改进爬行动物搜索算法优化ENN模型预测管道腐蚀速率
2023-11-23卢鹏飞王霄杨文博陈卓秦国伟
卢鹏飞,王霄,杨文博,陈卓,秦国伟
(1.长庆工程设计有限公司,西安 710018; 2.中国石油长庆油田分公司第一采气厂,榆林 718500;3.西安石油大学石油工程学院,西安 710065)
管道运输作为一种运输量大、经济可控的方式被广泛应用于现代工业。随着管道“老龄化”程度加深,因腐蚀引起的管道失效造成的经济损失以及人员伤亡事故频发[1]。因此,及时掌握管道的腐蚀情况并在管道失效前对存在的安全隐患进行排除,是确保管道安全运行的关键内容[2-3]。目前关于管道腐蚀的研究有很多,其中管道腐蚀速率的预测一直是研究的重点。
迄今为止,中外学者对管道腐蚀情况预测方法进行了大量的研究。主要可归纳为概率统计法、可靠度函数分析法、灰色系统理论预测法、机器学习预测法等[4]。其中在管道腐蚀速率的预测研究中,机器学习预测法发挥了重要的作用。机器学习预测法在对大量实验数据进行学习的基础上,通过建立相关模型来预测未知数据,其不需要探究影响管道腐蚀速率的具体机理,目前已广泛应用于管道腐蚀速率的预测中[4]。张新生等[4]为更精确地预测海洋管道外腐蚀速率,建立了基于因子分析(factor analysis,FA)和天牛须搜索算法(beetle antennae searc,BAS)的极限学习机(extreme learning machine,ELM)腐蚀速率预测模型。骆正山等[5]通过对管道内腐蚀机理及影响因素进行分析,提出了基于主成分分析法(principal component analysis,PCA) 和改进甲虫天牛须算法(improve beetle antennae search,IBAS)的极限学习机(extreme learning machine,ELM)预测模型。赵清娜等[6]建立了支持向量机(support vector machine,SVM)和反向误差传播(back propagation,BP)神经网络模型对管道腐蚀速率进行预测,对比发现SVM具有更高的预测精度。夏俏健等[7]引进主成分法分析(principal component analysis,PCA)各因素与腐蚀速率的关系,建立了PCA-SVM管道腐蚀速率模型。