基于卷积神经网络的岩爆烈度等级预测
2023-11-06李康楠吴雅琴王乙桥
李康楠,吴雅琴,杜 锋,张 翔,王乙桥
(1.中国矿业大学(北京) 共伴生能源精准开采北京市重点实验室,北京 100083;2.中国矿业大学(北京)应急管理与安全工程学院,北京 100083;3.中国矿业大学(北京) 机电与信息工程学院,北京 100083)
深部脆性岩体受外界扰动影响,发生动力失稳现象致使其内部弹性能极速释放,从而导致岩体碎片弹射、抛掷与剥落,同时伴随不同程度的爆炸声响等现象,称为岩爆地质灾害[1-3]。岩爆灾害发生的影响因素多,不确定性大,严重干扰现场作业的有序进行;岩爆灾害危险性大,一旦发生中等、强烈岩爆,往往会造成一定的人员伤亡和巨大的经济损失。随着地下岩土工程逐步加深,岩爆灾害事故日益增多,高效准确的岩爆烈度等级预测方法研究迫在眉睫[4-5]。
国内外学者对岩爆烈度等级预测方法的研究大致可分为判据预测方法和综合分析预测方法2 种[6]。判据预测方法首先会确立岩爆烈度等级的单因素分类标准,然后将预测区域该因素的数值大小与预定标准进行对比,从而预测岩爆的烈度等级,如:Russenes[7]与Hoek[8]与二郎山[9]应力系数判据、Turchaninov[10]判据、Kidybinski[11]与Singh[12]岩爆倾向性指数判据、N-Jhelum[13]判据、Aubertin[14]改进脆性指数判据、Wang[15]最大储存弹性应变能判据、陶振宇判据[16]等。岩爆诱发因素众多,单因素很难全面揭示灾害发生规律,且各因素之间可能存在相互耦合的现象,故仅以单因素判据预测岩爆灾害缺乏可信度。因此,越来越多的学者采用多因素分析预测方法进行综合研究,以期通过数学方法、机器学习与智能算法达到准确预测岩爆烈度等级的目的。传统数学方法如贝叶斯模型[17]、功效系数法[18]、支持向量机[19]、决策树[20]等虽应用广泛,在一定程度上提升了岩爆烈度等级预测的准确率,但存在一些方面的缺陷:在确定指标权重与定性因素方面受人为主观影响严重,很难客观预测岩爆烈度等级;影响因素之间相互联系、共同作用,预测过程往往忽略非线性因素。为弥补上述缺陷,国内外学者展开机器学习与智能算法领域的研究,如SVM (Support Vector Machines)模型[21]、IPP-PNN(Improved Projection Pursuit-Probabilistic Neural Networks)模 型[22]、PCA-PNN(Principle Component Analysis-PNN)模型[23]、PCA-RBF(PCA-Radial Basis Function)[24]模型等,进一步提高了岩爆烈度等级的预测精度,但存在两方面的局限性:所需训练样本量与计算权值量大,导致模型复杂程度提高与运算时间延长;需要配合数据降维方法进行模型训练,易丢失重要的数据信息从而影响模型预测的准确度,故需要继续深入研究并探索新的预测方法。
