基于分割区域的配电网异常线损数据辨识与修正
2023-10-31张新鹤何桂雄梁琛马喜平何振武姜飞
张新鹤,何桂雄,梁琛,马喜平,何振武,姜飞
(1.中国电力科学研究院有限公司,北京 100192;2.国网甘肃省电力公司电力科学研究院,兰州 730070;3.长沙理工大学 电气与信息工程学院,长沙 410076)
0 引言
配电网在我国经济建设中发挥着重要作用[1]。随着社会经济的发展,用电负荷增加,线损问题越来越受重视。在线损管理系统中,基础数据冗余大,数据共享难度大,数据的一致性、完整性及有效性难以保证[2-4]。准确、快速地识别并修复异常线损数据,为制定合理的降损措施提供依据,是供电企业的重要任务[5-6]。
在异常线损数据辨识方面:文献[7]考虑拓扑异常对线损率的影响,针对配电网两种接线方式下的不同异常类型,提出拓扑异常辨识方法,但未考虑数据冗余和数据统计异常对线损率同期统计值的影响;文献[8]针对数据噪声对台区线损数据造成的干扰,分析线损数据时域特征,提出电网台区线损数据识别方法,但忽略了线损数据异常波动对拓扑异常的影响;文献[9]提出一种利用改进k-最邻近和多分类SVM(支持向量机)的循环迭代算法,实现缺失数据的变压器故障诊断,但该方法只适用于缺失数据的修复,对于错误数据不具备辨识能力;文献[10]考虑用户动态用电行为的潜在规律性,结合时间序列分解和自相关分析,采用用电相似度判据实现对伪异常点的准确辨识,但欠缺对不同类别负荷用电特性的考量;文献[11]采用灰色关联分析筛选出最佳的电气特征指标,利用自适应遗传算法改进BP神经网络对线损进行预测,具有较好的收敛性和准确性;文献[12]基于相似性比较原则,提出运行状态相似性评估方法,并通过确定型估计模型和组合概率估计模型对异常状态进行检测,但缺乏多组数据来验证其普适性和实用性;文献[13]利用用户历史用电量与线损电量的关联关系,通过归因分析法来识别台区窃电用户,但所提方法受信息完整度影响,不能用于检测零电量窃电用户。
在异常线损修复方面:文献[14]提出将扩展卡尔曼滤波和限定记忆最小二乘法用于智能电表远程估计校准,并根据线损率特征对异常估计值进行滤波;文献[15]采用联络线分区解耦方式对互联系统进行分布式状态估计计算,实现了复杂电网的降维计算和子区域估计解耦,分区解耦方式能够有效计算效率和修正精度;文献[16]提出基于DAE(降噪自编码器)和LSTM(长短期记忆)相结合的配电网日线损率预测模型,基于配电线路线损率短期变化趋势预测日线损率,但时序特征指标的选取对预测的精准度影响较大,系统的鲁棒性难以保证;文献[17]提出一种基于高级量测体系全量测点分区的配电网动态状态估计方法,并进行多尺度量测数据融合,实现数据快速修正,但实际线路量测状态较为复杂,缺乏基于实测数据的模型验证。
