改进全局上下文注意力新冠肺炎X光诊断方法
2023-11-20吉旭瑞
吉旭瑞,刘 静,吉 辉,张 帅,曹 慧
1.山东中医药大学 智能与信息工程学院,济南 250355
2.陕西学前师范学院 历史与文化旅游学院,西安 710100
2019年底,新型冠状病毒肺炎(corona virus disease 2019,COVID-19)暴发,并很快席卷了全球多数国家,严重威胁了人类的生命安全。新型冠状病毒具有较强的传染性[1],且大量无症状感染者的出现给疫情防控工作带来了更大的压力,因此加强新型冠状病毒的诊断以避免其进一步传播至关重要。
检测COVID-19 的方法包括逆转录聚合酶链反应(reverse transcription-polymerase chain reaction,RT-PCR)检测、计算机断层扫描(computed tomography,CT)、胸部X 射线(chest X-ray,CXR)。RT-PCR 检测是被广泛采用的诊断方法,但RT-PCR 检测有时会出现假阴性的情况,不利于防止病毒的传播[2]。与CT图像相比,CXR成像更具有时效性、且成本较低,对人体的伤害也更小,此外,在一些医疗不发达的地方,CXR 成像要比CT 更容易使用。因此,这使得CXR 图像成为抗击疫情的有效成像工具。
近年来,深度学习在医学方面的应用越来越广泛[3-5],机器取代人力来识别医学图像,可大大增加医学诊断的效率,并且许多研究人员在保证效率的基础上也能保证诊断的精度。越来越多的研究人员利用深度学习技术基于CXR 图像对COVID-19 进行检测[6]。Sousa等[7]提出CNN-COVID 模型用于对COVID-19 患者分类,并分别对两个不同的COVID-19数据集进行数据增强。Loey 等[8]使用条件生成对抗网络(conditional generative adversarial nets,CGAN)来进行数据增强,提高了经典分类模型在COVID-19 中的分类性能。Rajpal等[9]提出了COV-ELM 的三阶段模型,创新性地引入极限学习机(extreme learning machine,ELM),加快了模型的收敛速度,在COVID-19的CXR图像三分类问题中展现了良好的效果。Wang 等[10]针对COVID-19 的CXR图像分类问题,设计了COVID-Net模型,嵌入大量轻量级残差投影-扩展的PEPX模块,在保证模型性能的基础上又降低了计算的复杂性,分类效果优于ResNet50 和VGG19。Maity 等[11]受UNet++启发提出了一种DCNN模型,使用EfficientNetB4作为编码器,残差块作为解码器对CXR 图像分割,正确区分肺实质区域和无实质区域,提取出肺部区域用于医学疾病诊断。Xu 等[12]提出了一种两阶段新冠肺炎分类方法MANet,使用带有ResNet 主干的UNet 模型作为分割网络,引入新的空间注意力模块MA到分类网络中,显著提高了原始模型的分类性能和训练稳定性。Kalaivani 等[13]提出了一种三阶段集成增强卷积神经网络来对COVID-19分类,首先使用ResUNet 网络对CXR 图像进行分割提取,再将其输入到卷积神经网络中提取特征,最后利用机器学习技术和投票机制对检索到的特征集成训练,其分类结果优于传统的卷积神经网络以及机器学习算法。
