基于注意力机制ResNet 轻量网络的面部表情识别
2023-11-18王若男李玥辰
赵 晓,杨 晨,王若男,李玥辰
(陕西科技大学 电子信息与人工智能学院,陕西 西安 710021)
1 引 言
面部表情是人类交流和传达情感的普遍信号之一,能够直观表达人类对外界事物的情绪反馈。社会心理学家Mehrabian 的研究表明[1],在日常人际交往过程中,声音和语言信息分别占到了38%和7%,而面部表情传递的信息占总信息量的55%。面部表情识别在计算机视觉领域和深度学习领域已经被广泛研究,这些研究对理解人类的面部表情以及揭示人类情感的语义信息具有重大意义,同时在人机交互、医疗卫生、驾驶员疲劳驾驶监控等领域也具有重大意义[2]。
面部表情识别是一个热门的研究方向,其主要的研究方法就是特征提取[3-4]。传统的人工提取方法包括:局部二值模式[5](Local Binary Patter,LBP)、词袋模型[6](Bag of Words,BOW)、方向梯度直方图(Histogram of Oriented Gradients,HOG)[7]与尺度不变特征变换(Scale-Invariant Feature Transform,SIFT)[8-9]等。这些方法不仅实现困难,且很难提取到高维特征,导致耗费时间长及识别准确率低的问题。因此,当今研究者使用卷积神经网络的方法用于面部表情的特征提取,如AlexNet[10]、VGG[11]、GooleNet[12]、残差整流增强卷积神经网络[13]等已经用于面部表情特征提取,并取得较好的效果。虽然神经网络模型会随着深度增加,特征学习能力增强,但伴随着梯度消失、梯度爆炸以及模型退化等问题,导致模型在识别和分类任务上准确率下降的问题。He Kaiming 等人提出了ResNet[12]网络模型,在卷积神经网络中引入残差的思想,解决了网络深度增加导致梯度消失的问题,但是ResNet网络模型仍存在参数量大和识别准确率低的问题。
针对ResNet 网络模型存在的问题,结合面部表情识别的特征提取的基本需求,本文提出了一种注意力机制ResNet 轻量网络(MCLResNet)用于面部表情识别。先采用ResNet18 作为主干网络提取特征,引入分组卷积减少ResNet18 的参数量;利用倒残差结构增加网络深度,优化了图像特征提取的效果。再将改进的CBAM 模块(Multi-Scale CBAM,MSCBAM)添加到轻量的ResNet 模型中,有效增加了网络模型的特征表达能力,再引入MSCBAM 的网络模型输出层增加一层全连接层,以此增加模型在输出时的非线性表示。本文在FER2013 和CK+面部表情数据集上进行了多组对比实验,实验结果表明,MCLResNet 比其他网络模型参数量少且保持较好的识别准确率。
2 本文方法
2.1 注意力机制ResNet 轻量网络模型整体构架
针对ResNet 网络模型在面部表情识别中存在面部表情特征表示不足及模型参数量大的问题,本文提出了一种用于面部表情识别的注意力机制ResNet 网络模型(MCLResNet)。
首先,MCLResNet在图像预处理阶段,通过随机水平翻转、随机旋转10°~15°、随机增加对比度、随机擦除方法等对面部表情数据进行增强,增强了模型的鲁棒性且丰富了数据集,将预处理后的图像作为模型的输入。其次,经过输入层后的中间特征图作为输入,通过4 组两种不同残差块连接的隐藏层得到高维的特征图。最后,高维特征图经过输出层,输出层中的两层全连接层能够较好地拟合高维特征图得到面部表情分类的一维向量。
