卷积神经网络的top-k相似节点搜索方法
2023-11-11孟祥福李子函纪鸿樟
孟祥福,温 晶,李子函,纪鸿樟
(辽宁工程技术大学 电子与信息工程学院,辽宁 葫芦岛 125105)
1 引 言
在社交网络和生物网络等大型复杂关系网络中,一些下游任务(例如链路预测、节点分类、社区检测等)都是基于相似节点展开的,因此高效准确的为目标节点检索top-k相似节点在复杂网络数据挖掘中起着至关重要作用.针对这一问题,现有研究工作提出了两种指标进行相似性搜索:基于局部信息和基于全局信息[1].局部信息主要指的是目标节点的邻居节点,即如果两个节点拥有的公共邻居数量越多,两个节点间的相似性越强,在结构上越等价.经典的衡量指标包括Jaccard系数[2],余弦相似度[3]等.全局信息主要指的是目标节点的拓扑结构,即这个节点在整个网络中占据的地位,扮演的角色.拓扑结构相似的两个节点在结构上是相似的.然而,局部信息主要以局部的方式为目标节点搜索相似节点,top-k相似节点的选取范围仅限于目标节点指定跳数的邻居,导致复杂网络中两个距离较远的节点无法比较相似性.Gu等人[4]提出的CDALS算法通过节点与其公共邻居连接紧密程度定义了一种相似性度量方法搜索相似节点,Fu等人[5]为搜索相似节点提出改进算法similarity,利用节点局部影响力进行相似性度量.虽然有一些工作利用整个网络来计算相似性,如simrank,sim2vec等,但他们本质上利用的是网络中相似性的传递性,依旧无法获取节点在网络中的全局信息.通过随机游走获取全局信息,能够考虑到整个网路的拓扑结构,为节点提供了一个高质量的结构相似性搜索.个性化PageRank[6]利用图结构递归计算全局节点信息;Zhang等人[7]提出了一种基于随机路径抽样的方法panther来为给定查询节点检索top-k相似节点;Meng等[8]人对panther做出改进,提出了一种单源路径抽样的相似节点搜索算法.然而由于全局随机游走的递归性质,这些算法将受到高时间和空间复杂性的影响,这在大型网络中的效率是非常低下的.
上述两种方式都侧重于节点间的结构相似性,大型复杂网络中节点具有文本信息,例如DBLP[9]数据集中,文章标题下有作者、文章类型、发表时间等信息.基于局部信息检索相似节点即使加入文本信息也只能在给定查询节点附近进行搜索,基于全局信息检索相似节点时加入文本信息使得本就受高时间空间复杂性限制的算法更加繁琐,浪费大量算力的同时效果不甚显著.
为解决上述问题,本文提出了一种基于卷积神经网络的复杂网络top-k相似节点搜索方法(LRE-CNN).该方法首先构造基于度和权重的最近邻网络,以最近邻网络相对加权熵来度量单个节点在复杂网络中的拓扑结构.利用概率论中的相对熵[10]度量任意两个节点间的结构差异,搜索到的节点(称为候选相似节点)与目标节点在结构上具有高相似性.即使两个节点间相隔很远,仍然能够通过节点相似度检索到.最后,利用卷积神经网络(Convolutional Neural Networks,CNN)和深度学习模型DeepL对目标节点和候选相似节点的文本进行特征提取,根据文本特征嵌入向量为目标节点预测出top-k相似节点.
本文的贡献主要有以下4个方面:
1)基于概率论中的相对熵,提出了一种新的节点结构相似度评价标准.
2)将卷积神经网络应用到节点相似度搜索,利用卷积神经网络挖掘文本间内在联系.
3)提出了两阶段相似节点检索方法,通过在结构相似候选节点集合上筛选文本相似节点,节省了大量算力资源.
4)在3个不同规模数据集上进行了大量的实验,并与现有3种主流top-k相似节点检索方法进行对比,结果表明本文方法具有更好的收敛性能,经过多次试验后得到的节点集趋于某个固定值而不再改变,在运行时间和查询准确率上有明显提升,能有效捕获节点的结构相似性和文本相似性.