Zhang等[8]引入粒子群算法(particle swarm optimization,PSO)对SVM模型的参数进行优化,建立了PSO-SVM管道腐蚀预测模型。Sobhan等[9]引入乌鸦搜索算法(crow search algorithm,CSA)对最小二乘支持向量机(least squares support vector machine,LSSVM)的惩罚参数和核参数进行寻优处理,构建了CSA-LSSVM管道腐蚀速率模型。Liang等[10]引入遗传算法(genetic algorithm,GA)优化BP神经网络的权重与阈值,构建了GA-BPNN腐蚀速率模型。上述学者所提出的模型方法都具有独特的优势,但受限于优化算法和神经网络自身局限性,可能导致针对多因素、高维度问题无法实现对管道腐蚀速率的精确预测。
在神经网络预测中,Elman神经网络是较为常用的一种,其具有实时反馈、短期记忆的功能(在传统三层网络结构的基础上增加了关联层)[11]。与BP神经网络相比,Elman神经网络虽在网络稳定性和计算精度上更优,但也存在一定缺陷(泛化能力不足、易陷入极小值)[12],如何通过相关优化算法对其进行改进仍是目前研究的一个重要内容。爬行动物搜索算法(reptile search algorithm,RSA)是种新型元启发式算法,其具有求解精度高、运算速度快的优点[13]。爬行动物搜索算法在应用过程中,其存在的一个难题就是如何取得全局与局部搜索之间的最佳平衡。事实上,这也是该算法存在的一个不足。
考虑到爬行动物搜索算法的优势以及目前研究的不足,现引入圆形混沌映射(circle chaotic map)并结合鲸鱼优化算法(whale optimization algorithm,WOA)的狩猎策略,提出一种改进爬行动物搜索算法(improved reptile search algorithm,IRSA),构建了IRSA-ENN模型并通过实例验证所建新模型的有效性,研究结果对于管道腐蚀速率的准确预测具有重要的指导意义。
1 基于改进爬行动物搜索算法的优化ENN模型构建
1.1 ENN模型构建
