基于Transformer的人脸深度伪造检测技术综述
2023-11-14赖志茂
赖志茂,章 云,李 东
(1.广东工业大学 自动化学院, 广东 广州 510006;2.中国人民警察大学 移民管理学院(广州) , 广东 广州 510663)
随着生成式人工智能和深度学习技术的快速发展,生成极具真实感的伪造人脸图像与视频变得越来越容易。然而,大众依然普遍持有“眼见为实”的理念,相关伪造视频无疑对当今社会的信任体系造成了极大的冲击。2017年,一个名为“Deepfake”的Reddit社交网站用户,在社交网站上发布了盖尔·加朵等女明星“换脸”视频,标志着人脸深度伪造技术的兴起,此后“Deepfake”和“换脸”也被引用成为了该技术的代名词[1]。在俄乌冲突过程中,假冒乌克兰总统泽连斯基的投降片段和伪造俄罗斯总统普京的紧急讲话视频,引发了民众的恐慌情绪。此外,一些不法分子利用智能AI换脸和拟声技术实施电信诈骗的新骗局走入了公共视野,引起社会多方重视。为应对深度伪造技术带来的社会风险和挑战,越来越多的研究团队开展人脸深度伪造检测技术研究。
早期的检测技术主要以卷积神经网络(Convolutional Neural Networks,CNNs) 为基础[2-12],提取人脸区域作为输入,基于生成过程中引入的伪造痕迹信息,从空域、频域、时域等多个维度中学习到有关伪造痕迹的特征进行二分类(真/假)判别,达到人脸图像和视频真伪鉴别的目的。受限于卷积神经网络感受野的大小和特征交互学习能力弱,基于卷积神经网络的检测技术提取到的人脸伪造特征往往更为局部和单一,难以考虑到图像中全局像素之间的关系和视频中的时序关联[13-15],模型泛化能力不足。
为了提高人脸深度伪造检测技术的泛化性,最新的研究工作开始引入一种基于自注意力机制的神经网络Transformer[16-19]。相对于CNNs模型,Transformer模型在人脸深度伪造检测任务上具有以下4个特点:(1) Transformer模型利用自注意力机制来捕捉输入数据中的长距离依赖关系。这使得它能够更好地理解输入数据之间的关联,这对于检测深度伪造非常重要,因为伪造可能涉及到远距离的上下文信息。相比之下,CNNs主要用于捕捉局部特征,而较难捕捉全局信息。(2) 深度伪造检测可以被看作是一个序列到序列问题,其中输入序列是视频帧或图像,输出序列是二元标签(真实或伪造) 。Transformer在序列建模任务中表现出色,因为它非常适用于处理可变长度的输入序列。CNNs通常需要固定大小的输入,因此在处理可变序列时可能需要额外的预处理步骤。(3) Transformer模型已经在大规模的文本数据上进行了预训练,然后可以迁移到视觉任务上。这种迁移学习使得Transformer能够受益于大规模的多模态数据,从而提高泛化能力。CNNs通常需要在特定的图像数据集上进行训练,泛化能力较弱。(4) 深度伪造技术可能涉及对抗性攻击,其中伪造者试图使检测器产生错误的结果。Transformer模型通常对对抗性攻击更加抵抗,因为它们在训练时包含了更多的数据多样性和复杂性,从而更难受到攻击。
到目前为止还没有文献对基于Transformer的人脸深度伪造检测技术进行全面的分析和总结。鉴于此, 本文首先简要介绍了该领域研究背景,阐述了人脸深度伪造生成典型技术,然后对现有基于Transformer的检测技术进行总结和归纳,最后探讨人脸深度伪造检测技术面临的挑战和未来研究方向。本文对如何设计具有良好泛化性能的人脸深度伪造检测技术有重要借鉴意义。
1 人脸深度伪造生成典型技术
现有的人脸深度伪造生成技术大致可分为以下4种类型:人脸生成、人脸交换、局部伪造和人脸重现。其中,人脸交换和人脸重现是目前深度伪造方向上最流行的方法。
1.1 人脸交换