尽管深度学习在COVID-19 检测中取得了很大的成功,但是在实际应用中仍面临着一些挑战。例如,诊断模型缺乏可解释性和泛化性[14]。此外,训练模型作出决策的区域不在病理区域甚至不在肺实质且模型没有抑制特征图的冗余信息,这使得这类诊断模型不易被推广到新的样本中,大大减少了模型开发的意义。针对这些问题,本文使用基于分割的方法来提取肺实质再进行COVID-19分类,以降低CXR图像内无关信息对分类结果的影响。由于提出的分类模型能集中在肺实质,且这些区域中与疾病无关的信息较少,因此提高了模型的泛化能力。本文提出了一种两阶段基于CXR图像分割的COVID-19 分类模型Res-IgSa,其中包含改进的全局上下文模块(WGC)以及空间注意力模块(CSA),主要贡献如下:
(1)使用ResUNet[15]网络先对CXR 图像进行分割,防止CXR图像中其他无关因素干扰分类结果。网络中残差单元的引入能够有效地识别肺部掩膜,从而准确地分割出肺实质,分割出的肺实质会作为分类网络的输入。
(2)提出一种基于全局上下文注意力机制的双分支模块应用于分类部分的网络,其中通道注意力和空间注意力的并行结合使得两者实现了最好的分类效果。
(3)在分割后的数据集上进行分类实验,最终能得到94.154%的准确率以及94.139%的F1 值,具有较强的稳定性。并与原论文Rahman 等在分割后分类的结果进行比较,实验表明本文的模型进一步提高了分类的准确率,证明了分割以及Res-IgSa模型在此任务中的有效性。
1 方法
Res-IgSa 总体模型结构图如图1 所示,其包含两部分,其中分类部分是在分割的基础上进行的。分割模型是在CXR图像以及相应的掩膜上训练的[16],分割得到的肺实质作为分类模型的输入。分类模型引入改进的全局上下文模块(WGC)以及空间注意力模块(CSA),接下来将详细介绍所采用的方法。
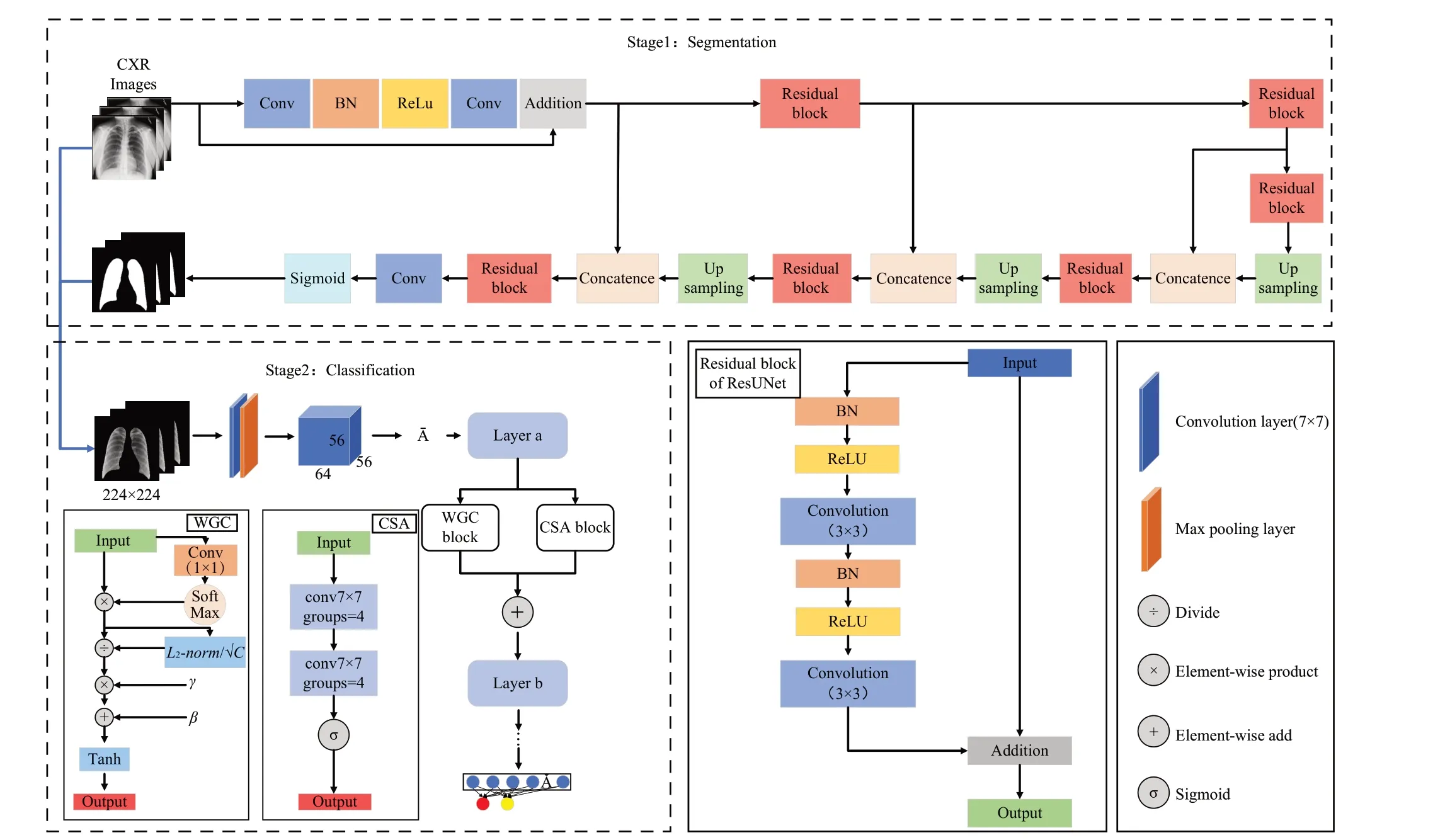
图1 Res-IgSa总体模型结构图Fig.1 Overall model structure diagram of Res-IgSa
1.1 ResUNet
第一部分,本文先对原数据集进行分割。在医学图像分割任务中,针对医学图像特点,Ronneberger等设计了U 型结构以及skip-connection,提出UNet[17]用于医学图像分割。ResUNet 是U-Net 模型与残差单元的结合,保留了UNet的U型结构,舍弃了U-Net模型中的裁剪操作。在语义分割任务中,保留高层的语义信息至关重要,引入残差单元,能够简化网络的训练,跳连操作促进了信息的传播,从而能够准确地预测肺部掩膜。