基于风速属性优化聚类的时序卷积特征聚合风速预测
2023-11-10李载源
李载源,潘 超,孟 涛
(1.现代电力系统仿真控制与绿色电能新技术教育部重点实验室(东北电力大学) 吉林吉林 132012;2.国网吉林省电力科学研究院有限公司,吉林长春 130021)
0 引言
“十四五”规划提出“双碳”目标后,电力行业重点围绕以风、光等资源构建新能源电力系统[1],其中风速的间歇性与波动性对风能的利用产生较大影响,因此准确的风速预测对电力系统消纳新能源、灵活调度及安全运行有重要意义[2]。
传统的风速预测包括物理法、统计方法(回归差分移动平均模型(Autoregressive Integrated Moving Average Model,ARIMA)[3]、卡尔曼滤波[4]等)和传统机器学习方法神经网络((Back Propagation,BP)[5]、支持向量机[6]及极限学习机[7]等),这类浅层学习方法无法对深层特征进行有效挖掘,易出现欠/过拟合现象[8]。相对而言深度学习方法在多隐含层结构的深层特征提取和关联表征方面具有较大优势[9],文献[10]构建了自校正小波长短时记忆网络(Long Short-Term Memory,LSTM)预测模型,能够分析不同尺度的时间信息,在时序数据信息的处理方面具有较大优势。文献[11]利用注意力机制改进时间卷积网络(Temporal Convolutional Network,TCN),改善了预测误差和训练时长,表明TCN 的膨胀卷积运算和残差连接机制在风速时序特征提取方面更具优势[12],目前考虑多维风速关联属性的深度学习模型多采用多通道LSTM 或多通道TCN,但随属性维数和网络层数的增加,多通道LSTM 参数量过高,训练复杂易出现过拟合;多通道TCN 缺乏长期历史信息记忆功能,模型泛化迁移能力较差。
文献[13]通过主成分分析获取风速的相关气象因素提高了模型预测精度,主成分分析基于线性变换思想构建特征筛选指标,但多维气象属性间存在复杂非线性相关特性,主成分分析降维过程缺乏非线性相关表征,可能降低特征筛选的准确性。文献[14]通过改进聚类实现多维风速属性数据的优选,并利用双隐含层LSTM 进行特征挖掘实现了高效、精确的预测。目前多数聚类方法(k-means,k-mediods等)需要人为指定聚类数,泛用性较差。文献[15]提出基于信息传播机制的近邻传播聚类(Affinity Propagation,AP),无需人为指定聚类数,适用于多维属性数据分类,但受初值选取影响较大,易陷入局部最优,且存在聚类划分边界不稳定的现象[16]。