深度学习算法卷积神经网络(Convolutional Neural Network,CNN)具有局部感知与权重共享的优点,能够极大减少连接权值的数量并降低模型复杂度,挖掘线性与非线性数据深层次的特征规律与数据之间的内在联系;无需配合额外的分析法即可降低多重共线性并提高模型的泛化能力,在短期电力负荷预测[25-26]、短时交通流预测[27-28]、电厂存煤量预测[29]与煤层底板突水预测[30]等方面都具有强大的功能。考虑到数据缺失使训练样本减少从而导致模型准确率降低的问题,笔者选用链式方程多重插补(Multiple Imputation by Chained Equations,MICE)法对空缺数据进行填补[31-33]。该方法能够通过表达数据的不确定性并进行综合分析,得到更加可靠与精确的插补结果。基于MICE-CNN,选取120 组典型岩爆案例现场数据,通过参数优选、数据处理与网络训练建立模型,并与RBF、SVM、PNN 模型的预测结果进行对比,期望得到更加可靠有效并利于工程实际的岩爆烈度等级预测模型。
1 岩爆烈度等级预测模型建立流程
基于CNN 的岩爆烈度等级预测模型建立流程如图1 所示,模型的建立主要分成4 个步骤。第一步,列举并选取岩爆灾害的影响因素,通过综合分析建立契合本预测模型的指标体系。第二步,搜集原始数据,对数据进行基于拉伊达准则的异常值剔除与基于MICE的缺失值插补,得到完整数据后进行数据集分割与数据转换,搭建CNN 的初始框架并进行训练,从而优选模型超参数,建立基于CNN 的岩爆烈度等级预测模型。第三步,输入现场数据进行验证模型准确度预测。第四步,建立基于RBF、SVM 与PNN 的岩爆烈度等级预测对比模型,输入相同数据进行预测,并与CNN模型比较预测结果,并观察预测结果的混淆矩阵,对比误判结果的倾向性,最终得到最优模型。
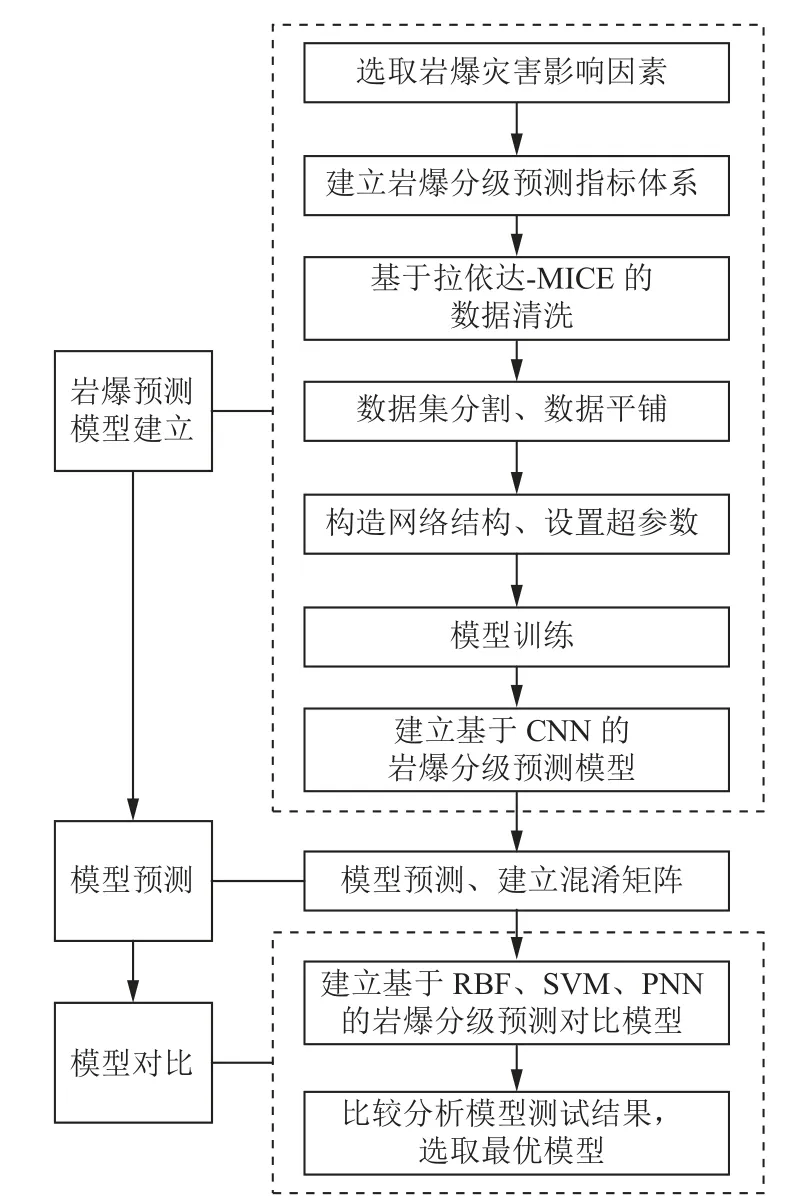
图1 岩爆烈度等级预测模型建立流程Fig.1 Flow chart for establishing prediction model of rockburst intensity grade
2 岩爆烈度等级预测指标体系
2.1 指标体系选取
本研究通过对国内外大量文献及矿井现场资料的查阅收集[7-9,14-16],得到了主流的岩爆分级标准与对应计算公式,详见表1。

表1 岩爆分级标准Table 1 Rockburst classification standard
