改进YOLOX-s算法的自动贩卖机商品检测方法
2023-10-30张少林姜吴瑾李太福
张少林,姜吴瑾,李太福,杨 杰
1.重庆科技学院 电气工程学院,重庆 400030
2.重庆科技学院 安全工程学院,重庆 400030
3.重庆工贸职业技术学院 人工智能学院,重庆 408000
4.重庆新制导智能科技研究院有限公司,重庆 400000
随着经济水平和互联网技术的不断向前发展,以自动贩卖机为代表的新零售方式已成为写字楼、商超中的常客,它极大地提高了商品交易效率,为顾客提供了方便、快捷的购物选择。在新冠疫情常态化防控的当下,自动贩卖机也以无接触式、快捷式售卖方式降低了消费者感染风险。现阶段常用的自动贩卖机通常使用RFID技术对商品进行识别,此技术对每样商品贴上电子标签,通过RFID 技术读取商品的详细信息,然后进行商品价格结算[1]。但此种方法成本较高,需要给每件商品人工张贴标签,无法大规模应用到自动贩卖机中,研究人员考虑用深度学习目标检测的方法来处理商品检测问题[2]。
自2012 年Hinton 等人[3]在ImageNet 大赛中提出AlexNet模型以来,深度学习网络模型得到了长足发展,科研人员提出的越来越多的卷积神经网络模型已广泛地应用于图像目标检测领域之中。目前,基于深度学习的目标检测算法主要包括两类,一类是以R-CNN[4]、Fast R-CNN[5]、Faster R-CNN[6]为代表的two-stage检测算法,其主要方法是先生成一系列候选框,然后根据候选框进行目标分类识别工作,相比较于one-stage 系列检测算法,two-stage 算法检测精度普遍较高,但是检测速度相对较慢,在实时检测性能上边表现较差。另一类是以YOLO系列算法[7-9]以及SSD[10]系列算法为代表的one-stage算法,此类算法检测速度较快,能够满足实时检测的需求,但是整体检测准确率相对较低,仍具有较大的提升空间。近年来,在通用目标检测领域,以Transformer框架为核心的算法逐渐成为研究主流[11],但此类算法模型普遍较大,无法满足自动贩卖机商品检测任务中对模型轻量化、实时性的需求。而以YOLOv4、YOLOv5、YOLOX 为代表的模型以轻量化的模型大小、较为迅速的检测速度和相对精确的识别精度,成为解决目标检测模型轻量化问题的重要抓手,其中YOLOX模型凭借其在目标检测工作上优异的检测速度和检测精度,赢得了越来越多研究人员的青睐。
在针对自动贩卖机商品检测的研究之中,科研人员已经做了大量的工作。刘照邦等人[12]则针对商品检测问题对RetinaNet 通用目标检测框架做出改进,提出用A-Softmax 替换传统SoftMax 函数,改进模型对场景形态和商品相似性的容忍度有了较大改进,提升了商品目标识别效果。Ji等人[13]针对商品小而密的特征提出了一种名为CommodityNet 的one-stage 框架,在自建数据集SDOD-MT上取得了卓越的性能。此外,刘文豪等人[14]提出了一种基于SSD模型和YOLOv3模型的半监督模型,采用self-training 方式充分利用大量无标签数据来提高模型的特征学习能力,相比于基准模型,改进模型的检测精度得到了显著提升。