因此本文使用了ResUNet 作为分割的网络模型,ResUNet 模型结构图如图2 所示。ResUNet 具有7 层架构,其中编码器、桥梁和解码器是三个主要组成部分,编码器和解码器通过桥梁部分相连。残差单元分布于这三部分中,包括批归一化(batch normalization,BN)、ReLU 激活函数、两个3×3 卷积以及跳连操作,残差单元可表示为如下公式:
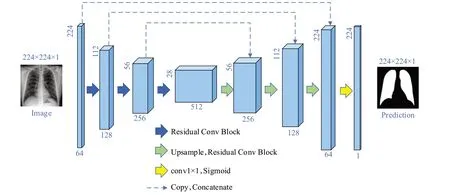
图2 ResUNet模型结构图Fig.2 Structure diagram of ResUNet
其中,z表示残差单元的输出,xl表示残差单元的输入,ƒ表示激活函数,g(xl)以及F(xl)分别表示恒等映射和残差函数。ResUNet编码器与解码器结构表如表1和表2所示。CXR图像的输入尺寸为224×224×3,编码器中包含三个残差单元,使用步长为2的卷积核对特征图大小减半。Unit4为编码器与解码器间的桥梁。与编码器相同,解码器也包含三个残差单元,编码器中的残差块减少了特征图的大小,解码器中的残差块能将特征图恢复到原来的大小。来自相同编码路径的特征映射会与解码器的相应位置进行相连。在最后一层解码中,使用一个1×1 卷积以及Sigmoid 激活函数得到最终的输出。
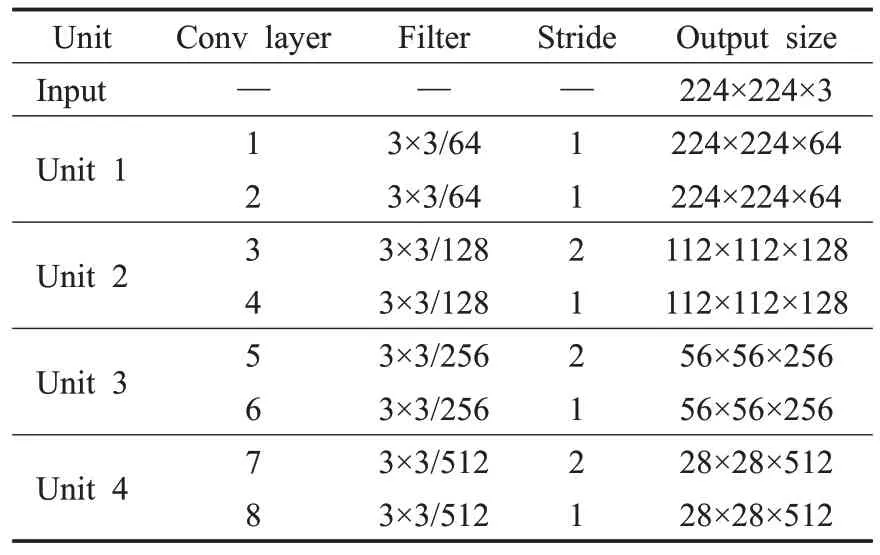
表1 ResUNet编码器结构表Table 1 Structure of ResUNet encoder
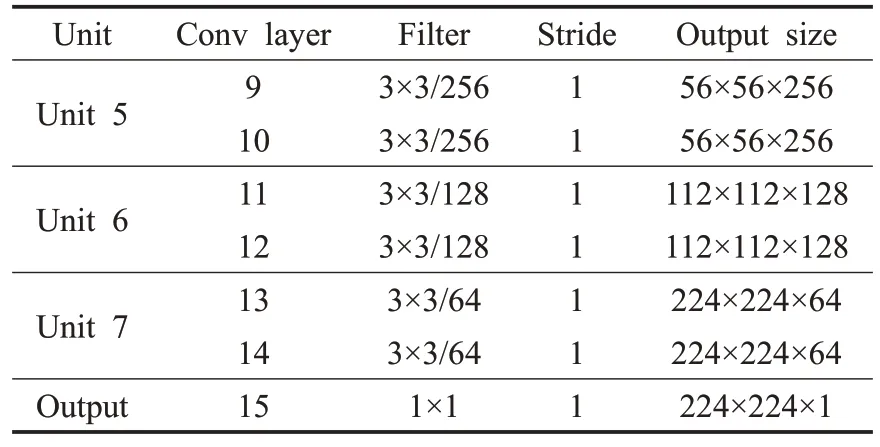
表2 ResUNet解码器结构表Table 2 Structure of ResUNet decoder
1.2 基于全局上下文注意力机制的双分支模块
1.2.1 改进全局上下文模块
在计算机视觉的各大任务中,捕捉长距离的依赖关系被证明是有很大益处的。在传统卷积神经网络中,要实现全局上下文的提取,就需要不断地堆叠卷积层,但这样会导致计算量的大幅增加且网络难以优化。针对这个问题,出现了non-local network,它引入自注意力机制,对远程依赖进行建模[18]。尽管non-local network避免了卷积层的堆叠,但大量的矩阵操作使得计算量非常庞大。而全局上下文网络(global context network,GCNet)[19]创新性地提出简化版的non-local network 并将其与Squeeze-Excitation Block结合起来,在减少计算量的同时实现长距离依赖关系的有效捕捉,对全局上下文建模。但是,在Squeeze-Excitation Block 部分中,全连接层的设计导致了两个显著的问题。由于Squeeze-Excitation Block 是嵌入到CNN 的块中,且为了减少计算成本需要降低全连接层的维度,这阻碍了SE 模块的部署。其次,全连接层使得通道关系的学习完全不可见,导致输出不可知。这些问题都制约着GCNet的性能。
