基于推荐区域的民国纸币冠字号码检测
2023-10-29王笑梅沈成龙王佳婧
杜 欣,王笑梅,沈成龙,王佳婧
(上海师范大学信息与机电工程学院,上海 201418)
1 引言
民国纸币蕴含着重要的信息如地区、发行商、印刷机构等。冠字号码是民国纸币的唯一标识符。
民国纸币冠字号码是一串序列号,涉及文本检测领域。目前用于文本检测的算法有CTPN[1]、EAST[2]、SegLink[3]、TextBoxes[4]等。CTPN结合了CNN与双向LSTM,能有效地检测出复杂场景文字,Anchor按照比例设定,只能检测横向或纵向文本;EAST采用特征图多尺度融合和带角度的预测文本框,能够检测任意方向文本,由于感受野和Anchor大小的限制,无法检测序列文本;SegLink将文字串切割成小文字块,采用邻近域将小文字块连接成序列;TextBoxes是一种快速而精确的文本检测器,但不能检测任意方向的文本块基于深度学习的目标检测算法可分为两类:两阶段检测算法和一阶段检测算法。两阶段检测算法代表有AlexNet[5]、R-CNN[6]、Fast R-CNN[7]、Faster R-CNN[8]等。两阶段检测算法由主干网络,候选区域模块和头部三个部分组成,采用SS(Selective Search)方法或RPN (Region Proposal Network)生成候选框,进行边框回归,检测的精度高,速度较慢。一阶段目标检测算法主要有SSD[9]、Retinanet[10]和YOLO[11-14]等。一阶段目标检测算法的核心是回归。将作为模型输入的整张图像划分为一定数目的网格,预测每个网格中的目标,提升检测速度。
针对纸币样式繁多,图案复杂的特点,本文提出了一种融合异常值检测、聚类和目标检测的序列检测算法。
2 冠字号码检测
本文的民国纸币冠字号码检测算法是基于推荐区域算法,整个检测算法分为生成推荐区域、处理推荐区域。生成推荐区域部分包括检测预处理和分割块检测,处理推荐区域部分主要是分割块处理。在检测预处理中实现纸币图像归一化、图像增强、冠字号码标注和冠字号码分割;分割块检测采用深度学习模型对冠字号码分割块训练和检测。在处理推荐区域中将分割块生成随机点,筛选并消除异常数据点,对经过异常处理的随机点聚合成完整的冠字号码。最后输出民国纸币的冠字号码。民国纸币图像冠字号码检测模型框架如图1。
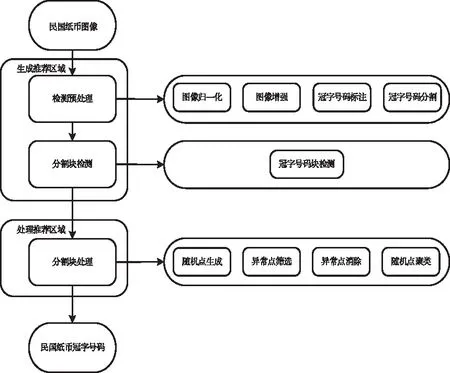
图1 检测模型框架图
2.1 生成冠字号码推荐区域
2.1.1 检测预处理
针对民国纸币图像存在破损、尺寸差异、字迹不清等情况,对图像进行预处理。涉及图像归一化、图像降噪和冠字号码分割。
为提升计算的精度进行图像归一化。经过实验的对比发现,将图像的长度设置为1500 pixels效果较好。采用高斯滤波消除纸币图像噪声。
经过图像标注后,目标检测算法不能有效处理序列,本文将序列号检测问题转换为物体检测问题。为实现对字符串的检测,需对标注框进行分割。可以采用的分割算法有自定义宽度划分法和自适应宽度划分法。框是按照一个常量宽度设定。设标注框的宽高分别为W、H,设定常量宽度为q,将每列以q分割。自定义宽度划分定义如式(1)。设定a是自适应宽度法的人工超参数,则自适应宽度划分法的定义如式(2)。
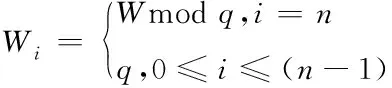
(1)

(2)
经过实验发现,自适应和自定义划分的效果相差甚微,考虑算法简便性,本文选择自定义宽度划分算法,通过多次实验和观察,将q值设置为20 pixels。自定义宽度划分效果如下图2。

