数据集与网络结构对基于FPGA的CNN加速器的抗软错误性能的影响
2023-11-10折夏煜刘玉宏王杨圣王海滨韩光洁
折夏煜,刘玉宏,王杨圣,郭 刚,王海滨,王 亮,韩光洁
1(河海大学 物联网工程学院,南京 211100)
2(中国原子能科学研究院,北京 102413)
3(北京微电子技术研究所,北京 100076)
1 引 言
人工神经网络是一种模拟动物神经细胞工作原理的算法模型.它通常由输入层、隐藏层和输出层构成,每层之间呈全连接.得益于其独特的神经元结构,神经网络可以做大规模的并行处理.
相比人工神经网络,卷积神经网络(Convolutional Neural Networks,CNN)是一种更高效的算法.它最大的特点是增加了卷积层,该层可以将输入和卷积核作卷积运算,实现对输入的特征提取.卷积层后通常跟随着ReLU层和池化层,它们可以在保证一定精度情况下,对数据简化,大大减小运算量.CNN如今已在图像识别、无人驾驶、医疗健康等领域得到了广泛的应用[1-5].
值得注意的是,CNN特有的计算模式导致其在通用处理器上的实现效率不高.而现场可编程门阵列(Field Programmable Gate Array,FPGA)因为具有灵活的架构,非常适合CNN的硬件实现,许多学者对此已有研究[6-8].
然而,基于SRAM的FPGA对软错误高度敏感[9].并且随着工艺尺寸的缩小,高能粒子打击对诸如SRAM的存储电路造成的影响变得不可忽略,进而削弱电路的可靠性.因此,基于SRAM FPGA的CNN加速器在设计时有必要考虑其对软错误的耐受性.特别是在配置位,一旦有软错误发生,该错误便有可能随着电路逻辑继续传播,或影响其他部分电路的功能,直到重新配置[10].这种基于FPGA中运行的CNN加速器对软错误的表征使分析其抗软错误性能成为可能.
为了从更多角度研究基于SRAM FPGA的CNN异构加速器的可靠性,同时给关键任务中的CNN加速器设计给出参考性指导,本文中以小型轻量级网络ZynqNet为原型设计了5种CNN异构加速器,并进行了大量的故障注入测试,分析了数据集、网络深度、宽度和资源开销对基于SRAM FPGA的CNN异构加速器的抗软错误性能的影响.
2 相关研究
Boyang Du等人展示了基于Xilinx SRAM的FPGA上CNN实现的故障注入结果,结果表明,尽管CNN实现中存在内置冗余,配置寄存器中的软错误仍会对任务执行结果产生影响[11].
F.Libano等人通过故障注入实验表明CNN的可靠性受软错误出现位置的影响,相比于网络中的其他层,隐藏层更加脆弱,并对输出产生较大的负面贡献[12].
此外,F.Libano等人对神经网络进行了选择性的三模冗余(Triple Modular Redundancy,TMR)加固,即仅TMR加固网络中的敏感层.相比传统的TMR加固,该方法对开销需求较低,同时获得了软错误恢复性能的提升[13].
Wenshuo Li等人提出了一种错误检测方案来定位不正确的处理元素(Processing Element,PE),并给出一种实现容错的错误屏蔽方法,用更小的开销实现了类似TMR加固网络的容错性能[14].
F.Libano等人利用二级制量化卷积层实现了优秀的抗软错误性能,该方法在精度方面有所牺牲[15].
H.-B.Wang等人提出的量化网络可以有效降低CNN加速器在故障注入期间的错误率,这种量化的方法不会对网络精度产生过大影响[16].
然而,以上研究都未针对网络深度、宽度或者数据集3个方面对基于FPGA的CNN加速器抗软错误性能进行分析.深度和宽度作为CNN的基本维度,是在进行网络设计与应用时必须要考虑和优化的参数;同时表征应用场景的数据集复杂度也值得在本例中考虑.因此,本文针对以上3点设计了故障注入实验,并研究其对可靠性的影响.