上述方案主要针对商品检测任务中数据量少、鲁棒性差、数据分布密集等问题提出改进方案,而由于自动贩卖机中摄像头拍摄角度是俯视角,商品目标特征信息较少,且商品之间互相遮挡造成对商品的特征提取较为困难,此外图片边缘部分图像畸变严重,造成部分特征损失,对商品的识别造成一定的困难。此外,出于成本考虑,自动贩卖机对模型计算量和大小容忍度较低,选用模型须保持轻量化和低计算量。针对上述问题,本文在目前综合性能较好的YOLOX-s 算法上进行改进,在进一步提高识别准确率的同时,保持原模型的轻量化和检测速度,本文主要改进点如下:
(1)针对YOLOX-s 中PAFPN 网络特征融合过程中容易丢失浅层网络信息的问题,采用改进后的双向特征金字塔网络(BiFPN-m)重构原始特征提取网络,在不增加额外损失的同时,将浅层网络与深层网络直接进行融合,增强不同网络层的特征信息传递,从而增强整个模型的特征提取能力。
(2)针对采用BiFPN网络重构后模型规模大幅度增加、计算量增加明显等问题,借鉴Ghost 卷积[15]思想,利用少量的卷积核对输入进行特征提取,然后将特征图进行线性运算,通过Concat 模块拼接生成最终的特征图,此方法可以有效地降低模型计算资源,且能保持模型性能。
(3)为了让模型更好地提取目标关键特征,本文借鉴注意力机制思想,经过充分实验论证,将CBAM[16]引入CSP3模块中,赋予重要特征更高的权重,以增强模型的目标识别能力。
经过在自动贩卖机商品检测数据集上进行实验,与原始YOLOX-s 网络模型相比,改进后的模型牺牲了部分检测速度,但在mAP指标上提升了1.91个百分点,达到了99.57%的识别准确率,且模型大小基本保持不变,在能够更加精确地识别出饮料贩卖机中饮料类别的同时,保持了模型的轻量化和较快的检测速度,能够满足自动贩卖机实际应用的使用要求。
1 基于YOLOX-BGC的商品检测网络
1.1 YOLOX-s网络
YOLOX-s网络是由Ge等人[9]于2021年提出的YOLO系列网络模型,其主要由输入端、主干网络(Backbone)部分、特征提取网络(Neck)和用于结果预测的检测头(YOLO Head)等四部分构成。与YOLOv5-s 相比,YOLOX-s 网络模型在多个部分做出了优化和改进。YOLOX-s网络模型基本结构如图1所示。
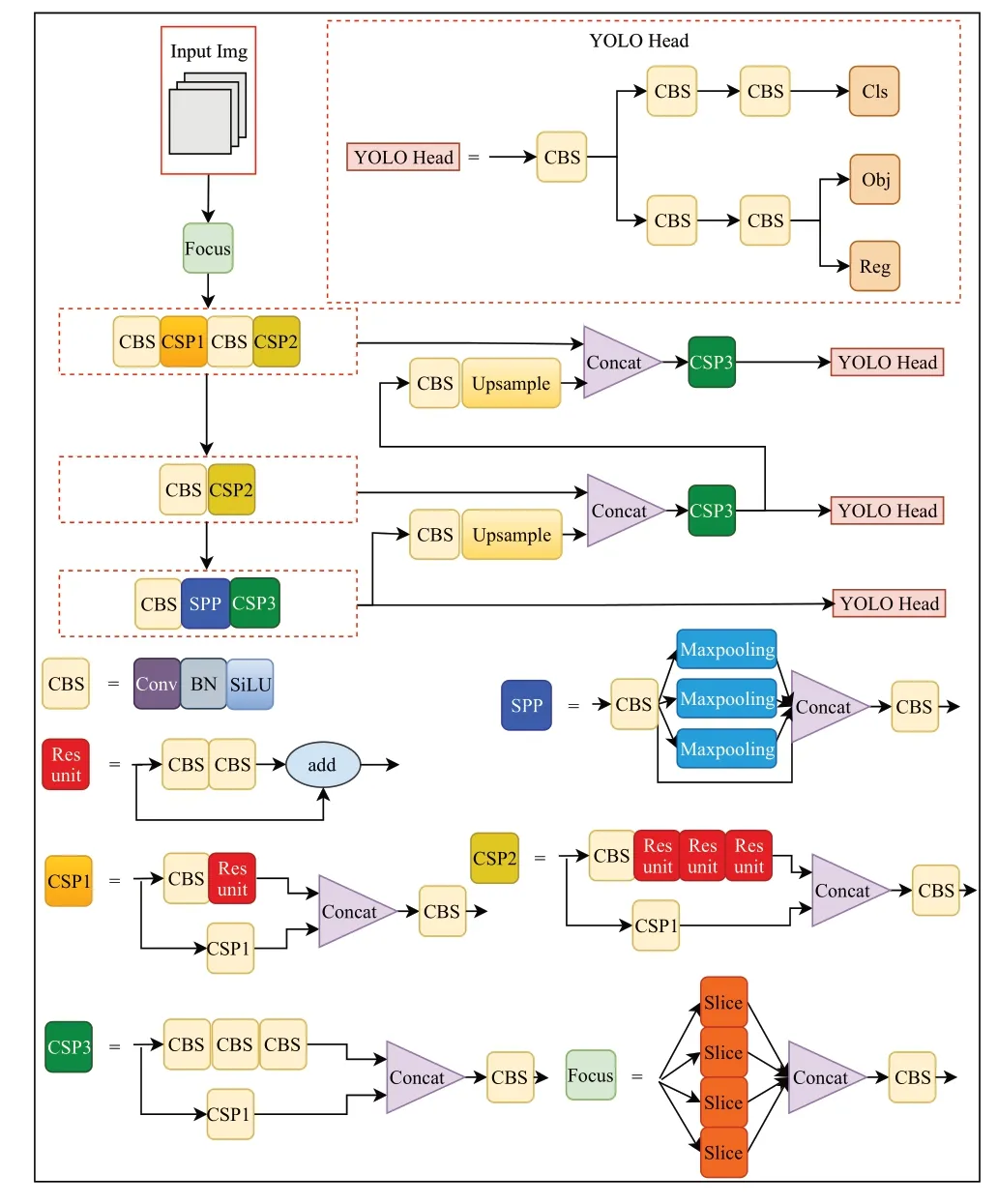
图1 YOLOX-s网络结构图Fig.1 Structure of YOLOX-s network
