基于改进联合滤波与CNN模型的仪表识别算法
2023-11-16李晓峰程远方李文豪
孙 辉,李晓峰,程远方,姜 飞,李文豪
(国营洛阳丹城无线电厂,洛阳 471000)
0 引言
如今数字式仪器仪表广泛应用于各个行业,由于历史原因、成本控制考虑、设计要求等因素,仍有相当数量的仪器没有提供与计算机的数据通讯接口,不具备程控功能,在工艺工卡录入时,还需手动记录仪器仪表测试数据。人工录入仪表数据耗费大量人力和时间,记录的测试结果容易受到更改。相比之下,更方便的是通过工业相机实时监控采集仪器仪表表盘图像,然后使用字符识别的机器视觉技术,对仪器仪表表盘图像中的字符数据进行识别[1-2]。
数字仪器仪表中的数据通常包含多个字符,传统的方法是先通过机器视觉定位算法,寻找仪表特征,来确定字符显示区域的位置,然后将字符区域分割成单个字符进行识别。整个过程复杂,识别结果容易受到预处理过程中定位和分割结果的影响[3-4]。如果我们实现了数字仪器仪表图像的像素级预测,并且预测结果同时包含了位置信息和类别信息,对识别的示数区域进行预处理,就可以直接将两者合成得到字符结果。基于卷积神经网络的目标检测算法被广泛应用于各类型工业应用场合[5-8]。若目标定位后需对目标信息进行内容的识别,则图像预处理阶段及其重要,处理算法为后续字符成功分割和识别提供了重要的基础。经过工业相机在复杂环境中获取到的图像会存留各种各样的噪声,均值滤波虽然能够很好的解决噪声点的保留问题,但是其对原有的信号点的灰度值进行了改变,尤其是针对前景与背景交界的边缘处,细节保留方面并不完备。文献[9-10]分别提出利用灰度检测器来检测图像中的噪声程度,设计了相关模糊加权的中值滤波器或滤波选择器来进行处理,有效的去除了椒盐噪声,保护了大部分图像细节。谐波均值滤波器和非局部均值滤波器(NLM)对高斯噪声和白噪声处理有着显著作用,但是参数取值时,则往往需要人工经验,且NLM滤波器[11-12]对非局部主要体现在利用整张图的像素点进行滤波,但是该滤波算法滤波速度较慢,无法应用于实时图像检测与处理。然而,仪器仪表所处各类工业应用场景较为复杂,目前仅仅针对光照不均匀和低对比度图像的增强算法层出不穷,被不断发展来应用于增强各种类型的图像,以方便后期对字符的分割与提取。文献[13]设计同态滤波器来增强图像对光照变化的适应性,算法能够解决不同光照条件下,存在指针阴影问题,能够较好的提取指针式仪表的指针区域。文献[14]通过同态滤波对图像进行锐化,以提高图像的清晰度,从而突出了图像的边缘细节特征。文献[15]提出了一种结合对比度约束的自适应直方图形式来增强图像对比度,取得了较好的效果。但是上述同态滤波器所需调节参数较多,且往往参数调节需要大量的人工经验,不利于算法的工业多场景下的快速部署。
