基于集成深度学习的培养评估大数据分析与跟踪算法
2023-11-10高晓梅张永红
高晓梅,张永红
(西安航空职业技术学院,陕西西安 710089)
毕业生的就业质量受到诸多因素的影响,但传统的问卷方法无法分析众多变量间的复杂关系[1-3],且严重依赖人工,进而造成了额外成本。因此利用集成深度学习算法(Integrated Deep Learning,IDL)来构建毕业生就业质量预测模型[4],研究一种可自动分析文本,并高效、准确地提取到文本评价内所包含的方面项与情感极性的学习算法,不仅能节约因手动理解、统计文本内容而带来的人力成本,还对高校教育的改革优化、提高人才培养质量具有重要意义。
该文基于集成深度学习中的方面词抽取(Aspect Term Extraction,ATE)及情感极性分类(Affective Polarity Classification,APC)联合学习模型LCFATEPC,针对文本信息展开了多方面话题的情感分析(Sentiment Analysis)。在以往的情感问题研究中,主要关注提升的是情感极性分类子任务的精度,而忽略了对于文本方面项提取的研究。LCF-ATEPC克服了上述问题,并在模型内部集成了面向文本情感分析的局部上下文聚焦与BERT(Bidirectional Encoder Representation from Transformers)机制。通过对少量的评价方面项及其极性的标注数据进行训练,最终实现了在大规模数据集中的自动提取并预测情感极性。
1 算法模型设计
1.1 框架设计
就业质量预测研究框架如图1 所示。
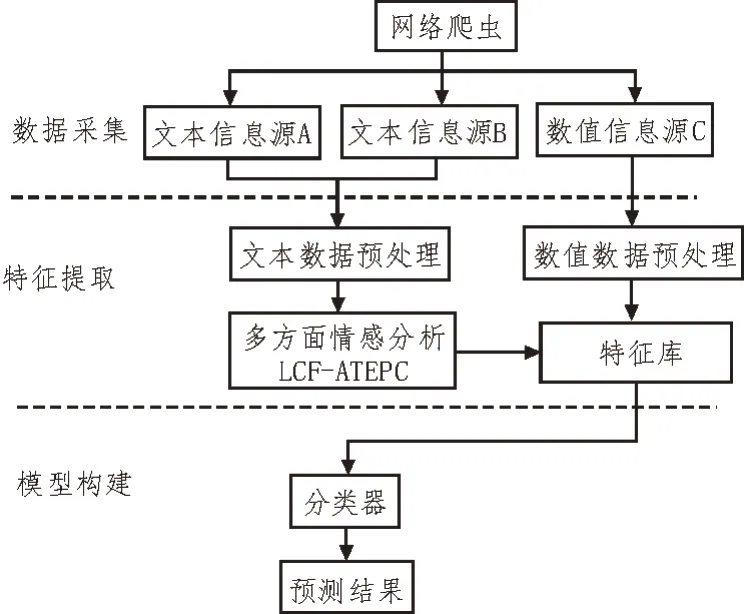
图1 就业质量预测研究框架
该文在上述研究框架的基础上进行以下工作:
1)数据爬取。针对研究主题的对象,对多源头媒体文本信息进行广泛收集。尽可能爬取到各媒体源下的不同立场、状态与人群的评论文本,从而使本模型内的方面项提取任务所得到的结果更加充分、全面。除了对文本数据的采集外,同时还挖掘研究主题的相关数值型数据,以确保输入的特征更加丰富,并使预测结果更为准确。
2)数据预处理。预处理工作主要聚焦于对评论文本进行多方面的话题情感分析,其主要依赖于LCF-ATEPC 模型进行处理。
3)模型训练与评估。通过建立深度学习模型,基于数据集进行大量的训练操作,并不断修改模型参数,从而适配此次所要评估的内容。最终的评估指标,可辅助进行不同模型的效果评价。
该研究主要有两个支撑模型:
1)采集文本数据的LCF-ATEPC 多方面情感分析模型。在情感分析过程中,基于网络上爬取得到的多数据源文本数据,对文本内包含的不同方面项进行挖掘。进而为后续情感极性分类提供人工理解的粒度,且打破模型输出结果的黑盒效应。
2)最终的目标预测模型。LCF-ATEPC 负责挖掘评论文本中所包含的方面项与情感分数。第二个预测模型将LCF-ATEPC 产出的方面项及情感分数作为部分特征,与数据采集阶段得到的数字化数据共同作为特征,输入模型便可得到最终就业质量的预测结果。
1.2 多方面话题情感分类
情感分析是指通过处理带有主观性的文本或观点,挖掘出包含态度、情感的一种计算研究[5]。文本的情感分析并非是仅基于正负性质,也可在其他维度或是多维度上进行[6]。文档级、语句级和方面级是研究者进行情感分析研究的三个主要粒度级别[7]。其中,方面级的情感分析在对文本的挖掘与处理上更为细腻,其任务主要是由实体提取、方面项提取及方面项情感分类这三个子任务组成的[8]。
由于长短期记忆网络(Long Short-Term Memory,LSTM)算法在处理上下文语义关系方面的表现较为优秀,近年来诸多学者提出了基于LSTM 变体的深度学习网络[9-13]。但由于对同一目标特征,不同句子、不同语境词会给token 的情感带来截然不同的影响,所以方面级的情感分析始终具备难度。为了提高模型的分析效果,文中搭建了一个拥有两个独立BERT层的多目标学习模型[14],同时完成方面级情感分析的方面项提取与情感极性分类两个子任务。在模型训练的过程中,通过两个子任务的交互,使得模型整体在方面项抽取及情感极性分类上表现更加优异。
1.3 LCF-ATEPC模型
方面级情感分类主要采用神经网络(Artificial Neural Network,ANN)算法解决。基于注意力的深度学习系统,已被证明是一种较为理想且可用于方面级情绪分析的方法论[15-16]。LCF-ATEPC 模型在处理文本分析任务中,将ATE 与APC 两个子任务相结合。再针对文本内全局与局部上下文,采用两个独立的BERT 层,即BERT-BASE 和BERT-SPC 分别进行训练。LCF-ATEPC 的算法结构如图2 所示。
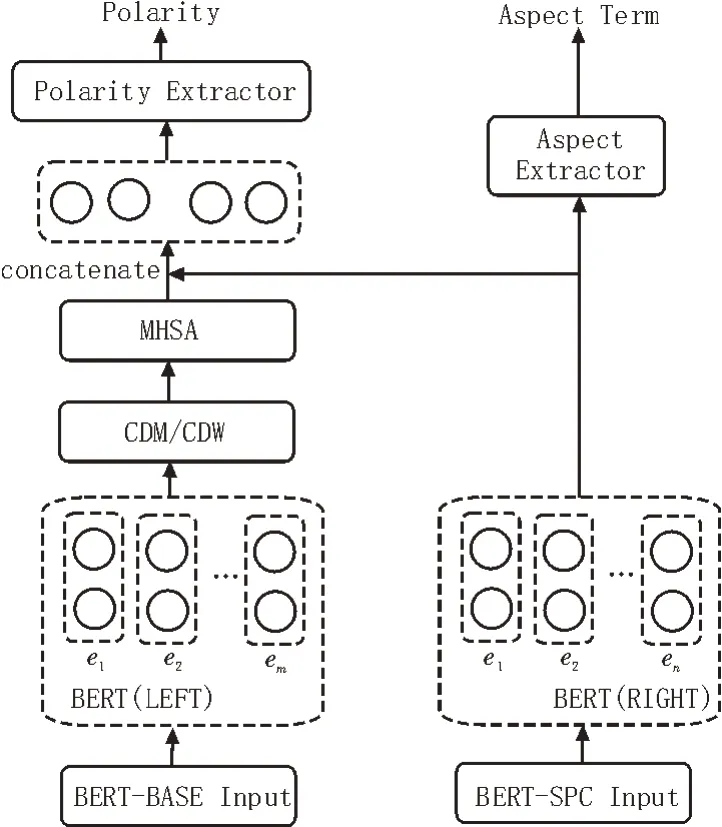
图2 LCF-ATEPC的算法结构
在模型内,输入序列中的每个词汇均被标记为两个不同标签:1)是否为方面词;2)标记方面词的情感极性。图2 左侧的LCF 结构通过CDM/CDW 及一个MHSA(Multi-Head Self-Attention)提取局部上下文特征。右侧的ATEPC 结构负责学习全局上下文特征。特征交互学习层则结合局部与全局上下文特征之间的交互学习来预测情感极性,并基于全局上下文特征提取方面项。
