基于改进的WOA-LSSVM樱桃番茄内部品质检测方法研究
2023-11-03康明月孙鸿雁李作麟
康明月, 王 成, 孙鸿雁, 李作麟, 罗 斌*
1. 北京市农林科学院信息技术研究中心, 北京 100097
2. 北京市农林科学院智能装备技术研究中心, 北京 100097
3. 中国地质大学(北京)数理学院, 北京 100083
引 言
樱桃番茄外形美观、 口感鲜甜、 营养丰富, 深受广大消费者的欢迎。 随着人们生活条件的提升, 对于果蔬的口感, 营养价值等内部品质有了更高的要求。 番茄中可溶性固形物(soluble solid content, SSC)是评价番茄风味品质的重要指标之一[1]。 维生素C(vitamins C, VC)又名抗坏血酸, 是植物和大多数动物体内合成的一类己糖内酯化合物[2]。 具有水果蔬菜之称的番茄含有丰富的人体所需营养物质, 尤其是VC含量极高[3]。 通过对不同类型番茄SSC和VC的测定, 来综合评价樱桃番茄的内部品质, 旨在为樱桃番茄品质鉴定和优良品种选育提供理论依据。
蔬果内部品质的传统测量方法多采用化学方法, 检测精度高, 但是会破坏样品原有的状态, 为有损检测, 而且所需化学试剂繁多, 样品处理流程复杂, 检测效率低。 近年来, 近红外光谱技术因无损、 分析速度快、 操作简单的特点在食品、 医药、 化工等行业得到了广泛应用[4-7]。 潘牧等[8]应用偏最小二乘法建立预测红薯淀粉及全粉粉丝中薯粉含量的定量模型, 2个模型相关系数分别为0.987 5和0.989 2, 交叉验证均方根误差分别为1.23和1.13, 校正后预测相对分析偏差分别为6.83和7.42。 表明采用近红外光谱技术对贵州红薯粉丝中淀粉及薯粉含量的快速无损检测可行。 杨宝华等[9]用光谱和机器学习算法结合测定鲜桃SSC含量, 提出了一种基于堆栈自动编码器-粒子群优化支持向量回归模型, 该模型预测效果最好, 其R2为0.873 3, 均方根误差为0.645 1。 因此, 将光谱技术和机器学习算法结合, 可提高鲜桃SSC含量的估计精度。 李鸿强等[10]基于可见/短波近红外光谱检测结球甘蓝VC含量, 采用多元线性回归进行建模, 得到校正集R2平均为0.78, 内部交叉验证均方差平均为3.760 9 mg·(100 g)-1, 验证集R2平均为0.73, 均方根误差平均为2.879 2 mg·(100 g)-1。 李俊杰等[11]运用近红外光谱探究塔罗科血橙的内在品质, 采用偏最小二乘法建立预测模型, 得到SSC、 可滴定酸及VC预测值与实测值的相关系数分别是0.833、 0.699、 0.925, 结果表明近红外光谱技术有与化学法近似的准确度, 可以应用在果品内部品质检测中。
随着市场需求量的增大, 樱桃番茄内部品质的无损快速检测对提高其市场价值具有重要意义。 基于近红外光谱分析技术提出了一种融合的特征波长提取方法, 筛选出有效的变量, 并改进优化建模方法, 使得模型预测结果更加准确, 更有利于开展樱桃番茄内部品质含量的检测研究, 为樱桃番茄内部品质含量的预测提供有力的技术支撑。
1 实验部分
1.1 仪器与材料
樱桃番茄光谱测定使用型号为团队自主研发BIO-NIRONE-HEM的手持式近红外光谱仪。 该光谱仪具有快速、 便携、 精确和非破坏的优点, 还可以根据用户的实际需要, 在前端可配置不同类型的传感器, 系统具有智能散热功能, 可保证检测结果不受环境温度影响。 该手持式近红外光谱仪测量参数为吸光度, 使用MEMS-FPI-Shortcut软件, 可以将BIO-NIRONE-HEM采集的光谱数据方便地导出。
试验所用樱桃番茄为在超市选购, 有千禧果、 粉圆圣女果、 荷兰小番茄和极星农业红色串装小番茄四个樱桃番茄品种, 每个品种选取了30个, 共计120个样本。
1.2 光谱采集
樱桃番茄的光谱采集时将手持式设备前端检测区域对准待测样本, 保证完全接触不漏光后, 点击扫描样本按键, 实现样本扫描, 扫描时间预计9 s。 设置波长采集范围为1 350~1 800 nm, 波长间隔为1.5 nm。 在室温(25 ℃)下将编号完成的四个品种依次进行光谱采集, 选择底部和在赤道相对的两个部位共3点, 并对这3个点光谱曲线做平均, 作为该样品的分析光谱。 测量过程及原始光谱如图1(a, b)所示。
1.3 内部品质化学测定
1.3.1 可溶性固形物测定
根据行标NY/T 2637—2014—折射仪法[12]SSC的测定, 将光谱采集完成的样品去掉不可食用部分后, 其余部分榨汁, 在棱镜表面用柔软绒布擦干后, 取2~3滴样液在2WA-J阿贝折射仪中央, 闭合上下两块棱镜, 调节旋钮, 读取示数, 从而获得样品的SSC含量。 每个样品测量3次, 取其平均值作为该样品SSC含量实际测量值。
1.3.2 维生素C测定
根据国标GB 5009.86—2016[13]食品中抗坏血酸的测定, 称取樱桃番茄样品5 g, 配置1%草酸溶液、 2%草酸溶液、 0.01% 2,6-二氯酚靛酚溶液和标准抗坏血酸溶液, 利用2,6-二氯酚靛酚滴定法测定。 对每个样品测量3次, 取其平均值作为该样品VC含量实际测量值。
1.4 近红外光谱模型的建立与优化
按照化学方法进行测定后, 采用三倍标准差对异常值进行剔除, 最后得到千禧果样本24个、 粉圆圣女果样本23个、 荷兰小番茄样本24个和极星农业红色串装小番茄样本29个。 建模过程中样本集的划分对模型性能有直接影响, 因此采用Kennard-Stone(K-S)分类算法[14]将樱桃番茄样本按3∶1的比例划分为校正集和预测集。 该算法可使校正集样品更具定代表性。 表1即是利用K-S算法划分样品的统计结果。

