基于服务总线的电网中心数据自动同步技术
2023-11-10梁雪青杜舒明赵小凡刘超
梁雪青,杜舒明,赵小凡,刘超
(广东电网有限责任公司广州供电局,广东广州 510610)
电网管理策略的形成需要电网实时运行数据的指导,而电网中心数据的同步处理有利于后续管理系统的调用[1]。考虑到当前电网运行规模不断扩大,实时电网数据量也在成倍增长[2],传统的数据同步技术在电网中心数据同步处理过程中容易出现数据丢失、同步时间过长等问题,无法满足电力系统工作要求。相关学者对此进行了深入研究,文献[3]深入分析了传统数据同步技术的完整性问题,应用全自动运行模式,明确数据同步中心位置。结合实时数据库集群技术,筛选出符合要求的数据,在多个数据库中运用主从数据复制技术,实现数据的同步处理,但是该同步技术耗时较长。文献[4]设计的同步方法以MySQL 二进制日志为基础,利用二进制日志对待同步数据进行解析,再通过Binlog 还原器重构为可以被同步识别的数据格式,完成分布式数据同步工具的设计,但是经过验证可知,该技术的同步效率较低。文献[5]针对数据同步问题建立一种以多环形队列为核心的共享方案,实现态势数据、调度数据、监控数据等多种类型的异构数据同步共享传输。并对该同步传输方法进行时间应用,按照数据同步要求实施调整同步策略,但是该技术自动同步稳定性较差。为解决上述问题,该文以电网中心数据同步问题为主要研究内容,提出一种以服务总线为基础的自动同步技术。根据实验结果可知,所研究的同步技术与以往数据同步方法相比,大幅度降低了数据同步时间。将其应用在电网数据管理系统内,有利于提升电网运行稳定性。
1 电网中心数据自动同步技术设计
1.1 设计电网中心数据监控方法
将粒子群算法应用在数据监控过程中,主要是通过后验概率采集粒子群权重,明确后验分布情况[6]。针对目标数据进行跟踪,得出的数据变化表达公式如式(1)所示:
式中,c表示目标数据,χc-1表示数据状态向量,δ表示数据更新过程中存在的噪声,ε表示过程噪声增益矩阵。
设置多个数据节点,采集电网中心目标数据的信号能量,随机选取一个数据节点,将其在当前时刻接收的信号能量表示为式(2):
式中,φw表示数据节点,Dc表示数据节点接收的信号能量,表示节点增益因子,Fw表示目标数据的信号能量,表示数据节点的位置,μ表示衰减参数。
采集前一时刻目标数据的粒子集,通过状态方程预测目标数据的状态[7],新粒子集采集结果表示为式(3):
式中,z表示粒子集,表示当前时刻数据节点粒子集,表示前一时刻数据节点粒子集,s表示状态预测函数,p表示目标数据后验概率。
针对每个数据电网中心数据节点,采集节点数据的实时状态向量,则该节点对应的粒子权重计算公式表示为:
式中,为粒子权重。针对某个聚合数据的更新情况进行监控,可得:
式中,l表示聚合数据,B表示没有归一化处理的权重,N表示没有归一化处理的本地估计,H表示数据状态估计误差,K表示数据退化控制系数,∂表示采样周期。将式(5)的计算结果传递至簇头节点,可得出权重和计算公式为:
根据权重和计算结果,通过以下公式得出方差和全局估计值:
式(7)、(8)中,G表示权重和,ρ表示目标数据方差,ψ表示目标数据全局估计值,将计算结果传送至数据监控节点,明确电网中心数据实时状态。
1.2 计算数据同步时间偏差
根据数据更新监控结果,针对待同步处理的数据计算同步时间偏差[8],电网中心数据同步模式容易受到影响,当前数据同步响应存在较大的时间偏差,导致同步数据的完整性较差。电网数据中心响应同步请求的时间偏差检测原理如图1 所示。

图1 同步时间偏差检测原理
在图1 所示的同步时间偏差检测过程中,在数据采集模块设置两个连续时刻,发送数据同步请求,并标注出电网数据中心响应请求的对应时刻,根据同步请求响应时间延迟情况,得到同步时间偏差。
其中,数据传输延时计算公式为:
式中,Δtα表示同步请求发送延时,Δtβ表示同步请求接收延时。
而时间偏差计算公式为:
式中,Tα1、Tα2表示两个连续的数据同步请求发送时刻,Tβ1、Tβ2表示两个连续的数据同步接收发送时刻。考虑到电网中心的请求响应速度较快,在时间偏差计算过程中可以忽略接收延时,可以将式(10)变化为:
1.3 构建ESB数据同步模型
考虑到当前需要同步处理的电网数量较大,使数据同步周期无法控制,针对该问题,设计以服务总线ESB 为核心的数据同步模型[9]。根据服务总线的数据集中特性,将待同步数据放置于共享数据中心,确保实时监控的更新数据可以迅速发送至各个系统。
同步控制器的主要功能包括数据清洗、数据分发以及数据传送[10],针对增量表内接收的实时电网数据,通过映射逻辑转换、字段非空判断、冗余数据检查等操作进行清洗处理,并将处理后的数据存储至共享数据中心。根据电网独立应用系统的同步请求,由控制器向相应系统发送同步数据字段[11-12]。最后,为了提升数据同步的实时性,根据应用系统同步请求发送频率,设置具有松散一致性同步特点的传送频率。
1.4 建立高效同步管理机制
电网中心数据同步过程中,数据的反复读取极大影响了同步效率[13]。针对该问题在内存管理方面引入池化资源思想,建立文件池,生成高效同步管理机制。所设计的文件池主要由四个部分组成,分别是文件池管理器、文件队列、缓冲区和工作文件列表。数据同步过程中缓冲区越大可以更加高效地管理同步数据[14],但是考虑到内存空间的有限性,运用多指针建立的缓冲区可以按照同步需求实时调整缓冲区容量。
在数据同步过程中,当新加入的电网中心数据超出了当前文件池剩余容量,需要运用置换策略从文件池内剔除一个旧文件,腾出更多空间放置新文件[15-16]。文件采用了基本置换策略进行文件池数据置换,具体操作如图2 所示。
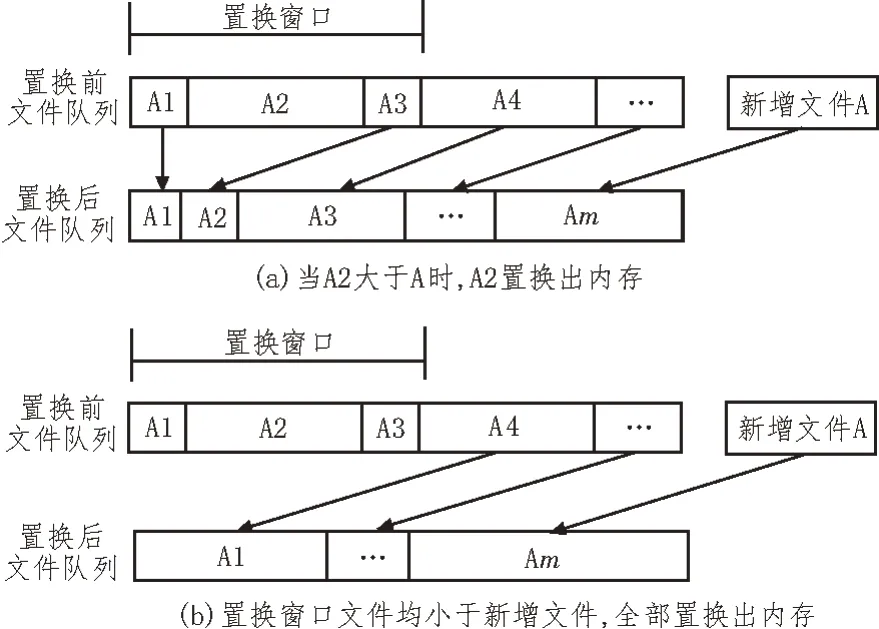
图2 基本置换策略示意图