在输入端部分,使用MixUp方法将不同输入图片按照一定比例生成新的图像,同时生成对应标签,在后续训练过程中采用新的图片和标签进行训练,而原始图像不再参与训练。此外,采用Mosaic 方法将四张输入图片拼接到一起,使模型可以一次训练4 张图,此种方式可以极大地丰富目标背景,一定程度增强网络模型的鲁棒性。
在BackBone 部分,沿用YOLO 系列的CSPDarkent结构,整体结构主要包含4 个部分,分别是Focus 模块、CBS模块、CSP1模块、CSP2模块、CSP3模块和SSP模块。
在Neck 层部分,采用FPN+PAN 的级联结构,其中FPN采用自上而下的方式,将浅层信息与深层信息进行信息融合,传递目标语义信息。PAN则采用自下而上的方式,将深层信息传递给浅层部分进行融合,传递目标位置信息。
在YOLO Head部分,开创性地提出Decoupled Head解耦头,提高了整体模型的收敛速度和精度,有利于YOLOX-s 实现端到端化,也便于下游任务一体化。此外采用Anchor Free 方式进行目标框的标注,实验证明相较于YOLOv3、YOLOv4、YOLOv5 中采用的Anchor Based 方式,Anchor Free 在减小计算量的同时,能显著提高模型最终识别准确率。
作为端到端的目标检测模型,YOLOX-s 网络通过PAFPN网络可以满足对不同尺度特征图进行目标检测,浅层网络检测小目标,深层网络检测大目标,但是在浅层网络到深层网络的特征融合过程中,特征图容易丢失一些重要的特征信息,对此本文提出了相应改进方案。
1.2 BiFPN网络
原始YOLOX-s模型在Neck层采用PAN+FPN的方式实现浅层和深层网络的特征融合,而BiFPN网络相比于PAN+FPN 可以获得更高级的特征融合方式,它可以增加各尺度特征的耦合,特别是有助于小目标检测的浅层特征[17-18]。此外,由于BiFPN采用了跨尺度连接方式,可以对不同检测特征按照跨尺度权重进行抑制或者增强特征表达,从而缓解因检测目标重合导致的识别不准确问题。FPN网络、PAFPN网络和BiFPN网络结构图如图2所示。
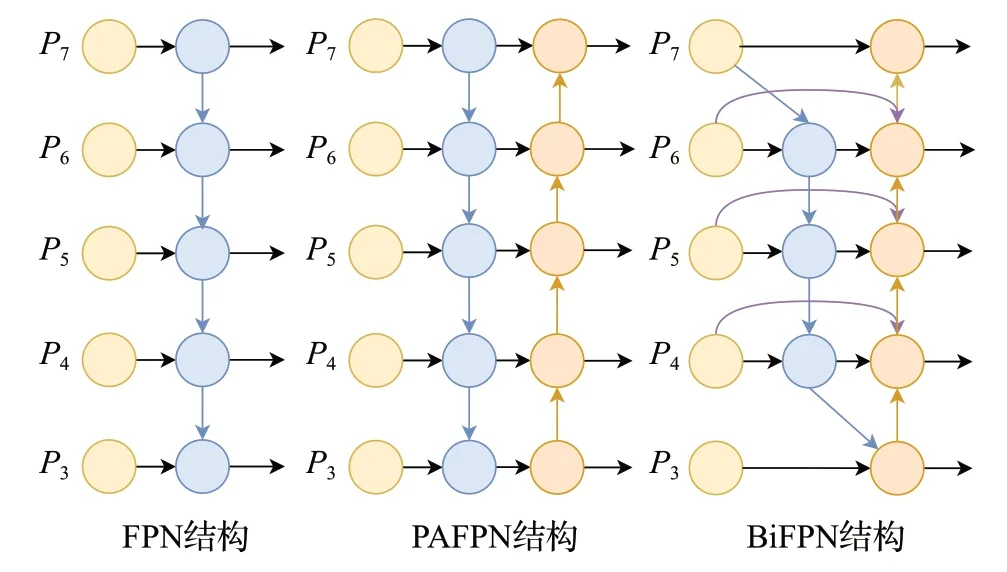
图2 三种特征金字塔结构对比Fig.2 Comparison of structure of three network
原始YOLOX-s模型仅会将主干网络的3层深层特征输入Neck层进行特征融合。受钟志峰等人[19]研究成果启发,本文将原始BiFPN 网络结构简化为3 层结构(记为BiFPN-m),此步骤可将BiFPN 融入YOLOX-s 网络结构,在减少模型计算量的同时实现对同级节点最大程度的特征融合,具体网络结构如图3 所示。相比于5层BiFPN网络,BiFPN-m网络的特征融合方式可以降低浅层特征中噪声对模型精度的干扰,显著降低模型计算量,并提高模型检测速度。后续实验也验证了多尺度特征输出层数的改进对算法整体检测效果,相比于5 层BiFPN 网络,将BiFPN-m 模块融入网络模型中,能够以更快的检测速度、更小的模型、更少的参数量得到更好的检测精度。
