一种语义增强与双级别注意力的关系抽取方法
2023-11-10阳磊,宋威,2
阳 磊,宋 威,2
1(江南大学 人工智能与计算机学院,江苏 无锡 214122)
2(江南大学 江苏省模式识别与计算智能工程实验室,江苏 无锡 214122)
1 引 言
关系抽取是信息抽取中的核心分支,旨在从非结构的文本中提取给定实体对之间的语义关系[1].通过对句子以及关系进行建模,关系抽取方法获得实体对间的语义关系,并形成结构化的三元组数据<实体1,关系,实体2>,这为文本摘要[2]、智能检索[3]、自动问答[4]、机器阅读理解[5]等下游任务提供了基础知识,有助于知识图谱的自动构建.
由于深度神经网络[6]具有良好的性能及泛化能力,众多学者将深度学习引入到关系抽取模型中.要训练一个基于深度学习的关系抽取模型,数据集中应当包含实体对以及实体间关系的标注,然而,关系的标注通常较为困难,人工构造关系抽取数据集通常需要昂贵的人力、时间成本.为了解决数据匮乏问题,MintZ等人[7]提出了远程监督关系抽取方法,通过对齐无标注语料库与现有的知识库来构建大规模数据集.远程监督基于以下强假设:如果知识库中两个实体间存在某种关系,那么所有包含这两个实体的句子都潜在地蕴含了这种关系.显然,这样构造的数据集不可避免地充斥着噪声句.
为了解决远程监督方法带来的噪声影响,多实例学习[8]被引入到关系抽取方法中.Zeng等人[9]提出分段卷积神经网络(Piecewise Convolutional Neural Network,PCNN),将包含相同实体对的句子聚成一个包,选择包内最相关的句子以用于模型训练.Lin等人[10]利用注意力机制为包内句子分配权重,在利用更多句子的同时也降低噪声句的影响.Ji等人[11]将注意力机制与外部知识相结合来进行关系抽取,改进了Lin的模型.这些神经网络方法与传统方法相比已经取得了显著的改进.然而,这些方法在对句子进行编码时平等对待每一个词,而实体对间关系通常能够通过一些关键词来明确表达,如在“Steve Jobs[e1] was the co-founder of Apple[e2]”一句中,“co-founder”一词对于判断实体对Steve Jobs与Apple之间的关系“founder”有重要帮助.其次,这些方法没有考虑实体的上下文语义环境信息,同一实体对在不同的语义环境下可能表达不同的含义.另一方面,大多数研究仅在由句子组成的包这一级别进行噪声句的筛选及降噪,在面临包中仅有一个句子的情况时,无法有效地鉴别噪音实例,进而影响关系抽取方法的性能.针对这些问题,本文提出一种语义增强与双级别注意力(Semantic Enhancement and Dual-Level Attention,SEDLA)的关系抽取方法,该方法首先利用门控机制对句子中的词进行筛选,过滤冗余词,得到句子中的关键词,进一步地,利用关键词作为上下文语义环境信息,对实体进行编码,得到语义增强的实体特征表示,与经过PCNN编码得到的句子特征表示相整合,得到鲁棒的句子特征.最后,设计一个双级别注意力层,从由句子组成的包以及由包构成的组两个级别降低噪声句对关系抽取方法性能的影响.
本文所提的SEDLA的关系抽取方法主要包含关键词门控层(Keyword Gated Layer,KGL)、语义增强层(Semantic Enhancement Layer,SEL)和双级别注意力层(Dual-Level Attention Layer ,DLAL)3个部分:
1)KGL:利用门控机制对句子中的词进行筛选,并控制信息流,过滤句子中与关系无关的冗余词;
2)SEL:基于上述步骤得到的关键词,作为上下文语义环境信息,在多头注意力机制[12]基础上对实体进行编码,得到语义增强实体特征,与经过PCNN编码得到的句子特征整合,得到鲁棒的句子特征表示.