模型的整体架构图如1 所示。该网络结构可以分为输入层、隐藏层及输出层3 部分。输入层由一个3×3 的卷积层组成。隐藏层由4 个Basic-Block 和4 个BasicBlock1 组成,两个基础块中含有跳连接和改进的CBAM 形成两种不同的残差块,两种残差块交叉连接组成网络的核心部分。输出层由一个平均池化层和两个全连接层组成。
隐藏层的核心部分BasicBlock 和BasicBlock1的结构分别如图2(a)和2(b)所示。BasicBlock 使用ResNet 原始的基础结构块同时在两次卷积之后添加一个MSCBAM 注意力模块,下采样部分使用一个3×3 的卷积,且步长为2;BasicBlock1使用一个倒残差结构并结合分组卷积,在减少参数量的同时可以增加网络模型的深度,获得更好的特征表达能力。实验证明,升维系数r=2 时,模型的参数量以及准确率达到最优。
2.2 MCLResNet 模型结构
本文针对网络模型在面部表情识别中存在参数量大、识别准确率低等问题,提出了一种基于注意力机制ResNet 轻量网络模型。先将面部表情图像通过随机增强对比度、随机剪切、随机旋转10°~15°、随机缩放等进行数据增强;再经过4 组交叉连接的BasicBlock 和BasicBlock1 提取面部表情特征,两个基础块中的卷积为分组卷积且引入了通道混洗操作,另外在两个基础块中添加MSCBAM 注意力模块;最后输出层增加的一层全连接层较好地增加了一维输出特征的非线性关系,使模型精度得到提升。网络整体结构图如图3 所示。
Hinton等人首次提到了分组卷积,分组卷积实现了让网络模型在两个内存有效的GPU 上运行。随着GPU 内存的增加,网络模型不再受内存的限制。基于分组卷积的特点,很多研究者引入分组卷积思想的模型用于实现数据的并行处理,以此减少模型的参数量,增加模型训练的高效性。本文将分组卷积引入到如图2 所示的BasicBlock 和BasicBlock1 两个残差块的卷积层和跳连接中,降低了MCLResNet 网络模型的参数量。分组卷积结构如图4 所示。在卷积核数量一定时,分组卷积相比普通卷积降低了计算复杂度和计算次数。
尽管分组卷积能够减少模型参数量,提高模型训练的高效性,但是分组卷积的弊端是不同分组的通道间无法进行信息交互,限制了模型的表征能力。针对这一问题,本文引入通道混洗操作增强不同组通道之间的信息交互[14]。通道混洗操作如图5 所示。通道混洗是将不同分组的通道重新排列得到新的特征图,再将新的特征图作为下一次卷积的输入,实现了不同分组的通道信息交互,增强了特征的表征能力,提高了整个网络的面部表情识别精度。
在引入分组卷积和通道混洗结构的基础上,为了进一步增强模型的特征提取能力,本文引入了倒残差结构加深网络模型层数[15]。倒残差结构如图6 所示,该结构呈现两头小中间大的形状(梭型),梭型相比漏斗型先升维再降维的过程,避免了部分的特征信息丢失[16]。在倒残差结构中,先使用1×1 的卷积核实现升维,再通过3×3的卷积核提取特征,最后使用1×1 的卷积核实现降维。倒残差结构的引入减少了特征提取过程中特征信息丢失的问题,加深了网络模型的深度,提高了模型提取特征的能力。
2.3 多尺度空间特征融合的CBAM(MSCBAM)