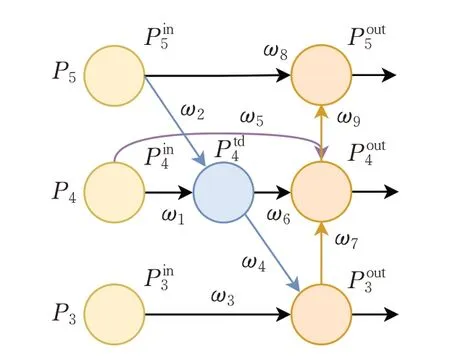
图3 BiFPN-m网络结构图Fig.3 BiFPN-m network structure
在BiFPN-m 结构中,P3~P5是从主干网络层传入的不同特征尺度的输入,每个输出节点的数学表达式如式(1)~(4)所示:
1.3 Ghost卷积模块
Ghost卷积是Han等人[15]在2020年CVPR会议上提出的一种稀疏卷积层网络,其基本结构如图4所示。对于一个输入特征图,Ghost 卷积先采用原始卷积得到m个特征图,然后利用分组线性运算得到n个Ghost 特征图,最后通过简单的Concat 拼接操作输出最终的n×m个特征图,传统卷积和Ghost 卷积的参数量分别为S1、S2,两者参数量之比为S1/S2,其中c表示输入图像通道数,k·k表示传统卷积核的大小,d·d为线性运算卷积核的大小,最终通过比较可以得到Ghost卷积运算所用参数计算量约为传统卷积的1/n。

图4 Ghost卷积网络结构Fig.4 Structure of ghost convolution network
1.4 注意力机制CBAM模块
CBAM(convolutional block attention module)是由Woo等人[16]在注意力机制理论和SENet研究基础上,提出的一种新的注意力机制模块。相比于SENet 模块通过学习的方式获取输入端每个通道的重要程度,CBAM 模块则同时关注输入数据在空间和通道两个方面的重要程度,从而更好地提升整个网络模型的性能。自注意力机制模块提出以来,许多科研人员将其添加进网络模型以提升模型效果[20-21],进一步证明了模块的有效性。CBAM模块包含channel attention module(CAM模块,图5)和spatial attention module(SAM 模块,图6)等两个部分,其基本原理如图7所示。

图5 CAM网络结构Fig.5 Structure of CAM network
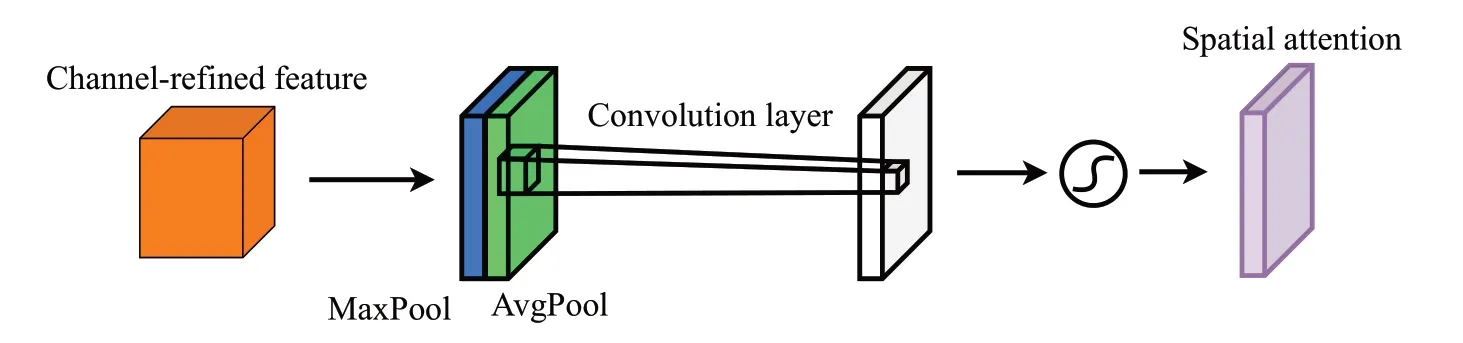
图6 SAM网络结构Fig.6 Structure of SAM network
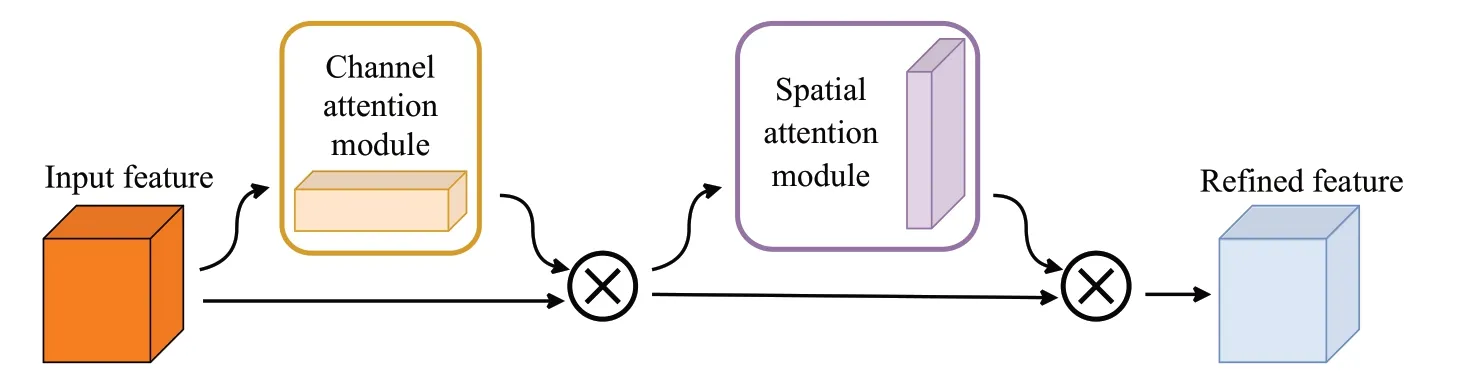
图7 CBAM网络结构Fig.7 Structure of CBAM network
CAM是针对特征图在通道维度上特征分布不均而提出的方案,用于强化重要特征的权重并弱化不重要特征的权重,具体方案为将输入特征图分别进行最大池化和平均池化操作,之后将两个输出分别经过MLP网络,将输出结果进行特征融合再经过sigmoid函数得到像素点权重,其基本公式如式(6)所示,其中MLP 代表两层神经网络,σ表示sigmoid激活函数。