3)DLAL:运用注意力机制挑选实例,从包和组两个级别对数据进行降噪.
进一步地,阐述本文的主要贡献:
1)语义特征增强:考虑到句中的关键词以及实体的上下文语义环境信息,为句子构建更为鲁棒的特征表示.
2)双级别注意力降噪:使用双级别注意力机制对数据进行降噪,有效地解决包内仅有一个句子的情况.
3)在NYT公共数据集上验证所提出的关系抽取方法的有效性,优于目前主流的关系抽取方法.
2 相关工作
关系抽取旨在快速高效地从文本中提取出有效信息,是信息抽取的关键任务.早期的关系抽取方法通常以传统机器学习模型为基础,通过人工精心设计特征来进行关系抽取[7,13,14].虽然这些方法在一定程度上能完成关系抽取任务,但是构建特征需要特定领域专家费时费力,另一方面,一些特征的提取依赖于自然语言处理工具,而这些工具不可避免地存在误差,容易造成误差传播现象,最终影响关系抽取模型的性能.
近年来,随着深度学习在自然语言处理领域的快速发展[15,16],众多学者将深度学习引入到关系抽取任务中.由于深度学习模型在通常需要大量训练数据以达到较好的泛化能力,而构造人工标注数据集通常需要大量的时间人力成本.为了解决数据匮乏问题,自动获取高质量的标注数据,MintZ等人[7]提出了远程监督关系抽取,通过对齐无标注语料与现有的知识库的方式构建大规模的关系抽取数据集.然而,通过此方式得到的训练语料中充斥了噪声句.因此,数据集的降噪成为近年来远程监督关系抽取的研究重点之一.2015年,Zeng等人[9]提出分段卷积神经网络,一方面采用神经网络作为句子的特征提取器,自动学习文本特征,解决了由自然语言处理工具所带来的误差传播问题;另一方面,通过削弱了远程监督的强假设,在由句子组成的包中,仅选最相关的实例进行训练,获得了当时最好的关系抽取模型效果.Lin等人[10]在Zeng的基础上引入了注意力机制,充分利用包内所有句子的信息.此外,许多基于注意力机制的方法也相继被提出.Zhou等人[17]使用粗粒度句子级别注意力选择若干相关实例,再使用细粒度句子级别注意力来聚合这些句子的特征表示.Huang等人[18]结合卷积神经网络和自注意力机制对句子进行建模,并在模型中引入课程学习[19],以缓解嘈杂数据的影响.Zhou等人[20]采用双向LSTM提取句子特征,并使用注意力机制降低噪声句子权重.
另一方面,越来越多的研究者开始关注句子中的关键词信息以及实体信息.Qu等人[21]使用词级别的注意力机制,增加关键词的权重,并将词聚合成句子表示.王红等[22]结合双向LSTM与注意力机制,学习词与词之间的相互关系信息.Ji等人[11]利用现有知识库提供监督数据,从外部知识库中提取实体描述,补充到任务的背景知识中,用来指导模型训练.Vashishth等人[23]使用实体类型和关系别名信息在预测关系时施加软约束以改进关系抽取模型.Kuang等人[24]利用实体对之间存在的隐式相互关系来改进模型,将关系知识从丰富实体对转移到非频繁实体对中.Zhao等人[25]将框架语义知识引入到远程监督关系抽取任务中,更全面地表示句子的语义信息.
3 模型方法
本节具体介绍SEDLA的关系抽取方法.如图1所示,SEDLA框架主要包含KGL、SEL和DLAL这3个模块.在KGL中,利用门控机制对输入句子进行关键词的筛选,过滤句子中与关系无关的冗余词;在SEL中,利用KGL模块得到的关键词作为实体的上下文语义环境信息,在多头注意力机制基础上对实体进行编码,得到语义增强实体特征,与经过PCNN编码得到的句子特征拼接得到鲁棒的句子特征表示;在DLAL中,运用注意力机制,从包和组两个级别对数据进行降噪.最终利用Softmax函数进行关系预测,并根据预测结果与实际结果调整网络参数.