CBAM[17]中的通道注意力生成通道注意力特征图时要经过全连接层进行映射特征到一维特征图,在生成通道注意力时要经过压缩和扩展处理,压缩时会损失较多的通道信息[18]。针对这一问题,本文提出了改进的CBAM 模块的通道注意力。
改进后的CBAM 通道注意力模块如图7 所示。改进后的CBAM 通道注意力模块将原有的全连接层改为一个1×3 的带状卷积,既减少了全连接层带来参数量大的问题,又增强了相邻通道之间的相关性,得到最佳的通道特征图。
CBAM 的空间注意力模块仅能得到单一特征的空间特征图。为了得到多种尺度融合的空间特征图,在CBAM 空间注意力模块中引入了不同大小的卷积核,得到融合不同尺度的空间特征图。改进后的CBAM 空间注意力模块如图8所示,改进后的CBAM 空间注意力模块中添加了3×3、5×5、7×7、9×9 的卷积核用于得到不同尺度的特征图,再将得到的不同尺度特征图通过最大池化和平均池化获取各自对应的空间特征图并将得到的4 个特征图进行融合,最后将融合后的特征图通过Sigmoid 函数进行激活得到多尺度融合的空间特征图。改进后的空间注意力机制输出实例如公式(1)所示:
其中:Ms ∈R1×H×W表示输出的空间注意力图,σ表示Sigmoid 函数,AvgPool 表示平均池化,Maxpool 表示最大池化,Conv 表示卷积操作,Conv 的脚标表示卷积操作使用的卷积核大小。
3 实验结果与分析
3.1 实验数据集及数据增强
本文在模型训练和模型验证所用的数据集为FER2013数据集[19]和CK+数据集[20]。FER2013数据集是人脸表情识别最通用的数据集,由35 886张人脸表情图片组成,其中,训练集28 708 张、验证集3 589 张、测试 集3 589 张,每一张图像大小为48×48 的灰度图像组成。7 种表情对应的标签如下:anger 0,disgust 1,fear 2,happy 3,sad 4,surprised 5,normal 6。CK+数据集包含123 个对象的327 个被标记的表情图片序列,共分为anger、contempt、disgust、fear、surprised、happy 和sad 7 种表 情,表情对应标签如下:anger 0、contempt 1、disgust 2、fear 3、happy 4、sad 5、surprised 6。图9列举了FER2013 数据集和CK+数据集的部分样例图。
为了解决因为数据分布失衡和数据量小而导致模型训练时出现过拟合等问题,本文使用数据增强等方法对数据集样本进行扩充,主要采用随机水平翻转、随机旋转、随机增加对比度、随机擦除等方法对数据集进行扩充。针对CK+中一副anger 原图经过上述方法扩充后的样例如图10所示。其他图像也采用了类似方法进行扩充,在此不再一一列举。
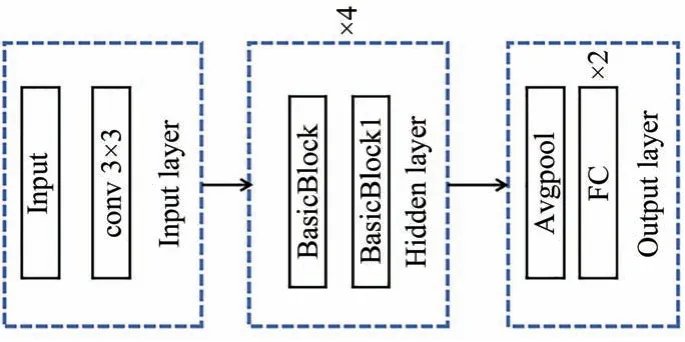
图1 MCLResNet 网络构架Fig.1 MCLResNet network architecture
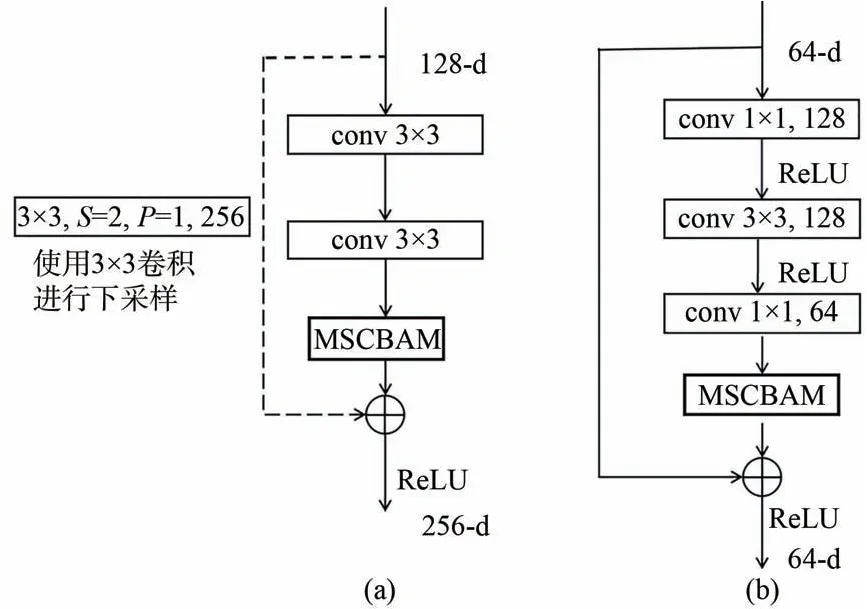
图2 隐藏层的核心部分。(a)BasicBlock 结构;(b)Basic-Block1 结构。Fig.2 Core part of the hidden layer.(a)Structure of BasicBlock;(b)Structure of BasicBlock 1.
