基于选址机制与深度强化学习的WRSN移动能量补充
2023-11-05王倩
王 倩
(1.昆明理工大学信息工程与自动化学院,云南 昆明 650500;2.昆明理工大学云南省计算机技术应用重点实验室,云南 昆明 650500)
0 引 言
无线可充电传感器网络(Wireless Rechargeable Sensor Network, WRSN)[1]通过配备可移动充电装置(Mobile Charger, MC)能从根本上解决传感器能量受限的问题,被广泛应用于战场监测[2]、生态系统监测[3-4]、交通监测[5]等信息感知领域,具有传感器节点密集且分布范围广泛的特点。一对多能量补充技术通过适当调整发送器和接收器线圈的工作频率[6],MC 可以同时为多个传感器充电,从而有效提高能量传输效率,更能适应规模较大、节点数目众多WRSN 的应用场景。
在WRSN 一对多充电方案中MC 充电驻点的选取以及充电路径的规划是实现高效能量补充的两个关键因素,目前大多数相关研究将其构造为组合优化问题。文献[7]将一对多充电问题归约成覆盖TSP 问题,首先采用PSO 算法得到MC 充电驻点,然后采用LKH 算法构造遍历这些驻点的最小TSP 回路。文献[8]提出一种基于加权启发式的充电策略GOCS,计算出充电优先级,抢占式按需充电。随着机器学习的发展,文献[9]引入时间窗的概念表示充电需求,基于传感器的时间窗信息和能量信息,将DQN 引入用于确定MC 的充电路径。可以看到,将机器学习与充电策略相结合有利于提高MC 的自主性,实时响应充电请求。
由于同时考虑组合优化问题的解空间复杂度过大,本文将能量补充问题离散化为驻点选取和路径规划两个子问题进行求解。针对上述问题,本文提出一种基于选址机制与深度强化学习的一对多充电策略(One-tomany Charging Strategy Based on Reinforcement Learning,MSRL)。