3 CNN实现
3.1 基本网络结构
本案例中选用了ZynqNet作为基本网络结构,并对其做了从XC7Z045到XC7Z020的迁移.ZynqNet具有适合FPGA加速器的高效CNN拓扑结构[17].其中使用到的Fire模块在SqueezeNet中被最初定义[18].ZynqNet将Fire挤压层卷积核大小由1×1改为了3×3,以实现在网络未用池化层情况下减小特征映射,最终有效减少网络权重的数量;为了让网络与本文中采用的数据集相匹配,原始ZynqNet的分类器中的输出数量被由1024个减少到了10个;此外,还将fire模块数量减少了50%,并调整了每层的输入和输出通道数.
3.2 网络深度不同的CNN加速器
深度表征神经网络的层数,更深的网络意味着更好的非线性表达能力,从而能够学习更加复杂的特征.大多数情况下,网络深度的调节都是一种对模型训练与优化的有力手段.因此,网络深度对基于SRAM FPGA的CNN异构加速器的影响有研究的必要.
本案例基于4层fire层的ZynqNet_baseline,实现了具有2、3和5层fire层的ZynqNet_less_2、ZynqNet _less_3和ZynqNet_more_5、网络,它们的拓扑结构如图1~图3所示,每层的特征映射大小表示为2的幂.
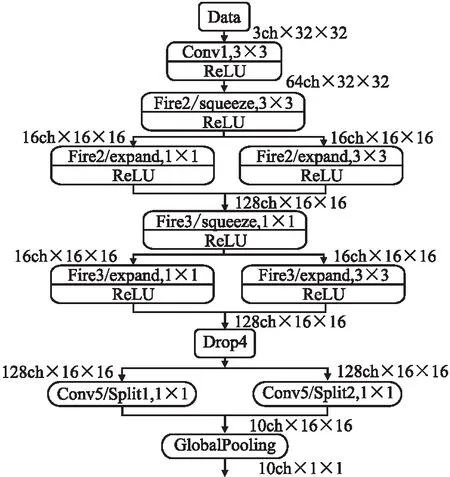
图1 ZynqNet_less_2拓扑结构结构图Fig.1 Topology structures of ZynqNet_less_2
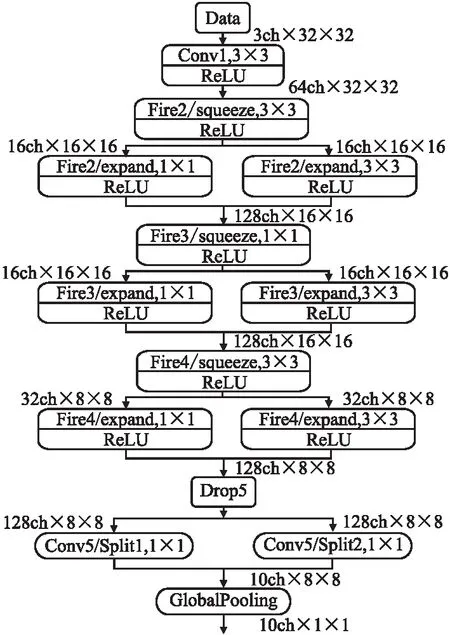
