地名实体识别研究与展望
2023-11-20王文涛奚雪峰崔志明
王文涛,奚雪峰,3,崔志明,3,徐 川
1.苏州科技大学 电子与信息工程学院,江苏 苏州 215000
2.苏州市虚拟现实智能交互及应用技术重点实验室,江苏 苏州 215000
3.苏州智慧城市研究院,江苏 苏州 215000
4.昆山市社会治理现代化综合指挥中心,江苏 昆山 215300
地名实体识别(toponym entity recognition,TER)从自然语言中提取地名,是泛在地理信息应用的一项基本任务。地名识别作为上游任务,首先将存在于文本中的地名实体进行识别,再将非标准的地名实体进行标准地名匹配,匹配的结果一般为POI精确坐标或者是公安系统的地址ID 编码,从而将数据与现实世界的地名信息进行关联。
地名识别(提取)过程是命名实体识别(named entity recognition,NER)的一个子集,其目的是识别文本中的位置名称边界,因为NER 是指识别出文本中具有特定意义的命名实体并将其分类为预先定义的实体类型,如人名、地名、机构名、时间、货币等,不同的是,TER 识别的是细粒度的地名。现如今,地名识别应用于许多领域,其中,较多的是用于地理信息和社交媒体事件中的地名识别。
本文从数据集、训练资源、评价指标和研究方法这4个角度来阐述地名实体识别研究。首先从基于规则和词典、基于统计机器学习、基于深度学习和混合方法这4方面对目前地名是实体识别研究工作进行系统性梳理,归纳总结了每一种TER方法的关键思路、优缺点和具有代表性的模型。
1 地名实体识别数据集及评价标准
1.1 地名实体识别概述
在过去的十年里,大数据、机器学习和人工智能的出现促进了社交媒体数据和空间信息数据的发展。社交媒体数据、空间地理信息等其他相关领域数据都可以被认为是无处不在的地名实体信息。这为研究人员充分利用这些信息提供了新的机会,从而对理解整个现实世界非常重要。现实世界中的基础应用是由“数据”构成的,因为在使用社交媒体技术的过程中会产生大量数据,然而,大多数数据都是非结构的,并且这些非结构数据基本都是以自由随意的形式存在于文本文档中,包括各种报告、科学论文文章、博客网页信息和社交媒体帖子。
地名识别在诸多领域都有许多应用。在本节中,总结了以往文献中讨论最多的4 个典型的地名识别应用领域——地理信息检索、灾难信息管理、医学疾病监测和交通管理。下面将对这些领域一一说明。
(1)地理信息检索
地名的主要应用之一是地理信息检索。大量信息系统研究人员希望对文档进行地理层面的访问,从而检索特定地理位置的相关内容。该领域的具体应用流程大致为,首先采用地名实体识别技术对包含地理信息的文本数据进行处理,将文本中的地名实体标注出来,并提取地名的相关属性信息,如地理坐标、行政区划、地理特征等。接着,将标注出的地名实体进行地理编码,将地名转换成地理位置坐标。最后,利用地理位置信息,结合用户查询条件,进行地理信息检索,找到符合用户查询条件的相关信息,如地图、图像、文本、视频等。比如,数字图书馆中的资源可以根据与资源相关的描述性元数据记录中包含的位置进行索引,从而改善用户搜索所需资源的体验。
(2)灾难信息管理
在日常的新闻报道中包含大量的实时灾难信息,基于地名识别的灾难信息管理会对描述灾难场景方面非常有帮助。例如在灾难发生后,救援请求、资源需求(如食物、衣服、水、医疗和住所)[1]以及基础设施状态(如建筑物倒塌、道路封闭、管道破裂和停电[2~4])等受灾信息,对于救援人员和被困人员至关重要。如果有了受灾人员的地点信息,那么应急人员可以跟踪事态发展,识别需要优先干预的受灾地点,实现资源实时优化配置,政府机构可以更快地对灾害进行损失评估,受灾群众也可以搜索到可以获得所需资源的地点。所以,在对灾难信息文本数据进行精准的地名识别体现的尤为重要。地名识别技术在灾难信息文本中的应用也是通过将灾难文本中的地名进行标注并提取地名的相关属性信息,将识别的地名信息进行地名匹配,从而得到具体的受灾地点信息。
(3)医学疾病监测
在医学领域的科学文章、历史档案、新闻报道和社交媒体中,包含了大量疾病事件的详细信息,如疾病首次报告的地点和疾病是如何进行时空传播的。从这些文本数据中挖掘疾病事件的地理位置和其他相关信息可以帮助跟踪疾病,从而进行早期预警和快速反应,并了解疾病发生的机制。比如,Tateosian 等人[5]为了了解19世纪美国和欧洲马铃薯病“晚疫病”的地理起源和传播方式,使用CLA VIN 19 对两篇历史文献进行了梳理。CLA VIN 是一个开源的地名信息提取模块,它利用Apache OpenNLP进行地名提取。
(4)交通管理
获取精确位置和其他相关信息对于有效的交通管理系统是非常重要的。在交通管理领域中,地名实体识别技术可以应用于以下几个方面:
①交通路线规划:利用地名实体识别技术对地址文本数据进行处理,识别出起点、终点以及途经的地点,并根据地点之间的距离、交通方式等信息进行路线规划。
②实时交通状况监测:通过地名实体识别技术对社交媒体等数据进行处理,识别出与交通相关的地点信息,如交通拥堵的路段、事故发生地点等,并根据这些信息进行实时监测和分析,提供交通状况报告。
③交通事件发现:利用地名实体识别技术对新闻报道等数据进行处理,识别出与交通相关的事件信息,如道路施工、交通事故等,并根据这些信息进行分析和挖掘,提供相关的预警和管理建议。
