基于信息量、加权信息量与逻辑回归耦合模型的云南罗平县崩滑灾害易发性评价对比分析
2023-11-11杨得虎朱杰勇刘帅马博代旭升
杨得虎,朱杰勇,,刘帅,马博,代旭升
(1.昆明理工大学国土资源工程学院,云南 昆明 650093;2.自然资源部高原山地地质灾害预报预警与生态保护修复重点实验室,云南 昆明 650093)
0 引言
云南以红河深大断裂为界,滇西为高山纵谷区,滇东为喀斯特高原[1],滇东北为地质灾害高易发区,滇西地质灾害易发性南相对较弱[2]。罗平县地处云南滇东喀斯特高原地区,是典型的岩溶山区。目前,崩滑易发性制图主要分为定性、定量和机器学习3 种方法[3-4]。定性分析是通过对成因机制的全面认识,基于专家经验和知识确定评价因子权重,定量分析方法通过数学或数值算法估计滑坡易发性[5]。定性分析方法主要有层次分析法[6-8],定量分析方法主要有频率比法[9-10]、信息量法[11-12],机器学习方法有逻辑回归法、随机森林法、K 近邻、支持向量机和神经网络等[13-15]。国内外学者进行研究分析,并采用多种研究方法进行对比,吉日伍呷等[15]通过逻辑回归、K 近邻、朴素贝叶斯和随机森林算法对鲁甸进行地震滑坡易发性评价,并得出统计建模地更多的是寻找变量之间的可解释关系;樊芷吟等[16]通过信息量法+Logistic 回归模型对汶川县进行易发性评价;张晓东[17]通过定量信息量法和确定性系数法分别与Logistic 回归耦合对宁夏盐池县进行易发性评价,得出耦合模型结果均优于单一模型评价结果。根据以上研究,易发性评价模型首先选取崩滑评价影响因子,再通过分类分级进行计算,根据不同方法得出的结果基于ArcGIS 进行等级划分。信息量法只考虑了评价因子分类分级状态下的权重,其优点在于原理简单,易于实现;缺点在于无法体现所选取的评价因子的权重。因此选取层次分析法和逻辑回归法分别赋予评价因子的权重,其中层次分析法依据崩滑灾害成因分析,通过专家法构建矩阵计算得出评价因子的权重,逻辑回归法是依据样本数据和连接方法,通过两种方法得出评价因子的权重分别与信息量法进行耦合,其耦合模型将评价因子的权重和分类分级的权重叠加得到综合权重,降低了单一评价模型人为主观性因素的影响,论证不同方法评价结果的准确性。