表1 样本划分统计结果

2 结果与讨论
2.1 光谱预处理
近红外光谱存在人为操作误差、 仪器产生的随机噪声或者光谱变化, 这些因素可能会导致结果出现偏差, 因此将光谱预处理应用于样本数据可以有效提高数据精度。 采用的光谱预处理方法包含多元散射校正(multiplicative scatter correction, MSC)[15]、 Savitzky-Golay卷积平滑(SG)[16]、 Savitzky-Golay卷积一阶导数(SG 1st)[17]、 去趋势化(De-trending)[18]和变量标准化(standard normal variate, SNV)[19]。
将原始光谱及多种方法预处理后的光谱数据作为输入变量, 樱桃番茄内部品质化学值作为目标变量, 建立内部品质含量的偏最小二乘回归(PLS)模型。 对输入的光谱变量进行主成分分析, 采用10折交叉验证法确定出最佳主成分数, 最后根据最佳主成分数进行模型的构建, 具体结果如表2所示。

表2 预处理方法比较


2.2 特征波长提取方法及其改进
每个近红外光谱均由大量谱带组成, 存在多重共线性, 选择重要变量来构建更简明和稳健的回归模型是必要的。 将采用连续投影算法(successive projections algorithm, SPA)[20]、 稳定性竞争性自适应重加权算法(stability competitive adaptive reweighted sampling, SCARS)[21]、 遗传算法(genetic algorithm, GA)[22]和改进的遗传算法(improved genetic algorithm, IGA)与机器学习算法相结合, 从而选择最优特征波长提取方法。 其中前三种特征波长提取方法都较为常见且有效, 最后的IGA是基于GA的改进算法。 GA算法是依据遗传学的有效搜索方法, 但在其运行过程中, 输入变量不宜超过200个, 因为这会增加过拟合的风险。 这种风险可通过“先验”去除变量来降低, 但该方法包含主观判断, 结果不精确。 因此, 在进行变量输入前, 先对变量进行自动有序预测因子选择(auto ordered predictors selection, Auto OPS)[23], Auto OPS是这种使用自动执行变量选择的方法, 通过信息向量及其组合, 提供最好的变量选择结果。 再将输出结果进行GA选择, 最终结果作为建模的输入变量。
图2和图3分别为SSC和VC含量在Auto OPS方法下选择的变量, 图4和图5分别为SSC和VC含量在Auto OPS和GA融合方法下选择的变量情况。

