基于计算机视觉的轨道交通站内客流识别与预测
2023-11-13张金雷陈瑶杨立兴李华阴佳腾
张金雷,陈瑶,杨立兴,李华,阴佳腾
(北京交通大学 轨道交通控制与安全国家重点实验室,北京 100044)
随着城市化进程的加快,轨道交通客流量不断增加,短时客流识别与预测相关研究也不断增多。既有轨道交通短时客流预测相关研究大多以整个车站为最小单元,但随着智慧地铁的建设,以车站为最小单位进行短时客流预测已经不能够满足更加精细化的轨道交通客流管理需要。因此,轨道交通短时客流预测需要向着更加精细化、科学化的方向改进,基于精细化的轨道交通站内场景短时客流预测信息,乘客可更加合理地规划出行,轨道交通运营管理部门可以及时采取措施疏散站内拥挤乘客,预测和处理紧急情况,保障乘客乘车安全,提升乘客出行体验。因此,研究轨道交通站内不同场景下更加精细化的短时客流识别与预测意义重大。近年来,基于计算机视觉的目标检测与目标跟踪相关研究发展迅速,为利用现有的站内监控视频数据,进行更加精细化的短时客流识别与预测提供了可用的算法。其中,目标检测指对视频当前帧内的所有乘客进行检测,目标跟踪指对视频内的所有乘客轨迹进行跟踪,客流识别指利用目标检测与目标跟踪进行乘客数量统计以及客流时间序列提取。目标检测是计算机视觉领域的基础研究内容,其基本思路是通过处理视频或图片,检测其中的目标。例如,可借助目标检测算法对道路车辆进行检测、分类与计数[1],对轨道交通站内场景下的乘客进行目标检测[2-4]。LIU 等[2]基于深度学习和光流法对上下车乘客进行检测,ZHANG 等[3]基于卷积神经网络对站台场景的乘客进行计数,SIPETAS 等[4]通过存档的视频数据对站台留守乘客数量进行统计。然而,既有的轨道交通相关的目标检测研究仅识别监控视频中的客流数量,没有与其他算法结合对站内不同场景的客流同时进行识别和短时预测。利用视频进行乘客数量统计以及客流时间序列提取时,需要借助目标跟踪算法对乘客轨迹进行跟踪以及计数。目标跟踪算法基于目标检测结果进行,WOJKE 等[5]2017 年提出的Deep SORT 算法是当前较为主流的目标跟踪算法,Deep SORT 可以较好地在目标被长时间遮挡时进行行人重识别。目标检测与目标跟踪结合可以确定检测目标的轨迹,实现乘客数量统计及客流时间序列提取,例如对入侵铁路的异物进行检测和跟踪[6]。然而,目标跟踪算法降低了实时性,因此在进行实时的检测与跟踪时,需考虑如何对模型以及视频进行处理,以满足实时检测与跟踪的要求。短时客流预测相关研究由来已久,从传统的基于数理统计的预测模型,到基于机器学习的预测模型,再到基于深度学习的预测模型,短时客流预测经历了长远的发展[7]。从道路交通领域的ST-ResNet[8],DCRNN[9]和GE-GAN[10]等深度学习框架,到轨道交通领域的WT-ARMA[11],ResLSTM[7]和ConvGCN[12]等深度学习框架,均为当前较为先进的短时客流预测模型。