基于BERT的金融文本情感分析与应用
2023-11-13季玉文
季玉文, 陈 哲
(1.浙江理工大学计算机科学与技术学院, 浙江 杭州 310018;2.浙江理工大学信息科学与工程学院, 浙江 杭州 310018)
0 引言(Introduction)
金融市场的发展水平是衡量社会商品经济发展水平的重要指标。学者们长期以来一直通过历史交易数据研究和预测市场变化规律。但是,金融市场的变化波动受到政策、股本、金融公司变动等多方面因素的影响,其数据具有非线性、非平稳性和高噪声等特点,因此研究难以取得有效的成果。
随着互联网和科学技术的发展,人们开始意识到可以通过网络监控金融舆情信息,进而分析行业动向和市场前景。已有研究表明,网络舆情信息可以影响投资机构或投资者的投资行为,进而对股市产生影响[1]。然而,网络文本数据的噪声高、数据量大,传统的经济学方法难以准确挖掘文本中隐藏的信息,因此学者们开始将深度学习技术应用于该领域。
本文基于深度学习主题爬虫,创建金融文本情感标注数据集,填补了当前金融文本情感标注数据集的空白;采用目前文本分析领域应用效果最好的BERT模型,并结合Bi-LSTM模型,丰富了深度学习方法在金融领域的研究。
1 相关研究(Related research)
1.1 主题爬虫
主题爬虫是一种特殊类型的网络爬虫,它的初始统一资源定位符(Uniform Resource Location,URL)集合是与预定义主题高度相关的页面。主题爬虫从这些种子URL开始,分析页面并提取与主题相关度高的链接,形成一个扩展URL集合。主题相关度计算是主题爬虫的核心模块,它决定了爬虫是否能够很好地保留主题相关的网页和过滤掉与主题无关的网页。目前,主题爬虫常用的相似度计算策略主要分为两类:基于网页链接结构的搜索策略和基于内容评价的搜索策略。
胡萍瑞等[2]根据互联网站点同一版块URL在结构和语义特征上的相似性,设计了一种基于URL模式集的主题爬虫,能够在下载页面之前判断主题相关度。于林轩等[3]将PageRank算法应用于主题爬虫,构建了一个垂直搜索引擎。需要注意的是,基于链接分析的搜索策略主要依据URL的构成进行主题相关度判断,忽略了网页正文内容,容易造成“主题漂移”的现象。
传统的基于内容评价的搜索策略使用词频和向量空间模型作为核心算法,通过对当前爬取的页面正文内容、网页结构进行分析,判断当前页面是否与主题相关。YOHANES等[4]采用遗传算法改进局部爬虫算法的缺陷,精确爬取和遍历主题相关的Web,使爬虫主题更加聚焦。DU等[5]采用将向量空间模型和语义相似度模型相结合的方法,改进了主题相关度计算模块。近年来,随着深度学习在文本、语音和图像等数据处理领域的不断发展,它在文本分类问题上的应用也已经取得了显著的成果。Word2Vec、BERT等词编码技术及TextCNN、LSTM等模型的提出和发展极大地提高了分类的准确率。HUAN等[6]将多种深度学习模型结合使用,提高了分类的准确性。
本文将主题爬虫中的主题相关度问题看作是一个文本分类问题,首先收集主题相关的文本数据集并训练模型,其次依据模型计算网页中文本的主题相关度,计算网页的主题相关度。
1.2 文本情感分析
目前,主流的文本情感分析方法可分为基于情感词典、机器学习和深度学习三类。