Elman神经网络是典型的局部回归网络,其在传统三层结构(输入层、隐含层、输出层)的基础上增加了承接层,通过将上一时刻的隐层状态连同当前的网络输入一同作为隐层输入,因此具有记忆的特性。
文中隐含层的传递函数采用Sigmoid函数,ENN的非线性状态空间表述为
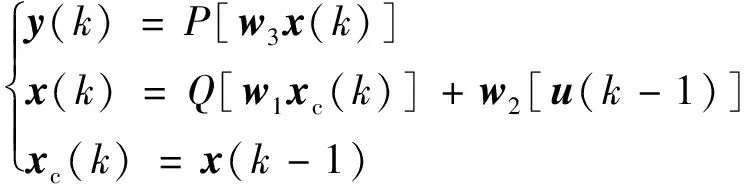
(1)
式(1)中:k为时刻;y(k)为输出节点单元的输出;x(k)为中间层的输出;xc(k)为承接层的输出;u为输入层单元向量;w1、w2、w3分别为承接层与隐含层的连接权矩阵、输入层与隐含层的连接权矩阵、输出层与隐含层的连接权矩阵;P为输出神经元的传递函数;Q为中间层神经元的传递函数。
1.2 爬行动物搜索算法原理
爬行动物搜索算法是由Abualigah等[13]提出的元启发式算法,其是一种通过对自然界中鳄鱼的社会行为、包围猎物机制和狩猎机制的研究而建立的基于种群且无梯度的算法。文献[13-14]已给出爬行动物搜索算法的详细原理。爬行动物搜索算法寻优过程,主要分为2个阶段:探索阶段和开发阶段,表述如下。
(1)探索阶段(环绕)。爬行动物在包围猎物时,有两种行走方式,即高位行走和低位匍匐行走,其数学表达式为
Xi,j(t+1)=

(2)
式(2)中:Xi,j(t+1)为第i结果上位于阶段j位置获得的当前解;Bestj(t)为该阶段j位置上获得的最优解;t为当前的迭代步数;T为最大的迭代步数;Ci,j为第i结果上的第j位置上的狩猎运算符;β为修正参数,控制该阶段中高走约束条件下解的精度;Ri,j为Reduce函数,主要作用是缩小搜索范围;r1为[1,N]的随机数,N为候选解的数量;xr1,j为第i个解的随机位置;ES(t)为进化比,是迭代过程中介于[-2,2]随机递减的概率比;rand为[0,1]的随机数。
(2)开发阶段(狩猎)。爬行动物在狩猎阶段,有两种社会行为,即协调与合作,其数学表达式为
Xi,j(t+1)=
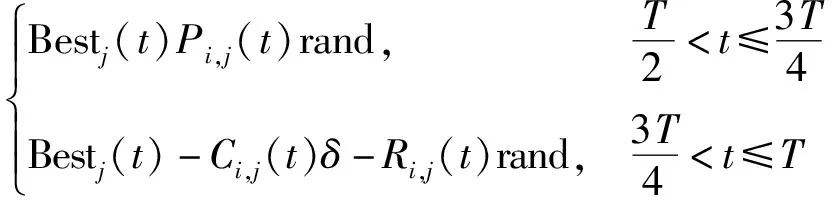
(3)
式(3)中:Pi,j为第j位置上的最优解的与当前解之差的百分比;δ为一个小值。
1.3 改进爬行动物搜索算法的基本思路