然而,目前轨道交通客流数据主要来源于AFC 刷卡数据,只能统计车站整体的进出站人数,对于站内的闸机口、楼扶梯口、换乘通道等场景,精细化短时客流识别与预测相关的研究不充分,难以从微观层面把握站内不同场景下的客流运行规律。为弥补既有研究的不足,基于检测速度满足实时性的轻量化YOLOv5 目标检测算法[13]和Deep SORT 目标跟踪算法,结合LSTM 预测算法[14],以实时的监控视频数据为输入,以精细化短时客流预测结果为输出,构建实时的、可在线训练的、端到端精细化短时客流识别与预测模型(Detect-Predict)。Detect-Predict 模型通过输入轨道交通站内场景下的监控视频数据,统计过去每5 min 此场景下通过的客流时间序列,并实时预测未来5 min的客流量。并且,模型采用借助稀疏化训练进行通道剪枝的方式对目标检测算法进行压缩,同时采用处理输入视频每秒传输帧数(Frames Per Second,FPS)的方法,使得模型同时满足了实时性与准确性的要求,可以部署应用到轨道交通站内的相应场景。
1 问题描述
为了进行精细化短时客流识别与预测,需要对视频中的乘客进行目标检测和目标跟踪,以获取乘客数量以及客流时间序列,将训练后的YOLOv5目标检测算法表示为f1(x),将Deep SORT目标跟踪算法表达式简化为f2(x),将LSTM 短时客流预测算法的表达式简化为f3(x)。利用获取的客流时间序列进行预测,Detect-Predict 模型可表示为:
式中:X为监控视频数据;Y为当前场景下的短时客流预测结果;f1为训练后的YOLOv5目标检测算法;f2为Deep SORT 目标跟踪算法;f3为LSTM 短时客流预测算法。
对于目标检测算法f1,将采集到的每张图片及其标注作为算法的训练集P(i,mi,xmi,ymi,wmi,hmi)。其中,i最大取图片总数量n=2 428;mi为第i张图片上标注的检测目标数量;xmi,ymi,wmi,hmi分别表示第i张图片、第mi个标注目标的中心点坐标以及检测框的宽和高。使用P(i,mi,xmi,ymi,wmi,hmi)训练YOLOv5目标检测算法,得到适用于轨道交通站内场景、检测目标为乘客头部的YOLOv5算法,YOLOv5算法训练前后可表示为:
式中:f′1为训练前的YOLOv5 算法;f1为训练后的YOLOv5算法。
利用训练后的YOLOv5 算法f1,得到输入视频中每帧图片内的检测目标坐标f1(Xj),并将其输入至Deep SORT目标跟踪算法f2中,对检测目标进行逐帧跟踪,得到乘客的运行轨迹,进而对视频中的乘客数量进行统计,得到统计结果yj。因此,以监控视频数据X作为输入,借助目标检测算法f1与目标跟踪算法f2,可得到客流时间序列识别结果:
