基于集成分类非定标摄像机单目表情识别的研究
2023-11-10邹建华龙卓群
余 涛,邹建华,徐 君,龙卓群
(1.西安航空学院电子工程学院,西安 710077; 2.西安交通大学系统工程研究所系统工程国家重点实验室,西安 710049; 3.广东顺德西安交通大学研究院,广东 佛山 528300)
0 引言
面部表情识别在很多领域都非常有价值,如医疗诊断[1]、教育[2]及人机交互系统[3]等。被识别的面部表情主要有两种类型,即二维表情[3]与三维表情[4],前者直接识别在二维面部图像中获得的处理过的特征,后者利用多个摄像机拍摄多个视角的面部图像、特定的3D数据库、特定的传感器获得三维特征。可将二维与三维结合起来识别面部表情[5],获取并处理特征。
面部表情识别方法主要包括神经网络(Neutral network)[6]、支持向量机(Support vector machine)[5]、马尔科夫链(Markov chains)[4]等。不同的学习机适应不同种类的数据集,当这些学习机被单独利用时,它们无法克服自身的局限性,甚至常常使实际数据集以牺牲很多有用的特征信息为代价在很大程度上作出改变调整来适应学习机,这样将影响识别的准确率。为尽可能保留这些原有的特征信息,需研究以某种架构集成学习机来提高整体性能。由于在多数情况下得到的是二维面部表情图像,故尝试直接从二维图像中获得并利用一些反应出的三维信息来实现逼近的三维识别。
本研究针对来自一个非定标摄像机的单目视频人的面部表情提出一个进行自动识别的框架方法,通过一个类似面部肌肉分布的弹性模板提取出相关的表情特征。经过规则化和正则化,随着一个表情的产生,这些特征在时空中变化形成的时间序列被逐行排列进一个矩阵中。利用保持邻域嵌入法(NPE),对这个特征矩阵进行降维,以这个被提炼后的矩阵作为输入,用一个集成了隐条件随机场(HCRF)和支持向量机(SVM)的集成分类器来识别表情。
1 基本原理
图1给出了面部表情识别的方法框架,其中单目视觉的二维动态表情序列或视频被用来作为训练或测试的输入表情,用表情图像中面部不同区域灰度值的质心作为特征。因为灰度包含亮度、对比度及饱和度的成分,它们都会随着不同深度而变化,故灰度值含有一定量的深度信息,特别是它的相对变化值。随着每个表情的产生,这些特征在时空中运动。

图1 面部表情识别原理Fig.1 Principles of facial expression recognition
通常相同类别表情的特征在时空运动中具有类似的周期性形式,因此每种类型表情在识别框架中只需要一个面部表情周期。随着表情产生过程,相关特征在时空中变化形成时间序列。将其排列成矩阵。这样识别问题就转化成处理所有时间序列数据的问题。
2 各环节处理及分析
2.1 特征提取与处理
用一个面部检测器检测人脸,如果检测成功,就在此面部区域再用相关检测器分别检测眼睛、鼻子及嘴巴(若这些感官中的某一个检测失败,将基于标准普通人脸的一些通用先验解剖学知识,按照一定比例在面部区域中确定可能的五官区域。如果面部检测没成功,就用面部检测器在该图像中其他区域搜索)。被检测出的区域用对应的圆圈、三角及椭圆绘制。用线条来连接检测出的区域边缘的不同位置,构成弹性模板。此方法可节省处理时间,检测器参照文献[7]进行设计,可自动检测,不需要手动辅助。图2是用于检测面部表情特征的弹性模板工作原理,可以看出,模板特征与人面部肌肉的一般分布在很大程度上是一致的,可从人体解剖学的角度来分析表情。图3为用模板检测一个人的常见表情。该检测是在以Microsoft Visual C++ 6.0为平台的环境下实现的。

图2 弹性模板匹配原理(a.面部肌肉分布 b.弹性表情模板c.真实人脸与弹性模板匹配示例)Fig.2 Elastic template matching principle (a.Facial muscle distribution, b.Elastic expression template, c.Real face and elastic template matching example)