受gated channel transformation(GCT)注意力机制[20]的启发,本文引入通道规范化以及门控自适应单元来对GCNet中的Squeeze-Excitation Block部分进行改进,同时保留GCNet中捕捉长距离依赖的特性。
通道规范化模块使用一个简单的l2规范化来对嵌入上下文信息的通道进行建模,代替传统的全连接层。通过构建规范化方法能够清晰地学习到通道间的竞争关系。在进行通道规范化时尺度因子C用来约束规范化的尺度以避免尺度过小,相较于Squeeze-Excitation Block中的FC部分,通道规范化模块具有更小的计算复杂度。具体的通道规范化公式为:
在得到通道间的关系后,门控自适应单元将对各个通道关系进行分析,基于规范化输出调整通道特征。可训练参数β=[β1,β2,…,βC] 和γ=[γ1,γ2,…,γC] 用于控制门控权值,使网络能同时促进通道竞争和协作关系。门控自适应单元公式如下:
不同于Squeeze-Excitation Block,为防止梯度消失,选择了tanh 作为这里的激活函数,舍弃了sigmoid。tanh 函数相较于sigmoid 函数是中心对称的,收敛速度更快且不容易出现梯度消失现象。门控自适应单元会判断一个通道(γC)处于积极激活状态还是消极激活状态,从而处理通道之间的竞争或合作关系。改进的全局上下文模块可简化为以下公式:

1.2.2 空间注意力模块
空间注意力可以被视为一种自适应空间区域的选择机制[21],通过压缩通道数,构建空间维度的信息,增强或抑制不同空间位置的特征,使得网络能聚焦于感兴趣的空间特征[22-23]。在本文中,为了减少信息的丢失让模型能尽可能多地学习到全局维度交互特征。在设计空间注意力模块时,本文使用两个卷积层对空间信息进行结合,但这样可能会显著增加模型的参数量,因此本文引入分组卷积以及衰减率r来控制模型的容量和其在计算方面的开销。
分组卷积[24]是将输入特征图的通道数以及卷积核的个数分成g组,同时每组滤波器来处理相应的输入特征通道组,这样能够显著降低计算成本以及模型大小,分组数g=2 的分组卷积如图3 所示。图中输入特征图大小为H×W×c1,经过分组卷积通道数c1被分成了c1/g个,之后通过concat 操作得到最终通道数为c2的输出。

图3 分组数g=2的分组卷积示意图Fig.3 Schematic diagram of group convolution with group number g=2
在实际设计空间注意力模块中,受Global Attention Mechanism[25]启发,引入分组卷积到两个7×7卷积中,并使用衰减率r来控制卷积尺寸的大小,有效地控制模型的容量,让卷积层能够有效地利用上下文信息。其空间注意力机制可被简化为以下公式:
其中,xr表示输入,f表示卷积操作,f7×7g表示7×7分组卷积,σ表示使用sigmoid激活函数。