图1 SEDLA框架Fig.1 Framework of SEDLA
3.1 输入表示
3.1.1 词嵌入表示
对于输入句子X={x1,x2,x3,…,xH}中的每一个词xi,采用word2vec[26]工具将其映射到低维、稠密的向量空间中,进而得到句子的词嵌入表示X∈H×d,其中dw是词向量维度.
3.1.2 位置嵌入表示
位置嵌入由Zeng等人[9]提出,其反映的是句中每个词距离实体间的相对位置.将位置距离向量化,构造位置词典,其维度为dp.
最后,将词嵌入与位置嵌入拼接得到输入句子的输入表示X∈H×d,其中,d=dw+2×dp.句中两个实体分别记为e1,e2∈d.
3.2 关键词门控层(KGL)
在KGL中,利用门控机制对句子中各词进行筛选,过滤句子中与关系无关的冗余词.具体地,首先将句子中每个词输入到门控函数,如公式(1)所示:
gi=σ(Wg·[xi;e1;e2]+bg)
(1)
其中Wg∈d×3d和bg∈d分别表示权重矩阵和偏置参数,[;]代表拼接操作,σ为sigmoid激活函数,门控向量g中反映了句中每个单词的重要程度.进一步地,将门控向量与句子嵌入表示X相乘,强调句子中的关键词信息,其计算过程如公式(2)所示:
(2)
其中,⊙代表按位相乘操作.通过门控机制,能有效地选择出句子的关键词并给与加强.例如,对于句子“Steve Jobs[e1] was the co-founder of Apple[e2]”,通过关键词门控层,过滤句子中与关系无关的字词,如“was”、“the”和“of”,加强句子中能反应句子关键信息的词,如“co-founder”.
3.3 语义增强层(SEL)
进一步地,在SEL中,利用KGL得到的关键词信息作为上下文语义环境对实体进行编码,得到语义增强实体特征.由于句子中的关键词可能是在对不同的实体进行语义增强,在实体增强过程,需要独立地考虑两个实体的语义环境.如在句子“Donald Trump[e1] was elected the 45th President of the United States[e2],after defeating Democratic candidate Hillary Clinton”中,“elected”、“president”、“candidate”均可被视为句中的关键词,然而,在考虑实体的上下文语义环境时,关键词“president”对实体2(United States)的影响更大,而“candidate”对实体1(Donald Trump)的影响更大.具体地,将实体对e1,e2∈d拼接后作为查询向量qe∈2×d,引入注意力机制,将查询向量qe中的两个实体分别与经过初步筛选后的句子表示Xg∈H×d中的每一个词进行相关性计算,并根据相关性对实体进行编码.具体计算如公式(3)~公式(4)所示:
(3)
(4)

为了捕捉更为细化的实体语义信息,采用多头注意力机制[12]来细化特征空间.图2展示了多头注意力的结构.

图2 多头注意力结构Fig.2 Structure of multi-head attention
不同于传统注意力机制,多头注意力将特征空间划分为h个子空间,并行地计算不同子空间下的语义特征.多头注意力具体计算如公式(5)所示:
(5)
其中,h为注意力头数,A1~Ah为不同语义空间下的待训练权重矩阵.将语义增强实体特征与经过PCNN编码得到的句子特征拼接整合,得到鲁棒的句子特征表示.具体来说,遵循Lin等人[10]的思想,在对经初步关键词筛选后的句子特征Xg∈H×d进行零填充后,使用卷积神经网络进行特征提取.定义卷积核大小为W∈c×d,获得经单个卷积核后的特征输出Q∈H,由于实体对天然地将句子划分为3段,通过分段最大池化层,在每段中保留最具有代表性的特征p=max{Q1,Q2,Q3}∈3×1.使用k个卷积核得到k个特征向量,分别通过分段最大池化层后拼接,得到句子的初步特征表示Sg∈3k,进一步地,与语义增强后的实体对表示拼接整合,得到鲁棒的句子特征表示S∈3k+2d用于关系抽取.