基于情感词典的方法是传统的情感分析方法,它利用情感词典中的情感极性计算目标语句的情感值。国外最早的情感词典是SentiWordNet,李寿山等[7]使用英文种子词典和机器翻译系统构建了最早的中文情感词典。尽管基于词典的分析方法实现简单,但准确率在很大程度上依赖于构建词典的质量,并且构建情感词典需要耗费大量人力物力,对新词的适应能力也较差[8]。
相对于基于词典的方法,机器学习在文本情感分析任务上能够取得更高的准确率。唐慧丰等[9]使用几种常见的机器学习方法(如SVM、KNN等)对中文文本进行情感分类,通过多次实验比较,研究特征选择方法、文本特征表示方法等对分类结果的影响。刘丽等[10]和唐莉等[11]将条件随机场与依存句法规则等结合,实现了特征与情感词的提取。前者利用复杂句式规则进行粗粒度分析,计算整体情感倾向;后者基于情感词二分网,采用MHITS(拓展的基于超链接的主题搜索)算法对特征词和情感词的权值进行计算排序。虽然机器学习在文本情感分析方面取得了不错的效果,但是需要专业人员对相关特征进行专业分析和提取且其泛化能力较差。
深度学习的自动提取特征的特点弥补了机器学习在特征提取困难,泛化能力差等方面的不足,它只需要对已标注的数据进行多次迭代训练,就可以实现高准确率的文本情感分析。潘红丽[12]基于RNN(循环神经网络)和LSTM(长短时记忆网络)对英文文本中的情感信息进行分析,准确率达到了94.5%。BASIRI等[13]提出了一种基于注意力的双向CNN-RNN(卷积神经网络-循环神经网络)模型(ABCDM),它考虑了时间信息流的双向性,同时结合注意力机制突出重要的词语。近年来,研究者发现Word2Vec和GloVe学习得到的是静态的词向量,忽视了上下文的关系,动态词向量算法ELMo和BERT的提出解决了这种语境问题。刘思琴等[14]和方英兰等[15]利用BERT预训练语言模型代替Word2Vec和GloVe训练词向量,嵌入其他模型后获得了更好的分类效果。
2 主题爬虫设计(Design of theme crawler)
主题爬虫的设计包括四个关键模块:网页获取、网页解析、搜索调度和网页存储。网页获取模块负责从目标URL获取HTML文件。网页解析模块则负责从HTML文件中提取出当前网页的链接和文本,并根据链接目标与爬虫主题的相关性判断链接的主题相关度。搜索调度模块基于主题相关度或其他规则,制定合理的访问调度策略。网页存储模块将目标网页存储到数据库中。
本文所采用的主题相关度计算是基于网页中文本的分类,在爬取新的网页时,先判断该网页包含的文本集合与爬虫主题的相关性,并根据结果计算该网页的主题相关度。这个过程是主题爬虫中至关重要的一环,它保证了爬虫能够针对性地爬取与主题相关的网页。
2.1 文本主题相关度判断模型
2.1.1 搭建数据集
首先,在综合考虑各个金融网站的用户量和知名度等因素的基础上,筛选出排名靠前的几个URL作为主题爬虫的种子URL集合,并从这些网站中获取短文本数据。其次,人工排除与主题无关的文本,将剩余的与主题相关的文本加入语料库,并标记为1。此外,从THUCNews、ChnSentiCorp和今日头条新闻等数据集中选择部分非主题分类的数据集加入语料库,并标记为0。经过处理后,得到的语料库样例如表1所示。

表1 语料库样例
2.1.2 文本主题相关判断模型