图2 ZynqNet_less_3拓扑结构结构图Fig.2 Topology structures of ZynqNet_less_3
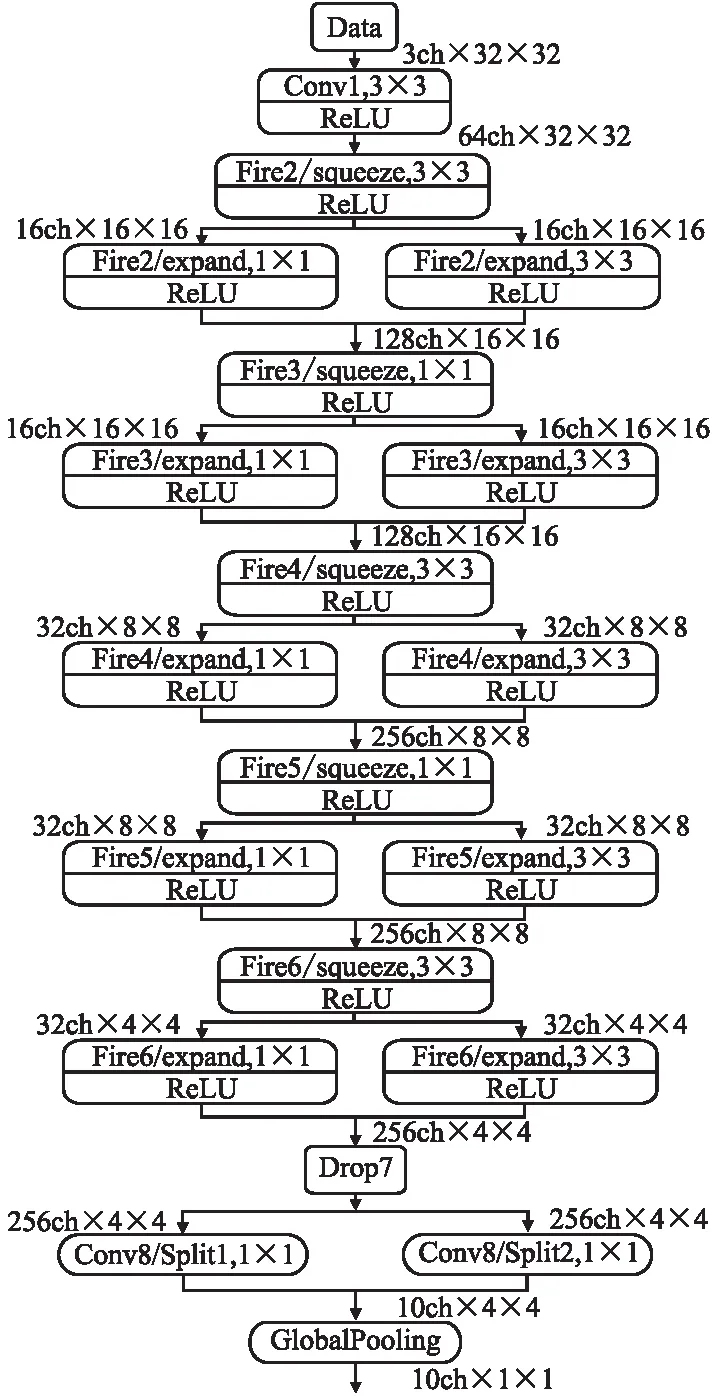
图3 ZynqNet_more_5拓扑结构结构图Fig.3 Topology structures of ZynqNet_more_5
在设计网络结构时,尽可能保证在相同层次的Fire层上输入输出通道数一致,以便让网络能在更好地收敛的同时将四者差异仅限于深度的不同.经过大量的训练,在CIFAR-10数据集上得到深度由浅到深的4个模型最终精度分别为77.28%、80.59%、79.6%和75.08%.
3.3 网络宽度不同的CNN加速器
网络宽度指的是各层所具有的神经元的数目,即通道的数量.其增加本质上是该层网络所学习的特征数目的增加,该参数的变化对辐照下加速器的软错误发生概率也存在影响.
为探究CNN网络宽度与加速器可靠性之间的联系,本案例中设计了两组对照:ZynqNet_baseline vs.ZynqNet_baseline_ x2和ZynqNet_less_2 vs.ZynqNet _less_2_x2.其网络拓扑和参数量如表1、表2所示.从中可看到,ZynqNet_less _2_x2在ZynqNet_less_2基础上,将Conv1、Fire2、Fire3和Conv5层中的输入输出特征图的维度增加了一倍.而对于ZynqNet_baseline _x2,由于FPGA资源的限制,只将ZynqNet_baseline中的Conv1、Fire2和Fire3的输入输出特征图维度增加一倍,同时仅加宽了Fire4层输入特征图的维度.
