基于用户兴趣和多特征融合的信息抽取
2023-11-16刘丽娟
刘丽娟
国家计算机网络应急协调处理中心上海分中心 上海 201315
引言
随着网络迅猛发展,大量负面网络信息井喷式爆发。如何从大量网络文本中进行信息的有效识别是一个复杂的课题。众多方法中,多标签分类法[1]容易遗漏关键信息,Simrank法[2]仅考虑节点与边的连接数,忽略不同的边将造成不同权重值,且耗时长,导致准确率计算不准的问题。
针对上述识别率低等问题,本文提出基于用户兴趣和多特征融合的信息抽取方法。在用户兴趣分析中,根据用户行为习惯,利用本体理论建立符合用户行为习惯的用户兴趣子树,充分挖掘用户的查询兴趣,为精准抽取文本结果做基础;在多特征融合分析中,首先对文本进行降维,提取特征,其次,将所有特征向量作为模型框架输入,最后,运用CNN(Convolutional Neural Networks,卷积神经网络)深度学习模型训练,输出文本信息筛选结果。创新点在于①网页综合本体和位置两种方式进行分析,提升分析的全面性和丰富性;②结合用户行为搜索日志,将用户兴趣拆分,利用本体理论形成用户兴趣子树进行分析,使理解主题信息的角度更为全面;③挖掘多特征,综合考虑实际需求挖掘需要的特征,融合分析文本信息。实验结果表明,本文基于用户兴趣和多特征融合的信息抽取方法不仅在相关主题的信息抽取文本返回结果中数量较高,更在主题识别的准确率F值度量上取得一定程度的提升,能够更准确地反映出网页信息,抽取文本信息。
1 信息抽取
信息抽取是按照特定需求从信息文本中进行抽取,本文研究的是针对Web信息抽取。目前针对Web信息抽取主要有两种方式:①基于本体的信息抽取,将网页信息用本体体征维度进行标识,对网页内容进行分析;②基于位置的信息抽取,依赖网页结构,可准确定位位置,在位置不变下准确度较高。本文综合本体和位置进行分析,提升分析效果。
2 基于用户兴趣的分析方法
针对信息抽取的分析需求,借助本体构建用户兴趣子树,以供扩展查询。
2.1 用户兴趣子树
本体是特定领域中存在的对象类型或概念及其属性和相互关系[3],具备结构化特点。运用本体,能全面清晰描述用户兴趣的主体关系和关联关系,体现用户最直接最关心的需求。
构建兴趣生成树[4]方法,提出基于领域本体三阶段用户兴趣子树。具体步骤是分析用户提交的查询,包括但不限于查询关键词等用户行为日志,并映射为本体中的概念,选取用户兴趣子树的基本节点﹑非基本节点和根节点,构建候选用户兴趣子树,并消除歧义,如图1。

图1 用户兴趣树构造
用户行为日志能够反映用户兴趣。例如,第一次查询“新东方”,用户仅点击2次新东方厨师培训的网页,点击5次新东方英语培训的网页;第二次查询“新东方”,用户点击5次新东方英语培训的详情介绍网页;第三次查询“新东方”,用户点击8次新东方英语培训的上课链接网页。
通过这三次用户日志,可知用户兴趣是查找新东方英语培训的相关信息,而不是新东方厨师培训机构的信息。将用户行为依次构建到用户兴趣子树中,能针对关键词挖掘用户查询的精准兴趣,为后续信息准确抽取提供基础。
3 多特征融合的分析
3.1 爬虫工作原理
网页信息抽取由爬虫实现,服务节点包括已访问﹑未访问﹑待访问的网址﹑地址库以及队列。主要运行过程如下[5-6]:①用户向服务器发送检索URL的请求;②服务器发送该请求到客户端;③客户端收到待检索的URL列表后,下载并保存,提取新的URL;④将已访问检索的URL列表和新发现的URL列表发送至服务器;⑤服务器从库中提取待访问检索URL列表,循环直到待访问检索URL列表为空停止。