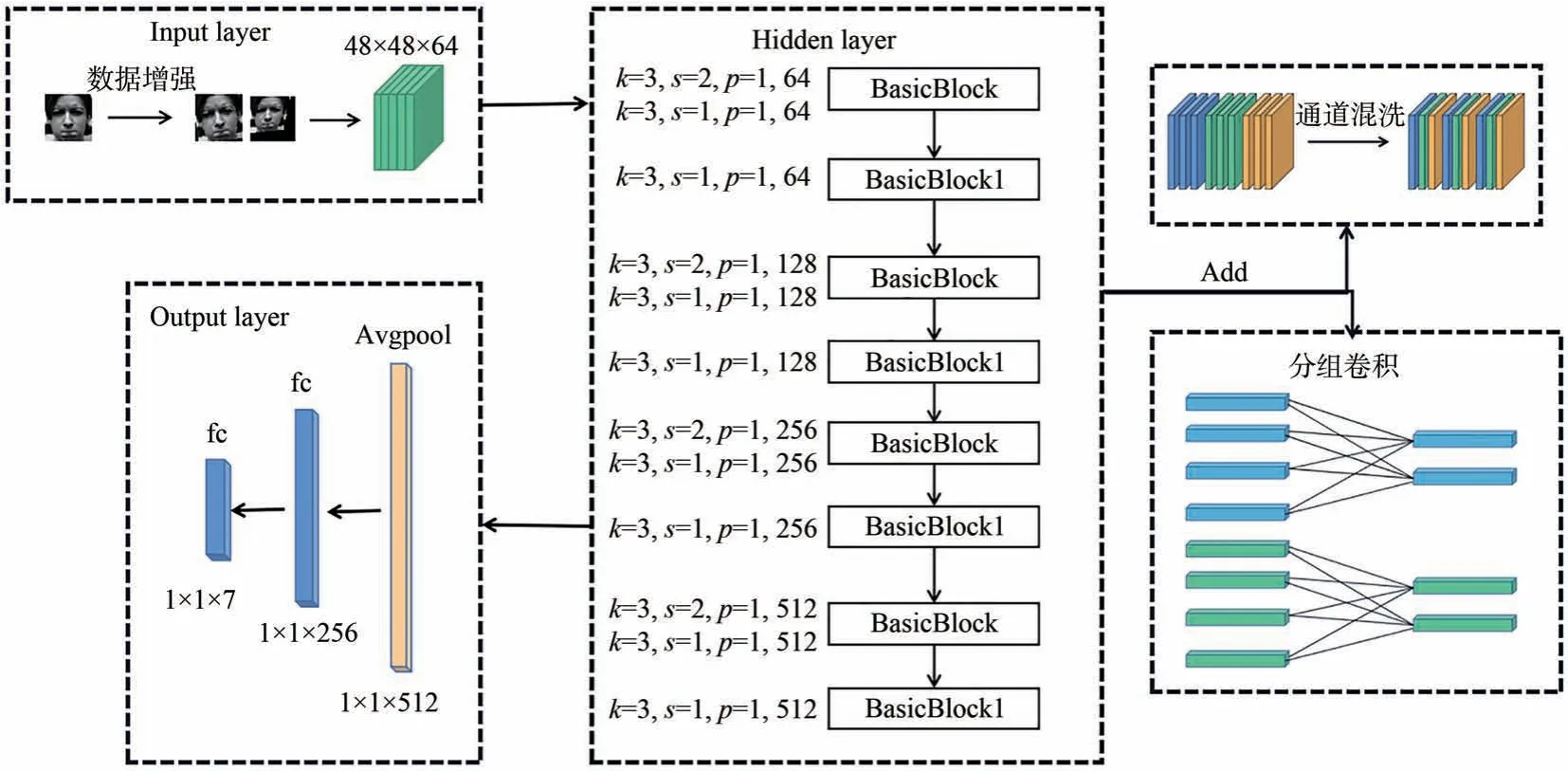
图3 网络整体结构图Fig.3 Overall network structure diagram
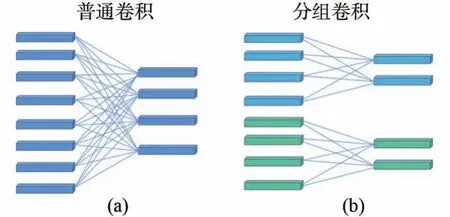
图4 (a)普通卷积;(b)分组卷积。Fig.4 (a)Ordinary convolution;(b)Grouped convolution.
