基于CUDA的并行雷达拼图算法研究*
2023-11-18李月安
韩 丰 高 嵩 薛 峰 李月安
国家气象中心,北京 100081
提 要:雷达组网拼图算法是强对流天气短时临近预报系统(Severe Weather Automatic Nowcasting,SWAN)的重要基础方法之一。提高拼图算法的效率,不仅可以提升现有SWAN临近算法序列的时效性,也能更好地应用高分辨率雷达数据,具有重要的实际意义。采用中央处理器(central processing unit,CPU)和图形处理器(graphics processing unit,GPU)混合架构设计并行雷达拼图算法,其中CPU负责雷达数据的解析和调度GPU并行模块,GPU负责大规模数据的并行计算。通过分析计算统一设备架构(compute unified device architecture,CUDA)算法的并行开销和拼图算法的特点,提出并实现了GPU内存管理优化和数据交换流程优化方案,提高了组网拼图算法的效率。对比试验结果表明,基于CUDA的GPU并行拼图算法和SWAN中30线程并行的CPU算法相比,在全国1 km和500 m分辨率的拼图任务上,加速比分别达到3.52和6.82。综上,基于CUDA的并行拼图算法不仅可以提高SWAN短时临近算法序列的时效性,也为更高分辨率雷达资料的拼图提供了技术支持。
引 言
随着观测技术和预报业务需求的发展,气象雷达的分辨率不断提高。2019年,中国气象局启动我国新一代天气雷达的双偏振改造和技术升级,升级后的S波段雷达强度径向分辨率由1 km提升至250 m。同时,为了满足精细化临近预报业务的需求,北京市、江苏省、广东省等地区先后建立X波段双偏振雷达网并投入业务使用(张哲等,2021;苏永彦和刘黎平等,2022;Ryzhkov et al,2005)。雷达径向分辨率的提升对数据的快速处理和客观算法提出了更高的效率要求。
雷达数据的三维组网拼图技术是雷达应用的重要基础方法之一(程元慧等,2020;张勇等,2019)。在进行雷达组网时,首先需要将回波从球坐标转换到等经纬度的直角坐标系下,再通过最大值、均值、距离反比等方案,在多部雷达的观测重叠区进行融合计算(肖艳姣和刘黎平,2006)。拼图计算过程中,涉及插值、坐标系转换、大规模数据网格等问题,计算密集且数据吞吐量大,是对计算资源需求量最大的雷达客观方法之一。以强对流短时临近预报系统(Server Weather Automatic Nowcasting,SWAN)(韩丰和沃伟峰,2018)为例,全国1 km雷达组网拼图算法是临近预报算法中耗时最长的算法,且雷达拼图后续还有风暴识别和追踪算法(Thunderstorm Identification,Tracking,Analysis and Nowcasting,TITAN)、外推等其他客观方法。所以提升雷达拼图的运算速度可以明显提升SWAN临近预报产品序列的时效性。此外,考虑到雷达径向分辨率的提升,将拼图的分辨率提升至500 m时,现有的拼图算法无法在一个观测周期(6 min)内完成计算,不具备业务应用能力。所以将更先进的并行计算技术应用于雷达组网拼图算法中,一方面可以提升现有算法序列的时效性,另一方面也可以更好地应用高分辨率雷达基数据,具有重要的实际意义。
气象部门常用中央处理器(central porcessing unit,CPU)并行技术和基于CPU的分布式计算框架来提高运算能力。王志斌等(2009)通过使用共享存储并行编程(open multiple processing,OpenMP)并行技术和消息传递接口(message passing interface,MPI)编程规范,实现雷达拼图系统的两级并行。吴石磊等(2012)使用多线程技术对全国组网雷达估测降水系统进行效率优化,通过调整计算负载,可以将计算效率提升5倍。SWAN系统设计实现了基于OpenMP的雷达组网拼图算法,使用30个逻辑线程,生成全国1 km分辨率三维拼图产品需约 2 min。
