融合隐式信任与属性偏好的群组推荐算法
2023-10-29边纪超庞继芳宋鹏
边纪超 ,庞继芳,2* ,宋鹏
(1.山西大学计算机与信息技术学院,太原,030006;2.山西大学计算智能与中文信息处理教育部重点实验室,太原,030006;3.山西大学经济与管理学院,太原,030006)
随着互联网技术的快速发展,推荐系统已融入人们的日常生活[1].传统推荐系统往往以单个用户为目标进行推荐,难以满足群组用户的团体需求[2].近年来,群组推荐逐渐成为活跃的研究方向[3],现有的群组推荐算法大多基于用户-项目评分矩阵中的总体评分进行推荐[4-6],对用户偏好的把握不够精准.为了更好地了解用户偏好,很多电商平台(如携程网、美团网、TripAdvisor 等)通过多属性评分模式收集用户的多维评价信息[4],多属性推荐算法应运而生[7-13].然而,现有的研究忽略了多属性评分中蕴含的隐性信息,对用户偏好的刻画不够全面.此外,随着信任网络的出现和发展,用户之间的信任关系也被引入推荐系统.考虑到信任数据通常难以获取,部分学者对基于隐性信任关系的推荐算法进行了初步的探索和研究[14-19].目前,基于信任网络的推荐算法主要利用出入度来表示用户间的信任关系,但是,对隐式信任的计算比较简单、直接,缺乏对信任关系的多角度分析和综合度量.为了提升群组推荐性能,研究者将深度学习技术融入群组推荐算法,通过注意力机制将用户偏好聚合为群组偏好[20-21],并利用神经网络来学习用户-项目之间的关联[22-25],但现有算法没有充分考虑组内用户间的关系,一定程度上限制了群组偏好的聚合效果.
针对上述问题,本文提出一种融合隐式信任与属性偏好的群组推荐算法(Group Recommendation Algorithm Combining Implicit Trust and Attribute Preference,ITAP),其主要贡献是:
(1)基于多属性评分矩阵从多角度挖掘用户间的隐式信任,并利用信任传递机制对信任矩阵进行填充,最大限度地获取用户间的隐式信任.
(2)综合考虑用户的总体评分及多属性评分信息,通过分析和度量二者之间的关系来建立组内用户关于属性的偏好矩阵.
(3)在融合用户隐式信任和属性偏好的基础上,利用注意力机制聚合群组偏好,并结合深度学习框架生成群组推荐列表.
1 相关工作
1.1 基于多属性评分的推荐算法研究现状为了更加全面、精准地捕获用户偏好,部分学者结合多属性评分矩阵对推荐算法进行了研究.Zhu et al[7]基于多属性评分信息,提出一种面向群组的高效提升算法(Efficient Promotion Algorithm in Recommendation,PromoRec).Biswas and Liu[8]基于多属性评分对用户进行画像,并使用线性回归算法学习用户对各个属性的偏好程度.Papamitsiou and Economides[9]提出一种基于多属性评分的协同过滤算法,能发现偏好相似的邻居并通过相似邻居完成推荐.朱文强等[10]基于多属性评分建立相似度计算公式,通过寻找相似用户来预测用户在每个属性上的评分,再根据预测评分对用户进行推荐.覃正和李岱峰[11]建立了一种面向群组的多属性推荐模型,通过模拟退火的方法学习各成员在各属性上的偏好权重,聚合组内所有成员的偏好.Nilashi et al[12]在使用决策树对多属性评分进行处理的基础上,提出一种多属性协同过滤推荐算法.Majumder et al[13]发展了一种基于多属性评分的矩阵分解方法来提高推荐的准确率.但上述算法仅仅分析了用户在各个属性上的偏好,本文充分挖掘用户在不同属性上的评分与总体评分之间的关系,对多属性评分进行更加全面的分析和利用,提高群组推荐效果.