2 相关工作
2.1 节点相似性度量
对于复杂网络中节点相似性问题的探索,早期的研究者认为:两个节点拥有的公共邻居越多,两个节点越相似.基于这一思想,提出了相似性度量标准,用以搜索相似节点.例如,Jaccard系数和余弦距离,在这些度量中,节点的特征(邻居节点,权重等)可以用来制定相似度评分,然而这种基于节点本地特征的度量标准无法度量不共享本地网络的节点对.Hamedani[11]在Jaccard系数的基础上引入归一化思想[12],以一种有效的方式解决了相似节点两两规范化问题.Haveliwala[6]提出了一种新的节点相关度PPR算法.RWR[13]与PPR的基本思想相似.Jeh[14]等人提出了simrank算法,利用“两个对象如果被相似的对象引用,则这两个对象是相似的”的思想衡量相似节点.P-rank[15],Topsim[16],Lu[17]利用矩阵形式求解所有节点对的simrank得分,Wang[18]采用蒙特卡罗和局部推理加快动态网络中节点对的simrank估计,都是基于迭代或随机游走的思想对simrank做出的改进.Zhang[19]利用相对熵度量节点间的相似性.Jiang[20]等人提出的LRWE-SNM 利用相对熵计算有向加权复杂网络中节点间的相似性.
2.2 相似节点搜索
为了在大规模网络中执行相似节点的top-k检索,Zhang[7]等人利用全局随机游动和VC维数理论,提出了一种基于随机路径抽样的方法panther,大致估计所有节点对的相似性得分从而检索出top-k相似节点.为加快检索速度,Wang[21],Song[22],Jiang[23]在大规模网络中建立索引,Mustafa[24]在网络近邻查询中引入切比雪夫不等式.上述3种方式加快查询速度的同时失去了精度,Wei等人[25]采用过滤精化模型迭代计算节点PPR直到以高置信度得到top-k结果集.然而,这些算法着重于为节点检索结构相似节点,对节点文本信息的描述非常少.
3 问题定义
定义1.无向加权网络:设G=(V,E,W)表示一个网络,其中,V表示节点集V={v1,v2,…vn},n为网络中节点数量,E表示边集E={e12,e13,…eij},i,j<=n,eij代表一条连接节点vi和vj的边,eij=eji.W表示权重集W={w12,w13,…wij},i,j<=n,wij代表边eij上的权重,wij=wji.
定义2.最近邻网络:对于无向加权网络G中的一个节点vi,vi的最近邻网络为Gi=(V′,E′,W′),其中V′={vi,vj},vi∈V,vj表示vi的所有邻居节点;E′={eij},eij∈E,eij表示所有与节点vi相连的边;W′={wij},wij∈W,wij表示eij的权重.

F(·)是节点在结构和文本上的相似度度量函数,δ为阈值0~1.
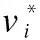
4 top-k相似节点搜索方法
top-k相似节点搜索方法主要分为两步:第1步是为目标节点寻找top-k′结构相似节点;第2步是比较top-k′结构相似节点与目标节点的文本相似性.通过“先结构匹配后文本匹配”的方式逐步缩小查询范围,提高了查询的效率.
4.1 基于最近邻网络的结构相似度评估
在复杂网络中分析节点结构相似性时,考虑所有节点对目标节点结构的影响将会耗费大量算力,并且部分节点对目标节点结构的影响微乎其微.现有研究发现节点在复杂网络中的“地位”是由其邻居节点决定的[26,27].因此,本文在第3节中定义的最近邻网络中计算节点结构相似度,从而为目标节点搜索top-k′结构相似节点.图1展示了两个节点结构相似度的完整计算过程.