本文以罗平县作为研究区域,基于野外详实的地质灾害调查成果,综合分析孕灾地质条件和崩滑点分布规律,选取岩土体(工程岩组)、地形地貌(坡度、坡向、高程、起伏度、曲率、地貌类型)、地质构造(距断裂距离)、气象水文(距河流距离)等评价因子。采用信息量法、加权信息量法、信息量-逻辑回归耦合法构建易发性评价模型进行对比分析,并对评价结果进行精度检验分析,选取精度最高模型易发性分布图,可为罗平县今后地质灾害治理提供参考依据,对今后城市的发展和防灾减灾有重要意义,也可为岩溶地区地质灾害易发性评价提供参考。
1 研究区概况及数据来源
1.1 研究区概况
研究区(罗平县)位于云南省曲靖市东部。东西最大横距75 km,南北最大纵距99 km。相对高差为1 705 m,全县面积3 018 km2,山区面积占78%,坝区面积占22%(图1)。研究区西部和北部属于岩溶盆地地貌和岩溶低中山地貌,中部属岩溶断陷湖形盆地,东部和南部受九龙河和南盘江流域侵蚀切割,形成峰林洼地和岩溶中山地貌。区内地层出露主要有古生界泥盆系(D)浅灰、深灰色中厚层状灰岩、泥灰岩、泥质白云岩;石炭系(C)深灰、灰黑色块状灰岩、白云质灰岩、泥质灰岩;古生界二叠系(P)灰、深灰色厚层块状、生物碎屑灰岩,结晶灰岩夹虎斑状灰岩及白云岩;中生界三叠系(T)上统为黄褐色粉砂岩、泥质粉砂岩及细砂岩、中统为深灰色灰岩夹泥质灰岩、中上部为黄色白云岩、下统为紫红色含长石粉细砂夹泥灰岩页岩及含铜页岩;新生界古近系(E)+新近系(N)褐黄紫红色砾岩、细砂岩及粉砂质泥岩、底部砾岩;新生界第四系(Q)细砂、砂砾石及砂质黏土。主要构造体系和构造型式有北东向构造、新华夏系构造、网状构造等。北东向构造为区内主导构造,是研究区内最重要的构造成分之一,主要断裂有:金鸡山断裂、长家湾断裂和腊庄断裂等。其次为新华夏系构造,多发育在褶皱边缘、密集成束、规模大、延伸远、呈舒缓波状,主要分布在西部及南盘江两岸。主要断裂有:洒土革断裂、大水塘断裂、罗格断裂等。

图1 研究区概况Fig.1 Overview of the study area
1.2 数据来源