1.2.3 改进全局上下文与空间注意力模块的结合
在这一部分对改进全局上下文模块WGC(xj)和空间注意力模块CSA(xj)进行了阐述。常用模块间的结合方法包括CBAM 中采用的串联方式[26]、BAM 中采用的并行结构逐元素相加、并行结构逐元素相乘等[27],采用并行结构两分支逐元素相加这一结合方式能够得到最优的分类效果。在模型结合后的信息流动时,逐元素相加能够有效地聚合来自两分支的输出,并且在网络训练的前传阶段两分支的信息又能给网络提供良好的互补,减少了信息的丢失。在反向传播时也能均匀地为所有输入分配相应的梯度,降低训练损失。相比较之下并行结构逐元素相乘会给输入分配较大的梯度,使得模型较难训练,不易得到较好的分类效果,从本文的实验结果中也证明了这一点。最终消融实验证明并行结构逐元素相加能够达到更好的分类效果,因此最终选择并行结构逐元素相乘这一模块间的结合方法。本文改进的注意力模块的总体结构如图4所示。
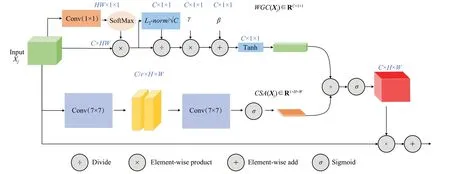
图4 改进的注意力模块总体结构图Fig.4 Overall structure of improved attention module
2 实验结果与分析
本文在操作系统Ubuntu 18.04,GPU型号为NVIDIA GTX 2080Ti的服务器端训练模型。使用深度学习框架Pytorch 1.8.0来构建整体网络模型,并使用Python作为开发语言。
2.1 实验数据集
本文使用的数据集是由卡塔尔大学和达卡大学的研究人员联合创建的COVID-19 Radiography DatabaseV5[28-29]。该数据集是当前最大的COVID-19 公开胸部X光图像数据集之一,包含3 616张COVID-19阳性、6 012 张肺浑浊和10 192 张正常的CXR 图像。为保证比较的公平性,本文选取了其中3 616 张COVID-19 阳性、6 012 张肺浑浊和8 851 张正常的CXR 图像作为实验数据集。在分割部分,将18 479 张CXR 图像的80%作为训练集,20%作为测试集。在分割后的分类部分,使用80%的CXR 图像作为训练集,剩余20%作为测试集,并将训练集中20%的图像作为验证集在训练过程中进行验证。为了保证数据的平衡性,本文发现训练集中COVID-19 的图像数量少于训练集中Normal 图像的一半,为了保持数据的平衡性,本文对训练集中的COVID-19类利用图像翻转技术进行数据扩充,表3展示了分类部分数据集划分的详细情况。

表3 分类部分训练、验证、测试数据集的详细信息Table 3 Details of training,verification and test dataset in classification section
2.2 分割部分
