基于EEMD的固定分段数分段线性表示方法
2023-11-22刘学彬梁智飞朱卫平
刘学彬,梁智飞,朱卫平,祝 凯*
(1.青岛理工大学 信息与控制工程学院,山东 青岛 266000;2.中石油煤层气有限责任公司,北京 102200)
0 引 言
由于时间序列是高维且存在大量噪音的,直接在原始序列上进行预测、模式发现和分类等挖掘任务的效率较低,同时也会影响挖掘结果的精度和可信度。因此,使用特征表示方法将时间序列从高维度转换到低维度,这种方法可以在降低时间序列复杂度的同时,保留时间序列的主要信息,为进一步深入研究时间序列奠定基础[1]。
目前国内外有不少学者致力于时间序列特征表示方法的研究,时间序列特征表示方法的主要代表有:基于域变换的表示方法(离散傅里叶变换[2]和离散小波变换[3];符号化表示方法,其中应用最广泛的是符号聚合近似方法[4-5];分段累计近似方法[6]和分段线性表示(Piecewise Linear Representation,PLR)[7]。其中PLR具有简单、直观的特点,能够有效保留原序列的形态信息以减少拟合误差,是一种应用广泛的时间序列特征表示方法。因此,该文着眼于分段线性表示方法的研究和改进。
目前,PLR的研究主要集中于解决分段数和分段点的选择问题上。为了解决这些问题,时序的分段表示方法可以分为以下几种:(1)限制分段数:主要代表是分段累计近似方法,但该方法没有考虑实际序列形态,不能很好地保留原始序列特征;(2)限制分段误差:主要代表性算法有自顶向下[8]、自底向上[9]、滑动窗口[10]。限制分段误差方法对一些状态变化的拐点不敏感,不能保证每一分段只具有一种基本趋势。针对上述问题,近年来不少学者提出了一些改进方法。例如,尚福华[11]和廖俊[12]提出基于趋势转折点的分段线性表示方法;陈帅飞[13]提出基于关键点的分段线性表示方法;刘意杨[14]提出基于转折点和趋势段的分段线性表示方法等。但是,这些方法使用单一的启发式规则,难以适用于数据分布复杂的时间序列,进而导致算法出现局部最优化问题,而且不能灵活控制压缩率,不能适应后期要求分段数一定的应用[15]。
针对上述方法存在局部最优化和不能预计分段数的问题,提出了基于EEMD的固定分段数分段线性表示方法。首先,通过模态重构思想过滤掉细节信息,提取到全局性分段点;然后,根据各初始分段子序列的波动程度,确定子序列段内分段点数量分布;最后,采用基于分段数阈值的自底向上方法将子序列合并到要求的分段数。
1 分段线性表示相关概念及问题描述
1.1 分段线性表示相关概念

(1)

(2)