本研究数据主要包括:(1)12.5 m 分辨率数字高程模型(DEM)收集自ASF,用于提取坡度、坡向、起伏度、曲率等评价因子;(2)1∶20 万地质图收集自全国地质资料馆,用于提取岩性、断裂等因子;(3)1∶5 万地理数据库提取水系;(4)历史崩滑数据:主要来自地矿眉山工程勘察院1∶5 万全区调查结果,共154 个崩滑灾害点的数据。
2 研究方法
2.1 信息量模型
信息量模型是对崩滑历史数据进行统计分析,将影响崩滑的各因子的实测值转化为信息量值,来衡量崩滑的易发性[18]。首先计算各评价因子的信息量值,再对各因子信息量值进行总和,作为崩滑易发性的综合指标[19]。单因子信息量计算公式为:
式中:I——评价因子j下的信息量;
Nj——评价因子j内发生的崩滑数;
N——研究区崩滑总数;
Sj——评价因子j下所占栅格数;
S——研究区总栅格数。
将每个评价单元各分类分级进行叠加计算,其地质灾害发生的总信息量计算公式为:
式中:Ij——总信息量,为地质灾害易发性指数;Ij值越大且为正值则表示该单元内有利于崩滑发生。
2.2 层次分析模型
层次分析模型是一种将决策者定性判断和定量计算有效结合起来的分析方法。通过比较相邻影响因子的重要性[19],根据专家法构建判断矩阵[20]:
式中:A——要素判断矩阵;
aij——因子i和因子j重要性比较的结果,有以下性质:
为保证求得的权重的正确性及合理性,还需要进行一致性检验。
式中:CI——一致性指标;
n——判断矩阵的阶数;
λmax——判断矩阵的最大特征值;
CR——随机一致性比;当其<0.1 时一致性检验通过;
RI——随机一致性指标。
2.3 逻辑回归模型
逻辑回归模型是一种研究二分类因变量常用的统计方法[16,21]。通过研究崩滑易发性与评价因子之间的关系,预测崩滑发生的概率。其中自变量为评价因子指标值(x1,x2,···,xn),是否发生地质灾害作为因变量(分别用1 和0 代表崩滑点和非崩滑点)。逻辑回归函数如下:
式中:α——常数项;
x1,x2,···,xn——自变量;
β1,β2,···,βn——回归系数;
Z——崩滑发生的可能性与各评价因子之间的关系;