基于以上研究,为实现配电网线路异常线损数据的快速修复,本文提出基于分割区域的配电网异常线损数据辨识与修正技术。首先针对节点存在冗余数据的情况,提出采取基于卡尔曼滤波的数据融合技术进行数据预处理。分析线损异常原因,提出配电网线损异常数据识别方法和分割区域的划分方法。基于分割区域邻近节点量测数据和不平衡度指标,动态调整区域规模,得到“任意分割”最终划分结果,并建立节点量测模型、约束模型和估计模型求解异常数据。通过西北某省10 kV什新线和什金线的实测数据进行算例分析,验证所提基于分割区域的配电网异常线损数据辨识与修正技术的准确性。
1 线损数据异常节点定位
配电网线损数据异常的原因主要有两种:一是电能表计量故障时,会导致系统采集电量数据缺失和异常,影响线损的计算结果;二是户变关系错误导致某台区档案记录其他台区用户的数据和台区用户档案缺失,造成台区高线损率或台区负线损率。配电网中,变电站馈线出口,台区配电变压器(以下简称“配变”)和台区用户均装有电能表,当线损异常时,逐一人工排查工作量大、效率低、周期长。因此,如何有效提高配电网线损管理中异常数据检测效率成为电网公司的重要研究内容[18-23]。
1.1 功率-电量预处理
台区配变的功率数据为96节点数据,为便于计算分析,需要对96节点功率数据进行预处理,得到日电量数据。以15 min为采样间隔采集台区配变的馈线出线功率数据,每条线路的节点电量E为:
式中:Pt为时刻t采集的功率数值;N为采样点数,N=96。
1.2 长期高负损台区配变剔除策略
为实现分割区域异常数据修复,首先需要对配电网线路异常配变进行辨识,但长期高负损配变台区由于其高负损特性会导致算法的误判和漏判,因此需剔除长期高负损配变台区配变,再进行异常数据辨识及分割区域分割模型研究。
对于配电网线路台区配变取其同期线损时间序列数据,并对比分析线损数据与人工制定标准区间,计算线损数据中异常线损的占比η,设定阈值分析,确定台区是否长期处于高负损[24]。η的计算公式为:
式中:N2为时间序列中超出标准的线损数据个数;N1为采集的同期线损时间序列数据总个数。若η>5%,则判定为长期高负损台区,并剔除该台区配变[24]。
1.3 异常节点数据检测
数据挖掘作为近几年热度较高的一种数据处理方法,能够高效处理基数大且状态复杂的数据[25]。为了快速检测配电网中线损异常台区配变,引入数据挖掘构建数学模型,检测识别异常节点数据。采用LOF(局部异常因子)算法分析配电网10 kV线路节点电压、有功功率、无功功率等数据,初步定位含有异常线损数据的节点。
