面向舆情监控的智能化自然语言处理算法设计
2023-11-10罗涛谢凤祥李光华
罗涛,谢凤祥,李光华
(国能大渡河流域水电开发有限公司,四川成都 610000)
随着互联网的发展,网络信息的规模和数量均呈现出爆炸式增长,任何舆情信息通过互联网均可在短时间内大范围传播,从而造成严重的舆情风暴[1-2]。而企业针对网络舆情进行分析,有利于及时获取网络评价、市场动向、品牌形象及广告效果等关键信息,并为企业经营决策提供重要参考[3-5]。
自然语言处理(Natural Language Processing,NLP)是一种利用人工智能算法对自然语言进行分析处理,从而完成目标任务的技术。其在智能翻译、语音识别和人机交互等领域的应用较为广泛[6-9]。传统舆情监控基于词库统计分析的方法,但其在数据爆炸的互联网时代,应用效果并不理想。因此将自然语言处理技术应用于网络舆情分析,以提高分析效率及准确性,成为一种前沿研究趋势。针对此,该文开展了自然语言处理技术在网络舆情智能监控中的应用研究,实现了对网络舆情的准确分析。
1 智能舆情监控技术框架
1.1 总体技术框架
基于自然语言处理的智能舆情监控框架如图1所示[10]。该框架各层的主要功能如下:1)数据源层是舆情监控分析的数据来源,承载着众多网络舆情信息。2)数据采集层则利用智能网络爬虫技术来实现舆情信息的采集。3)数据处理层实现对获取页面信息的预处理。4)舆情分析应用层利用深度学习算法对预处理后的数据进行挖掘分析,并实现分析结果的应用与可视化。
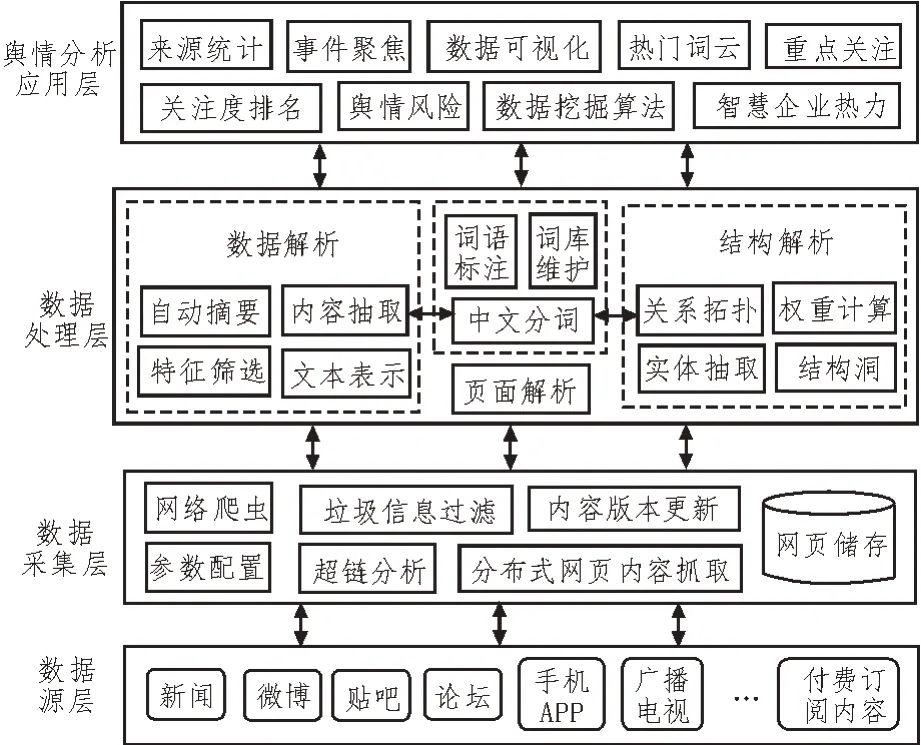
图1 智能舆情监控技术框架
1.2 网络爬虫技术
网络爬虫是在互联网技术快速发展、数据规模急剧增加的背景下,所诞生的一种模拟人类阅读浏览习惯的互联网网页自动获取技术[11-13]。该技术通过不断循环访问URL 列表来实现页面信息的获取与存储,具体的工作流程如图2 所示。