图3 弹性模板与真实人脸在不同表情下的匹配Fig.3 Matching of elastic template and real face under different expressions
根据人面部肌肉的分布及其动态性能的解剖学知识[8],将面部表情分为8个区域。在每个区域中用一个相关的质心来描述该区域的像素在时空中随着不同表情而产生的整体变化。每一个质心通过公式(1)进行计算,其中,在时刻t时,ni是区域i中像素的数目;xm、ym和zm分别是每个像素的水平坐标、垂直坐标及灰度值。
(1)
图4用Matlab工具描绘了从一个人的中性表情开始,逐渐产生上述典型表情过程中运动质心的时间序列分布。这些时间序列的分布与形状因表情种类的不同而不同,故可用来作为区分彼此不同表情的依据。

图4 一个人由中性表情逐渐变化到不同种类表情中运动质心的时间序列分布Fig.4 Time series distribution of the center of mass of motion of a person from neutral expression to different kinds of expression
(2)
公式(2)描述了对上述时间序列预处理的原理,包括提取相对变化值、正则化及离散化。
2.2 NPE用于运动时间序列的降维
由于现实中时间序列长度很长,而序列在认知意义上的结构维数本身较低,需要降维。考虑到对同种类型的表情来说,所有特征的时间序列互相关联且这种关联性是重要的个性化特征,故希望这种结构相关性在进行降维的同时尽可能得以维持继承。
文献[9]中的保持领域嵌入法(NPE)是一种在维持数据流形的局部领域结构的流形学习方法,比主成分分析法(PCA)[10]对外围数据的敏感度小,与流形学习方法(如Isomap[11]及LLE[12]相比,NPE方法不只局限于定义在训练数据中,而是定义在全局意义上,故采用此方法来降维。
如文献[9]所述,主要原理如公式(3)~(5)所示。需注意由相关曲线产生的每一个时间序列i(i=1,…,8×3=24)被看做一个数据点xi。为了保持曲线间的相关特性,构建领近图的方式用KNN,设K为24。面部表情中的每个时间序列由领近的其他23个时间序列进行重构。尽管这些数据点可能属于一种非线性的支流形,但对每个点的局部领域范围内假设为线性流形也是合理的。用公式(3)来计算存在于这些数据点中的结构关系的权重矩阵W,用公式(4)来计算关于降维的投影,用公式(5)依次对各数据点xi进行降维转换。
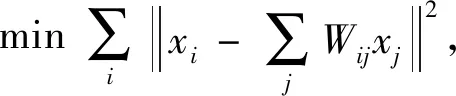
j=1,2,…,k
(3)
X(I-W)T(I-W)XTa=λXXTa,其中X=(x1,…,xk),I=diag(1,…,1)
(4)
yi=ATxi=(a0,a1,…,am-1)Txi,
(5)
其中,yi是一个m维向量。
最初,在一个表情周期下的每条表情特征运动曲线有50个空间采样点,用NPE方法后,对应的时间序列维数从一个面部表情周期的50维降至24维,且其局部流形结构以优化嵌入的方式在低维空间中得以维持。
2.3 集成分类器SVM+HCRF用于分类所有时间序列
在识别的关键环节采用集成隐条件随机场(HCRF)和支持向量机(SVM)来组建分类器,这种集成分类器同时具有HCRF与SVM的优势:对每个时间序列以局部特征为条件的隐变量被训练学习,观测值不需要条件独立,可在时空域上重叠[13];分类的最终决策边界的分类间隔在被称作特征空间的高维空间中被最大化[14],即这种分类器可解决存在于同一个时间段中的多序列分类问题。具体说明如下:
2.3.1 HCRF用于标记所有时间序列

(6)

(7);
图1中,对某第X(X=1,2,…,7)种表情,根据人面部表情中不同的质心点对应不同的运动时间序列,对应第X种表情的所有运动时间序列可以依次标记为:X01A,X01B,X01C,X02A,X02B,X02C,…,X08A,X08B,X08C。
由于所有时间序列彼此关联,故这些观测不是条件独立过程。文献[13]提出的隐条件随机场(HCRF)分类方法用中间隐变量来模型化输入域的潜在结构,并对类标记和以观测为条件的隐状态标记定义了一个联合分布,依赖于由间接图形关系表达的隐变量,不需要条件独立,且在时空域中可以重叠,该方法能够对帧间具有暂态依赖的潜在图模型关系的序列进行建模,并能够纳入长范围的依赖关联,故采用HCRF作为一种描述模式来标记这些序列,且这些序列和对应标记间的映射是通过对HCRF的训练及推理识别来进行的。HCRF具体方法参见文献[15],相关公式如式(6)、式(7)所示。