图2 SSC含量Auto OPS特征提取过程

图4 SSC含量IGA特征提取过程

图5 VC含量IGA特征提取过程
由图4可知, 运用IGA方法选择的变量主要集中在1 350~1 440、 1 459~1 600和1 647~1 783 nm。 SSC含量主要基团是由C—H和O—H组成, 1 430 nm为O—H的二倍频, 1 720 nm为C—H的二倍频。 因此该波段可以作为预测SSC含量的依据。 根据图5所示, 改进的方法选择变量主要集中在1 422~1 535.5、 1 459.5~1 549.5和1 632~1 633 nm。 VC的分子式是C6H8O6, 1 430 nm为O—H的二倍频。 由此, 该方法下选择的近红外光谱变量可以充分反映樱桃番茄内部品质含量的结构和组成信息。
2.3 粒子群优化的BP神经网络模型
基于SPA、 SCARS、 GA和IGA特征变量算法提取的特征变量建立的樱桃番茄内部品质含量基于粒子群算法优化的BP神经网络方法(particle swarm optimization-BP neural network, PSO-BPNN)[24]预测模型如表3所示。 PSO-BPNN建模时, 隐含层神经元个数由经验公式[25]来确定, 迭代次数为100次。
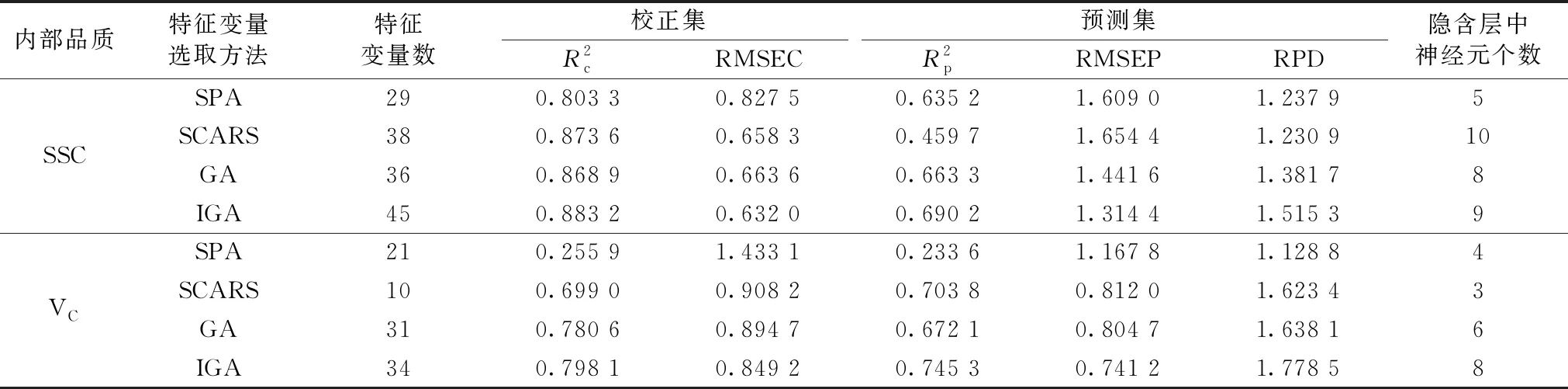
表3 PSO-BPNN建模特征变量选取方法比较
2.4 鲸鱼算法优化最小二乘支持向量机模型
鲸鱼算法是一种模仿座头鲸的狩猎行为而提出的一种新型启发式优化算法。 采用SPA算法、 SCARS算法、 GA算法和IGA算法选择的特征变量作为自变量, 樱桃番茄内部品质含量作为因变量, 分别建立鲸鱼算法优化的最小二乘支持向量机方法(whale optimization algorithm-least squares support vector machine, WOA-LSSVM)预测模型[26]。 在WOA-LSSVM建模中, 初始种群设为30, 迭代次数为100次,γ和σ2两个参数的搜索范围设置为0~1 000, 搜索后确立γ和σ2的最优值。 基于不同特征变量选取方法建立的樱桃番茄内部品质含量WOA-LSSVM 预测模型的结果如表4所示。