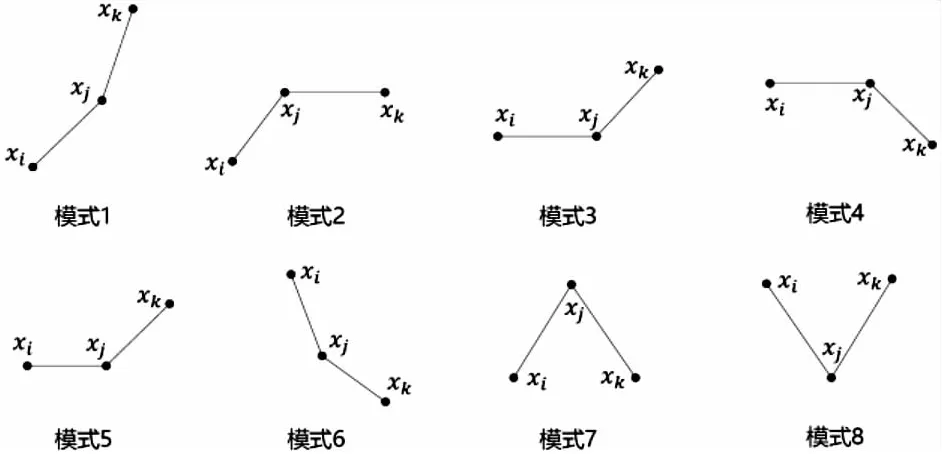
{xpq-1≤xpq}∩{xpq+1 或 {xpq-1≥xpq}∩{xpq+1>xpq}∪{xpq-1>xpq}∩{xpq+1≥xpq} (3) 此外,规定一个有限长度的时间序列起点和终点为重要点。由式(3)得到m个重要点,则重要点序列表示为: (4) 传统的算法采用单一的启发式规则提取局部特征点,当原始时间序列波动频率较为剧烈且集中时,容易出现多个点的斜率变化近似。时间序列如图1所示。 图1 斜率波动频繁剧烈的情况 图1中序列点a,b,c,d,e,f点斜率变化近似,当通过调节斜率变化阈值d使得达到要求的压缩率时,会出现临界阈值,如下: 其中,下标L表示左,R表示右。由上述公式和图1知,c,d两点作为反映序列整体趋势的特征点因斜率变化小而“漏提取”,即分段方法的结果遗漏掉能够反映整体特征的数据点;由此可认为,b,e两点为“过提取”,即分段方法的结果提取到不能反映整体特征的数据点,导致算法陷入局部最优化。 Huang[17]提出了经验模态分解(Empirical Mode Decomposition,EMD)。该方法的核心思想是将复杂的信号分解为有限个频率从高到低的本征模态函数(Intrinsic Mode Functions,IMF),对于某时间序列{x(t)}经验模态分解的具体步骤如下: (1)求出{x(t)}中所有的极值。 (2)采用3次样条函数进行插值拟合上包络线bmax(t)和下包络线bmin(t)。 (3)计算上下包络线平均值m(t): m(t)=[bmax(t)+bmin(t)] (5) (4)从时间序列中提取均值并将x(t)和m(t)的差定义为: d(t)=x(t)-m(t) (6) (5)检查d(t)的属性:如果满足IMF分量条件,则将d(t)表示为第k个IMF,并将x(t)替换为残差r1(t)=x(t)-d(t)。第k个IMF分量通常表示为ck(t);如果不满足,则将x(t)替换为d(t)。 (6)重复步骤(1)~(5)直到残差为单调函数为止。 原始时间序列可以表示为若干个IMF和一个残差的线性组合: (7) 其中,x(t)表示1维信号;ck(t)表示第k个IMF分量;r(t)表示残余。 当时间序列的时间尺度呈现跳跃性时,采用EMD对其进行分解,将会产生一个IMF分量包含不同时间尺度特征成分的情况,这种现象被称为模态混叠[18],它使得EMD得到的分解结果的可靠性和可解性受到影响。Wu[18]提出了集合经验模态分解(Ensemble Empirical Mode Decomposition,EEMD)解决这一问题。基本思想是将不同白噪声多次加入原始时间序列以消除模态混叠现象。 如图2(a)所示,对1组示例时间序列进行EEMD分解,得到了6个IMF分量和1个RES残余,如图2(b)所示。 Zhang等人[19]采用EEMD技术来分析石油价格 (a)示例时间序列 (b)EEMD分解结果图2 示例时间序列集合经验模态分解 变化。他们发现,经本征模态函数重构后的序列可以很好地反映序列的关键转折点和整体趋势变化。基于这项研究,该文使用EEMD技术对时间序列进行分解,并将分解得到的IMF分为高频部分、低频部分和残余。前两个成分能够揭示时间序列所蕴含的物理意义,并发现时序的一些新特征。对EEMD分解得到的N个IMF,求出每个IMF的平均值,得到用于分解高频和低频分量的K函数。以图2(a)的时间序列为例,构建的K函数及高、低频和残余分量如图3所示。 (a)分解高频和低频分量的K函数 (b)原始时序和3个分量图3 K函数及对应的3个分量 由图3(a)知,在IMF5处,平均值开始偏离零点,因此使用IMF1~IMF4的部分重构表示高频分量,使用IMF5和IMF6的部分重构表示低频分量,残余单独处理。图3(b)显示了原始时间序列和3个分量。残余反映时间序列长期缓慢变化;低频分量的每次急剧上升或下降可能对应1个物理事件或是某种程度上的噪声表征;而高频分量通过去除大量的小幅波动使得可以反映时间序列的整体变化趋势。