图2 自适应宽度划分效果图
2.1.2 YOLOv4模型检测分割块
相比于灵活性更强的YOLOv5,YOLOv4的可定制化程度很高,整体性能更高。选择整体性能更优的YOLOv4作为目标检测算法。
YOLOv4采用CSPDarknet53[15]代替Darknet-53作为网络骨架,SPP[16]和PANet[17](path-aggregation neck)作为模型颈部,保留YOLOv3中高效的头部。
数据输入:在YOLOv4中,运用Mosaic数据增强增加数据量。Mosaic数据增强方法借鉴了CutMix[23]数据增强的方法,将四张图片随机地缩放或裁剪后放入同一张图像,可以有效地应对小目标分布不均匀的情况,达到丰富数据集的效果,减少GPU的工作。采用SAT对抗性训练方式,将训练分为两个阶段,在第一阶段,神经网络通过对自身进行对抗性攻击来改变原图像。在第二阶段,训练神经网络更新权重去检测目标。
主干网络:CSPDarknet53网络结构是在Darknet53 基础上结合CSPNet思想,采用CSP模块将底层的特征映射划分为两部分:一部分经过卷积运算得到残差结果; 另一部分越过卷积计算与上一部分得到的残差结果跨层次融合,既降低计算量又可以保持较高的准确率。
颈部:SPP解决了输入图像大小需要固定的问题。SPP将特征转化为一维矩阵形式。PANet(path-aggregation neck)通过自底向上的通道解决底层特征向高层特征流动路径中的信息流丢失问题,增强整个特征层次架构。
YOLOv4在FPN后融入了由下到上的特征传播路径,在特征金字塔之中结合了双重PAN[11,17]结构,上采样与下采样相结合的方式对顶层特征和底层特征聚合提取。
预测:传统的目标检测模型的损失函数一般是由分类损失函数和边框回归损失函数两部分表示。本文的损失函数采用LCIoU[25]表示代替最广泛使用的边框回归损失函数IOU_Loss[24]。解决了当两个物体 (并交比)相同时的真实框和预测框的位置信息不明确问题。LCIoU定义如式(3)所示,
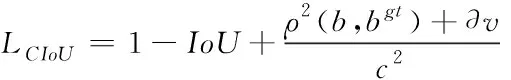
(3)
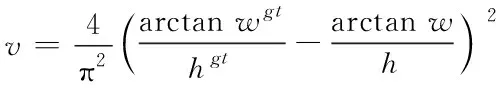
(4)
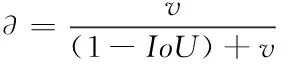
(5)
其中b,bgt分别代表了预测框和真实框的中心点。ρ代表的是计算两个中心点间的欧式距离。c代表的是能够同时包含预测框和真实框的最小闭包区域的对角线距离。是度量长宽比的相似性,定义为式(4),是权重函数,其表达式如式(5)所示。
以一张冠字号码为“4855215”的民国纸币为例,经图像预处理后,采用YOLOv4检测民国纸币分割块。其冠字号码分割块检测结果如图3所示。