爬行动物搜索算法作为新的群体智能优化算法,其和传统的优化算法都存在共同的缺陷,即:无法在局部和全局搜索之间获得最佳平衡,尤其是当其应用于高维数据集中的特征选择时[14]。全局搜索与局部搜索不平衡则会导致收敛缓慢并很快陷入局部最优问题。因此,本文提出改进爬行动物搜索算法,主要从两方面着手,第一方面是将圆形混沌映射应用于初始解来增强算法的种群多样性;第二方面是通过引入鲸鱼优化算法中的狩猎策略对爬行动物搜索算法的原始狩猎策略进行改进。
具体来说,改进爬行动物搜索算法是利用圆形混沌映射增强种群多样性和借鉴鲸鱼优化算法的优势改进爬行动物搜索算法的一种耦合算法。在IRSA中,圆形混沌映射被用作丰富RSA的种群探索空间范围的能力;WOA的狩猎策略被用作RSA的局部搜索从而提高其解决不同优化问题的能力,两者增加了IRSA探索和利用搜索空间的能力和灵活性。
1.3.1 圆形混沌映射的引入
混沌映射是用于解决优化算法中种群多样性问题和低收敛速度的有效方法。使用圆形混沌映射来初始化种群位置,可以有效提高算法的求解性能[14]。此外,引进圆形混沌映射可进一步扩展搜索空间(与原始随机搜索方法相比),其表达式为
CircleChaosMap=xn+1=xn+b-
CircleChaosMap∈(0,1)
(4)
式(4)中:xn为混沌序列的第n个混沌数;b和a为控制变量,b取0.2,a取0.5;CircleChaosMap的值用来更新改进爬行动物搜索算法中随机粒子初始位置;mod为取余函数。
1.3.2 鲸鱼优化算法狩猎策略的引入
鲸鱼优化算法主要是模仿座头鲸捕猎时的生物学行为。分为两种策略:包围策略和狩猎策略。改进爬行动物搜索算法主要引入鲸鱼优化算法的狩猎策略,利用螺旋修正位置机制来修正Bestj(t)和Xi,j(t+1) 之间的距离,计算公式为
Xi,j(t+1)=Dis′eblcos(2πl)+Bestj(t)
(5)
式(5)中:l为对数螺旋形状的值,为[-1,1]的随机数;Dis′为当前搜索个体到当前最优解之间的距离;b为定义螺旋线的形状参数;Bestj(t)为该阶段j位置上获得的最优解。
2 基于改进爬行动物搜索算法优化ENN模型的建模过程
2.1 IRSA-ENN模型构建
