决策树模型在基于外显属性预测市场状态中的应用
2023-11-07蒋丽雯张革伕王雄峰魏俊蓉
蒋丽雯,张革伕,王雄峰,魏俊蓉
(1.衡阳市烟草专卖局(公司),湖南衡阳 421001;2.南华大学经济管理与法学学院,湖南衡阳 421001)
0 引言
我国烟草生产量和销售量占全世界的35%,是烟草生产大国,也是消费大国。烟草税收是我国国民经济重要来源之一,占全国总税收收入的7%。近年来,随着“Z 时代”变为消费主力,原有群体的健康消费理念的起伏,烟草消费市场同样呈现出多样化,许多品牌卷烟生产企业倾向于研发新品规香烟来应对复杂多变的市场环境。2012至2017年,卷烟行业共有673个新品上市[1],到2018 年的卷烟在销品达千个,但其中有近半数的卷烟品规并未受到消费者的欢迎,年销售量仅在千箱以下的有相当一部分是新开发的品规。这种情形对于零售商和商业企业构成了巨大的库存负担,最终影响到烟草工业企业的开发生产。国家烟草局提出,要充分应用行业数据来评估品规市场状态,实施精准市场投放。本文试图通过对卷烟品规的外显属性特征进行分析,寻找其与品规的市场状态之间的关联性,从而帮助相关企业在品规采购、品规开发设计决策上快速做出优化,减少损失。
1 文献综述
随着数据在企业运行过程中积累越来越多,数据逐渐被认为是企业新的资产而加以利用,数据挖掘技术应时而生。数据挖掘作为新兴的信息处理技术逐渐被应用于各行各业,就是要从“看似无益的数据堆中找出有价信息”的过程,如在税收领域可用来寻找逃税漏税者,证券领域可用来识别老鼠仓,教育领域可用来发现行为异常者。烟草行业也有大量的应用,包括用来优化卷烟仓储、物流和营销等[2]。数据挖掘技术通常包含一系列的数据分析算法模型,例如决策树、关联规则、聚类、神经网络、回归、支持向量机等,所谓的大数据分析技术也以这些算法模型为基础。限于本研究仅采用决策树技术,在此仅就决策树技术应用做介绍。
决策树算法常用于分类预测。张伟丰[3]提出了将决策树算法应用于卷烟产品零售客户分类中,从而根据客户重要性和产品依存度来制定更为合理化的卷烟营销策略。Salazar-Concha C 等人[4]通过决策树技术建立了捐赠者重复献血意愿的预测模型,准确性达到84.17%,预计可以降低联系希望献血人和血液管理系统的成本。Permana B A C等[5]通过决策树得出烦渴现象是糖尿病患者发病迹象的主导因素,分析了该因素对疾病的预测价值,可以帮助医生更快地进行诊断和分析疾病。Yunmeng Zhang[6]等人运用决策树算法来预测和分析两种类型员工的营业额,管理者可以依据实验结果制定相应的管理措施。