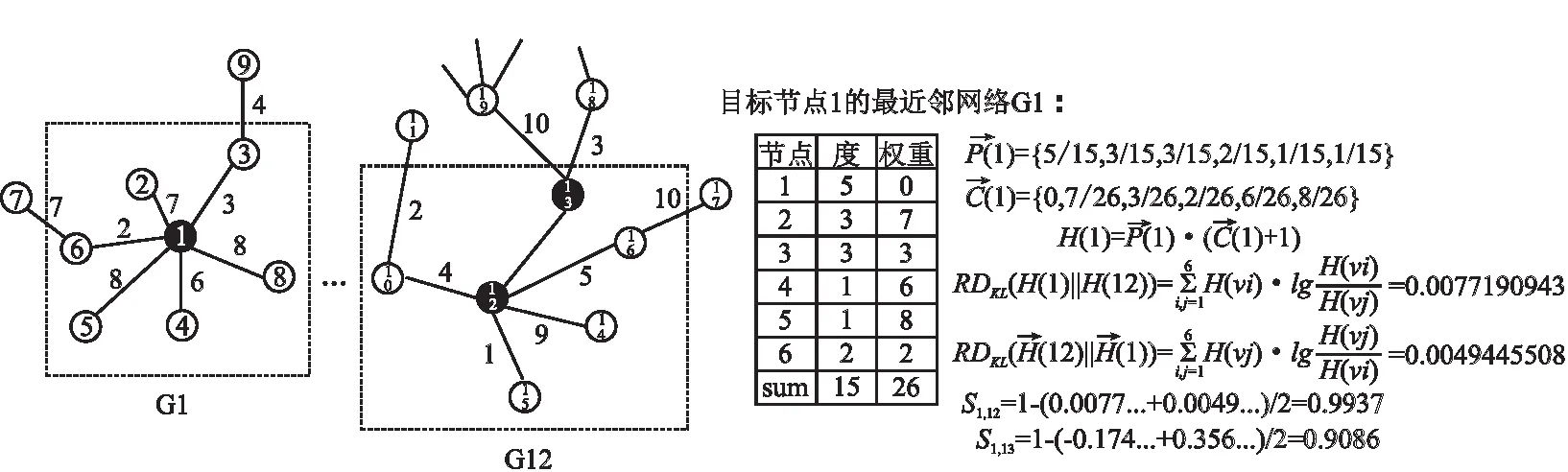
图1 节点结构相似度计算过程Fig.1 Calculation process of node structure similarity
对于目标节点vi及其最近邻网络Gi,Di表示节点vi的度,Disum表示Gi中所有节点度之和,即Disum =ΣDi.vi的任一邻居节点在最近邻网络Gi中的度概率公式为:
d(i)=Di/Dsum
(1)
目标节点vi在Gi中的度概率表示为:
P(i)
={d(1),d(2),d(3)……d(k),0,0,…….d(MAXn+1)}
={D1/Dsum,D2/Dsum,D3/Dsum,……D(MAXn+1)/Dsum}
(2)
MAXn表示复杂网络中节点度的最大值,n表示复杂网络中节点的总数,最终得到的P(i)是一个按照d(i)降序排列的向量.由于模型在计算度概率时将不同邻居节点与目标节点的权重均设置为1,未能考虑邻居节点权重不同带来的影响,因此提出权重概率来衡量在最近邻网络中权重对目标节点的影响.目标节点vi在Gi中的权重概率表示为:
C(i)={Coni1,Coni2,……Conin′}
(3)
Conin′表示vi的任一邻居节点在最近邻网络Gi中的权重概率,定义为:Conin′={wi1/wsum},wi1表示任一邻居节点与目标节点连接形成的边的权重,wsum表示最近邻网络Gi中所有边权重之和.
利用最近邻网络相对加权熵综合评价权重和度对节点结构的影响,计算方法定义如式(4)所示:
(4)
概率论中通常用KL散度(相对熵)来描述两个概率分布之间的差异,概率分布P与Q的概率之差可以用式(5)描述:
(5)
N是概率集合R和T中元素的个数.同样可以将两个节点的最近邻网络相对加权熵代入上式,比较两个节点之间的差异.
(6)
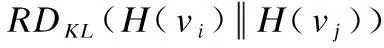
(7)
综上所述,复杂网络中任意两个节点的结构相似性均可由上式计算出,两个节点之间的相似度值越大,就表明两个节点在结构上越具有相似性.根据相似度计算出的与目标节点具有高结构相似性的节点被称为候选相似节点.