将改进爬行动物搜索算法应用到优化传统ENN模型的初始权值和阈值,从而构造出IRSA-ENN模型。通过这种方法构造的改进ENN模型能克服传统ENN模型预测精度低、泛化能力不足等问题,模型建立步骤如下。
(1)在对管道腐蚀速率实验数据进行归一化处理的基础上,对传统ENN模型进行初始化,确定输入层、隐含层、输出层的层数。并引入爬行动物搜索算法,对初始参数进行设置(包括种群数量、迭代次数、问题维度等)。
(2)引入圆形混沌映射[式(4)],初始化爬行动物种群序列和丰富爬行动物探索空间。并对构造的适应度函数(训练样本的均方误差)进行计算,用以衡量整体寻优过程中的最优解。
(3)利用鲸鱼优化算法的狩猎策略对爬行动物搜索算法进行改进,体现为采用鲸鱼优化算法的狩猎策略[式(5)]来替换爬行动物搜索算法的狩猎策略[式(3)]。并时刻更新迭代各爬行动物位置,进一步寻找各爬行动物的全局最优位置。
(4)通过每次迭代寻找的各爬行动物全局最优位置对适应度函数进行更新计算。达到终止条件时,终止计算,否则继续步骤(3)。
(5)将获取的最优爬行动物位置赋值给传统ENN模型,通过重新训练学习后,进而构造出改进的ENN模型,并输出最优的预测解,流程如图1所示。
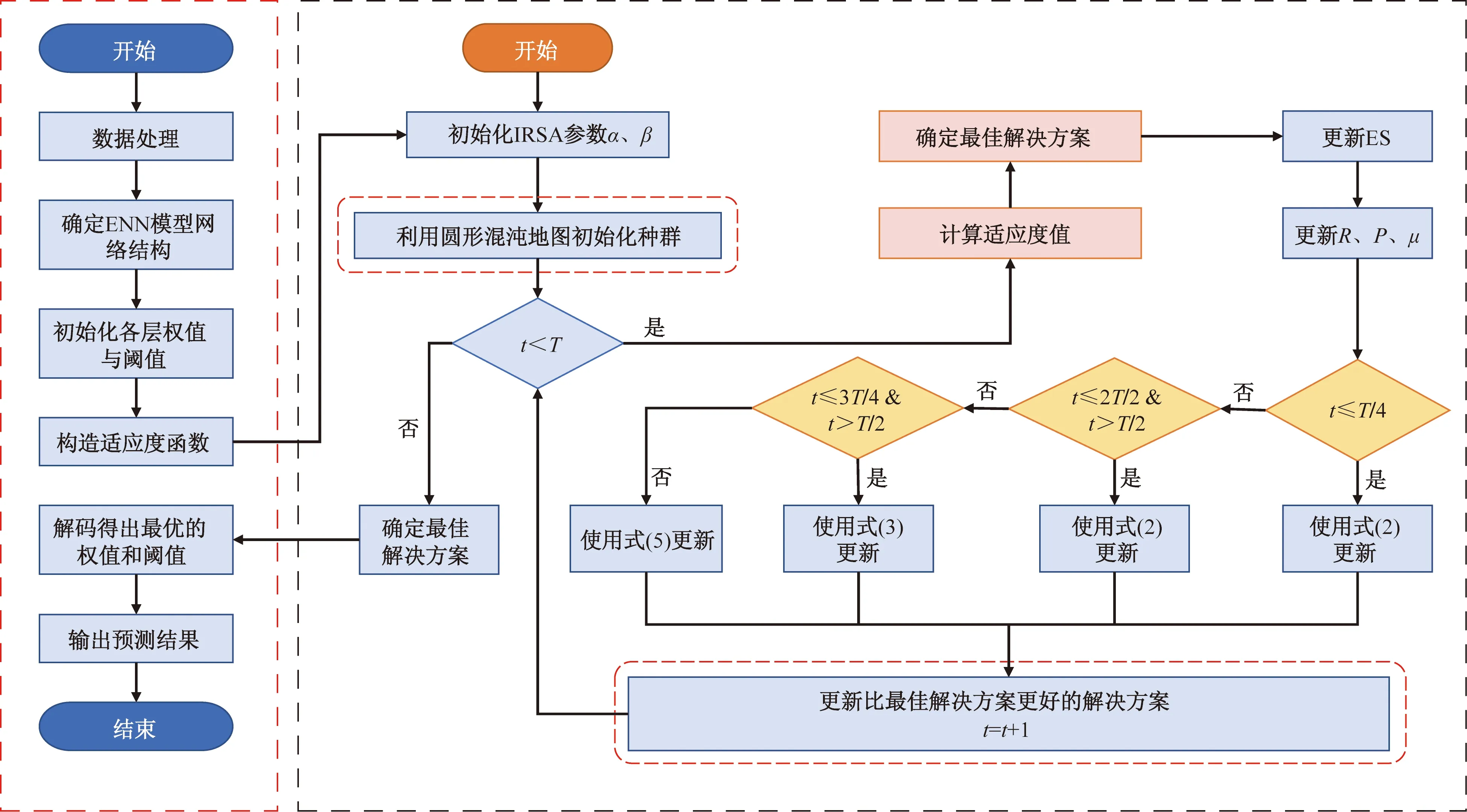
图1 IRSA-ENN模型建模流程
2.2 模型验证指标
引进3个评价参数对模型的预测精度进行评估,均方根误差(root mean square error,RMSE)、平均绝对百分比误差(mean absolute percentage error,MAPE),两者数值越小则证明模型预测精度越高。相关系数R2越接近于1,则证明预测数据与实际数据越接近。其三者计算公式为
(6)
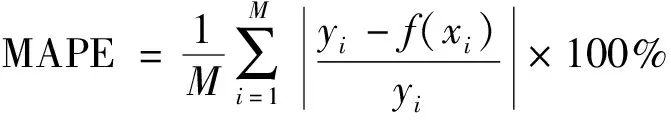
(7)
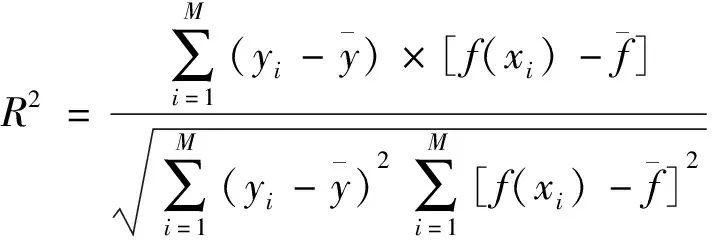
(8)
3 基于实测数据的改进新模型预测精度分析
3.1 数据选取与预处理