SAM 则是讨论空间层面上输入特征图的内在关系,将CAM模块的输出结果沿Channel方向进行再次平均池化和最大池化,将两者结果经过卷积核为7×7大小的卷积层和sigmoid函数后得到SAM模块的特征图,其基本公式如式(7)所示,其中f n×n表示n×n的卷积运算,σ表示sigmoid激活函数。
WOO 等人[16]已通过实验证明,将注意力机制模块嵌入不同目标检测任务之中,可以带来较好的性能提升,但是将CBAM 模块嵌入网络结构的哪一部分没有具体的参考标准,所以本文将改进后的YOLOX-s-BG(YOLOX-s+BiFPN+Ghost 卷积)算法在主干网络CSP1和CSP2 模块内、特征提取网络的CSP3 模块内、主干网络与特征提取网络连接处、特征提取网络的CSP3 模块前分别嵌入CBAM 模块,探究其对网络性能的影响,从而产生了4 种网络模型,分别为YOLOX-s-BG-A、YOLOX-s-BG-B、YOLOX-s-BG-C、YOLOX-s-BG-D,具体位置如图8所示。
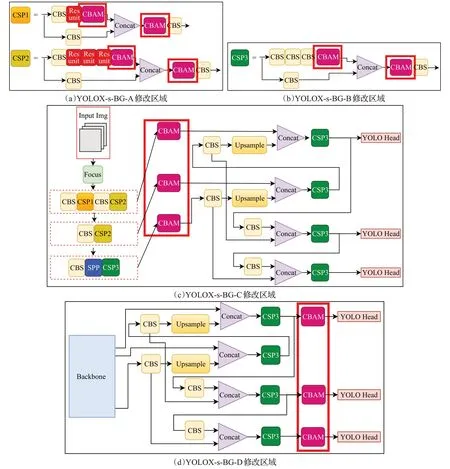
图8 四种嵌入CBAM模块后的YOLOX-s-BG模型Fig.8 Four YOLOX-s-BG models embedded with CBAM modules
图8(a)、(c)、(d)三种融合方案均是在特征融合过程中提取关键信息,但是在后续更深层次特征融合中仍会造成一定程度的特征损失,而将CBAM 模块融入CSP3 中能够同时在浅层和深层网络中提取重要特征,从而可以更好地为检测头提供更多的关键性信息,后续实验也证明,将CSP3中对应位置加上CBAM模块对网络模型精度提升较大,因此本文最终选取了此种方法作为最终网络模型,命名为YOLOX-s-BGC(BiFPN-m+Ghost卷积+CBAM),其网络结构如图9所示。
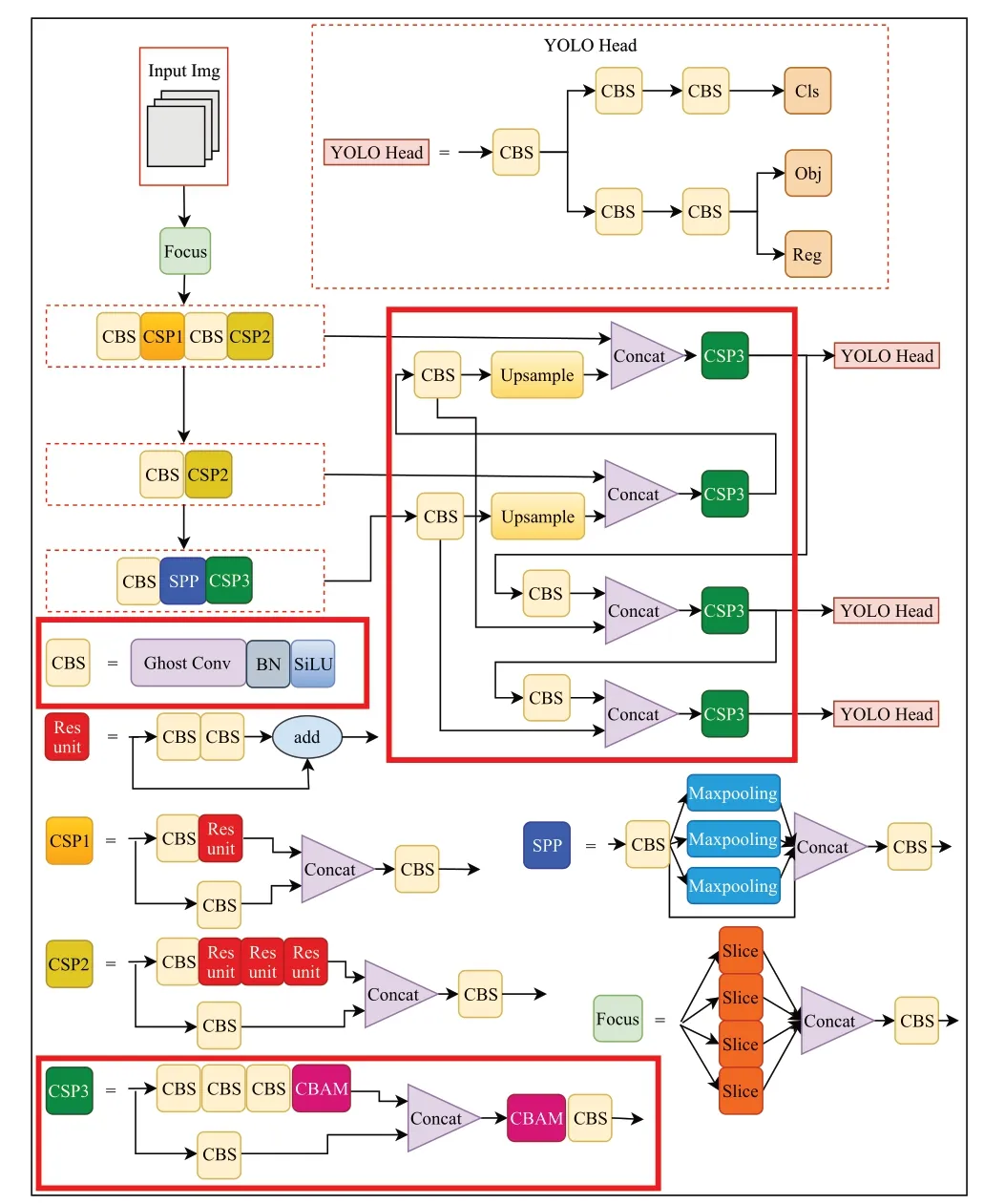
图9 YOLOX-s-BGC网络结构Fig.9 YOLOX-s-BGC network structure
2 实验
2.1 实验数据集
本文选用第六届信也科技杯图像算法大赛提供的自动贩卖机商品检测数据集,本数据集采用鱼眼摄像头拍摄,包含5 422张图片,已经按照7∶2∶1的比例分为训练集、验证集和测试集,数据集分布情况和数据集示例分别如表1和图10所示。
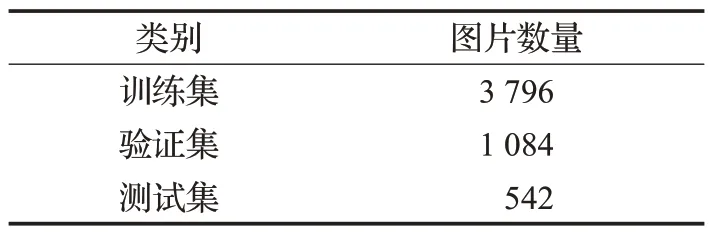
表1 数据分布Table 1 Data distribution

图10 数据集展示Fig.10 Dataset presentation
整个数据集包含了113 种自动贩卖机中常见的商品类型,商品数量分布较为不均。单张图片至少包含一个待检测商品目标,至多包含40 多个待检测商品目标。部分类型商品之间细粒度差异极小,仅存在颜色和包装文字的差异,对检测算法特征提取能力要求较高。此外,由于商品目标之间互相遮挡,数据图片边缘部分图像畸变严重造成部分特征损失,也给检测算法特征提取能力带来了一定挑战。