人脸交换可以实现让原始人物出现在他/她从来没有出现过的场景中,需要提供一组原始人脸和目标人脸作为训练数据进行伪造。典型技术包括Deepfake[20]、FaceSwap[21]等。Deepfake基本原理如图1所示,图中原始视频和目标视频选自公开数据集Faceforensics++[2]。Deepfake技术需要先提取源视频中的人脸以及目标视频中的人脸,并对提取到的人脸进行裁剪和对齐,如调整统一大小。在训练编解码器阶段,使用原始人脸A和目标人脸B作为训练数据,训练一个权值共享的编码器,用于提取A和B的共有面部属性;随后,A和B各自训练一个独立的解码器分别学习A和B特有的面部信息,完成对应人脸重构。在测试生成阶段,待A和B的编解码器训练好后,为了实现原始人脸A和目标人脸B之间的人脸交换,首先利用编码器对B进行面部属性编码,接着用A的解码器对B的面部属性编码特征进行解码重构人脸,生成具有人脸A外貌特征同时保留人脸B面部表情动作的深度伪造人脸。延续类似的思路,研究者提出和发展了更多的人脸交换方法,如FaceShifter[22]、SimSwap[23]等,使得生成的伪造人脸质量大幅提高。
1.2 人脸重现
人脸重现是利用目标人脸的姿态和表情来驱动源人脸,使修改后的人脸保留目标人脸的长相和原始人脸的表情与姿态。典型技术包括Face2Face[24]和FsGAN[25]等。Face2Face是由Thies等提出的一种基于经典计算机图形学进行人脸重现的技术[24]。它能够在保持身份信息不变的情况下将源人脸的表情转移到目标人脸,并可以使目标视频人脸实时模仿口型和表情。首先通过摄像头实时捕获源人脸视频作为源序列帧,并利用密集的光照一致性特征来实时跟踪源和目标视频的面部表情,分别生成对应的面部表情掩码。然后,通过一种新传递函数在二维空间中有效地传递形变,从而将源人脸表情实时传递给目标人脸。最后,利用生成的表情转换掩码文件重新渲染目标人脸,在目标人脸和表情转换掩码融合的基础上处理平滑痕迹,并进行光照强度的匹配得到最终合成的效果图。Face2Face基本原理如图2所示。
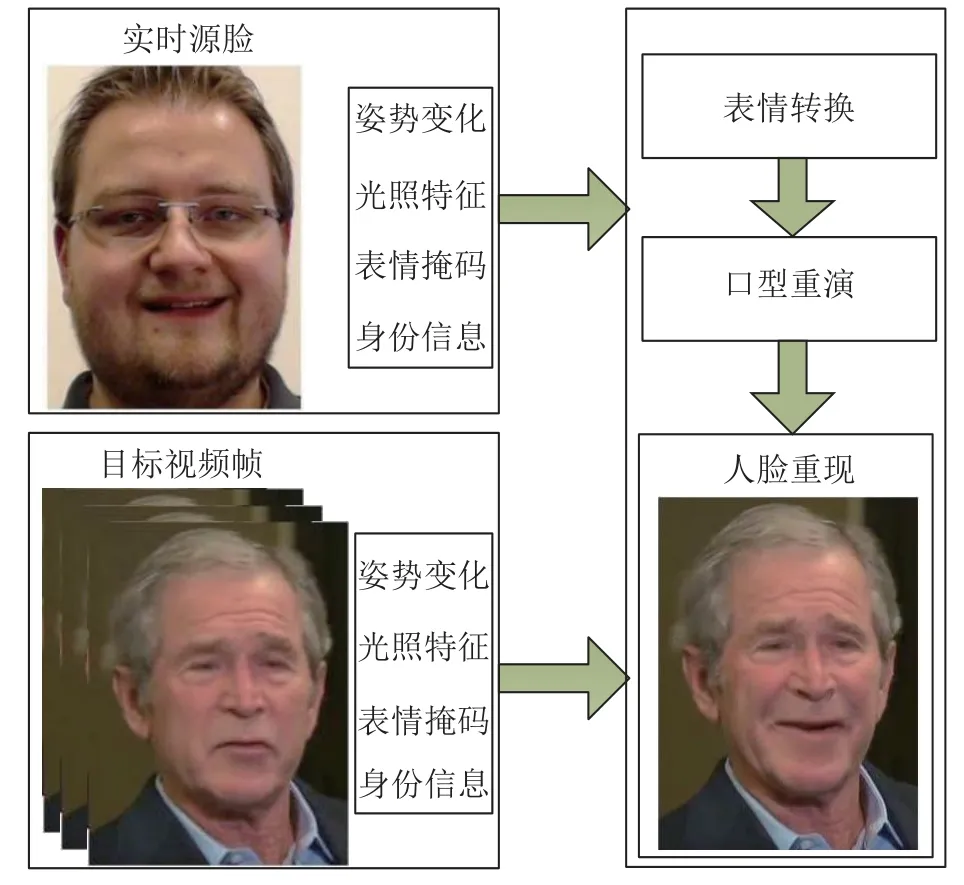
图2 Face2Face基本原理框图Fig.2 Framework of Face2Face
2 基于Transformer的假脸检测技术
2.1 Transformer基础理论
2.1.1 Transformer核心模块
Transformer[16]是一种基于自注意力机制的深度神经网络,首先应用于自然语言处理(Natural Language Processing,NLP) 任务,并逐渐在计算机视觉领域中得到广泛应用。Transformer核心模块是基于编码器和解码器架构,而编码器和解码器由多个层构成。在编码器和解码器的结构中,编码器负责提取特征,解码器负责将提取到的特征转化为结果。其中,编码器由注意力层和全连接层组成。注意力机制主要能让神经网络更聚焦于输入中的相关信息,减少无关信息的干扰,通过权值来决定赋予输入数据的注意力高低。同时,Transformer具有长距离依赖建模能力和更广阔的感受野,从而更准确地提取和处理图像特征[26]。从数学角度来分析,计算注意力可以被描述为一个查询(Query) 到一系列键值对(Key-Value) 的映射。主要有以下3个步骤:
1) 对输入序列z∈RN×d,通过线性映射矩阵UQKV将其投影得到Q、K和V三个向量,分别代表查询向量、被查询向量和信息向量:
2)计算查询向量Q和被查询向量K的点积,并添加一个缩放因子1/,得到相似性权重系数f(Q,K):
3) 利用softmax函数将相似性权重进行归一化处理,并依据权重对信息向量进行求和得到注意力:
而多头注意力就是通过h个不一样的线性变换一起对输入的Q、K、V进行投影,并进行点积注意力计算,最后再把不同的结构拼接起来。多头注意力计算公式如下所示:
2.1.2 视觉Transformer
ViT(Vision Transformer)[17]是在Transformer的基础上修改形成,主要应用于计算机视觉中的图像分类,是视觉Transformer的标准架构。ViT首先将输入的图像X∈RH×W×C进行分块处理,得到N=HW/P2个图像块 (patch) ,对应于NLP中的单词(token) ,将其排列成一维向量X∈RN×(P2×C)作为编码器的输入,其中(H,W)是原始输入图像的分辨率,C是通道数,P是每个图像块的分辨率。随后,利用正弦曲线或余弦曲线对每一个方块进行位置编码。位置编码可以看作是一个特殊的嵌入层,它将位置信息编码成一个向量,并将其加入到输入数据中,用作分类的类别预测结果表示。在进行注意力计算时,模型也能同时区分不同位置的信息,更好地理解输入序列中的上下文关系。最后,通过一个全连接层输出结果。ViT的网络结构如图3所示。