本文采用快速相关滤波算法(Fast Correlation-Based Filter,FCBF),考虑不同风速属性间的非线性相关特性,基于信息熵筛选与风速序列高关联的属性因素,提高特征降维准确度,据此构建模型样本集。利用近邻传播机制自适应聚类模型样本集并明确划分边界,同时嵌入鲸群优化算法(Whale Optimization Algorithm,WOA)优选聚类初值,提高近AP 聚类的全局寻优性能。考虑风速与属性因素的隐含关联,在时序卷积网络中嵌入注意力机制实现特征聚合,并结合共享权值门控记忆单元提高超短期预测计算效率,提出基于时序卷积特征聚合(Temporal Convolutional feature Aggregation Network,TCAN)的风速预测模型。将聚类优化后的属性样本输入时序卷积特征聚合网络,通过时序特征提取与降维聚合,结合记忆单元预测风速,并将预测结果与实际值比较,对模型的有效性和准确性进行验证。
1 考虑关联属性构建样本集
风速变化受到气温、压强以及湿度等关联属性的影响,合理选择风速属性能够降低模型输入的复杂度并提高预测精度[17]。本文采用FCBF 从风速属性中筛选相关度较高的因素,构建模型训练样本集合。风速属性信息熵的计算式为:
式中:H(W)为风速序列W的熵;w(t)为t时刻的风速值;H(Vk)为第k个风速属性序列Vk的熵;vk(t)为t时刻的元素;H(Vk/W)为风速序列W确定时第k个风速属性序列Vk的信息熵;P为变量出现的概率。
基于信息熵计算风速属性序列与风速序列的对称不确定性,构建相关性度量指标:
式中:SU为相关性度量指标,其取值范围为[0,1],其数值越高说明风速与属性信息的相关性越强,当SU为1 时表示风速与属性信息完全相关;反之,则表示完全独立。
选择风向、湿度、气温、气压、辐照度及降水量6 种风速属性,并计算SU排序,选择SU最大的3 种关联属性构建模型输入样本:
式中:I(t)为t时刻的模型输入样本;分别为t时刻的风速及3 种关联属性序列。
选择未来ρ步风速作为模型输出样本:
式中:O(t)为t时刻的模型输出样本;w(t+ρτ)为t时刻未来第ρ步的风速值;τ为采样步长。
构建模型样本集如下:
式中:(I,O)为模型样本集,含n组输入-输出映射对。
通过深度学习挖掘各属性间的关联规则,并构建映射函数f以描述输入样本与输出样本的时序关联,依据该映射关系实现未来ρ步风速的超短期预测:
由于实际环境的复杂性,预测风速与实际值始终存在误差,其中机器学习模型的预测误差受训练数据集与模型架构影响较大。为提高模型预测精度,采用聚类算法优化训练集合,并结合时序卷积特征聚合模型进行训练。
2 WOA-AP聚类优化
风场多维风速属性的变化趋势具有关联性[18],相似样本间隐含的关联性将直接影响特征提取和预测效果[19],本文采用WOA-AP 聚类优化样本集合,考虑到输入样本的高维复杂性,选择其风速序列为主要特征,并依据风速序列相似度,聚类相似样本于同一典型集合。
1)构建相似度矩阵S=[S(i,j)]n×n,其中S(i,j)为第i行第j列风速序列相似度函数,用于表征样本间的空间距离:
式中:W(i)为i时刻的风速序列;对角元素S(i,i)=1为中心参考度,代表对聚类中心的评判期望。