3.4 双级别注意力层(DLAL)
在获得句子的特征后,采用Lin等人[10]提出的注意力对数据进行降噪.假定一个包中有m个句子,其特征表示为{S1,S2,…,Sm}∈m×(3k+2d),包的最终特征表示B是通过包级别注意力机制加权包内各个句子得到,其计算方式如公式(6)所示:
(6)
其中,αi为句子Si的权重,其具体计算如公式(7)~公式(8)所示:
γi=SiAc
(7)
(8)
其中,γi表示句子Si与关系c的匹配得分,A为待训练的权重对角矩阵,r为数据集的关系数量.
包级别注意力能够在一定程度上解决噪声句对于关系抽取方法性能的影响,然而,当包内仅有一个句子的情况,仅使用包级别注意力机制无法达到降噪目的.因此,在包级别注意力的基础上引入组级别注意力机制,旨在缓解上述情况带来的影响.具体来说,将同一关系标签的包以一定规模聚成组,假定一个组由n个包构成,其特征表示为{B1,B2,…,Bn}∈n×(3k+2d),组的最终特征表示G是通过组级别注意力机制对组内各个包加权而得到,其计算方式如公式(9)所示:
(9)
其中,ηj为包Bj的权重.直观上,蕴含同一关系的包的特征表示之间应当相互接近,因此,可以通过计算每个包与其他包的相似度之和来为每个包赋予权重.具体计算方式如公式(10)~公式(11)所示:
(10)
(11)
其中,βj是第j个包与组内其他包相似度之和,sim(,)函数为求两个包之间的相似度函数,通过余弦相似度函数实现,计算方式如公式(12)所示:
(12)
值得注意的是,关系抽取模型最终评价指标是在包层面上,因此仅在训练阶段使用组级别注意力机制.
3.5 关系分类器及网络优化
最后,利用全连接层将组级别特征映射到r个关系的分类标签空间中,获得关系预测信息o∈r,计算方式如公式(13)所示:
o=WoG+bo
(13)
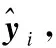
(14)
本文采用交叉熵作为损失函数,利用L2正则化对参数进行惩罚,模型采用了dropout[27]策略防止模型过拟合.损失函数的具体定义如公式(15)所示:
(15)
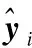
在最终的预测阶段,使用softmax函数作为分类器对包进行关系分类,其计算公式如公式(16)所示:
(16)
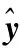
4 实验与评估
4.1 数据集及评价指标介绍
本文实验采用通用远程监督关系抽取数据集NYT来验证所提方法的有效性.此数据集由Riedel等人[8]开发,通过对齐大规模知识库Freebase与纽约时报(New York times,NYT)语料库构建而成,数据集中有53种关系,包含52种具有实际意义的关系和一个特殊关系NA,其表示实体对之间没有关系.表1展示了NYT数据集的统计信息.

表1 NYT数据集的统计信息Table 1 Statistics for NYT dataset
为公平比较,在测试过程中,均采用held-out方法对模型性能进行评估.实验采用PR曲线和P@N作为评价指标.PR曲线是以precision(精准率)和recall(召回率)分别作为纵坐标与横坐标绘制的曲线,是机器学习中常用指标之一,P@N是检验远程监督关系抽取模型性能的一个常用评价指标,通过计算置信度前N个包分类结果的精准率而得到.为了更精细地对实验结果进行评价,本文采用不同的N值(100、200、300)计算P@N值,并计算三者的平均值mean P@N.