3.2 基于位置的分析
网络信息抽取需要分析页面结构,利用网络爬虫执行,工作原理是依照网页层次化结构进行分析,如元素标记,可通过A元素﹑href元素标签等数量,对网页的结构进行定量分析,甄别待抽取的主题文本网页与普通非主题网页的差别,归纳特征。
3.3 多特征融合
多特征融合是特征选择提取的基础上,融合多个特征。
特征选择提取进行预处理,具体是从原始文本数据集中,通过分词处理﹑去停用词﹑统计词频等,得到低维向量,进而提取特征,如图2。
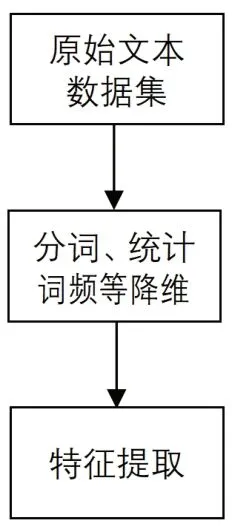
图2 特征选择提取流程
融合特征即将所有特征向量放在一起,用数学方法变换为全新的特征表达方式。
可建立1﹑2﹑3﹑4…等多个特征,例如1代表是否包含关键词a,2代表是否包含关键词b,3代表网页是否跳转,4代表网页是否包含特殊标记……根据实际抽取需求建立多个特征,形成特征向量,作为后期深度学习的输入。
3.4 基本框架
在上述构建用户兴趣子树和特征提取的基础上,进行初步知识表示﹑标准知识表示。已有知识来自原始数据,即结构化数据﹑半结构化数据﹑非结构化数据,经过实体抽取﹑关系抽取等理解用户兴趣,融合多特征,输入深度学习框架进行训练。经分析得到标准知识表示,从而经过挖掘抽取文本信息。
深度学习框架采用CNN深度学习模型。分为输入层﹑卷积层﹑池化层﹑激活函数层﹑全连接层,主要如下。
输入层:将特征进行标准处理﹑完成输入的层。
卷积层:是用以特征提取的层。
池化层:进行特征压缩,降低维度。
激活函数层:运用上述模型进行分类达到抽取主题文本信息的目的。
4 实验分析
用对比实验比较不同方法的效果。实验一针对“流浪地球”主题,分析关键词法﹑用户兴趣法﹑基于用户兴趣和多特征融合抽取方法的结果。横坐标表示返回结果的PR值(PageRank)前N个网页,纵坐标表示前N个网页中符合要求的网页数量。图3整体反映返回前N个网页满足要求的网页数量情况。随着返回结果的页面数量增加,基于用户兴趣和多特征融合抽取的方法符合要求的网页数比其他二者方法高。
实验二对比不同主题的准确率,结果表明,基于用户兴趣和多特征融合的方法比用户兴趣法的F值提高了11%以上,验证了该方法的有效性;本文法比关键词法F值提升了16%,如图4。可见该方法在算法可行性和效果上均优于其他方法。
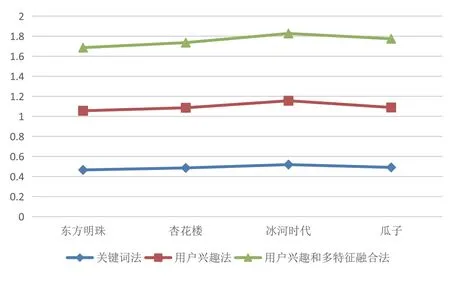
图4 不同方法的F值对比
5 结束语
针对现阶段文本分析大多存在不准不全的问题,本文提出基于用户兴趣子树和多特征融合的信息抽取方法,依据用户兴趣子树获得知识,并融合多种特征,输入深度学习模型进行训练。通过实例阐述说明该方法的实施过程。对比关键词法和用户兴趣法,实验表明本文提出的方法在信息抽取的返回结果数量和F值方面明显提高。究其原因是本文的方法充分刻画用户在信息获取全过程的兴趣(行为习惯),对语义进行关联扩展,并通过网页的特征进行本体和位置多维度的分析,能够全面动态地反映抽取全过程。未来针对文本语义分析信息抽取这一领域,将考虑整合优化训练模型,丰富应用场景和适用领域,形成更为量化立体的抽取评价体系,以进一步提升实际识别效果。