4.2 基于卷积神经网络的top-k相似节点预测
复杂网络中,节点除了具有拓扑结构外,还具有标签,类别,含义等文本信息.在为目标节点搜索相似节点时,需要综合考虑节点的结构相似和文本相似.本节通过构建CNN卷积神经网络在候选相似节点的基础上为目标节点筛选top-k相似节点.
4.2.1 卷积神经网络学习节点对文本关联
候选相似节点集vk′中的任意一个节点v与目标节点u构成节点对(u,v).为了比较(u,v)之间的文本关联,首先将节点对的文本特征以稠密低维向量u={u1,u2,…,um},v={v1,v2,…,vm}的形式嵌入到同一向量空间中,不同数据集文本特征也是不同的,因此不同类型的文本特征采用不同的嵌入方式.对于嵌入向量u和v,通过函数fθ(u,v)生成一个节点对文本相互作用矩阵Xc来表示u,v之间的文本关联.其中,每个元素fij表示向量u的元素ui和向量v的元素vj之间的关联.然后,将Xc输入进卷积层进行特征提取,计算方法如式(8)所示:
Mc=a(W×Xc+b)
(8)
其中,W为权重矩阵,b为W的偏置,α为非线性激活函数(如ReLU).
将卷积后得到的特征进行池化,此时得到的结果MP为节点对文本相互作用的局部向量,为了增加特征提取的准确性补充卷积丢失的信息,将Xc展平为一个向量,与局部向量连接,最终得到节点对全局相互作用向量E.向量E代表卷积神经网络提取到的节点对(u,v)的文本信息.
4.2.2 DeepL预测相似节点
本小节构建一个深度学习模型DeepL,捕捉了从评分行为推断出的隐含节点对文本间联系从而预测相似节点对(网络模型如图2下部所示).评分行为被定义为由结构相似度形成的评分函数.为简化计算,DeepL将节点u和v的id的one-hot向量映射到具有相同维度的联合潜在因子空间中,生成低维稠密向量p,q

图2 相似节点预测Fig.2 Similarity node prediction
(9)
将p,q进行元素级乘积,得到节点对的线性交互向量r.
r=p⊗q=(p1q1,p2q2…pkqk)
(10)
然后将向量r输入到一个多层全连接神经网络中,深入学习高层抽象节点对的交互.在训练DeepL模型后,Wu和Wv为所有的节点呈现潜在因素.每层的输出,计算如式(11)所示:
a1=ReLu(WT·r+b1)
a2=ReLu(WT·a1+b2)
……
aL=ReLu(WT·aL-1+bL)
(11)
DeepL通过sigmoid函数将模型输入压缩到[0,1]进一步预测节点对相似的概率,0表示节点对不相似,1表示节点对相似.通过将多尺度评分转化为二进制,解释了节点对相似预测.
Pθ(y=1|(u,v))
(12)
θ是神经网络权重,使用y′作为预测输出.
(13)
5 实验与评估
5.1 实验设置
5.1.1 数据集
Dolphin[28]:Lusseau等在新西兰对62只宽吻海豚的生活习性进行了长时间的观察,他们研究发现这些海豚的交往呈现出特定的模式,并构造了包含有62个结点,159条边的社会网络.如果某两只海豚经常一起频繁活动,那么网络中相应的两个结点之间就会有一条边存在.
Grqc[29]:Arxiv gr-qc(广义相对论和量子宇宙学)协作网络来自电子印刷的 arxiv,涵盖作者之间提交到广义相对论和量子宇宙学类的科学合作.由5242个节点和28980条边组成.如果一个作者i和作者 j 合著了一篇论文,这个图包含一个从 i 到 j 的无向边,如果这篇论文是 k 作者合著的,这个图就会在 k 上生成一个完全连通的(子)图.