经过多年的发展,CPU性能提升已经逐渐达到瓶颈,多核应用的成本-效益比不断下降,仅仅通过挖掘CPU性能来提升算法效率已经不能满足现有的需求。图形处理器(graphics processing unit,GPU)作为一种新的计算资源,由于其区别于CPU的硬件架构,特别适合解决大规模数据的计算问题。同时GPU并行计算接口的快速发展,也使得GPU在通用计算领域的应用越来越广泛(钱奇峰等,2021;黄骄文等,2021)。
目前国内外也有一些使用GPU加速气象算法的研究成果。Vu et al(2013)、Mielikainen et al(2013)、Govett et al(2017)、Schär et al(2020)、王艺儒(2020)、Wang et al(2021)和肖洒等(2019)等学者将GPU并行技术应用于数值模式,改写相关动力框架和计算模块,在保持计算精度的同时,显著提高模式的运行效率。Olander et al(2021)介绍了GPU在台风定强深度学习模型中的应用。Rukmono et al(2018)、王兴等(2015)和胡荣华(2015)将GPU应用于雷达数据处理和临近预报算法,得到了10倍以上的加速比。
由于GPU程序主要使用图形应用程序接口(application programming interface,API)进行编程,如气象信息综合分析处理系统(Meteorological Information Combine Analysis and Process System)MICAPS4(高嵩等,2017)使用开放式图形语言(open graphics language,OpenGL)开发气象数据渲染引擎。但是图形API并不适用于通用计算任务。因此,比较主流的GPU并行算法一般通过一些标准化的并行编程接口实现。常用的并行计算接口有开放运算语言(open computing language,OpenCL)如王兴等(2015),开源加速接口(open acceleration,OpenACC)如Govett et al(2017)、Schär et al(2020)、肖洒等(2019),计算统一设备架构(compute unified device architecture,CUDA),如Wang et al(2021)等。本文设计基于CUDA的雷达组网拼图算法,通过分析CUDA算法的并行开销和组网拼图算法的流程,提出高效的CPU+GPU的并行拼图算法实现方案。通过和现有SWAN中的CPU并行组网拼图算法对比,获得较好的性能优化和实际效果。
综上所述,本文为了提高SWAN临近客观算法的时效性,更好地应用高分辨率雷达资料,将GPU并行技术应用于雷达组网拼图算法,设计了基于CUDA的并行拼图算法。通过算法性能分析,提出并实现了一种基于GPU内存管理和数据流程优化的方案。对比试验表明,基于CUDA的并行算法能获得超过3.5以上的加速比。
1 基于CUDA的GPU并行计算模型
1.1 CUDA编程模型
CUDA是NIVIDA公司发布的通用并行计算平台和编程模型,它提供了GPU编程的简易接口,如初始化GPU空间,主机和GPU设备间的数据传输等。基于CUDA编程可以构建GPU计算的应用程序,而无需关注底层的图形API。
CUDA是一个异构编程模型,可以协同调度CPU和GPU,共同完成一个计算任务。在CUDA编程模型中,计算资源被分为主机端(host)和设备端(device),其中主机端表示CPU及其内存,设备端表示GPU及其内存。CUDA程序中既包含主机端模块,又包含设备端模块,它们分别在CPU和GPU上运行。