④地名标准化:在地址数据管理中,地名实体识别技术可以识别出重复地址、错别字等问题,并进行标准化处理,提高地址数据的准确性和可靠性。
从整体上看,所有这些领域相关的信息都可以被认为是无处不在的地名信息,这为研究人员提供了充分的利用这些数据的机会。关于地名位置地址数据的描述,它从相关文本中识别地名并将它们与一组具体的地理位置数据关联起来,在自动理解各种自然语言文本的语义信息方面发挥着重要作用[6]。例如,在2022年9月13日至15 日的“梅花”台风中,检索到以下险情:“苏州市万佳花苑小区空调外机支架脱落,悬挂高空”和“树木被台风吹倒,堵塞交通”。当紧急情况发生时,从这些文本中提取位置信息对救援规划和决策至关重要,因为它们提供了受灾害影响地区、风险人群的位置以及需要救援和医疗援助的人的关键信息。
1.2 地名识别研究的难点
由于带有地名标记的自然语言文本非常稀疏,自然语言地名的自动提取非常具有挑战性。根据研究,只有很少的自然语言文本包含地名标签,而这些标签很少能反映相关人员的精确地理位置。因此,从自然语言文本中准确地提取和识别地名是必要的。
目前,针对地名实体识别研究仍存在一些问题:
(1)地名歧义问题。地名歧义是指一个地名可能有多种含义或解释,造成对地名含义的不确定或模糊。例如,迪士尼乐园可以指上海的迪士尼乐园,也可以指中国香港地区的迪士尼乐园。在自然语言处理中,地名歧义经常会导致语义理解的错误或混淆。为了解决这个问题,需要进行地名消歧,即在上下文中确定一个地名实体的具体含义。在一些具体的应用场景中,如地图应用或者导航系统中,地名歧义可能会造成更为严重的后果,因此进行地名消歧尤为重要。
(2)地名嵌套问题。地名嵌套是指在地名中包含另一个地名的情况。在某些情况下,地名嵌套可能导致歧义,因此在自然语言处理中,需要对地名嵌套进行识别和处理。例如,在“苏州市虎丘区学府路苏州科技大学石湖校区”中,虎丘区是苏州市的一个行政区划,学府路是虎丘区的一条街道,而苏州科技大学石湖校区则是学府路上的一个POI 地名实体。这个地名包含了多个地名,其中虎丘区嵌套在了苏州市中,学府路则嵌套在虎丘区中。在地名实体识别中,需要对这种地名嵌套进行识别,以便更准确地理解地名实体的含义。
(3)未登录地名问题。未登录地名指的是在地名识别过程中,没有出现在预定义地名词典中,无法被识别的新地名。未登录地名的出现可能有多种原因,包括地名发生变化、地名使用场景的变化、新地名的出现等。例如,近年来高新科技园区和商业中心的兴起,这些地方的名字可能没有被纳入到地名词典中,因此在命名实体识别过程中可能无法被正确识别。
(4)语境依赖问题。地名的含义通常是依赖于上下文语境的,例如在“我想去巴黎”和“我想去巴黎贝甜买点蛋糕”中,前者“巴黎”指的是法国巴黎城市,后者“巴黎”指的是一家蛋糕店铺,但是这个差异需要在上下文中才能确定。
1.3 数据集和训练资源
由于地名识别的应用领域相对于其他任务领域比较广泛,并且数据来源也比较杂,大多来源于社交媒体,所以基本都是非正式的数据集(即推特或微博),所以收集了32 个非正式的英文数据集(如表1 所示)和5 个常用的中文数据集(如表2 所示)。它们可以根据数据集的用途分为:地名实体识别(TER)和命名实体识别(NER)。前者只标注地名,后者不仅标注地名,还标注其他类型,如人名、组织机构名和其他实体类别。
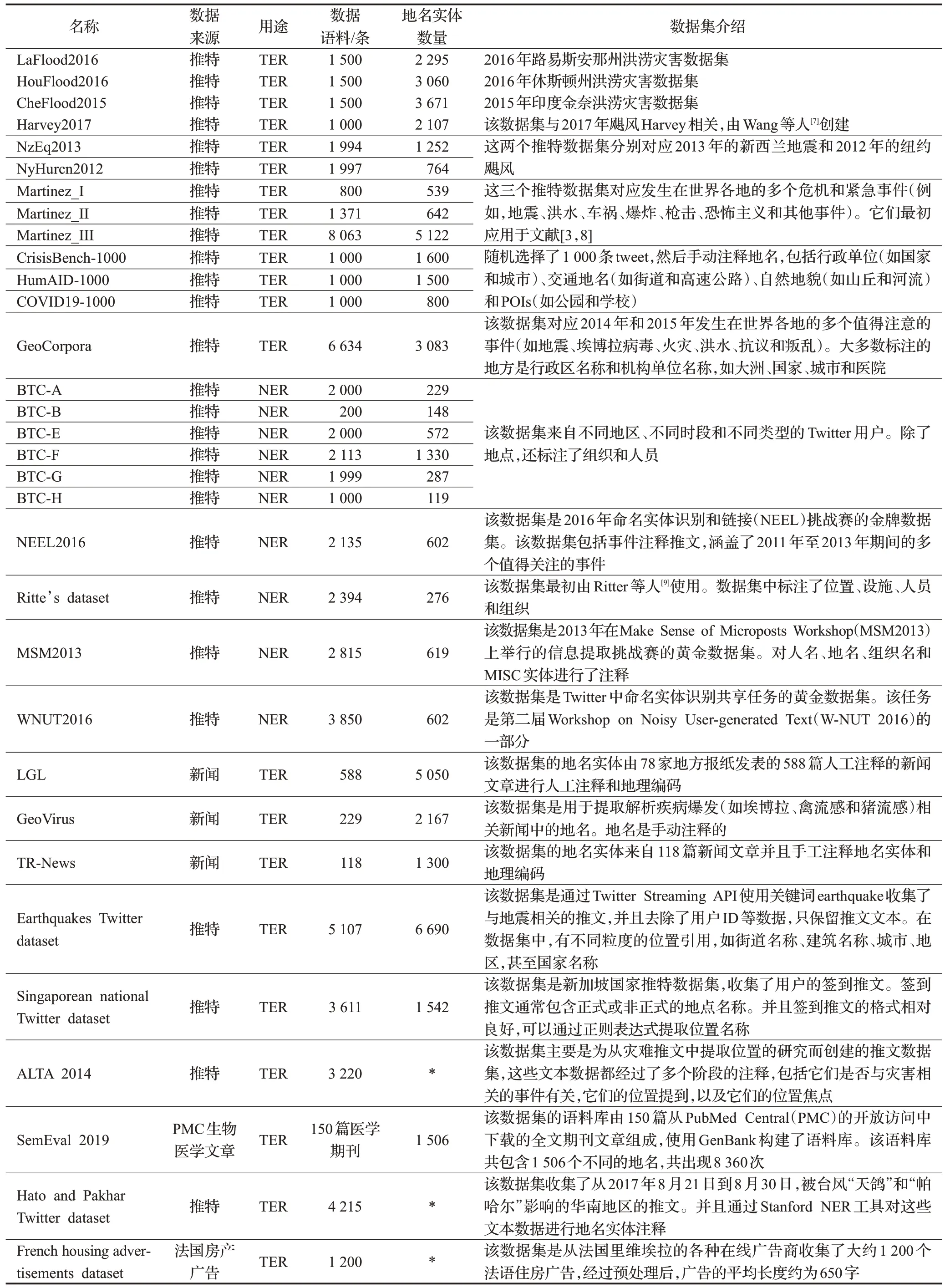
表1 非正式的英文地名识别数据集Table 1 Informal English toponym recognition datasets
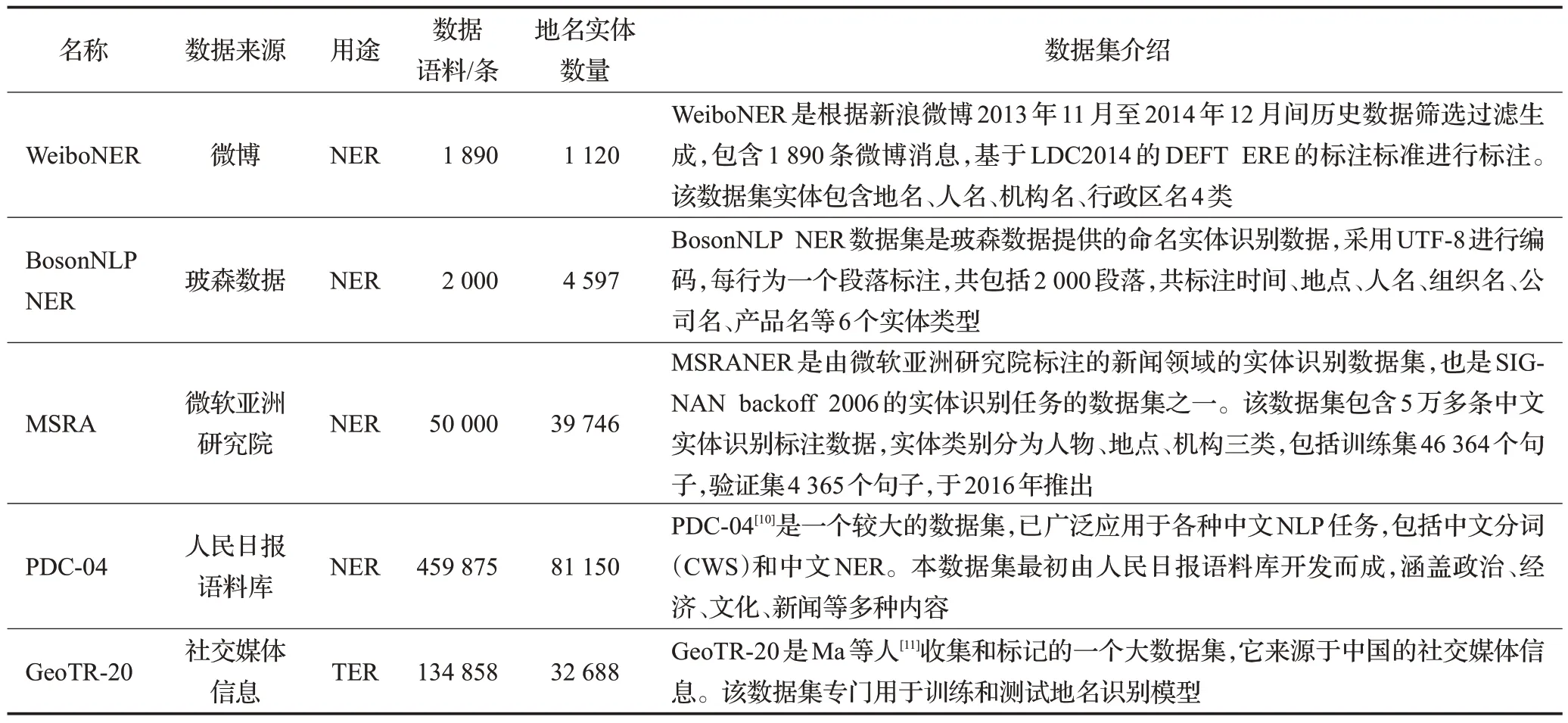
表2 通用的NER中文数据集和中文地名识别数据集Table 2 General NER Chinese datasets and Chinese toponym recognitions datasets
从表1 可以看出大多数的数据集都是来源于社交媒体的灾难事故信息,比如地震、台风、洪涝灾害等。对灾难事故信息的地名信息处理往往会涉及到细粒度的地名实体,比如街道地名、楼宇店铺门牌号等,因为在灾难过后的救援需要精确的地名信息定位,从而实现救灾资源的实时配置。
1.4 评价指标
采用精度、召回率和F1-score三个标准指标来评价深度学习模型的地名识别性能:
TP 表示被正确识别地名实体的数量,FP 表示非地名实体但被识别为地名实体的数量。此外,FN 表示被标记为地名实体但未被识别的实体数量,TN 表示被标记为非地名实体且被识别为非地名实体的数量。精度是通过正确识别的实体数量除以识别的地名实体总数来计算的。召回率的计算方法是:正确识别的实体数量除以语料库中地名实体的总数。F1值表示精度和查全率的调和平均值,该指标代表地名识别的整体性能。在本文的研究中,只有所有地名实体标签的预测都是正确的,才能认为它们是正确的。
2 地名实体识别的方法
由于地名实体识别是命名实体识别的子任务,所以根据地名实体识别的发展历程,主流的TER方法可以分为3类:基于规则和词典的方法、基于统计机器 学习的方法和基于深度学习的方法,这3类方法根据处理特点又细分为若干种不同的子方法,比如,基于深度学习的可以根据使用的模型细细划分。后面的内容将围绕该分类方法分别进行详细阐述。
