基于动态基线和无监督异常检测技术的业务风险分析系统实践
2023-11-22叶枰
叶 枰
中国电信股份有限公司江苏分公司
0 引言
随着移动业务互联网化的发展,江苏电信建设了一大批面向互联网的应用系统:网上营业厅、掌上营业厅、微信公众号等,通过这些线上渠道系统,用户可足不出户,享受在线查询、充值、业务办理等便利,越来越多的交易正在从传统的线下渠道迁移到线上渠道。互联网的发展在提升用户体验的同时,也带来了网络安全风险,相关黑色产业链的兴起,不仅有可能造成业务层面的损失,也会对企业形象产生不良社会影响。此外,为应对网络安全风险,我国出台颁布了《数据安全法》《个人信息保护法》,对用户个人信息保护也提出了更高要求。
围绕上述风险和发展要求,江苏电信建设了Web 应用防火墙(WAF),基于静态特征码、行为特征和特定规则进行报文检测与过滤,实现对已知特定攻击的阻断,在一定程度上有效遏制了网络攻击行为,但在面对攻击者使用新工具、利用未知漏洞的攻击行为时,往往无法进行有效防护,因此需要在做好传统安全防护的基础上,探索出一条新的安全风险感知思路,及时发现、处置安全风险,降低风险影响。
本文实现的系统通过采集线上渠道数据,对用户访问行为、业务数据进行清洗和转换,结合业务场景建立业务风险模型,通过数据分析,构建各业务特征模型,有效识别绕过安全策略、非法为别人办理业务等恶意行为,并对这些欺诈或违规行为进行分析识别和告警。
1 技术概述
1.1 动态基线技术
基线技术主要与异常检测和异常告警结合使用,传统基线技术一般采用事先设定好的告警基线值,当异常检测结果达到基线值时即触发告警。基线值的设置至关重要,由业务特性决定。当监测指标较多,且业务特性复杂时,需要针对性地配置多个基线值,比如业务一天内高峰时间、低谷时间、正常时间的基线值不同,工作日和非工作日基线值不同,尤其是在业务发生重大变化后,需要对基线值重新进行设置。
动态基线技术中的基线值并不是事先设定的,而是通过动态计算出来的,核心思想是结合时间计算出各个时间区间的理想基线。计算的数据来自历史业务数据,在实际计算中一般需要对数据进行预处理,去除不合理数据,以减少数据异常对动态基线的影响,提高算法的稳定性。动态计算结果作为触发告警的依据,可以是一个具体的基线值,也可以是一个基线区间。在真实应用场景中,部分动态基线算法可采用插值法对数据进行填充以及降噪处理,提高数据的完整性。
动态基线技术能有效解决业务迭代速度快、基线值变动频繁、基线值维护工作量大等问题,尤其是在某些场景下能够基于历史经验给出未来一段时间内的预测结果,相较于传统基线技术更能准确、有效地发现业务风险并进行告警。
1.2 无监督异常检测技术
异常检测是一种识别不正常情况与挖掘非逻辑数据的技术,用来在数据集中发现显著不同于其他数据的对象,是数据挖掘中的一个重要组成部分,常用于金融、工业、通信等风控领域。
异常检测模型根据数据标签内容可大致分为有监督异常检测、半监督异常检测、无监督异常检测。当训练数据集中的数据都能打上正常和异常标签时,有监督异常检测模型能快速建立并作出预测。当训练数据集中的数据包含正常标签时,半监督异常检测模型也能适用。然而在实际应用中,训练数据集往往来自不含任何标签的历史业务数据,如果需要通过人工训练进行打标,必然产生大量的人工成本。因此,无监督异常检测技术更适用于正常业务数据和异常业务数据都存在但没有标签,同时正常业务数据远大于异常数据的情况。