以文献[15-16]中给出的两组不同环境因素下的管道腐蚀速率实验数据为例(分别对应实例一、实例二),用以验证改进模型的泛化性能(对不同实验样本的学习能力),并对比分析所建IRSA-ENN模型和其他模型的预测精度。文献[15-16]中给出的腐蚀速率实验数据均为20组,分别随机选取其中的15组数据作为训练样本建立模型,采用剩余的5组数据(预测样本)来对比分析各模型的预测精度。具体的管道腐蚀速率实验数据分别如表1和表2所示。

表2 管道腐蚀速率实验数据[16](实例二)
在对训练样本进行学习时,由于变量间的量纲不同,需要使用mapminmax函数对数据进行归一化处理,即把各变量转化为[0,1]的数。
3.2 仿真结果对比分析
使用MATLAB软件自主编程实现仿真过程,其中电脑端参数如表3所示。

表3 电脑软硬件参数
传统ENN模型在对实例一、实例二训练样本进行机器学习时,以训练样本的均方误差最小为衡量标准,确定最佳隐含层节点数。其中传统ENN模型学习设定参数如表4所示。
传统ENN模型针对实例一、实例二管道腐蚀速率实验数据确定隐含层节点数H时,经验公式为

(9)
式(9)中:m为输入层节点个数;n为输出层节点个数;a取1~10的整数。
基于实例一、实例二不同隐藏层节点数求解的训练样本均方误差结果,如表5和表6所示。

表5 不同隐含层节点数计算训练样本的均方误差(实例一)

表6 不同隐含层节点数计算训练样本的均方误差(实例二)
由表5可见,当隐藏层节点数为9时,对应的训练样本均方误差最小(实例一),故实例一仿真试验确定构建10-9-1三层ENN模型。同样由表6可见,当隐藏层节点数为10时,对应的训练样本均方误差最小(实例二),故实例二仿真试验确定构建7-10-1三层ENN模型。
为了验证和评估IRSA-ENN模型的预测精度,建立了ENN、WOA-ENN、RSA-ENN模型与其对比。为了便于分析,保持上述模型种群规模为30,迭代次数50次,其中WOA-ENN模型初始化常量取a=[0,2],b=1,l=[-1,1];RSA-ENN、IRSA-ENN模型初始化常量取α=0.1,β=0.005。各模型基于实例一在训练过程中的均方误差迭代曲线,如图2所示。

图2 基于不同算法耦合ENN模型的训练迭代过程(实例一)
图2通过各模型在训练过程中均方误差求解迭代结果对比,可明显看出,IRSA较RSA和WOA具有更高的求精精度。