考虑到文件池所管理的数据大小不一,无法进行统一管理,所以需要根据实际数据情况,确定基本置换策略,包括两种典型情况。一种情况如图2(a)所示,文件池内包含多个电网数据,根据最近使用时间对文件池内数据进行排序,设置数据A1 使用间隔时间最久,但数据A1 占用空间太小,而A2 既满足置换要求又占有较大的空间,则在新增文件管理过程中可以保留A1,从文件池内剔除A2。另一种置换策略如图2(b)所示,当A2 占用空间小于A1,那么就按照顺序比较A1 与A3,当A3 占用空间较大将A3 调出文件池。若A3 也不满足置换要求,则需要进行删除处理,删除多个许久未使用的数据来满足新增同步数据管理需求。
2 实验分析
2.1 部署实验环境
文中应用六台计算机搭建Hadoop平台,完成实验环境的合理部署,具体的集群配置情况如表1 所示。
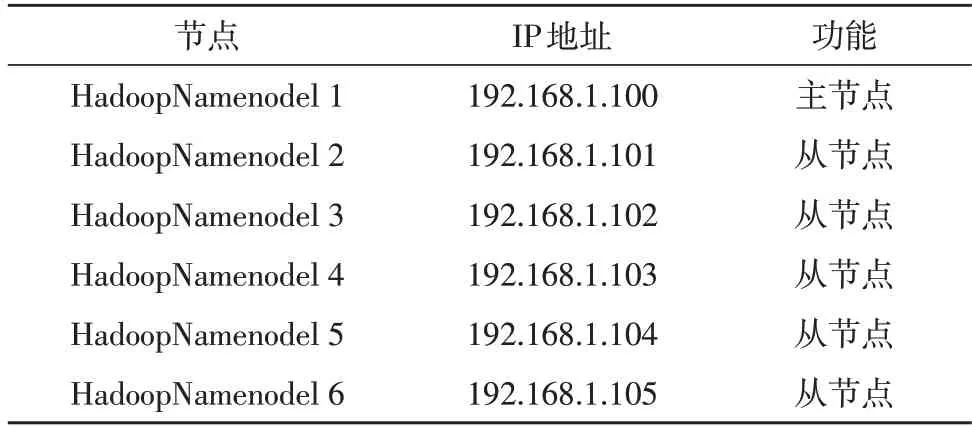
表1 节点设置
根据表1 所示的配置信息,设置其中一台计算机为主节点,其余计算机均为从节点,参考实际电网数据传输流程,形成网络带宽为50 MB 的电网数据中心。
2.2 设计数据自动同步模块
数据自动同步模块是所设计同步技术实现的载体,根据所设计的步骤建立图3 所示的数据自动同步模块,内部主要架构由输入队列、输出队列、同步引擎以及同步源组成。

图3 数据自动同步模块
根据图3 所示的数据自动同步模块结构图可知,输入报文和输出报文的处理是数据同步的重要环节之一,实验采用SyncML 进行分析处理。
同步引擎作为数据自动同步模块的核心,具有数据监控、数据拆分、同步时间偏差计算、同步策略生成以及同步管理等多种功能。通过同步引擎的处理,将数据监控环节检测到的更新数据转化为便于后续同步处理的报文,并将拆解信息封装在待同步数据项列表。经过同步时间偏差计算、同步策略生成和同步管理等模块,完成封装电网中心数据的同步更新。
2.3 数据同步性能分析
应用上述设计的数据自动同步模块运行结果,明确所设计技术的数据同步性能。同时为了加强实验结果的说服力,采用文献[3-4]提出的数据同步方法进行相同的实验。考虑到同步时间是判断同步技术优劣的重要指标,对比三种方法的数据同步时间,生成图4 所示的数据同步时间性能对比图。
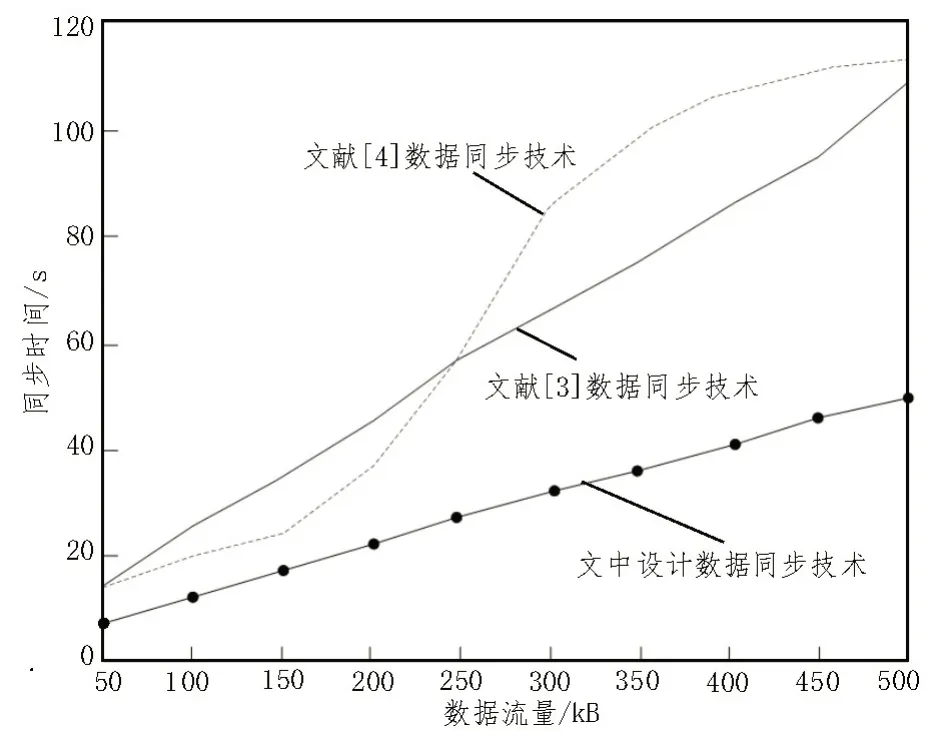
图4 数据同步时间性能对比图
根据图4 可知,随着数据流量的不断增长,各项数据同步技术的同步时间均有所增长。其中,所设计技术的同步时间明显低于其他两种同步技术。从平均同步时间来看,所设计技术的平均数据同步时间相比其他两种方法降低了50.59%、59.84%。
3 结束语
通过数据更新实时监控、同步时间偏差计算、同步模型构建以及管理机制的生成,实现电网数据的高效同步处理。经过实验验证可知,所提出的数据同步技术有效降低了数据同步时间,提升电网数据同步性能。考虑到电网内很多数据涉及到个人隐私,数据同步过程中需要确保数据安全,下一步的研究重点就是完善数据同步技术,将数据安全性要求融入其中。