为了解决上述问题,本文提出了一种基于改进的联合滤波与CNN检测模型算法,用于对复杂场景下的数字式工业仪表进行快速识别与判定。通过CNN目标检测模型快速准确定位仪表表盘位置,然后通过联合滤波算法对多场景约束下的表盘图像进行自适应滤波操作,能够快速处理相关图像,大幅度的减少运算时间,较好的保留了图像受关注的细节成份,对于复杂场景下的算法工业部署具备较高的实用性。
1 基本原理
1.1 数显区域识别与定位
常见的CNN主要分为显示层和隐藏层两部分,显示层包括输入层和输出层,隐藏层包括卷积层和池化层。在每一层中,一个二维平面由多个神经元组成,然后由这些平面形成一个层结构[16]。图1是常见的CNN结构图。
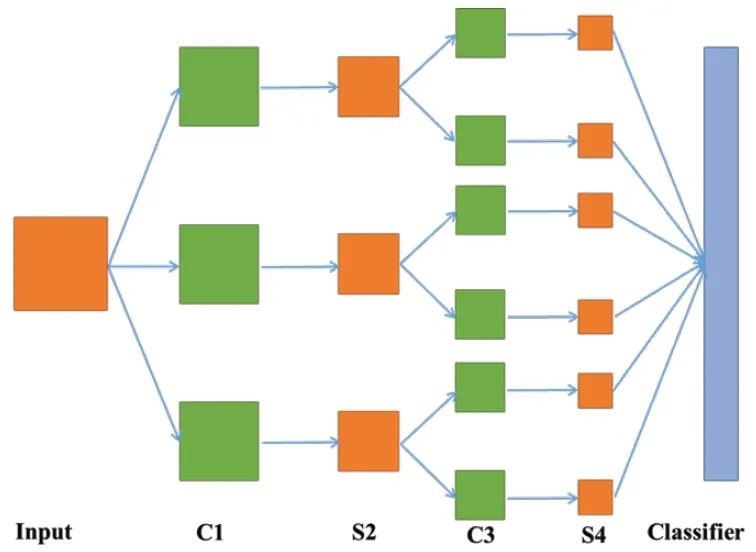
图1 CNN结构
其中,C1和C3为卷积层,卷积层的作用是通过在之前的特征图上滑动卷积核来提取卷积核对应的特征。将前一层的输出作为输入,根据卷积层的卷积核数进行卷积运算。卷积层中每个神经元的输入连接到前一层的局部感受野,局部感受野与卷积核进行卷积[17]。然后,经过一个激活函数(通常是Sigmoid函数),提取局部特征,如式(1)所示。
其中S(x)为Sigmoid函数,含义如式2所示。θ和x为卷积核中的参数值,b为偏置,i和j为卷积核的大小,k为上层特征图的数量。使用激活函数的原因是它是一个非线性函数,它的输出对输入是非线性的。如果没有激活函数,多个卷积层和单个卷积层之间不会有数学差异。卷积层的本质是从一个大尺寸的特征图中选择一小块作为样本,然后通过训练从这个小样本中学习到很多不同的特征。然后将这些特征作为检测器应用到图像的其他部分进行卷积,从而从特征图不同位置的局部区域中得到许多不同特征的激活值。
层S2和S4是池化层。可以看成是一个模糊滤波器,起到二次特征提取的作用,也可以降低特征维数。池化层将在不同位置通过卷积层的特征进行聚合,计算特征图某个区域内某个特定特征的平均值。这些汇总统计特征不仅具有较低的维度,而且还提升了检测效果。这种聚合的操作称为池化,池化函数通常分为平均池化和最大池化。对于池化层,如果有N个输入特征图,则有N个输出特征图,但每个输出特征图都被池化函数减少。池化操作是选择上层的输出特征图不与区域结合,平均池化计算区域的平均值作为输出,最大池化选择区域的最大值作为输出。
本文中所提出的基于改进的联合滤波与CNN检测模型的数字式仪表识别算法的工作流程分为两个阶段,一个是游标卡尺数字显示区域的位置,另一个是数字字符识别。在识别游标卡尺读数之前,需要对游标卡尺仪器的数显区域进行定位,这在很大程度上影响了后续字符识别的准确性。如图2所示,我们随机收集了多个不同场景下的游标卡尺图像。从图2可以看出,游标卡尺图像存在倾斜、位置、焦距、光照差等现象,增加了字符识别的难度。图2(a)的背景不同。图2(c)的位置不同,焦距较远。