表4 WOA-LSSVM建模特征变量选取方法比较
由表4所示, 不同特征变量选择方法建立的樱桃番茄SSC含量预测模型效果不同。 综合来看, 采用WOA-LSSVM建模时, IGA算法是樱桃番茄SSC含量最佳特征变量选择方法, 该算法将全波长变量由301个减少到45个, 变量个数减少了超过85%, 在决定系数R2上有明显优势。

2.5 改进的鲸鱼算法优化最小二乘支持向量机模型
由于WOA算法有收敛速度慢和精度低等问题, 因此将冯诺依曼拓扑结构[27]、 轮盘赌选择[28]、 锦标赛选择[29]和自适应权重相结合引入WOA算法进行改进。 为加强算法的局部搜索能力, 加入冯诺依曼拓扑结构, 增强鲸鱼间信息交互。 为了选择合适的算子, 引入了轮盘赌选择和锦标赛选择来提高精度, 最后引入自适应权重, 加快收敛速度。 该算法流程图如图6所示。

图6 改进鲸鱼算法优化最小二乘支持向量机流程图
应用特征波长选取方法后的数据作为改进的鲸鱼算法优化最小二乘支持向量机方法(improved whale optimization algorithm, IWOA-LSSVM)的输入, 樱桃番茄的内部品质含量为目标输出。 预测模型结果如表5所示。 不同特征变量选择方法建立的樱桃番茄SSC含量预测模型效果不同。

表5 IWOA-LSSVM神经网络建模特征变量选取方法比较

2.6 樱桃番茄内部品质含量不同建模方法比较
图7—图9展示了基于特征变量建模过程中, 针对不同建模方式分别挑选的最优方法所对应的樱桃番茄SSC含量预测结果。 其中红色实线代表实际测量值, 黑色的点代表经过模型拟合的预测值, 当点与线越接近时, 预测效果越好。
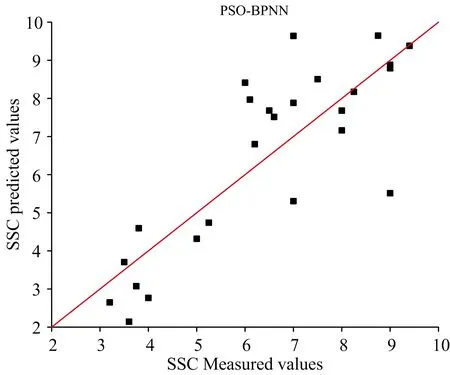
图7 基于PSO-BPNN模型SSC含量预测结果