式中:Xj为第j个时间段的监控视频数据;yj为第j个时间段内的客流识别统计结果。本文以5 min 为时间粒度进行客流统计。
最后,将多个时间段的客流识别与统计结果作为客流时间序列,输入至LSTM短时客流预测模型f3中,可得到当前场景下的精细化短时客流预测结果:
式中:t为历史时间步,采用8个历史时间步;Y为未来1个时间步的客流预测结果。利用实时的客流统计结果,对LSTM 短时客流预测模型f3进行在线训练并微调,以提升LSTM 算法的实时在线预测精度。
2 模型构建
2.1 Detect-Predict模型框架
基于计算机视觉的轨道交通站内精细化短时客流识别与预测模型的整体结构如图1所示。

图1 Detect-Predict模型框架Fig.1 Diagram of the Detect-Predict model
在构建端到端的精细化短时客流识别与预测模型前,利用闸机口、楼扶梯口、换乘通道、站台等处拍摄并标注乘客头部的图片数据集训练YOLOv5目标检测算法,使得模型能够在轨道交通站内场景下进行乘客头部检测。其次,对模型进行剪枝压缩,以满足实时性及模型部署要求。然后,利用训练并剪枝优化后的YOLOv5 目标检测算法,进行乘客数量统计以及客流时间序列提取。最后,利用提取的客流时间序列训练LSTM 模型,得到预训练后的短时客流预测模型。
模型总体输入轨道交通站内各场景下的监控视频,输出精细化的短时客流预测结果,并通过不断的在线训练,提升模型的预测效果。为了平衡识别精度与处理速度,该模型首先将输入视频处理为30 fps,并输入以头部为检测目标的YOLOv5 算法,检测视频中每帧图片的目标。其次,将检测完毕的、带有检测框的每帧检测结果依次输入到Deep SORT 目标跟踪算法中,获取每位乘客的运行轨迹,并根据运行轨迹统计5 min 时间粒度下视频中的乘客数量。目标检测和目标跟踪部分共同构成客流识别算法。最后,将上述客流识别算法输出的客流时间序列实时输入到LSTM算法中,进行精细化短时客流预测并在线训练与微调,以提升LSTM算法的后续预测精度。
2.2 乘客数量统计以及客流时间序列提取算法
首先,对各场景下的客流数量进行识别和统计。利用站内已有视频监控,借助计算机视觉领域的YOLOv5 目标检测算法和Deep SORT 目标跟踪算法,根据每位乘客在画面中的通行情况统计乘客数量。视频中存在乘客之间互相遮挡问题,由于轨道交通站内视频监控的视角通常较高,头部遮挡情况较轻,因此将检测目标设置为乘客的头部,以减少画面中乘客密集时互相遮挡对检测精度的影响。
YOLOv5目标检测算法是对YOLO系列算法的轻量化改进和对检测速度的进一步优化,既有的方法不能在站内的具体场景内做细粒度检测。YOLOv5具有检测精度高的属性,且能够满足检测的实时性,因此选取YOLOv5 作为模型中的目标检测算法。