2)吸引度因子R(i,j)表征中心样本对隶属样本的吸引度,隶属度因子A(i,j)表征隶属样本对中心样本的归属度,吸引度因子R(i,j)和隶属度因子A(i,j)在聚类迭代过程中不断更新,更新过程如下:
式中:κ表示矩阵中的第k列;η为迭代轮次,初始值R0(i,j)=0,A0(i,j)=0。
3)提出因子衰变控制策略,对吸引度和归属度进行衰减处理:
式中:λ为衰减系数,且λ∈(0,1),以避免迭代过程中出现数据振荡问题。
4)循环步骤1)—步骤3),直到满足收敛条件或达到迭代次数要求,停止更新并产生u个聚类中心。
研究表明,聚类中心参考度S(i,i)的初始设置对聚类结果影响较大,易导致聚类结果出现局部最优情况[20]。故引入聚类评价指标[21]表征聚类性能:
式中:Sil为聚类评价指标,Sil∈[-1,1],该值越大表明聚类准确率越高;m为样本数;a(ϕ)为样本ϕ与同类其他样本距离的均值;b(ϕ)为样本ϕ与同类其他样本间距离的最小值。
视中心参考度S(i,i)为种群个体,定义适应度函数E为:
结合鲸群算法(WOA)[22]以适应度最小化为目标寻优种群个体,提高样本集边界划分的准确性。WOA-AP 依据风速序列相似度将样本集划分为若干相似典型集,针对典型集数据进行深度学习,挖掘属性关联特征,提高预测模型精度与效率。
3 时序卷积特征聚合风速预测
时序卷积特征聚合网络(TCAN)的结构如图1所示,主要分为3 层:(1)时序卷积层,对输入的风速属性提取深层特征;(2)特征聚合层,对属性特征经特征聚合模块进行降维聚合;(3)记忆预测层,通过记忆单元捕获聚合特征向量的关键历史信息,并输出风速预测值。
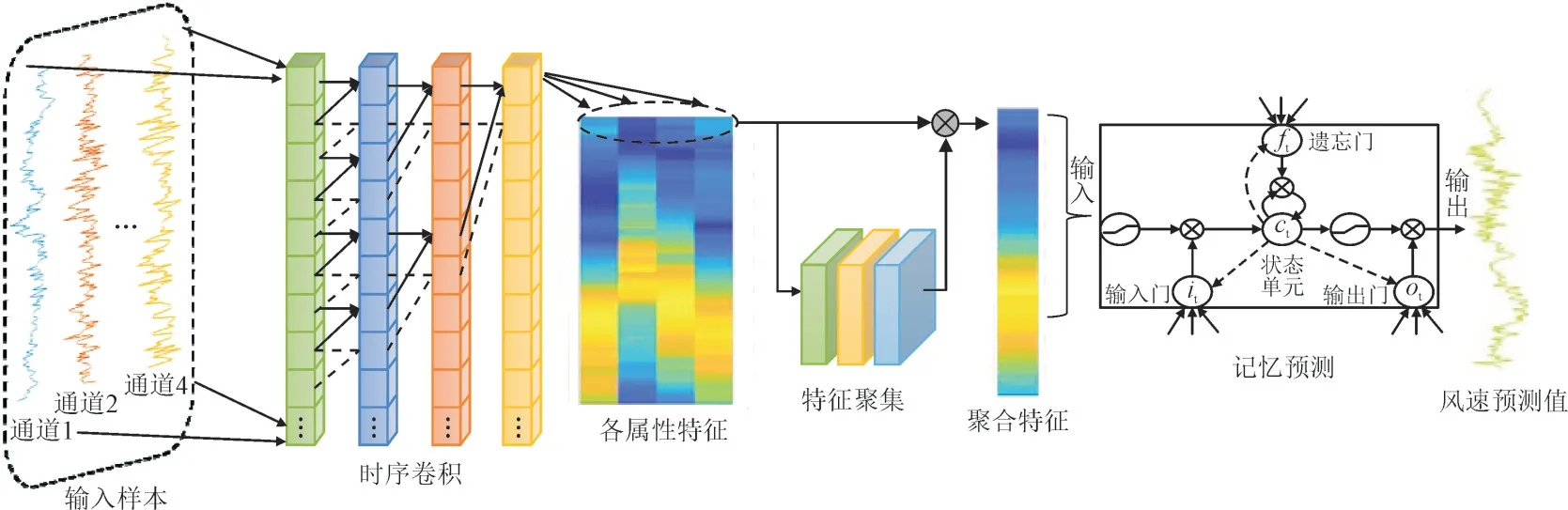
图1 TCAN网络结构Fig.1 Structure of TCAN
3.1 时序卷积层
将样本所含风速及3 类关联属性序列输入时序卷积模块,进行深层特征提取,结构如图2 所示。图2 中Xs-2,Xs-1,Xs为模型输入序列,Ys-1,Ys为经双层时序卷积后的输出序列,其中时序卷积单元采用四通道TCN,每一通道对应单一序列,该单元在一维因果卷积的基础上引入膨胀因子和残差连接,有效增加了历史信息覆盖率和网络深度[23],图1 中因果膨胀卷积结构数学模型为:
式中:F(·)为因果膨胀卷积;x为模型输入序列;f为卷积核;s为索引;d为每层的膨胀因子,d=2p-1;ζ为卷积核大小;ωi为卷积核i索引处元素;Xs-d·i为输入序列在索引s-d·i处的元素。
残差连接模块通过双卷积跨层连接进行特征提取,并添加权值归一化和随机失活模块加速网络计算。
3.2 特征聚合层
特征聚合层对时序卷积层各通道提取后的特征向量进行降维加权聚合,具体步骤如下:
1)信息压缩。通过平均池化将每个通道的特征向量压缩为1×1 作为该通道的原始权重,构建1×4 的原始权重序列,公式如下。
式中:U为特征矩阵;uj为第j个通道的特征序列;Z为通道原始权重序列;zj为该通道对应的原始权重。