图3 分割块检测结果
2.2 处理推荐区域
2.2.1 随机点生成
本文将对分割框的处理转化为对相应的数据点的处理,故将分割框转化为相应随机点。在转化为随机点过程中需要考虑的核心是随机点数量问题。由于每张民国纸币图像的冠字号码数量和尺寸不固定,依据冠字号码数量来确定随机点数量不能处理冠字号码长度过长或高度过高的情况,故采用宽高自适应设置随机点数量。设单个分割块的高和宽分别为H、W,随机点数的装填因子为α,则采用依据宽高自适应算法生成的随机点数量Rc定义如式(6)。
Rc=α*(W*H)
(6)
选取合适的装填因子并以一张双冠字号码的民国纸币图像为例,其采用依据宽高自适应随机点的方法转化效果如图4。
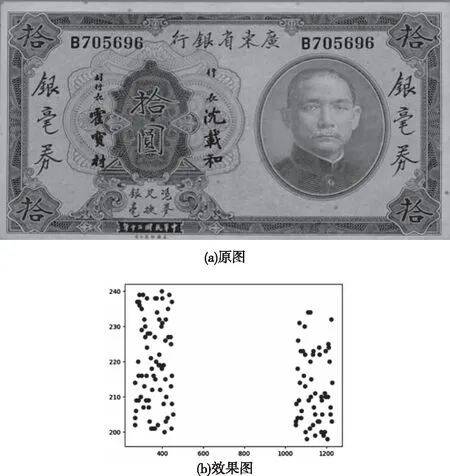
图4 随机点转化前后效果图
由图4可知,两边随机点分布较为均匀,两个冠字号码之间间隔清晰,能够很好地描述冠字号码的位置信息和宽高信息。
2.2.2 局部相关积分(LOCI)
依据数据维度和使用场景的不同,异常值检测算法从种类上可以分为基于统计的检测算法、基于密度的检测算法、基于聚类以及基于邻近度的检测算法。
由于序列号附近的随机点密集,误检框附近数据点稀疏。因此,采用基于密度的局部相关积分算法。在异常值检测过程中,为了避免假正例和假负例的情况,使用双重随机点转换。适当增加随机点数目可以避免删除假负例对实验结果的干扰。考虑到异常值消除的效率和速度,将每个分割块增加的随机点数目设置为3。利用局部相关积分和邻域计数函数估计MDEF值。对于N个数据集P={p1,p2,…,pi,…,pN},P的r-近邻集Ν(pi,r)={p∈P|d(p,pi)≤r},对于任何pi,r和α将半径(或标度)r处的多粒度偏差因子(MDEF)定义为如下表达式(7)。

(7)
当分割块所在区域的数据点少于阈值T时,将该分割块内的所有随机点消除。异常值消除效果如图5。

图5 异常消除效果图
2.2.3 Mean Shift聚类
考虑到随机点集合代替矩形框,深度学习检测分割块时漏检分割块和分割块边界定位偏差这两种情况对序列号的整体区域界限的确定几乎不产生影响。由于随机点集中主要集中在冠字号码区域,随机点集合数量取决于纸币冠字号码的数量,因此本文选择可自定义簇数量的聚类算法。
根据随机点在冠字号码区域分布密度高,在非冠字号码区域分布密度小或无,且不同序列号形成的随机点集合之间具有明显的间隔,采用可设置带宽的 Mean Shift算法,该算法是一种核密度估计算法(无需明确K值),它将每个点更新到密度梯度函数的局部极大值点处,通过不断地更新局部极大值点的位置实现聚类的效果。
在给定n维空间的m个数据点的集合N,则MeanShift向量如式(8)。
(8)
其中,Sk表示距离n点在球半径h的数据点集。通过Mean Shift向量不断地更新球心的位置,使得球心向数据集密集的位置跟进。最终的Mean Shift向量可以表示为式(9)所示。其中,X为中心点,Xi为球半径内的数据点,n为数量,g表示负的核函数的导数。
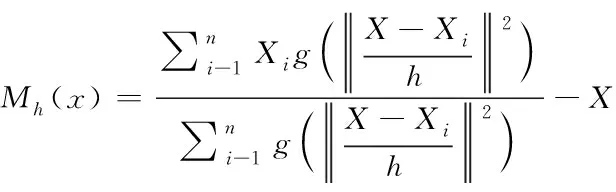
(9)
以本文中的其中两张图像识别结果为例,使用均值漂移聚类Mean Shift算法,设置合适的带宽值,合并分割块后效果如图6。