图8 基于WOA-LSSVM模型SSC含量预测结果

图9 基于IWOA-LSSVM模型SSC含量预测结果
由图9可知, IWOA-LSSVM模型, 在红线周围最密集, 效果即为最佳。 采用IGA算法选出的45个特征变变量建立的樱桃番茄SSC含量De-trending-IGA-IWOA-LSSVM预测模型最优, 说明在识别和选择有价值的信息变量时, 采用IGA所选出的特征变量结合LSSVM模型能够替代全波长变量进行樱桃番茄SSC的无损检测, 其预测集决定系数为0.866 7, 表明近红外光谱技术对樱桃番茄SSC含量的检测是可行的。
真实值(true value)表示的是樱桃番茄SSC含量的化学值, 预测值(predictive value)表示应用最优方法建模后的预测结果。 樱桃番茄SSC含量最优预测模型——De-trending-IGA-IWOA-LSSVM的校正集和预测集拟合情况如图10和图11所示。 可看出估计值和参考值之间拟合较好。
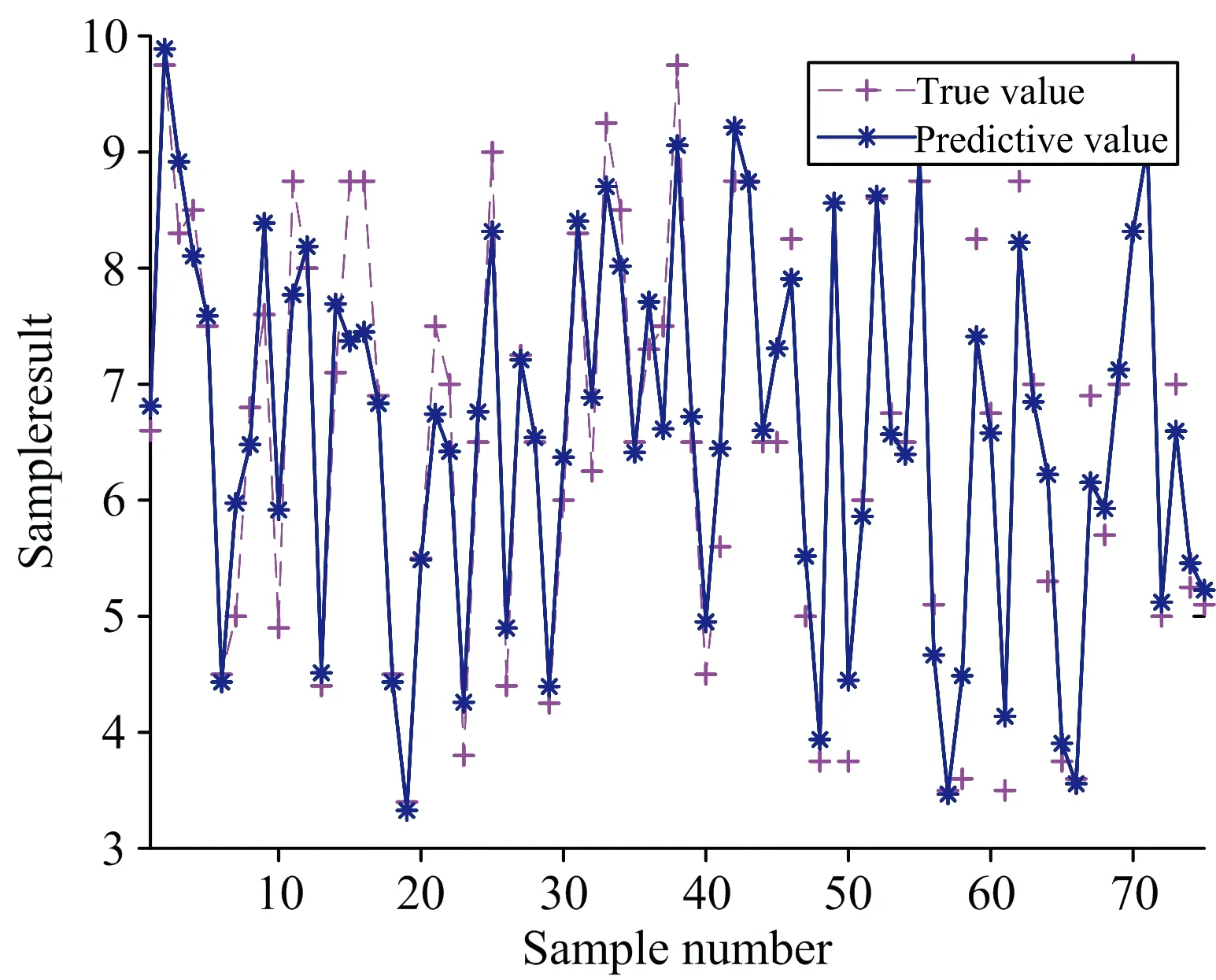
图10 校正集拟合情况

图11 预测集拟合情况
图12列举了基于全波长及特征变量建模过程中, 针对不同建模方式分别挑选的最优方法所对应的樱桃番茄VC含量预测结果。

图12 不同模型预测集效果对比
三种建模方法在不同特征波长提取方法下迭代变化曲线如图13所示, 其中紫色, 绿色和蓝色的线分别代表PSO-BPNN, WOA-LSSVM和IWOA-LSSM模型迭代情况, 适应度函数均为均方差, 均方差越小, 则模型效果越好。 由图13可知, 改进的鲸鱼算法的迭代具有稳定性, 因此可以减小迭代次数, 进一步缩短运行时间。

图13 迭代曲线
3 结 论