2.1 基于规则的地名实体识别方法
早期的TER 方法[12]主要运用由语言学专家根据语言知识特性手工构造的规则模板,通过匹配的方式实现命名实体的识别。针对不同的数据集通常需要构造特定的规则,一般根据标点符号、关键字、指示词、方向词、位置词和中心词等特征来构造。早期,Gelernter等[13]根据语法规则为英语和西班牙语建立了相对应的词语组合分析器,基本规则是一个或多个形容词加上一个或多个名词组成一个短语。其中分块算法的差异主要来自于西班牙语和英语的语法差异,以及它们各自的词类标记器带来的差异。Leidner 等人[14]综述了如何基于语法规则来识别地名实体。Giridhar等人[15]根据描述位置的短语总是由名词(NN)、限定词(DT)、形容词(JJ)、基数词(CD)、连词(CC)和名词所有格结尾词(PE)组成,根据这种语法规则来提取地名实体。
虽然基于规则的方法很早便提出,但用于特定领域,其准确率也较高。在近三年的文献综述中,MartíNez等人[8]提出了LORE 系统,LORE 是一个概念证明应用程序,利用语言知识和NLP 技术在短文本中进行位置提取,它的主要目标是如何通过LORE中的基于知识的规则自动检测这些地名实体。在LORE系统中,地名实体这一部分是基于语言的规则来抽取的,主要通过关注推特文本类型的语言特质和自然语言的地理空间特征来进行语言模式的提取。深入分析了n维数组的不同组合和标记的词性以及地名实体在上下文中的位置,如位置介词、位置指示名词和位置标记,这些通常标志着地名的存在。所有这些知识都被整合到正则表达式的表述中,该表达式考虑了上述语言变量。使用英语评价语料库,考虑基于实体的评价标准,该系统的准确率为0.81,召回率为0.81,F1 值为0.81。使用西班牙语评价语料库,准确率为0.64,召回率为0.72,F1值为0.67。但由于模型的限制,只能支持英语和西班牙语,对于其他语言,需要对模型进行微调。
2.2 基于地名词典的地名实体识别方法
在地名识别领域中,基于地名词典的方法主要是通过将逐个字符与整个地名词典进行遍历匹配,并搜索预定义的一组地名的出现情况。这些地名存储在地名表中,地名表是地名和相关元数据[16]的数据库。词典通常存储在try树(例如Patricia tries)、散列表[17]和SQL数据库中。早期的地名实体识别技术都是基于词典的较多[18-27],因为那会的数据集不大,用到的领域范围也偏小。
对于近几年基于词典或者是用到词典的技术的文献中,也有不少特色之处。De Bruijn等人[28]为了确定推特文本的地理位置,将推文的文本与地名词典匹配,而且对词典进行了额外的处理,比如,删除了url和标点符号,将文本大驼峰单词全部转换成小写等。Al-Olimat等人[29]使用n-gram统计和位置相关的字典,并且提出一个地名提取工具(LNEx)来处理地名缩写,并自动过滤和扩充地名词典中的位置名称(处理名称缩写和辅助内容),以帮助检测多词位置名称的边界,从而在文本中识别它们。Milusheva 等人[30]使用OpenStreetMap、Geonames 和GooglePlaces 为内罗毕都市区的5 个下属行政区建立了一个地名词典。地名词典包括地标名称、地理坐标和地标类型(例如:学校、公共汽车站)。Milleville 等人[31]提出了一种以地名检测和地名匹配为核心的地名识别算法。对于人来说,这些地名地址相对容易阅读和理解,但对于机器来说却很难自动处理。地名词典可用于将识别出的地名实体与现实世界的地名进行匹配,从而提高注释质量。当部分地名被识别出来时,可以基于相对位置进行模糊匹配,从而将潜在候选地名限制在该区域。然后,使用字符串相似度对识别的文本与候选地名进行匹配。Ahmed 等人[32]针对交通类的推特文本进行一种实时的提取交通拥堵信息的方法,其中会涉及地名信息的提取,为了自动识别地名,作者使用公开数据创建了城市中所有主要位置和道路名称的列表。每个位置名称和推文中的所有单词都被标记,从而将推文和位置名称表示为单个单词的列表,然后使用Jaro-Winkler方法[33]查找位置中的每个单词和推文中的单词的相似性。当相似度大于一个给定的阈值时,这个词被标记为地名词。
综上所述,本文针对基于规则方法和基于地名词典方法进行了比较分析,具体如表3所示。尽管基于规则和地名词典的地名识别方法使用简单,但是需要手工制作匹配规则模板并且制作地名词典更是需要大量的时间成本,为了保证准确率,甚至每隔一段时间需要手动更新地名词典。为了解决上述问题,一些专家学者研究了统计机器学习的地名实体识别方法[34]。

表3 基于规则和基于地名词典方法对比Table 3 Comparison of rules-based and gazette-based methods
2.3 基于机器学习的地名实体识别方法
基于统计机器学习的方法必须建立在带有注释的训练语料数据集上,并且带注释的语料库要通过人工定义的特征来训练模型,例如字符串的长度、大小写和上下文特征,以及深度学习算法自动学习的特征。然后将训练好的模型应用于未标记的文本。基于统计学习的方法通常使用传统的机器学习模型,如随机森林(random forest)[35]等。通过统计以往文献的地名识别方法,将基于统计学习的方法进一步分为两组:一是基于统计机器学习的地名实体识别工具,而是基于统计机器学习算法的地名识别。下面,将分别讨论这两组方法。