图2 不同场景下的游标卡尺图像
由于游标卡尺的背景环境非常复杂,需要排除仪器的背景干扰,才能获得较高的识别精度和稳定性。为减少数据样本采集工作量,同时提升模型的泛化能力,本文对采用数据增强技术对扩充样本类别,通过旋转、位移、镜像等操作来扩充数据样本量。本文采用CNN模型来提取游标卡尺数字显示区域的特征进行定位。首先将游标卡尺的数显区域作为候选区域,随机选取10000幅图像样本作为数据增强的样本输入,将数据增强后的游标卡尺样本放入CNN模型进行训练,使得计算机自己学习候选区域的特征。训练完成后,得到一个结构化的CNN模型。如图3所示,黄色框为多种游标卡尺样品的候选区域标定图。为验证模型的定位效果,随机选取多张游标卡尺图像样本进行实践实验,定位正确率均在99%以上,因此,构建的模型得到验证。

图3 游标卡尺候选区域标记效果图
1.2 预处理与倾斜校正
在游标卡尺图像采集过程中,由于操作过程的随机性,难免会导致图像采集倾斜。定位倾斜图像的候选区域后,图像的数字显示部分倾斜,字符倾斜,如图4所示。在这种情况下,后续字符分割得到的字符噪声会明显增加,降低字符识别的正确率,倾斜过大的图像甚至会出现无法进行字符分割的情况。因此,有必要对倾斜的游标卡尺图像进行校正[18]。对于游标卡尺的水平倾角,主要有两种修正方法,Hough法[19]和Radon法。与Hough法相比,Radon法计算简单,依赖性小。本文选用Radon法校正游标卡尺图像的倾斜,图4(a)为逆时针操作得到的图像,图4(b)为顺时针操作得到的图像。

图4 游标卡尺倾斜校正示意图

图5 本文所提改进型的中值滤波算法流程图
通过工业相机拍摄到的高质量图像,是后续开展字符得以准确识别的前提,由于拍照过程会受到周边环境、杂物、光照等影响,因此对拍摄到的数字仪表表盘信息,开展相关的预处理工作尤为必要,一次位分割后的图像可以看到,由于环境光源和数字式仪表表盘自身反光或光照不均匀等影响下,导致图像中的数字字符显示部分与背景液晶表盘对比度不高,且受一定的噪声干扰,不利于后期的字符的提取,因此需要采用图像增强技术来改善现有的数显部分对比度。
1.3 预处理与倾斜校正
本文设计一种联合滤波方式,来的对分割获得含字符的表盘信息进行预处理,选取改进后的自适应中值滤波算法来对分割后的图像进行先期滤波操作,用来去除噪声干扰,然后再对滤波后的图像进行同态滤波操作,使得一次分割图像具备字符与液晶背景具备明显分离条件。
通过工业高清相机,获取得图片分辨率较高,区域分割定位后,仪表显示区域所占总画面较小,因此受环境噪点影响较大,针对定位分割后的仪表区域图像,采取了滤波操作,现阶段滤波分为均值滤波、中值滤波和NLM滤波,本文设计一种急速中值滤波器用于对一次定位后带有噪声分布的仪表图像进行快速滤波。根据检测图像中噪声含量,来自主切换卷积核的尺寸,从而达到急速滤波的效果。本算法中卷积核的尺寸分为3×3、5×5和7×7三种大小,通过依次检测图像中存在的噪声强度,来逐步切换不同的卷积核,以期达到混合滤波的效果。其中,噪声强度检测公式如式(3)所示:
其中,像素灰度Gray(i,j)的取值范围为[λ,255-λ],λ为灰度偏差,当Noise(i,j)为1时,代表当前像素颗粒为噪声。
具体的滤波算法流程如下:
步骤一:对输入含噪声图像时,采用3x3卷积核进行滤波操作,当滤波完成后,判别当前滤波后的图像是否存在疑似噪声点,若不存在,则噪声滤波结束;若存在,则继续下一步;
步骤二:对步骤一完成滤波后的图像,采用5x5卷积核进行滤波操作,当滤波完成后,再次判定滤波后的图像是否存在疑似噪声点,若不存在,则噪声滤波结束;若存在,则继续下一步;
步骤三:对第二步骤完成滤波后的图像,采用7x7卷积核进行滤波操作,滤波完成后检测当前图像是否存在疑似噪声点,若不存在,则完成滤波;若仍然存在疑似噪声点,则判定是否图像有大面积二值背景,若存在,则停止滤波,输出当前像素图像;若判定非二值背景,则继续采用7×7卷积核进行滤波操作,最终输出滤波后的像素图像。
图6表示几种滤波算法处理50%密度椒盐噪声的对比图,这里对比了高斯滤波器、算数均值滤波器、逆谐波滤波器、自适应中值滤波、NLM滤波。从图中可以看出,在加入50%椒盐噪声密度时,本文所提算法能够较好的滤掉噪声,且数显部分对比度较为明显。