P——崩滑灾害发生的概率,范围0~1。
2.4 加权信息量模型
根据层次分析法得出各评价因子的权重值,结合信息量法各评价因子分类分级的信息量值,两者相乘得出加权信息量值,其计算公式可表示为:
式中:Ij——加权信息量;
ωi——每个评价因子的权重;
Ii——评价因子i的信息量值。
2.5 信息量-逻辑回归耦合模型
将信息量模型与逻辑回归模型进行耦合,通过逻辑回归确定评价因子的权重,可降低信息量模型评价因子分级的主观性影响。其原理将信息量模型中评价因子分类分级的信息量值作为逻辑回归模型中的自变量,建立回归方程进行逻辑回归运算,得出各评价因子的回归系数,以此为依据建立信息量-逻辑回归耦合模型。
3 评价因子选取分级
3.1 评价因子选取分级
本文在罗平县资料收集和野外地质调查的基础上,选取岩土体(工程岩组)、地形地貌(坡度、坡向、高程、起伏度、曲率、地貌类型)、地质构造(距断裂距离)、气象水文(距河流距离)等评价因子进行分析。根据12.5 m×12.5 m 栅格单元作为易发性评价的制图单元,通过对研究区评价因子与崩滑点数据进行归纳分析,得出各评价因子的分类分级处理(图2)。
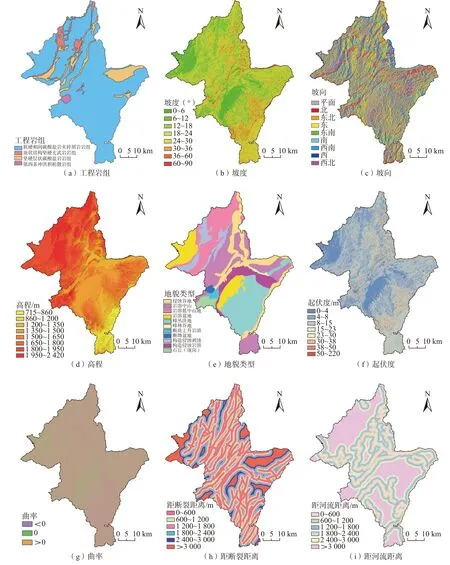
图2 崩滑评价因子分类分级图Fig.2 Classification map of landslide susceptibility evaluation factors
3.2 评价因子共线性诊断
进行逻辑回归时,需确保所选评价因子之间的相互独立,相关性高会出现多重共线性[22-23]。采用容忍度(tolerance,TOL)和方差膨胀因子(variance inflation factor,VIF)对自变量进行多重共线性诊断:
式中:R2——以xi为因变量时对其他自变量回归的复测定系数;
TOL是VIF的倒数,当TOL大于0.1 且VIF小于10 时,则不存在多重共线性。
根据308 个独立属性样本,提取每个样本的各类级信息量值,在SPSS 软件中进行多重共线性诊断。结果显示对所选9 个评价因子其VIF值在1~1.5(表1)。其VIF<5,表明各因子之间相互独立,不存在共线性。