1.2 融合信任关系的推荐算法研究现状随着信任网络的出现和发展,信任关系逐渐被引入推荐系统.Da'u et al[14]提出一种根据信任网络的出入度来重构信任度的混合推荐算法.Guo et al[15]提出一种融合项目流行度和用户信任关系的矩阵分解推荐算法.Chen et al[16]结合信任关系和协同过滤建立了一种随机游走模型来提高推荐性能.Victor et al[17]将用户交互信息作为信任关系,提出一种社交推荐(Social Recommendation,SoRec)方法.由于隐私问题,获取用户之间的信任分数通常很困难,当用户之间的信任关系无法直接获知时,可以通过分析用户行为、社交网络等隐含信息来进行推断.近年来,越来越多的研究开始探索隐性信任的提取方法.刘辉等[18]利用用户之间的相似度来计算信任度,提出一种整合用户相似度、地理位置和信任关系的混合推荐算法.张槟淇等[19]根据用户的影响力来计算用户信任度,提出一种融合信任关系的群组推荐算法.上述算法虽然能得到用户之间的信任关系,但缺少对用户间信任程度的客观度量.本文基于多属性评分来挖掘用户之间的隐式信任关系,结合用户在共同评分项目上的数量和多属性评分的相似度两个方面来获得用户之间的信任程度,能更好地刻画用户信任关系,获得更精准的群组偏好.
1.3 基于深度学习的推荐算法研究现状基于深度学习的推荐算法大多是将用户和项目嵌入神经网络,从用户、群组和项目之间的交互数据中学习用户偏好.Choudhary et al[20]通过群组和用户组成的双层注意网络来学习群组成员权重.Cao et al[21]利用注意力机制,动态地调整用户在不同群组中的影响力,较好地解释了群组偏好的集结过程.Wang et al[22]利用神经注意网络,以动态方式来学习成员之间的相对影响,利用组内的成员偏好来表示群组偏好.He et al[24]利用自注意力机制来挖掘用户与项目间的潜在信息,进而学习得到群组的潜在偏好.Jia et al[25]提出一种由成员级偏好网络和组级偏好网络构成的双通道超图卷积网络.深度学习技术与群组推荐算法的结合有效地促进了群组偏好融合研究,但现有研究大多根据评分来获取用户与项目之间的交互,没有充分考虑用户之间的关系,导致获取的群组偏好不够全面,影响推荐效果.本文在利用神经网络学习用户-项目交互的基础上,引入用户之间的信任关系,能获得更全面的群组偏好.
2 问题描述
在多属性评分矩阵中,除了常用的总体评分外,还包括用户对项目各个属性的细粒度评分,其中既隐含用户之间的信任程度,又潜藏着用户对不同属性的重视程度和个体偏好.充分利用并挖掘用户提供的多属性评分矩阵有助于获得更加细致、全面的群组偏好,提升群组推荐的效果.
3 ITAP 模型
融合隐式信任与属性偏好的群组推荐算法(ITAP)由五个部分组成:数据准备阶段、输入层、池化层、隐藏层、输出层.在数据准备阶段,基于多属性评分矩阵获得群组gl、项目ij、混合隐式信任矩阵Trustn×n与属性偏好矩阵Prefern×k.通过对gl,Trustn×n与Prefern×k进行one-hot 编码及拆分,得到群组gl内的用户嵌入向量{ub,uc,…}、信任嵌入向量{Trustb,Trustc,…}以及属性偏好向量{Preferb,Preferc,…}.输入层在获得数据准备阶段的四类数据ub,ij,Trustb与Preferb后,利用注意力机制学习用户权重并得到聚合后的群组偏好gl(j).池化层通过对群组偏好gl(j)和项目嵌入ij进行内积运算,提取二者之间的相互作用.隐藏层利用多层感知机对池化后的数据进行处理,捕获群组与项目之间的非线性特征和高阶相关性.最后,在输出层生成群组对于候选项目的预测评分.ITAP 算法的整体架构如图1 所示.
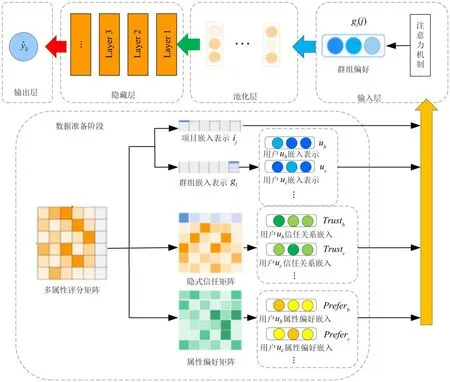
图1 ITAP 算法的框架Fig.1 The framework of ITAP algorithm
3.1 数据准备阶段数据准备阶段为本文的主要工作,在对群组、项目进行one-hot 编码的基础上增加了两方面的内容.(1)基于多属性评分矩阵构建混合隐式信任矩阵Trustn×n.考虑到用户之间的信任度通常是双向的而且是不对称的,首先基于用户共同评分项目计算用户置信度,进而基于多属性评分计算用户相似度,综合用户置信度与评分相似度得到用户之间的直接隐式信任关系.在此基础上,进一步利用信任传递机制[26]挖掘用户之间的间接隐式信任关系,对直接信任矩阵进行补全,得到混合隐式信任矩阵,减少数据稀疏性的影响.(2)结合多属性评分与总体评分构建用户属性偏好矩阵Prefern×k.通过距离公式对用户各属性评分与总体评分之间的相关性进行量化分析,并据此计算用户在不同属性上的偏好程度,获得更加精准的用户偏好.