本文采用预先设置驻点的方式对传感器节点进行能量分批管理,实现网络的全覆盖。首先将充电驻点选取问题抽象为选址问题中的集合覆盖问题,通过WSC_RA[10]算法求解出最优充电驻点集。在确定驻点位置后,引入充电奖励,基于Dueling DQN 得到充电调度的最优策略,实时动态提供充电方案,延长WRSN 网络寿命。
1 网络模型与问题描述
1.1 网络模型
本文的网络模型如图1 所示,在网络覆盖区域随机部署N个传感器节点V={v1,v2,…,vn},vi代表第i个传感器节点,节点具有监控自身剩余能量、数据融合的能力;基站位置固定位于网络中心,为MC 供应能量且能量不受限。当传感器剩余能量低于充电阈值时,传感器节点会通过多跳通信的方式向基站发送充电请求,基站再将充电请求转发给MC。MC 为带有高容量无线充电电源的移动设备,具有强大的计算能力和足够的服务池来接收充电请求,当收到充电请求后沿着充电路径访问充电驻点P={p1,p2,…,pm},并为覆盖范围内的传感器节点以一对多的方式充电。因此根据模型假设和相关定义,在表1 中列出了主要的参数符号,此外还进一步给出了充电驻点的定义。
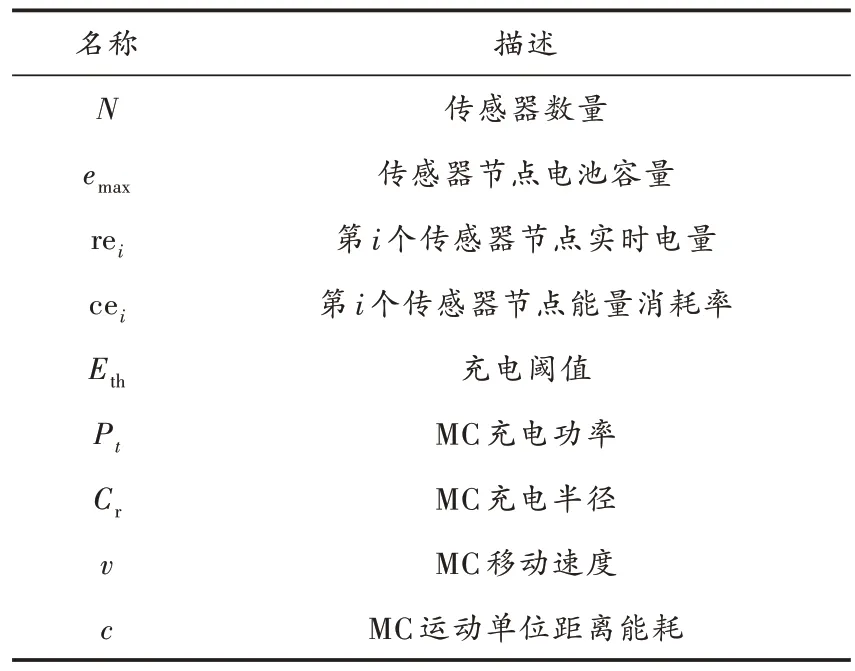
表1 主要参数符号
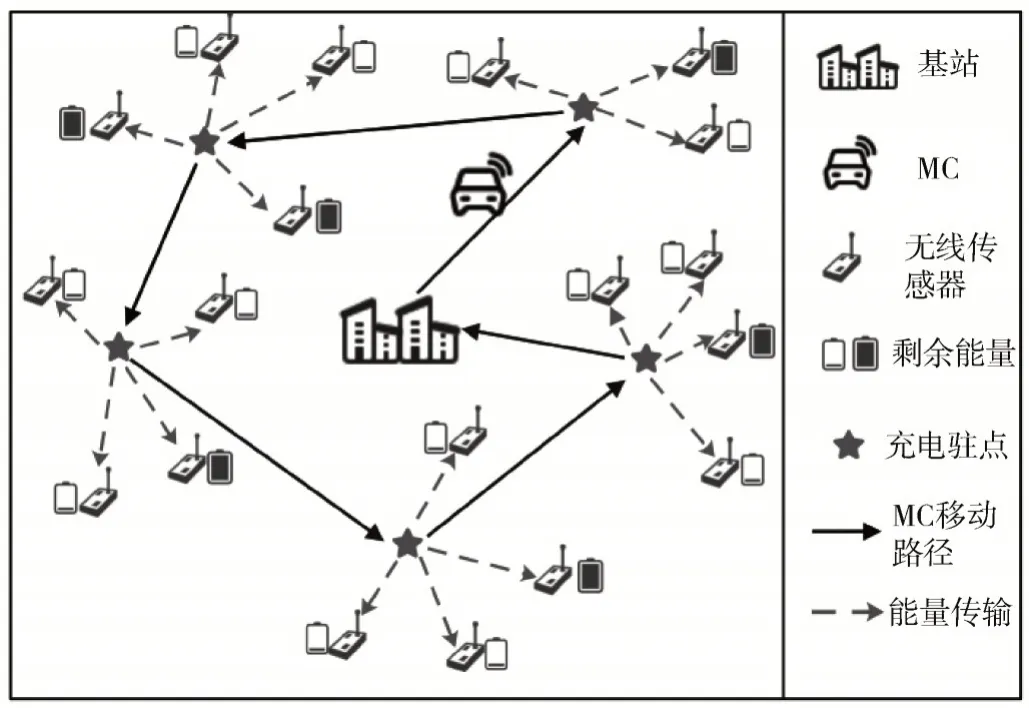
图1 网络模型
定义1:充电驻点即MC 预设停靠位置。MC 在网络中停靠时才对传感器进行充电行为。
1.2 问题描述
WRSN 可持续稳定工作对确保监控质量至关重要,为了衡量MC 的充电性能,将一次充电周期结束后,网络中所有传感器节点的平均剩余能量定义为网络平均剩余能量,如式(1)所示:
与此同时,传感器节点失效时无法保证网络的连通性,会产生数据丢失、网络断开等问题[11],如何最小化节点失效数,是充电方案中要解决的关键问题。因此,本文引入传感器节点死亡数DN作为衡量充电方案性能的主要指标之一,并且假设t时刻MC 剩余电量为Et,此时距离基站距离为dt。表述受限的组合优化问题为:
式中:Et≥c*dt表示限制MC 在移动过程中任意时刻的电量,可以保证其返回基站。
2 MSRL 策略设计与实现
2.1 确定候选充电驻点集
以优化MC 移动距离为目标,为MC 确定合适的充电驻点位置,实现全覆盖的同时充电驻点数最少。确定候选充电驻点位置的具体步骤如下:
1)以每个传感器为圆心,充电距离为Cr半径作圆,求出圆与圆之间的交点。
2)当两圆之间存在两个交点时,基于向心法则选择距离基站位置较近的交点,将其加入候选充电驻点集合U。
3)当两圆之间只有一个交点时,则将该点加入候选充电驻点集合U。
4)若存在独立的圆,即不与其他圆相交,则将该圆圆心加入候选充电驻点集合U。
如图2 所示,以传感器节点为圆心作圆,黑色菱形即为候选充电驻点位置。由于此方法得出的充电驻点数量较大,不利于求解最短充电路径,接下来将基于选址问题中的带权集合覆盖问题,求得最优充电驻点集。
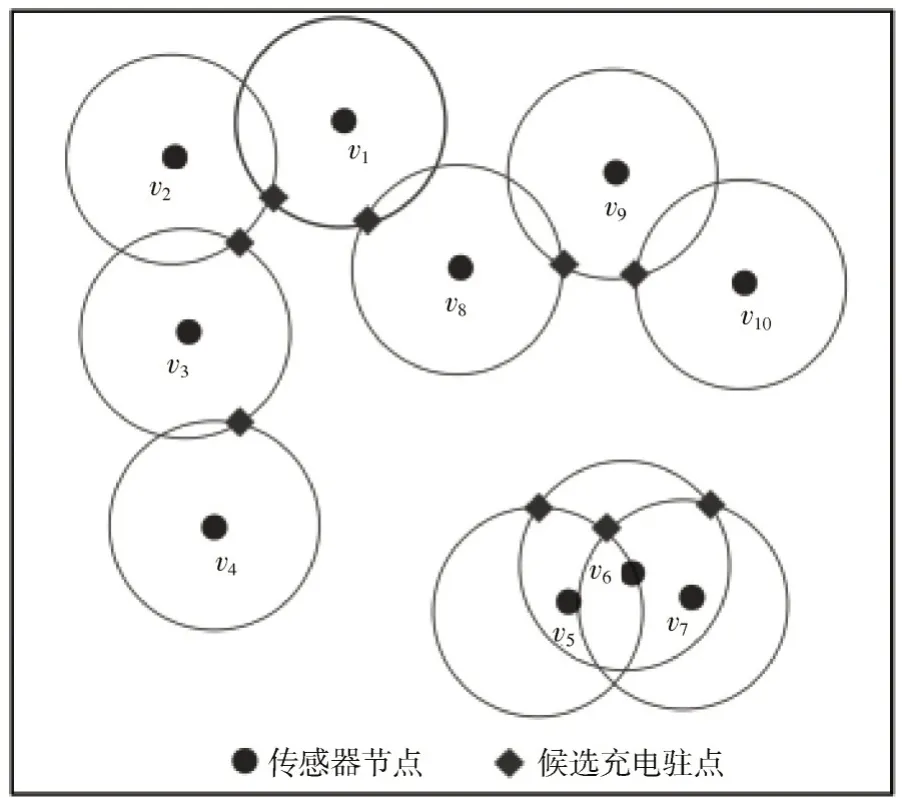
图2 确定候选充电驻点
2.2 确定最优充电驻点集
考虑到驻点选取问题与选址问题的相似性,将驻点选取问题抽象成带权集合覆盖问题,则是求解满足覆盖所有传感器节点的前提下,充电驻点总的位置个数最少且距离最小的问题。对于传感器节点集合V={v1,v2,…,vn},候选充电驻点集合U={u1,u2,…,um},定义候选充电驻点到基站的距离为权值。将驻点选取问题转换为求解带权集合覆盖问题,其形式化定义如下:
输入:V={v1,v2,…,vn},U={u1,u2,…,um},W(U) ={w(r1),w(r2),…,w(rm)}(w(ri) > 0,1 ≤i≤m), 其中ui⊆V,1 ≤i≤m。
输出:C⊆U,∪uk=V,且最小化∑w(uk),uk∈C。