图2 网络爬虫流程
文中采用的网络爬虫软件为Scrapy 引擎爬虫框架。该引擎是爬取过程中数据和信息交换的核心;调度器负责对待访问URL 列表进行管理维护,并安排访问任务顺序;下载器根据来自调度器的请求从互联网上下载相关信息,且将应答返回给引擎;而爬虫负责对获取的应答内容进行分析处理,根据项目需求提取数据,再提交新的访问请求;管道则负责管理和处理爬虫项目数据。
2 基于NLP的智能舆情监控算法设计
该文提出基于自然语言处理的智能舆情监控算法,如图3 所示。首先利用网络爬虫技术获取与舆情相关的语料集,并进行初步的分词、标注等预处理操作;然后利用CBOW(Continuous Bag-of-Words)词向量模型实现文本语料的结构转化;最终将其作为多维注意力机制网络(Multi-Dimensional Attention Network,MDAN)的输入,再经过特征学习实现舆情风险等级划分。

图3 智能舆情监控算法框架
2.1 CBOW词向量模型
词向量模型通过智能算法将文本非结构化数据转化为矩阵等结构化数据。传统的词向量模型采用独热表示法(One-Hot Representation),该方法仅能表示词语在文本中出现的次数,而无法保留原始文本结构中所蕴含的信息,且高维度向量的表示方式大幅降低了求解速度。CBOW 模型是一种改进的分布式文本表示模式,其利用上下文词语信息预测目标位置词语的概率分布,故可较为完整地保留上下文语义。因此,CBOW 模型在繁杂文本的挖掘中应用广泛[14],其模型如图4 所示。

图4 CBOW词向量模型
假设i为目标位置,b为目标词语,集合Z由b的所有可能取值构成。则原始文本前后n个词语,可表示为:
式中,bi+1为目标位置的后一个词语,其余变量定义同理。则输入文本向量x为:
式中,e(bj)为词语bj的词向量。则目标词语b为b′的概率分布如下:
式中,e(b′)是目标词语b为b′时的词向量。若整个文本库表示为A,则CBOW 模型的最终优化目标G为:
2.2 注意力机制
注意力机制是模拟人类大脑在搜寻信息时聚焦重要的部分,而忽略不重要的部分,从而高效完成任务的模式[15-16]。其应用于自然语言处理中可理解为由n个词语构成的输入x=[x1,x2,…,xn],在某个查询任务r下,索引位置γ=i分配的注意力系数,具体可表示为:
式中,f(xi,r)为注意力分配函数。其可表示如下:
式中,U、V和W为可优化的网络参数,q为位置参数。
进一步计算输入文本x的所有分词向量加权和,该权重即为分词的注意力系数:
最后将式(7)作为注意力机制的输出,可以看到对于查询任务r而言,越重要的分词,权重系数越大,其对注意力机制的输出结果影响也越大。注意力机制可看成是基于信息选择机制对输入文本向量x进行的一次编码。
2.3 融合多维注意力机制的算法
融合多维注意力机制的舆情监控算法架构,如图5 所示。输入文本向量x经过多维注意力机制计算,可得到前后向的句子特征ξq(x,xj)、ξh(x,xj),再通过句子特征获取层及最后Softmax 层得到舆情风险等级。