构建决策树常用的算法有:CHAID、CART、QUEST、ID3、C4.5和C5.0算法等。邹黄刚等[7]用ID3决策树算法来设计一种新型汽车故障检查方案,查找出何种因素引起的汽车故障,使驾驶员自身具备故障检查能力,并做出相应的预检修,大大节约时间与成本。徐蕾等[8]在探讨基于信息熵的决策树在慢性胃炎中医辨证分型中的应用中,采用基于信息熵的决策树C4.5算法建立中医辨证模型,产生了可用于分类的诊断规则。蒋丽雯等[9]构建了一个两阶段卷烟市场状态评价模型,第一阶段用决策树C5.0算法进行“俏、紧、待评”三态分类,然后再用C5.0对“待评”态进行“平、松、软”三态分类预测。
将决策树算法和其他算法进行组合,形成更为精准和有效的分析模型也应用广泛,在此不再进行介绍。
2 决策树算法原理
决策树算法是一种机器学习模型,是一种导师监督的机器学习模式,保证每次学习都能比原来做得更好。有监督学习是一种从实例中学习的方法,导师能够凭借自身掌握的知识对实例中样本进行分类,学习者可以利用导师分类好的实例进行学习,总结并导出其中的决策规则。导师分类决策的结果称之为目标变量值,样本的其他属性称之为输入变量。决策树算法通过归纳和提炼现有数据中目标变量和输入变量的取值规律,以树形结构的形式展示实例的分类规则。
一棵决策树可以划分为节点和有向边两部分,节点分为三种:根节点、内部节点与叶子节点。根节点是位于决策树第一层的节点,包含了所有的样本。内部节点代表着样本中的某个属性,叶子节点则表示实例划分到最后的决策结果。有向边表示从决策树的根节点到叶节点的一条路径,对应着一条取值规则。一棵决策树如图1所示。

图1 决策树模型
ID3 算法作为决策树的最典型模型,采用所谓的启发式学习法,以信息增益率来确定最佳的分组变量和分割点。
基本问题描述:一个数据集可分为训练集和测试集两个实例集,每个实例属于一个特定的类型即分类,训练集用于学习以生成分类模型,测试集用来检测模型的分类效果。数据集包含一组可供分割的属性,每个属性的取值可把训练实例集划分为多个子集。每个属性就是对实例进行分类的可选影响因素。定义如下:
选择属性集A={A1,A2,…,Ai,…,An}
选择的检测属性设为:Ai
Ai的值域V(Ai)={V1, …, VS}的S 个取值把训练实例集T分为S个子集如式(1)。

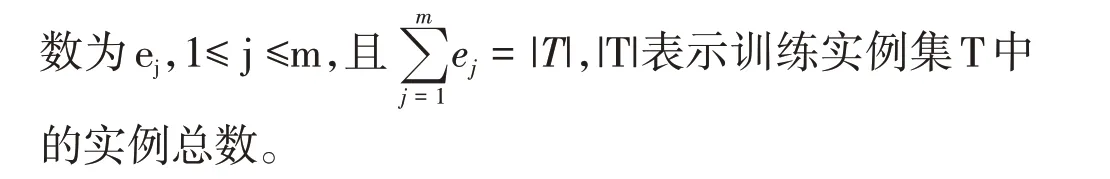
实例分类结果为Cj的概率为式(2)。
定义训练实例集T 的实例平均信息量由式(3)决定。
子集实例数与实例总数关系满足式(5)。