2)权重提取。信息压缩所得原始权重Z通过Relu 函数进行信息聚合,经sigmoid 函数修正后输出通道权重序列Q。
式中:q1,q2,…,q4为第1 到4 个通道对应的权值,ω1,ω2分别为2 个权值矩阵;sigmoid,Relu 均为非线性激活函数。
3)聚合输出。各通道特征向量加权求和得到聚合特征向量P。
结合图2 中的可视化特征变化过程可知,特征聚合层实现了多通道特征向量的维度约简,同时通过加权聚合保留了风速及关联属性特征的关键信息。
3.3 记忆预测层
以获取聚合特征向量关键历史信息为启发,控制记忆单元捕获聚合特征向量相邻时刻的依赖关系,进一步挖掘其深层特征,输出风速预测值。
记忆单元将长期历史信息的关键特征存储为状态向量ct,并通过门控机制读取和修改各时刻的状态向量,并结合共享权值提高计算效率,计算式如下:
式中:ht,pt分别为t时刻的输出向量和输入向量;“:”为向量拼接符号;it为输入门,控制当前信息的流入;ft为遗忘门,减少上一时刻状态向量ct-1中的冗余信息;ot为输出门,决定ct传递多少信息作为当前时刻输出;Wi,Wf,Wo,Wc分别为输入门、遗忘门、输出门与状态向量的权值矩阵;bi,bf,bo,bc为偏置向量;σ,tanh为非线性激活函数。
记忆单元如图3 所示。

图3 记忆单元Fig.3 Memory unit
3.4 模型评价
选取平均绝对百分比误差(Mean Absolute Percentage Error,MAPE)、均方根误差(Root Mean Square Error,RMSE)及拟合优度系数(Coefficient of Determination,R2)构建适用于多步预测的多维评价体系。MAPE,RMSE 的值用EMAP,ERMS表示。
式中:wi,分别为风速实际值和预测值;w为风速均值;n为样本数。
3.5 基于属性优化聚类的TCAN风速预测模型
基于属性优化聚类的TCAN 风速预测模型流程基本步骤如图4 所示。

图4 基于属性优化聚类的TCAN风速预测流程图Fig.4 TCAN based wind speed prediction flow chart considering attribute optimization clustering
4 算例仿真
选取东北某风场2021 年春季(3 月1 日-5 月31 日)实测数据构建模型样本集并进行仿真分析,采样步长为10 min,模型输入样本的历史步长为144 步(前24 h),输出样本步长为6 步(后1 h),单个样本总计步长为150 步,样本集共计13 099 组样本,其中样本集前80%为训练数据集,后20%为测试数据集。
4.1 属性相关性分析
选择风速及6 种关联属性进行归一化处理,采用FCBF 对属性数据进行筛选,各属性与风速序列的关联度指标SU(无量纲)如图5 所示。

图5 风速属性关联度Fig.5 Wind speed attribute correlation degree