为确定最优驻点集合,本文通过带权集合覆盖问题的一种随机近似算法WSC_RA,从概率的角度出发,多次运行求得最优覆盖集合。此外该算法时间复杂度O(n)远小于解决集合覆盖问题最常用的贪婪算法,其优化结果如图3 所示,五角星位置表示最终确定的充电驻点。
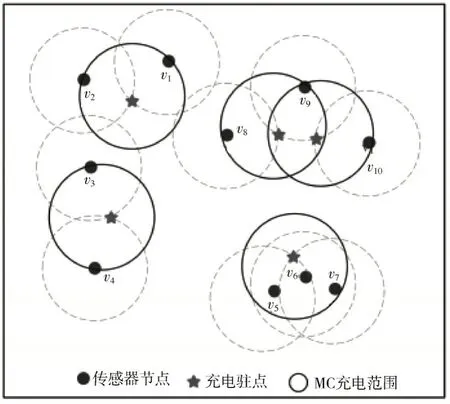
图3 确定最优充电驻点
2.3 基于竞争深度Q 网络的充电路径规划算法
2.3.1 学习模型
本文基于马尔科夫模型对文中描述的充电场景进行建模,将无线可充电传感器网络视为强化学习中的环境,将负责执行充电决策的MC 视为智能体。该模型可以由四元组
1)状态空间S:该模型的状态由MC 的剩余电量和WRSN 中所有传感器节点的状态两部分组成。
式中:EMC表示MC 的剩余电量;Snetwork表示传感器节点的状态集合;si表示第i个传感器节点的状态,由两部分组成,即坐标位置信息(xi,yi)、剩余能量信息rei。
si的表达式如式(5)所示:
2)动作空间A:MC 的基本动作集合A中包含2 种基本动作,如式(6)所示:
当a=m+ 1,表示MC 返回基站进行能量补充;当a=i(i∈{1,2,…,m}),表示MC 移动到第i个充电驻点处进行充电任务。为避免电池过度充电,只给MC 充电覆盖范围内低于能量阈值的传感器充电。
3)即时奖励:智能体通过即时奖励的反馈来评价动作的好坏,因此奖励函数的设定对于强化学习至关重要。在本文中,MC 在t时刻执行动作结束后得到的即时奖励从三个方面综合考虑,定义为:
①表示路径奖励,用于引导优先考虑距离较近的充电驻点,其与MC 从上一个充电驻点移动到当前充电驻点的距离l成反比,如式(8)所示:
②用于惩罚网络中的传感器节点死亡,如果当前执行的动作导致传感器节点能量耗尽失效,则给MC一个负奖励值,见式(9):
式中:DN 代表一次充电动作结束后传感器节点死亡数;K代表常数系数。