无监督异常检测模型一般定义一个打分函数来表示一个数据对象的异常程度,按照数据对象的异常分排序,异常分高的数据对象往往作为异常。根据算法不同,无监督异常检测模型通常分为基于统计与概率的模型、基于距离的模型、基于密度的模型、基于线性的模型、基于树的模型和基于神经网络的模型。
2 业务风险分析系统实践
2.1 系统设计
本系统的技术架构主要分为展示层、分析层、系统层等三层结构,核心分析层主要分为离线分析及终端检测模块,如图1 所示。
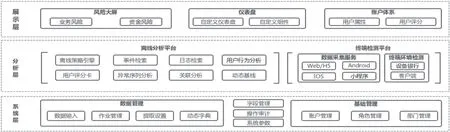
图1 系统技术架构设计
系统层实现各类安全数据的采集、处理、汇聚、存储、检索能力,以接口形式向安全威胁分析与预警分析提供输入数据。系统层通过主动或被动方式采集相关系统及应用数据源,主要包括登录日志、订单日志、接口调用日志以及业务办理日志等。针对采集数据格式的不一致、数据输入错误、数据不完整等情况,系统层对数据进行转换和加工,如字段映射、数据过滤、数据清洗、静态补齐等过程,将输出的数据进行存储。
分析层提供平台分析方法与分析能力,其中分析方法采用了分析引擎、分析场景、分析输出的分别定义,建立威胁分析检测模型、预测分析模型等,依据不同安全场景需求采用离线分析、汇总统计、机器学习等方法进行数据分析的驱动。
展示层将分析、处理、整合的数据根据不同业务场景需求进行可视化的呈现、风险的概览、用户行为的分析、事件管理呈现,同时提供原始日志与标准化日志的智能搜索功能以及系统管理入口。
2.2 数据管理模块设计
数据管理模块是系统实现的核心,主要包含数据采集、数据清洗和标准化、数据存储。
采集模块原则上以主动采集为主,被动收集为辅,通过Flume 组件采集用户各类操作日志并传输至消息队列Kafka 中,支持基于Ftp/Sftp、webservice、SNMP、file、JDBC/ODBC、Syslog、Flow 协议的日志采集,支持分布式多节点部署,支持多采集节点存活、健康状态监控,发现节点异常后,及时告警。
数据清洗和标准化模块通过分布式消息队列Kafka 组件,对采集到的数据进行字段映射、数据类型转换、数据清洗、数据加载解析规则等处理。
数据存储模块中的日志存储用于对采集上来的不同类型的数据进行分类存储,以满足数据分析的要求,支持对结构化数据、非结构化数据、关系型数据库等进行分类存储,支持的存储方式包括HDFS、Hbase、Kafka、Elasticsearch 等。
2.3 终端检测模块设计
当用户使用终端设备启动应用程序时,判断设备是否存在异常,服务端通过接收终端设备信息,提取核心字段进行设备指纹计算,为终端生成高唯一性、强稳定性的设备标识符。随后使用多维度终端属性数据建模分析识别伪造虚假设备,检测恶意终端绕过业务规则进行如虚假订单、活动作弊等风险行为。
2.4 离线分析模块设计