下面给出模态重构序列的定义。 定义4(模态重构序列):对于某时间序列X,对X进行EEMD分解得到N个IMF,定义参与重构的起始IMF索引为s,终止索引为e,重构序列XR表示为: (8) 在高频分量基础上,提取全局特征点,实现时间序列的初始分段。 (9) 根据上式,对图3(b)中的高频分量提取全局特征点,实现时间序列的初始分段。 由图4知,原始时间序列被全局特征点分割为12段子序列,每段子序列都保持整体上升、下降、保持三种基本趋势,有效去除大量小幅波动,反映时间序列整体变化趋势。 图4 全局特征点初始分段 假设在序列中需要查找N个分段点,上节已提取了M个全局特征点,并将原时间序列分成了M+1个初始段。接下来,采用廖俊[12]提到的时间序列点间的模式变化提取剩下的N-M个分段点,如图5所示。 为了反映时间序列内的模式变化,将所有时间序列数据点符号化[20]。在时间序列X中,给定某一序列点xj,然后分别用前一点xi和后一点xk与该点做差分,即xk-xj=Q和xj-xi=P。具体步骤如下[1]: (3)将不符合上述条件的点用“0”表示。 (4)遍历整个序列,得到符号化序列。 图5 时间序列3点之间的模式变化 其中δ为自定义阈值,将所有符号化的子序列分别求和,存入Hi中,得到长度为M+1的序列:H={H1,H2,…,HM+1},通过以下公式: (10) 得到M+1个子序列内分段点的分布数量: C={C1,C2,…,CM+1} (11) 经典的自底向上方法由Keogh等人[7]提出,该方法的基本思想是通过循环地合并误差最小的相邻分段,直到所有的拟合误差均不小于分段阈值为止。该算法存在偶数限制的不足,为了解决该问题,孙焕良在其[21]研究中提出了优化的PLR_BU算法,但是仍无法准确地预测时间序列的分段数。 针对这一缺陷,该文在优化的PLR_BU算法基础上进行了改进,提出了固定的PLR_BU算法。该算法的基本思想:首先将长度为n的时间序列依次相连前后两点,然后给定分段数阈值,循环地执行下述过程:(1)计算相邻的分段合并后的拟合误差;(2)查找拟合误差最小的相邻分段{xi,xj,xk},移除此相邻分段的中心点xj,序列长度减1;(3)计算新生成的段与前后分段的拟合误差。重复上述过程,直到合并到满足设定的分段数为止。固定分段数的PLR_BU算法伪代码如表1所示。 该文提出基于EEMD的固定分段数分段线性表示方法,具体算法步骤如下: 给定时间序列X={x1,x2,…,xn},斜率变化阈值δ,分段数N。 (3)时间序列符号化和确定初始分段段内分段点分布。根据斜率变化将时间序列转换成由“0”和“1”组成的符号化序列。计算符号化后各初始分段内数据和,得到H={H1,H2,…,HM+1},根据式(10)和(11),得到最终子序列段内分段点分布数量序列C={C1,C2,…,CM+1}。 (4)固定分段数的PLR_BU算法确定最终分段点。根据改进的PLR_BU算法对子序列继续分段,直到分段数为N,最终分段点序列:X={x1,xi1,…,xiN-2,xn}。 表1 固定分段数的PLR_BU算法 参数说明:在文中方法中,斜率变化阈值δ是主要的参数。设置阈值δ的目的是按照斜率变化过滤数据点,δ值过小时,会将斜率变化相对较小的数据点也转换为“1”,导致相对平缓的序列段分段点的分布数量也较多;δ值过大时,会将斜率变化相对较大的数据点转换为“1”,导致只有斜率变化相对较大的序列段分段点的分布数量才会较多。由于P和Q表示相邻点的差分,所以δ取值范围为0<δ 该文选择以下3种时间序列分段线性表示方法作为比较对象。 (1)PAA[6]。 (2)PLR_ITTP[12]。 (3)PLR_TRIP[14]。 X= (12) 式中,t为整数,共600个数据。选择该仿真序列作实验,是由于这个序列的重要点比较清晰,且没有噪声的干扰,因此,重要点更容易被发现。对序列X加上均值(μ=0)、方差(σ设为0.5~3)、步长为0.5的随机误差,对比在不同噪声的情况下,各个分段方法的抗噪声能力,检验是否可以准确提取全局特征点的有效性,对于对比分析时间序列消除局部最优化问题具有参考意义。 