4.2 参数设置
为公平地与进行对比试验,本文使用Lin等人[10]相同的参数进行实验,词嵌入维度为50维,位置嵌入维度为5维,卷积核数量设置为230,初始学习率设置为0.1,每100000步学习率降低到之前的1/10,详细的超参数设置如表2所示.
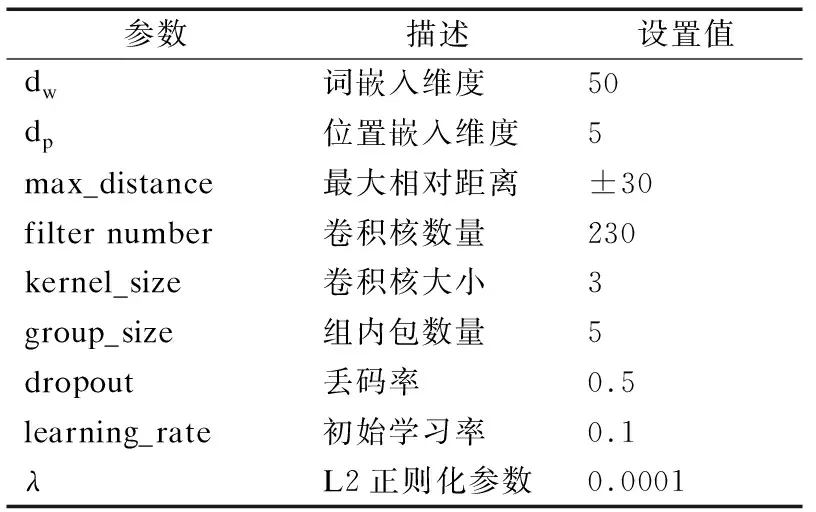
表2 超参数设置Table 2 Hyper-parameter settings
4.3 对比方法
本文采用以下8种方法和所提的SEDLA进行比较,前3种为基于传统机器学习的方法,后5种为基于神经网络的方法.
MintZ[7]:采用传统人工设计方式的抽取词汇特征和句法特征,利用多分类逻辑回归模型进行关系抽取.
MultiR[13]:基于多实例学习的概率图模型进行远程监督关系抽取.
MIMLRE[14]:采用多实例多标签的方法进行关系抽取,建模方式采用贝叶斯网络.
PCNN+ONE[9]:首次将神经网络引入到远程监督关系抽取任务中来,同时设计了分段池化层.在每个包内仅选择最相关的实例进行训练,是利用神经网络实现关系抽取的经典模型.
PCNN+ATT[10]:在上述方法基础上引入注意力机制,为句子分配不同的权重,利用包内所有句子来表示包的特征,通过强调置信度高的句子的重要性来降低远程监督数据集噪声句的影响.
PCNN+ATT+SL[28]:引入软标签来解决数据集中的错误标签问题.
RESIDE[23]:从外部知识库中提取实体类型和实体别名,补充到任务中用来指导模型训练,采用图卷积神经网络编码句子特征.
CFSRE[25]:将框架语义知识引入到关系抽取任务中,更全面地表示句子的语义信息.
4.4 对比实验结果与分析
在实验部分,本文首先进行SEDLA方法的对比实验.图3绘制了8种对比方法以及SEDLA在NYT数据集上的PR曲线.