③表示充电奖励,用于引导优先给能量较低的传感器节点进行充电,一方面可以避免传感器节点死亡,另一方面可以提高MC 的充电效率,见公式(10):
式中k表示MC 在当前充电驻点时,其充电覆盖范围内传感器节点的数量。
综上所述,奖励函数可以表示为式(11):
2.3.2 基于Gradient Bandit 策略采样
强化学习中通常认为奖励值越高的动作与环境交互表现越好,越具有学习价值。基于Gradient Bandit 策略采样,根据奖励值进行重要性评估,给每条经验数据设置一个偏好度。当经验奖励值越高,偏好度越高,经验被选中的概率也就越高;反之亦然。在该方法中,首先将所有经验的偏好度Ht(ei)初始化为0,将经验数据的平均奖励值作为基线,根据基线设置各个经验的偏好度。每个时间步t时,当有新的经验数据加入经验池,会更新平均立即奖励值,从而更新偏好度。偏好度Ht(ei)的更新公式见式(12):
式中:ψ为步长影响因子;ri表示经验池中第i条经验的立即奖励值;rˉ为平均立即奖励值;Pt-1(ei)表示第t-1时间步时采样第i条经验的概率,其计算公式如式(13)所示:
2.3.3 基于竞争深度Q网络的充电路径规划算法实现
在WRSN 能量补充场景中,当网络中死亡节点较多时,无论MC 采取何种动作所得到的即时奖励可能还是很小的,此时下一步的状态主要取决于当前状态。考虑到这种情况,将原网络的输出层替换成基于竞争架构的两个全连接层:价值函数V和动作优势函数A。其中V表示状态环境本身具有的价值,A表示选择某个动作额外带来的价值。为体现动作优势贡献的唯一性,一般要将动作优势函数设置为动作优势减去当前状态下所有动作优势的均值,这样可以保证在该状态下各动作的优势函数相对排序不变,提高算法稳定性。Q函数如公式(14)所示:
式中:S、A分别表示当前状态和当前选择的动作;θ、β、α分别是神经网络参数、价值函数的参数、动作参数。本文提出基于竞争深度Q网络的充电路径规划算法执行框架如图4 所示,执行算法见算法1。