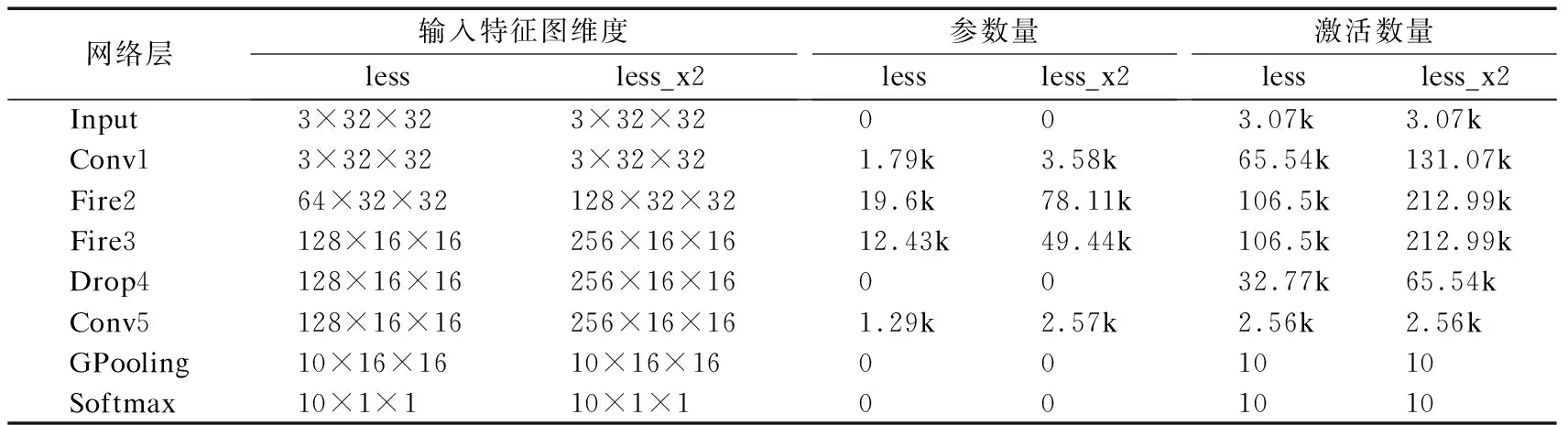
表1 ZynqNet_less_2与ZynqNet_less_2_x2的网络结构对比Table 1 Network constructure comparison of ZynqNet_less_2 and ZynqNet_less_2_x2
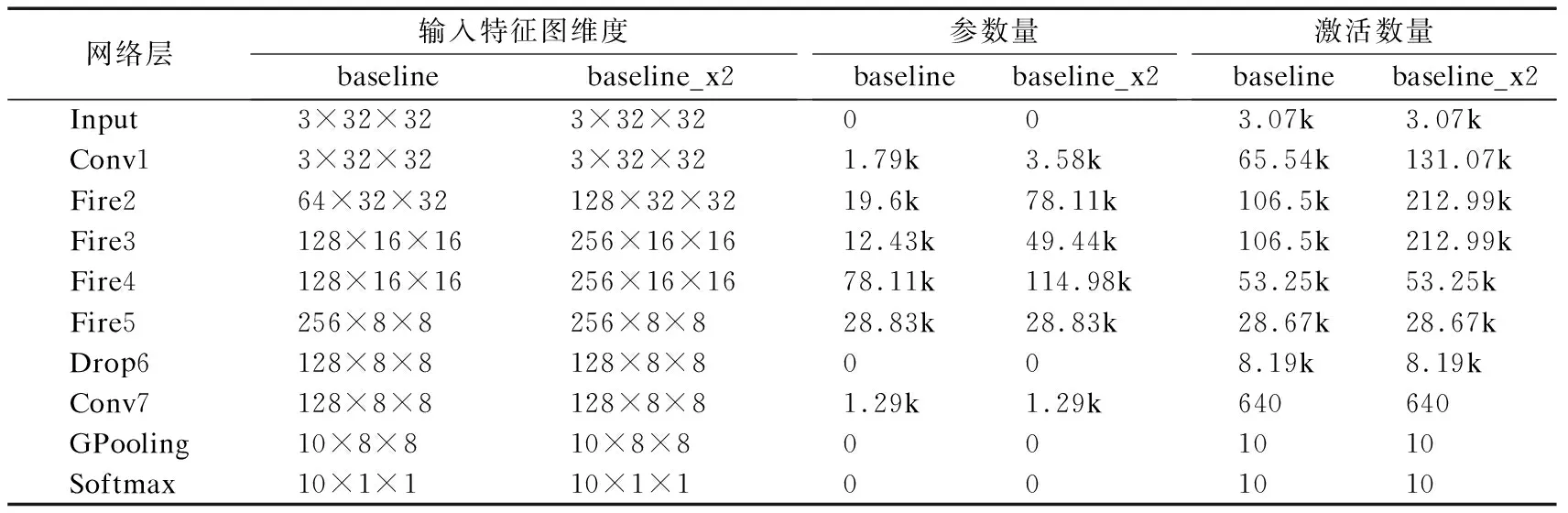
表2 ZynqNet_baseline与ZynqNet_baseline_x2的网络结构对比Table 2 Network constructure comparison of ZynqNet_baseline and ZynqNet_baseline_x2
最终,ZynqNet_baseline_x2网络的精度为81.66%,与ZynqNet_baseline的79.6%仅相差约2%;ZynqNet_less_2_x2网络的精度为80.43%,与ZynqNet_less_2相差不到3%.
3.4 数据集不同的CNN加速器
对于不同的应用场景,CNN加速器处理的目标会有所不同.环境简单、背景单一的情况下会使用相对简单的数据集;而对于复杂环境下的任务,则需要更加复杂的数据集以达到精度需求.
为了研究数据集复杂度的不同对基于SRAM FPGA的CNN加速器可靠性的影响,且使结论具有一定的普适性,本例中采用了MNIST和CIFAR-10两种被广泛使用的数据集.MNIST中为0~9的灰度手写数字图片,CIFAR-10则包含鸟类、猫、飞机、汽车、蛙类、马、卡车、船、狗和鹿共10类彩色图片.