3.1.1 混合隐式信任矩阵混合隐式信任矩阵由直接隐式信任矩阵和间接隐式信任矩阵两部分构成.其中,用户间的直接隐式信任度从两个方面进行刻画:(1)基于共同评分项目的用户置信度;(2)基于多属性评分的用户相似度.
首先,通过用户共同评分的项目数量与用户自身评分的项目数量之比来计算基于共同评分项目的用户置信度.用户ub对uc的置信度为:
然后,使用皮尔逊相关系数(Pearson Correlation Coefficient,PCC)计算[16]基于多属性评分的用户相似度.用户ub与uc在属性av(1 ≤v≤k)上的评分相似度simv(ub,uc)的计算如下:
用户ub与uc在所有属性上的平均相似度为:
综合用户置信度与用户相似度可得用户ub对于uc的直接隐式信任度Trubc:
考虑到现实生活中一些用户的评分项目比较少,无法直接计算用户间的信任度,导致得到的直接隐式信任矩阵比较稀疏,为此,使用Victor et al[16]的基于T范数的信任传播方法来计算间接隐式信任度,对直接隐式信任矩阵进行补充,从而获得混合隐式信任矩阵Trustn×n.
当用户ub到uc的路径长度大于2 时,用户ub对uc的间接信任度为:
若用户ub和uc之间有多条不同的路径,则在每条路径上都存在一个间接信任度.集结所有路径上的间接信任度可得用户间总的间接信任度.
采用Victor et al[17]的有序加权平均(OWA)算子来集结不同路径的信任度.由于OWA 算子能够灵活反映不同的集结度,其在群体决策的信息集结过程中得到了广泛的应用.
3.1.2 属性偏好矩阵用户的属性偏好可通过计算其在某个属性上的评分与总体评分之间的距离来刻画.用户ub在属性av上的评分与总体评分之间的距离如下:
利用式(10)~(12)计算组内所有用户在所有属性上的偏好,得到群组的属性偏好矩阵Prefern×k.
3.2 输入层表示输入层在得到数据准备阶段提供的ub,ij,Trustb,Preferb后,利用注意力机制获取群组gl对项目ij的偏好gl(j),计算如下:
其中,PT表示用户ub的隐式信任影响权重矩阵,PP表示用户ub的属性偏好影响权重矩阵,PI和PU分别表示项目嵌入和用户嵌入的权重矩阵,bi表示偏置向量,h为权重向量.
输入层具体流程如图2 所示.

图2 基于注意力机制的群组偏好获取Fig.2 Group preference acquisition based on attention mechanism
3.3 池化层表示池化层主要是对群组偏好表示gl(j)与项目嵌入表示向量ij进行内积运算,其目的是通过在每个嵌入维度上使用乘法来获得两个嵌入向量之间的相互作用[15].为了避免内积运算中可能出现的原始嵌入信息丢失的情况[23],可将原始嵌入信息与内积结果进行拼接,得到最终的池化层表示向量e0,具体计算如下:
其中,⊙表示内积运算.
3.4 隐藏层表示隐藏层的任务是对池化层传入的表示向量e0进行变换,通过多层感知机来捕获群组偏好嵌入gl(j)与项目嵌入ij之间的非线性特征和高阶相关性.计算如下:
其中,h表示隐藏层层数,ReLU 为激活函数,b1,b2,…,bh为可训练的偏置向量,W1,W2,…,Wh为可训练的隐藏层权重矩阵,eh为e0经过多层感知机后的输出向量.