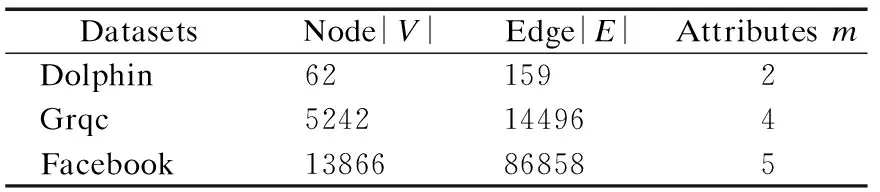
表1 数据集Table 1 Dataset
Facebook[30]:收集2017年11月 facebook 页面的数据.从这些数据中选出了代表运动员的页面,组成13866个节点和86858条边的运动员社交网络.其中,一个节点表示一个运动员页面,边表示这些运动员具有相同的喜好.除此之外,还包括运动员的姓名,性别,地区,运动类型等文本信息.
5.1.2 参数与环境
在所有的实验中,设定学习率为0.005,迭代轮次为30次.所有的实验都在windows10操作系统,Intel(R)Core(TM)i5-6300HQ CPU @ 2.30GHZ cpu和12GB内存的服务器上进行,算法采用python实现.对比方法中基于路径的panther和random的路径长度设置为5,因为文献[7]中证实t=5时,算法精度和效率都趋于稳定.
5.1.3 评价指标
参考Mei[31]提出的网络科学密度利用top-k结果的子图密度来度量结果集的结构相似性.图的密度是途中存在边数除以图中可能的最大边数,密度越大,结构相似性越好.子图密度定义如下:
(14)
给定节点vi的top-k相似结果集,利用结果集中的顶点构造子图Gk,Gk中边的总数除以结果集的个数即为vi的子图密度.整张图的子图密度衡量算法在结构相似性上的准确性.
两个节点拥有的相同属性越多,两个节点在文本上就越具有相似性.因此,利用公共属性分数[7]来衡量结果集与给定查询节点的文本相似程度.公共属性分数定义如下:
(15)
其中,u为目标节点,v为u的top-k相似节点集S中的元素,A(u),A(v)分别代表u,v的属性.CA评估结果集中所有成对节点的属性相似性.
5.1.4 比较方法
Random:从图的任意一个顶点vi出发,随机走至其邻居节点中的任意一个节点,将邻居节点视为目标节点继续选中邻居节点的下一个节点,直到获得一条长度为5的路径,以vi为初始点的n条路径中,出现次数最多的节点即为vi的相似节点.
Simrank[14]:基本思想是如果图中两个节点相似,那么它们相关的节点也相似.为节省时间空间消耗,使用矩阵形式代替迭代公式,定义相似度矩阵S和转移概率矩阵Q,如果从节点vi可以转移到节点vj,则这两个节点相似.通过迭代更新相似度矩阵,寻找目标节点的top-k相似节点.
Panther[7]:随机选择网络中的一个节点vi作为起点,根据其转移概率从vi到其邻居进行l步的随机行走得到r条随机路径,之后通过迭代所有采样路径来累计每个节点对的相似性分数.最后,根据基于堆结构的相似性得分对节点进行排序,以返回排名top-k的相似节点的列表.
5.2 实验评估
5.2.1 准确性
图3(a~c)显示了不同网络上top-k结果集的子图密度.从图中可以看出,LRE-CNN在Dolphin和Grqc数据集上表现不佳.基于路径对Panther和Random进行采样,得到的结果集具有很高的可见性.Simrank利用递归的思想来获得路径上具有连接性的结果集.LRE-CNN的提出打破了随机游动和递归的局部化.因此,LRE-CNN在子图密度下的低性能从侧面证明了算法的有效性.
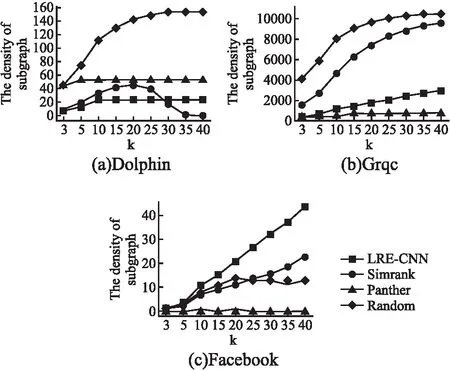
图3 子图密度比较Fig.3 Comparison on subgraph density
图4(a~c)显示了不同网络中top-k结果集的公共属性得分.可以看到LRE-CNN明显优于Panther和Simrank.LRE-CNN得到的top-k结果集与目标节点具有较高的文本相似度.
