通信诈骗预警模型设计研究
2023-11-22马云海
马云海
中国电信股份有限公司连云港分公司
0 引言
近年来通信诈骗日益泛滥,社会危害性越来越大。随着通信技术的发展,数据源种类越来越多,因此而产生的数据量呈现指数级增加,这也进一步加大了反诈工作中诈骗数据分析的难度。根据目前的通信诈骗现状,国内外学者进行了广泛的探索,传统的治理方式主要是结合已知诈骗号码情况对电话号码的结构分析,从而对疑似号码进行拦截。也有部分学者开始基于大数据挖掘技术分析诈骗违法行为号码,尝试提前预测诈骗行为,并取得了一定的进展。对于我国的运营商而言,传统的防诈技术很难满足他们要在很短时间内分析海量数据、识别诈骗号码,同时还要尽可能地减少对用户正常通信干扰的需求。本文提出的是一种基于大数据挖掘技术的通信反诈分析模型。该技术能够实现对通话情况提取疑似号码的话务特征,利用大数据分析挖掘模型快速研判和处置并进行有效分析,从而在较短时间内实现诈骗号码的确认并进行拦截,最终有效防止通信诈骗的发生。从某种意义上来讲,该模型填补了现有电信拦截技术的短板,为以后有效防范通信诈骗提供了新的思路。
1 相关理论与技术
1.1 传统分类模型
从判断通信诈骗的方法上,决策树模型和朴素贝叶斯模型这两类传统的分类模型有着较为广泛的使用,但是传统模型的使用前提是要有独立属性的假定样本,这和实际情况严重脱节,所以通过这些模型得出的结论较难复制到实际生产中。新出现的支持向量机(SVM:Support Vector Machine)是一种常见的监督核学习(kernel learning)方法,SVM 可以在使用较少的抽样数据的情况下,通过非线性分类方法将经验风险降到最低,并且能归纳出较好的统计规律。能够避开高维度空间是SVM 方法的一个最大的优点,借助空间内核函数可以将线性不可分的情况进一步转化成线性可分问题,然后再通过对线性可分问题的解决方案,解决相应的高维空间难题。使用SVM 对潜在的通讯诈骗号码进行检测,如果选取的号码话务特征仅包含呼叫次数和呼叫时长,那么就很难全面的提炼出疑似诈骗号码的特征。如果相关的测试验证不结合实际数据,就算能够取得很高的命中率也只是针对于测试数据,很难进行实际应用。
1.2 熵值法
(1)算法简介
熵值法是一种客观赋权法。其根据各项指标观测值所提供的信息大小来确定指标权重。在信息论中,熵和不确定性是一个正比关系,与信息量成反比。熵值可以用来判断某个指标的离散程度,离散程度越大,那么它对结果的影响也越大。因此,信息熵可以在建模中用来为多指标计算权重,选择出那些对判定影响大的变量。
(2)熵值法的优缺点
熵值法是一种客观的赋权法,是根据各种指标的指标值变化程度来确定相关指标的权数,它可以避免人为因素带来的主观偏差,但是这种方式忽略了指标本身的重要程度,而且熵值法也不能减少评价指标的维度数。
2 通信诈骗预警建模需求分析
2.1 本地网防诈现状
本地网诈骗拦截工作起始于2017 年,当时公安部下发的重点监控区域有9 个地市,要求重点监控漫游到以上地区的用户呼叫情况。但是通信诈骗的势头并没有被遏制住,反而愈演愈烈。因此国家十三部委联合下文整治诈骗号码,并在全国开展“断卡行动”。根据连云港市反诈中心每月通报,连云港市涉诈号码数量在全国排名较高,曾排名全国前20,被发黄牌。中国电信连云港分公司成立专班开展通信诈骗的防范工作。
