中,主要采用了撕囊镊、主切口刀、侧切口刀、超乳头及波恩钳作为手术器械,使用离体猪眼作为目标组织来模拟手术场景。
2.2 迭代式点云配准
通过机械臂将扫描仪定位到特定的空间位姿可实现对模拟手术场景获取三维点云,但受组织吸光、水膜镜面反射和结构光遮挡等因素影响,单个点云中存在不同程度信息缺失。采集多个姿态下的点云可以实现迭代互补融合,从而显著增加点云密集程度以获得稠密深度数据。其主要步骤如下。
设输入的9个点云分别为P1,P2,…,P9,对应的机械臂末端姿态分别为T1,T2,…,T9,手眼标定矩阵为Mhand-eye,成对配准停止准则为C,输出的点云为Pfused,对应姿态变换为Tfused,1,Tfused,2,…,Tfused,9。
步骤1将9个原始点云转换到机械臂TCP坐标系下,得到Ptcp,1,Ptcp,2,…,Ptcp,9。
Ptcp,i=Mhand-eyePi,i=1,2,…,9
(13)
步骤2根据TCP实时姿态获取姿态转换矩阵,将点云转换到机器人基坐标系下,得到Pbase,1,Pbase,2,…,Pbase,9。
Ttcp=Tk,k∈[1,9]
(14)
(15)
Pbase,i=TbasePtcp,i,i∈1,2,…,9
(16)
步骤3对每个点云进行统计滤波,得到Pfiltered,1,Pfiltered,2,…,Pfiltered,9。
步骤4使用ICP算法[22]对滤波后的点云进行配准,当满足停止准则C时停止,得到粗粒度姿态映射图Tcoarse为
Tcoarse=ICP(Pfiltered,1,…,Pfiltered,9,C)
(17)
步骤5基于参考点云Pbase,1进行全局姿态图优化,得到最终姿态映射图Tfinal为
Tfinal=GO(Pbase,1,…,Pbase,9,Tcoarse)
(18)
步骤6使用最终姿态映射图将每个点云转换到参考点云Pbase,1并融合,得到最终点云Pfused和最终姿态变换矩阵Tfused,i为
Pfused=Merge(Pbase,1,…,Pbase,9,Tfinal)
(19)
Tfused,i=TfinalTbase,i,i=1,2,…,9
(20)
式中:GO表示全局优化函数,采用图优化方法,将ICP算法配准结果表示为一个图结构,每个节点代表一个点云,每条边表示两个点云之间的变换关系。通过最小化图中节点之间的误差优化所有点云的变换关系,获得更精准的匹配结果。Merge表示聚合函数,将一组点云累加为单个稠密点云。
上述渐进点云配准融合的结果如图2所示,分别为单个点云可视化结果和2~9个点云融合可视化结果,色调越暖表示深度值越小,颜色越冷表示深度值越大,可观察到随着融入的不同位姿点云数目递增,点云中的空洞区域数量和表面积递减。以上结果充分说明所提出的策略可以较好地还原被采集场景的稠密空间结构。

t为点云融合轮次
2.3 点云后处理
2.3.1 深度投影
由于深度估计任务通常采用三通道彩色纹理图像作为输入,采用单通道深度图作为输出,需要将上述配准融合后的点云投影回图像坐标系以形成单通道深度真值数据。设点云在扫描仪坐标系下的表示为Pcam,需要投影回的深度图为D,相机内参矩阵为K,通过点云坐标转换投影回二维深度图的过程如下。
对每个点pi∈Pcam,计算其在深度图中的像素坐标(ui,vi)为
(21)
根据像素坐标(ui,vi),将深度图中对应像素点的值赋为该点的深度值zi,从而获得投影后深度图。
D(ui,vi)=zi
(22)
图3展示了多视角点云迭代配准过程中是否对点云进行统计滤波的深度投影结果对比。由此可见,主要受空气中灰尘对结构光漫反射影响,原点云数据在各个区域存在部分深度值较小的微小噪音。而上述滤波过程能够有效滤除分布在各深度区间的噪音,获得更平滑且符合实际目标的深度分布,有利于提升逐对配准效率。
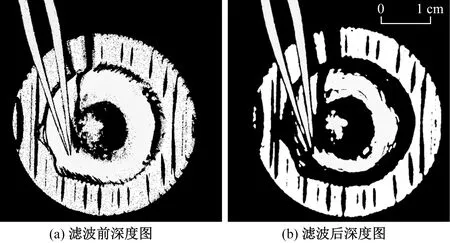
图3 是否进行点云统计滤波处理的深度图对比
2.3.2 感兴趣区域提取
在采集到的场景深度中包含器械长柄、器械夹持器等无关深度数据。定义感兴趣区域(region of interest,ROI)为眼球组织及组织上方的器械末端,因此深度图中的组织支撑台区域近似为ROI的内切圆。对该区域点云进行圆台平面上、下局部区域的深度截断,从而使得该区域的最大轮廓为圆台外边缘。针对不同视角采集的深度图执行圆检测,并沿其外接正方形进行图像截取。分别对原始灰度纹理图像和深度图提取ROI的部分结果如图4所示,其中,为了更好地展现深度差异,将空洞区域赋值为场景中最大深度,并对深度图进行了可视化增强处理,色调越暖表示深度值越大。