图5 的6 种关联属性均与风速序列存在一定相关性,其中风向、气温、气压3 种属性的SU较高,因此选择这3 类属性构建模型的输入样本,经归一化处理后的可视化结果如图6 所示。
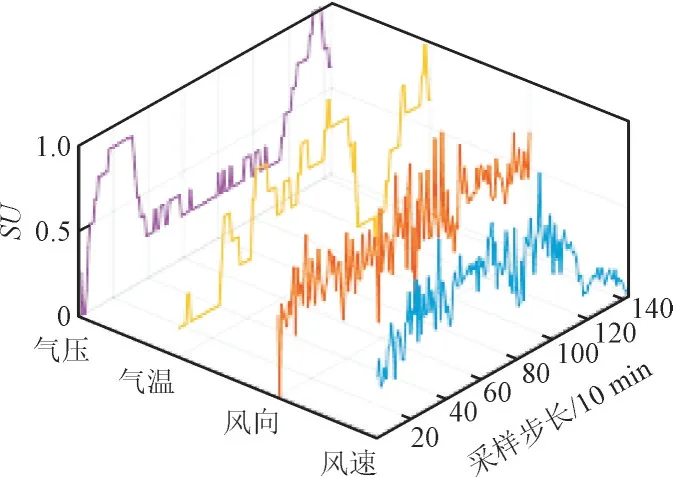
图6 模型输入样本Fig.6 Input samples of prediction model
由图6 可看出3 类风速属性与风速序列间的时序波动一致性,与传统的风速样本数据相比,该输入样本包含了更加丰富的时序信息与隐含联系。
4.2 聚类分析
利用WOA-AP 算法对样本集进行聚类优化,并计算划分典型集的Sil指标(无量纲)评估算法的准确性。
设置初始种群数为25,最大迭代数为100。WOA-AP 与AP 聚类算法进行对比,结果如图7 所示。
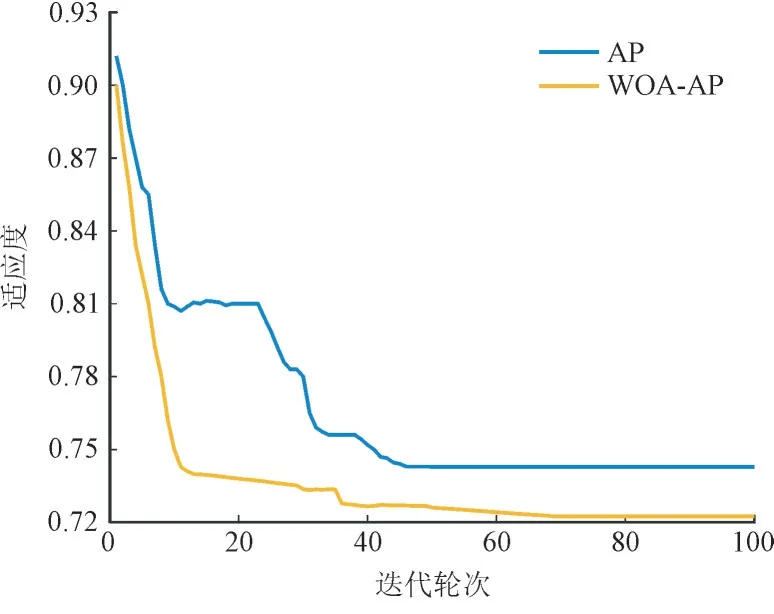
图7 算法迭代过程Fig.7 Diagram showing algorithm iteration
聚类划分类别数自动化分为4 类,其中AP 聚类算法Sil为0.334 5,WOA-AP 聚类算法Sil为0.368 9。由于WOA 优化模块的鲸群捕猎仿生机制使算法参数更少、寻优性能更强,WOA-AP 聚类算法在收敛速度和全局寻优能力上更具优势,并有效提升了聚类准确性,聚类划分结果见表1 和图8。

表1 WOA-AP聚类结果Table 1 WOA-AP clustering results
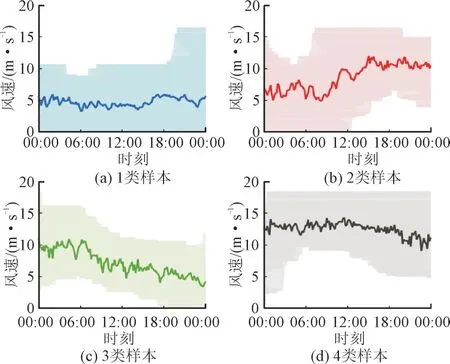
图8 聚类结果可视化Fig.8 Visualization of clustering results
由表1 结合图8 可知,WOA-AP 聚类算法各类样本的Sil指标较高,类内样本相关性高,表明聚类结果具有较高准确度。同时划分边界选取合理,稳定性强,样本数均大于2 500,保证了后续各类模型训练的数据库规模。
经聚类优化后的样本集合作为训练数据输入预测模型以提高预测精度及泛化能力。
4.3 TCAN预测性能分析
经大量仿真模拟结合网格搜索法确定网络结构,TCAN 的时序卷积层数为3,全连接层隐含单元数为200,记忆预测层为双隐含层,隐藏层1 隐含单元数为128,隐含层2 隐含单元数为256,梯度阈值为0.8。时序卷积模块结构参数见表2,其中卷积核尺寸无量纲。
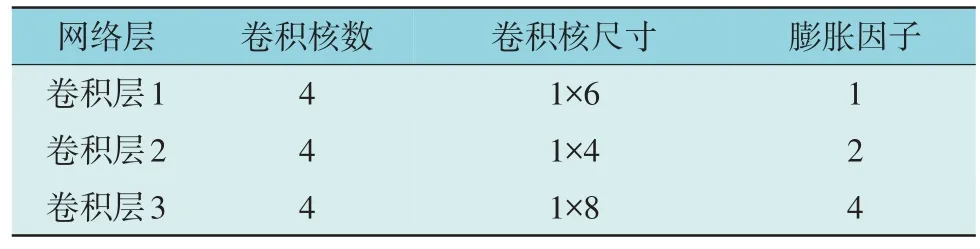
表2 时序卷积模块结构参数Table 2 Structural parameters of temporal convolution module
以60 号风机为研究对象,利用训练完成的TCAN,TCN 及LSTM 分别进行1 h 风速超短期预测,输入时间窗为144 步,输出时间窗为6 步,预测采用6 次模拟取平均所得,不同模型的结果如图9和表3 所示。

表3 不同模型预测误差Table 3 Prediction error of different models