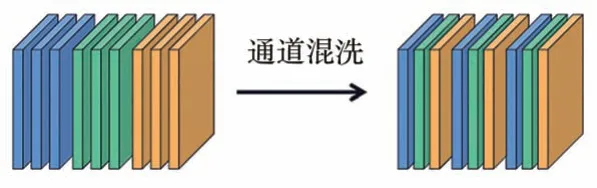
图5 通道混洗Fig.5 Channel shuffle
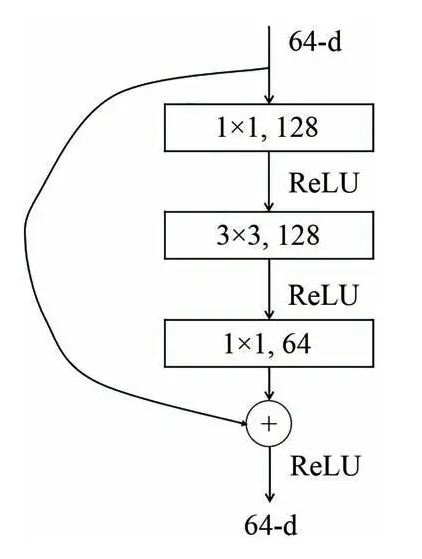
图6 倒残差结构Fig.6 Inverted residual structure
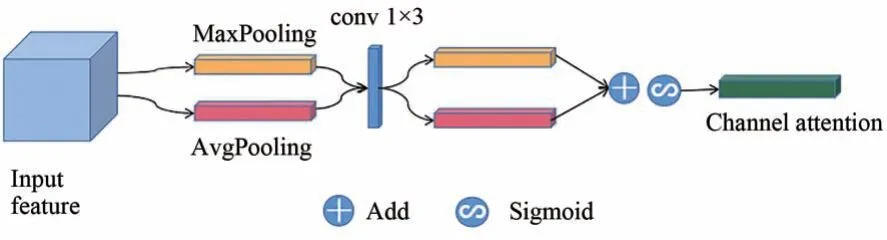
图7 改进后的通道注意力模块Fig.7 Improved channel attention module
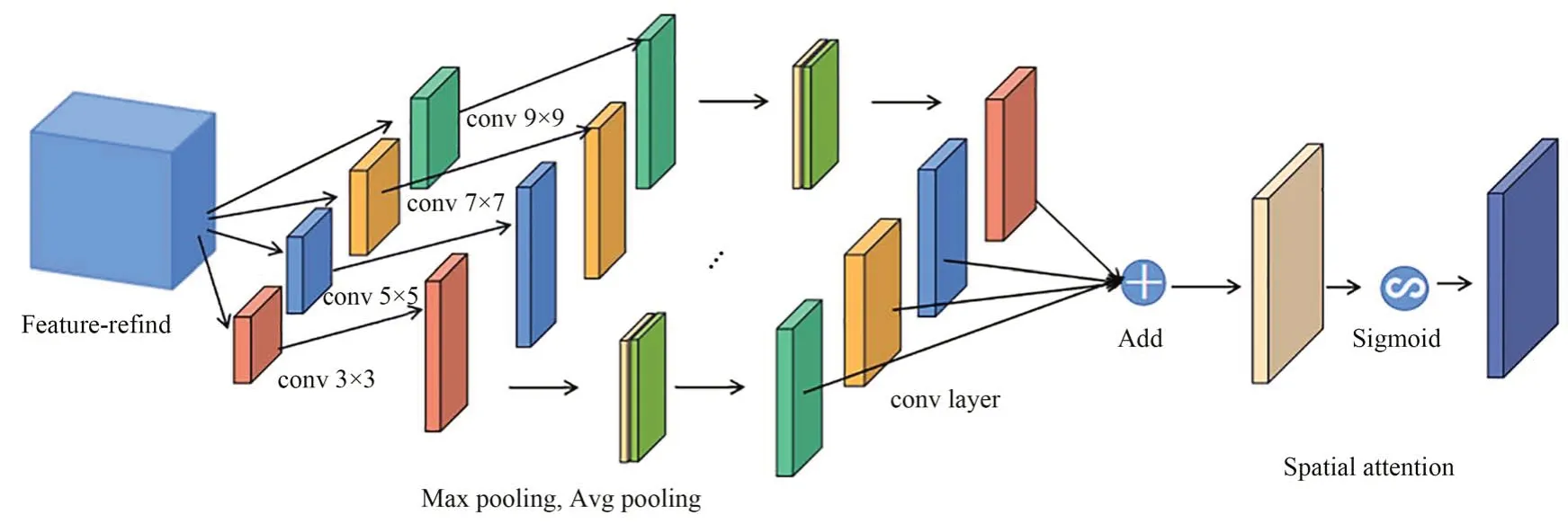
图8 改进后的空间注意力模块Fig.8 Improved spatial attention module

图9 FER2013 和CK+数据集样例图Fig.9 Samples of FER2013 and CK+datasets

图10 数据增强样例图Fig.10 Sample diagram of data enhancement
3.2 实验环境