图6 滤波算法对比图
工业部署情况环境较为复杂,针对光照不均匀情况,本文引入同态滤波器来对光照不均匀图像,进行进一步滤波,同态滤波属于图像频域处理方法中的一种,通过结合图像频率过滤和灰度变换来处理相关图像,具备调节图像灰度范围,突出图像细节,增强对比度,去除照明不均匀的作用,可以用提高图像对比度的增强方法。它将图像f(x,y)看作是由入射分量i(x,y)和反射分量r(x,y)组合而成[20],具体如式(4)所示:
同态滤波是一种依靠图像的照度—反射模型来改善图像质量的频域方法,对式(4)两端求对数可得:
对式(5)两端求取傅里叶变换,可以得到:
选取频域函数H(u,v)对F(u,v)进行滤波处理,可以得到:
其中,H(u,v)为同态滤波的传递函数,滤波后对式(7)做傅里叶反变换到空间域内,可得:
对式(8)两边同取指数,可得:
输出图像g(x,y)为经过同态滤波后的最终增强的图像,具体的同态滤波的流程如图7所示。
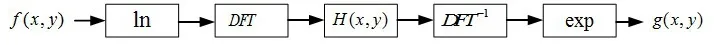
图7 同态滤波流程图
其中,f(x,y)表示输入图像,1n表示以e为底的对数变换,DFT为傅里叶变换,H(u,v)表示滤波处理,DFT-1表示傅里叶逆变换,exp表示指数变换,g(x,y)表示输出图像。因此,可以通过图像照射分量和反射分量的特征来选取合适的同态滤波函数H(x,y),从而达到在减弱图像低频信息的同时,增强图像高频信息的分量的目标。
工业场景中游标卡尺的使用,受光照影响较为普遍,为了达到图像增强的效果,以期方便后期对字符的顺利分割,选择合适的同态滤波器尤为重要[21]。常用的同态滤波器有高斯型同态滤波器、Butterworth型同态滤波器、指数型同态滤波器等。由于传统的同态滤波器在调参时,需要花费大量的时间,参数量较多,如式(10)所示:
其中,D(u,v)为频率(u,v)到(u0,v0)的距离,;D0为截止频率;n为滤波器阶数;rH为高频增益系数;rL为低频增益系数;c为锐化系数,为了增强对比度,选取n为2。由于指数型的同态滤波器可调参数较多,且对于不同的图像,需要调节的参数也不同,尤其是针对不同情况来控制高频或低频增益以及截止频率,就需要依赖大量的经验才能调节好相关参数。为此,本文在指数型同态滤波器上进行改进,在保持较好的滤波效果情况下,引入高低频增益参数γ,提出了改进型的单参数同态滤波器,如式(11)所示:
式中:γ为可调参数,相比其他各类型同态滤波器,可调参数个数从原始的各类型同态滤波器的≥3个,减少至1个,可以方便的调节相关参数,可使滤波器达到最佳效果。其三维结构与文献[22]中采用的同态滤波器相对比,如图8所示。如图8(b)为文献[22]所提同态滤波器结构图,在压缩图像动态范围容易出现过压缩情况,而本文所提改进的同态滤波算法由中心频率到高频的过渡较为平缓,斜率较小,从而导致滤波更为均匀,如图8(a)所示。

图8 改进后同态滤波三维结构对比
本文所提改进型同态滤波与高斯同态滤波器、Butterworth滤波器、文献[22]所提的同态滤波器和指数滤波器,对同一低光照度图像进行处理,处理结果进行比较,如图9所示。