根据仿真数据的实际趋势,将序列分为13段,将拟合误差作为评价标准,显然,提取的分段点越接近原始序列趋势分段点,拟合误差越小。实验结果如图6和表2所示。 表2 不同噪声下不同PLR的拟合误差 图6是不同噪声情况下,不同分段方法的分段拟合结果。 图6 不同噪声情况下的不同PLR结果 由图6可知,随着σ的逐渐增大,分段算法对能够反映整体趋势的分段点的识别越来越困难,而文中方法相比于其他3种方法,对该序列中能够反映整体趋势的分段点的识别较为准确,尤其在高噪声情况下更为明显,而其他3种方法均提取了错误的分段点。 由表2知,文中方法虽受噪声干扰,但总的来说,抗噪声干扰的能力比其他3种方法有所加强,可以非常准确地提取反映整体趋势的分段点,而其他方法则极易受到噪声的干扰,导致陷入局部最优状态。 由图6和表2可知,尽管噪声的增加对PAA的拟合误差影响较小,但其整体的拟合误差相对较大,这是由于PAA采用等长分段,分段点的选取不会受到噪声的影响。而PLR_ITTP、PLR_TRIP都通过某种抗噪机制削弱了噪声的干扰,使得拟合误差相对较小。PLR_ITTP在噪声较低时,拟合误差较小,但在噪声较高时,拟合误差随之变大,这是因为PLR_ITTP只重视时间序列的局部特征,而忽略了全局意义下的时间转折点,这将导致在高噪声的时候,算法会错误地提取关键点。PLR_TRIP在不同噪声下拟合误差都较大,并且出现了震荡上升的情况,由于PLR_TRIP的角度阈值和趋势段阈值的组合选取是复杂的,不同的阈值组合会造成拟合误差的大幅变化,同时PLR_TRIP提出趋势段的概念来削弱噪声的干扰也是只关注局部信息。而文中方法先通过模态重构方法得到全局分段点,使得文中方法有效克服上述方法存在的局部最优化缺陷,之后使用自底向上方法进行融合,保留了基于分段误差的分段算法拟合误差较小的优点。 压裂施工过程中,通过记录不同时间段的施工压力、泵注排量和加砂体积分数获得压裂施工曲线,有效利用压裂施工曲线并提取有效信息,不仅能够对储层及裂缝参数再认识,而且对于指导压裂施工以及调整压裂设计方案、提高压裂技术水平和施工效果有重要的借鉴作用。因此,对压裂施工曲线的挖掘和分析有着重要的工程意义和应用价值[22]。但压裂施工曲线是一种高维数据,为了方便后续存储和挖掘需要对其进行压缩表示。该文选用某区块的压裂施工数据,时间间隔为1 s,共2 500个数据值。 为了比较文中算法与其他算法的优劣,并考虑到实际压裂施工曲线的高维性特点,将考察所有方法在压缩率分别为90%、92%、94%、96%、98%时的拟合误差,实验结果如图7所示。 图7 压裂施工曲线不同压缩率下的拟合误差 由图7可知,文中方法在不同压缩率下的拟合误差都是最小的,优于其他3种方法。 图8 96%的压缩率下不同方法分段拟合效果对比 由图8可知,对压裂施工时间序列这种高噪声且分布复杂的序列进行趋势提取时,PLR_ITTP、PLR_TRIP因存在局部最优化的问题而导致“漏提取”“过提取”现象较为严重,丢失了反映整体趋势的重要点;而文中算法能够有效地去除时间序列中的噪声,准确提取反映时间序列整体趋势的分段点。 针对现有方法的不足,该文提出一种基于EEMD的固定分段数表示方法。仿真实验结果表明:该方法的拟合误差分别比PAA、PLR_ITTP、PLR_TRIP平均减小了80%、59%、78%,其有效地解决了现有分段方法存在的问题,极大地削弱了噪声干扰,从而能够准确地找到反映整体趋势的分段点。最后将该方法应用于压裂施工数据,其拟合误差分别比PAA、PLR_ITTP、PLR_TRIP减小了86%、84%、89%,再次证明了所提方法对趋势提取的有效性和准确性。1.2 问题描述

2 集合经验模态分解和改进的自底向上分段
2.1 集合经验模态分解
2.2 IMF重构






2.3 时间序列符号化


2.4 固定分段数的自底向上分段
2.5 时间序列分段线性表示方法



3 实验与分析
3.1 实验对比方法
3.2 仿真数据验证


3.3 工业实例应用


4 结束语