本文实验配置如下:Windows10 系统,CPU 为主频3.19 Hz 的 Intel Core i9-12900K,内存为64G,GPU 为NVIDIA GeForce RTX 3080(12G)×2。本实验基于Pytorch深度学习框以及Pycharm 进行模型训练和测试,实验参数设置是:Batch Size 为128,学习率取0.1,优化器为随机梯度下降(SGD),冲量为0.9,损失函数为交叉熵损失函数,学习率下降算法使用余弦退火算法。
3.3 实验结果及分析
3.3.1 消融实验
为了验证MCLResNet 网络各个模块的有效性,对每一个模块进行消融实验。其中Baseline 表示引入分组卷积且增加一层全连接层的ResNet18网络模型;BasicBlock1 如图2 所示;MSCBAM 是多尺度空间融合的CBAM;Better-Down 表示使用3×3,步长为2 的卷积替换原有的1×1 卷积。
该实验在扩展的FER2013 和CK+数据集上验证,实验过程是在网络模型中逐步添加模块或者修改相应的模块。表1 的实验结果表明,在不同的数据集上所提模型具有良好的泛化性,替换或添加的模块明显提高了整体模型的识别准确率。
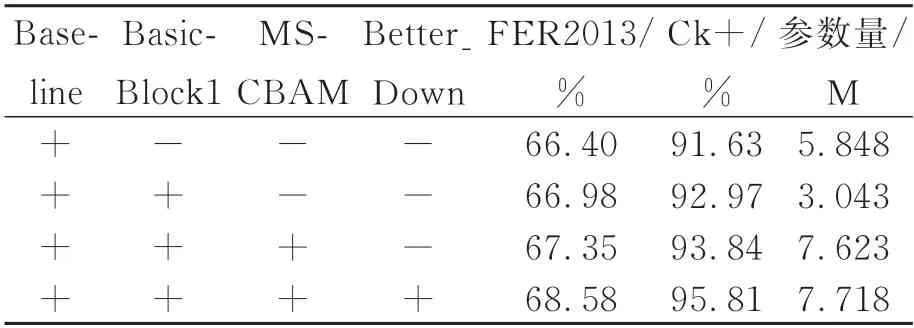
表1 消融实验Tab.1 Ablation experiments
3.3.2 确定BasicBlock1 升维系数r的对比实验
为了选取BasicBlock1 的升维系数r,在FER2013 数据集上验证了不同的r对模型大小和识别准确的影响。具体实验参数如图11 所示。①表示本文所提方法不含MSCBAM。②表示本文所提方法含MSCBAM。
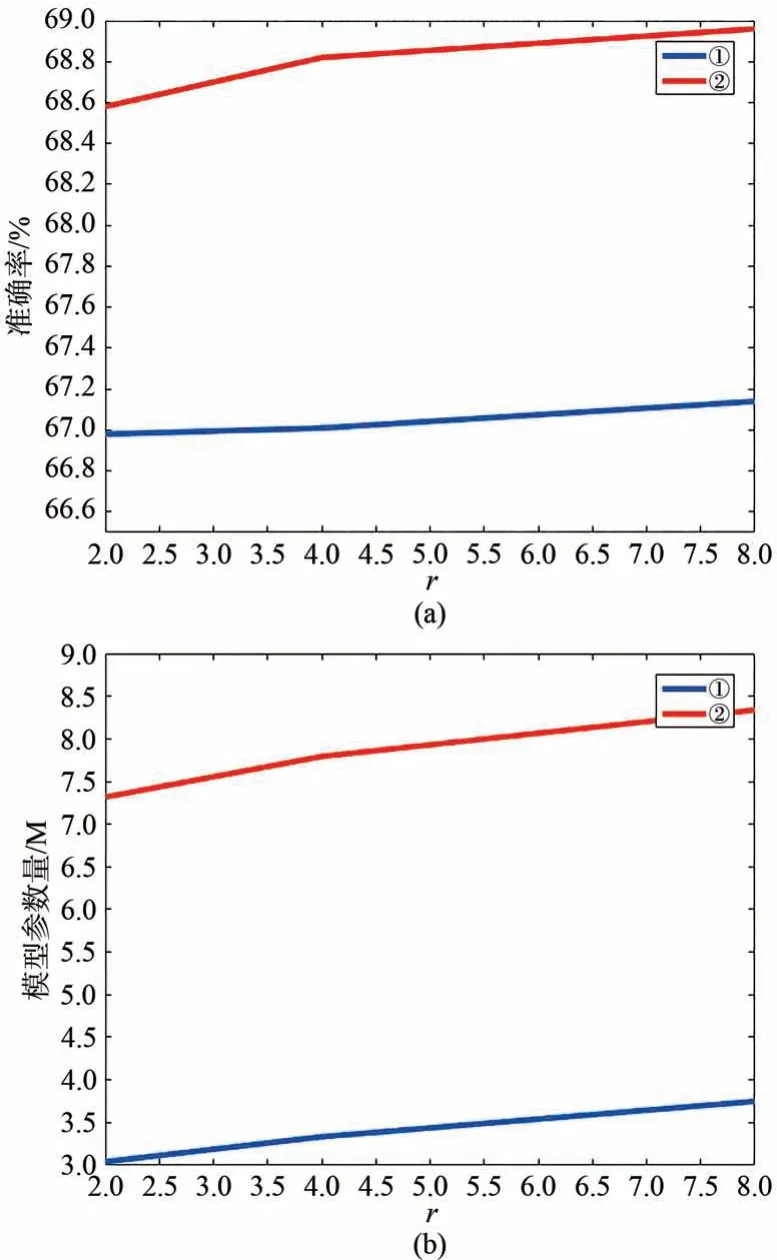
图11 (a)升维系数和准确率之间的关系图;(b)升维系数和模型参数量之间的关系。Fig.11 (a)Relationship between the ascending coefficient and the accuracy rate;(b)Relationship between the ascending coefficient and the number of model parameters.