在第一阶段,本文先在按训练集和测试集8∶2划分的整个数据集(8 851张正常类、6 012张肺浑浊类、3 616张新冠肺炎类)训练ResUNet 模型,优化器使用Adam,epoch 设置为30。初始学习率为0.001,每10 轮做一次学习率衰减,权重衰减为0.000 01。在进入分类阶段之前,本文使用保存的模型权重来对原数据集的所有CXR图像进行掩膜预测,图5展示了原CXR图像、预测得到的掩膜、GroundTruth 和分割出的肺实质。每一行分别对应COVID-19、肺浑浊、正常类的图片,也能证明经过训练后的ResUNet网络能够正确地分割出肺实质,这也能为之后的分类阶段做好铺垫。

图5 三类CXR图像各阶段对比图Fig.5 Comparison diagram of three types of CXR images at each stage
2.3 分类部分
本节将上一阶段分割好的肺实质按原有标签进行分类。在这一阶段,本文对于数据集的划分以及处理情况如第二节数据集部分所述。本文使用ResNet50[30]作为分类的基础网络模型,并将所改进的注意力模块加入到基础网络中组成新的分类网络模型Res-IgSa。在训练的开始,本文加载ResNet50 在ImageNet 上的预训练权重,使用SGD 优化器训练60 轮,初始学习率设为0.001,在前10 轮进行warmup 后每20 轮进行一次学习率衰减。模型的输入为224×224。
由于不同类别的图像数量存在差异以及保证比较的公平性,因此本文使用加权性能指标和总体准确率来比较模型。使用准确率(Accuracy)、精度(Precision)、召回率(Recall)、F1值(F1)来对模型进行评估。各指标的定义式为式(6)~(9):
其中,TP代表真阳性,TN代表真阴性,FP为假阳性,FN为假阴性。
2.3.1 消融实验
(1)模块消融实验结果
为了验证本文所改进注意力模块的有效性,表4显示了在分割后的数据集上进行分类的消融实验结果。
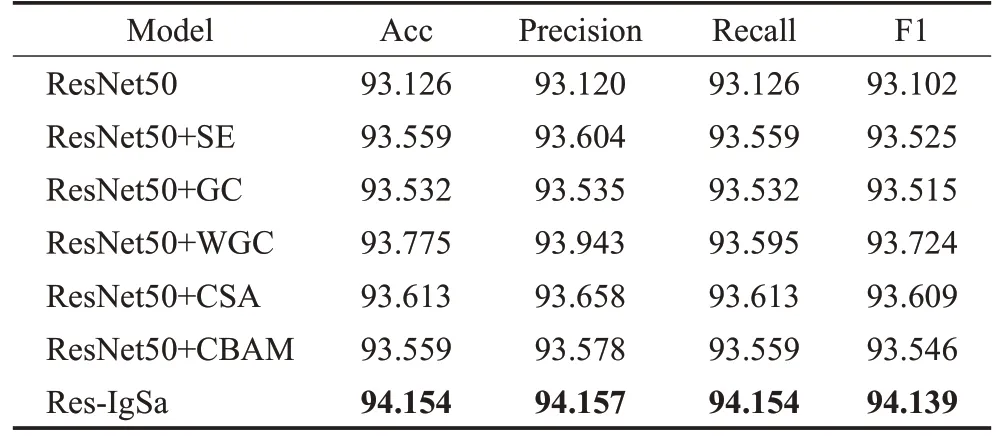
表4 各模块在ResNet50上的消融实验Table 4 Ablation experiments of each module on ResNet50单位:%
在表4中,ResNet50为本文实验的基础模型,模型2和模型4 分别在此模型的基础上加入经典的SE 注意力[31]和本文改进的全局上下文模块(WGC)。与基础模型相比,所改进的全局上下文模块能将准确率提高0.649 个百分点,精度提高0.823 个百分点,召回率提高0.469个百分点,F1值提高0.622个百分点。与模型3相比,WGC 引入通道规范化模块以及门控自适应单元后提高了分类准确率,在此任务中WGC 对模型的适配性更强。