岩爆灾害的发生与围岩特征、地质构造、地应力与外界扰动等因素密切相关[34-36],这导致了影响岩爆发生的因素众多,使指标选取困难。目前国内外尚无统一的岩爆烈度等级预测指标体系,但多数包含3~6 种岩爆判据或岩石力学参数。过多影响因素组成的预测指标体系既不易于获取,增加计算的冗余程度与预测时间,而且相关度小的因素数据离群点还会在一定程度上影响模型的学习与判断;过少的指标缺乏代表性,难以支撑灾害预测,从而导致预测结果出现较大偏差。由表1 的计算公式可以得到计算岩爆分类标准所常用的具有较好代表性的影响因素,在此基础上,考虑现场获取便捷,且能够全面反映岩爆特征信息等条件,最终选取硐室最大切向应力σθ、岩石单轴抗压强度σc、岩石单轴抗拉强度σt、岩体应力系数σθ/σc、岩石强度脆性系数σc/σt和弹性变形能系数Wet这6 种指标组成岩爆预测指标体系。
2.2 样本数据获取
基于本研究所建立的岩爆预测指标体系,通过现场实测、查阅资料等方式搜集岩爆烈度等级工程实例,得到120 组实际发生烈度的原始数据用来建立岩爆预测模型,部分数据见表2,其中,无、弱、中等、强烈岩爆4 种烈度等级分别用数字1、2、3、4 表示。

表2 部分工程实例原始数据[7-24]Table 2 Partial engineeri ng examples raw data[7-24]
3 基于CNN 的岩爆烈度预测模型
3.1 CNN 卷积神经网络
CNN 卷积神经网络的结构如图2 所示。

图2 CNN 网络结构Fig.2 Structure of CNN
1) 卷积层
卷积层线性抽取局部范围内的神经元信息与特征,然后运用非线性激活函数对神经元进行激活。卷积运算主要为2 个数值矩阵的变换运算,过滤器(卷积核)首先会选择每次移动的距离(步长),然后与输入矩阵进行对应的映射点积运算,运算结果组成输出矩阵(特征图)。假定在l层的卷积层有n[l]个滤波器,权重为K[l]∈大小为3×3,其中n[l-1]是前一层的过滤器数量。这些过滤器以[1,1]的步伐遍历整个输入特征图,卷积操作可用下式表达,输出特征Y[l]是:
式中:f(·)为激活函数;b为偏执项。
2) 池化层
池化层可降低模型过拟合并提高模型的泛化能力。常用最大池化法进行降采样,其表达式为:
式中:X为输出;α为乘性偏置;S(x)为降采样函数。
3) 全连接层 (Fully Connected Layers,FC)
全连接层能够将最后一个池化层所得到的特征图平铺为一条一维向量,从而将数据进行由高到低的维度变换,同时不丢弃任何有用的信息,其中每个输入通过一个可学习的权重连接到每个输出。
4) 损失函数层
损失函数可以表达模型预测值与真实值之间的不一致程度,损失函数与模型的鲁棒性是负相关,在模型的学习过程中起到一定的指导作用。本研究选用Softmax 损失函数[37]。