3.5 输出层表示输出层将由隐藏层传入的最终表示向量eh转换为预测评分,具体计算如下:
其中,w为可训练的输出层权重矩阵.
通过对不同项目的预测评分进行排序,生成最终的群组推荐列表.
3.6 损失函数得到预测评分后,利用均方差损失函数对模型进行优化,具体计算如下:
其中,M表示群组中候选项目数量,ylj表示训练集中群组gl对项目ij的实际评分,表示gl对ij的预测评分.
在优化策略选择方面,考虑小批量梯度下降(Mini Batch Gradient Descent,MBSD)能比传统的随机梯度下降(Stochastic Gradient Descent,SGD)更快地达到最优解[27],故本文采用MBSD策略来最小化损失函数.
4 实验分析
4.1 实验数据在大众点评、Yelp2018、Ratebeer 和BeerAdvocate 四个数据集上进行实验,数据集包含用户ID、项目ID、多属性评分、评论时间等信息.随机划分其中80% 的数据为训练集,20%的数据为测试集[28].数据集的信息如表1所示.
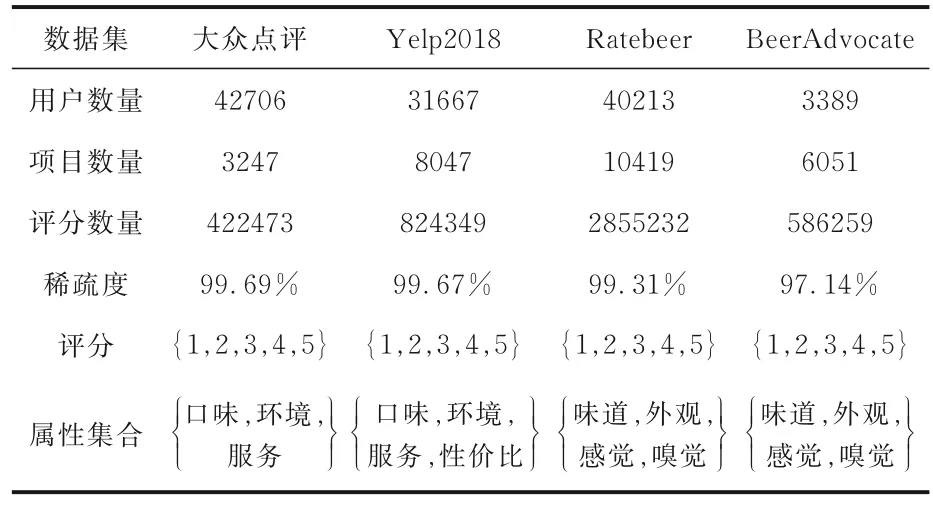
表1 实验使用的数据集Table 1 Datasets used in experiments
4.2 实验设置及评估标准群组的形成[29]是群组推荐的首要环节,通过聚类算法找到一群具有相似兴趣的用户是当前常用的创建群组的方法.K-means 作为经典的聚类算法,在以往的研究中获得了很好的效果[29].因此,本文选择K-means聚类来自动生成群组.
ITAP 算法中的主要参数设置如表2 所示.
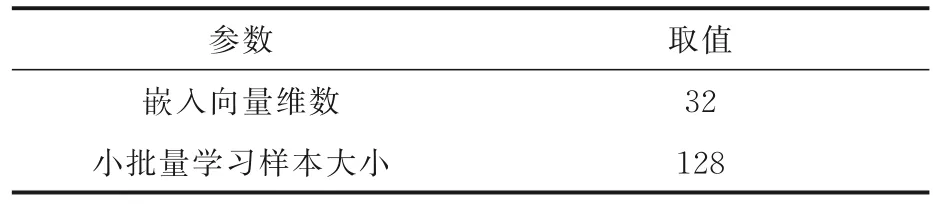
表2 参数设置Table 2 Parameter settings
为了衡量ITAP 算法和基线方法的性能,采用标准差(Standard Deviation,STD)[19]、归一化折损累计增益(Normalized Discounted Cumulative Gain,nDCG)[20]和均方根误差(Root Mean Square Error,RMSE)[21]三个评估指标对算法进行比较分析.具体定义如下.
定义2STD指标用来衡量数据集中数据点的离散程度,计算如下:
STD越低说明数据越集中,推荐结果越准确.
