大语言模型在信息化中的应用研究
2023-11-03王玉平
文/王玉平
随着ChatGPT 的出现,自然语言处理技术的发展再次引起业界的注意。而ChatGPT 模型1750 亿参数的规格,使得业界大力训练超大规模参数的模型,也就是基于大规模参数的语言模型。随后出现了大量大语言模型,如Meta AI 的LLaMa 和基于该模型的Alpaca、Vicuna,国内复旦大学团队推出了MOSS 模型,清华大学团队推出了ChatGLM 模型。
大语言模型的能力
大语言模型之所以再次引起注意,是因为其可以按照人类语言语法生成文本,而且文本与问题相关。那么大语言模型除了人工智能领域的Transformer、参数等技术属性和规格属性之外,还具有什么特征呢?
根据现有大语言模型的表现,以及NLP 领域的研究,我们认为大语言模型主要包含了知识内容和推理能力。根据神经网络的技术架构可以推断出大语言模型存储的内容主要是权重,知识内容主要是通过大规模语料训练使得大语言模型在已知文本的情况下可以预测到在人类语言中与已知文本最相关的下一个字,从而在形式上让人感觉到大模型存储了知识。而推理能力则是因为参数超大规模后涌现出来的一种能力,其科学机理仍在研究中,但是从表现来看,大语言模型已经具备链式思考的能力。尤其是通过提示(Prompt)告诉大语言模型如何推理问题,使其更有效、更正确地按步骤推理问题。
大语言模型应用场景
高等教育信息化主要是指发挥信息化在教学、科研、管理和生活中的作用,提高四个领域的效能。根据前几年的探索,我们把大语言模型定位在新型的人机交互接口、副驾驶(Copilot)或者助手。这种定位主要描述了大语言模型不能取代人类,只能在人类的指导下,帮助人类去完成特定工作。
在自然语言处理分为自然语言理解和自然语言生成的基础上,针对高校育人为本的任务,我们把大语言模型适用的场景分为三类:内容创作助手、内容消费助手和任务过程助手。内容创作助手主要是指根据师生指令从无到有地生成内容,譬如撰写邮件、撰写报告等。内容消费助手则是指基于现有知识库回答师生的问题,譬如智能客服、新型业务入口。任务过程助手则是指人工智能根据问题自动思考解决问题的子任务并按序自动执行这些子任务,最终解决问题,譬如Auto GPT。
根据以上分类,我们首先试验了上海海事大学官方网站上内容的问答交互方式。在该试验下,访客不再通过搜索引擎访问,而是由人工智能自行检索相关内容并给出答案。另一个试验是在学校门户上集成了规章制度、通知公告、新闻动态的问答系统,以及网上办事中心的业务检索系统。下一步,我们将探索根据语音输入结合数据智能生成业务申请表单,而大语言模型在教学、科研中的作业则因学科特点和研究内容的不同差异较大,只能有针对性地引入大语言模型。
大语言模型的微调
目前,开源大语言模型训练的语料多是英文语言,无法直接适用于国内中文环境。此外,开源模型的语料多是网上公开的内容,内容的准确性、专业性都有待考量。因此,开源模型无法直接在高校落地应用,必须对其进行定制微调。
大语言模型定制的方法主要有精校技术、参数高效微调(PEFT)技术和提示微调技术。自然语言处理的神经网络模型基本采取了预训练和精校两阶段的策略。这种策略主要是将重复的、高成本的训练过程独立出来,形成阶段性的预训练模型,之后再根据不同应用场景进行适配性的精校,从而达到高效复用的目标。这种策略吸引了大量研究人员投入自然语言处理领域的研发,也推动了自然语言处理技术再应用。