图3-4 是两个上下文焦点机制的实现,分别是特征动态掩码层及动态加权层。图的底部是每个token 的特征输入,顶部则是token 的输出位置。箭头表示在自我注意力机制下token 对箭头位置的贡献。其中,图3的箭头指向位置特征会被掩盖;而图4指向的特征将会加权衰减。
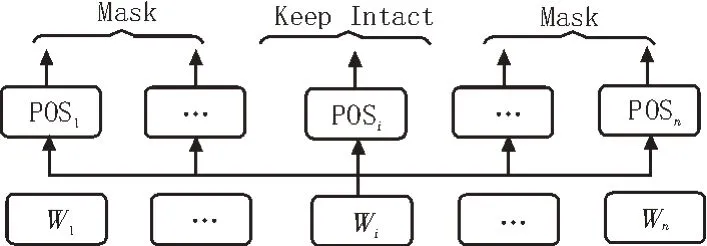
图3 特征动态掩码层

图4 特征动态加权层
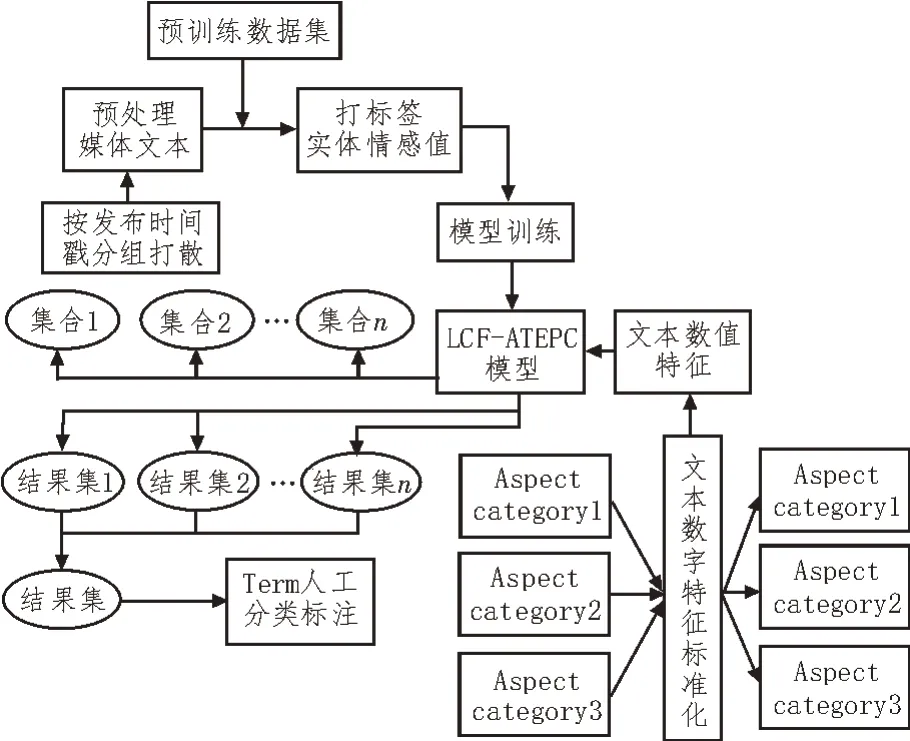
图5 数据特征实验设计流程图
在情感极性分类时,ATE 模型首先对token 进行分类,假设Ti是T对应位置上的特征,则有:
其中,N是token 的类别数量,Yterm表示模型推论的token 所属情感类别。
在APC 过程中,模型对抽取到的上下文特征进行POOL 池化。池化提取输入文本序列首个token 相应位置的隐藏状态,然后进行Softmax 运算,预测token 所归为的情感极性。
2 实证分析
2.1 特征处理
实验过程中的数据特征处理步骤,如5 所示。
在完成数据清洗后,对爬取的文本数据进行去停用词等预处理,并按发布时间戳进行分组。在模型训练阶段,选用方面项及情感值预达标的评论数据集训练LCF-ATEPC 模型。保存好最优模型后,将已按时间戳分组好的文本数据输入至预训练的最优模型,并输出提取后的方面项及情感极性。文中在梳理影响毕业生就业质量的相关文献后,将方面项纳入预先已进行人工分类的主体维度中,进而得到主体维度下方面项的情感极性,再进行标准化处理以得到情感得分。
数据采集阶段所获取的数值型数据,在ATE任务得到的主体维度下分别进行聚合处理[17-18]。将情感得分与数值型数据输入至机器学习模型中进行满意度预测训练,并根据评价标准比较模型的预测误差,从而确定最优模型。同时将不同情感分析深度学习的最优模型输入特征按特点加以分组,且分批次输入。最终考虑不同算法与不同特征集对模型预测结果的作用,进而证明LCFATEPC 算法的有效性与将媒体文本纳入预测的可行性、重要性。
2.2 实验预测
在LCF-ATEPC 算法识别到多方面情感后,得到了方面项及与其对应的情感极性。从刻画就业质量的因素出发,为多方面情感分析得到的方面项找到了对应的主体。对于数值型特征数据,则在主体维度下进行统计学求和及最大-最小标准化处理。最终把不同主体维度下情感倾向得分、对口度与落实率等数值特征分别加入不同机器学习模型中进行训练。