1.2 CUDA并行算法流程
如前文所述,GPU具有独立的内存系统,所以CPU在调度GPU进行并行计算时,首先需要将数据从CPU内存拷贝到GPU内存,最后再将计算结果拷贝回CPU内存。表1是一个典型CUDA算法和CPU算法的执行流程。对比两者可见,CUDA算法多了一次内存的分配,一次内存的释放和两次数据的搬运。可将这四次操作认为是CUDA并行算法所必须的并行开销。下文将通过组网拼图试验,按照表1中的步骤,分析基于CUDA的雷达组网拼图算法效率瓶颈,并给出优化方案。
2 基于CUDA的雷达组网拼图算法设计
2.1 基于CPU并行的雷达组网拼图算法设计
在雷达组网拼图算法中,首先需要每个单站分别进行三维离散化处理,最后将所有站的三维离散化结果拼接到一个大的数据网格中。在多雷达重叠部分,按照雷达融合策略进行取值。目前常用的策略为最大值法、距离反比权重法等。在SWAN中的CPU并行拼图算法和本文设计的CUDA并行算法中,均采用肖艳姣和刘黎平(2006)提出的三维离散化方案,并按照距离反比权重法进行重叠区融合。
SWAN中目前使用的CPU并行拼图算法包括两个并行块。并行块1:由于每个站雷达数据都是独立离散化的,则设计并行方案,在多线程中并行处理不同站的数据;并行块2:在离散化后数据组网拼图过程中,由于不同垂直层之间也是相互独立的,则设计并行方案,并行处理多层的数据拼接。并行块1和并行块2为顺序执行,即先完成全部站点的离散化之后,再进行多站拼图。
雷达三维离散化插值分为两步,首先计算出平面直角坐标系中点P(x,y,z)在以雷达站为中心的球坐标系中的位置(r,θ,φ),随后将雷达基数据用双线性插值的方法插值到直角坐标系中。可以采用预先计算坐标转换查找表的方式,加快雷达数据空间插值的计算速度。当硬盘读取速度大于查找表计算速度时,优化是有效果的。
2.2 基于CUDA的雷达组网拼图算法设计
2.2.1 CUDA并行粒度分析
上述CPU并行拼图算法是合理而且有效的,主要是因为CPU一般只有几十个逻辑核心,且每个核心的计算能力很强,可以处理复杂的任务。将不同的站点和层次分配到单独的线程里面,既可以充分利用所有的核心,还能够充分发挥CPU核心的性能,减少频繁创建、销毁线程的开销。
但是GPU一般有几十个流式多处理器,每个流式多处理器可以同时启动上千个CUDA计算单元,且每一个计算单元的计算能力较弱,不能完成一个站点的三维离散化任务。所以要充分发挥GPU的并行性能,需要设计格点级的并行方案。
2.2.2 CUDA并行拼图算法初步设计
图1给出了CUDA并行拼图算法初步设计流程图。算法采用CPU+GPU并行混合的设计方案。其中,CPU负责雷达基数据的解析和最终拼图产品的输出,GPU负责每一步插值算法的并行计算。整个计算流程分为两个部分,单站的三维离散化插值和多站拼图。在单站三维离散化插值时,由CPU作为主要的调度程序,负责解压、解析雷达基数据,并调用GPU中的三维插值模块,实现并行计算。不同雷达站之间的离散化部分采用串行的方式依次进行。在多站拼接阶段,依然使用CPU作为调度程序,调用GPU中的空间插值模块,实现多站拼图的并行计算。
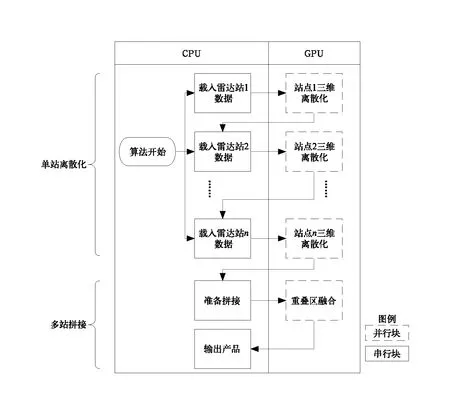
图1 CUDA并行组网拼图算法流程设计Fig.1 Process design of radar mosaic algorithm based on CUDA
2.2.3 效率分析