2.2 实验平台
操作系统为Ubuntu 20.04.1;处理器为AMD Ryzen 9 5900X 12-Core;GPU 为NVIDIA GeForce GTX 3090(24 GB);深度学习框架为Pytorch 1.12.0;利用CUDA 11.2 和cuDNN 8.1.1 加速训练;使用Python 3.7.2 作为主要编程语言。
2.3 网络训练
YOLOX-s-BGC网络初始化设置信息为:采用Mosaic和Mixup方式对图像数据进行数据增强,增强概率设置分别设置为0.5和0.7,epoch设置为150,batch_size设置为32,IoU阈值设置为0.5,运行线程数设置为4,选取的优化器为SGD。在实际训练过程中,初始学习率设定为0.01,最低学习率为0.000 1,采用余弦退火算法作为学习率降低的策略。
为评判模型的有效性,本文选取均值平均精度(mean average precision,mAP)、准确率(precision rate,P)、召回率(recall rate,R)、F1 值、每秒帧率(frame per second,FPS)、模型大小和参数量等七个指标作为模型的评估指标。其中P和R指标依赖于真正例(true positive,TP)、假正例(false positive,FP)、真负例(true nagetive,TN)和假负例(false nagetive,FN),P和R指标的计算公式如式(8)、(9)所示;AP 表示P-R 曲线的面积,FPSAP值越高表示模型准确度越高,mAP表示所有检测类别AP的平均值,AP和mAP的计算公式如式(10)、(11)所示。
训练过程中训练集和验证集的损失曲线如图11所示,训练集和验证集的loss值最终收敛于1.85和1.48。
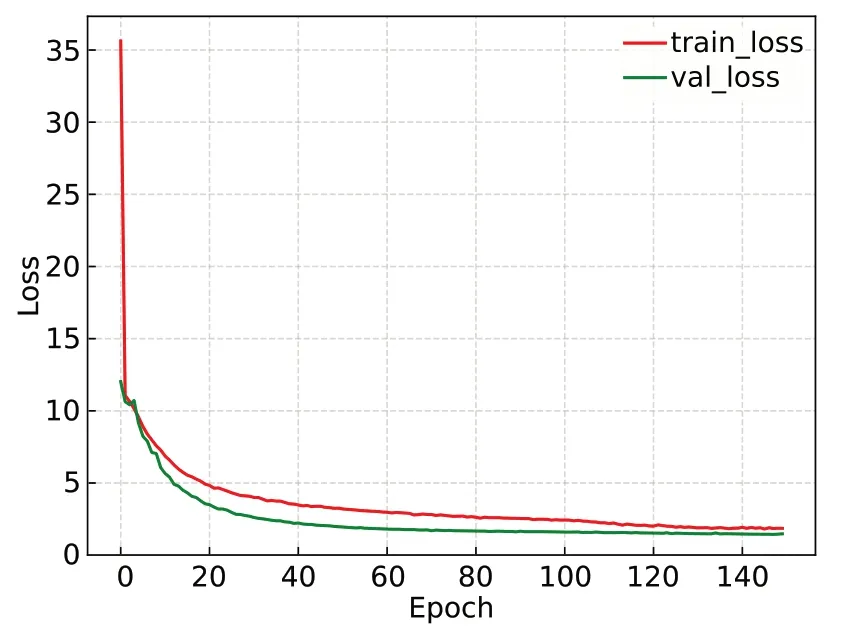
图11 Loss值下降曲线Fig.11 Decline curve of Loss value
3 实验结果与分析
3.1 改进特征提取层的实验分析
为了验证将5 层BiFPN 网络(模型记为YOLOX-s-B1)和3层BiFPN网络(模型记为YOLOX-s-B2)融入原始YOLOX-s 模型中特征提取层的效果,本文将原始YOLOX-s模型与改进后的两种模型在数据集上作了实验对比,实验结果如表2所示。

表2 改进特征提取层验证实验Table 2 Verifying experiment of improved feature extraction layer
结果表明,相比于原始YOLOX-s 模型,改进后的YOLOX-s-B1模型检测精度提升不明显,且模型FPS大幅下降,模型大小和参数量大幅增加,证明此方案改进效果不佳。而YOLOX-s-B2模型算法相比于原始YOLOX-s模型,精度提升了1.54 个百分点,且模型检测速度也有一定的加快,说明BiFPN-m网络可以在一定程度上更好地融合特征图中的特征,证明了将BiFPN-m 融入模型Neck层的有效性,此网络模型记为YOLOX-s-B。