模型5 为在基础模型上加入本文引入的空间注意力模块(CSA),模型6 在基础模型上加入CBAM 注意力[26]。模块7为本文提出的新的分类网络模型Res-IgSa,它将本文提出的WGC 以及CSA 进行结合,引入到ResNet50的两个阶段之间。最终结果表明,Res-IgSa在实验中的分类效果要优于CBAM、SE 以及单独在基础模型中加入WGC 或CSA,最终实现了94.154%的准确率,94.157%的精度,94.154%的召回率以及94.139%的F1 值。Res-IgSa 和其他网络的混淆矩阵分别如图6 所示。从混淆矩阵中本文可以看出,Res-IgSa能够在三类上都具有较高的准确率。

图6 Res-IgSa和其他网络分类混淆矩阵Fig.6 Res-IgSa and other network classification confusion matrix
(2)分组数g以及衰减率r的选择
在表5 和表6,本文展示了选择CSA 部分分组数g以及衰减率r这两个主要参数的实验结果。分组数g控制着空间注意力中分组卷积的个数,尽管分组数越大会让模型的计算开销以及容量降低,但带来的信息丢失也是其存在的问题。表5展示了分别选取分组数g=1、2、4时模型的分类结果。本文能清楚地看到当g=4 时产生了最高的准确率,而标准卷积(g=1)的分类效果较差,可以证明分组卷积在空间注意力模块中起到了较大的作用。衰减率r与输入通道的数目直接相关,它也能控制本文模型的容量以及计算量。在表6,本文比较了r=2、4、8 三种不同衰减率的分类结果,最终发现r=4获得了最高的分类准确率,使得模型具有较好的分类性能。尽管当r=8 时模型的参数量最少,但准确率偏低。基于表5 和表6 的实验结果,在本文选取分组卷积数g=4 以及衰减率r=4 进行分类实验。

表5 分组数g选择实验Table 5 Group number g selection experiment

表6 衰减率r选择实验Table 6 Reduction ratio r selection experiment
(3)WGC与CSA结合方式的选择。
本文也比较了三种不同的方式去进行WGC与CSA的结合:串行结构、并行结构之两分支逐元素相乘、并行结构之两分支逐元素相加。表7 展示了三种不同结合方式的分类结果,对于串行结构,实验结果显示其分类效果与并行结构两分支逐元素相加较为接近,最终本文也是选择了分类效果更好的并行结构两分支逐元素相加去结合WGC与CSA。

表7 两分支结合方式选择实验Table 7 Selection experiment of two branch fusion mode
2.3.2 不同模型性能比较
在这一节中,本文比较了两阶段模型Res-IgSa 在COVID-19 Radiography DatabaseV5 数据集上分割之前以及分割之后的分类效果。与原论文进行比较,证明分割以及Res-IgSa在分类任务中的有效性。