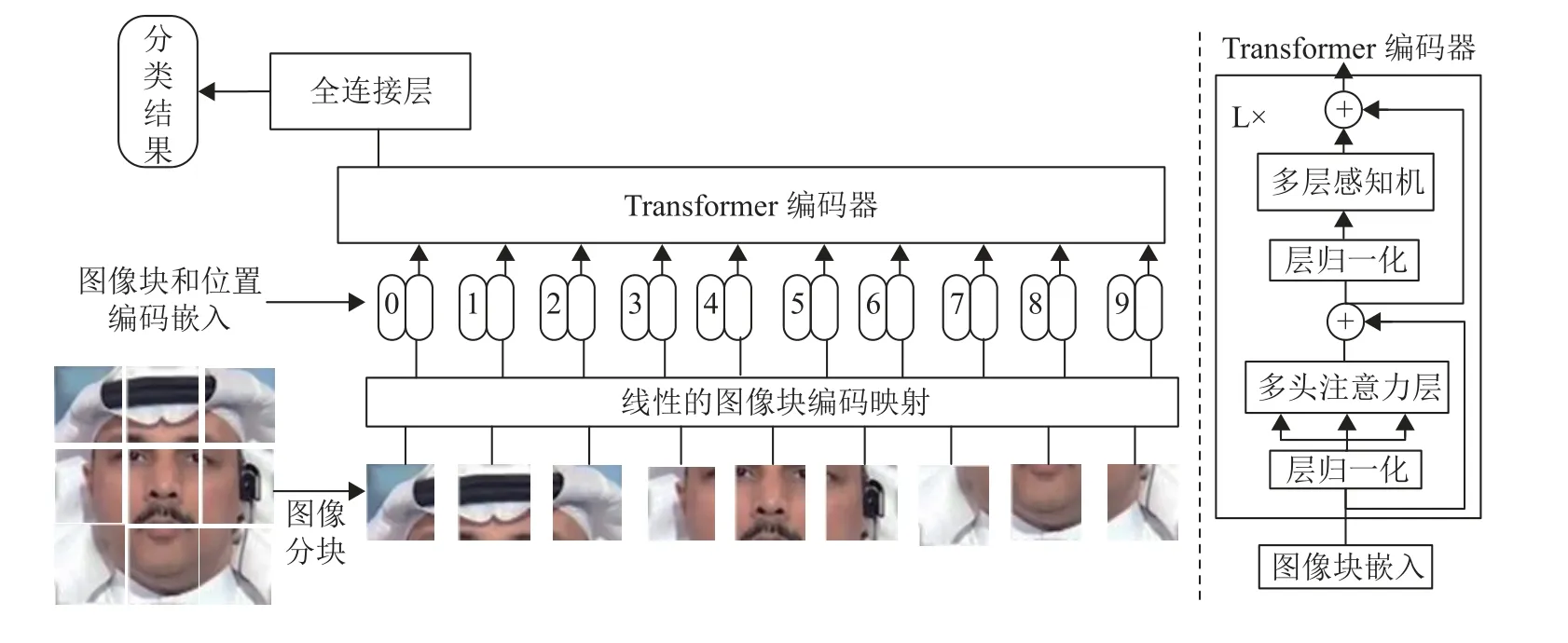
图3 ViT的网络结构Fig.3 Architecture of ViT
为扩大视觉Transformer的适用性,研究者们相继提出了适合不同视觉任务的变体[26]。根据变体模型的特点和达到的处理效果,大致可分为4类:
1) 卷积Transformer。为了增强模型对于局部特征的提取能力,在Transformer模型中引入卷积操作,有效结合归纳偏差与自注意力。典型模型代表有DeiT[27]、CvT[28]和ConViT[29]。
2) 局部Transformer。为了增强模型对于长序列数据的建模能力,减少内存开销,并提高模型在处理长序列数据时的效率,在Transformer模型中放弃全局特性采取局部注意力,灵活处理来自不同空间尺度的特征,提高特征的表达和交互能力。典型模型代表有Swin Transformer[18]、TwinsS-VT[30]和RegionViT[31]。
3) 分层Transformer。为了有效减少梯度消失和梯度爆炸等训练过程中的问题,使得模型训练更加稳定和高效,在Transformer模型中采用分层策略,可以提高模型的训练性能,更好地捕捉图像中的不同尺度和层次结构特征。典型模型代表有PVT[32]和Tokens-to-Token ViT[33]。
4) 深度Transformer。为了减少模型的计算复杂度,可以设计不同的注意力机制来代替Transformer中的自注意力结构,构建出更深层次的Transformer模型以达到更好的效果。典型模型代表有DeepViT[34]、CaiT[35]和CrossVit[19]。
2.2 Transformer在深度伪造检测任务中的应用
随着深度伪造生成技术的日益精细化,研究人员开始引入基于Transformer架构的检测技术,以提升检测器在跨数据集下的泛化性能。根据Transformer表征学习的任务类型可分为基于视觉模态学习的检测技术、基于视觉和听觉跨模态关联学习的检测技术两类。其中,基于视觉模态学习包含了空间上下文关联学习和时间上下文关联学习。表1对Transformer模型在人脸深度伪造检测任务中的应用做出分类并简要说明了各个模型的特点和主要作用。

表1 Transformer模型在人脸深度伪造检测任务中的应用Table 1 The applicetion of Transformer model in Deepfake detection tasks
2.2.1 基于视觉模态学习的检测技术
1) 基于空间上下文关联学习的检测技术。
CNNs架构擅长于通过使用局部感受野、共享权值来学习局部特征。但由于CNNs的感受野有限,它难以捕获全局信息。相反,Transformer的自注意力机制将全局关系和长距离特征依赖关系建模为视觉表示。对于人脸深度伪造检测,基于空间上下文关联学习的检测技术主要从空域和频域挖掘局部和全局的不一致线索。
相比于真实图像在相邻区域的自然连续性,深度伪造人脸图像的人脸区域与其上下文区域具有不同的图像来源,导致其存在不一致的现象。基于空域线索的检测技术侧重于捕获图像空间的不一致信息(如颜色纹理、噪声指纹、视觉伪影等) ,以学习更为本质的篡改检测特征。然而,当遇到各种破坏性形式的图像退化时(如图像压缩、视频编解码转换等) 或者数据域不匹配的条件下,这种低级别的纹理不一致信息很容易受到干扰,从而导致检测方法的性能急剧下降。为此,Dong X等[36]提出基于ViT的身份一致性检测模型(Identity Consistency Transformer,ICT) ,学习人脸高级语义信息,特别是检测对象的身份信息,通过在输入端嵌入序列中添加两个额外的可学习的嵌入标记,从而利用内部和外部面孔区域的身份不一致性来检测可疑的人脸。该模型在获得身份提取网络后不需要任何额外的训练,且可以在没有任何由人脸操作方法生成的假视频情况下进行训练。