相关度计算采用的模型是BERT+Bi-GRU模型,BERT模型基于双向Transformer结构生成上下文感知的动态词向量,能够更好地表示上下文语义信息。首先利用BERT模型将中文字符转换为包含文本信息的词向量,其次将BERT输出的词向量输入Bi-GRU模型进行特征提取。GRU模型是LSTM模型的一种变种,相比LSTM,GRU只有两个门控开关,其一是将LSTM中的输入门和遗忘门合二为一的更新门,用来控制前一神经元保留的数据量,其二是重置门,用于控制要遗忘多少过去的信息。GRU状态的传输是从前到后的单向传输,由于文本语义信息是由前后文语境综合得出,所以采用包含一个前向GRU和一个后向GRU的Bi-LSTM作为特征提取模型,分别学习序列中各个词的左右和上下文信息。GRU合并了LSTM的门控函数,其参数数量要少于LSTM,所以GRU的计算更简单,实现更容易,也更加节省计算资源。
2.2 网页主题相关度计算
对于网页中一个新的URL链接,相关度计算的步骤如下。
(1)判断新的URL是否已被爬取。
(2)分析网页内容,获取其中的所有文本集合。
(3)将集合中的短文本依次输入神经网络获得每一个短句是否为与主题相关的分类。
(4)将“步骤(3)”中得到的两种分类数目的比值作为最终的主题相关度。
2.3 主题爬虫设计
结合深度学习模型的主题爬虫具体步骤如下。
(1)选择10个初始种子链接作为种子集合,将之放入等待队列WaitQueue中。
(2)计算种子集合中各URL的主题相关度。
(3)选择集合中相关度最高的网页进行爬取解析并存储其中与主题相关的短句。
(4)对“步骤(3)”中选择的URL解析的新URL集合进行相关度计算,并选取相关度最高的前10个URL加入种子集,从种子集中删除当前URL。
(5)判断网页存储数量是否到达目标数量,否则重复“步骤(3)”。
3 文本情感分析(Text sentiment analysis)
3.1 数据预处理
文本情感分析数据集是通过主题爬虫爬取,专业软件数据导出等方式进行收集,并请金融从业专家进行标注。收集的原始文本数据样例如表2所示。

表2 原始文本数据样例
针对表2中文本的处理工作主要包括数据清洗、数据标注等。具体来说,首先去除与金融无关的文本数据,其次去除文本数据中多余的符号和连接词等无用字符。再次邀请三位金融从业专家分别标注数据集,按照文本情感偏向分类,积极标1,消极标-1。最后将三位金融从业专家对每一条文本数据的标注值取平均值,大于0取1,小于0取-1,得到最终的分类标注。最终标记完成的文本数据如表3所示。
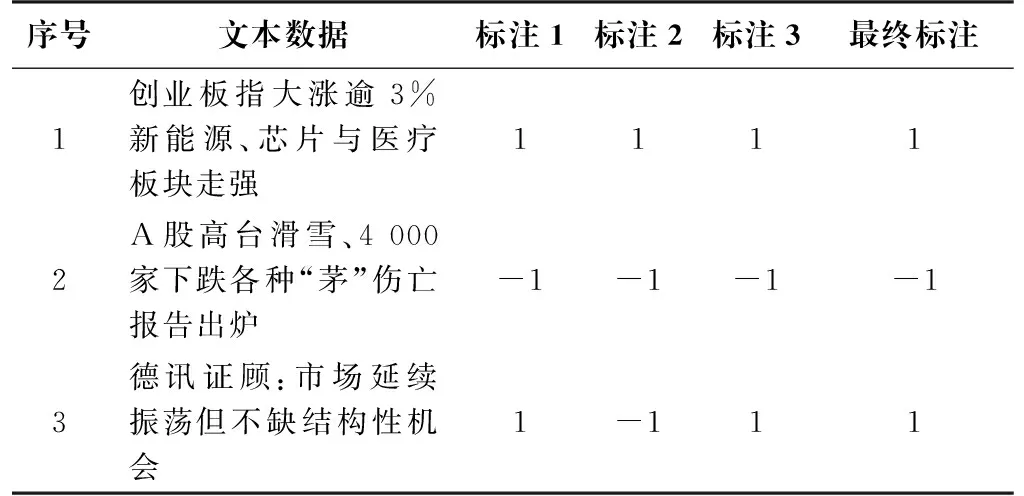
表3 预处理结果
3.2 基于BERT+Bi-LSTM的金融文本情感分析模型
本文采用基于BERT+Bi-LSTM的金融文本情感分析模型共包含四层,模型结构如图1所示。

图1 模型结构Fig.1 Model structure
3.2.1 BERT预训练模型获得文本的向量表示
本文采用哈尔滨工业大学•讯飞语言认知计算联合实验室发布的中文预训练语言模型BERT-wwm-ext作为预训练模型。相比原始BERT模型,随机掩盖15%的字进行上下文预测,BERT-wwm-ext模型采用WWM(Whole Word Masking)方法,将同一个词中的每个字全部掩盖,从而预测整个词,进一步增强了模型对上下文的理解能力和语义信息的学习[16]。该方法是当前中文预训练模型中最为适合的方法,能够为金融文本情感分析任务提供较高的语义信息提取和表达能力。
3.2.2 Bi-LSTM提取特征