Rahman 等[29]首先使用修改后的U-Net 分割肺实质后进行COVID-19 分类。本文未使用其他的数据增强方法,在表8,本文将Res-IgSa 与Rahman 等在分割后的分类结果进行了比较。为了证明分割的有效性,本文以ResNet50预训练模型为标准,将Rahman等使用ResNet50预训练模型在其分割后的数据集分类的结果与本文分割后使用同样的模型分类进行比较,如表8 前两行所示,结果证明ResNet50 模型在本文分割后的数据集分类将准确率、精度、召回率、F1 值分别提高了0.616、0.62、0.616、0.602 个百分点。表8 还显示了Res-IgSa 在准确率、精度、召回率、F1 值方面表现最好,从实验结果可以看出Res-IgSa 在分割后进行分类的有效性,在COVID-19图像识别方面取得了显著的性能。
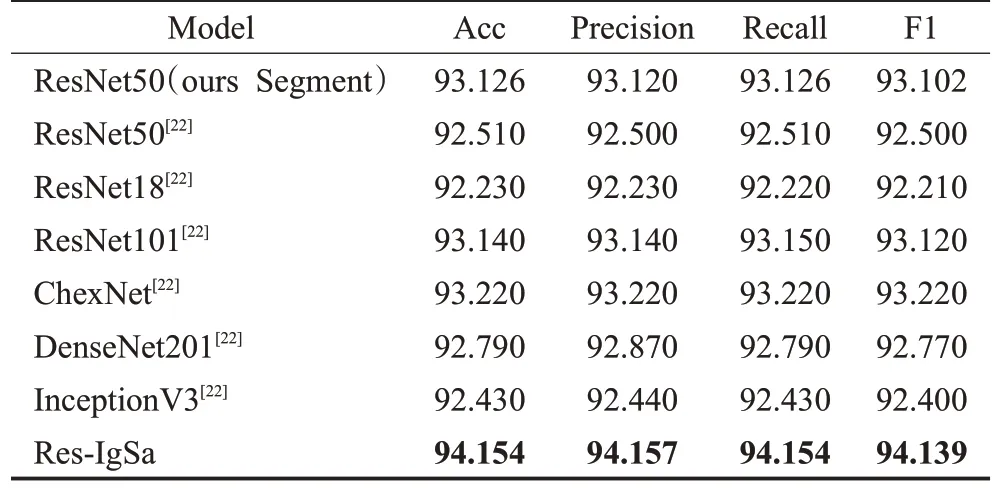
表8 各模型性能比较Table 8 Performance comparison of various models单位:%
2.3.3 可视化分析
为了进一步证明本文提出方法的有效性,本文使用梯度加权类激活图(gradient-weightedclass activation mapping,Grad-CAM)[32]可视化了相关模型的输出,可视化结果如图7 所示。图中第一行是原始图像分割后的肺实质图像,从左到右的三张为COVID-19 图像,第四张为肺浑浊图像,第五张为正常类图像。第二行和第三行分别为ResNet50 以及CBAM-ResNet50 的可视化结果。Res-IgSa的可视化结果显示在第四行,比ResNet50以及CBAM-ResNet50 更能关注它们所忽略的细节,表明Res-IgSa可以有效地识别肺部的病变区域,提高分类的准确率。

图7 三种模型在分割后分类的可视化结果Fig.7 Visual results of classification of three models after segmentation
3 结论
本文提出了一种两阶段基于分割的COVID-19 分类网络Res-IgSa,它包含了分割和分类两个阶段。第一阶段为ResUNet 分割并预测掩膜,从而提取出肺实质;第二阶段为分类阶段,使用上一阶段处理好的肺实质按原标签组成新的数据集进行COVID-19分类,在这一阶段本文引入了两种注意力模块:WGC 和CSA 并加入到ResNet50中构成本文的分类网络。WGC模块保留了全局上下文部分,并引入通道规范化代替传统的全连接层以及门控自适应单元来调整通道特征,加强通道间的相互关系。CSA 在两个7×7 卷积的基础上加入分组卷积以及衰减率来控制模型的容量,本文也对分组卷积数以及衰减率的选取进行了实验,最终也得出了两者最优的组合。本文的消融实验也证明了WGC 和CSA 具有很好的互补能力,两者结合后的分类效果也要优于经典的注意力模型CBAM 以及SE,在分割后的基础上进一步提高了分类的准确率。本文还使用了Grad-CAM 算法将模型的输出可视化,从图中可以看出各个模型的决策都是在肺实质做出的,分割肺实质能够辅助网络模型做出正确的决策,也重申了从CXR 图像中准确分割肺实质的重要性。如何进一步提高分割以及分割后分类的准确率将会是接下来研究的重点。