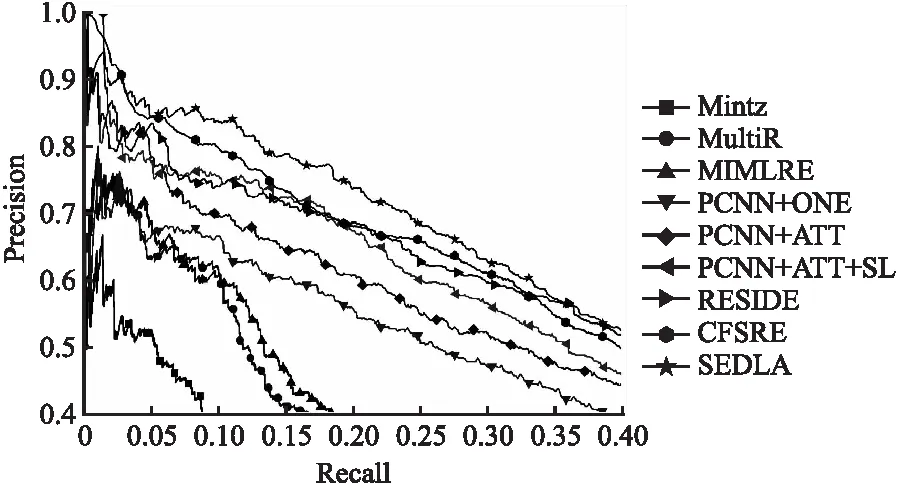
图3 SEDLA与对比方法的PR曲线Fig.3 PR curves of SEDLA and comparison methods
从图3可以观察到:
1)基于神经网络的方法较传统机器学习方法更具优势,这是由于传统机器学习方法采用人工设计的特征,其提取到的特征无法很好地适应关系抽取任务.同时也说明了基于深度学习的方法可以从大规模数据中学习到更好的特征表示;
2)PCNN+ATT较PCNN+ONE有较大的提升,这是由于PCNN+ATT能充分利用包内所有句子的信息,通过注意力机制能有效降低了置信度较低的句子所带来的影响.
3)使用软标签(PCNN+ATT+SL)代替硬标签能有效地提升模型性能,软标签能够在一定程度上缓解通过远程监督方式构造的数据集时带来的错误标签问题.此外,使用外部知识能够获得更为丰富的特征,提升关系抽取模型性能.
4)与所有的对比方法相比,SEDLA在整个召回率范围内几乎都取得了最高的精准率.特别地,当召回率处于[0.1,0.25]区间时,SEDLA较第二好的方法高出约5%.这反映出本文提出的方法能提取到更有用的特征信息,从而更有效地解决关系抽取任务.
遵循前人工作,本文使用P@N来比较上述方法的性能.表3为8种对比方法以及SEDLA的P@N值,其中N的取值分别为100、200、300,并计算三者的平均值.

表3 SEDLA与对比方法的P@N值Table 3 P@N(s)of SEDLA and comparison methods
由表3可以看出,除了在P@100时CFSRE取得最好的结果外,SEDLA在P@200、P@300以及mean P@N评价指标中均拥有最好的表现.CFSRE将语义框架信息这一外部知识引入到任务中,改善了模型的性能,但在P@200以及P@300时,CFSRE精准率下降较快.而SEDLA方法同时兼顾了精准率与召回率.
4.5 消融实验结果与分析
为了探讨所提出的SEDLA方法中各个模块的作用,本小节设计消融实验.其中SEDLA-KGL、SEDLA-SEL、SEDLA-DLAL分别表示为SEDLA缺省KGL、SEL和DLAL模块.图4绘制了SEDLA与3种消融方法的PR曲线.

图4 SEDLA与消融方法的PR曲线Fig.4 PR curves of SEDLA and ablation methods
从图4可以观察到,SEDLA在PR曲线上表现最优,在缺省任意模块后,SEDLA的性能均有所下降,其中缺省SEL模块对模型影响最大,这是由于SEL模块通过利用关键词对实体建模,使得实体能够学习到丰富的上文语义环境信息,进而为句子构建更为鲁棒的特征表示.
此外,本小节使用P@N来比较SEDLA与3种消融方法的性能.如表4所示.