在预测模型中,选取了线性回归(Linear Regression,LR)、支持向量机(Support Vector Machine,SVM)、随机森林(Random Forest,RF)及XGBoost(eXtreme Gradient Boosting)等较为有效的机器学习算法进行训练。
为了对各个模型准确度做出有效评价,采用了预测误差对模型效果进行量化。其中,均方根误差(Root Mean Squared Error,RMSE)是对真实值与估计值差的平方的数学期望计算其算术平方根。若N为样本个数,则其计算方式为:
决定系数R2 是指可相互以直线关系来说明的部分所占的比重,计算公式如下:
其中,SESS为回归平方和,SRSS为残差平方和,STSS为总体平方和。
2.3 实验结果
XGBoost 是一种改进的梯度提升算法,在Gradient Boosting 框架下提供并行树且进行分布式运算优化。由输入数据的性质,进一步将模型输入特征按数值型数据与媒体信息分为不同特征集,再分别传输至XGBoost 中,进而研究不同特征集的影响程度。将提取到的特征输入至不同模型内,由表1可知,输入不同特征,LCF-ATEPC 的多方面情感分析效果为最优;在输入相同特征的情况下,XGBoost模型的预测效果最佳。

表1 不同机器学习算法预测效果
根据结果可知,数值型特征数据与社交媒体文本数据均具有提升预测准确度的作用。通过表1 可以发现,基于梯度提升的XGBoost 算法的预测效果R2 指标值达到了0.927。因此,该文选择将提取到的特征数据输入到XGBoost 机器学习模型中,再进行后续针对不同特征集的预测,所得结果如表2 所示。

表2 不同特征集预测效果对比
由表2 可知,在纳入LCF-ATEPC 算法提取到的社交媒体数据后,该文算法预测结果较传统方法提升了3.58%,故预测更为准确。由此说明了LCFATEPC 算法的有效性,更凸显了将媒体文本纳入预测的可行性与重要性。
3 结束语
高校就业质量是现今社会关注的重点问题,但传统的问卷方法无法分析诸多变量间的复杂关系。为此,该文建立了一种联合学习模型LCF-ATEPC,由于该模型集成了局部上下文聚焦与BERT 机制,通过子任务交互的方法,使得模型整体在方面项抽取及情感极性分类上的表现更为理想。在实验过程中,通过对社交媒体上文本数据的多方面情感分析,拓宽了特征提取的角度。从建模实验的结果来看,加入LCF-ATEPC 算法的特征后,模型的表现与结果均有了进一步提升,因此可以将其应用于实际工程中。