隐状态的数目设为10,窗参数w依次设为0、1、2来测试对比。在训练中,对所有的训练个体的所有表情,人脸每个区域中其质心运动的每个维度的时间序列及对应的标记分别用一个HCRF模型来学习;在推断中,被测试的序列用来自同样的脸部区域的产生同种维度的时间序列HCRF模型来判别,具有最大测试概率的类标记则为对应该测试序列的标记。这样就实现了多特征运动时间序列的标记训练及标记推断问题。
2.3.2 SVM用于对多序列的所有标记分类
通过HCRF的训练,对于一个具体的人面部表情而言,一组标记与其对应的一组运动曲线,即对应的时间序列被用于学习,且这些标记的定义值因表情和面部区域而异,故将这些标记看作是一个具体面部表情的一组特征。但大多数人的表情风格中存在一些相似成分,尽管HCRF能够在一定程度上克服时空域上的重叠,但在推断中还可能存在一些表情的某些特征完全相同的情况,此时这些特征部分是重叠的。参阅文献[14],根据SVM的性质,其决策边界直接由训练数据决定,最终决策边界的分类间隔在被称作特征空间的高维空间中被最大化,这样多数在低维空间中不可分的数据映射在高维空间中变得可分。故将与面部表情相关联的标记特征作为输入,用SVM作为最终分类手段来识别表情。
分类支持向量机(multi-class SVM)有很多种设计方法。根据文献[17]的比较测试,1对1(one-against-one)模型方法较适合于实际应用,采用此方法对训练样本中的所有类别的各类之间两两建立一个SVM模型,用以区别相关联的两类样本,具体如文献[18]所述,如果数据库中被训练的个体种类数量是K,则需要K(K-1)/2个二分类SVM分类器。每个分类器采用具有径向基函数(RBF)核的C支持向量机(CSVC)模型,其中有两个参数需要确定,即C和γ,通过平行网格搜索采用典型的交叉验证法来实现参数选择,所有K(K-1)/2个决策函数共享相同的参数(C,γ)。
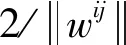
约束条件:

(8)