图11 例举了r=2、4、8 三个值对本文提出方法的模型参数量大小和准确率的影响。实验数据表明,r值为2 时,①和②的模型参数量分别为3.043M 和7.318M,尽管②比①的参数量大,但模型的准确率提升了1.6%;模型同为①,r=2 和r=4 时,r为4 的模型 比r为2 的模型 参数量增加了0.293M,但模型精度仅提升了0.03%;模型同为①,r=4 和r=8 时,r为8 的模型比r为4 的模型大小增加了0.708,但模型精度仅提升了0.16%。本文旨在设计一个轻量的网络模型,即由图11 表明本文选取r=2 为BasicBlock1 的升维系数。
3.3.3 与其他网络的对照实验
为了验证本文所提模型的准确性和有效性,与其他的网络模型进行对照实验,如AlexNet、VGG19、Zhang[21]、ResNet18 及MobileNetV2。这些网络模型及本文所提网络模型在FER2013 数据集、CK+数据集上的识别准确率以及所对应的参数量如表2 所示。
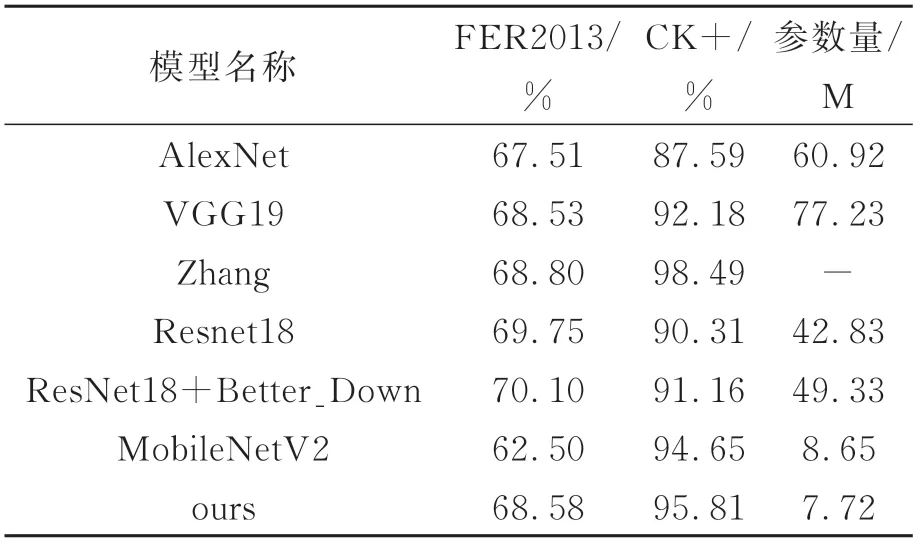
表2 与其他网络的对照实验结果Tab.2 Results of controlled experiments with other networks
模型参数量方面,本文提出的模型参数量相比于其他常见的网络模型参数量明显下降。与本文的主干网络ResNet18 相比,本文模型的参数量为ResNet18 网络参数量的17.42%;与MobileNetV2 的参数量相比下降了1.33M。在FER2013 数据集识别准确率方面,本文所提出的模型相比AlexNet、VGG19 和MobileNetV2 的识别准确率分别高1.07%、0.05%、6.08%;但相比ResNet18,Zhang 及ResNet18+Better_Down的方法识别准确率略低。在CK+数据集识别准确率方面,本文所提出的模型识别准确率较AlexNet、VGG19、MobileNetV2 和ResNet18 等模型的识别准确率分别高8.22%、3.63%、1.16%、5.5%。
4 结 论
本文基于面部表情识别提出了一种注意力机制ResNet 轻量网络模型(MCLResNet),其参数量为改进前ResNet18 的参数量的17.42%。首先,所提模型中引入了分组卷积和倒残差结构,减少了模型的参数量,增加了网络深度,通过减小模型大小提升了模型训练速度;在不同的分组通道中引入通道混洗操作用以增强特征图层与层之间的信息交互;改进了ResNet18 中跳连接中的卷积核大小,降低了特征信息的丢失。其次,改进的CBAM 注意力模块(MSCBAM)在模型训练过程中提供了多尺度融合的中间特征图,增加了模型的精度。最后,本文提出的MCLResNet模型在FER2013 数据集和CK+数据集上的测试准确率体现了模型良好的泛化性。尽管本文所提出模型及其他模型在CK+数据集上表现良好,但在FER2013 数据集上准确率较低,其原因一方面是数据集存在部分标注错误,另一方面是FER2013 数据集的复杂多样(正脸、左侧脸、右侧脸等)。解决数据集多样性带来的准确率低的问题是后期工作改进的一个方向。