图2给出了GPU中单站三维离散化并行模块的执行流程。对照表1,GPU并行计算中包括内存管理、数据传输和计算模块三个部分。表2给出了一个单站三维离散化实例(1 km分辨率)和多站拼图(213个站)实例的运行时间分布。表中可以看出单站的三维离散化总计耗时0.483 s,考虑到多站雷达数据三维离散化之间采用串行方式,以表2的执行速度,处理全国大约200个站的数据大概需要80~90 s,再算上CPU解析处理雷达基数据的时间,GPU并行算法和CPU并行算法相比,没有明显的效率优势。由表2可以看出单站离散化过程中有超过99%的运行时间都用在了内存管理和数据传输方面。所以从优化算法和提高效率的角度考虑,应提高内存管理和数据传输部分的效率。多站拼图并行模块的时间分布与此类似,不做赘述。

图2 基于CUDA的单站三维离散化并行模块Fig.2 Parallel module of radar archives discretization based on CUDA

表2 基于 CUDA的组网拼图算法中的耗时分配(单位:s)Table 2 Time consuming in each step of radar mosaic algorithm based on CUDA (unit: s)
2.2.4 改进方案
通过效率分析,本文从内存管理和数据传输两个方面提出CUDA组网拼图算法改进方案。
改进1:以计算代替存储。考虑到GPU计算的耗时明显少于内存管理的耗时,尽可能减少数据存储和设备间的数据拷贝,进而减少内存管理开销。通过表2可以看出,单站离散化中的空间插值表计算和三维离散化插值计算总计用时不到0.001 s。由于存储查找表需要在GPU中申请单独的大数组,其内存管理时间远远大于计算时间。由此,将空间查找表计算和三维离散化插值合并成一个并行计算模块,格点的坐标系转换关系直接存储在GPU中。通过测试,应用改进1后,分配空间的耗时由0.269 s下降至0.202 s。
改进2:增加数据结构复用,避免重复申请和释放GPU内存空间。考虑到CPU以串行的方式调度GPU进行不同站的三维离散化计算,在不同站处理时,部分数据结构可以直接进行复用,减少GPU内存管理开销。在算法开始时,可以一次性申请全部内存空间,并在最后统一进行空间释放,减少内存管理的操作次数。通过测试,应用改进2后,200个站的内存申请耗时0.428 s,内存释放耗时0.192 s,效率提升非常明显。
改进3:以存储代替传输。组网拼图算法的第二步是将单站离散化之后的数据融合拼接到拼图网格上,需要将单站离散化结果从单站模块搬运到多站拼图模块。此处考虑到由于两个并行模块都在GPU中完成,可以将单站离散化结果临时存储在GPU内存中,拼图模块直接从GPU内存读取相关数据进行拼图。应用改进3后,可以省去单站三维离散化模块的数据返回耗时和多站拼图模块的数据传输耗时。
表3给出了改进前后的GPU并行开销对比。在四个对比项目中,除了CPU—GPU传输数据部分是必要开销外,其余三部分都得到了明显优化,并行开销总计时间也得到了显著下降。

表3 改进前后GPU组网算法并行开销对比(单位:s)Table 3 Comparison of parallel overhead of GPU networking algorithms before and after optimization based on CUDA (unit: s)
2.2.5 基于CUDA的并行组网拼图算法设计
综上,图3给出了CUDA并行拼图算法的最终设计,图中n表示雷达站点数。和2.2.2节相比,最终设计增加了对于GPU内存的管理和CPU—GPU数据传输的优化,即上文提到的三个优化方案。GPU完成单站三维离散化计算后,仅发送回调消息,通知CPU开始下一个雷达站数据的处理。拼图模块直接从GPU内存中读取数据,完成计算,最后将拼图产品返回给CPU端。通过数据流和内存管理的优化,组网算法一共只有n次CPU—GPU数据拷贝,1次GPU—CPU的数据拷贝,1次申请空间和1次释放空间。