分别设定节点r的电压、有功功率、无功功率数据的时间序列数据集Ur(e)、Pr(e)、Qr(e),Ur(e)、Pr(e)、Qr(e)分别表示第r节点第e日的电压数据、有功功率、无功功率。通过LOF算法给每个数据分配一个依赖于相邻区域密度的离群因子的离群程度值,计算每个数据周围数据点的平均密度与该数据密度的比值,通过LOF值来判断数据点是否为异常数据[18,24]。以有功功率数据集Pr(e)为例,第e日有功功率数据的局部可达密度ρk(e)和LOF值Fk(e)计算公式为:
式中:Nk(e)为数据e的第k距离邻域;dk(e,f)为第e日有功功率数据与第f日功率数据的欧式距离;v1(e)和v1(f)分别为第e日和第f日功率数据的编号;v2(e)和v2(f)分别为第e日和第f日的功率数据。第e日功率数据的ρk(e)越低,其LOF值越大。当第e日功率数据是离群数据时,则其ρk(e)小而其邻域数据ρk(e)较大;若e为簇中数据,则数据e与邻域数据的ρk(e)相差小,其LOF值接近1。因此,采用LOF算法可以消除簇间密度差异带来的影响,通过判断Fk(e)大小来确定数据是否离群。
2 分割区域的分割原则
为实现电网运行的在线监测及运维管理,电网公司通常会将现有电网分为若干子区域,实行分区治理,提高计算速度[26]。线损管理可细分为“四分”管理线损率,即分压线损率、分区线损率、分元件线损率和分台区线损率,中压配电网的线损管理采取分线、分台区管理。传统基于“四分”管理的中压配电网线路异常数据通过线路前推回代法和潮流计算得到,但台区和终端采集数据量庞大,导致计算量较大且精度难以控制。为加强中压配电网线路异常数据修复效率和精度,提出基于分割区域的估计模型修复异常数据的方法。
2.1 基于GN算法的节点分割
GN(Girvan-Newman)算法是一种经典的社区发现算法,最初由Michelle Girvant和Mark Newman提出。为实现分割区域内异常数据修复,需要先对异常节点分割区域,但由于每台配变之间存在连接关系,不能直接通过是否相邻来确定区域划分的结果。为此,采用GN算法实现各异常节点初步分区,划分为区域内耦合程度高、区域间耦合程度弱的区域。
GN算法首先需对台区异常配变之间的连线进行删除,该过程应保证先删除区域之间的连线,后删除区域内的连线[27]。其次,将所有目标配变节点初始化为各个独立区域,再判断各区域是否可合并成新区域,并将模块度M作为分割区域合并过程的指标,若模块度M增加则可行。最后多次迭代合并区域步骤,直到模块度M达到最大,停止区域合并,得到区域划分结果。
模块度M的计算公式为:
式中:C为配电网络分割区域;Si,j为分割区域内异常节点集合;ci和cj分别为异常节点i和j所属的区域;δ(ci,cj)为0-1变量,若节点i和j属于同个区域,则δ(ci,cj)取1,否则为0;ki为节点i的度,即与节点i相连的所有边的权重之和;kij为连接节点i和j的边权重;m为网络中所有边的权重之和。网络模块度M可以看作各区域的模块度之和,M的取值范围为(-1,1),其值越大,说明区域内连结越紧密。
模块度M是评价区域划分的指标,模块度越大,区域划分的效果越好。在计算模块度时,需要节点间的连接权重数据kij,节点i和j相距越远,边权重越小。kij的计算公式为:
式中:Lij为节点i和j之间的距离;L1和L2为设定的线路距离阈值。
2.2 分割区域动态调整
由于节点数据异常与相邻节点数据存在关联关系,可结合线路拓扑关系调整区域规模,实现区域内正常节点数据对异常节点数据的修正。
2.2.1 分割区域动态调整策略
利用线路拓扑关系和基尔霍夫定律对异常数据进行判断是比较可靠、精准度较高的方法。但直接结合电网拓扑关系和基尔霍夫定律的异常数据识别方法工作量巨大,只适用于样本数据较少的情况,对于数据量较大的线损管理系统的异常数据辨识难度大、周期长[28]。
为了能够结合线路拓扑关系实现对异常数据的辨识及修正,采用LOF算法初步识别筛选出异常节点并基于GN算法分割区域,分析各分割区域的拓扑信息,收集区域邻近节点、线路的运行数据,判断是否满足异常节点数据修正条件,动态调整区域规模。
分割区域调整如图1所示,存在包括异常节点5和3的分割区域,结合线路拓扑可判断节点1、6、2、7的数据可修正节点5和3的异常数据。若节点6量测数据满足节点5异常数据的修正条件,则扩大区域至节点6;若节点6量测数据缺失,不满足对节点5数据的修正条件,继续扩大区域至节点6的子节点1,通过节点1与节点6、节点6与节点5的关联模型来修正节点5的异常数据。同理,对异常节点3可采取相同策略进行区域调整,直至满足区域停止调整条件。在区域动态调整过程中存在某节点同时划分到两区域的情况,为满足区域内部耦合较强、区域间耦合较弱的条件,将含有相同节点的区域融合。

图1 分割区域调整Fig.1 The segmented region adjustment
2.2.2 分割区域停止调整条件
通过GN算法实现了对异常节点的分割,为满足分割区域内异常数据的自动修正,需要动态调整分割区域,将区域扩大至邻近正常节点,通过邻近正常节点数据和节点间关联度模型校正异常节点数据。若区域内满足实现异常数据修正计算的可观性,则停止分割区域动态调整;反之,则充分考虑相邻近节点数据的信息,扩大分割区域范围,直至分割区域内异常数据可实现全部校验计算。
为判断区域分割结果是否满足区域异常数据修正计算可观性条件,设立复杂配电线路的配变异常节点分区模型中区域量测冗余不平衡度指标G[29]:
式中:b为区域个数;ηa为第a个分割区域的量测冗余度;ma为第a个分割区域的量测量个数;sa为第a个分割区域的状态量个数。通过量测冗余不平衡度指标能有效判断区域估计的可观性和数据估计精度。该指标数据越小,表示分割区域量测冗余度不平衡度越低,各分割区域的估计数据与真值的偏差值越相近,分区越合理[30]。
3 分割区域异常数据辨识及修正模型
3.1 基于卡尔曼滤波的冗余数据融合
通过SCADA(数据采集与监视控制)系统和AMI(高级量测体系)采集的量测数据存在缺失、异常和冗余,为实现异常数据自动辨识,需要对缺失和冗余的数据进行预处理。缺失数据可采用数据填补的算法进行修正。要将实际的量测数据从含有噪声、谐波的冗余电力信号中分离出来较为困难,因此采用基于卡尔曼滤波的数据融合技术对冗余数据进行预处理[31-33]。
卡尔曼滤波过程具体分为预测和校正两部分,预测方程为:
式中:k表示当前时刻,k-1表示上一时刻;为k时刻先验状态量;为k-1时刻后验状态量;A为上一状态到当前状态的状态转移矩阵;B为控制输入到当前状态的状态转移矩阵;uk为控制输入矩阵;为先验估计误差协方差矩阵;Pk-1为后验估计误差协方差矩阵;Q为过程噪声协方差矩阵。
校正方程为:
式中:Kk为卡尔曼增益矩阵;H为量测矩阵;R为量测噪声协方差矩阵;zk为k时刻量测量;I为单位矩阵。
通过卡尔曼滤波可以得到当前时刻系统所需的估计值,该估计值存入系统数据库中,并通过该数据预测下一时刻的状态量。
3.2 分割区域异常数据修正
基于区域内正常节点与异常节点的关联度模型和量测模型,通过区域间的分支线路前推回代对各区域异常数据进行计算修正,可有效提升修正精度和速度。
1)量测方程。通过对异常节点定位和分割,将完整的10 kV线路和线路节点分解为S个区域,用Sλ表示第λ个区域的节点集合,用I表示分割区域的内部节点集合。
若分割区域Sλ内节点r存在邻近节点(jj=1,2,…,β,j∈I),其功率平衡关系可表示为:
式中:Pr和Qr分别为节点r注入的有功功率和无功功率;Ur和Uj分别为节点r和j的电压幅值;δrj为节点r和j之间的相位差;Grj和Brj分别为节点r和j间线路的导纳实部和虚部。
化简式(12),可得到节点之间的电压数据量测模型,通过区域内正常节点修正区域内异常节点,节点r存在β个邻近节点,则节点r的电压Ur可表示为:
式中:Prj为节点r和j之间线路的有功功率;Irj为节点r和j之间线路的电流。
2)等式约束。分割网络内异常节点负荷功率应满足如下的潮流方程[34]:
式中:Ω为节点r连接的节点集合;PDGr和QDGr分别为节点r的分布式电源系统输出的有功功率和无功功率,若节点无分布式电源接入,则PDGr=0,QDGr=0;PDr和QDr分别为节点r的有功负荷和无功负荷。