地名实体识别是命名实体识别的一个子任务,已经得到了广泛的研究。因此,许多研究[2,3,5,36-42]使用现有的基于统计的NER工具从文本中提取位置参考。
Linga 等人[38]研究了使用命名实体识别器从推特文章中提取位置的可行性,分别使用了OpenNLP、TwitterNLP[9]、Yahoo!Placemaker和Stanford NER从2 878条与灾难相关的推特文本中提取地名。Stanford NER和OpenNLP在他们的研究中也通过10倍交叉验证进行了再训练和评估,结果表明,再训练模型的F1得分高于预训练模型。
Karimzadeh 等人[40]提出了名为GeoTxt 的地名实体识别工具,一个可扩展的地理定位系统,并用于识别和定位非结构化文本中的地名。GeoTxt 提供了6 种用于地名识别的命名实体识别(NER)算法,分别是Stanford NER、Illinois CogComp[43]、GATE ANNIE[44]、MITIE、Apache OpenNLP和LingPipe。并利用企业搜索引擎对地名进行索引、排序和检索,实现了对文本的地理定位。
Belcastro等人[2]利用推特来收集灾难发生之后的事故信息,如倒塌的建筑物、破裂的煤气管道和被淹的道路。提取地质坍塌推文是其中的关键任务之一。具体来说,采用CoreNLP[45]工具识别街道和地区名称,然后通过与当地地名词典匹配对这些名称进行地理编码,从而与灾区相关联。Fan等人[3]通过使用Stanford NER提取地名实体,然后过滤和地理编码,只保留谷歌地理编码API中匹配的地名,从而来揭示灾难事故的发生。
Mircea[41]实现了一个全球COVID-19信息规模的可视化界面,用于COVID-19 推文的实时分类、地理定位和交互式可视化。spaCy-NER20 可以从推特内容和用户资料中提取城市和国家。Suat-Rojas等人[42]利用一个重新训练的spaCy-NER 来检测和分析哥伦比亚市的西班牙语推文中的交通事故。
综上所述,本文针对基于机器学习的地名实体识别主流工具进行了总结,具体如表4所示。

表4 基于机器学习的地名实体识别主流工具总结Table 4 Summary of main tools for toponym entity recognition based on machine learning
除了使用或再训练现有的NER 模型工具外,许多研究还通过使用机器学习算法[6,46-52]来训练自己的地名实体识别模型。
Nissim 等人[51]提出了一个使用现成的最大熵标记器[53]来识别苏格兰历史文献中的地名实体,最大熵标记器使用内置的C&C 标准特征来训练和测试Curran 和Clark(C&C),这包括一组形态学和正字法特征,以及单词本身的词性标记和上下文特征的信息。该模型评估了648 份苏格兰历史文献,共10 868 句语料,5 682 个地名实体。
Habib等人[46]提出一种基于隐马尔可夫模型(HMM)和支持向量机(SVM)的混合方法来进行地名提取。作者将带有地名标注的训练数据用于训练HMM[54],进而用于地名提取。首先使用训练过的HMM 模块从训练集中提取地名,接着将提取的地名与GeoNames地名表进行匹配,并且将训练好的HMM 应用于测试集,提取的地名将与GeoNames进行匹配,并消除它们的候选地名的歧义。最后计算地名的信息性和相干性特征,并将其输入经过训练的支持向量机中,得到最终的地名提取结果。
Sobhana 等人[47]提出基于条件随机场(CRFs)的地质文本命名实体识别(NER)系统的开发,不同类型的地质命名实体指的是国家、州、城市、地区、山、岛屿、水体、河流、村庄等,然后利用机器学习算法对这些地质实体进行识别、分类。
由于地名实体识别任务和传统的命名实体识别任务不同,TER 任务有着特殊领域的需求,所以并没有地名实体识别领域通用的训练数据资源,而大多数数据集都是不同笔者根据应用场景的需要制作的数据集。为了避免使用监督学习模型却缺乏足够的注释数据而产生较差的性能,Kamalloo等人[6]提出了一个无监督模型来解决训练资源少的地名实体识别问题。该方法仅仅依赖于文档内容和地名词典,它利用文档的上下文特征以及地名的空间关系来产生一个连贯的地名识别解析任务。并且实验数据表示上下文层次融合的无监督模型,在精度上优于拓扑聚类算法。
综上所述,本文针对基于统计机器学习的地名实体识别方法进行了比较分析,具体如表5所示。

表5 基于统计机器学习的地名实体识别方法比较Table 5 Comparison of toponym name entity recognition methods based on statistical machine learning
2.4 基于深度学习的地名实体识别方法