图6 聚类效果图
由上图可知,使用均值飘移(MeanShift)算法可以有效的合并深度学习检测出的分割块。不仅如此,对于检测过程中出现的漏检、重复检测、边界框偏差等有较好的鲁棒性。
3 实验结果与分析
3.1 实验配置
本实验训练环境是Ubuntu20.04系统,使用Darknet深度学习框架,配置PyTorch和OpenCV环境,实验所用显卡为NVIDIA 2080Ti,内存11G,CUDA版本为CUDA11.0,配有interi9-10900k处理器,算法的测试和训练均在GPU中完成。
3.2 数据准备
本实验数据集来自908张民国纸币图像,通过对原始数据图像数据增强,最终应用于本实验的图像共3502张图像包括正面、反面以及横版和竖版。训练集、验证集和测试集按照8∶1∶1的比例。
3.3 模型训练
网络模型参数设置如下:YOLOv4模型训练的MAX_batches设置为2000,subdivision=32。初始学习率learning_rate设置为0.00261,YOLOv4模型训练结果Loss值在batch达到1000以后基本稳定在1.0%。经过2000epoch迭代后模型逐渐收敛,Loss值在1%附近上下波动。训练的Loss图如下图7。
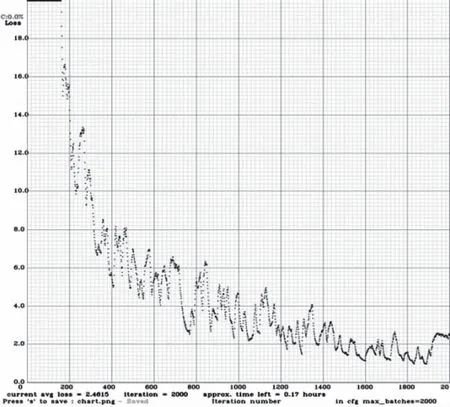
图7 YOLOv4训练Loss变化图
3.4 评价指标
在目标检测中,将准确率(P)和召回率(R)作为模型的评价标准。准确率(P)评估模型返回相关实例的能力,召回率(R)评估模型识别所有相关实例的能力。由准确率(P)和召回率(R)计算平均精准度(AP),以平均AP值(mAP)作为检测准确度的综合指标。式(10)是准确率计算公式,式(11)是召回率计算公式,式(12)是mAP计算公式。

(10)
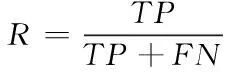
(11)

(12)
检测速度也是判定算法性能的重要指标之一,本文采用单张图片平均检测时间(time)作为检测速度的评价指标。定义如式(13)。
(13)
其中,totaltime为检测花费总时间,num为检测的图片总数量。
3.5 性能分析
模型参数设置:MAX_batches设置为2000,学习率learning_rate设置为0.001。
表1为YOLOv4、YOLOv5和本文的推荐区域算法在民国纸币数据集上的检测性能对比,由表可知,推荐区域检测算法实验mAP达到99.7%,通过对比YOLOv4目标检测模型对冠字号码的检测结果发现,本文算法准确率提升了4.9%,图像检测的平均耗时0.83s,在提升准确率的同时满足实时性的要求。
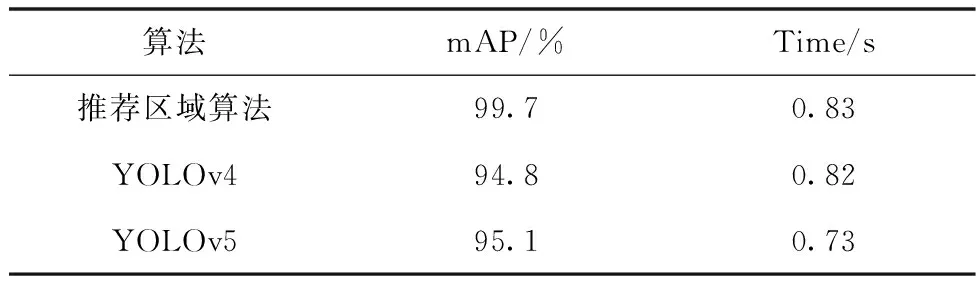
表1 YOLO v4、YOLOv5与本文方法对比
图8(1)、(2)、(3)分别为YOLOv4算法、本文推荐区域算法与YOLOv5算法检测效果图,可见本文检测算法能够较精准的定位民国纸币的冠字号码区域。

图8 检测结果示例图
4 结语
本文提出了一种融合异常值检测、聚类和目标检测的序列检测算法,实现了民国纸币的精准定位,提升检测的效率。
1)由于目标检测对序列号检测的精准度较低且文字检测算法对非冠字号码的无效定位,本文采用分割算法将冠字号码的检测转换为冠字号码块的检测;2)针对冠字号码的精准定位和矩形框合并的复杂度,本文运用随机点转化算法将矩形框转换为数据点;3)针对到检测分割块过程中出现的漏检、误检等问题,采用异常值检测处理数据点;4)采用聚类算法合并数据点,实现分割区域的合并。最后输出冠字号码。
实验结果表明,相比于文本检测算法如East模型,本文的推荐区域检测算法消除了无效检测且提高了精准度。相比于目标检测模型如YOLOv4、YOLOv5,本文的算法准确率更高,且能够保持实时性。