3)估计模型。估计模型是提升量测量和状态量接近程度的优化过程,基于加权最小二乘法的优化目标[35]为:
式中:x为节点r的状态量;ξ为分割区域内节点个数;Rr为网络分割后各区域协方差对角矩阵;Zr为分割后各区域量测量向量;Xr为网络分割后各区域的状态量向量;hr(Xr)为网络分割后各区域量测模型;cr(x)为网络分割后各区域的等式约束条件;gr(x)为网络分割后各区域的不等式约束条件。
3.3 分割区域异常数据辨识及修正策略
图2为分割区域数据辨识及修正流程。首先采用卡尔曼滤波算法对终端冗余数据进行融合,再通过LOF算法确定存在异常线损数据的节点配变;通过判断区域邻近节点的数据信息及区域不平衡度指标,动态调整区域边界,直至全部邻近节点满足校验计算,得到分割区域;最后建立区域内节点量测模型、约束模型和估计模型,通过区域内正常数据修复区域内异常数据。

图2 分割区域数据辨识及修正流程Fig.2 Data identification and correction process in the segmented region
所提分割区域异常线损检测修复方法具有内部耦合程度高、外部耦合程度弱、异常线损数据检测精度高等特点。该方法不仅有利于线损管理,还提高了配电网异常线损修正效率。
4 算例分析
为验证本文所提方法的有效性,以西北某省10 kV什新线和什金线为算例进行分析。如图3所示:什新线由35 kV什新站馈线接出,取其中19台配变(编号1—19);10 kV什金线由35 kV什新站接出,取其中17台配变(编号20—36)。
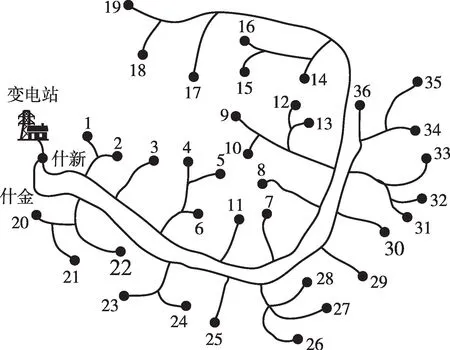
图3 10 kV什新线、什金线拓扑Fig.3 Topology of 10 kV Shixin line and Shijin line
10 kV线路中存在大型光伏电站接入的情况,光伏电站数据波动对线路线损值影响大。为验证分割区域划分模型的有效性,本文所采用的分布式电源数据均为正常值,且在分割区域划分时不包括光伏电站,单独分析光伏电站运行数据。
在异常数据辨识和分割区域划分前,采用卡尔曼滤波算法对存在多组量测值、信号噪声较大的赵家阳山配变对量测值进行滤波和融合。
赵家阳山配变96点采样数据测量值和滤波值如图4所示,相对误差如图5所示。功率量测值1、量测值2经卡尔曼滤波后,去除了多余噪声,并对多组量测数据进行了融合,得到的滤波值与真实值曲线相似度更高。量测值1的平均相对误差为0.535,量测值2的平均相对误差为0.922,滤波值的平均相对误差为0.391,滤波值与真实值之间的相对误差明显减小。综上,卡尔曼滤波算法可有效将实际的量测数据从含有噪声、谐波的复杂电力信号中分离出来,减小其与真实值的相对误差。