3.3 评价因子相关性分析
崩滑的易发性与评价因子之间存在一定的相关性。为了保证各评价因子间的相互独立性和结果的可靠性,进行因子相关性检验[24]。结果显示各评价因子之间的相关系数均<0.3(表2),评价因子之间的相关性较小,所以9 个评价因子均可以进入模型。
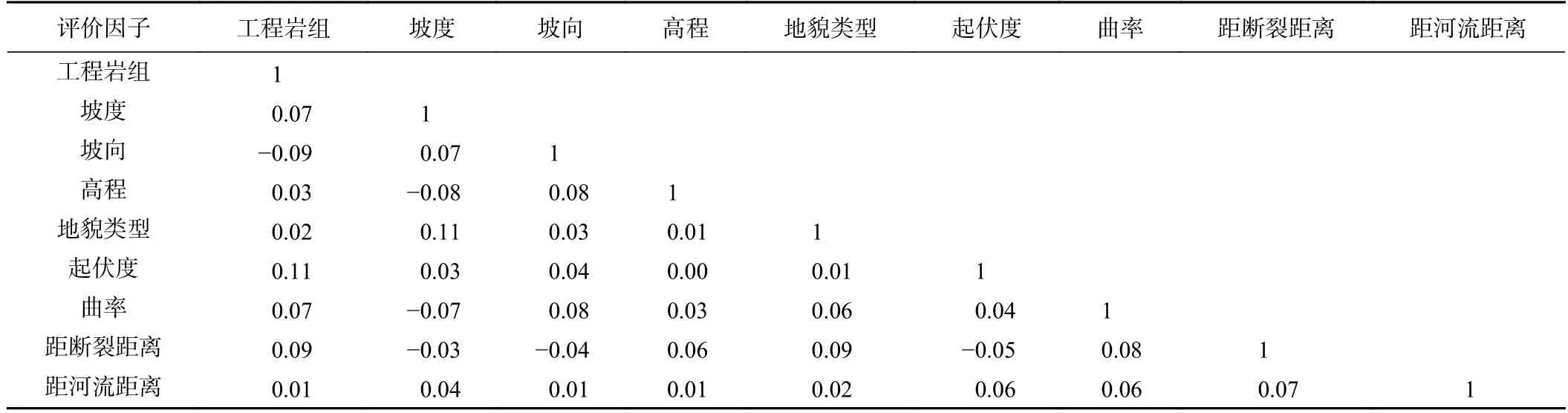
表2 评价因子之间的相关系数矩阵Table 2 Correlation coefficient matrix of evaluation factors
4 易发性评价结果
4.1 信息量模型评价结果
信息量模型中,崩滑的易发性与因子信息量值有关,信息量值越大且为正值则表示单元内崩滑越容易发生[25-28]。根据已有154 个地质灾害进行重分类统计,根据公式(1)计算各评价因子分类分级的信息量值(表3)。
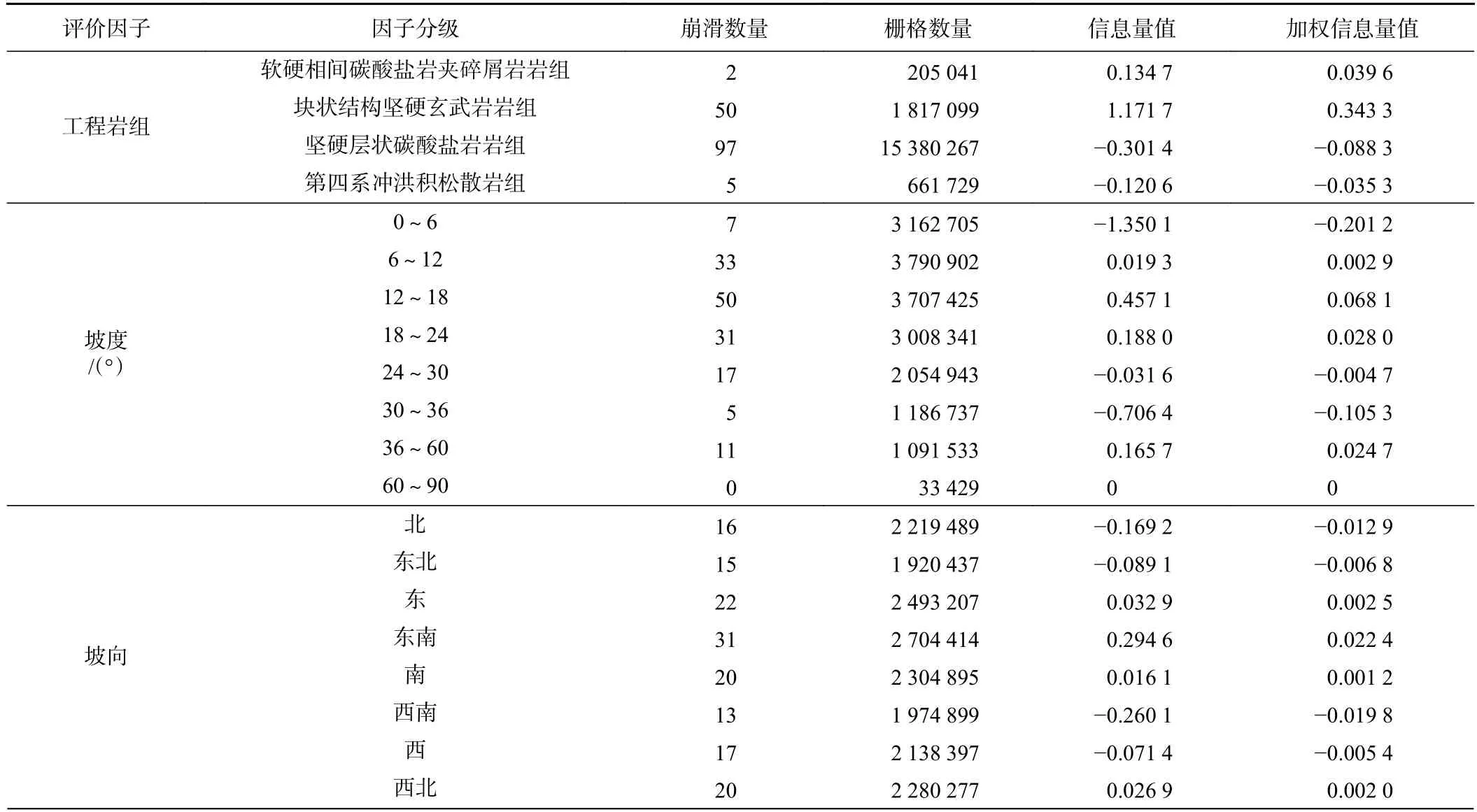
表3 评价因子分类分级信息量值Table 3 Information value of classification levels for evaluation factors
4.2 加权信息量模型评价结果
根据加权信息量法构建模型,对研究区地质灾害及其背景因素和影响因素的相对重要性进行分析,依据所选取的评价因子,按照专家法对选取的评价因子根据式(3)构建判断矩阵计算出各评价因子的权重值,根据式(5)求出每个判断矩阵的一致性指标CI,并通过式(6)进行一致性检验(表4),各评价因子的权重值与各评价因子分类分级的信息量值根据式(9)得出加权信息量值(表3)。
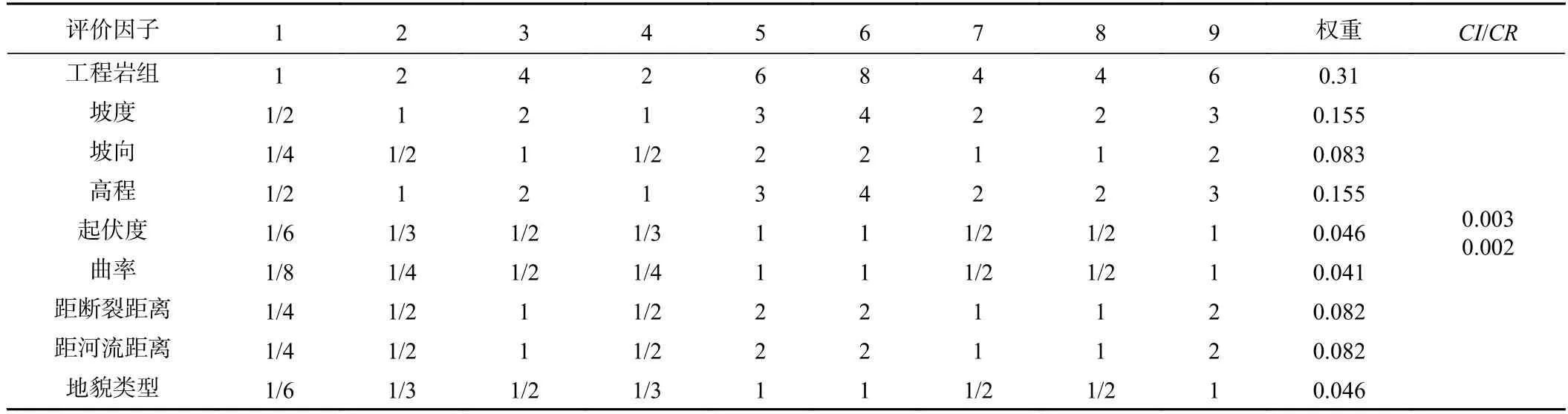
表4 评价因子分类分级判断矩阵及其权重Table 4 Judgment matrix and weight of classification levels for evaluation factors
4.3 信息量-逻辑回归耦合模型评价结果