选择属性作为检测属性的原则是:属性Ai的不同取值把实例集划分为若干子集之前和之后的实例平均信息量差值最大的那个,即挑选式(7)取最大值的属性。这就是启发式规则。
GI(T,Ai)可认为是属性Ai对训练实例集T的信息变化量,熵总是朝大的方向增加,故称之为熵增益原理。因此,启发式规则实际上是选择信息量最大的属性作为检测属性Ai来划分实例集,从而达到分类的目的。C4.5 和C5.0 都以ID3 算法为基础,做了改进和优化。
IBM SPSS Modeler 从SPSS 旗下的Clementine 而来,因后者被IBM公司收购,而改名为IBM SPSS Modeler。Clementine 最开始由SPSS软件开发的部分人员脱离出来,以开发专业的商业智能软件,旨在对海量数据进行商业洞悉,挖掘数据价值。Clementine 提供了大量的算法模型,例如决策树、C5.0、Apriori、KMeans和神经网络等,通过数据流图来完成建模,并进行可视化输出。本文将利用该工具建模,完成从卷烟品规外显属性特征来预测其市场状态。
3 卷烟的外显属性特征与品规市场状态
卷烟的外显属性是指卷烟品规的外部包装显示出来的卷烟结构特征,这种特征无需烟民实际品吸感受后形成认知,而是实际存在的物理特征,对所有人的感知无差别。这些外显特征包括如下:
1)品牌名称(品规,实际上为包含一定的子品牌和规格特征合成称呼,例如:云烟小熊猫家园);省内外(分省内品规、省外品规);类型(分烤烟型、非烤烟型);
2)焦油含量(实际由机构测定,外包装上注明);一氧化碳含量(实际由机构测定,外包装上注明);烟气烟碱量(实际由机构测定,外包装上注明);
3)长度(异型烟的参数之一,标准为84cm);过滤嘴长(异型烟的参数之一,标准为25cm);
4)包装类型(软、硬两种);包装主色调;包装副色调;
5)烟支数(20支为标准,其他数量为异型);零售价(单位元/盒)。
品规的市场状态以国家烟草总局发布的要求为依据,各地根据卷烟品规的市场表现来评估,参考品规的订购频率、覆盖面等指标,分为“俏、紧、平、松、软”,反映出消费者的接受度,是烟草商业企业采购卷烟和投放卷烟的依据。蒋丽雯等以衡阳地区销售的卷烟为研究对象,就销售的190多种卷烟品规进行了市场状态评估,本文研究的卷烟同样为衡阳烟草,将以这些状态数据为导师,应用决策树模型,基于卷烟品规的外显属性特征来预测其可能状态。也就是看卷烟外表来预判卷烟在消费者中的接受情况。本研究所采集的卷烟品规外显属性特征数据如图2所示,用Excel文件形式作为数据源,右边最后一列为市场状态,最开始将利用文献给出的状态值作为导师,交给模型学习。
4 基于SPSS Modeler C5.0的预测模型