但是,此种方法需要大量的身份信息标记进行训练,且只能针对存在身份不一致的人脸交换视频,无法检测人脸重现的伪造视频,因其身份前后保持一致。为了减少数据标记工作,解决由于数据域不匹配导致检测性能下降的问题,Chen H等[37]提出用一个两阶段的自监督范式(Transformer-Based Self-Supervised,TBSS) 来提高深度伪造检测的泛化能力。在第一阶段的自监督掩蔽图像建模(Masked Image Modeling,MIM) 和预训练中,利用没有任何图像类注释的序列掩蔽和预测策略来训练一个Swin Transformer编码器,并通过强大的长期依赖建模能力对像素之间的关系建模,提取类内一致性特征。其中,图像序列是视觉Transformer的基本处理单元,在序列级别上操作可以实现可见或掩蔽,从而通过重建被掩蔽破坏的图像来学习有用的表示,更好地保存图像信息。经过预训练后的第二阶段,用标记数据对预训练后的编码器进行微调,以提高其鉴别性能。虽然该模型在检测泛化性能上有了一定的提升,但由于采用了大规模的预训练数据,需要对一个庞大的骨干网络进行预训练,导致了较大的计算成本。
此外,研究人员[3-4,7]在研究中发现,深度伪造生成网络中的反卷积上采样操作无法重建自然图像频谱分布,在频域上呈现网格化特征从而导致合成假脸与真实人脸的频谱分布存在差异。因此,部分研究工作采取融合空域和频域特征进行检测的研究路线。Wang J等[38]引入了一个多模态多尺度检测网络(Multi-modal Multi-scale Transformer,M2TR) ,将输入图像分割成不同大小的序列块,并使用卷积Transformer集成多尺度信息,用于捕捉图像块序列在不同空间层次的局部不一致性。而频率滤波器用于捕捉频域内的细微伪造痕迹,作为一种互补的模式。在空频域交叉模态融合块上,采用Transformer的查询-键-值自注意力机制融合成一个统一的表示。该方法虽然面对高压缩的伪造图像时具有较强的伪造检测能力,但面对未知伪造方法时检测能力仍会急剧下降。为了学习不同空间层次的特征,Tan Z等[39]从全局角度出发,提出了一种具有局部特征补偿和聚合检测框架(Transformer-based Framework with Feature Compensation and Aggregation,Trans-FCA) ,除了利用Transformer捕获全局线索外,还利用卷积来捕获局部细节伪造缺陷。在局部特征补偿模块,提出的全局-局部交叉注意取代Transformer自注意力模块,融合了全局Transformer特征和局部卷积特征。在聚合模块,提出了一个频导融合模块来交互频域中的所有特征,旨在分层聚集与频率相关的特征,随后,使用多头聚类投影将所有特征聚合到单个聚类(特征向量) 中进行深度伪造检测。该方法是Transformer和CNNs 两种架构集成的典型代表,揭示了局部伪造模式和全局关系表示是深度伪造检测器泛化能力的关键,为后续工作提供了很好的研究思路。受此启发,中国科学技术大学的缪长涛等[40]提出一种双分支的分层频率辅助交互网络(Hierarchical Frequencyassisted Interactive Networks,HFI-Net) ,以更好地利用Transformer和CNNs架构各自优势,分别捕获全局上下文信息和局部细节。具体来说,所提出的双分支网络采用可分离的卷积模块和Transformer模块来集中捕获局部伪影和全局特征,利用中高频模式来细化双分支网络的特征,加强两个分支之间的互补特征交互。该方法证明了局部伪造伪影和全局上下文信息具有强烈互补关系,改善了深度伪造检测在跨压缩、跨库检测时的效果;但并没有优化Transformer体系结构的自注意力机制,只是将多个Transformer模块和CNNs进行简单的组合。为了增强视觉Transformer自注意力机制捕获细粒度的特征细节,该研究团队提出高频细粒度检测网络(Fine-Grained Transformer,F2Trans)[41],在Transformer架构中引入中心差分算子,专门设计了一个单流高频微粒度模型用于人脸伪造检测任务,充分利用了在空域和频域的细粒度伪造痕迹信息。