2.2 预警诈骗号码难点分析
目前通信诈骗传统的治理方法,主要是结合投诉数据对用户号码的结构进行简单分析,通过这种方法来确定是否是诈骗号码,纳入灰名单数据库,从而实现对疑似号码进行呼叫拦截。但是随着诈骗分子不断升级更新相关诈骗手段,通过对现有的案例进行统计分析发现,目前的反诈工作存在以下几个难点:(1)涉诈号码均符合实名制管控的相关规范要求,日常稽核较难发现;(2)号卡涉及买卖和非法收购;(3)通信诈骗具有跨区域性、隐蔽性、判定滞后性的特点;(4)诈骗号码的使用行为不断升级更新。
为了及时打击涉诈犯罪分子,减少群众财产损失,同时降低连云港手机号码被举报率,公司专班提出主动追踪挖掘诈骗号码的需求和设想:精准定位疑似号码,及时封停高危号码,便捷复机申诉通道,消除潜在高危号卡。
3 通信诈骗预警系统总体架构
3.1 整体系统技术架构
通信诈骗预警系统主要包含诈骗号码识别、号码封停、申述复机,沉默卡号处理和白名单等几个模块。系统根据话单数据中主叫异常特征及呼叫频率来预判诈骗号码,通过话务相似特征来辨别是否实施了通信诈骗,使用大数据挖掘技术对号码的历史通话记录,办理的套餐和装机时间等资料进行分析研判。目前反诈预警模型使用的主要是话务数据中的几个变量,根据这几个变量运用大数据筛选,将异常号码标识为涉诈号码。在话单数据、EDA 数据中提取疑似诈骗号码的所有话务特征,根据熵值法和SVM 判断是否为诈骗号码。若判断为诈骗号码,则通过紧急停机流程进行风险单停,限制号码的呼叫功能,从而终止该号码的诈骗行为。同时对该号码同一身份证下的所有号码进行关联停机,并上报专班进行多维度分析,对同批办理的号码进行筛查,发现疑似号码进行相应处置。
3.2 诈骗号码的判定模型设计
3.2.1 现有诈骗卡号特征的大数据挖掘
在通信诈骗预警模型建立之前,首先从公安机关提供的涉案号码、用户投诉的诈骗号码以及反诈专班通报的数据中抽取样本,分析他们的通话行为、装机时间、受理渠道、套餐类型、年龄等特征,确定诈骗号码特征判定规则。根据分析发现:大部分诈骗电话的入网时间都较短;诈骗电话基本都是漫游到异地;受理渠道一般是网上渠道;每次通话的时间较短、拨打的时间比较集中,被叫话单少、主叫话单多。根据以上的特征进行建模,集中挖掘特定场景下的诈骗行为。
3.2.2 诈骗电话特征探索
采用熵值法,首先对选取的涉案用户数据的卡号信息、受理信息、当月通话情况、历史通话情况进行采集挖掘。采集数据如表1 所示。

表1 数据采集
建模变量需要选用区分能力强的变量,连续离散化可以显著提升变量的区分能力。将诈骗号码入网的时间、被叫区号离散度、主叫话单占比、被叫号码离散度等变量根据熵值法进行离散化的处理。然后对变量进行划分,选取其中总熵值最小的分裂点变量。
抽取12321 公安侦办下发的诈骗号码对主叫话单被叫号码离散度进行分析,如图1 所示,基本分布在80%到100%区间。

图1 被叫号码离散度