本研究模型的构建包含三个阶段:数据准备、数据预处理和建模。
4.1 数据准备
本文使用的卷烟外显属性特征数据通过相关烟草网站和烟草局查询获得,对应的卷烟市场状态根据相关领域蒋丽雯等的研究所得。研究数据集包含湖南省在销的45个大品牌、191个香烟品规的外表特征值记录,每条记录的属性包括上文所交代的14个。
4.2 数据预处理
在实际业务中所采集的数据往往是脏数据,所谓的脏数据是指数据中出现数据缺失、数据噪声、数据冗余、数据集不均衡和离群点等问题。这需要进行处理,否则可能产生运算异常,影响准确性。

图2 卷烟品规外显属性特征数据集
1)数据空缺值的处理。其处理方式主要有直接删除含有缺失值的记录和补全缺失值两种。对于原始数据集中部分雪茄型香烟的焦油含量、一氧化碳含量和烟气烟碱量缺失,本文通过其他雪茄烟的特征经验推导出来。对于零售价字段的缺失,本文通过获得的单支雪茄烟价格和每盒支数进行简单运算得到。
2)分类属性值较繁杂的数据。收集的原始数据集包装主色调和副色调颜色类型繁杂,在建立决策树中可能会造成“过拟合”的现象,对预测结果产生不良的影响,所以需要化繁为简。根据相同色系聚集的方法,将包装主副色调重新进行简化分类,主色调分为白、黑、红、黄、蓝、棕六种颜色,副色调分为白、黑、红、金、蓝、绿、棕七种颜色。
3)异常值处理。异常值也称为离群点,指其数值明显偏离样本其余观测值。在进行异常值处理前,首先要辨别出异常值。在SPSS Modeler 软件中,可以利用“数据审核”节点对异常值进行辨别和处理,如针对焦油含量、一氧化碳含量、烟气烟碱量、长度、过滤嘴长、零售价和烟支数这些连续型变量,选择四分位差方法对异常值进行判断。同样的方法,可处理极值、离群值,如图3所示,在“质量”窗口对离群值进行“强制替换离群值/丢弃极值”操作。之后,数据集删除了9条记录,剩余182条记录。
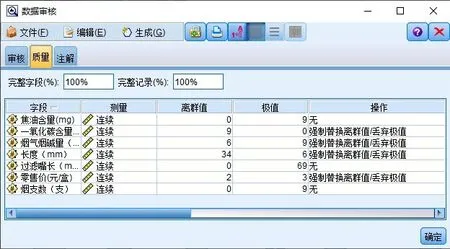
图3 异常值处理操作
4)数据规约
本文所采集的数据中存在大量离散数据,例如焦油含量、一氧化碳含量、卷烟长度等,对这些数据值进行规约,进行分级处理,有利于统一认识。在SPSS Modeler针对数据离散化处理问题,提供了包括固定宽度、分位数法、等级法、平均值、标准差法和最优法等分级方法。本文应用三分位数法对一氧化碳含量、焦油含量和烟气烟碱量进行分级,分成高、中、低三级。
4.3 预测模型
在SPSS Modeler 18.0 版本软件中,建立数据流,形成基于卷烟品规外显属性特征的市场状态预测决策树模型,决策树算法使用C5.0,如图4所示。