根据研究区已有的154 个崩滑点,并随机选取等量的非崩滑点,共计有308 个独立属性样本。将全部样本点依次赋予相应评价因子的信息量值,导入SPSS 25 软件进行二项逻辑回归分析(表5),各评价因子的信息量值作为自变量,是否发生地质灾害作为因变量(1 和0代表崩滑点和非崩滑点)。
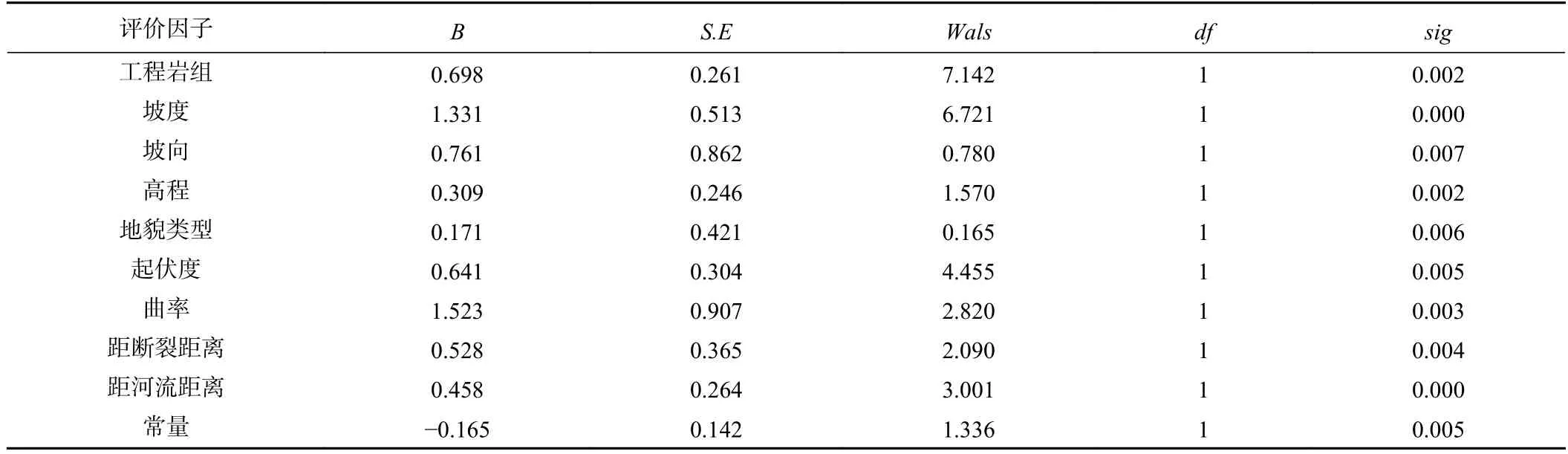
表5 逻辑回归分析结果Table 5 Results of logistic regression analysis
在逻辑回归分析结果中,sig值越小,代表评价因子的显著性越高,表(3)中sig小于0.05,说明9 个因子均有统计意义。基于模型分析结果中的各因子系数值根据公式(7)得逻辑回归公式如下:
式中:x1~x9分别为地层岩组、坡度、坡向、高程、地貌类型、起伏度、曲率、距断裂距离、距河流距离的信息量值;运用ArcGIS 的栅格计算器功能将z值代入式(8)得到崩滑灾害发生的概率p。
信息量模型根据信息量法求出各评价因子分类分级的信息量,然后进行叠加分析,加权信息量模型根据表(4)得出的各评价因子的权重值,结合公式(9)求出各分类分级的加权信息量值(表3)。信息量-逻辑回归耦合模型根据公式(11)所求出的概率值构建模型,将结果进行重分类处理,并利用自然断点法将3 种评价模型结果划分为非、低、中和高4 个等级(图3)。
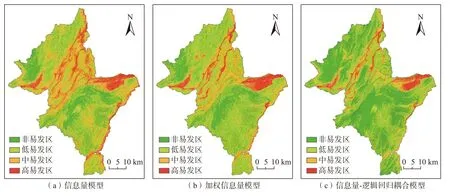
图3 崩滑易发性评价结果Fig.3 Landslide susceptibility evaluation results
4.4 易发性评价结果精度检验
为进一步验证3 种评价模型分区结果的精度,本文采用ROC(receiver operating characteristic)曲线进行精度检验。ROC 曲线又称接收者工作特征曲线,其横轴特异性代表易发性面积百分比累积量,纵轴敏感度代表崩滑地质灾害点数百分比累积量。ROC 曲线与坐标轴围成的面积用AUC值来表示,其线下的面积大小表示预测成功率,值越大准确率越高,模型的预测效果越好[28]。3 种评价模型ROC 曲线中AUC值分别为0.757,0.723,0.852(图4),加权信息量模型的精度最低,其原因是在采用层次分析法得出评价因子权重时,依据专家打分法构建判断矩阵时主观性因素较大,导致权重综合时降低了准确性,信息量-逻辑回归耦合模型的精度最