Deep SORT 跟踪算法是在以乘客头部为目标的检测算法的基础上,对输入每帧图片中的乘客进行重识别,从而获得乘客的运行轨迹。其中,Deep SORT 的核心算法是卡尔曼滤波算法和匈牙利算法,卡尔曼滤波算法用于对下一帧的目标检测框进行预测,匈牙利算法用于级联匹配和IoU匹配。通过不断的预测和匹配过程,得到乘客的运行轨迹。考虑到算法落地需要模型部署和移植,对YOLOv5 算法进行压缩。采取通道剪枝(Network Slimming)的方法[14]对YOLOv5 算法进行剪枝和紧凑。剪枝的整体步骤如图2所示。

图2 剪枝整体流程Fig.2 Process of pruning
剪枝的具体流程为:对YOLOv5 算法进行正常训练得到能够检测乘客头部的初始网络;对初始网络的Batch Normalization(BN)层进行剪枝;稀疏训练,改变BN 层参数的权重分布,使其均值趋向于0;对参数趋向于0 的BN 层进行剪枝,算法参数减少;微调,使得算法的精度回升,压缩工作完成。
将剪枝完成后更紧凑的YOLOv5 目标检测算法与Deep SORT 目标跟踪算法组合用于乘客数量统计,将不同时间段统计的乘客数量组合成客流时间序列。规定乘客检测框左侧中点处为检测撞线点,如图3中乘客检测框的左侧标定点。在监控画面中设置2 条横向的居中检测线,如图3 中标号分别为1 和2 的横线。根据乘客运行轨迹的标定点通过画面中横向检测线的顺序判断画面中乘客的通行方向和数量,具体为,标定点依次通过2条检测线则相应通过方向乘客数量计数增加一个单位。例如,ID号为41的乘客标记点先通过1线再通过2线,则下行方向Down 的数量加1。最终以此输出5 min 时间粒度下乘客通行数量的时间序列数据,实时输入后续短时客流预测算法中。
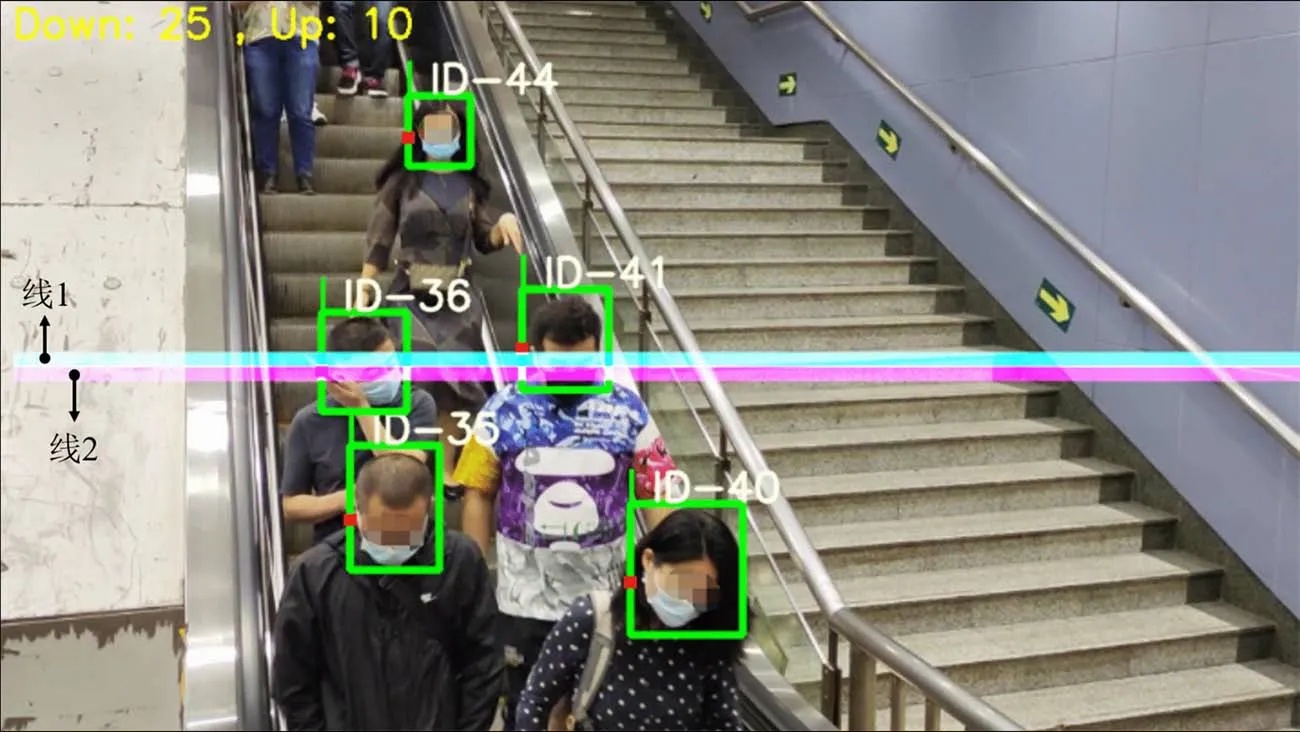
图3 客流识别Fig.3 Passenger flow extraction
2.3 短时客流预测算法
利用以5 min 为时间粒度的客流时间序列,构建LSTM 短时客流预测算法。LSTM 算法可以在一定程度上解决长期依赖问题。将实时提取的客流时间序列不断输入LSTM 算法中,对LSTM 算法进行实时在线训练并预测输出未来客流时间序列。至此,完整的基于计算机视觉的端到端轨道交通站内精细化短时客流识别与预测模型构建完毕。
3 实验及分析
本节对实验环境及数据集进行简介,对Detect-Predict模型以及实验结果进行分析。
3.1 实验环境及数据简介
1) 实验环境
实验平台为64 位win10 服务器,CPU 为i9-10900X,GPU 为RTX3080,配置CUDA10.0+Anaconda3,使用PyTorch深度学习框架1.9.0版本。
2) 目标检测数据集简介