3.2 基于MICE 的数据预处理
1) 基于拉伊达准则的异常值剔除
在数据测量与记录的过程中存在人工操作不当、采动影响等产生的错误数据,剔除错误数据能够消除其对模型预测准确性的影响。对120 组原始数据的前4 列数据进行处理,设数据集qi(i=1,2,···,m),计算剩余误差vi,并计算标准偏差β,若某一值的剩余误差va(1≤a≤m)满足下式,则认为该值为异常值并予以剔除。
式中:qa为数据集中第a个数据;为数据集均值。
2) 基于MICE 的缺失值填补
对前4 列中经过异常值剔除的数据在原本空缺的地方进行数据填补。通过在每个空缺位置使用插补模型进行多次填补产生若干完整数据集,然后对若干完整数据集分别进行分析,得到相应的分析结果,对结果做出综合推断与比较分析,最终得到最优估计值。本研究使用R 语言中的mice 程序包实现MICE。
本研究选用随机森林(Random Forest,RF),贝叶斯线性回归(Bayesian Linear Regression,BLR),极 限树(Extra Tree,ET),K 临近(K-Nearest Neighbor,KNN)4 种插补模型作为MICE 的估计器,并结合中值法(Median)与均值法(Mean)2 种传统插补方法分别进行数据填补,为验证MICE 的优越性并优选最佳插补模型,对比6 种填补结果的均方根误差(ERMS),如图3 所示。

图3 不同插补模型/方法的ERMSFig.3 ERMS for different imputation models or methods
观察图3 可以得出MICE 比传统插补方法拥有更高的精度,其中ET 模型的精度最高,故本研究选用ET 模型作为估计器对前4 列进行MICE 插补,插补后计算并补全后2 列数据,完整数据如图4 所示。

图4 完整数据Fig.4 Complete data
3) 数据集分割
为使模型以有限的现场实测数据进行充分学习,将样本数据10 等分,其中训练集占8 份、验证集与测试集分别为1 份[38],即120 组样本数据中随机抽取96 组作为CNN 模型的训练集样本,12 组验证集样本,共108 组数据为预测模型建立过程中的训练样本,剩余12 组测试集样本作为工程实例以进一步验证模型准确率;3 部分数据相互独立且均具有代表性。
4) 数据转换
CNN 在图像分类预测方面具有良好的预测精度,故本研究需要将数值数据转换为包含RGB 三通道的图像数据[39]。由于本研究的训练样本仅包含6 个指标,将数据平铺为6×1×1 的一维图像数据,既可以充分提取样本数据内涵特征信息,又可降低特征维度使神经网络的训练与计算更加便捷。
3.3 预测模型参数确定