近年来,深度神经网络模型已被开发出来,并在NER 方面取得了非常好的效果,特别是在地名识别方面[7,55]。深度学习可以看作是一种由多层神经网络构成的机器学习算法[56-61]。深度学习最大的特点是具有较强的泛化能力,可以从原始数据中自行获取特征,而且不依赖于专家知识和人工特征。在NLP领域中,深度神经网络模型的本质是对文本序列数据进行处理,主要将输入的字词编码成高维向量,并利用该向量通过神经网络层将单词映射到标签空间,实现地名标签和其他标签的分类。基于以上所述,本文将基于深度学习的地名实体识别方法分为基于深度学习模型的NER 工具、主流的神经网络深度学习模型和混合方法模型。
2.4.1 基于深度学习的NER工具
最近,有关地名实体识别的基于深度学习的NER工具也被大量使用。例如,Limsopatham 等人[62]提出通过BiLSTM 特征提取工具和使用字符嵌入和单词嵌入自动学习正字法特征来识别推文中的名称实体。Akbik等人[63]提出了Flair,这是一种使用上下文字符串嵌入进行序列标记任务的NLP 工具,如词性标记(POS)和NER。Qi 等人[64]提出了一种名为Stanza 的基于深度学习的NLP工具包,该工具包采用了基于上下文的字符串表示标记器。近年来,全连接自注意体系结构(又称Transformer)因其在上下文建模方面的并行性和优势而备受关注。例如,Ushio 等人[65]提出了一个用于NER 模型微调的python 库,命名为T-NER。它支持基于Transformer 的NER 模型的培训和测试。来自不同领域的9个公共NER 数据集被编译为T-NER 库的一部分,如CoNLL 2003、ontonoot 5.0和WNUT 2017数据集。
2.4.2 卷积神经网络模型
卷积神经网络是一种多层的监督学习神经网络,隐含层的卷积层和池化层是实现卷积神经网络特征提取功能的核心模块。卷积神经网络在计算机视觉中广泛应用,并且在图像处理方面展现出强大的计算能力,所以研究学者们将其进行领域迁移,将CNN 应用在自然语言处理领域,进行序列问题处理。
Gritta 等人[66]提出了一种名为CamCoder 的地名解析方法,该方法结合了卷积神经网络(CNNs)、用于输入表示的单词嵌入和用于位置名称的地理向量表示来解析地名。通过CamCoder与NER工具,并将其转换为一个地质传感器,以进行进一步的地名识别。在地名实体识别领域中,Kumar 等人[67]提出基于卷积神经网络(CNN)的模型(如图1 所示)来提取推文中使用的地名位置。该模型通过10 倍交叉验证对5 107 条地震相关推文和6 690个地名进行了评估。该体系结构包括三个部分:向量形式表示推文的词嵌入;卷积神经网络模型;从文本表示中学习显著特征和全连接层,以预测输出。在数据集方面,使用了与地震相关的tweet 数据集,并且数据集包括了一些细粒度的位置信息,如街道、建筑物、城市、地区和国家名称。尽管CNN最大的特点是可以并行化,加快运行计算速度,但它无法更好地处理序列信息。
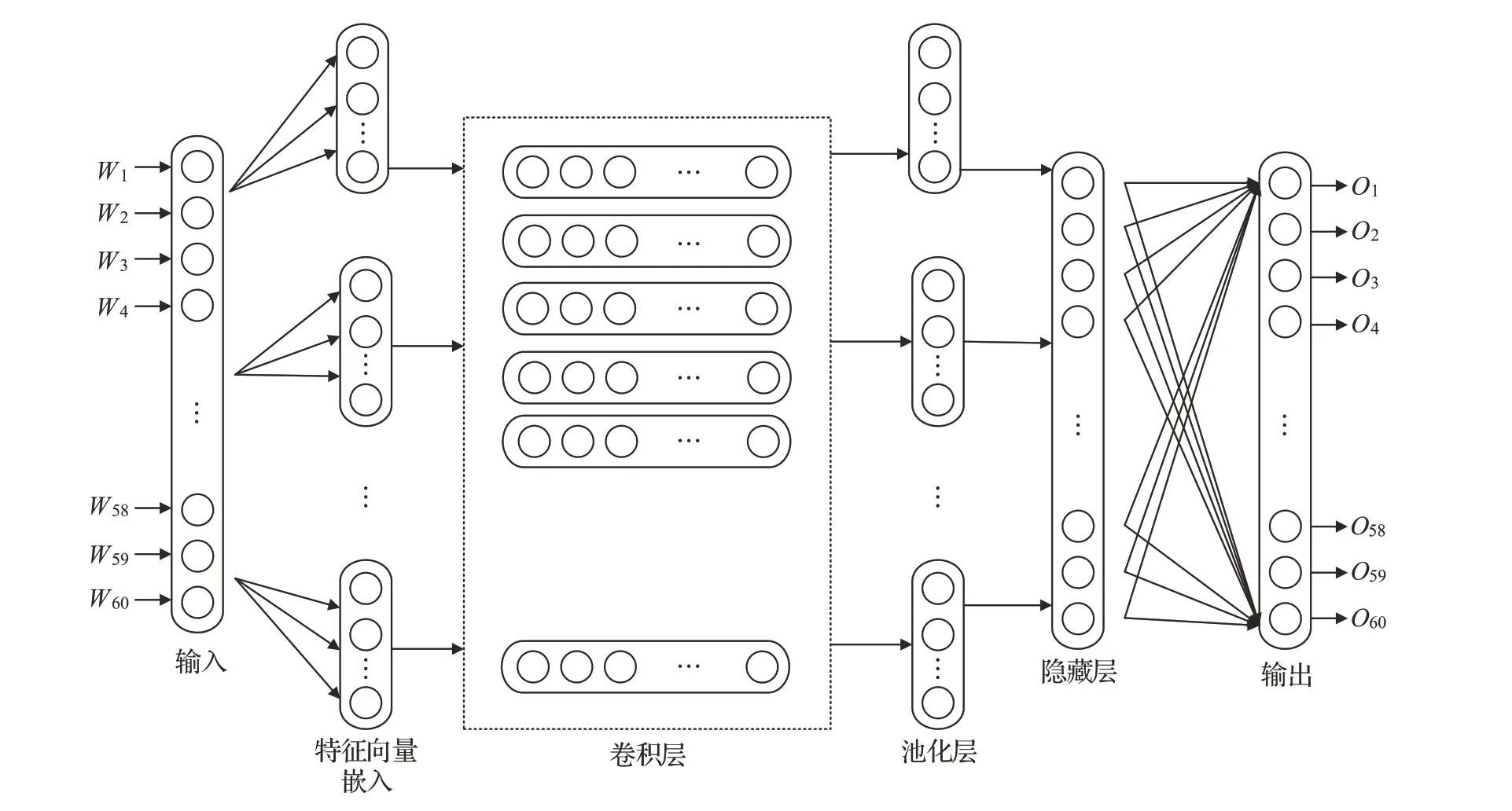
图1 基于CNN的地名实体识别模型Fig.1 Toponym entity recognition model based on CNN
2.4.3 循环神经网络模型
在对序列信息处理的过程中,预测句子的下一个单词时需要用到前面的单词信息,因为一个句子中前后单词并不是独立的,这便是句子的局部特征。
然而,CNN并不能很好地利用单词前后的特征,所以研究学者们提出更适合序列信息的循环神经网络(recurrent neural networks,RNNs)。RNN 已经在众多自然语言处理(natural language processing,NLP)中取得了巨大成功以及广泛应用,它一般以序列数据为输入,通过网络内部的结构设计有效捕捉序列之间的关系特征,一般也是以序列形式进行输出,它的目的是处理序列数据。
RNNs 之所以称为循环神经网路,即一个序列当前的输入与前面的输出有关。具体的表现形式即为隐藏层的输入不仅包括输入层的输出还包括上一时刻隐藏层的输出。理论上,RNNs 能够对任何长度的序列数据进行处理。但是在实践中,为了降低复杂性往往假设当前的状态只与前面的几个状态相关。
然而,传统的RNNs 有一个致命的缺陷——“梯度消失”。所谓“梯度消失”是RNN 模型当前的输出与之前的输出有关,一旦序列信息逐渐增加导致过长,模型会逐步丧失“学习能力”。针对RNN在训练过程中容易出现梯度消失和梯度爆炸的问题,专家学者对RNNs进行改进——长短期记忆网络模型。
2.4.4 长短期记忆网络模型
LSTM(long short-term memory)也称长短时记忆结构,最早是由Hochreiter 等人[68]于1997 年提出它是传统RNN的变体,与经典RNN相比能够有效捕捉长序列之间的语义关联,缓解梯度消失或爆炸现象。
在地名实体识别研究方向中,使用LSTM模型的也不在少数,甚至后续的模型都是基于长短期记忆网络的基础上改进的。Xu等人[69]提出了DLocRL,一种用于推特中细粒度位置识别和链接的深度学习管道,模型如图2所示。具体地说,他们首先使用BiLSTM-CRF来训练兴趣点(POI)识别器。然后,给定输入对

图2 基于BiLSTM的地名实体识别模型Fig.2 Toponym entity recognition model based on BiLSTM