图9 图像增强算法对比
从图9可以看出,图9(a)为原始定位分割出来的仪表显示区域图像,基于高斯同态滤波器增强后的字符区域,如图9(b)所示,可以看出相较原图可以较好的将前景与背景分离出来,但是并不能够将字符的边缘细节呈现出来,如图9(b)、图9(e)所示,Butterworth同态滤波与文献[22]所提同态滤波均不能够对字符和背景进行较为明显的提取,但是指数同态滤波后的图像可以较好的将前景和背景明显区分出来,但是前景字符细节比较模糊,出现联通情况,并不能够较好的体现细节。如图9(f)所示,本文所提算法可以很好的增强了图像边缘与细节,与其他算法相比较而言,对所关注图像边缘纹理细节得到了较好的重构。
1.4 字符提取与识别
二值图像只包含黑白色,灰度值只有0和1,进一步缩小了图像处理数据。候选图像二值化的目的是将图像分成两部分:目标和背景。目标是我们需要的信息,即字符部分,背景是不需要的部分,包括游标卡尺字符的背景信息。二值化过程大致分为两个步骤,首先确定一个合理的阈值,然后将每个像素的灰度值与我们设置的值进行比较。如果灰度值小于阈值,则将像素转换为黑色,否则转换为白色,如图10(b)所示。二值化处理的重点是如何确定阈值,阈值过小可能会得到过多的干扰信息,给后续的字符处理带来困难。如果阈值过大,会破坏部分目标信息,导致缺少有效字符信息,无法进行字符识别。这里我们选取灰度图像自动阈值分割法,通过统计学的方法来选取一个阈值,使得这个阈值可以将前景色和背景色尽可能的分开[23]。这里使用的判据为最大类间方差判据,如式(12)所示。
其中:M为灰度平均值;MA为前景色平均值;MB为背景色平均值;前景色像素数占总像素数的比例记作PA;背景色像素数占总像素数的比例记做PB,最终目标是确定最佳阈值,以确保ICV最大。
此外,图像样本还需要进行边缘检测处理,如图10(c)所示。边缘通常是指像素与周围像素之间明显的阶跃变换,边缘包含丰富的信息,如方向、阶跃属性和形状。该方法的目的是检测图像中亮度变化明显的突出,这些点反映了图像的局部特征。图像数据中还存在不必要或冗余的干扰信息,会严重影响图像质量,因此必须进行腐蚀噪声处理,如图10(d)所示。其基本原理是用一定区域内点的平均值代替图像中某个点的值。主要作用是使周围像素灰度值差异较大的像素点变得接近周围像素点,从而消除孤立的噪声点。如图10(e)所示,闭合操作可以连接图像的近区域,放大不连续的噪声,结构元素不同,放大程度也不同。封闭操作使图像的像素点粘附在一起,可以填充图像的封闭区域,弥补微小裂缝。为了更彻底地消除图像中的噪声,我们进行了二次腐蚀噪声处理,如图10(f)所示。经过一系列的图像后处理,我们得到了一个非常清晰的游标卡尺字符,为我们进一步的图像字符定位提供了依据。
本文的字符识别过程采用基于多浅层网络算法对单个字符进行识别,通过引入循环检测方式,快速检测出相关字符,与显示区域定位的训练方式类似,在开展的图像字符数据识别之前,必须增加训练阶段。在该算法中,应在训练过程中选择合适的单个字符训练样本。样本输入网络后,计算各层神经元的输出和理想输出,然后进行反馈,网络模型根据差异调整修改网络的权重和阈值,重新计算输出与理想输出的差异。以此类推,经过大量学习,不断修改权重和阈值,直到确定网络权重和阈值,最终形成分类器。
本文所提数字式仪表识别方案的总体算法结构图如图11所示。

图11 总体算法结构图
2 实验结果与分析
2.1 硬件及软件环境
实验以MATLAB2017b为仿真平台,开发相关识别模型和人机交互界面,实验所使用计算机操作系统为Windows7,英特尔酷睿I7处理器,NVIDA GeForce GTX 1050Ti显卡,8G内存,摄像头选取手动可调变焦距CMOS工业摄像头,最大分变率为2448×3264。
2.2 实验结果与分析
为了证明本文所提的算法的多场景下的具备较强的泛化能力,和鲁棒性,对比传统识别算法,本文开展了一系列实验与分析。
本文中将摄像头的拍摄区域划分为四个象限,如图12所示,在正常光照条件下,分别对所处四个象限空间的游标卡尺进行识别,共采集1800组数字式游标卡尺图像,分别用于模板匹配法[24]、穿线法[25]和本文所采用的方法进行了评估比较。将参与评估算法的预处理、训练时间、推理与识别时间和识别正确率作为统计指标进行评判,本文所提算法与传统算法的实验结果如表1所示。