离线分析模块中的用户行为分析是通过对用户操作日志数据持续监控,为单个用户或群体构建标准行为基线,通过动态基线技术提供从用户、终端设备、IP 地址、UA 等维度,配置分析算法(基于经验法则、四分位异常、MA 序列)和自定义策略找出偏离基线的异常行为。它不仅仅是把行为分成非白即黑,而是经过概率计算输出分值来判断是否异常,根据风险累计的数值判断用户风险级别。同时为用户及其操作添加标签,通过可视化的方式呈现单个用户的行为画像。
由于业务存在大量的多维数据,离线分析模块采用基于孤立森林模型的异常识别打分算法,对历史数据进行训练,同时根据时间维度不断完善训练数据集,算法的识别率随着时间稳步提升。假设用户在访问同一个接口时调用的参数相对固定,那么将这个接口的所有访问参数在query 参数个数、参数中数字个数和参数总长度等维度上做对比,来确定哪一条访问的参数异常,并对异常度进行打分,然后对异常分数最高的一批访问进行人工打标签来确认是否真实存在异常,并将结果作为后续模型的训练样本。
3 应用场景和效果
3.1 应用场景
围绕识别数据信息泄露、用户异常行为等业务风险,构建了以下三个场景模型:
(1)登录异常检测模型:对业务系统中用户登录认证操作进行行为分析,识别出有撞库、暴力破解、扫号等风险行为的账户。
(2)业务系统互联网安全检测模型:对用户登录系统后办理流量包、基础业务、积分兑换等业务进行风险分析,通过办理业务时间、业务名称、办理状态等信息,建模分析识别其存在风险,如绕过检测规则、非法为他人办理业务、恶意兑换积分等敏感操作,防止敏感信息泄露。
(3)违规脚本订单检测模型:分析通过各个系统产生的数据,及时发现无效订单,同时避免恶意刷单、恶意下单、订单频次异常等业务风险。
3.2 效果验证
为验证风险识别效果,江苏电信以线上渠道生产的数据进行训练,并输出风险识别异常结果,包括风险用户、风险行为、风险事件及风险评分,如图2 至图5 所示。

图2 业务风险识别异常结果总览(a)

图3 业务风险识别异常结果总览(b)
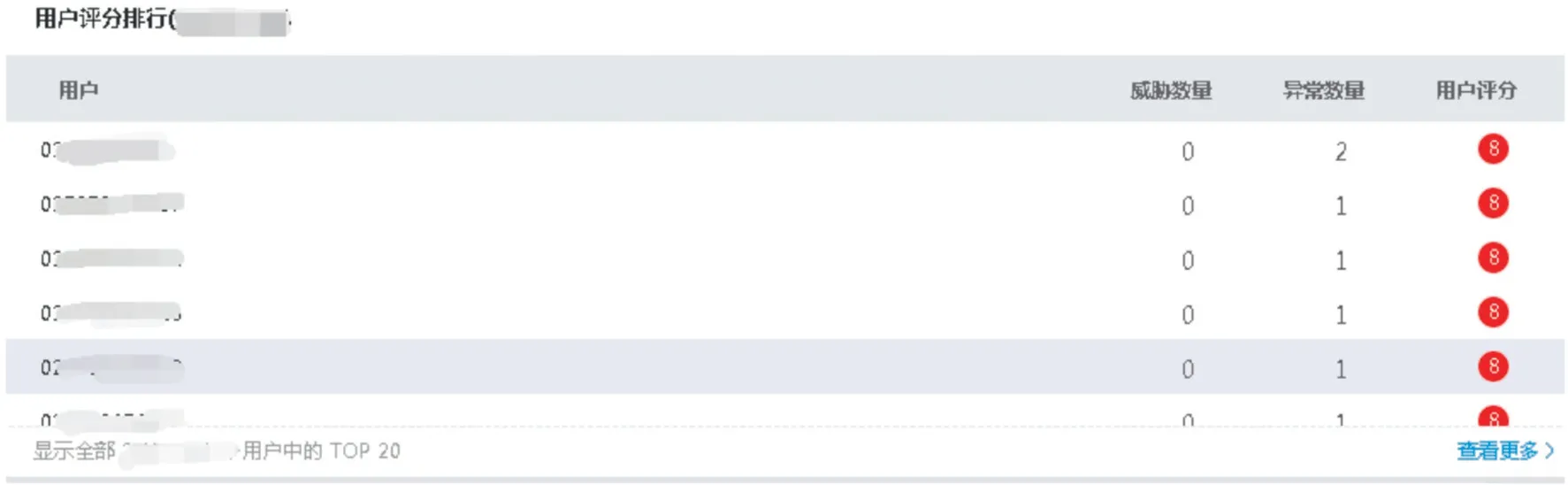
图4 业务风险识别异常结果总览(c)

图5 业务风险识别异常结果总览(d)
系统运行初期,根据事先定义的风险模型自动化输出的风险识别异常结果较多,月均达50000 条以上,经过分析筛选出实际存在风险数量月均2 条左右,有效识别率不超过0.04%,这主要是风险模型构建不够精细、样本数据质量不高等原因造成的。经过5 个月的数据训练及模型优化,目前风险识别异常结果数量下降至月均300条左右,经分析实际存在风险76条,有效风险识别率提升至25.3%。
4 结束语
业务风险分析系统作为一种分析平台,是以数据驱动为核心主线,使用多种算法检测、提取、建模出整个分析过程,通过行为分析尽可能将异常行为从海量数据中分析出来,提供更加精准的异常行为结果,经测试获得了较好的应用效果,从而在实践过程中探索出一条新的运营商线上渠道安全风险感知思路。但是不同的算法都有各自的局限性,很难有一个算法完全适用所有场景,且业务风险分析系统依赖于历史数据、专家经验,未来需要针对不同业务场景进行参数优化和算法优化,不断对异常检测结果进行验证和回馈,以提升有效风险识别率。