Mao等人[4]提出了一种新的基于深度学习的Twitter停电检测框架,利用双向长短期记忆网络模从推特文本中提取停电位置,从而来应对停电事故引起的事故灾害。方法上,使用的深度学习模型是双向LSTM模型和CRF,它不需要任何先验知识,也不需要任何字词嵌入编码,也不依赖其他NLP 工具进行预处理(如词性、分块)。因此,它可以很容易地适应新的数据,而且自动准确地检测社交媒体文本中的位置,那么应急人员可以利用这些数据找到需要帮助的人,并且从数据训练资源的角度来说,这有助于解决位置标记数据稀缺的问题,并显著增加了大量带标注的数据。
2.4.5 Transformer网络模型
在2.4.3 和2.4.4 小节中,介绍了RNN 和它的变体。由于RNN 能够处理长序列输入,这些结构已经成为许多自然语言处理任务的首选模型方法,例如语言建模[71-73]、机器翻译[74-77]以及句法解析[78-80]。然而,RNN 只有轻微的并行性,这意味着计算资源不能在训练过程中得到充分利用,从而导致了一个非常耗时的训练过程。
为了缓解这一问题,Vaswani 等人[81]提出了Transformer架构。Transformer模型基于注意机制,并使用自我注意层来学习单词表征。在序列数据的背景下,Transformer 架构优于经典的神经结构方法,如RNN 或CNN,并且基于三个重要的标准:计算复杂度、并行性和长期依赖建模。
其中,Devlin 等人[82]提出了BERT 模型,即来自Transformer的双向编码器表示的简称,这是一种完全基于Transformer 的语言模型架构。BERT 架构由多层双向编码器组成,并且是通过两种具有相同架构的模型大小引入的:BERTBase 和BERT-Large。由于BERT 模型的强大,使得自然语言处理领域的各个方向都有BER模型的身影。
比如,Davari[83]提出了一个基于BERT 的地名识别模型(模型如图3 所示),模型使用预先训练的BERT 作为主干,并对两个领域的数据集(通用文章和医学文章)进行微调。模型首先将带有地名的句子的文字片段序列构成模型的输入,然后将这些序列令牌传递到一个预先训练过的BERT网络,接着将网络的输出以及某些语言特征传递到一个全连接层,该层决定了每个令牌的标签,并识别出地名标签。
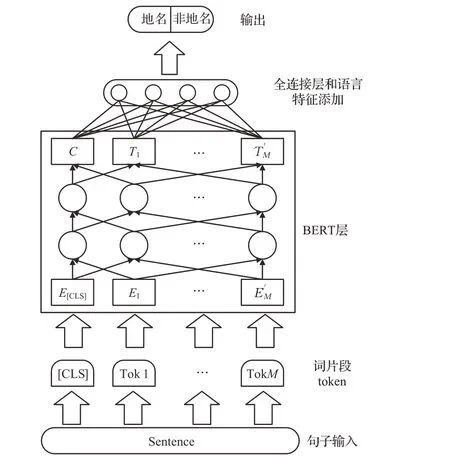
图3 基于BERT的地名实体识别模型Fig.3 Toponym entity recognition model based on BERT
在2022 年年初,Ma 等人[11]提出基于BERT 模型的中文地名识别方法。Ma等人[11]提出了一种深度神经网络BERT-BiLSTM-CRF,该网络扩展了基本的双向递归神经网络模型(BiLSTM),并且BERT-BiLSTM-CRF 模型利用字符嵌入和预训练词嵌入对输入序列进行编码,然后对这些序列信息进行预处理,从而实现对输入的中文地名进行分类,并用于处理中文文本地名识别任务。
2.4.6 弱监督深度学习模型
现有的具有最先进性能的地名识别方法主要利用监督学习(即基于深度学习的方法),从必须手动注释的海量标记数据集学习参数。当模型训练需要适应不同的领域文本,特别是那些社交媒体消息时,这是一个很大的不便。所以Qiu等人[84]提出了弱监督中文地名识别器ChineseTR。它首先根据单词集合和来自不同文本的相关单词频率生成训练示例。在训练实例的基础上,探讨了一种基于BERT词嵌入的BiLSTM-CRF网络用于训练地名识别器。在三个中文NLP数据集(即WeiboNER、Boson和MSRA)上对该方法进行了评价。
综上所述,本文针对基于深度学习的地名实体识别方法进行了比较分析,具体如表6所示。

表6 基于深度学习的地名实体识别方法比较Table 6 Comparison of toponym entity recognition methods based on deep learning
2.4.7 混合方法模型
通过以上对深度学习网络的解析,可以大致了解序列模型的运行原理。但是对于现阶段的地名实体识别领域来说,想要更高准确度的模型,基础的模型架构总是不够的。所以,人们在基础的模型架构对其进行改进加强,通常的做法是融合其他的特征来增强原始的文本表示,从而更好地提取实体信息。
(1)上下文字词嵌入特征与主流模型混合
Cadorel 等人[85]提出了一个基于BiLSTM-CRF 的体系结构通过将其应用到法国房产广告的案例来展现此模型,这些广告通常提供了关于房产位置和社区的信息。模型结构的第一个阶段是命名实体识别模块,它提取上面提到的所有实体。该模型基于BiLSTM-CRF架构[57],在NER 任务中取得了很好的效果。同时还向BiLSTM-CRF添加了特征嵌入,这是一个由三种不同文本形式(CamenBERT[86]、Flair[63]和Word2Vec[19])的拼接组成的全局向量,以捕获不同级别的特征。
Wang 等人[7]提出从维基百科文章中生成带标签的训练数据来训练一个名为NeuroTPR 的BiLSTM 模型。他们的模型包含若干层来解释Twitter 文本中的语言不规则性,例如使用字符嵌入来捕获单词的形态学特征,以及使用上下文嵌入来捕获推文中的标记的语义。