精校技术在中小模型的模型微调中是适用的,但是对于大规模语言模型则因为参数规模非常大,精校的成本非常高,让人却步。而PEFT 技术的出现则比较好地解决了这个问题,其在尽可能减少所需参数和计算资源的情况下,实现对预训练语言模型的有效微调。这种技术特别适用于对英文大语言模型加入中文语料的微调,使之同样理解中文语义。目前常见的Alpaca、Vicuna 模型均是通过PEFT 技术进行微调所得。提示微调则是使用大语言模型的能力,重点通过调整输入提示,求得问题的答案,其对模型并不进行改造。
常见大语言模型
除了闭源的以服务方式运行的ChatGPT 大语言模型外,Meta AI 发布了开源模型LLaMa,斯坦福大学团队在此基础上通过微调技术生成了Alpaca 模型,之后多家机构联手发布了同样基于LLaMa 的Vicuna。130亿参数的Vicuna 模型能力接近于OpenAI 的GPT-4 模型。以上开源模型主要适配英文,对中文的效果不理想,近期出现了对以上开源模型的中文微调模型。而BLOOMChat 多语言大模型则直接支持了中文,但是其模型文件大小超过100GB。清华大学团队的ChatGLM和复旦大学团队的MOSS 模型也是可用的模型之一。
除了开源大语言模型,国内还出现了云服务方式提供的大语言模型,如百度的文心一言、科大讯飞的星火和阿里的通义千问等模型。云服务方式的大语言模型需要用户将文本传给云端进行处理,部分用户不一定适用这种模式,可能更喜欢本地化部署。
本地化部署大语言模型
大多数高校使用大语言模型主要是通过提示微调的方式,而非通过PEFT 技术对模型进行微调。提示微调的方式侧重于应用,恰好符合了高校教育信息化的特点,也是最早可行落地的方案。图1 是通过提示微调使用大语言模型的流程。
该流程主要分为四个步骤:第一步,用户对前端代理提出问题;第二步,代理提交问题给向量数据库,获得相关文本片段;第三步,代理将问题和文本片段提交给大语言模型,大语言模型作阅读理解,返回问题答案;第四步,代理将答案反馈给用户。
通过以上步骤,可以看出本地化使用大语言模型的核心点在于查找问题相关的文本片段和大语言模型作阅读理解的能力。
大语言模型应用试验
为了能够选择足够好的解决方案,我们对查找问题相关的文本片段和阅读理解能力进行了实验。我们节选了学校主页上的学校介绍、网上办事中心的服务指南、新闻,作为知识库,并整理了9 个问题,针对这9 个问题评估词向量模型、向量数据库和大语言模型的优劣。
1.词向量模型
据表1 可知,OpenAI 的词向量模型最佳,其次是chinese-roberta-wwm-ext-large,该模型是与GPT 同期出现的基于Transformer 技术的BERT 模型,擅长阅读理解,故而其语义相关性的能力在开源模型中相对较强。
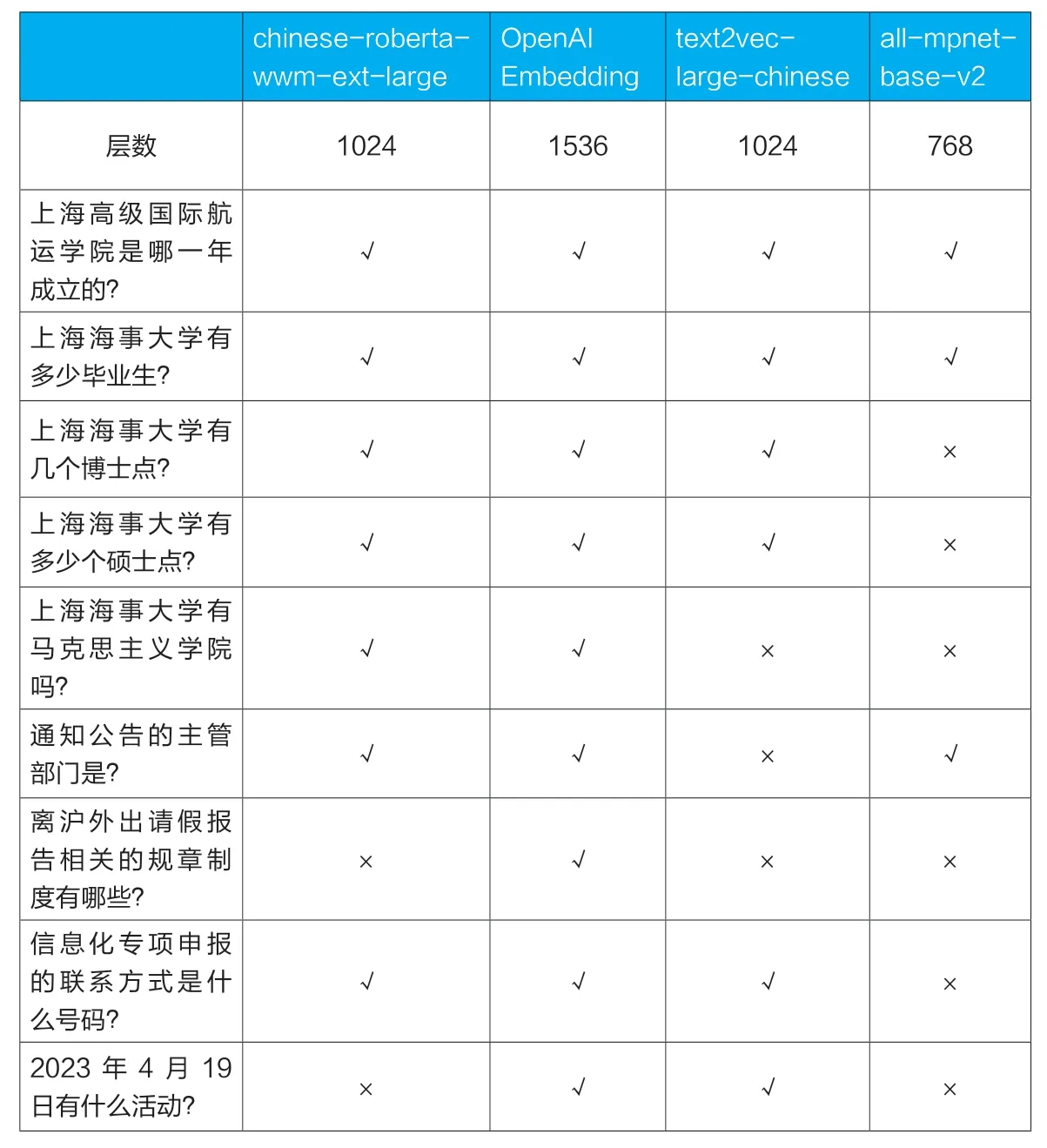
表1 词向量模型测试结果
2.向量数据库
向量数据库有多种产品,如提供云服务的Pinecone,开源的Chroma。经过以上9 个问题的测试,结果都是100%命中,所以在此不予以列表展示。
3.大语言模型
人工挑选出针对9 个问题的文本,将问题和文本提供给大语言模型去理解并给出答案。同时,为了验证提示微调的技术,同一个文本和问题分别提供有提示和无提示两种方式实验。
据表2 可知,OpenAI(GPT-3.5-Turbo)模型是最佳模型,在没有提示的情况下,所有问题均给出了较为通顺的答案。其次是中文微调过的Alpaca 7B 模型,9 个问题中仅错了1 个。
目前,大语言模型依然在快速进化中,但是针对中文的词向量模型和大语言模型还不够完美,仍需要进一步优化。高校在信息化过程中,可以按照新型人机交互接口的方式去探索大语言模型的应用方式,挖掘更多的应用场景。对于企业,则可以探索利用大语言模型助力教学过程的应用场景。