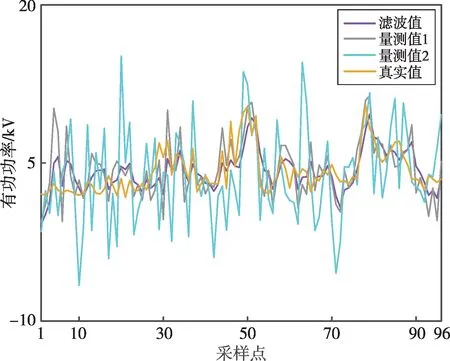
图4 赵家阳山配变96点数据滤波图Fig.4 Filter diagram of the data at sampling point 96 of distribution transformer at Zhaojiayangshan
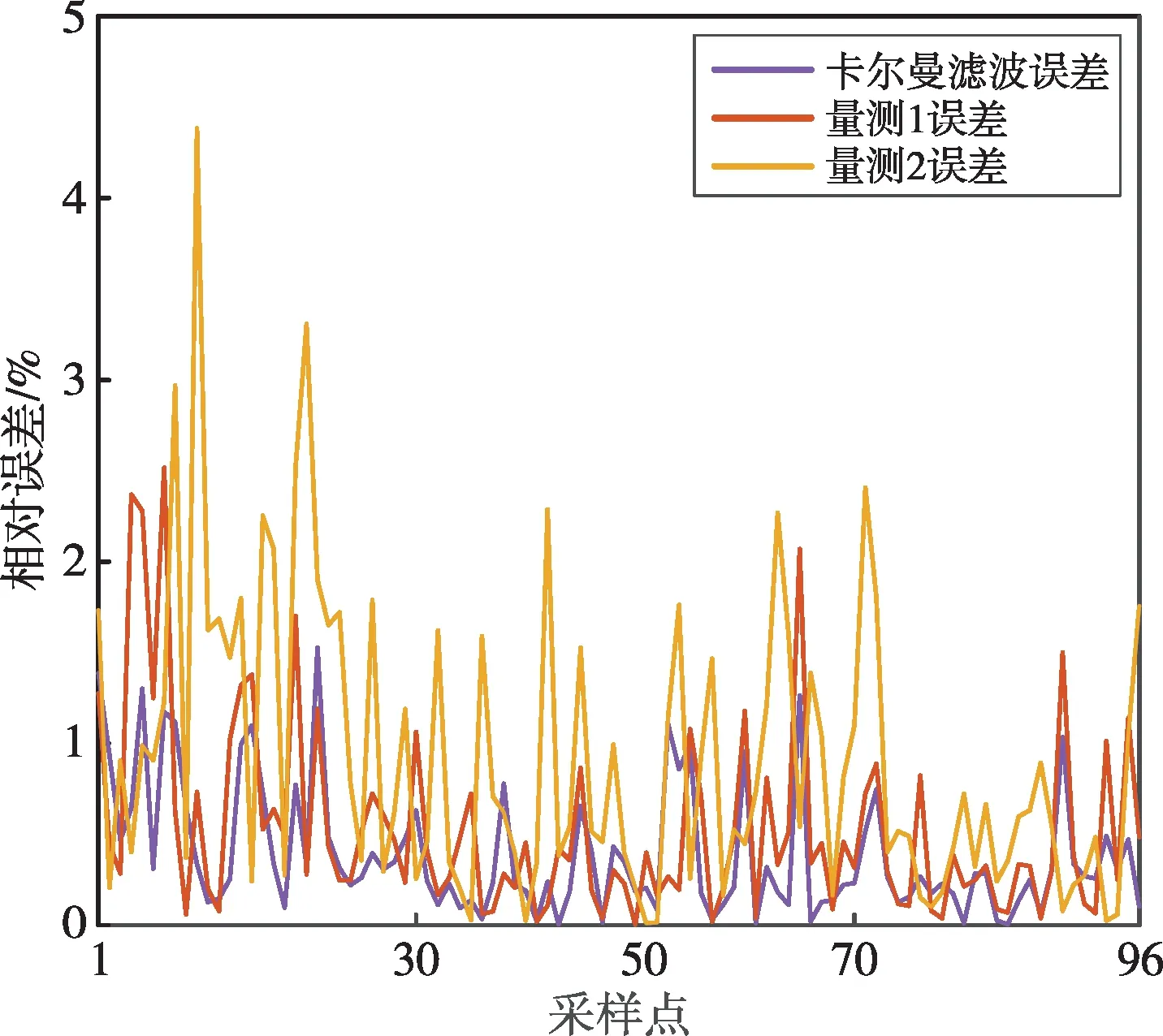
图5 卡尔曼滤波前后相对误差图Fig.5 Diagram of relative errors before and after Kalman filtering
对10 kV什新线和什金线各节点配变台区馈线出口2022年4月9日采集的电量、有功功率和无功功率数据进行预处理,并采用LOF算法进行检测,选取阈值为1.8,结果如图6所示。
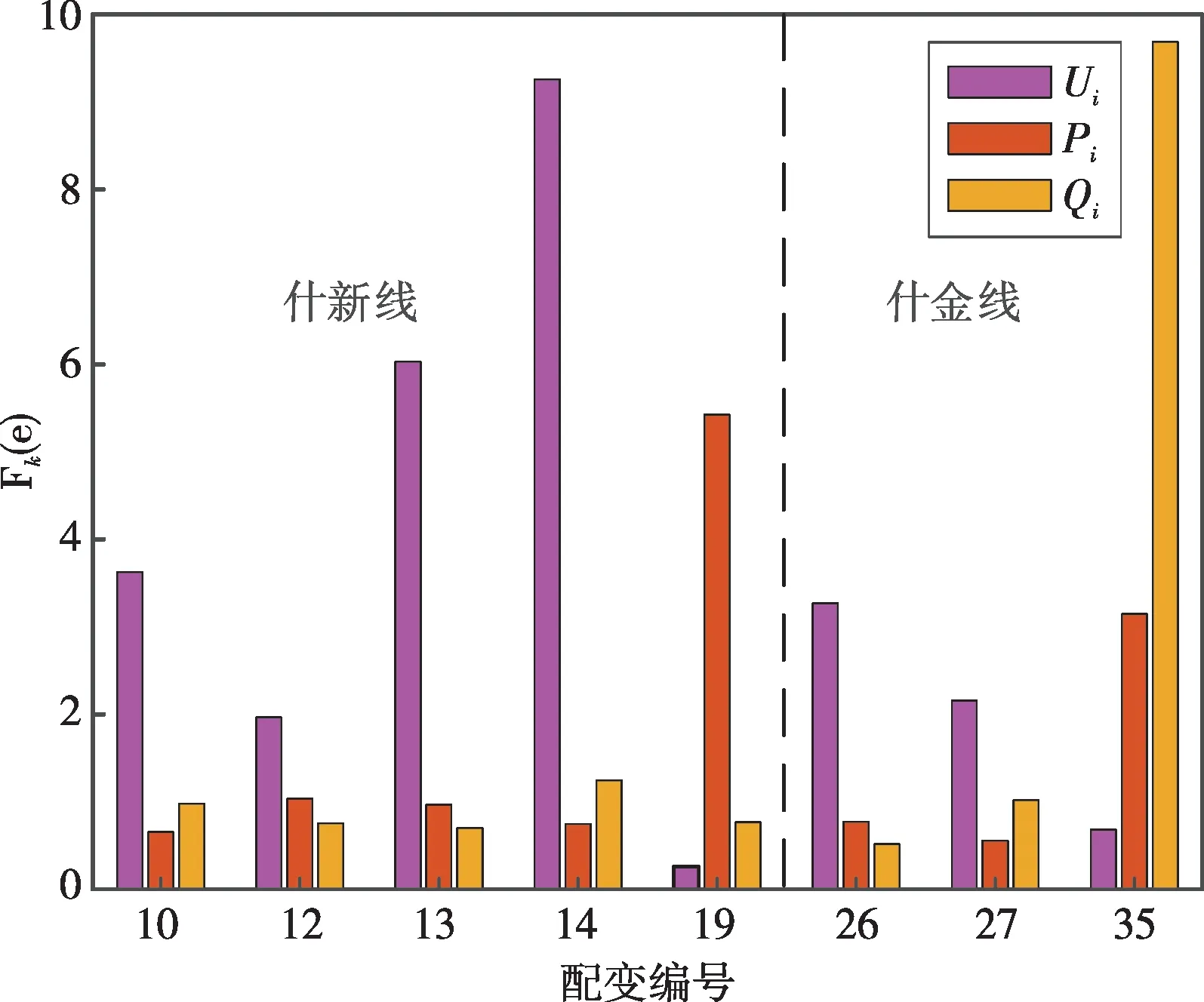
图6 线损数据LOF值Fig.6 LOF values of line loss data
从图6中看出:2022年4月9日什新线异常电压数据的配变节点为10、12、13、14,异常有功功率的配变节点为19,其中13、14、19的LOF值较高,离群程度较大;什金线异常电压数据的配变节点为26和27,异常无功功率、有功功率的配变节点为35,其中35的LOF值较大,离群程度较大。
采用GN算法计算,通过确定合适的连接阈值来建立节点连线,得到划分结果如图7所示。结果表明,什新线中配变节点10、12、13划分为同一区域,26和27划分为同一区域,19和35各自单独划分为一个区域。
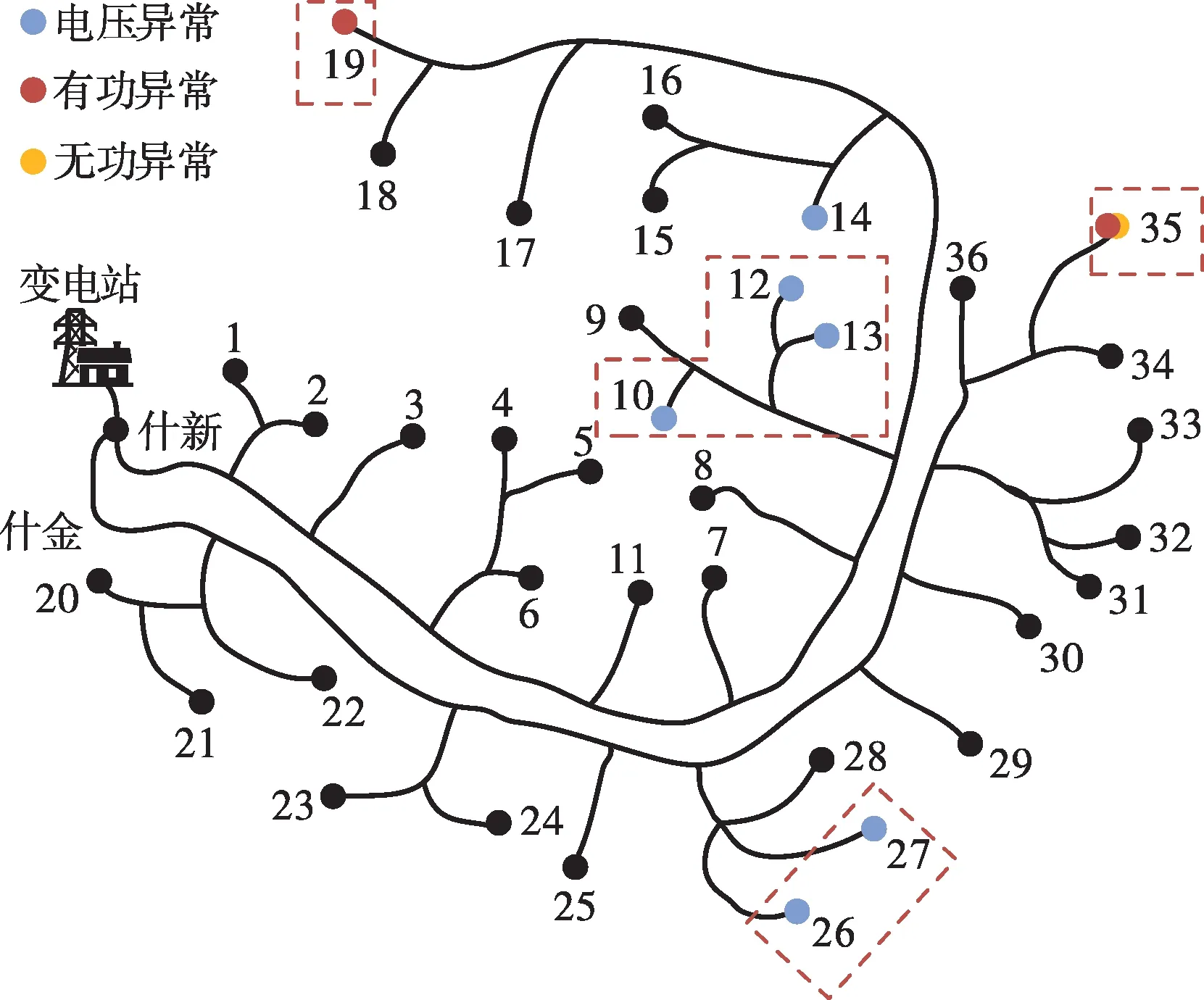
图7 异常配变划分结果Fig.7 Segmentation results of anomalous distribution transformers
基于分割区域调整策略扩大、融合区域,在区域动态调整中,通过计算区域量测冗余不平衡度指标,得到最优分区方案,如图8所示。此时,不平衡度指标G=2,若分割区域继续扩大,不平衡度指标G会增大,在G=2时目标函数最小,此时的分区方案为最优分区方案。图8中配变节点9、10、12、13划分为同一区域,26、27、28划分为同一区域,19和18划分为同一区域,34和35划分为同一区域。
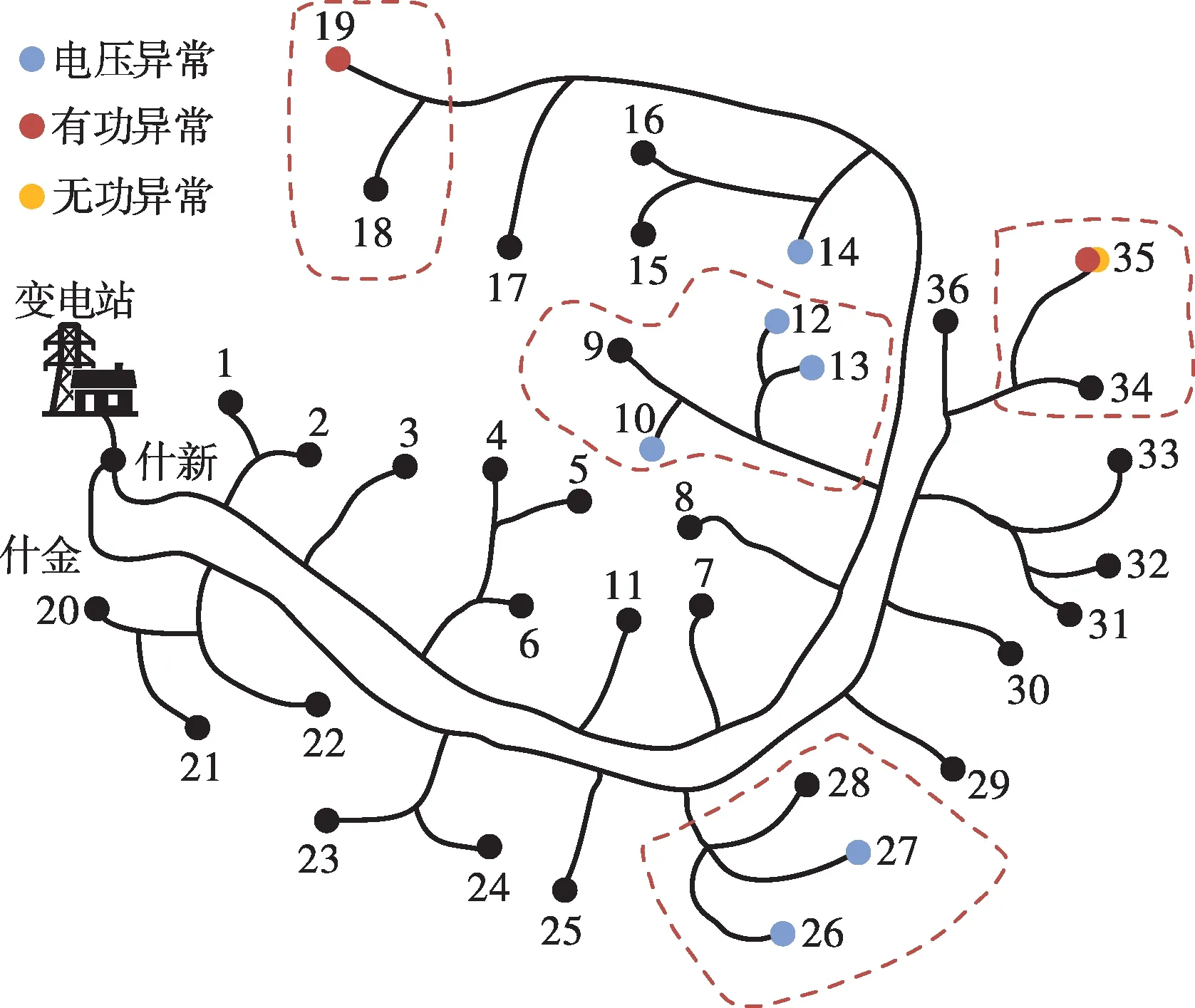
图8 分割区域最终划分结果Fig.8 The final division results of the segmented regions