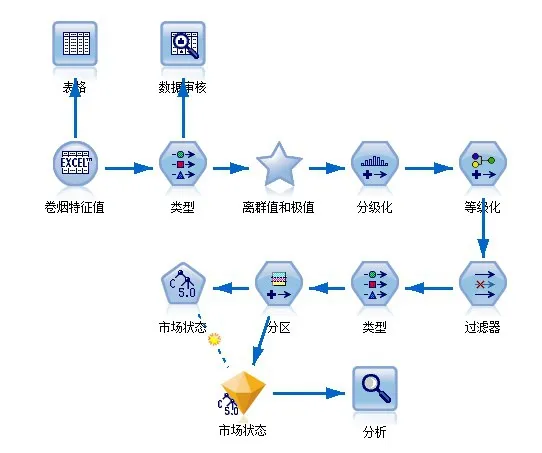
图4 基于决策树的品规市场状态分类模型
在上述数据流图中,包含数据源Excel、输出观察表格、数据审核超级节点、分级化、等级重新分类、过滤器、分区、C5.0模型、生成模型应用及模型效果分析等11种节点。将运行后生成的决策树模型与“输出”选项卡中的“分析”节点连接,可以得到预测正确率,从而评估模型预测效果。
5 研究结果与分析
本研究设置的样本数据训练集合测试集比例为7:3,设置修剪置信度为75,每个节点允许的最小样本量为3,决策树模型的准确性可达到87.91%。
图5 为决策树模型的规则输出图,影响卷烟市场状态重要的因素依次有:包装主色调、省内外、一氧化碳含量、长度、焦油含量、零售价、包装副色调,其中包装主色调相对于其他因素来说更为关键。烟气烟碱量、过滤嘴长和包装类型这三个属性由于在剪枝过程中被剪掉,没有进入决策树,因此香烟烟气烟碱量、过滤嘴长和包装类型对卷烟市场状态评价的影响很小。
图5 决策树模型运行结果
实际在Modeler 中,决策规则集可转换为一棵相应的决策树,如图6所示,只实现了部分决策规则。
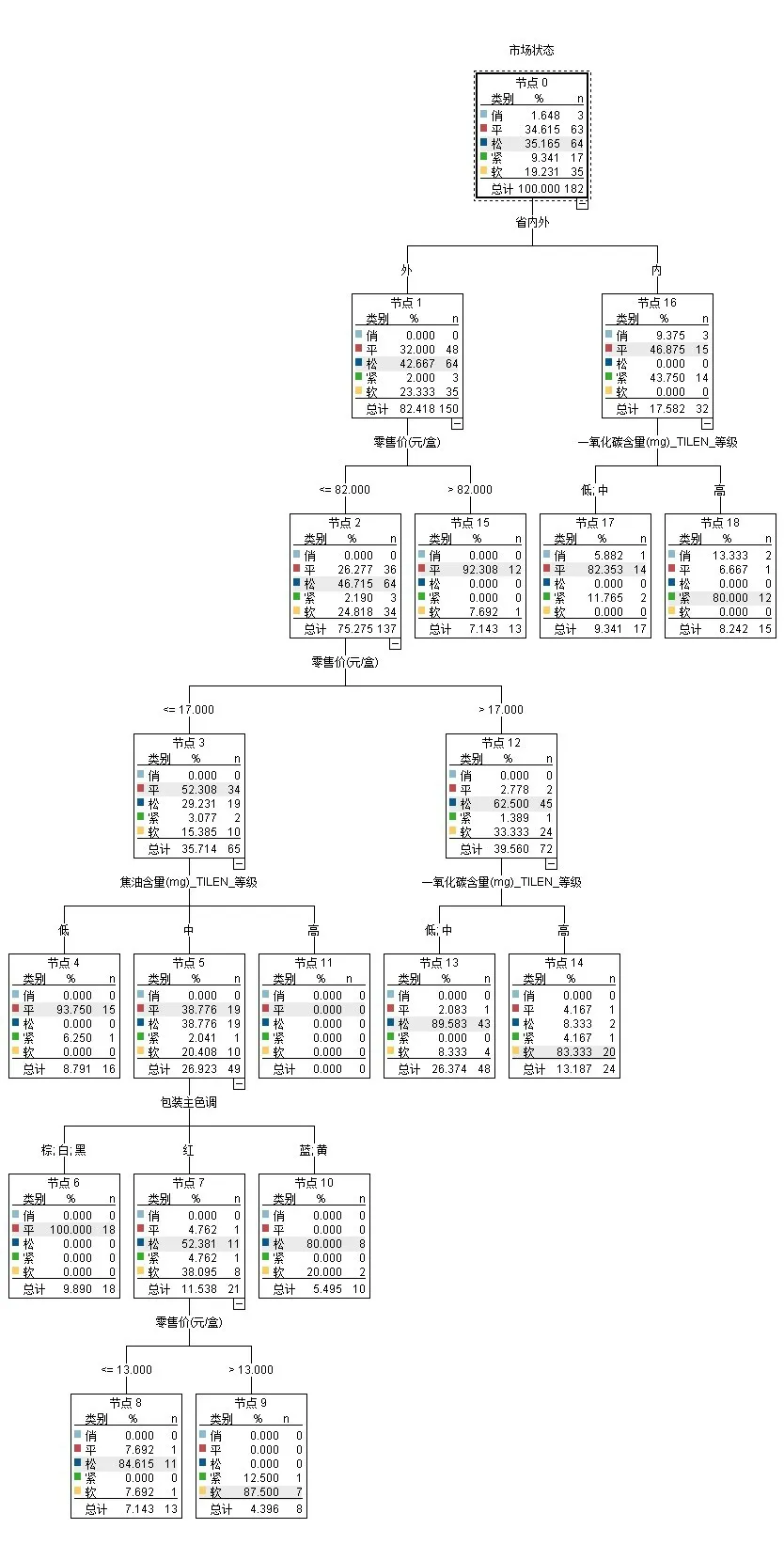
图6 卷烟市场状态的决策树模型
下面来解释所得到的有价值的分类预测规则集,如表1所示。所谓有价值是指置信度在一定范围内的规则,例如80%~95%,剔除100%的过拟合嫌疑情形。分类规则4很有意思,“如果一款香烟属于湖南省外,零售价格>82元,则其市场状态为‘平’”,置信度大于92%,十拿九稳,外省的昂贵烟在湖南几乎卖不动。

表1 部分预测规则集
“分析”节点展示了模型的效果,表明:训练样本中预测正确的记录有105 条,预测错误的记录有17条,训练样本正确率约为86.1%。测试样本中预测正确的记录有49条,预测错误的记录有11条,测试样本正确率为81.7%。
6 结束语
从卷烟品规的外显属性特征来预测其市场接受度,或者预估卷烟的采购量与投放量,可比针对消费者的大量市场调查来得更简单,成本更低。构建的决策树模型,以卷烟品规的外显属性特征数据为输入,以卷烟市场品规状态为分类输出,通过学习已有的品规市场状态评价训练数据,可以让预测输出变得更有效。研究表明,卷烟品规的部分外显属性特征对消费影响很小,影响最大的除了工业企业属地属性,还包括包装主色调、一氧化碳含量等属性。预测的置信度达到了8成,模型具有较强应用可行性。当然模型受数据量限制,机器学习深度有限,下一步可直接让外显特征与其销售投放数据结合,数据学习量可达到千万级以上,相信可获得更加准确的预测效果。