在不同应用场景中,Chen等人[87]也提出了类似的框架,一种基于BiLSTM-CRF 神经网络的深度学习模型,用于识别社交媒体信息中局部地理实体。测试了单词嵌入、字符嵌入、POS 标记、大写和介词的五个特征,以评估它们区分地名实体标签和非地名实体标签的能力。研究发现,POS标签对分类的贡献最大。
(2)基于规则、地名词典与主流模型混合
本文在对基于规则和词典的传统算法的论述中,发现许多研究将基于规则的方法归为一类[14,29,88],或者将基于词典的方法归为一类,但纯基于规则或者词典的方法很少。所有在文献[88]中讨论的基于规则的方法实际上都是混合方法。这可能是因为仅依靠语言模式的方法是无效的。以一种完整而健壮的方式来定义规则,并且识别文本中所有可能出现的地名实体,这仍然是一个挑战,尤其是在写作风格变化巨大、语法薄弱的推特语料中[9]。但是,可以使用一组简单的规则来增强地名词典匹配和基于深度学习的方法,这将在以下的内容中介绍。
在这种混合方法中,地名词典的使用主要有两种方式:一种将统计学习模型的检测结果与地名匹配相结合;另一种使用地名匹配结果(例如,是否有n-gram在地名中)作为机器学习模型的输入特征。
第一种方法的例子有文献[46,70,89-90]。例如,为了改善用户从数字图书馆中搜索所需资源的体验,Freire等人[89]提出了与数字资源相关的描述性元数据记录地质arsing。通过将记录的令牌与GeoNames中的候选数据相匹配,来识别初始位置实体。然后通过随机森林分类器消除歧义,并将初始位置实体链接到最终的地址数据。
Li 等人[70]提出识别推文中的POIs。推文中的候选POIs首先通过与一个POI清单进行匹配来提取,该清单是根据Foursquare 中的签到数据库构建的。然后利用一个基于CRF的时间感知POI标记器,根据文本中的上下文特征去除候选POI的模糊性。
第二种方式的例子包括文献[48,91-94]。例如,Inkpen等人[92]训练了三种CRF模型,用于基于手工定义的特征(包括地名词典特征)来识别国家、省/州和城市等地名。这些模型的目的不仅是检测推文中的位置引用,还将其分类为三种类型。通过对6 000条推文(包含1 270 个国家、772 个省或州和2 327 个城市)进行10 倍交叉验证,对模型进行了评估。
为了支持病毒系统地理学研究,Weissenbacher 等人[48]提出通过使用CRF 模型来识别与病毒相关的GenBank记录相关的研究文章中的位置参考。词法(即POS标记)、语义和地名词典特征。
还有一些研究将基于规则、词典和机器学习三种技术结合起来进行位置参考识别[1,12-13,93,95-96]。例如,Gelernter 等人[13]提出了一种针对推文的跨语言位置参考识别,通过使用地名表匹配、基于规则的建筑解析器、基于规则的街道解析器和经过训练的基于CRF的命名实体解析器,将命名位置解析器的结果结合起来。街道和建筑解析器的规则是基于POS标签和指示词创建的,例如形容词+名词和街道和建筑指示词(例如,英语中的“street”和“highway”,西班牙语中的“calle”和“carreterra”)。
Magge等人[93]提出了一种基于深度神经网络的NER,用于生物出版物中的地名检测,该系统在不使用任何手工特征的情况下优于以往最先进的系统。所有提出的模型通过两个公开可用的预先训练词嵌入进行评估。该论文展示了如何使用远程监督来生成更多的训练数据,以提高NER 的性能。其中该论文提出的所有模型都取得了较高的性能,其中最优的F1-score 为0.927,短语F1-score为0.915。所提出的基于深度神经网络的NER具有足够的通用性,可用于可靠地检测生物医学文本。
最近,Hu等人[95-96]为推文提出了两个地名提取器。第一个提取器被命名为GazPNE[95],它是一个神经网络分类器,主要基于美国地区和印度地区的OpenStreetMap中的地名以及由规则合成的非地名进行训练。由于GazPNE对上下文信息的使用有限,仍然存在歧义问题,因此开发了第二种更强大的方法GazPNE2[96]。它利用两个预先训练的变压器模型,BERT和BERTweet[97]来消除检测到的位置引用的歧义,并在19 个公共Twitter 数据集上获得0.8的改进F1得分。
综上所述,本文对使用混合模型的地名实体识别方法在融合特征和每个方法的特点进行总结归纳,具体如表7所示。
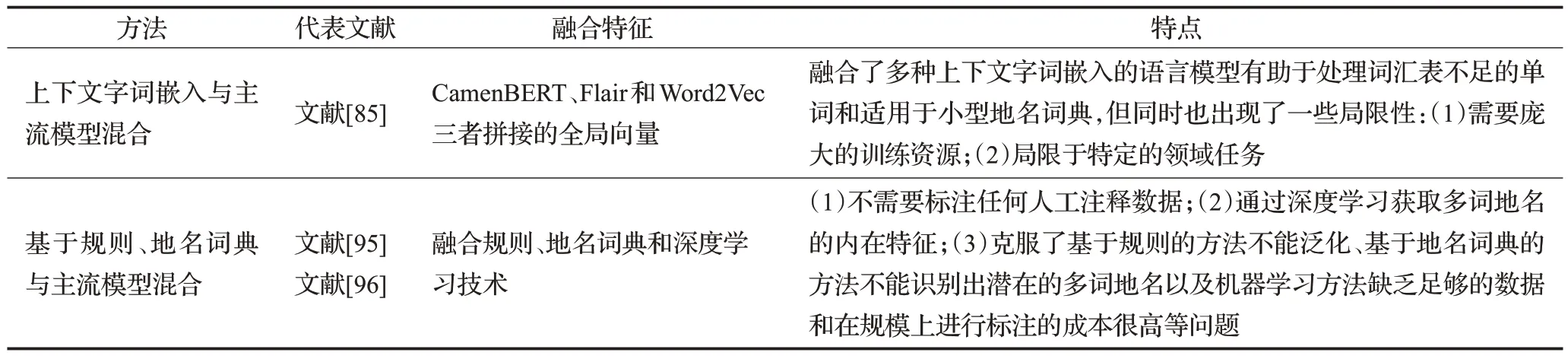
表7 使用混合模型的地名实体识别方法总结Table 7 Summary of toponym entity recognition methods using hybrid models
3 TER模型性能对比和展望
3.1 不同模型的性能对比
为了让读者能对主流TER 模型有一个直观的了解和对比,本文列举了具有代表性的深度学习模型在各自数据集的性能表现。