3 实验测试方案及结果分析
3.1 实验测试方案
为证明此方法在一般环境下的应用能力,以奔腾1.73 G的个人电脑为平台,在VC++6.0环境下进行试验。
面部表情识别框架方法用数据库the Cohn-Kanade AU-Coded Facial Expression(CKACFE) Database[20]进行测试。该数据库包含来自97个个体的486个640x480或640x490、8位灰度尺度值的图像序列。每一个序列开始于一个中值表情,逐渐进入一个峰值表情。每一个序列的峰值表情对应一个情绪标记。每一个个体有至多7种情绪:中性,惊奇,悲伤,厌恶,生气,恐惧及高兴。在实验中采用留一交叉验证法(the leave-one-out cross validation)来训练推断表情。将第一个人的所有表情用于识别,其余人的所有表情用于训练;将第二个人的所有表情用于识别,用其他人的所有表情用于训练。再次改变识别人顺序,用其他人的所有表情用于训练,以此类推,直到所有人的表情都有机会被识别过。计算每种类型表情被成功识别的比率,并把它作为最终结果。计算公式如(9)所示。其中,函数function_infer可以看作是当第i个表情是测试的情绪xi(xi>0) 时,对应相关识别系统(HCRF+SVM)的整体函数,只有在此函数的结果等于输入xi时,此结果才是正确的。
(9)
其中:δ是单位冲激函数: 若m=0,δ(m)=1 ;否则,δ(m)=0。在对HCRF的训练中,文献[16]中的共轭梯度法被用于估计相关参数;在对SVM的训练中,文献[18]中通过平行网格搜索的交叉验证法被用于估计相关参数。试验中共有97个实验个体,每个个体有7种表情,每个表情对应8个3D时间序列,则共有8×3=24个HCRF模型和7×(7-1)/2=21个SVM分类器。当对CKACFE数据库中的表情训练结束时,HCRF模型与SVM分类器的所有训练参数也被存储在另一个数据库database中。
在进行完相关时间序列的降维后,用暂态数据分别作为单个分类器HCRF及SVM的输入来直接识别面部表情。在这种情况下,一个HCRF模型对应一种类型的表情,即此时共有7个HCRF模型,SVM分类器的数量与之前设置一样。在相关训练结束后也会产生另一个与相关训练参数有关的数据库。在同样的窗口参数w下,将相应的识别结果与本方法的识别率及典型的Kotsia’s method[5]方法进行比较。
3.2 实验结果及相关分析
图5为CKACFE数据库中所有个体不同表情的时间序列分布。不同种类的表情对应不同类型的时间序列分布。这为利用这些时间序列来识别表情提供了很大便利。
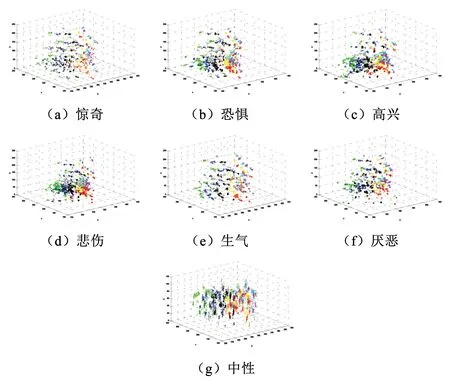
图5 CKACFE数据库中所有个体不同表情特征的时间序列分布Fig.5 Time series distribution of different facial features of all individuals in CKACFE database
表1给出了集成分类器HCRF+SVM方法与典型的Kotsia方法[5]及单个分类器HCRF/SVM用于表情识别的结果比较,可以看出,本方法的识别率比Kotsia方法更稳定,尽管在少数情况下Kotsia方法比本方法略高一些,但集成分类HCRF+SVM 比单个分类HCRF 或 SVM 的识别率高很多。当用NPE方法对时间序列降维时,相关数据流形的局部临近结构得到保持;当用HCRF训练或推断时间序列标记时,这些在帧间具有暂态依赖的潜在图模型关系的序列被模型化并纳入长范围的依赖关联;当用SVM训练或推断相关标记的最终表情时,随着分类数据被映射到高维空间中,相关分类的决策边界的分类间隔被最大化。这样与单个分类器HCRF或SVM相比,集成分类器(HCRF+SVM)在处理数据过程中包含了更多待分类数据的结构特征,使得识别更加充分。识别率随着窗口w的不同而不同,当w等于1时,识别率普遍比其他尺度的窗口要高。从总体效果上看,此识别方法结果是令人满意的。

表1 在不同窗口w下与Kotsia方法及单个分类器HCRF/SVM表情识别率的比较Tab.1 Comparison of expression recognition rate with Kotsia method and single classifier HCRF/SVM under different window w
在进行完相关时间序列降维后, 用HCRF的识别率略高于SVM,这是因为HCRF比SVM更适合于分类时间序列,而SVM直接把相关序列作为独立的参数来处理,是不合理的。无论是用单独HCRF还是单独SVM,在不同表情下识别率的变化趋势与集成分类器HCRF+SVM在总体上是一致的。
4 结论
提出了一个基于集成分类器HCRF+SVM 用于面部表情识别的方法。根据人面部通常的肌肉分布,用面部图像不同区域的质心作为特征,从人的解剖学结构角度来分析表情。随着某个基本表情的产生,这些质心在时空中运动形成多个时间序列。用NPE方法对特征序列降维后,这些数据流形的局部临近结构得以保持。在推断过程中提出的集成分类器HCRF+SVM包含了数据在时空中更多的结构特征,故试验测试中相比单个HCRF 或SVM 直接从特征序列的识别获得了更高的识别率,比典型的Kotsia 方法[5]更加鲁棒。
在后续研究中要进一步提高该方法在不同光照及遮挡条件下的鲁棒性。用一个数学模型等价代替二级分类集成,直接实现多序列的分类,这样可有效避免级间分类可能产生的累积误差,进一步提高识别率。除了本研究测试的数据库外,也可以通过新的测试将此方法应用于其他数据库中。为提高方法的实时性,还需引入并行机制,进一步提高算法速度。