仿真求解结束后,得到各模型腐蚀速率的预测结果并计算相对误差,结果分别如表7~表9、图3和图4。
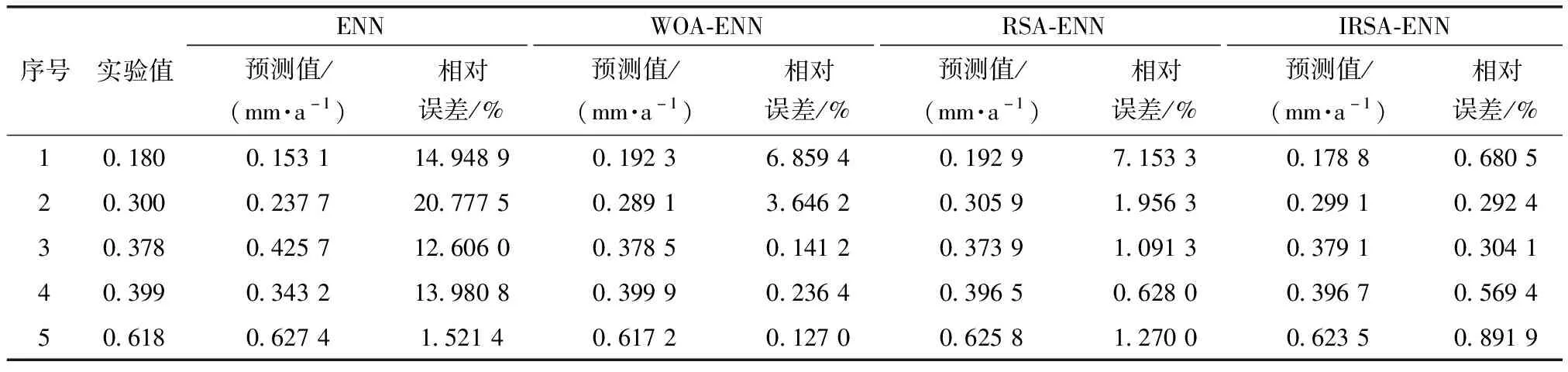
表7 不同模型的预测结果及相对误差(实例一)

表8 不同模型的预测结果及相对误差(实例二)

表9 不同模型预测精度对比
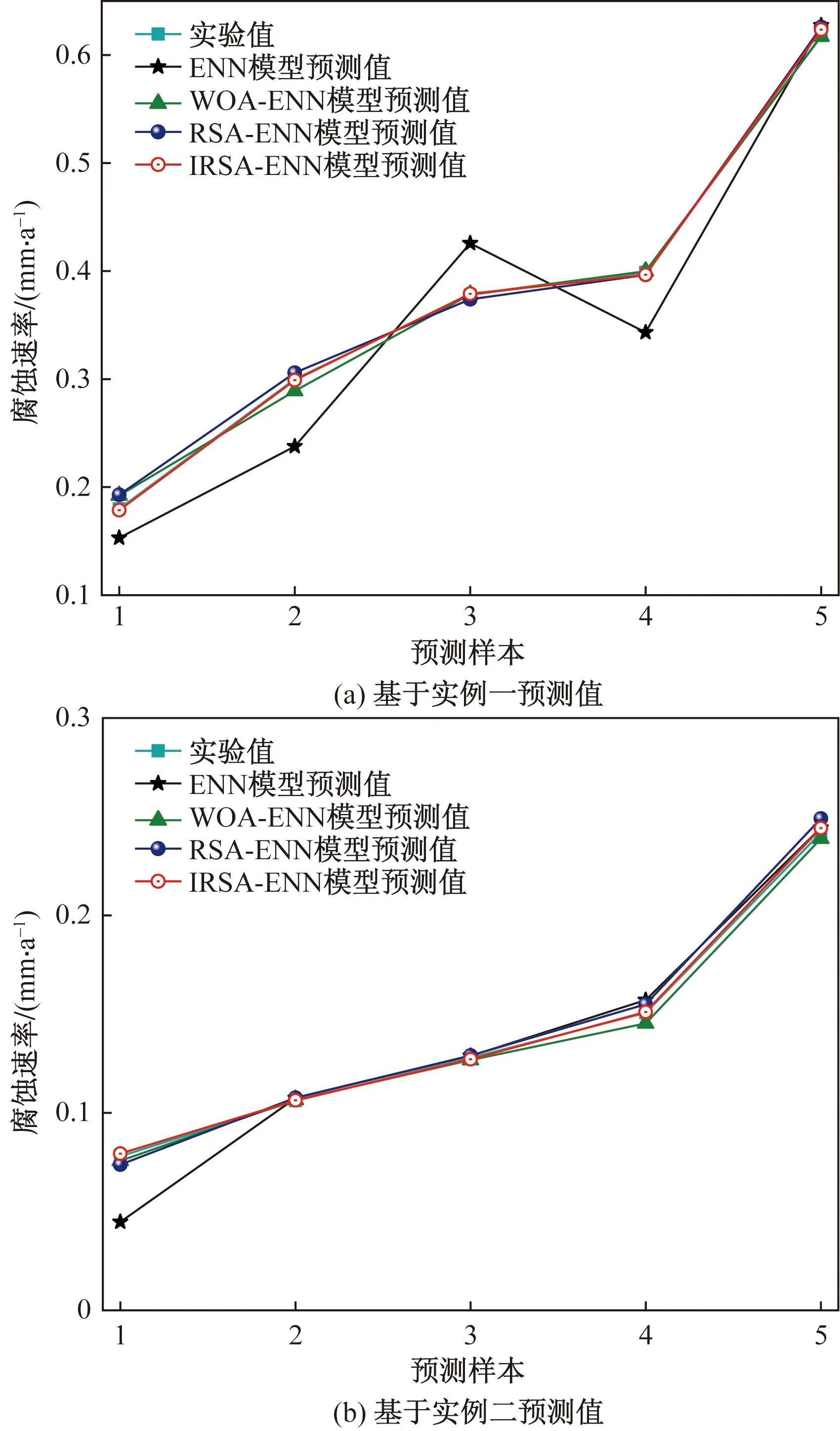
图3 不同模型预测值结果对比
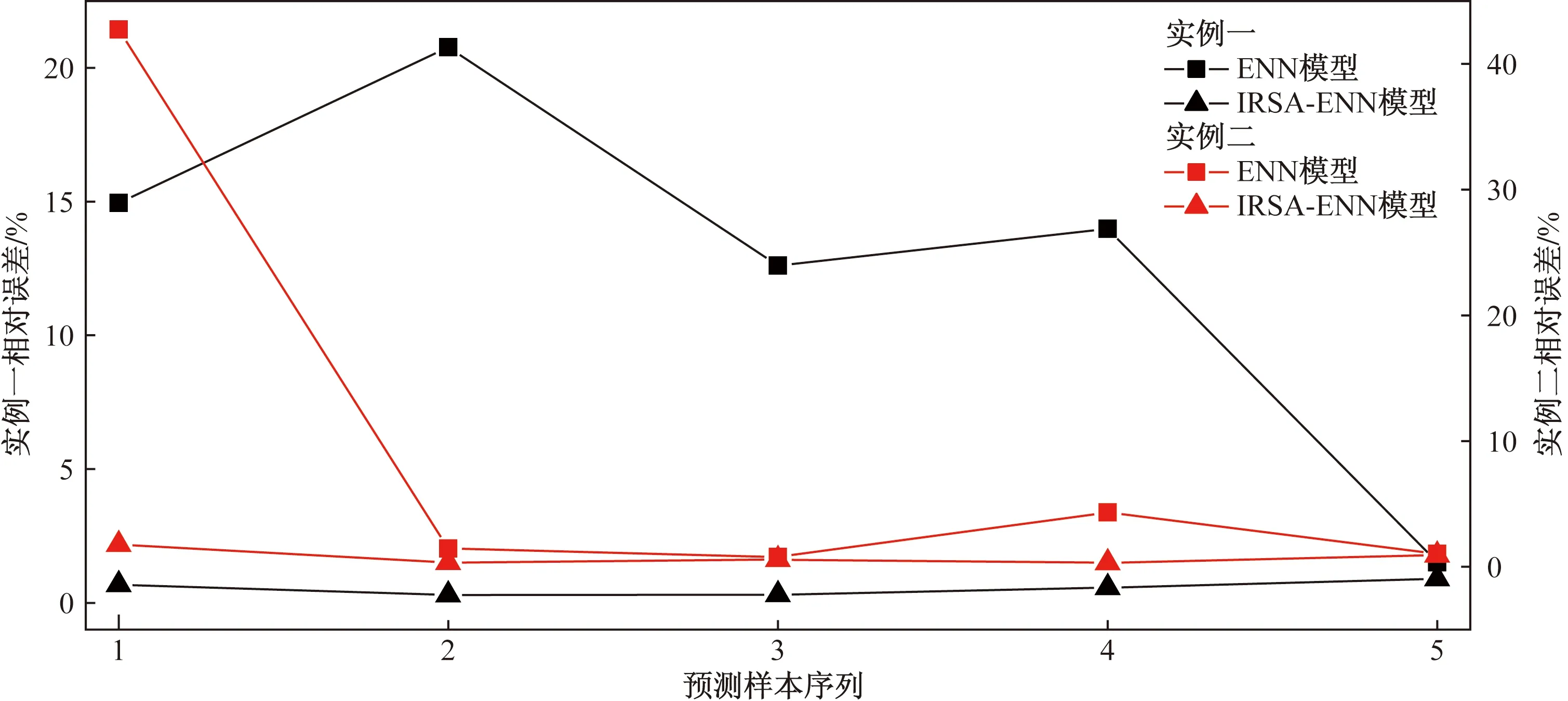
图4 IRSA-ENN与ENN模型预测误差对比
从表7~表9、图3及图4可见,对于实例一预测结果而言,ENN模型的MAPE为12.766 9%,相关系数R2为0.944 98;WOA-ENN模型的MAPE为2.202 1%,相关系数R2为0.997 59;RSA-ENN模型的MAPE为2.419 8%,相关系数R2为0.998 1;IRSA-ENN模型的MAPE为0.547 6%,相关系数为0.999 87。对于实例二预测结果而言,ENN模型的MAPE为10.062%,相关系数R2为0.966 62;WOA-ENN模型的MAPE为1.828 1%,相关系数R2为0.998 97;RSA-ENN模型的MAPE为2.716 8%,相关系数R2为0.999 28;IRSA-ENN模型的MAPE为0.7831 %,相关系数为0.999 76。
从两组不同实例预测结果来看,新建的IRSA-ENN模型预测精度最高,传统ENN模型的预测精度相对较低,WOA-ENN、RSA-ENN模型的预测精度均高于传统ENN模型,这也证明了所用改进模型的有效性。通过所建模型对两组不同管道腐蚀速率实验数据的学习预测,可以明显看出传统ENN模型泛化能力不强(基于实例一、实例二两组管道腐蚀速率预测时,MAPE分别为12.766 9%、10.062 0%)。而改进的ENN模型在对不同样本进行学习预测时,具有较强的泛化能力(对不同实验样本的管道腐蚀速率预测时,精度较高)。其原因是:传统的ENN模型采用基于梯度下降法求解E(k)对权值的偏导数,因此存在容易陷入局部极小点的缺陷,对Elman神经网络的训练较难达到全局最优[17-19]。而使用改进算法可对传统ENN模型随机初始化的权值与阈值进行迭代寻优处理,最终获得最优的权值与阈值,因此能够大幅度提高传统模型的预测精度,且可以避免初始权值与阈值的随机性导致泛化能力不强的缺陷。