RNN常用于捕捉序列之间的依赖关系,通过将前一个神经元的输出作为后一个神经元的输入利用序列间的隐藏信息。然而在训练过程中,函数迭代会导致梯度消失或梯度爆炸问题。为了解决这个问题,LSTM被设计出来,它是一种特殊的RNN,具有独特的“门”机制。每个LSTM细胞都包含三个门和一个记忆单元,LSTM细胞的结构如图2所示。LSTM可以有效地处理长序列的训练,并在文本情感分析中表现出色。
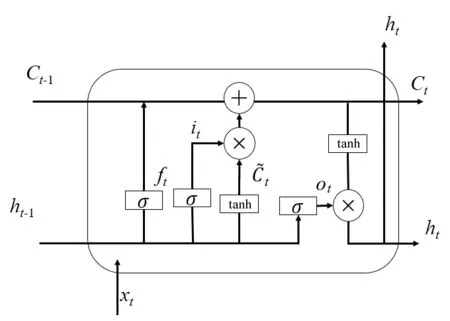
图2 LSTM细胞结构Fig.2 Cell structure of LSTM
遗忘门用来决定前一个细胞中信息的保留或丢弃,它读取ht-1和xt,经过Sigmoid函数输出一个在0~1的值,对于每个在记忆单元Ct-1中的元素,1表示完全保留,0表示完全舍弃;具体计算方式如公式(1)所示:
ft=σ(Wf·[ht-1,xt]+bf)
(1)
输入门用于更新细胞状态,确定什么样的信息内存放在记忆单元中,包含以下两个部分。
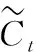
it=σ(Wi·[ht-1,xt]+bi)
(2)
(3)
输入门完成工作后,要更新细胞状态,将Ct-1更新为Ct。首先将旧状态Ct-1与ft相乘,遗忘掉由ft确定的要遗忘的信息,然后加上被筛选后的候选状态,得到新的记忆单元,如公式(4)如下:
(4)
输出门ot将内部状态的信息传递给外部状态ht,同样传递给外部状态的信息也是过滤后的信息。首先,Sigmoid层确定记忆单元的哪些信息被传递出去[如公式(5)所示]。其次,将细胞状态通过tanh层进行处理,并将它和输出门的输出相乘,最终外部状态仅仅会得到输出门确定输出部分,如公式(6)所示:
ot=σ(Wo·[ht-1,xt]+bo)
(5)
ht=ot⊙tanh(Ct)
(6)
情感分析模型采用双向的LSTM模型,结合前向传播和反向传播得到的向量,同时捕获上下文语义信息。本文实验中,使用BERT对字符进行编码,并将输出乘以权重W作为Bi-LSTM的输入。Bi-LSTM在不同方向的隐层上进行计算,最终将两个方向的计算结果拼接输出。
3.2.3 情感计算
首先将Bi-LSTM输出的特征向量作为一个全连接层的输入,其次将全连接层的输出经过一个Softmax函数得到一个向量,该向量表示该条文本属于积极或消极的概率值,介于0~1。
4 实验结果分析(Analysis of experimental results)
4.1 文本情感分析实验结果分析
4.1.1 数据采集与标注
本实验使用的数据主要来源于Choice金融数据终端和主题爬虫从种子URL集合开始爬取的网络文本,总计获得7 000条文本数据。数据集的分布结果如表4所示。

表4 数据集分布结果
4.1.2 评价指标
本实验使用准确率(Accuracy)、召回率(Recall)、精确率(Precision)和F1值(F1-Score)评价模型预测效果[17]。准确率是预测正确的样本数量占总体样本数量的比例。精确率反映的是在所有预测为正向的样本中,预测正确的比例。召回率反映的是预测为正的数量与实际为正的数量的比例。F1值是为了调和精确率和召回率而设计的指标。各项指标的计算如公式(7)至公式(10)所示:
(7)
(8)
(9)
(10)
其中:TP表示预测为正且真实为正的样本数量,TN表示预测为负且真实为负的样本数量,FP表示预测为正真实为负的样本数量,FN表示预测为负真实为正的样本数量。