表1 识别效果统计与分析

图12 工业相机拍摄区域坐标
虽然,从表1看出模板匹配法和穿线法在平均推理+识别时间,均少于本文算法,然而从识别正确率来看,文本所提算法远远优于这两类算法。在工业部署场景中,仪表检测的正确率往往作为一个重要指标来衡量算法适配场景部署的适应度。
为了进一步说明所提算法具备较强的泛化性能,又将游标卡尺所处环境设计为高光照度、低光照度和正常光照度,共计采集图片测试集样本2000张,如图13所示。应用MATLAB GUI开发相关人机交互软件,软件平台的操作界面如图14所示,能够直观的显示读数结果,大大提高了实验效率。通过本文算法对游标卡尺进行识别,在四个象限内分别进行展开三类光照度的实验,具体结果如图15所示,对实验数据进行统计分析如表2所示。
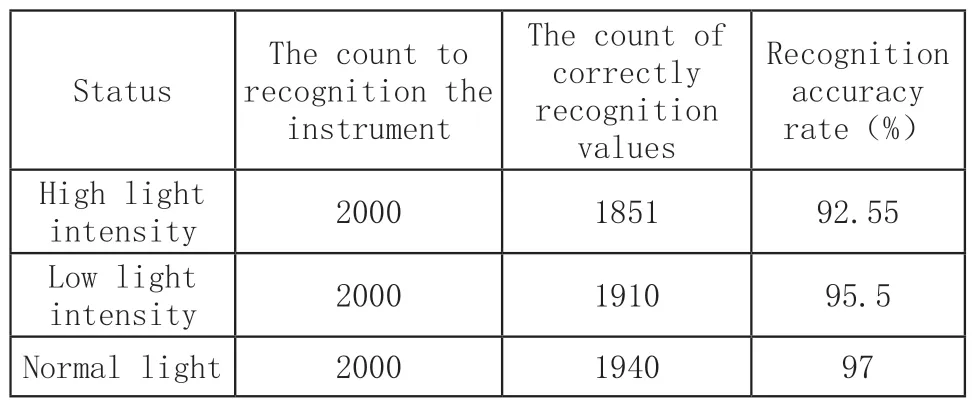
表2 多场景测试实验结果分析

图13 多场景测试样本选取示例
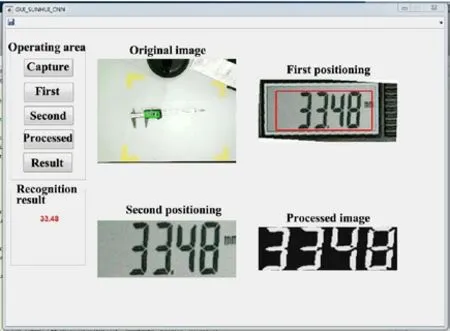
图14 智能识别系统人机交互界面

图15 光照样本识别正确率统计
如图14所示,我们整合了游标卡尺图像候选区域的定位、后处理、二次定位和识别,并建立了人机交互界面。通过对6000张游标卡尺图像的测试,经统计第三象限在强光照条件下识别率相对较低,这是由于本实验所采取的光源为固定照射光源,更加模拟真实工业场景内现场部署时的光照条件,摄像头固定位置不变,因此会导致在第三象限内出现大量的反光照射情况,且对游标卡尺的字符影响较大,甚至出现反光字符遮盖情况,导致了字符缺失,从而使得识别率较低,但从整体实验结果统计来看,平均识别准确率在95.02%以上。
3 结语
由于数字式仪表字符的识别率受到光照对被检测仪表的影响而持续降低,图像增算法能够有效的提升图像质量,更有利于机器识别。本文针对数字式游标卡尺所处的环境光照不均匀,所采集的图像清晰度、对比度不高的问题,研究了基于改进的联合滤波与CNN检测模型的数字式仪表识别算法,引入CNN模型对仪表表盘进行定位和分割,然后设计了改进的联合滤波算法对分割后的图像进行进一步滤波操作,得到对比度较高的灰度图,进而引入浅层神经网络对字符进行识别与组合。最后,本文对算法进行了对比仿真实验,实验结果表明,本文提出的算法能够有效的削弱光照不均匀干扰的影响,同时可增强图像细节及清晰度,在多场景下平均识别率已经能达到95%以上。虽然本文针对多场景的已经达到了较高的识别率,但工业场景的部署应在边缘计算终端进行,尤其是针对老旧设备的智能化改造,因此在接下来的研究中,在保障较高识别率的前提下,将提升本文算法在边缘计算终端部署的能力。