拍摄北京地铁某站站内闸机口、楼扶梯口、换乘通道、站台等处2 428 张图片,标注其中共45 983个检测目标作为轨道交通站内场景下的乘客头部数据集,用于训练YOLOv5 目标检测算法。拍摄的部分场景如图4 所示,画面内乘客角度丰富:图4(a)中闸机口乘客较分散,没有明显分布规律,学习到的特征集中于检测目标本身;图4(b)中换乘通道1的乘客大多背对摄像头,学习到的特征角度多样化;图4(c)中换乘通道2 的乘客十分密集,算法更能适应密集场景下的目标检测。使用LabelImg 准确标注数据集中的每个乘客头部。图4中的方框为标注结果。以此数据集训练目标检测算法可以提高其在不同角度、不同尺度等方面检测乘客头部的准确性。
3) 精细化短时客流识别与预测模型数据简介
此处使用拍摄的北京地铁某站某楼扶梯口的视频数据。考虑到视频数据体积庞大,同时为避免周内各天客流规律不同对实验结果造成影响,选取连续5 个周五且在客流数量最多的早高峰6:30—9:30拍摄视频数据,每日视频时长为180 min,视频分辨率为1 080 P。按照5 min时间粒度统计下行方向通过检测线的乘客数量,每日生成36 个早高峰客流时间序列。其中,视频中的真实人数由人工计数确定。
客流识别时间不能超过视频本身时长,否则会影响识别的实时性。同时,视频帧数越高,识别结果越接近真实值,但是识别的时间越长。因此,为了平衡客流识别的实时性与准确性,将一段5 min 的视频数据处理成如图5 所示的12 个不同帧数下的视频,统计该帧数下对应的识别时间以及识别结果,该5 min 视频内的真实乘客人数为112 人。由图5 可知,随着视频帧数的增加,识别时间相应增长,识别结果更加准确,当视频帧数为30 fps,即图5 中加大圆点处时,识别时间小于5 min,能够满足实时性要求,选取30 fps 的视频作为精细化短时客流识别与预测模型的输入。

图5 帧数选择对识别时间与识别结果的影响Fig.5 Influence of frame number selection on recognition time and recognition results
为验证将视频帧数处理为30 fps是否满足客流识别的实时性,使用本研究拍摄的视频数据对客流识别的实时性进行验证。将总时长为900 min 的视频数据划分为180 个时长为5 min 的视频,将视频帧数批量处理为30 fps,并依次输入客流识别模型中统计单个视频的识别时间。结果表明,在视频帧数为30 fps 的情况下,客流识别的时间均在5 min 以下,识别的平均时间为272 s,部分视频的识别结果如表1所示。因此,客流识别能够满足实时性的要求,时长为5 min 的视频均可在5 min 以内识别完毕。
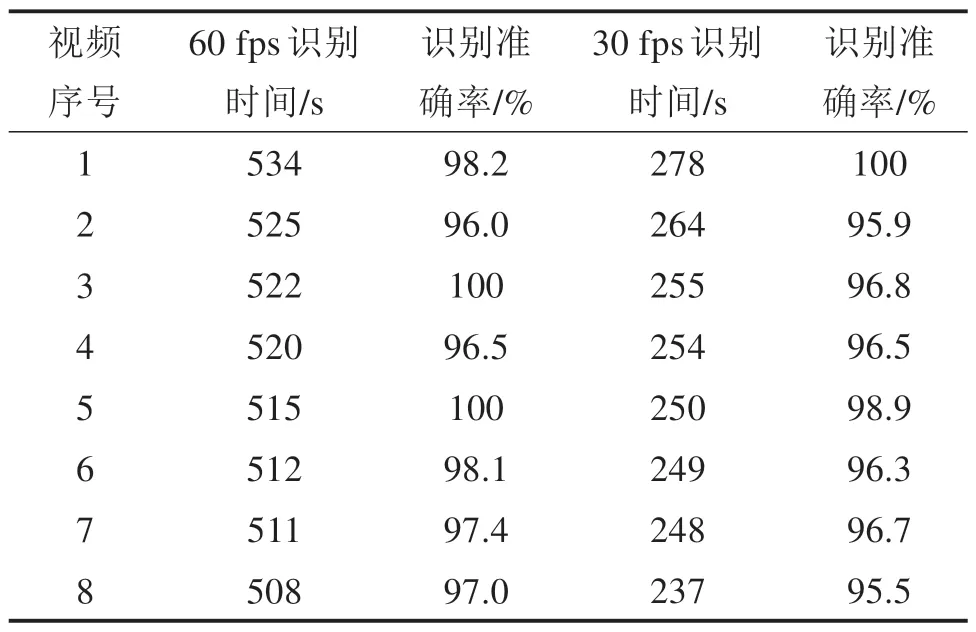
表1 60 fps与30 fps识别时间及准确率对比Table 1 Comparison of recognition time and accuracy between 60 fps and 30 fps