从表8可以看出,大多数主流模型结构都来自基于序列模型、基于预训练BERT 类模型以及混合模型,对于卷积神经网络模型却很少涉及。这是由于大多数TER 任务的数据都以序列信息为主,而CNN 网络结构并不适用于序列信息。在对主要的网络结构的解读中,发现大多数网络结构都有底层的字词特征嵌入,这主要集中在LSTM及其改进模型上,并且从表格上可以看出字词嵌入模型和LSTM 模型的融合在性能数值上得到了有效的验证。发现基于预训练BERT 类模型的主要网络结构并没有大面积地加字词嵌入特征表示,为此做了基于词嵌入的地名识别方法与基于预训练BERT 类模型的地名识别方法的比对分析,具体如表9所示。除了模型的网络结构对TER性能有较大的影响外,数据集的优劣同样对TER 性能有着重大影响。通过表8 的性能表现,可以看出在同一BERT 模型结构下,Boson 数据集的TER 性能数值比MSRA 数据集低了许多,同时MSRA数据集的TER性能数值又略低于人民日报PDC-04数据集,这说明质量较高的数据集有助于模型性能的提升。
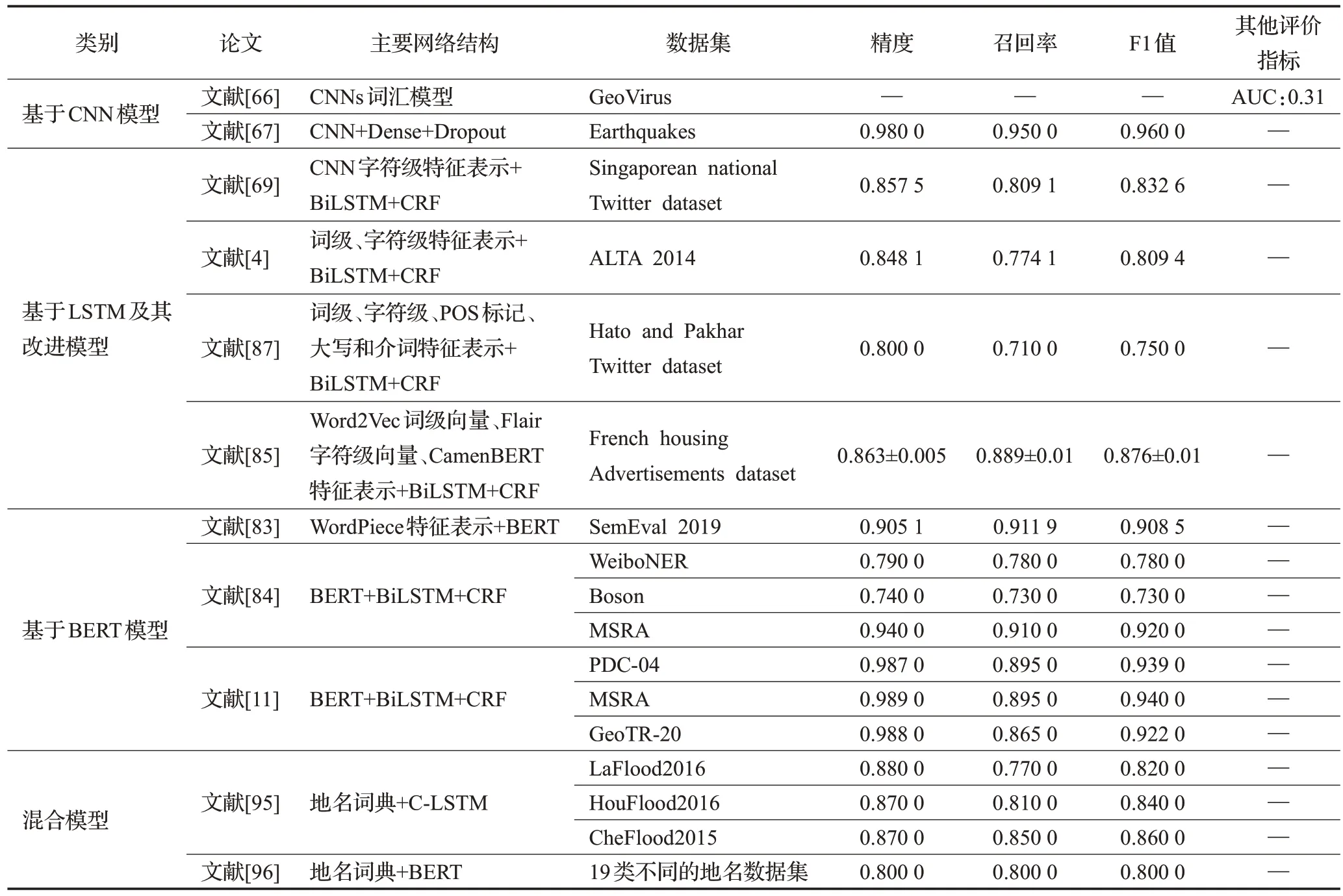
表8 主流模型在不同数据集的性能表现Table 8 Performance of mainstream models in different datasets

表9 词嵌入模型与预训练模型的地名识别方法比较Table 9 Comparison of place name recognition methods between word embedding model and pre-training model
综上所述,总结了4 类模型的性能对比,分别是基于CNN模型、基于RNN及其改进模型、基于BERT模型和混合模型。在这些模型类别中,并不是单单只有一个模型,而是基于一个基本模型和其他特征表示的各种融合。比如,基于RNN及其改进模型,传统的循环神经网络已经不能满足高效处理序列信息的需求,基于RNN的变体模型BiLSTM 可以更好地满足此类需求。在此类模型的基础上融合其他特征向量表示已经是业界内比较受欢迎的模式了,比如基于BERT 的多模型混合,其模型性能已经达到了业内较高水平。未来的研究方法可以从更好的文本特征向量入手,或者融合更加全面健壮的地名词典等特征。
3.2 地名实体识别方法的特殊性
地名实体识别与其他领域,在使用机器学习和深度学习方法时存在一些不同之处,主要体现在以下4个方面:
(1)数据资源的特殊性[98-99]。地名实体识别的数据往往是地理信息数据或者是含有地名信息的非结构化文本[100],其中包含地名实体及其位置等信息,而非传统的NER任务文本数据。因此需要针对数据的特殊性进行处理和分析。
(2)地名实体识别涉及的语言现象较为特殊。地名实体识别任务需要处理各种语言现象,如地名省略、地名错别字、地名歧义等[101],同时还要考虑地名实体的多样性和复杂性。
(3)模型的训练与测试。地名实体识别任务通常需要使用大规模的数据集进行训练和测试,这些数据集包含各种地名实体和语言现象。同时,为了提高识别效果,需要使用多种算法进行组合,构建复杂的模型。
(4)精度要求较高。地名实体识别的应用需要高精度和高召回率,因为地名实体识别是地理信息检索、地图导航等应用的基础,错误的地名实体会导致误导用户。
3.3 地名实体识别展望
目前,地名实体识别技术日渐成熟,但依然需要研究人员投入大量精力进行不断探索,通过对现有TER研究工作进行总结,在以后的研究中可以从下面几个方面展开相关的研究。
(1)针对细粒度的地名实体识别研究。从文本内容中提取精确的地名地址信息是TER的主要任务,并且在许多的应用程序中都是至关重要的。例如,在灾难事故文本或者危险事件中[102],一个精确的地名提取框架可以将相关地点与新闻媒体帖子所讨论的主题联系起来,并确定来自社交媒体的人道主义帮助请求[103]。然而,大多数的地名实体识别任务都集中在泛在宽广的地名识别任务上,比如国家、省市等,缺乏细粒度的、准确的地名地址识别任务模型。细粒度的、精确的地名地址涉及到道路建筑名称、小区住宅、楼栋单元等细粒度的建筑地名[104]。由此可见,细粒度的地名识别任务仍是未来的一个研究热点。
(2)针对中文地名嵌套实体识别研究。由于中文地名构词规则复杂,数量庞大,其取名受区域性、民族性和时代性等因素影响。而且社交媒体数据中存在地名信息表达不规范、实体边界不清晰、地名简化表达等现象为中文地名识别增加了难度。这导致了中文地名出现地名实体嵌套的现象。因此,将各种神经网络、BERT、注意力机制等方法融合用于中文地名嵌套的TER任务仍然值得研究。
(3)针对地名实体消歧研究。在TER任务中不仅仅是对地名实体的精准识别,同时还伴随着对地名的精准定位,即确定它们的地理坐标[105]。然而,在对地名进行精准定位时,会出现一个地名可以指代多个地理位置的情况,这会造成地名歧义。比如,“迪士尼乐园”可以指多个不同的地方,比如巴黎(法国)、加利福尼亚州(美国)、上海(中国),以及其他以“迪士尼乐园”命名的地方。因此,探索更优的地名实体消歧方法来提升低资源的TER模型性能是该地名实体识别领域的重要研究方向。
4 结束语
地名实体识别是自然语言处理的重要任务之一,为许多领域提供基础的数据支持。通过本文可以看出,地名实体识别在应对自然灾害、交通管理等领域具有重要应用价值,可以帮助提高灾害应对效率、交通管理智能化程度[106]。同时,地名实体识别的研究不应仅仅依赖于现有的数据集,需要从更广泛的数据资源中进行收集和整理。比如建立通用的非结构化文本的地名数据集。地名实体识别的研究还需要关注多语种[107]、未登录地名等问题,提高技术在多场景下的适用性。面对一项随时都能应用在人们的日常生活的技术,相信未来会有更多的优质模型产生,进而推动整个领域的前进。