1) CNN 神经网络构造
第一层为图像输入层(Image input)。第二层为卷积层1(Conv_1),由于数据为一维,所以卷积核大小选取为z×1,而z为1 时会丧失感受野的作用,故需z>1;当卷积核为偶数时,输出特征图比输入特征图尺寸变小,可学习的特征信息减少,故需z为奇数。考虑到卷积核过大可能忽略数据特征信息,故本研究所选用的卷积核大小为3×1;同理,本研究以1 为步长进行卷积操作能够尽量减少信息的丢失;采用的硬件资源为单GPU,结合硬件配置选择卷积核的数目为16;卷积层与池化层的特征边缘处理方法有不填充与前后补零2 种,不填充即忽略最后未卷积的区域并降低特征图尺寸,前后补零方式可以使最后输出的特征图尺寸和原图尺寸一致。本研究选用前后补零的特征边缘处理方法,可保证输入与输出特征图尺寸Sc一致。输出特征图的尺寸计算公式如下:
式中:Co为输出通道数;Ho、Io分别为输出特征图的高和宽;Hi、Ii分别为输入特征图的高和宽;F1与F2分别为卷积核的高与宽;M为步长;P1、P2分别为补零的行数和列数。经过计算,特征边缘处理后的特征图尺寸始终保持为6×1×1。
第三层为批量归一化层(Batch norm)[40],该层对训练样本进行局部归一化,加快模型的收敛与运算速度,并且使模型更加稳定。本研究对是否添加批量归一化层进行对比训练,结果显示,添加该层后预测准确率略微提高,运算速度显著提高。
第四层为激活函数层1(ReLU_1),激活函数通过添加非线性因素的方法捕捉非线性信息,进一步提高线性模型的表达能力,常用的激活函数有[41-42]:(1) Sigmoid 函数,该函数在其饱和时的梯度值相对低下,梯度的耗散问题将会随着模型中神经网络层数的增多而严重;(2) Tanh 函数,该函数的缺点是仍然具有饱和的问题;(3) ReLU 函数,可有效解决Sigmoid 函数所存在的梯度耗散问题,网络稀疏性较大从而降低Tanh 函数存在的饱和问题,且运算效率高。3 个函数公式分别如下:
以训练样本的预测准确率为校验目标对各激活函数进行模型训练,结果如图5 所示。观察图5,以ReLU 函数进行模型训练的准确率均较高,特别地,训练集准确率达到100%,故本研究选取ReLU 函数作为激活层函数。

图5 激活函数的选取Fig.5 Activation function selection
第五层为池化层1(Maxpool_1),常用的池化方法有平均池化法与最大池化法。平均池化法能够最大限度地保留数据背景信息,最大池化法能够尽可能地提取数据的特征纹理,本研究期望能够挖掘到更多的数据特征,故选取最大池化法进行池化操作。池化核与步长的确定过程类似于卷积层卷积核与步长的确定过程,确定本研究池化核大小为3×1,步长为1,特征边缘处理方法选择前后补零。