3.2 乘客数量统计以及客流时间序列提取算法
1) 正常训练
训练YOLOv5 的目标检测算法,迭代次数epoch 为300,得到轨道交通站内场景下乘客头部检测的权重。在交并比IoU 为0.5 的情况下目标检测算法的精确率Precision 为0.912,召回率Recall为0.779,平均精度mAP为82.1%。
精确率的计算公式为:
4.教学考核体系不完善。目前空乘专业学生的考核还是沿袭高校学校教学管理部门统一的评估体系,不利于加强空乘专业学生教学过程的控制与管理。第一,所有专业学生大学英语课程统一考试,没有考虑到学生基础的差异性;第二,各专业培养目标不同,学生特点不同,考核形式和内容也应体现个性化特征。对于空乘专业的学生,应该加强教学过程的控制,提高平时的分数比例,结合其到课情况、课堂表现、学习效果给予及时、客观的评价,以提高其学习的信心和积极性。
其中:TPA为乘客头部被正确检测的数量;FPA为将背景错误地识别为乘客的检测数量。
召回率的计算公式为:
其中:FNA为将乘客头部错误地检测为背景的数量。
训练后算法的可视化结果如图6所示,其中检测框为模型的检测结果。该结果显示轨道交通站内多个场景的检测效果较好,正对、背对镜头的乘客能够得以识别,密集通道处的遮挡乘客也得到了较好的识别。这表明该检测算法可以满足统计乘客数量以及提取客流时间序列的需求。

图6 目标检测效果Fig.6 Example of object detection effect
2) 稀疏训练
以上述正常训练得到的YOLOv5 作为初始网络,对其BN 层的权重γ进行稀疏化处理,其中正则系数λ设置为0.000 1。未进行稀疏训练时,初始网络的权重γ值随训练迭代次数epoch 的分布如图7(a)所示,随着训练迭代次数的增加,权重γ始终接近均值为1 的正态分布,其中几乎没有接近0的权重参数,因此可用于剪枝的BN 层较少,难以达到模型压缩的效果。对网络进行稀疏化训练后,权重γ值随训练迭代次数epoch 的分布如图7(b)所示,BN 层的参数随着训练迭代次数的增加,权重分布的均值逐渐趋向于0,因此,存在较多权重的取值接近于0,可用于剪枝的BN 层较多,满足剪枝条件,剪枝后能够达到模型压缩的效果。
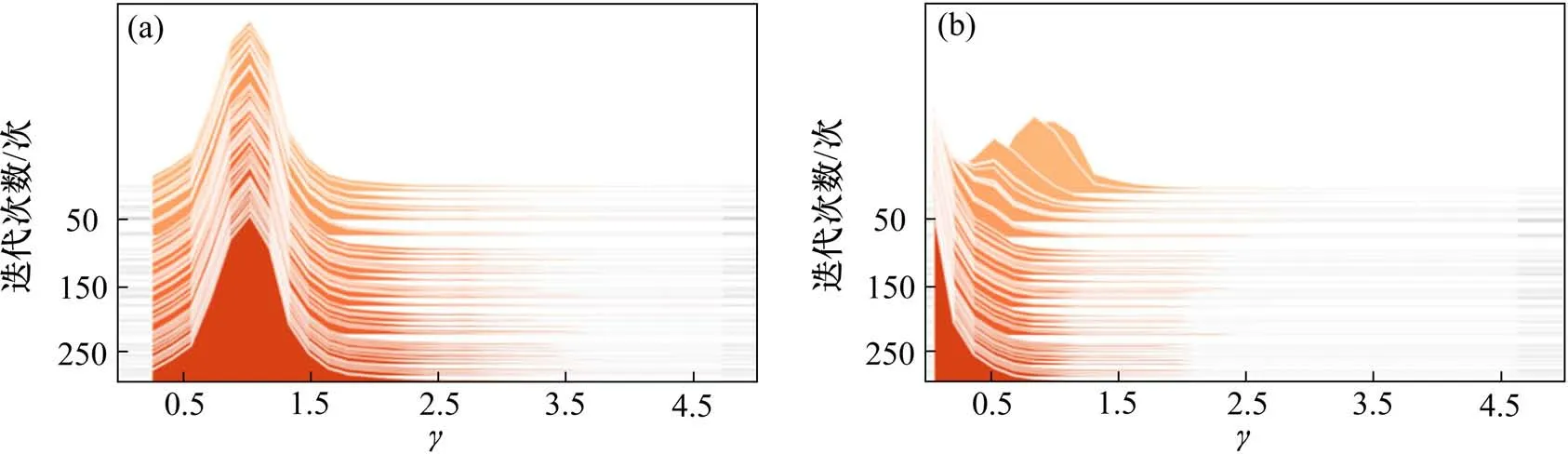
图7 正常训练与稀疏训练的γ值分布Fig.7 Distribution of γunder normal training and sparsity training
3) 模型剪枝及微调
随着训练次数的增加,越来越多的权重γ值接近于0。将权重γ值接近于0 的BN 层从网络中删除,从而达到剪枝压缩的目的。