定义3nDCG指标用来衡量生成Top-K推荐列表的命中率,计算如下:
nDCGK越大,表示推荐的命中率越高.
定义4RMSE指标用来衡量用户的真实评分与预测评分之间的误差,计算如下:
RMSE越小,表示推荐的准确度越高.
4.3 对比算法为了评价ITAP 算法的综合性能,将其与AGREE,COM,PromoRec,Trust-SVD,HCR 和HHGR 六种算法进行对比分析.表3 展示了七种算法的异同.
4.4 参数敏感性分析
4.4.1 嵌入维度对于嵌入维度的选取,一般需要通过具体的任务来进行评测,维度过低则模型的表示能力不够,维度过高则容易导致过拟合.为了说明嵌入维度对ITAP 性能的影响,将小批量学习样本的大小固定为128,迭代次数固定为10,TOP-K 值固定为10,嵌入维度分别设为[8,16,]32,64,128 进行实验.实验结果如图3 所示.
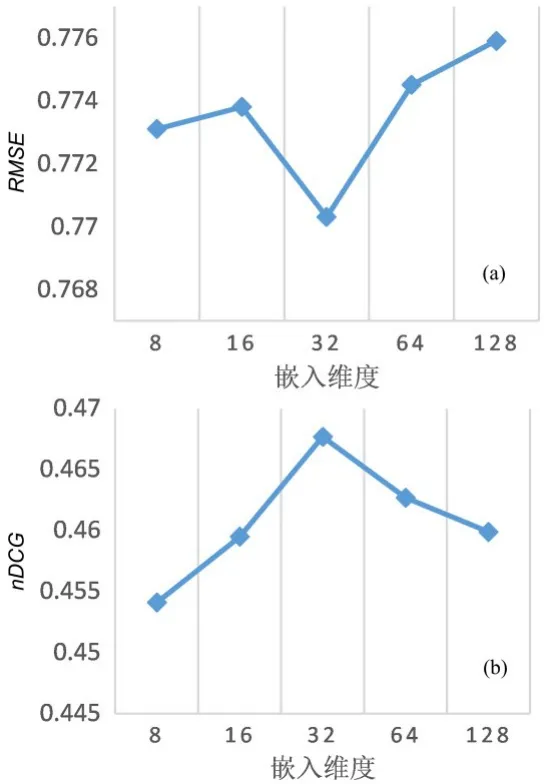
图3 不同嵌入维度下的实验结果Fig.3 Experimental results with different embedding dimensions
由图可见,当嵌入维度在8~32 依次递增时,RMSE逐渐降低,nDCG逐渐提高;当嵌入维度在32~128 时,RMSE逐渐升高,nDCG逐渐降低.因此将ITAP 的嵌入维度设为32.
4.4.2 批量学习样本大小批量学习样本数越大,其确定的下降方向越准确,训练所需的迭代次数越少,但当批量学习样本数增大到一定程度时,其确定的下降方向已经基本不再变化.为了说明批量学习样本数对ITAP 性能的影响,将嵌入维度固定为32,迭代次数固定为10,TOP-K 值固定为10,批量学习样本数分别设为[32,64,128,256]进行实验.实验结果如图4 所示.
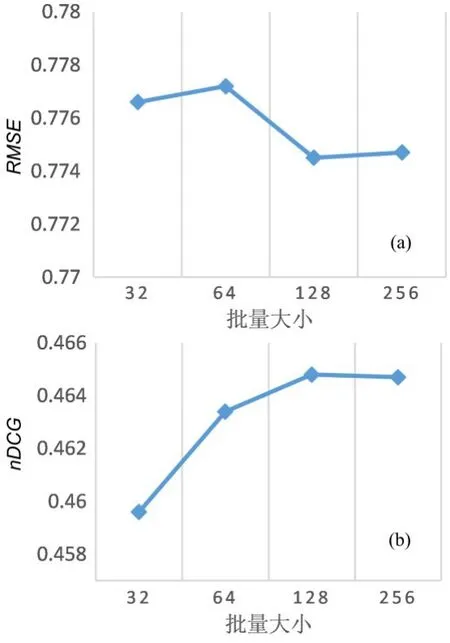
图4 不同批量学习样本下的实验结果Fig.4 Experimental results with different batch sizes
由图可见,当批量学习样本数为32~128 时,RMSE逐渐降低,nDCG逐渐提高,这是因为随着批量学习样本数的增加,训练效率更高.当批量学习样本数在128~256 时,RMSE与nDCG趋于稳定,但在相同精度下,运行时间大大增加.因此选择128 作为ITAP 的批量学习样本的大小.