该网络包含两个核心组件:中心差分注意(Central Difference Attention,CDA)和高频小波采样(High-frequency Wavelet Sampler,HWS) 。其中,中心差分注意利用卷积来生成局部纹理特征作为自注意力的查询,然后由中心微分算子对查询特征的邻居之间的局部关系进行建模,生成自注意力的键值对,从而增强了Transformer自注意力机制的细粒度表示能力,以捕获更多的信息特征。高频小波采样组件对特征图的高频伪造线索进行层次探索,并关注局部频域信息,有效遏制了低频分量引起的模型干扰。但是,该方法在遇到不可见的扰动时,性能下降明显。
2) 基于时间上下文关联学习的检测技术。
上述基于空间上下文关联学习的检测方法大多针对伪造人脸图像或者伪造视频中的单帧图像进行检测, 而对于伪造视频来说, 还可以利用时间域线索提高伪造检测算法的性能。基于时间上下文关联学习的检测技术主要从不同时间尺度挖掘更精细和全面的时域不一致线索,以检测深度伪造视频。为了提取时间域信息,以往采用的长短期记忆(Long Short-Term Memory,LSTM)[42]机制通过设计门控状态,从而记住需要长期记住的东西,忘记不重要的信息来控制传输状态。而在Transformer的自注意力机制中,视频帧序列中的每一帧都可以与所有其他帧进行关系计算。因此,与LSTM相比,可以更好地捕捉远距离帧的关系,从而提供更有效的时间上下文关联。
由于现有的伪造视频大多都是对真实视频中每一帧图像进行伪造,再将伪造图像进行拼接,最后得到伪造视频。因此,不可避免地会导致明显的闪烁和不连续面部区域。为了挖掘帧间的动态不一致性,Zheng Y等[43]提出一个端到端框架来学习更一般的时间不相关性。它包括两个主要的阶段:第一阶段是一个全时态卷积网络(Fully Temporal Convolution Network,FTCN) ,为了鼓励时空卷积网络学习时间上的不相干性,重新设计了卷积算子,将所有空间(高度和宽度) 维的核大小设置为1,并在三维卷积算子中保持时间维的原始核大小,有助于模型提取时间特征;第二阶段是一个时间Transformer网络,在伪造视频中面部的皱纹或痣可能会逐渐出现或消失,利用Transformer沿着时间维度捕获这种长期依赖关系。相比之前需要依赖于预训练的检测技术,该方法可以在没有任何人工标注的情况下,定位和可视化面部伪造视频中的时间不一致性,更具灵活性和通用性。但由于这种时间不相干性容易受到噪声、压缩等因素的干扰,仍然存在对后处理的鲁棒性问题。为进一步利用局部低水平线索和时间信息,Guan J等[44]提出了基于局部和时间感知的深度伪造检测框架(Local & Temporal aware Transformer-based Deepfake Detection,LTTD) 。该框架采用了一个局部到全局的学习协议,特别关注局部序列内有价值的时间信息。具体地说,作者提出了一种局部Transformer序列,模拟了有限空间区域序列的时间一致性,其中低水平信息通过学习的三维滤波器的浅层分层增强,并以全局对比的方式实现最终的分类。该方法考虑到了局部出现的时间差异信息,这种潜在的时间模式受到空间干扰的影响较小,使得低级建模更加鲁棒。考虑到深度伪造生成和对抗性训练的不断进步,该方法将会遇到在低水平和时间上反向增强的深度伪造视频,预测的可信度有待验证。此外,考虑到已有基于Transformer 的深度伪造检测缺乏可解释性,Zhao C等[45]提出了一种具备可解释性的分离时空自注意力网络(Interpretable Spatial-Temporal Video Transformer,ISTVT) 。它包括一种新分解的时空自注意力和一种自减法机制来捕获空间伪影和时间不一致,并通过相关性传播算法来可视化空间和时间维度的区分区域,提供了在Transformer 内的时间与空间维度的可解释性。该方法有助于研究人员理解Transformer模型如何在时空维度上检测到深度伪造视频,从而改进检测模型的设计。但是,由于该方法侧重于学习短期的帧间不一致,在光照条件和头部姿势一致的数据集上表现不如FTCN算法。为了挖掘更详细的时空信息,Yu Y等[46]提出了一种具有局部时空视图和全局时空视图的多时空视图网络