经过微调,剪枝前后的模型效果对比如表2所示。由表2可知,剪枝的所有步骤完成后,目标检测算法的mAP 上升了一个百分点,权重文件和参数数量均得到了较好的压缩。将剪枝后的乘客头部检测算法与Deep SORT 目标跟踪算法相结合构成客流识别算法,用于统计乘客数量以及提取客流时间序列,其中Deep SORT 算法已在大型行人重识别数据集上训练完毕,适用于对乘客头部进行追踪。

表2 剪枝前后模型对比Table 1 Model comparison before and after pruning
4) 客流识别算法实验结果
以某楼扶梯口下行方向乘客的统计为例,利用客流识别算法对该场景下的乘客数量进行统计。每5 min 输出一次统计结果,得到以5 min 为时间粒度的时间序列数据。将连续5个周五的早高峰视频数据统计与识别结果进行可视化,如图8 所示。结果显示算法识别结果与真实值接近,满足预测需要。
此外,该算法在该楼扶梯口连续5个周五的早高峰6:30—9:30的视频数据上进行测试,得到算法准确率为99.48%。准确率Accuracy 的计算如式(7)所示。
其中:TPB为乘客被正确识别且计数的数量;TNB为非乘客没有被计数的数量;FPB为假阳性,即非乘客被错误识别并计数的数量;FNB为假阴性,即乘客被错误识别且并未得到计数的数量。
3.3 精细化短时客流预测
利用上述识别的客流时间序列,构建基于LSTM 的短时客流预测模型,取80%的数据为训练集,学习率为0.002,迭代次数epoch 为1 500。剩余20%的数据为测试集,用于端到端的Detect-Predict 模型的测试,该模型预测结果的均方根误差RMSE 为11.07,平均绝对误差MAE 为8.02,加权平均绝对误差百分比WMAPE 为12.57%,预测结果如图9所示。预测结果能基本拟合真实结果,说明Detect-Predict 模型具有较好的短时客流预测效果。
4 结论
1) 当视频取30 fps时,短时客流识别算法能够同时满足实时性与准确性要求。
2) 采用的通道剪枝方法能够有效降低模型体积和参数量,节省计算资源,使得剪枝后的模型权重文件大小由14.4 M 减小到2.9 M,参数数量由706万减少到139万。
3) 提出的端到端的Detect-Predict 模型中,识别部分的准确率Accuracy 为91.0%,召回率Recall为78.0%,平均精度mAP 为82.1%,预测部分的RMSE 为 11.07,MAE 为 8.02,WMAPE 为12.57%。精细化短时客流识别与预测效果均较好,可用于部署应用,掌握轨道交通站内微观客流变化规律,从而进行精细化客流监控和运营管理。
Detect-Predict模型为轨道交通站内的精细化客流统计和预测提供了理论方法,但由于轨道交通站内场景具有复杂多样性,模型精度可能受监控设备的分辨率、乘客的重叠程度等外部因素影响。在此基础上对输入视频和模型精度的影响关系进行探究,有望实现精度更高、鲁棒性更强的轨道交通站内精细化短时客流的识别与预测。