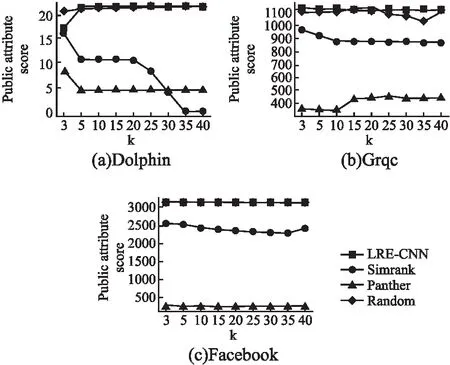
图4 公共属性得分比较Fig.4 Comparison on CA
5.2.2 可扩展性
图5(a~c)显示了在不同k条件下,这4种方法在Dolphin、Grqc和Facebook网络中的运行时间.从图中可以看出,数据集大小和k值的变化都会导致simrank和panther的检索时间出现波动,并且随着k值的增加,运行时间显著增加.当LRE-CNN和random对同一数据集进行不同的top-k检索时,时间基本没有变化.LRE-CNN和random比其他两种方法有更好的收敛性.
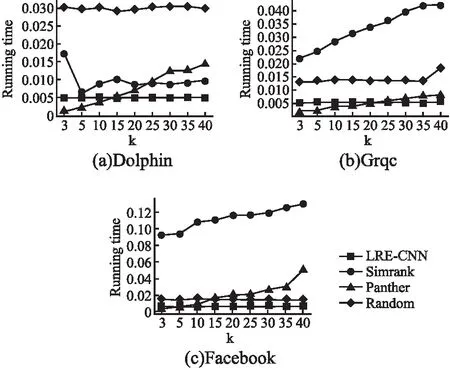
图5 可扩展性比较Fig.5 Comparison on scalability
5.2.3 超参数
本实验旨在验证LRE-CNN算法的超参数.具体实验如下:将Grqc数据集上的epoch固定为30,改变学习速率l(分别设置为0.001、0.003、0.005和0.01),测试算法在不同k值下的准确性.将学习速率固定在0.005,改变epoch轮数,测试不同k值下算法的准确性.
从图6可看出,当学习速率l=0.001时,算法的准确率最高.但是,epoch的变化对算法的精度影响很小.证明了算法的稳定性和收敛性.
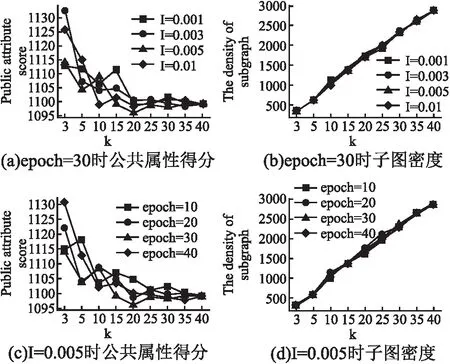
图6 超参数实验Fig.6 Hyperparametric experiment
根据不同方法的子图密度和公共属性得分以及不同的参数敏感性,可以得出LRE-CNN可以有效地估计结构和文本中节点的相似度,具有较高的精度和收敛性,大大提高了查询效率.
6 结 论
本文针对复杂环境下,搜索与给定节点具有结构和文本相似性的top-k节点问题,提出了一种基于卷积神经网络的相似节点搜索算法.本文与现有先进方法的不同之处在于3个方面:1)基于概率论中的相对熵,提出了一种新的结构相似度评价标准,节点相似度;2)将卷积神经网络应用到节点相似度检索,利用卷积神经网络挖掘文本间内在联系;3)提出了两阶段相似节点检索方法,通过在结构相似候选节点集合上筛选文本相似节点,节省了大量算力资源.未来工作将研究将本文方法推广到规模更大,节点具有更多文本属性,以及节点间具有更多复杂关系的网络中.