(Multiple Spatiotemporal Views Transformer,MSVT) 。首先,为了建立局部时空视图,不同于现有的稀疏采样单帧来构建输入序列,作者使用局部连续时间视图来捕获动态不一致性。此外,将每组内提取的帧特征输入时间转换器,生成组级时空特征。然后,通过加入全局时空视图和特征融合模块,建立全局时空视图。最后,利用Transformer集成这些多层次的特征,以挖掘更微妙和全面的特征。该方法论证了局部连续帧的不一致性在伪造人脸视频检测中所起的重要作用。
2.2.2 基于视觉和听觉跨模态关联学习的检测技术
除了从视频的空域、频域、时域等提取信息,部分研究人员也尝试结合音频信息,从跨模态的视角来进行人脸深度伪造检测。相比于CNNs,Transformer具有更强的跨模态融合能力,且鲁棒性更好。由于Transformer的自注意力机制可以将不同模态的信息合在一起变成一维长序列,提取序列特征,计算不同序列的相关性,从而更好地捕捉跨模态数据之间的内在联系。因此,它能够很好地处理多种类型的数据,如图像、音频和文本等,并且对于一些噪声或异常数据也有很好的处理能力。
由于现实场景中的深度伪造视频通常由视觉和听觉两种模态组合而成,针对跨模态深度伪造的检测方法和多模态深度伪造基准,成为了近期的研究热点方向。之前的深度伪造检测工作大多只关注视觉或听觉单模态的检测任务,致力于捕获模态内的伪造信息。基于视觉和听觉跨模态关联学习检测的关键思想是利用同一视频中提取的视频和音频模式之间的关联信息。相比于真实视频,现有伪造技术难以保持伪造视频在视觉和听觉的自然一致性。
早期基于跨模态的检测方法主要利用语音内容挖掘不一致的嘴部动态和扩展辅助训练数据。然而,这类方法关注的是部分面部特征,无法检测视听协同伪造视频。为了克服这种缺点,受跨模态生物特征匹配思想的启发,Cheng H等[47]设计了语音-面孔匹配检测算法(Voice-Face matching Detection,VFD) 。鉴于假视频中声音和人脸背后的身份往往不匹配,且声音和人脸在一定程度上具有同质性的特点。作者首先在一个通用的视听数据集对模型进行训练,采用ViT自注意力机制提取与身份相关的语音和人脸多模态特征,然后对下游的深度伪造数据进行微调。该模型是第一个通过面部和音频的内在相关性来进行深度伪造检测,专注于声音和人脸的一般匹配目标,并且可以快速迁移到各种深度伪造数据集,而不是关注指定的人脸区域。其次,采用预训练微调范式减轻了对辅助数据的需求。但是,该方法遇到脸部光照不足或侧脸的视频检测能力有限,且对特定的面部属性编辑视频检测失效。为提高对侧脸视频的检测性能,Ilyas H等[48]提出基于Swin Transfomer的端到端检测模型(Audio-Visual Deefakes Detection,AVFakeNet),并提供了一个同时操纵音频和视觉模式数据集FakeAVCeleb。该模型利用Swin Transfomer捕获全局的长期依赖性和密集的层次特征,能够正确地分类侧摆姿势的面孔。其中,密集层对网络体系结构中的输入图像和Swin Transfomer进行了精细编码,提取了具有全局感知属性的特征图,建立了不同图像特征之间的关系,能够检测出具有极端侧脸的假视频。此外,所提供的音频-视频多模态深度伪造检测数据集,促进了基于视听觉跨模态检测模型的发展。与此同时,Yang W等[49]同样建立了一个多模态深度伪造检测基准DefakeAVMiT,并提出利用视听不一致性的联合学习方法(Audio-Visual Joint Learning for Detecting Deepfake,AVoiD-DF) 进行多模态伪造检测。具体来说,AVoiD-DF首先在时空编码器中嵌入时间序列和空间位置信息,然后设计了具有交叉注意机制的联合解码器学习内在关系,最后采用一个跨模态分类器来检测具有模态间和模态内不一致的操作。为探索基于两种模态之间更常见的不一致关系,Feng C等[50]提出一种基于异常检测的方法(Audio-Visual Anomaly Detection,AVAD),训练一个自回归Transformer模型来生成视听特征序列,使用了两个Transformer的解码器学习视频帧和音频之间的时间同步特征分布。