此外新建的IRSA-ENN模型较RSA-ENN模型预测精度也有所提升,这主要是因为:引入圆形混沌映射丰富了种群多样性,扩展了种群的搜索空间,可克服RSA在迭代寻优初期全局搜索能力不足的缺陷;同时新模型采用WOA的狩猎策略改进了RSA的狩猎策略,能够进一步提高RSA的局部搜索能力。综合来看,改进爬行动物搜索算法无论是全局搜索能力还是局部搜索能力都较爬行动物搜索算法有很大提升,故其预测精度较高。
从仿真结果可见,新建的IRSA-ENN模型同样较WOA-ENN模型预测精度有所提升,这主要是因为:IRSA将其狩猎策略分为两个阶段,既保留了WOA局部搜索能力强的优势,又在迭代后期很好地平衡了全局搜索与局部搜索之间的关系,能够克服原始WOA过早陷入局部最优解的缺陷,故其预测精度仍较高。
4 结论
(1)引入圆形混沌映射并结合鲸鱼优化算法的狩猎策略对爬行动物搜索算法进行改进,提出了一种基于改进爬行动物搜索算法的优化ENN模型并预测了管道的腐蚀速率。仿真结果表明,所建的优化ENN模型预测结果与实际值吻合很好,其用来预测管道的腐蚀速率完全可行。
(2)对比IRSA-ENN模型与其他模型的预测精度可知,IRSA-ENN模型的预测精度最高(两个实例的MAPE分别为0.547 6%、0.783 1%),其次是鲸鱼优化算法建立的改进ENN模型(两个实例的MAPE分别为2.202 1、1.828 1%)和传统爬行动物搜索算法建立的改进ENN模型(两个实例的MAPE分别为2.419 8%、2.716 8%),而传统ENN模型的精度较差(两个实例的MAPE分别为12.766 9%、10.062 0%)。
(3)新建的IRSA-ENN模型有效解决了传统ENN模型预测时泛化能力不足、易陷入极小值的缺陷,且克服了传统爬行动物搜索算法在迭代寻优初期全局搜索能力不足和迭代寻优后期易陷入局部最优解的缺陷,其为管道腐蚀速率的准确预测提供了一种新思路。