4.1.3 模型与参数设置
模型参数的设置对实验结果的好坏起到决定性作用,本实验经过多次调整后,最终选取的参数如表5所示。

表5 模型参数
4.1.4 结果分析
为验证本文所使用的预训练模型与特征提取模型的有效性,本文设计多组对比实验,对比结果如表6所示。

表6 实验对比结果
由实验结果可知,BERT+Bi-LSTM模型取得了87.1%的准确率和87.5%的F1值,相比Word2Vec+Bi-LSTM模型,准确率提升了4.7%,精确率提升了4.2%。由此证明:BERT-wwm-ext模型能更有效地将文本信息转化为向量表达。相比BERT+LSTM模型,BERT+Bi-LSTM的准确率提升了3.2%,说明双向LSTM能够更好地提取文本特征。通过比较Bi-LSTM和Bi-GRU模型的结果可知,尽管GRU模型在参数数量和计算效率上具有一定优势,但由于参数减少,导致准确率略有下降。
4.2 主题爬虫实验结果分析
主题爬虫的应用主要可以分为两个方面:一是爬取大量的文本数据用于训练情感分析模型,二是每日爬取当天的股评、新闻等文本,用于市场情绪的可视化。
在为文本情感分析模型爬取数据集时,本研究共爬取了500个网页中的5 000条数据。为了评估主题爬虫中文本主题相关度判断模型的性能,本研究采用准确率、召回率、精确率以及每100条数据的判别时间作为评价指标。BERT+Bi-LSTM和BERT+Bi-GRU的实验结果如表7所示。

表7 实验对比结果
经过对比发现,尽管BERT+Bi-LSTM的准确率比BERT+Bi-GRU高0.8%,但它每百条文本的判别时间比BERT+Bi-GRU高了0.6 s,这对于包含大量文本数据的网页来说,并不是最优选择。因此,在主题爬虫的文本相关性判断中,使用BERT+Bi-GRU模型能够获得更好的效果。
4.3 市场情绪可视化实验结果及应用
4.3.1 市场情绪值的计算
市场情绪值的计算是根据当日网络媒体中的短文本集合进行的,具体的计算步骤如下。
(1)利用主题爬虫爬取5 000条当日互联网中与金融相关的文本并存储。
(2)将文本集依次输入文本情感分析模型,得出每条文本的情感倾向。
(3)计算文本集中情感倾向为1的文本数量与总文本数量的比值,作为当日的市场情绪。
4.3.2 应用
本次实验结果已经作为市场技术分析的一部分被金融软件“对聪易”采用,市场情绪可视化应用结果如图3所示。

图3 市场情绪可视化应用结果Fig.3 Market sentiment visualization application
5 结论(Conclusion)
市场情绪对于个人投资、公司经营、政府监管等方面都有重要意义。本文结合自然语言处理和网络爬虫技术,搭建了金融相关的主题爬虫,并利用爬虫为情感分析模型爬取数据。使用基于BERT和Bi-LSTM的深度学习模型,对金融文本数据进行情感分析,并将模型运用到交易软件的搭建中。
在未来的研究过程中,可以从两个方向继续深入探索。一方面,可以引入注意力机制提升情感分析过程中某些关键词的权重,同时降低非关键词的权重,从而获得更好的分析效果。另一方面,本文只考虑了积极、消极两种情绪,未来可以考虑更多元的分类或者量化分类,以更好地反映市场情绪的变化。这些深入研究的探索,将有助于更准确地把控市场情绪,帮助投资者、企业家和政府监管者更好地做出决策。