图9 和表3 表明,3 种模型均实现了风速的有效预测。其中LSTM 具备记忆功能,但缺乏高效的特征提取模块,存在梯度散失的问题,预测精度相对较低,该结论与文献[24]基本一致;TCN 的时序卷积实现了高效的特征提取,其预测精度较LSTM 高,但缺乏对长期历史信息的处理功能;TCAN 综合时序卷积的特征提取能力与记忆单元的长期信息处理能力,相较单一的TCN,LSTM 网络,网络表征及特征挖掘能力更强,预测精度更高。
4.4 TCAN预测性能分析
为进一步分析组合模型的预测性能,选择本文模型FCBF-WOA-AP-TCAN(模型1),FCBFTCAN(模型2)及TCAN(模型3)分别对测试集中5月23 日、5 月25 日、5 月27 日风速进行1 h 超短期预测,结果见图10 和表4。

表4 组合模型预测误差对比Table 4 Comparison of prediction error between combined models

图10 组合模型预测结果对比Fig.10 Comparison of prediction results between combined models
由图10 可知,在风速波动较为平缓的区段,3 种方法均能对实际风速进行准确预测;但在风速波动剧烈的区段,FCBF-TCAN(模型2)及TCAN(模型3)预测效果相对欠佳,本文模型(模型1)预测准确性更高。
由表4 可知,由于风速波动性对预测结果的影响较大,各模型的预测效果迥异。其中TCAN(模型3)的预测效果相对较差,预测误差波动性较强;模型2 通过FCBF 属性筛选优化TCAN 模型的输入,预测精度得到提升,但由于训练样本集的复杂性,模型2 缺乏对分类变化特征的针对性学习,预测结果泛化适应能力较弱,缺乏稳定性;本文模型(模型1)采用WOA 克服AP 聚类算法的局部寻优特性,构建类内关联性强、数据分布均匀的训练集合,在训练数据划分边界选取上更具优势。通过对WOAAP 聚类算法优化的各类典型集合进行学习,针对不同风速日变化趋势选择与之适配的模型进行预测,模型易捕获不同类别的变化特征,在不同预测日下均保持了良好的预测性能,训练所得TCAN 模型预测误差最小,各项指标均满足风速预测技术标准要求。表明本文模型(模型1)具有较好的预测效果及泛化迁移能力。
5 结论
提出基于风速属性样本优化聚类的时序卷积特征聚合风速预测模型,得出以下结论:
1)快速相关滤波算法能有效筛选风速关联属性因素优化样本集,提高了模型预测精度及训练效率。
2)将智能优化模块嵌入临近传播聚类机制,对训练样本进行合理分类,满足了类间差异性和类内相似性要求,提高聚类准确性与稳定性。
3)时序卷积特征聚合模型进行风速时序特征提取与信息记忆,降低深度学习的复杂度,实现高效的风速属性隐含信息挖掘与多时间尺度信息处理,提升了网络预测精度。通过仿真结果与实测数据对比,验证了该模型的准确性和适用性。