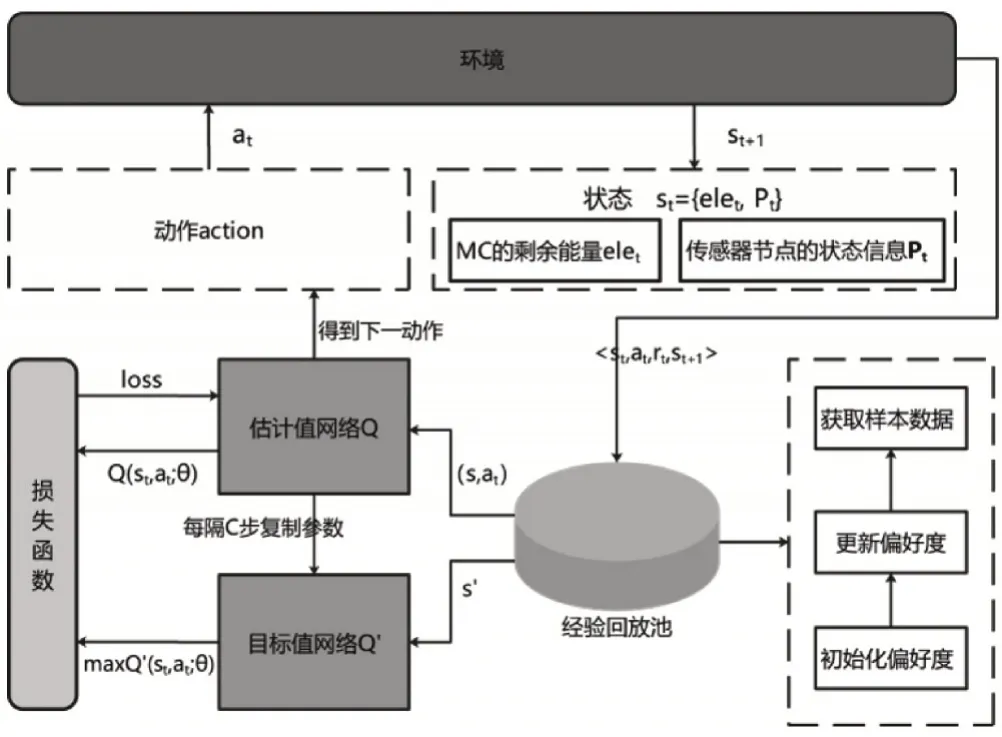
图4 充电路径规划算法框架
算法1:基于竞争深度Q网络的充电路径规划算法
①初始化网络参数
②For each learning episodeedo
③初始化充电环境,得到初始状态s0
④For each time steptdo
⑤根据ε-greedy 策略选择动作at,并执行获得相应的状态st+1与奖励rt
⑥存储ei={st,at,rt,st+1}到经验池D和初始化Ht(ei)
⑧通过公式(12)更新偏好度
⑨利用公式(13)计算样本被采样的概率
⑩从回放经验池D中根据采样概率采样
⑪计算Q网络标签
⑫计算损失函数loss = (yt-Q(st,at;θ))2,更新参数
⑬每C步复制一次参数,Q'=Q
⑭End for
⑮End for
3 实验与分析
3.1 实验设置
本文构建了一个无线传感器网络仿真环境,在100 m×100 m 的二维平面区域内随机部署90~150 个传感器节点,基站位于网络中心位置,MC 初始从基站出发,每充电一轮后回到基站进行能量补充。表2 中列举出了所有的仿真参数。
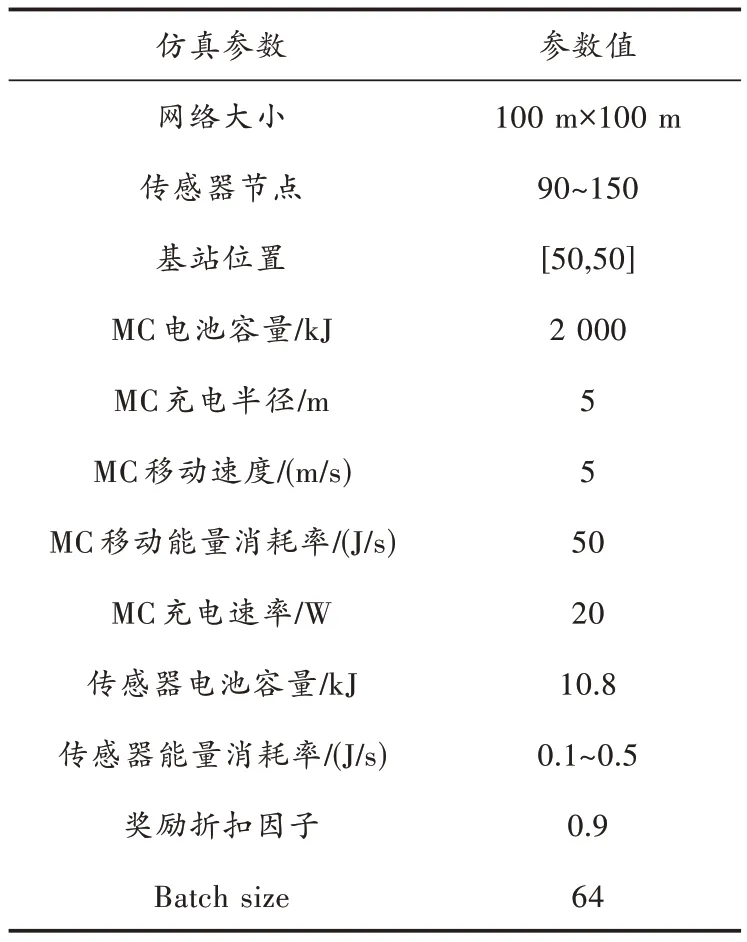
表2 参数定义
3.2 比较方法
为了有效地评估本文提出的MSRL 算法,将与以下3 种算法进行实验性能比较分析,其方法介绍如下所示:
1)TSCA[13]:始终选择最先发出充电请求的驻点位置。
2)NJNP[14]:选择发出充电请求距离最近的驻点位置。
3)GOCS[8]:是一种一对多充电算法,根据剩余能量、贡献价值、欧氏距离等计算出充电权重,抢占式的按需充电。
3.3 MSRL 算法收敛性实验