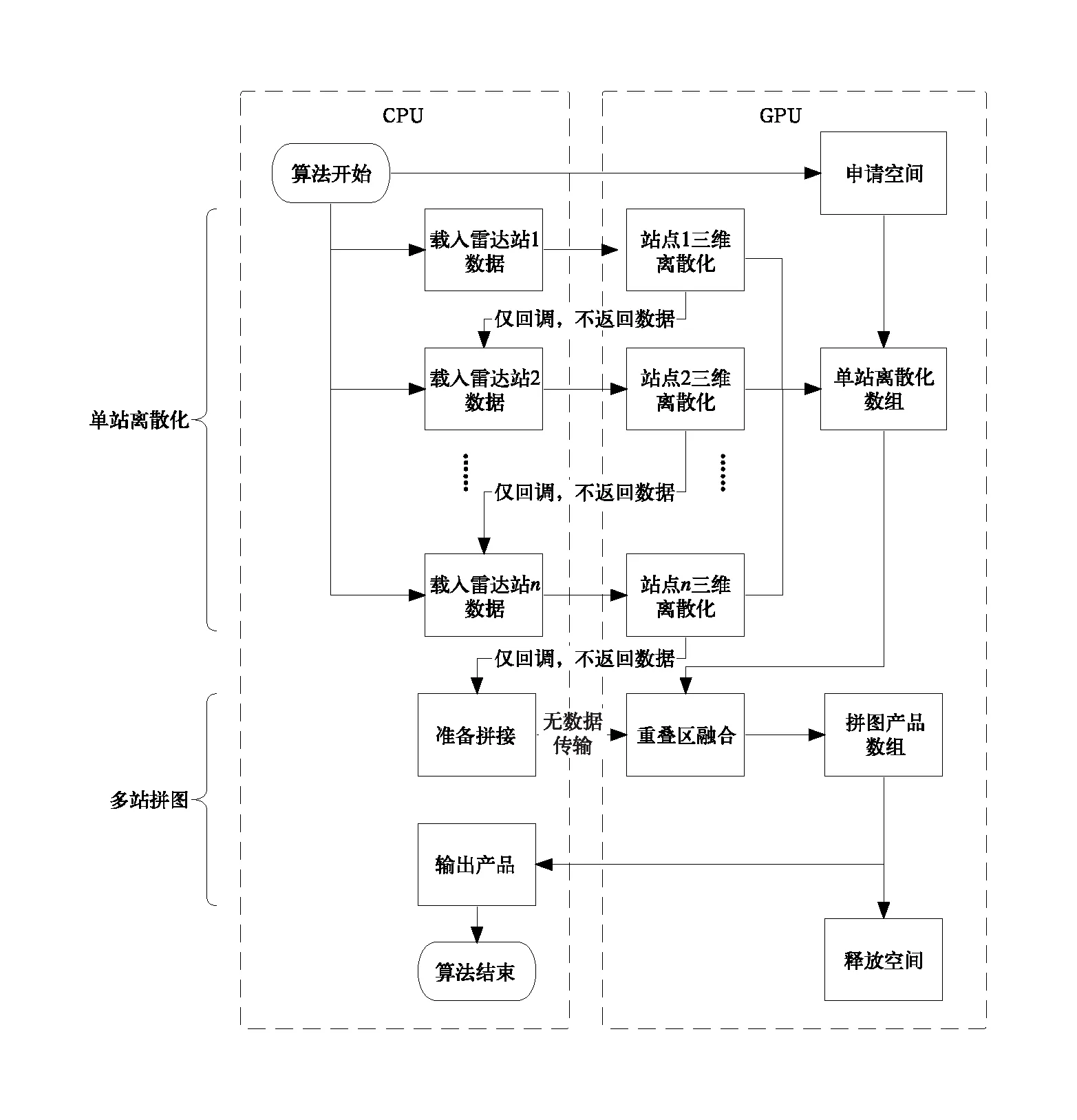
图3 基于CUDA的并行拼图算法设计Fig.3 Flow chart of radar mosaic algorithm based on CUDA
3 组网拼图算法对比试验
3.1 对比试验介绍
SWAN实时业务逐6分钟生成全国(18°~55°N、70°~135°E)三维(垂直20层)拼图产品,每个时次大约处理210个雷达(约2 GB)的数据。以此业务场景为基础,本文设计两组对照试验,验证CPU并行和GPU平行拼图算法的效率。试验内容如表4所示,其中CPU并行算法采用SWAN系统中的拼图算法(30个线程并行)。试验在同一台服务器上进行,其中CPU为E5-2690,内存64 G,显卡为GTX1080,显存8 G。耗时采用5次运算取均值的方法。

表4 对比试验Table 4 Comparison experiments of algorithm efficiency
3.2 运行效率分析
本文按照公式1进行算法运行效率分析:
ttotal=tdecode+tstation+tmosaic
(1)
式中:ttotal表示算法的总运行时间,tdecode表示解析全部雷达基数据的耗时,tstation表示全部单站完成三维离散化的耗时,tmosaic表示多站拼图的耗时。
使用加速比SG定量评估CUDA并行算法加速效果:
SG=tC/tG
(2)
式中:tC表示CPU并行算法的运行时间,tG表示CUDA并行算法的运行时间。SG越大,说明CUDA算法加速效果越好。
表5给出了算法效率试验结果。对比ttotal可以看出,CUDA并行算法的效率优势明显,SG分别达到3.52和6.82。对比试验一、试验二可以看出,随着拼图分辨率的提高,CUDA算法的效率优势也更加明显。这主要是由于在当前拼图的计算量下,CUDA算法的耗时主要是内存管理和数据传输。当拼图分辨率提高时,GPU内存管理和拼图产品的传输开销变大,并行计算部分的耗时还是仅占不到10%。这说明CUDA并行算法具备应对更大规模计算的潜力。表中tdecode主要包括CPU解压和解析雷达基数据的时间,此步骤在四个试验中是基本一致的。从试验结果也可以看出,四个试验方案的耗时接近,符合预期。如果排除tdecode,仅考虑计算部分的加速比,SG分别达到11.8和12.4。表中的试验二表明,基于CUDA的并行拼图算法可以在40 s内完成全国500 m分辨率拼图的运算,说明应用GPU并行技术之后,更高分辨率的雷达拼图具备一定的业务可行性。

表5 算法效率试验结果(单位:s)Table 5 The result of algorithm efficiency experiments (unit: s)
4 结 论
本文基于CUDA设计一种CPU+GPU并行的全国雷达组网拼图算法,其中CPU负责文件解析和流程调度,GPU负责大规模的插值并行计算。在算法设计时,考虑到GPU特性和拼图算法特点,通过优化GPU内存管理和数据流程,减少CUDA算法的并行开销,和CPU并行算法(30个线程)相比,获得了超过3.5的加速比。
本文的试验表明,CUDA并行拼图算法可以在40 s内完成全国500 m分辨率拼图的实时计算,为高分辨率雷达资料在业务中的应用提供了一种新方式。本文设计的雷达组网拼图算法,可以代表计算密集、数据吞吐量大的这一类气象算法的CUDA并行方案。此类算法都可以通过本文类似的方法实现CUAD的并行化改造。
在今后的工作中,考虑将拼图算法和其前序的单站质控、后序的外推算法进行进一步整合,直接实现基于GPU的SWAN算法序列。此外,配合中国气象局雷达流传输业务改革,拼图算法可以直接对接雷达基数据数据流,通过在体扫观测结束前,预先加载部分数据的方式,进一步提高产品时效。