在本例中,CIFAR-10和MNIST两种数据集都被应用于具有4层Fire层的ZynqNet_baseline网络.经过训练后,两者在网络精度上稍有所不同,分别为79.6%和98.4%,这种精度差异源自两种数据集复杂程度的不同.
在实验中,选择加速器能正确分类的图片进行故障注入,因此,网络精度的差异不会对本课题的研究产生影响.
3.5 ZynqNet加速器实现
ZynqNet加速器系统由处理系统(Processing System,PS)和可编程逻辑(Programmable Logic,PL)两部分构成,如图4所示.其中,PS端上运行ZynqNet嵌入式软件系统平台Petalinux,该平台由PetaLogix专为Xilinx FPGA中的微处理器开发.ZynqNet加速器位于PL部分,与CPU通过AXI互连.

图4 ZynqNet加速器硬件实现框图Fig.4 Block diagram of CNN accelerator hardware implementation
FPGA上电并完成初始化后,加载到片上存储器(On Chip Memory,OCM)的第一阶段引导加载程序(First Stage Boot Loader,FSBL)不仅会对PS进行初始化,还利用比特流文件在PL端配置ZynqNet加速器.映像文件则用于启动Petalinux系统.在Petalinux系统上运行可执行文件后,输入图片的权重和像素被ZynqNet加速器根据推理层的配置读取,并输出推理结果到DRAM.最后由CPU对推理结果进行分类和排名.
3.6 性能比较
ZynqNet_cifar10与ZynqNet_mnist的资源开销如图5所示,纵轴表示某项资源所使用的百分比,两者仅有细微的差异.