4.5 对比实验及分析图5 展示了七种算法在四个数据集上的STD与RMSE.由图可见,随着TOP-K 的扩大,七种算法的STD与RMSE逐渐降低.在绝大多数情况下,ITAP 算法的STD与RMSE更小,表现出更高的推荐准确性.
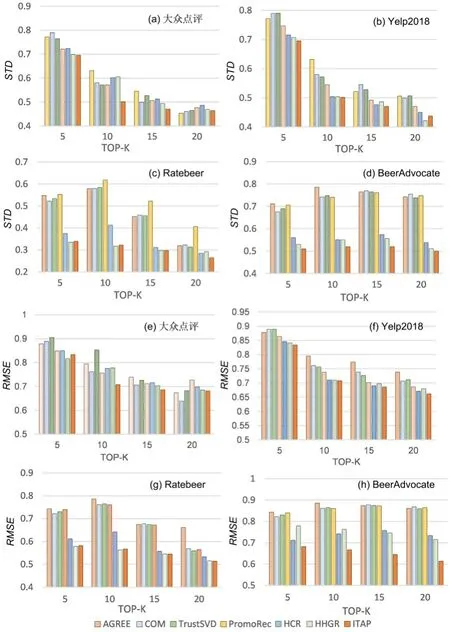
图5 七种算法在四个数据集上的STD 和RMSE 的比较Fig.5 STD and RMSE of seven algorithms on four datasets
图6 展示了七种算法在不同数据集上的nDCG.由图可见,随着TOP-K 的扩大,七种算法在不同数据集上的nDCG均逐渐增大,其中,ITAP 算法的nDCG均比其他对比算法更高,这主要是因为ITAP 算法考虑了隐式信任与属性偏好,能够更加全面、细致地刻画群组偏好,所以表现出更高的推荐准确率.
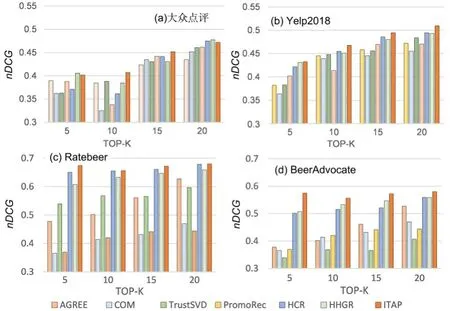
图6 七种算法在四个数据集上的nDCG 比较Fig.6 nDCG of seven algorithms on four datasets
通过上述对比实验可知,ITAP 算法的三种评价指标均表现良好,充分说明在总体评分的基础上,融合用户间的隐式信任与属性偏好可以获得更加精确的群组偏好,能有效增强推荐效果.
4.6 消融实验通过消融实验进一步说明隐式信任和属性偏好在学习群组偏好中的作用.表4展示了三种变体算法ITAP-T,ITAP-A 和ITAPM 与本文算法ITAP 之间的关系.
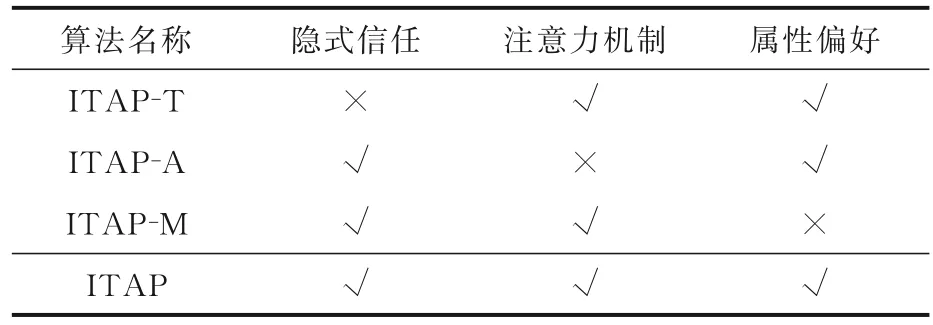
表4 变体算法的介绍Table 4 The introduction of variant algorithms
图7 为四种算法在不同数据集上的RMSE和nDCG的比较.由图可见,随着TOP-K 的扩大,四种算法在不同数据集上的RMSE均逐渐下降,nDCG均逐渐上升,其中,ITAP 算法的RMSE均比其他算法低,而nDCG均比其他算法高.