基于Pytorch 深度强化学习框架对MSRL 算法的神经网络部分进行训练,设置1 200 个训练周期,其中从MC 任务开始直到返回基站为一个周期。算法的收敛性训练结果如图5 所示,展示了算法周期奖励回报曲线。在智能体自探索阶段,被设置为一个较大的数值,以确保较高的探索可能性。随着训练周期的增加,经验的逐步累积,逐渐降低其探索率,减少至0.1 时不再明显变化,直到完全收敛。
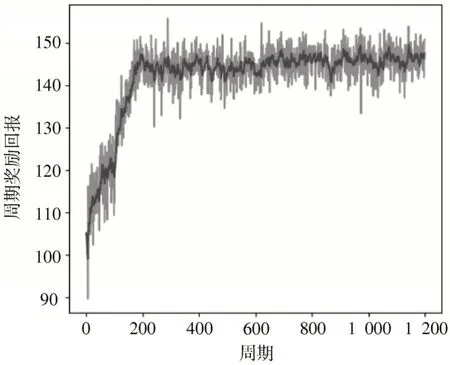
图5 训练过程中周期奖励回报收敛曲线
3.4 传感器节点死亡数量比较分析实验
本组实验考虑各算法在不同节点数量和不同充电速率下的网络中节点死亡情况。图6a)表示充电速率为20 W 时,节点死亡数随着网络中传感器节点数量增加的变化曲线图,可以看出当网络中传感器数量较少时,需要充电的节点也较少,MC 可以满足充电任务,MSRL 相比其他3 种算法的提升较少;当传感器数量较多时,需要充电的节点也增多,这时MSRL 相较其他3 种算法优势更加明显。这是由于随着网络中传感器数量的增加,网络中的充电请求增加,MSRL 算法优先引导MC 给能量较低的传感器节点进行充电,从而减少节点死亡数。而GOCS 算法的引导作用有限,NJNP、TSCA 算法无法优先给能量较低的节点进行充电,节点死亡数较高。而通过图6b)可以发现,当充电速率与节点死亡数呈负相关时,MSRL 算法依然优于其他3 种比较算法。
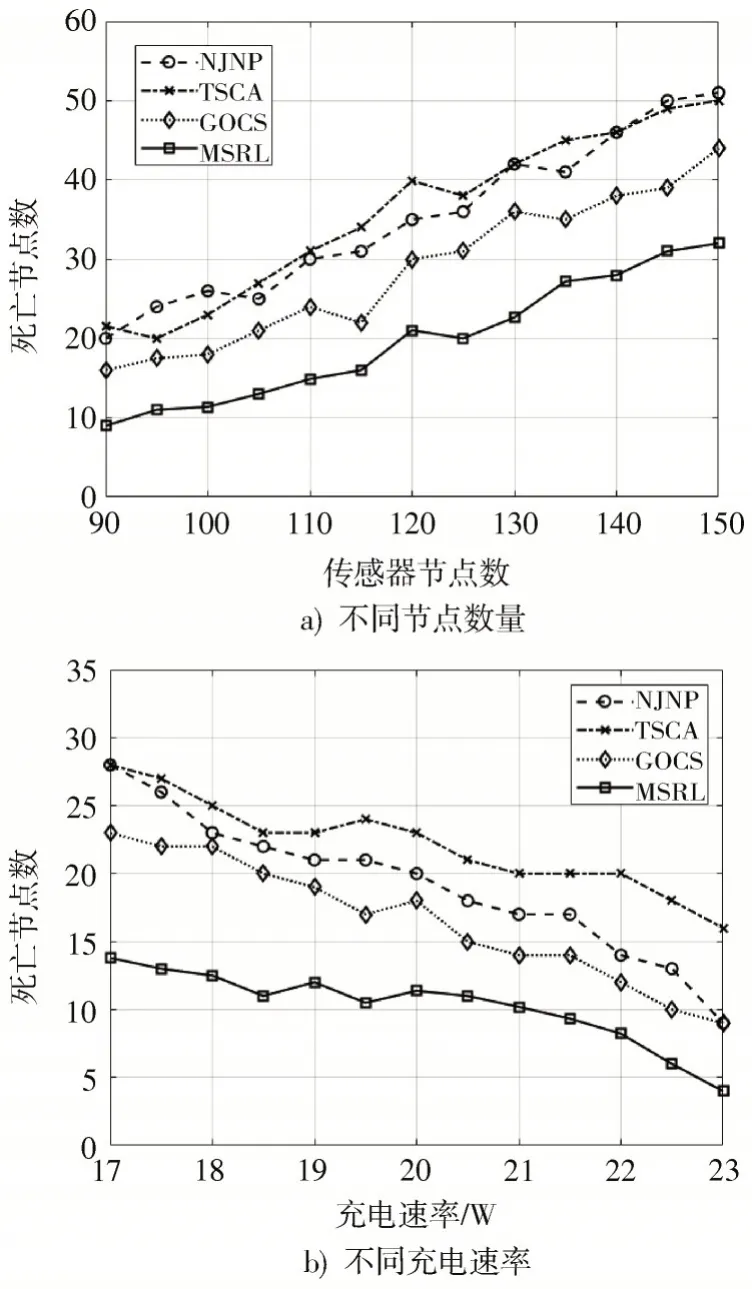
图6 网络中节点死亡变化趋势
3.5 网络生存时间比较分析实验
网络生存时间被定义为MC 从基站出发后,直到网络中第一个传感器死亡的时间,是无线传感器网络的重要衡量标准之一。图7a)中网络生存时间随着传感器节点数的增加而降低,这是由于随着节点数量增多,网络中的充电请求增多。MC 无法应对那么多的充电请求,传感器节点的等待时间变长,导致节点能量耗尽而死亡,网络生存时间自然降低了。