第六层为卷积层2(Conv_2),由大小为3×1 的卷积核以1 的步长进行卷积操作,生成32 幅特征图,特征边缘处理方法选择前后补零。第七层为批量归一化层。第八层为激活函数层2。第九层为池化层2(Maxpool_2),特征边缘处理方法选择前后补零。
第十层为全连接层(FC),将上一层数据展开,经过激活函数Softmax 激活后挖掘特征信息,得到4 类输出,即岩爆烈度的4 个等级。本研究所建立的CNN神经网络共有12 层,各层参数见表3。
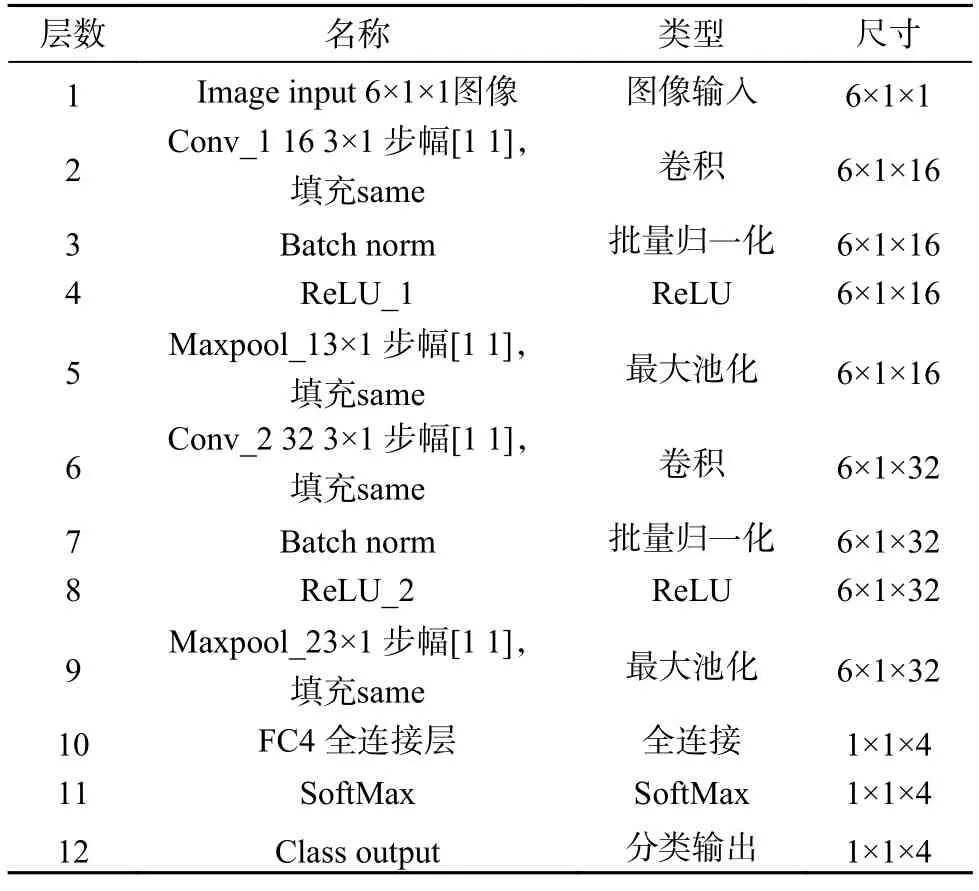
表3 CNN 网络结构参数Table 3 Structural parameters of CNN
2) 超参数优选
优化器的选择方面,目前常用且性能优秀的优化器有3 种:SGDM、RMSProp 和Adam[43]。SGDM 在梯度下降的过程中引入一阶动量解决了可能仅找到局部最优点而不是全局最优的缺陷;RMSProp 加入了迭代衰减,不会在迭代过程中梯度下降过大使自适应梯度出现变化异常等现象;Adam 结合了前2 种优化器的优点,在提高自适应学习率、寻找全局最优点等方面皆较为突出。以训练样本的预测准确率为校验目标,对RMSProp、SGDM 与Adam 进行模型训练,结果如图6 所示,经对比,Adam 能够在较少的训练次数下达到较高的预测准确率,故本研究选用Adam 优化器进行模型优化。

图6 优化器的选取Fig.6 Optimizer selection
由图6 可知,训练次数达到200 时,预测准确率便不再升高,继续升高训练次数只会延长模型训练时间,故本研究的最大训练次数选为200。预测模型的超参数详见表4。

表4 预测模型超参数Table 4 Prediction model hyperparameter
3.4 模型训练与建立
将本研究构造的CNN 神经网络与选取的超参数相结合建立岩爆烈度等级预测模型,输入训练样本进行训练,训练集预测结果如图7a 所示,验证集预测结果如图7b 所示。由两图可得,训练集预测准确率达到100.00%;验证集的预测准确率达到91.67%,其中第七组真实值为弱岩爆,而预测值为中等岩爆,其他组预测结果均正确,错误率在合理范围内。由训练样本预测结果可得,本研究所建立的CNN 岩爆烈度等级预测模型是合理可行的。
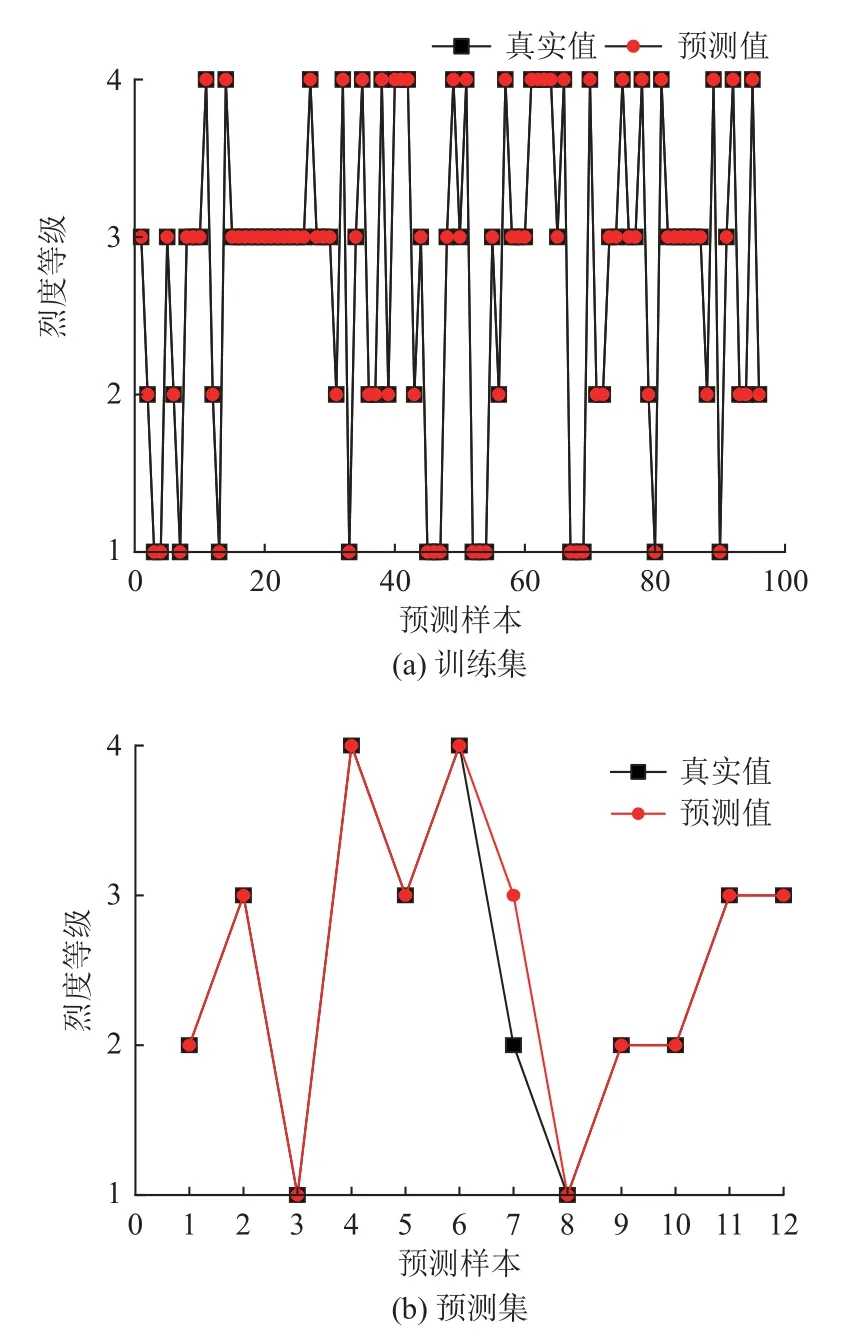
图7 训练集与验证集预测结果Fig.7 Prediction results of the training set and verification set
3.5 模型预测结果对比