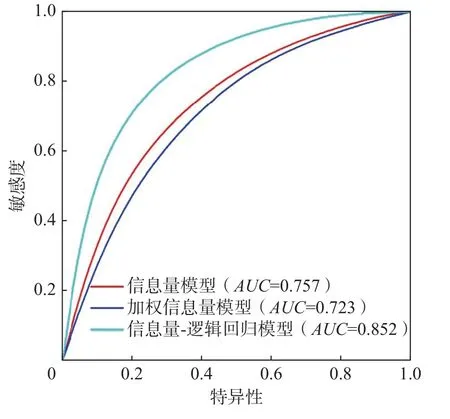
图4 ROC 曲线Fig.4 ROC curve
高,其模型构建主要依据样本点与信息量法中分类分级信息量值进行连接,其精度与所构建的样本点存在紧密的联系,样本点统计规律越明显预测效果越好。
4.5 评价结果分析
根据所得出的评价结果,利用ArcGIS 自然断点法将其划分为非、低、中和高4 个等级,并将各易发性等级之间的面积(分级比)进行统计(表6),根据3 种模型精度评价结果,信息量-逻辑回归耦合模型精度最高,其非-高易发区崩滑面积(分级比)分别为771.1 km2(25.55%)、836.6 km2(27.73%)、864.36 km2(28.64%)和545.94 km2(18.08%)。

表6 崩滑易发性等级分布预测结果Table 6 Prediction results of landslide susceptibility grade distribution
5 结论
(1)以罗平县为研究对象,选取工程岩组、坡度、坡向、高程、地貌类型、起伏度、曲率、距断裂距离、距河流距离等9 个评价因子,进行独立性检验,选取3 种评价方法构建易发性评价模型进行对比分析。
(2)通过对评价因子的分类分级处理,计算信息量值和权重值,值较大的因子类分别是:工程岩组中的层状结构坚硬长石石英砂岩岩组、地貌类型中的岩溶中山地貌和侵蚀谷地地貌、坡度主要分布在6°~30°度之间、高程集中在1 350~1 950 m、起伏度在23 m 以下、距断裂距离和距河流距离1 800 m 之内,信息量值总体为正,对崩滑发育具有促进作用。
(3)根据构建的信息量模型、加权信息量模型和信息量-逻辑回归耦合模型进行对比,通过ROC 曲线对3 种模型的精度检验,其AUC值分别为0.757,0.723,0.852,模型的精度均大于0.7。结合崩滑点分布图,信息量-逻辑回归耦合模型评价与灾点分布情况相符合,可为快速建立评价指标体系和区域崩滑易发性提供参考依据。