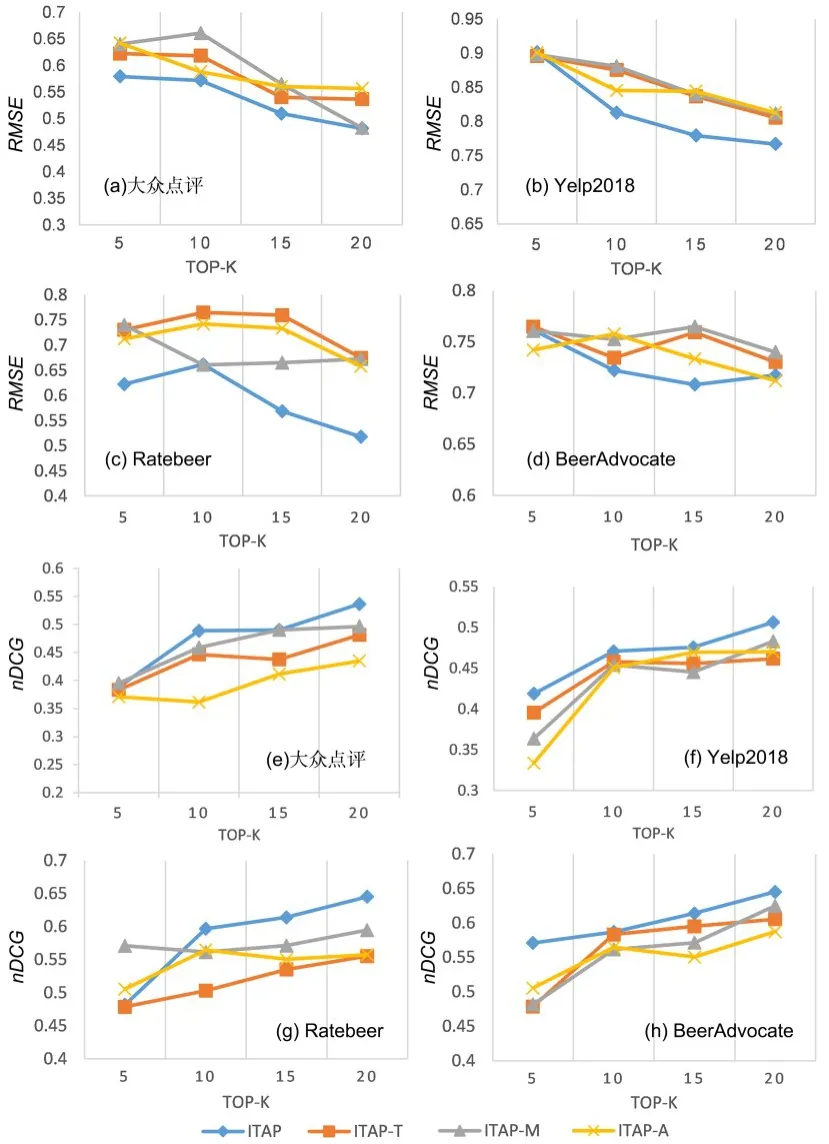
图7 四种算法在四个数据集上的RMSE 和nDCG 的比较Fig.7 RMSE and nDCG of four algorithms on four datasets
通过实验结果对比分析可知,随着推荐列表长度的增加,隐式信任与属性偏好在整个推荐过程中所起的作用越显著,所以推荐效果更好.
5 结论
本文提出的融合隐式信任与属性偏好的群组推荐算法(ITAP)综合考虑了用户的总体评分和多属性评分,从多个角度挖掘组内用户间的混合隐式信任关系,建立了属性偏好矩阵,通过注意力机制融合各类数据,可以获得更准确的群组偏好.本文算法具有较强的客观性和综合性,在降低数据稀疏性的同时有效提高了推荐准确率,在四个数据集上的多个对比实验和消融实验验证了本文算法的有效性.
未来将考虑群组推荐过程中用户属性(如年龄、性别、工作等)、项目属性(如价格、服务等)及地理位置等辅助信息,通过聚合多维用户偏好来实现群组画像的多兴趣提取,获得更好的推荐效果.