3.2 改进卷积层的实验分析
为了验证将卷积层替换为Ghost卷积对模型性能提升的有效性,本文将原始YOLOX-s 模型中的部分卷积层替换为Ghost卷积,其余部分不做改动,改动后的算法记为YOLOX-s-G,将改进前后算法在数据集上进行实验对比,实验结果如表3所示。

表3 改进卷积层验证实验Table 3 Verifying experiment of improved convolution layer
结果表明,将原始YOLOX-s 模型中的部分卷积层替换为Ghost 卷积之后,改进后的模型在mAP、Recall、Precision等指标上仅下降0.1~0.4个百分点,但是在模型大小和计算参数量等指标上均减少了50%,即改进方法对模型轻量化效果有一定的提升,证明了改进方案的有效性。
3.3 融合CBAM模块的实验分析
为了验证融合CBAM 模块对原始模型的有效性并探究将CBAM 模块嵌入网络模型的具体位置,本文以经过Ghost 卷积和BiFPN-m网络改进后的YOLOX-s网络模型(YOLOX-s-BG)为基础,将CBAM模块分别嵌入网络模型的不同位置,形成了1.4 节所示的4 个新的网络模型,将4种模型与YOLOX-s-BG模型在数据集上进行实验对比,实验结果如表4所示。

表4 融合CBAM模块验证实验Table 4 Verifying experiment of fusion CBAM
结果表明,通过四种方式将CBAM 模块嵌入到YOLOX-s-BG 模型后,均能进一步提升整体模型的精度,证明了CBAM 模块对本模型改进的有效性。通过各项指标对比发现,将CBAM模块嵌入CSP3模块的对应位置之后,改进后模型的mAP 提升最大,达到了99.57%的整体识别准确率,因此本文最终选定图8(b)方案作为CBAM最终嵌入的位置。
3.4 消融实验
本文所提的改进方案分别为B(BiFPN-m)、G(Ghost卷积)、C(CBAM)。为了验证改进方案在不同方案上的改进效果及其有效性,本文在采用相同软硬件配置、相同参数设置的前提下,探究了原始YOLOX-s 网络模型与添加1种改进方案、2种改进方案和3种改进方案的不同优化策略进行对比实验,实验结果如表5所示。结果表明,三种改进方案均能取得预想的改进效果,证明了改进的有效性。
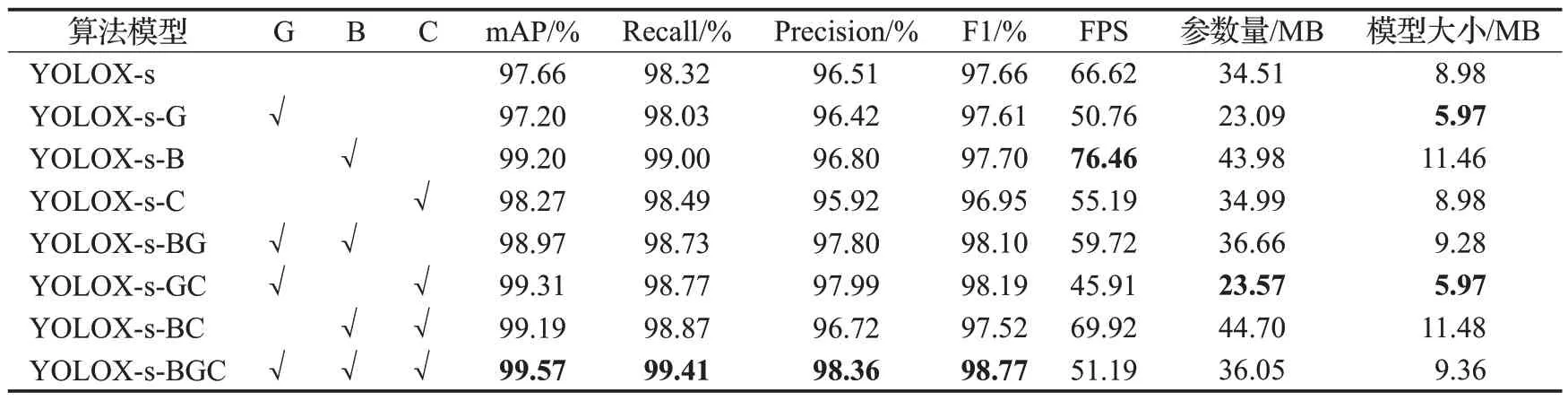
表5 消融实验Table 5 Ablation experimental
3.5 对比实验
为了进一步验证本文提出的改进网络模型的有效性和性能的优越性,本文将改进后的YOLOX-s-BGC算法与原始YOLOX-s 算法、SSD 算法、ScaledYOLOv4 算法[22]、YOLOv5Lite-g 算法[23]在数据集上进行了对比实验,实验结果如表6所示。