该方法以自监督的方式提取真实视频中的自然视听觉对应,然后以学习到的真实对应作为目标,指导后续视听觉不一致的提取,挖掘视觉和音频信号之间的细微不一致,并且单独使用真实的、未标记的数据进行训练。但是,该模型无法检测嘴部运动和音频之间保持相对一致的伪造视频,比如只改变说话者面部外观而嘴的运动保持不变。由于不同模态存在差距,其固有的视听觉关系难以提取,且受视听觉协同伪造操作影响,导致上述自监督方法的辅助性能有限,Yang Y等[51]提出了预测性视觉与音频对齐自监督的多模态深度伪造检测方法(Predictive Visual-Audio Alignment Seaf-Supervision for Multimodal Deepfake Detection,PVASS-MDD)。它由预测性视听觉对齐自监督辅助阶段PVASS和多模态检测阶段MDD组成。在真实视频的PVASS辅助阶段,设计了一个基于Swin Transfomer的三支路网络,将两个增强的视觉视图与相应的音频线索关联起来,从而基于交叉视图学习探索常见的视听觉对应。其次,引入了一种新的跨模态预测对齐模块来消除视听觉间隙,以提供固有的视听觉对应。在MDD阶段,提出了辅助损失,利用冻结的PVASS网络来对齐真实视频的视听觉特征,以更好地帮助多模态深度伪造检测器捕获细微的视听觉不一致性,提高泛化性能。
虽然,基于视觉和听觉跨模态的检测方法得到了众多研究者的青睐,但这类跨模态的方法需要伪造视频中包含音频信息,而当前的主流数据集往往只包含视觉内容,只有少部分数据集包含音频内容,因此这类方法的发展也受到了一定制约。
3 模型评测结果
3.1 常用公开数据集
为了降低深度伪造人脸图像与视频所带来的负面影响,给相应的检测技术奠定数据对抗基础,已有一些学者组织了一批人脸深度伪造数据集,用于训练以及评估检测模型的性能。根据数据集的视觉质量和规模,现有常用的深度伪造公开数据集可分为三代,如表2所示。第一代数据集包括FaceForensics++[2]、DeepfakeDetection[52]、DFDC-preview[53]、Celeb-DFv1[54]、Celeb-DF-v2[55]、WildDeepfake[56];第二代数据集包括DFDC[57]、DeepForensics-1.0[58]、 Vox-Deepfake[59]、FFIW-10K[60]、ForgeryNet[61];第三代数据集包括K o D F[62]、F a k e A V C e l e b[48]、L A V D F[63]、DefakeAVMiT[49]。

表2 Deepfake检测主要数据集基本情况Table 2 Overview of mainstream Deepfake detection datasets
3.2 模型性能分析
检测模型的性能评价指标主要包括准确率(Accuracy,ACC) 和接受者操作特征曲线(Receiver Operating Characteristic curve,ROC) 下的面积(Area Under Curve,AUC) 。深度伪造人像视频检测问题也可以看成是一个二分类问题,即样本存在正负两个标签。由于准确率ACC往往会受到正负样本数量分布的影响,因此,在进行跨数据集测试时,主要采用AUC作为评价指标。AUC表示ROC曲线下的面积,主要表示预测结果中正样本排在负样本前面的概率,值越接近于1分类效果越好。AUC不会受到正负样本数量分布的影响,能够客观地衡量模型分类效果的好坏,尤其适用于二分类的问题。