TSCA 优先为最先发出充电请求的传感器进行充电;GOCS 也对剩余能量较低的传感器增加其充电优先级,故表现较为良好;而MSRL 相比其他三种算法(NJNP、TSCA、GOCS)表现更好,这是因为RL 的探索机制增加了MC 为能量较低的传感器提供充电服务的可能性,从而延长了网络生存时间,其实验结果具体如图7b)所示。

图7 网络生存时间变化趋势
3.6 能量消耗情况比较分析实验
网络中所有传感器节点的平均剩余能量值如图8所示。其中通过图8a)可以发现,随着网络中传感器数量的增加,4 种算法的平均剩余能量值均有所下降,但MSRL 算法执行的结果始终优于其他3 种算法,这是由于MSRL 可以减少MC 的移动能耗,使更多的能量用于传感器充电。当网络中传感器数量为100、充电速率为20 W 时,相比NJNP、TSCA 和GOCS 分别有20.41%、28.71%、10.32%的提升。由此可以看出算法在降低能耗方面效果显著,可以有效延长网络寿命。而图8b)则展示了网络中平均剩余能量值与充电速率的关系,实验结果表明MSRL 方法在同等情况下依旧要优于另外3 种比较算法。
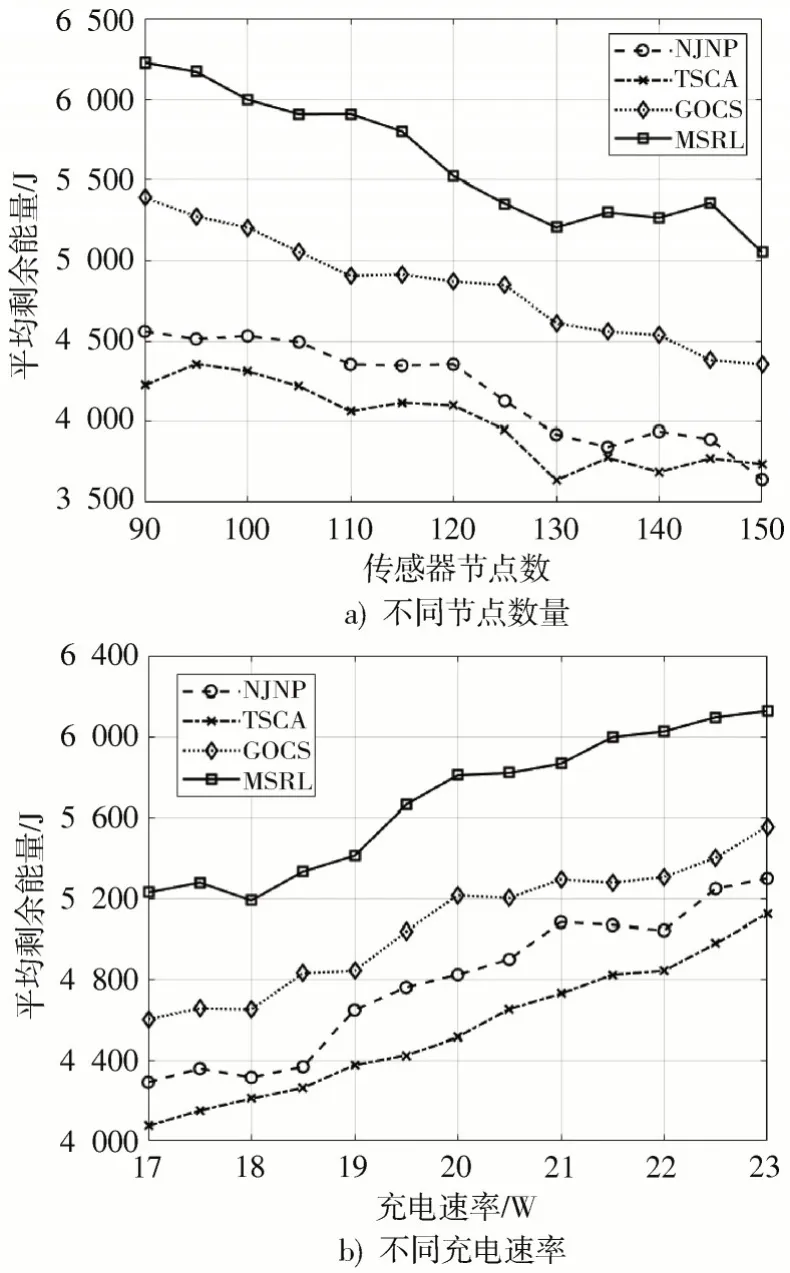
图8 网络中传感器节点的平均剩余能量变化趋势
4 结 论
本文设计了一种基于选址机制与深度强化学习的一对多充电策略用于解决WRSN 中的能量补充优化问题。首先,MSRL 基于选址问题中的带权集合覆盖问题求解出近似最优充电驻点集合,实现对传感器网络全覆盖的同时驻点数最小;其次,设计了一种基于竞争Q网络的充电路径规划算法动态地调整充电路径。仿真实验结果表明,本文提出的MSRL 在降低传感器节点死亡数和延长网络寿命等方面都优于比较方法。此外,MSRL 策略存在通过预设驻点导致充电移动距离增加的局限性,因此未来将考虑通过动态选取驻点位置来进一步地降低充电代价作为研究方法。
注:本文通讯作者为王倩。