为进一步说明模型的可行性,将包含12 组数据的测试集分别输入本次所建立的CNN 预测模型和3 个对比模型:RBF、SVM 与PNN 模型中进行预测,预测结果见表5。观察各模型预测结果准确率可知,CNN模型的预测结果准确率最高,仅第9 组数据预测错误,其他组皆能够正确预测岩爆烈度等级。

表5 各个模型的预测结果与准确率Table 5 Prediction results and accuracy of each model
CNN 模型测试集混淆矩阵[44]如图8a 所示。图中可以看到有一组现场案例的实际结果为中等岩爆,而模型预测结果误判为强烈岩爆,预测结果略高一级,虽在应急防治方面会消耗更多的人力物力,但在误判的情况下依然能够保证现场工作人员的生命安全。

图8 CNN 与PNN 测试集混淆矩阵Fig.8 Confusion matrix of CNN and PNN test set
PNN 模型测试集混淆矩阵如图8b 所示。PNN 预测模型的准确率与CNN 模型相近,但观察混淆矩阵,有2 组现场案例的实际结果为中等岩爆,而模型预测结果分别误判为一组无岩爆与一组弱岩爆。当误判为弱岩爆时,现场人员的准备与预防措施不够充分,难以保障人身与财产的安全;而当误判为无岩爆时,岩爆灾害将对施工现场造成极大的破坏并严重危害工作人员的生命,造成巨大的财产损失。
通过以上分析可以得到,本研究所建立的基于CNN 的预测模型是可行的,且具有准确率高、安全系数高等优点。由于现场数据收集较为困难,缺乏地下水、微震、声发射等影响岩爆的关键因素与动态指标;需要收集与应用的现场数据量需进一步扩大,未来需要结合更多案例与更多影响指标进行综合研究。
4 结论
a.建立岩爆烈度等级预测指标体系,对原始数据进行基于拉依达准则的异常值剔除与MICE 的缺失值填补,建立RF、BLR、ET、KNN 4 种插补模型并结合2 种传统插补方法,依据ERMS评价指标优选MICE 的估计器,其中,ET 模型得到的观测值与真值偏差最小,能够保证模型预测的准确度。
b.搭建CNN 神经网络初始框架,确定卷积核和池化核大小、特征边缘处理方法与激活函数等;优化模型超参数,确定优化器函数等,提高了模型预测准确率,降低了运算时间,增强了模型的适用性。运用训练样本对模型进行训练,训练集准确率为100.00%,验证集准确率为91.67%。
c.建立基于RBF、SVM 与PNN 对比模型,并对实例应用结果进行综合分析显示,基于CNN 的岩爆烈度等级预测模型准确率最高,为91.67%。对比CNN与PNN 模型的混淆矩阵得到,在误判的情况下CNN预测模型安全性更高。
d.未来需进一步扩大用来建立指标体系与预测模型的现场数据量,结合现场案例的更多影响因素进行综合分析。有必要运用先进算法进行超参数优化,建立成熟的深度学习模型对岩爆灾害进行精确预测。