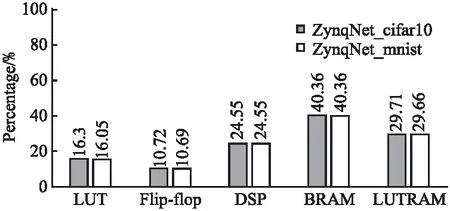
图5 数据集不同ZynqNet加速器资源开销对比Fig.5 Resource overhead comparison of ZynqNet heterogeneous accelerator with different datasets
由于CIFAR-10为32×32×3的彩色图片,而MNIST为28×28的灰度图片,前者在正向处理阶段的速度要慢于后者.根据公式:
(1)
ZynqNet_cifar10的每秒传输帧数(Frame Per Second,FPS)为3.64,而ZynqNet_mnist的FPS为4.72.
深度不同的4种ZynqNet在FPGA上实现后的资源开销如图6所示,从中可以看到,随着网络深度的增加,各项资源的开销都有所提升.
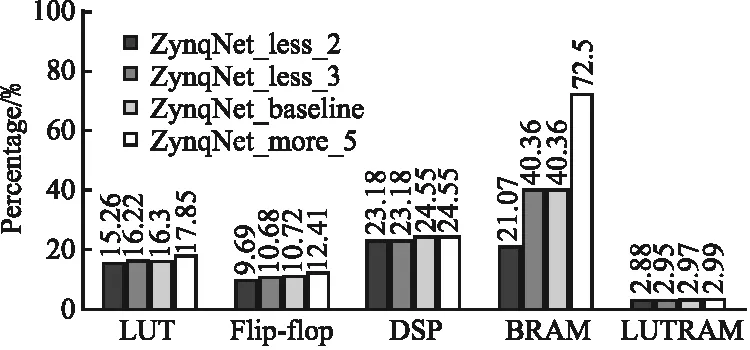
图6 深度不同ZynqNet加速器资源开销对比Fig.6 Resource overhead comparison of ZynqNet heterogeneous accelerator with different depths
由于正向推理时网络的计算量随网络深度的增加而增加,深度由深到浅的4种ZynqNet的FPS依次为3.37、3.64、4.39和4.02,大体呈增大趋势.ZynqNet_less_2的FPS未按照趋势继续增大是因为其下采样次数较少,导致最后需要在卷积层处理的特征图维度远大于其他三者,从而卷积耗费更多时间.
网络宽度导致的开销变化如图7所示,由于在ZynqNet加速器的设计中,BRAM主要用于权重和输入输出特征图的存取,因此变化主要体现在BRAM的开销增大,而其他资源上差异较小.
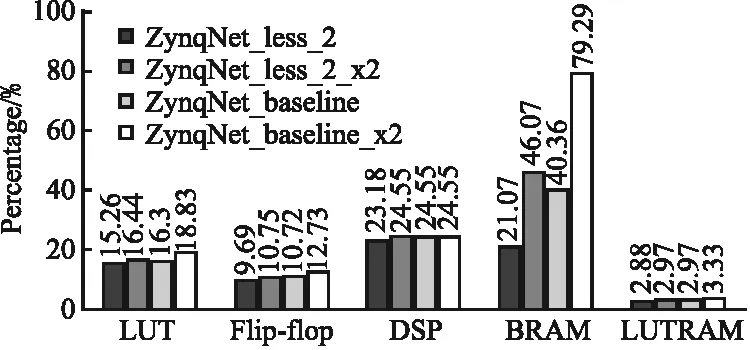
图7 数据集不同ZynqNet加速器资源开销对比Fig.7 Resource overhead comparison of ZynqNet heterogeneous accelerator with different widths
由于增加宽度会进一步增加卷积耗时,ZynqNet_less_2_x2和ZynqNet_baseline_x2的FPS分别为1.85和 2.01,对比宽度增大前有46.02%和55.22%的明显下降.
4 故障注入实验
4.1 故障注入系统
本文中采用的故障注入框架由故障注入软件和硬件构成,如图8所示.故障注入软件一方面负责在Petalinux操作系统被启动后,将随机生成的故障注入指令通过串口发送到SEM(Soft Error Mitigation)控制器,从而内部配置访问端口ICAP可以翻转解析得到的指定配置内存的值.另一方面,故障注入软件通过向Petalinux发送重启指令,来控制ZynqNet加速器开始推断图像.通过将推理完成后的图像结果与黄金结果比较,完成对是否发生分类错误的判断.若错误分类发生,则对此做记录并重新启动系统.