根据话务数据筛选,发现92%的诈骗用户是在入网一个月内就开始实施诈骗,并且此类用户很少接听电话,主叫话单占总话单数的90%以上,这些主叫话单的被叫号码均为长途号码,且重复情况极低,主叫话单中被叫号码的离散度大于85%。根据以往经验,将用户的主叫话单占比和被叫号码离散度这两个变量收入建模变量。根据对诈骗号码目标判定影响大小排序,最后选出被叫区号离散度字段对目标变量的判定有着较大影响,数据分析结论如表2 所示。
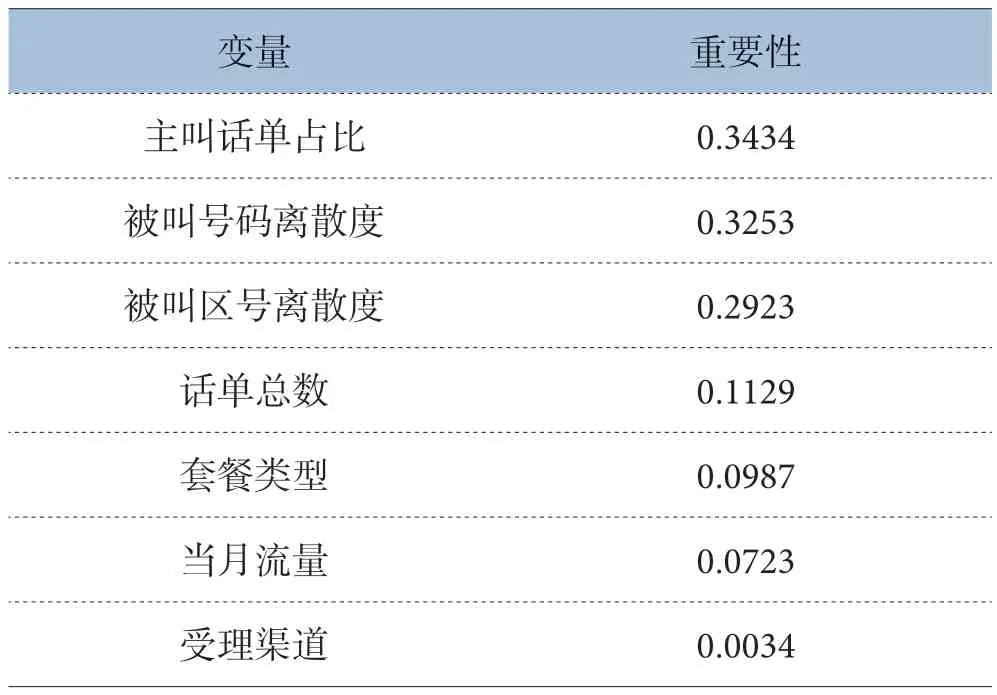
表2 数据分析结论
通过Python 筛选,主叫话单占比、长途话单数量、被叫号码离散度、被叫区号离散度、主叫拨打频次这几个变量对判定诈骗号码区分能力较为显著,可作为建模的变量来使用。
3.2.3 建立挖掘模型
在完成模型变量筛选后,开始选择建模的方法。通过比对朴素贝叶斯模型、决策树模型、随机森林算法和线性回归算法等方法,根据评估的效果,预警模型选择了支持向量机(SVM)这一算法。
根据以上对数据变量筛选以及话务特征的分析,根据SVM 建立了诈骗号码的匹配模型。如表3 所示,诈骗号码匹配模型为:异地的长途话单拨打频次每小时主叫大于等于9张,被叫号码离散度大于等于0.8,且不同被叫区号个数大于3 个,标记为高度疑似诈骗号码;漫游用户在3 个小时内主叫话单张数大于等于20 张,被叫号码离散度大于等于0.8,且被叫区号个数大于3 个,标记为高度疑似诈骗号码。剔除199 以上主卡、政企行客VPN、名称包含电信、后三位相同的吉祥号和携入用户等白名单用户。

表3 诈骗号码匹配规则
4 通信诈骗预警系统功能实现
(1)普通话务小时模型
在ORACLE 数据库中建立定时任务:LYG.MYH_ZP_XYH_2021_JOB 每30 分钟运行一次,扫描本地网的移动详单表,筛选出扫描时间点前一个小时的主叫话单张数大于等于9张的用户SERVID,同时给这些号码标识出被叫号码的离散度(不同被叫号码个数/主叫话单张数),标记为:小时话务量异常A 模型。
(2)基站话务模型
在ORACLE 数据库中建立定时任务:LYG.MYH_ZPJK_2021JZ_JOB 每天9 点运行一次,扫描本地网的移动详单表,筛选已被小时话务量异常A 模型标记出来的疑似诈骗号码与话务较为集中的基站ID 是否存在交集,如果存在交集那么可以判断为有GORP 设备用于诈骗活动,该设备危害性更大,需要及时反馈给省公司和公安反诈中心。
5 反诈模块运行情况分析
通信诈骗和骚扰数据分析及大数据拦截模型投入运行以后,优化预警范围和准确度,实时拦截疑似的诈骗号码,大大提升了处理的及时性和准确性。如图2 所示,反诈模型投入使用后诈骗号码迅速从2021 年4 月份的24 个降低到2021 年6 月份1 个,反诈效果明显。经过不断地优化,2022 年上半年更是保持0 个记录。同时通过运用该模型的大数据分析协助公安部门破获了多起通信诈骗案件,有效控制了连云港诈骗案发率,让连云港公司摆脱了被动局面,并使该项工作在全省名列前茅。

图2 公安侦办派单
6 结束语
通信诈骗预警系统设计研发时间紧任务重,可以借鉴的经验较少,在运行期间诈骗分子的诈骗手段还在不断地升级更新,所以还需要在应用中对公安部门下发的漏网诈骗号码进行进一步的分析,对模型逐步改进完善。