为了评估基于视觉模态的人脸伪造检测器在跨数据集下的泛化能力,构建了一个跨数据集测试协议。具体地说,分别收集整理了8个基于CNNs模型和8个基于Transformer模型的代表性检测算法,统一在FaceForensics++训练集中的所有4类伪造数据上进行训练,并在3个未知数据集上进行测试,包括Celeb-DF-v2、DFDC和DeepForensics-1.0。具体结果如表3所示。从实验结果可以看出,在测试集Celeb-DF-v2上,基于Transformer模型的LTTD算法AUC达到了最高AUC值89.3%,其次是MSVT算法88.81%;在测试集DFDC上,基于Transformer模型的LTTD算法AUC达到了最高AUC值80.3%,其次是MSVT算法76.79%;在测试集DeepForensics-1.0上,基于CNNs模型的PCL+I2G算法AUC达到了最高AUC值99.4%,但是该算法在其他两个测试集性能较低,且多个基于Transformer模型的算法AUC值也都超过了98%。总体来看,基于Transformer模型的检测算法泛化性能普遍高于基于CNNs模型的算法。目前来看,基于Transformer模型的LTTD算法整体上具有最优的检测性能,这主要得益于所提出的局部Transformer捕获局部序列内有价值的时间差异信息,受空间干扰较小。

表3 基于视觉模态的人脸深度伪造检测代表性模型跨数据集AUC结果Table 3 The AUC of cross-dataset experiments for Deepfake detection based on visual modes%
为了评估基于视觉和听觉跨模态的人脸伪造检测器的泛化能力,收集整理了3个基于CNNs模型和3个基于Transformer模型的代表性检测算法,利用3个多模态公开数据集DFDC、FakeAVCeleb和DefakeAVMiT进行跨数据集比较。选取其中一个数据集进行训练,其他2个数据集测试。具体结果如表4所示。从实验结果可以看出,在不同跨数据集测试条件下,基于Transformer模型的跨模态检测算法的泛化性能都优于基于CNNs模型。其中,基于Transformer模型的PVASS-MDD算法取得了最优的检测性能,这主要得益于采用基于Swin Transfomer的自监督网络学习视听觉对应关系,以及引入了跨模态预测对齐模块来消除视听觉间隙,更好地捕获细微的视听觉不一致性。

表4 基于视觉和听觉跨模态的人脸深度伪造检测代表性模型跨数据集AUC结果Table 4 The AUC of cross-dataset experiments for Deepfake detection based on visual-audio modes%
4 结论与展望
本文重点总结分析了Transformer模型在人脸深度伪造检测器性能提升中发挥的作用和技术特点。主要包括基于视觉模态和基于视听觉跨模态两类:在基于视觉模态的检测技术中,Transformer的自注意力机制发挥其全局关系和长距离特征依赖关系建模能力,更好地捕获到伪造人脸图像区域与其上下文区别的空间不一致信息,以及视频帧之间的时间连续性,以改善深度伪造检测在跨压缩、跨库检测时的效果;基于视听觉跨模态联合学习的检测技术中,Transformer发挥其更优异的跨模态融合能力,能更好地捕捉跨模态数据之间的内在联系,挖掘深度伪造视频在不同模态间的不一致关系。
由于如Stable Diffusion等视觉生成模型的快速发展,高保真度的人脸图片可以自动化地伪造,而且一些技术开始进行视听协同伪造,制造越来越严重的DeepFake问题。Transformer由于其具备全局交互能力和大模型预训练能力,有助于人脸深度伪造检测器获取更通用的特征和数据融合能力,有效提升其检测器的泛化能力,有望成为未来的主流模型之一。但也面临一些挑战,包括:
(1) Transformer模型通常需要大规模的数据进行训练,以便获得强大的泛化能力。在深度伪造检测领域,获得大规模的带有标签的深度伪造和真实数据集可能相对困难,因此数据收集和标注成为一个挑战。
(2) Transformer模型通常需要大量的计算资源来进行训练和推理,尤其是大型的预训练模型。这可能对硬件和能源资源产生压力,使得部署成本高昂。
(3) 深度伪造制作者可能会尝试对抗深度伪造检测,通过对抗性技巧来生成更具迷惑性的深度伪造视频。虽然Transformer模型相对于CNNs模型更能抵抗对抗性攻击,但仍然需要采取额外的对抗性训练和防御机制来应对这一挑战。
(4) 虽然Transformer模型在很多任务上表现出色,但在某些特定任务或数据集上,它们可能无法取得最佳性能。这需要更多的研究和调优,以适应深度检测的特定需求。