图5 舆情监控算法设计
该文在注意力计算中引入位置信息,改进后的注意力分配函数为:
式中,λ为偏置参数,Q为与位置信息相关的参数。
将 式(8)代入式(5)和 式(7)可计算得到ξq(x,xj)、ξh(x,xj),并进行拼接操作。进而获得总分词特征向量,其规格为m行2n列,具体公式为:
句子特征获取层对拼接后的特征矩阵按列求取平均值,以得到句子特征向量:
式中,si为句子特征向量第i个元素值。故句子特征向量为:
最后,利用Softmax 层计算得到舆情风险等级:
式中,y为舆情风险等级;Ω为整个模型的网络参数集合;W′和b′分别为Softmax 层的连接权重与偏置。
上述舆情监控算法通过语料集B 进行学习训练,并利用反向传播算法(Back Propagation,BP)优化网络参数Ω,使得以下损失函数最小:
2.4 模型评价指标
文中采用F1 值评估舆情风险监控模型的性能:
式中,P和R分别为准确率与召回率,α是调制系数。
3 算例分析
从互联网爬取的正负向文本各一万条,并按4∶1的比例划分为训练集与测试集,再将其作为该实验数据集进行仿真验证。
3.1 CBOW模型性能分析
为了使CBOW 模型的准确率最高,以不同词向量维数进行训练,得到的准确率如图6 所示,当词向量维数为200 时,CBOW 模型的准确率最高,达到了95.6%。因此,该文所有实验中的词向量维数均取为200。

图6 不同词向量维数的准确率
CBOW 模型与n元模型(N-Gram)、神经网络语言模型(Neural Network Language Model,NNLM)的性能对比,如表1所示。由表可知,CBOW 模型在处理网络舆情文本信息时,具有更高的计算速度与准确率。

表1 词向量模型性能对比
3.2 舆情风险识别效果分析
将该文所提MDAN 模型与卷积神经网络(Convolutional Neural Networks,CNN)、长短期记忆网络(Long Short-Term Memory,LSTM)进行对比验证,结果如表2 所示。
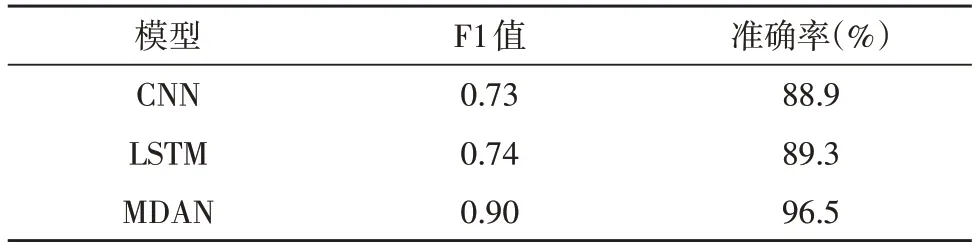
表2 算法模型性能对比
从表中可以看出,在网络舆情风险监控方面,CNN 及LSTM 模型的性能相差较小,而文中所提MDAN 模型明显优于二者,且舆情风险等级识别的准确率可达96.5%。
3.3 应用效果分析
将所提算法应用于某企业实际网络舆情监测,连续30 天内的舆情风险等级如图7 所示。由图可知,在第9 天时舆情风险等级提升至第II 级。这是因为该企业发布重大决策引起网络舆论关注,故相应舆论风险等级得以提升[17-19]。随着关注度的下降,风险等级也逐渐降低,最后恢复至正常等级,且因该事件引起网络的关注持续了约1 周时间。

图7 舆情风险等级评价
4 结束语
该文利用网络爬虫技术获取网络舆情信息,并提出了一种融合多注意力机制模型实现对舆情信息的分析处理。通过仿真分析表明,所提的CBOW 模型相比于N-Gram 和NNLM 模型在处理网络文本方面具有更高的准确率及更快的计算速度;而所提的MDAN 模型相比于CNN 与LSTM 模型,在舆情风险等级预测上具有更优的准确度;所提智能舆情监控算法则在实际应用中能够准确监测舆情事件,并为企业的及时应对处理提供技术指导。但文中未能实现舆情风险的分类,这将在下一步研究中展开。