选取什新线节点19和什金线节点35的A相有功功率的估计值和真实值进行对比分析,如图9所示。图9(a)中有功功率数据估计值和量测值的96点平均绝对误差为0.242 kW。图9(b)中有功功率数据估计值和量测值的96点平均绝对误差为0.014 kW。综上,基于分割区域的异常数据修正具有较高的精度。
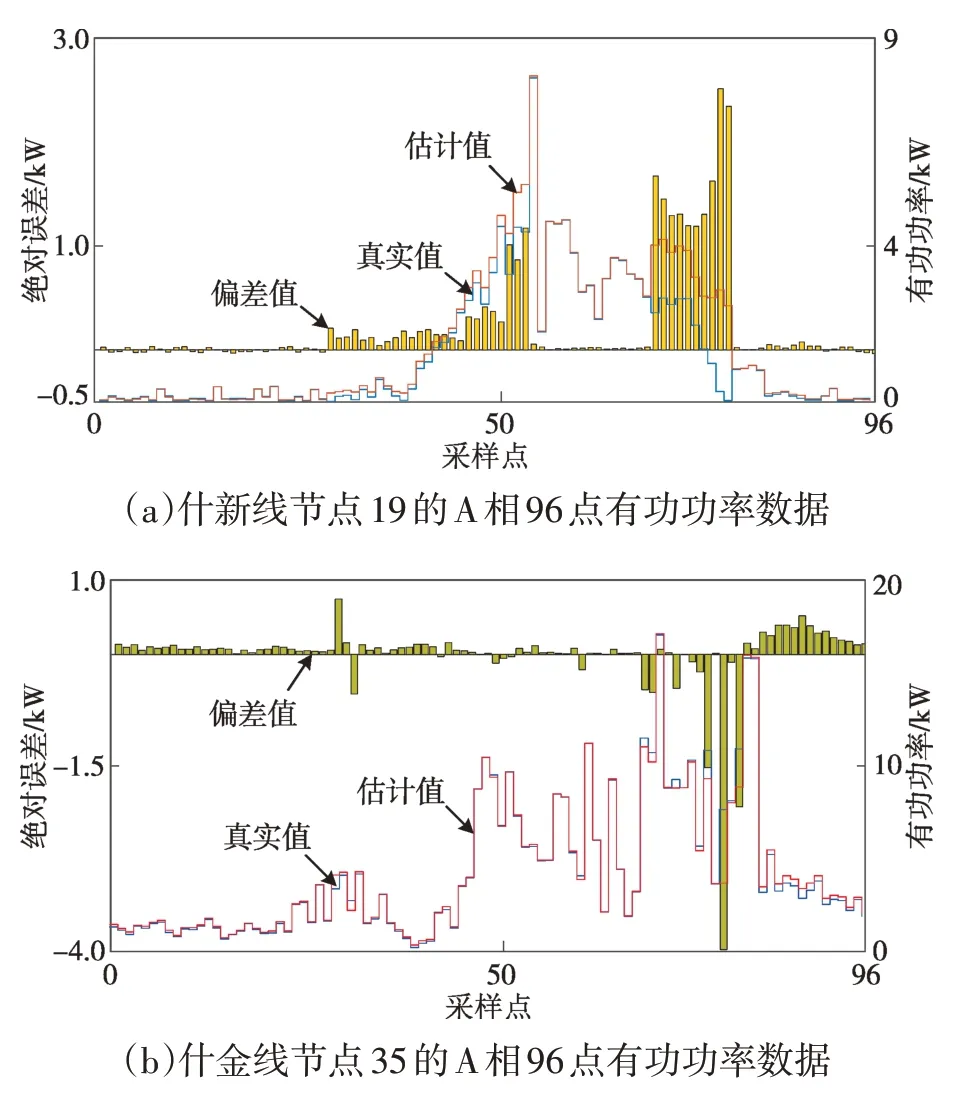
图9 A相96点有功功率数据Fig.9 The active power data at sampling point 96 on phase A
收集10组异常有功功率数据,分别采用分割区域估计和LSTM算法进行修正,修正结果与真实值比较并求误差值,修正结果如图10所示。根据图10可知,其中2组数据LSTM算法误差明显较小,6组数据分割区域估计算法误差明显较小,2组数据两种方法误差接近。
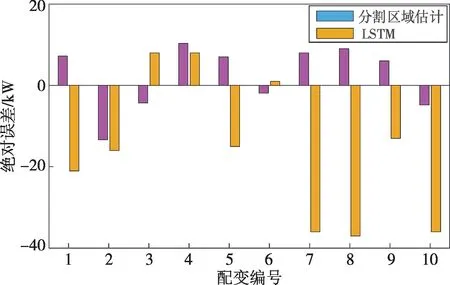
图10 异常数据修正结果误差对比Fig.10 Comparison of errors of the corrected anomalous data
统计分割区域估计算法与LSTM算法修正时间和RMSE(均方根误差),其中LSTM算法修正时间包括训练时间和预测时间,结果如表1所示。和LSTM算法相比,分割区域估计算法平均估计时间降低了40%,RMSE降低了23.7%。综上,分割区域估计算法能有效提高估计精度并减少时间成本。

表1 两种方法的修正时间和精度对比Table 1 Comparison of the correction time and accuracy of the two methods
5 结语
本文提出基于分割区域的配电网异常线损数据辨识与修正技术,并将其应用于西北某省10 kV什新线、什金线进行验证,得到以下结论:
1)由于配电网中台区配变数量大、分布广,配变数据修正工作量大且检验周期长。依托配电网实时检测平台采集的大量基础数据,剔除长期高负损台区配变,并采用LOF算法对运行数据进行辨识,初步定位异常节点配变,能有效避免长期高负损台变对LOF算法异常数据辨识的影响,提高异常数据识别效率。
2)分割后各区域异常数据类型特征明显,区域间耦合关系弱,有利于实现异常数据的快速修正。通过卡尔曼滤波对终端冗余线损数据进行预处理,基于线路节点量测模型、等式约束和估计模型对分割区域失真数据进行修正,能在获得较高精度的同时减少时间成本。
3)所提方法中所需基础数据和指标均充分考虑数据获取难度和对台区线损率的贡献度等因素,模型具有一定的实用性和可操作性,可强化线损精细化管理,提升经营效益。