图4 9位姿下深度图及纹理图ROI可视化结果
3 实验
3.1 数据集
深度数据集包括1 500对576×576像素的纹理图和深度图对,其中采集深度有效精度为35 μm,深度图保存精度约10 μm。由于原始采集纹理为灰度图,通过直方图均衡化方法对暗处增强后进行上色处理,以适应网络输入。选择其中1 100对作为训练集,其余作为测试集。
3.2 实验环境与参数设置
所有的训练和验证都在NVIDIA TITAN Xp显卡上运行,CUDA版本为10.2。使用Pytorch实现上述网络,并利用Adam作为优化器。λ、w1、w2值分别设置为0.75、1和2。最大深度设定为0.070 55,最小深度为1×10-1。通过针对数据集的微调,将本文方法与主流深度估计基准中的算法进行了对比。
3.3 评价指标
为了同时评价不同网络在上述数据中的深度估计性能,引入3种主要的评价指标:RMSE、log10和SILog。RMSE表示实际深度值和预测深度值之间的均方根误差,SILog和log10是针对深度值的比例误差进行评估的指标。SILog在一定程度上对小深度值的误差更加敏感。RMSE的公式为
(24)
log10的公式为
(25)
SILog的公式为
(26)
3.4 定量对比结果
基于在创建的数据集上的实验结果,对不同方法的性能进行了评估和比较。其中,各评价指标定量对比结果如表2所示,在RMSE、log10、SILog等指标下,本文提出的方法表现出了优秀的性能,相较于Lap、GLP、Bts以及NeWCRFs等主流深度估计方法,均具有更小的误差和更高的精确性。

表2 本文方法与主流方法评价指标对比
在RMSE指标下,本文提出的方法相较于Lap、GLP、Bts、NeWCRFs等方法的改进比率分别为22.2%、7.4%、30.7%、42.8%;在log10指标下,相应的改进比率33.7%、31.4%、42.0%、53.2%;在SILog指标下,相应的改进比率13.0%、9.4%、17.1%、6.1%。这些实验结果表明,本文方法在对该场景进行全局深度推理时比其他方法更加准确可靠,在绝对精度方面领先。
3.5 定性对比结果
对不同方法推理的深度图进行定性比较的结果如图5所示,像素颜色越暖代表深度值越小。本文方法对于器械位于眼外的部分能够更加显著地区分器械和周围组织的边界,尤其对于小型器械如撕囊镊或波恩钳表现出更为出色的性能,如图5中撕囊镊位于眼外部分的两个分支间的间隙更为清晰。
对于器械在眼内的部分,如图5中白框所标注,本文方法能够更精准地识别器械尖端的深度信息,而其他方法中则存在深度信息模糊或器械部分被过度放大的情况,这在实际应用中可能导致对危险操作的预计失效。本文方法在眼内外器械深度估计中均表现出优越的性能,具有更好的临床应用前景。
3.6 消融实验
为了探究模型不同组件对性能的影响,进行了分别去除通道注意力和分支注意力组件的实验,并与完整模型进行了性能比较。实验结果如表3所示。

表3 是否采用关键注意力机制的消融实验结果
在RMSE评价指标上,无通道注意力和无分支注意力组件的模型相对于完整模型均出现了性能下降,RMSE分别为0.001 66和0.001 72,而完整模型的RMSE为0.001 51。在log10评价指标上,无分支注意力组件的模型相对于完整模型的表现下降最为明显,log10分别为0.009 79和0.008 33,而无通道注意力组件的模型相对表现稍好,log10为0.009 24。可以看出,在log10评价指标上,通道注意力和分支注意力组件对模型的性能提升也非常重要。在SILog评价指标上,虽然无通道注意力和无分支注意力组件的模型相对完整模型的表现都有所下降,但差距相对较小,SILog分别为0.031 55和0.032 07,而完整模型的SILog为0.030 39。因此,本文采用的通道注意力和分支注意力组件对模型性能起到了较好的提升作用,在不同评价指标上表现略有差异。
4 结论
设计并实现了一种基于双注意力引导特征级联的深度估计网络,并提出了一种多视角点云迭代式配准方法。在构建的数据集上的实验结果表明,通过与主流算法对比,本文方法更为准确地恢复了显微手术影像中的三维结构,并在全局推理精确性上有较大提升。该方法在推理时不依赖于昂贵的深度采集装置和精密的双目成像设备,可与现有的影像系统高效集成,端到端地进行深度估计,为医生提供术中导航信息支撑。尤其是在关键的微小器械深度估计方面,解决了局部深度模糊、细节丢失问题,有望为难以人为察觉的危险操作提供预警机制。
然而,本文研究只涵盖了器械末端全部处于透明角膜组织下且纹理清晰可见的场景,但在临床实践中,手术器械对于非浅表组织的误伤也多见于器械被不透明结构如虹膜或晶体皮质等遮挡导致视觉特征模糊的情形下,仅凭借点对点的像素到深度估计将难以有效识别器械末端深度。在未来的工作中,将进一步对眼内被组织遮挡的器械的深度估计问题进行研究。