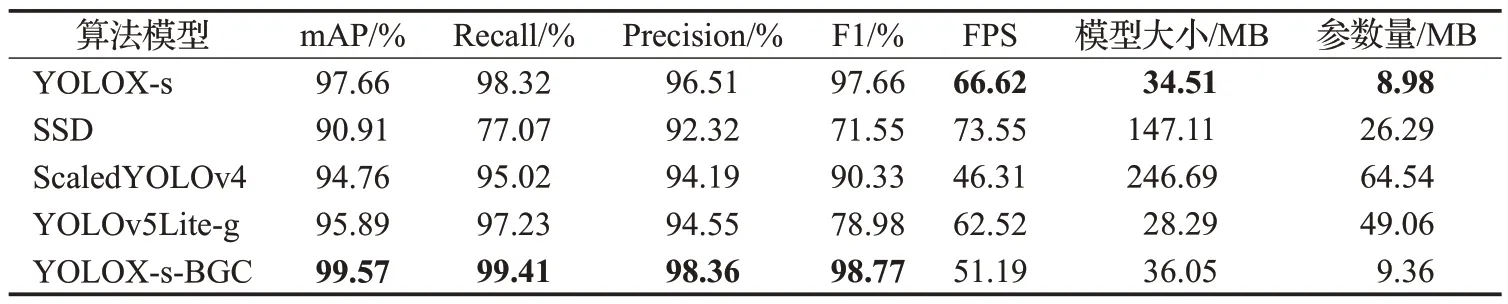
表6 不同算法网络模型性能对比Table 6 Performance comparison of different algorithm models
结果表明,本文提出的YOLOX-s-BGC网络模型相较于其他主流算法,在mAP、Recall、Precision、F1值等指标上有着明显的优势。其中,相较于SSD 算法,本文所提方法在模型大小上只有SSD的24.5%,且在整体精度上提升了8.66个百分点,优势较为明显。而相较于体积相似的YOLOv5Lite-g 算法和ScaledYOLOv4 算法,本文所提算法在保持模型轻量化的同时,检测精度也有了较大的提高,且FPS 下降不明显,能满足实时检测的需求,证明了本文所提算法的优越性。改进前后网络模型识别效果图如图12所示。

图12 算法改进前后效果对比图Fig.12 Comparison of detection effect before and after algorithm improvement
通过对比可以看出,在待检测商品边缘压缩较为严重、商品特征丢失明显的情况下,SSD 算法、Scaled YOLOv4、YOLOv5Lite-g 算法模型均存在漏检、误检等问题,而经过本文改进后的YOLOX-s-BGC模型能够精准识别所有待检测商品,明显提升了商品检测准确率。
4 结束语
本文针对鱼眼相机拍摄的商品图片检测任务提出了一种YOLOX-s-BGC算法。首先,为提高模型对不同尺度特征提取能力,同时减小特征图损失,使用改进的BiFPN 网络(BiFPN-m)替换原始YOLOX-s 网络中的PAFPN结构,在提高模型推理速度的同时大幅提高了模型的识别准确率。然后,为避免改进模型过大,使用Ghost 卷积替换部分卷积层,在大幅减小模型大小和计算参数量的同时,保持模型识别准确率基本不下降。此外,为了进一步增强模型对目标关键特征的提取能力,在改进模型的CSP3模块中引入CBAM注意力机制,实现了模型整体mAP值的进一步提升,最终达到了99.57%的识别精度。将YOLOX-s-BGC模型与YOLOv3、Scaled YOLOv4、YOLOv5-Lite-g 以及原始YOLOX 模型对比,改进后的模型在mAP、Recall、Precision、F1 值等多个指标上均取得了最优,而在FPS、模型大小、计算参数量等指标上也保持了较为优越的性能,达到了模型改进的目的。将YOLOX-s-BGC 模型应用到无人贩卖机的商品检测中,能够达到实际应用的要求。但是,本文的算法仍存在一些问题,对只有颜色差异的两类产品的识别准确度相对较低,同时没有考虑自动贩卖机照明故障等特殊情况对模型检测精度的影响。后续研究将针对这些不足,进一步优化算法,提高模型的鲁棒性。