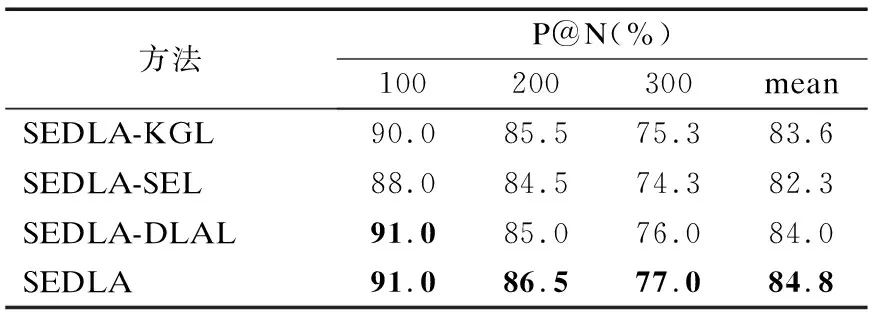
表4 SEDLA与消融方法的P@N值Table 4 P@N(s)of SEDLA and ablation methods
由表4可以看出,缺省KGL模块与缺省DLAL模块在P@N(N=100/200/300)评价指标上各有优劣,总体上缺省DLAL模块的性能略优于缺省KGL模块.缺省SEL模块对模型影响最大,这与通过PR曲线得到的结论基本一致.完整SEDLA在各个P@N值上均拥有最好的表现,这表明SEDLA中各个模块都是不可或缺的,对模型性能的提升均有帮助.
4.6 在全监督数据集上的表现与分析
为了进一步验证所提出SEDLA方法的泛化能力,验证其有效性,在经典的全监督数据集SemEval-2010 Task 8上进行了实验.该数据集包含8000条用于训练的句子以及2717条用于测试的句子.由于该数据集的标签均为手工标注且其训练的基本单位为句子而非远程监督关系抽取数据集的包结构,故本文所提出的DLAL模块在该数据集上失效,仅利用KGL与SEL模块来验证本文所提出的SEDLA方法的有效性.
本文采用官方评价指标F1值来评价模型的性能,为公平比较,在超参数的选择上,本文使用300维GloVe词向量[29]作为神经网络的输入.表5展示了EDLA与几种经典对比方法在SemEval-2010 Task 8数据集上的F1值.
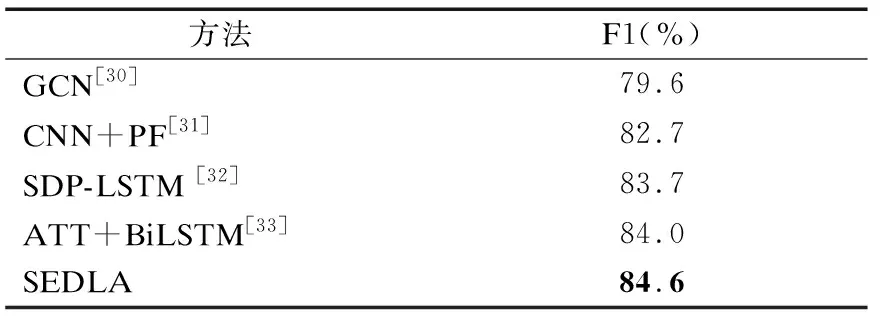
表5 SEDLA与对比方法的F1值Table 5 F1 value of SEDLA and comparison methods
从表5可以观察到,本文所提出的方法的F1值高于表中其他模型,这也说明了本文所提出方法的泛化能力,在全监督关系抽取数据集上仍有着较好的表现.
5 总结与展望
针对现有方法缺乏考虑实体上下文信息以及传统多实例学习无法处理句子包内只有一个句子的情况,本文提出了一种语义增强和双级别注意力的关系抽取方法.所提出框架包含3个模块,分别用于筛选关键词过滤冗余词;在多头注意力机制基础上对实体进行编码,得到语义增强实体特征;运用注意力机制,从包和组两个级别对数据进行降噪.通过在NYT数据集上的对比实验和消融实验,验证了模型的有效性和各组件的必要性.在将来的工作中,将继续优化特征提取器,同时,考虑将利用外部知识来指导模型训练,进一步提高模型性能.