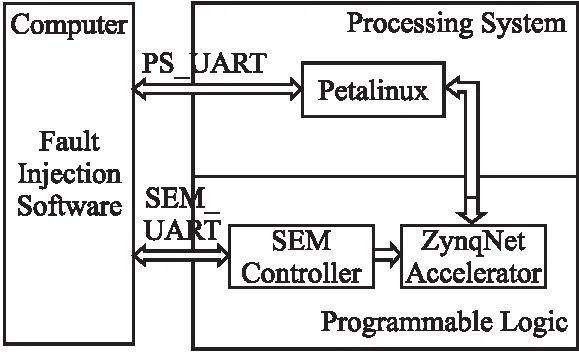
图8 故障注入系统框架Fig.8 Architecture of fault injection system
由于SEM控制器与ZynqNet加速器都在同一FPGA的PL端实现,FPGA的配置内存中随机注入的故障也可能导致SEM控制器故障,此情况下需手动重新配置FPGA.
本章2、3、4小节将从数据集、网络深度和宽度3个角度对ZynqNet异构加速器的故障注入结果进行描述和分析.
4.2 数据集不同的CNN加速器实验分析
为使实验结果具有统计学规律,本案例采用广泛应用的MNIST和CIFAR-10两种数据集,并进行了大量的故障注入测试.从表3故障注入结果中可以看出,ZynqNet _cifar10对15699张图片进行了测试,最终产生了187张错误分类的图片,分类错误率为1.191%.ZynqNet_mnist测试的17582张图片中有103张出现了分类错误,即存在0.586%的分类错误率.ZynqNet_mnist的分类错误率仅为ZynqNet_cifar10分类错误率的49.20%.尽管两种加速器开销类似,ZynqNet_mnist加速器的可靠性远高于ZynqNet_cifar10.

表3 ZynqNet_cifar10与ZynqNet_mnist的故障注入结果Table 3 Fault injection results for ZynqNet_cifar10 and ZynqNet_mnist
导致上述可靠性差异的原因有两点:
1)两者在正确分类上输出的值与其他分类上输出的值之间的差异不同.ZynqNet_cifar10返回的结果显示,尽管可以实现正确分类,但正确分类与其他分类之间输出值的差值较小.例如一张CIFAR-10数据集中的图片经过分类等处理后,正确类别的返回值为2.59,排名第2的类别的返回值为1.11,排名第3的类别的返回值为-0.04,相应地,排名由高到低前3名分类的概率依次为69.90%、15.86%和5.05%.而对于ZynqNet_mnist,输出的结果在正确分类上的值比其他分类上的值大一个数量级.例如一张MNIST数据集中的图片在正确分类上的输出值为2887.41,而在排名第2和第3分类上的输出值仅为289.51和268.23,最终得到100%的正确分类概率.因此,在故障累积的过程中,ZynqNet_ cifar10在正确分类上的输出值更容易受到影响从而导致分类结果出现错误.
2)两者数据集本身有较大差异.MNIST数据集中为灰度手写数字图片,其背景单一、特征明显,因而其特征容易被提取;而CIFAR-10数据集中图片的背景明显复杂于MNIST,特征的位置更加紧密,提取难度大.因此在受到软错误影响后,CIFAR-10图片中的特征提取与识别更容易出现错误,从而导致最后的分类错误.
4.3 网络深度不同的CNN加速器实验分析
ZynqNet_less_2、ZynqNet_less_3、ZynqNet_baseline和ZynqNet_more_5的故障注入结果如表4所示.随着网络深度的增加,ZynqNet加速器的分类错误率逐步从0.89%上升至1.38%,即抗软错误性能逐渐降低.

表4 深度不同的4个ZynqNet加速器的故障注入结果Table 4 Fault injection results for four ZynqNet accelerators with different depths
结合资源开销和拓扑结构对故障注入结果进行分析后,推理得出两点原因.首先,ZynqNet加速器的可靠性与其设计时的资源开销相关.随着网络深度的增加,如图5所示,ZynqNet加速器使用更多资源,这会导致与ZynqNet加速器设计相关的配置寄存器有更大概率被软错误影响.
其次,网络本身结构对此有影响.分析网络推理时每层的输出后发现,正数值数量远大于负数值数量,而ReLU层只能过滤掉负数值,因此大部分受软错误影响而翻转的正值中间结果被继续传播,对CNN加速器可靠性有负面贡献.
4.4 网络宽度不同的CNN加速器实验分析
两组宽度不同的对照ZynqNet_less_2 vs.ZynqNet_less _2_x2和ZynqNet_baseline vs.ZynqNet_baseline_x2的故障注入结果如表5所示.与网络深度对可靠性的影响不同,随着网络宽度的增加,尽管开销也随之增大,但ZynqNet加速器的分类错误率反而有所下降.ZynqNet_baseline_x2、和ZynqNet _less_2_x2的实验结果显示,错误率分别由加宽前的1.19%和0.89%下降至1.00%和0.85%.
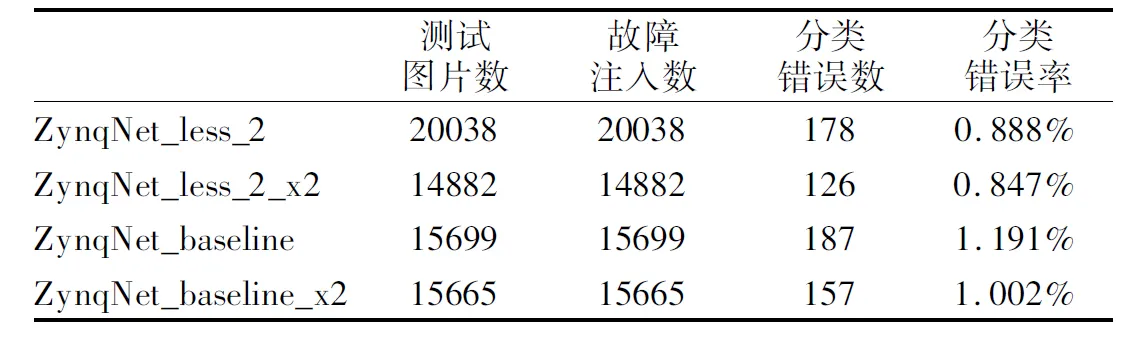
表5 宽度不同的两组ZynqNet加速器的故障注入结果Table 5 Fault injection results for ZynqNet accelerators with different widths
这种抑制了资源开销所带来的负面影响的机制与CNN本身的特性有关.从本质上来讲,CNN是靠卷积完成特征的提取的,卷积核的数量会直接影响卷积层所提取的特征的数量.通常情况下,靠前的卷积层负责提取一些诸如色差的简单特征,靠后的卷积层所提取的特征则相对复杂.若卷积层因为软错误而无法成功提取图片中某一特征,其后卷积层的特征选择和分类判断也有很大概率受到影响.
当卷积层的宽度增加时,每层所提取特征的种类也相应增加.此时的网络在受到软错误的影响时,即使某一特征在提取时出现问题,依旧能通过因卷积层宽度增加而增加的提取特征将输出特征图的结果向正确的分类引导.
5 总 结
本文主要评估了数据集、网络深度和宽度3个因素对ZynqNet加速器抗软错误性能的影响.通过提出3种不同深度和两组不同宽度的网络拓扑,并利用故障注入系统对其进行大量的故障注入测试,由分类错误率表征软错误发生概率,分析实验结果后得出以下结论:对于同种网络拓扑,输入复杂度更高的数据集会导致其软错误恢复能力的降低;同样是以更多的资源开销作为代价,随着网络深度的增加,其对应的ZynqNet加速器的可靠性会有所降低;相反,网络层宽度的增加对ZynqNet加速器软错误耐受性有提升作用.
