基于混合注意力机制的视频序列表情识别
2023-10-29李金海
李金海,李 俊
(1. 桂林电子科技大学电子工程与自动化学院,广西 桂林 541004;2. 桂林电子科技大学计算机与信息安全学院,广西 桂林541004)
1 引言
表情能传递人类的情绪、心理和身体状态信息。研究表情自动识别技术能够有效地辅助人工智能机器分析判断人类的情绪,近年来该研究广泛应用于智能教育[1]、交通安全[2]、医疗[3]等领域,使得许多学者逐渐开始关注动态表情识别方面的研究。
传统的视频表情识别算法主要有LBP-TOP[4]与光流法[5]等,这些手工提取特征的方法很大程度上依赖于特定的任务,且这些方法都具有缺乏泛化性与稳定性的特点。
近几年来,随着人工智能的迅猛发展,许多深度学习方法应用在表情识别领域上,并且识别精度比手工提取特征方法有很大提升。现阶段主要有级联网络[6]、三维卷积神经网络[7]、多网络融合[8]等方法对视频表情进行识别。以上方法对特征的提取具有一定的随意性,且忽略了对表情峰值帧的关注,而表情在变化过程中表情峰值帧往往具有更多判别性的特征。此外,深度学习方法在训练模型时候要有大规模的数据量支撑。而表情识别任务中可靠的数据集规模较小,在该类数据集上直接训练会导致模型出现过拟合现象。
本文提出了一种混合注意力模型。该模型在通道维度上能有效地增强与表情相关性高的通道信息,时间维度上给予表情峰值帧更多的关注,以此增强网络提取有效特征的能力。数据集方面通过数据增强,增加训练样本数量,解决数据集规模小的问题。最后通过对比结果验证本文方法能够明显提高识别准确率。
2 基于混合注意力机制的表情识别模型
本文提出了一种基于混合注意力机制的时空网络对视频中的脸部表情进行分类。模型主要包括了三部分:空域子网络、时域子网络和混合注意力模块。
2.1 空域子网络
空域子网络中,通过VGG16网络中的卷积层和池化层来学习人脸各类表情的空域特征。本文对VGG16网络进行了修改,首先是保留VGG16的卷积层部分,并使用自适应平均池化(Adaptive average Pooling,APP)代替原始网络中的全连接层。其中自适应平均池化层的池化窗口(kernel size)大小为4*4,滑动步长(Padding)为4,经过池化层的操作实现特征降维。最终得到的特征向量的通道数(channel)为512,大小为1*1的特征图。
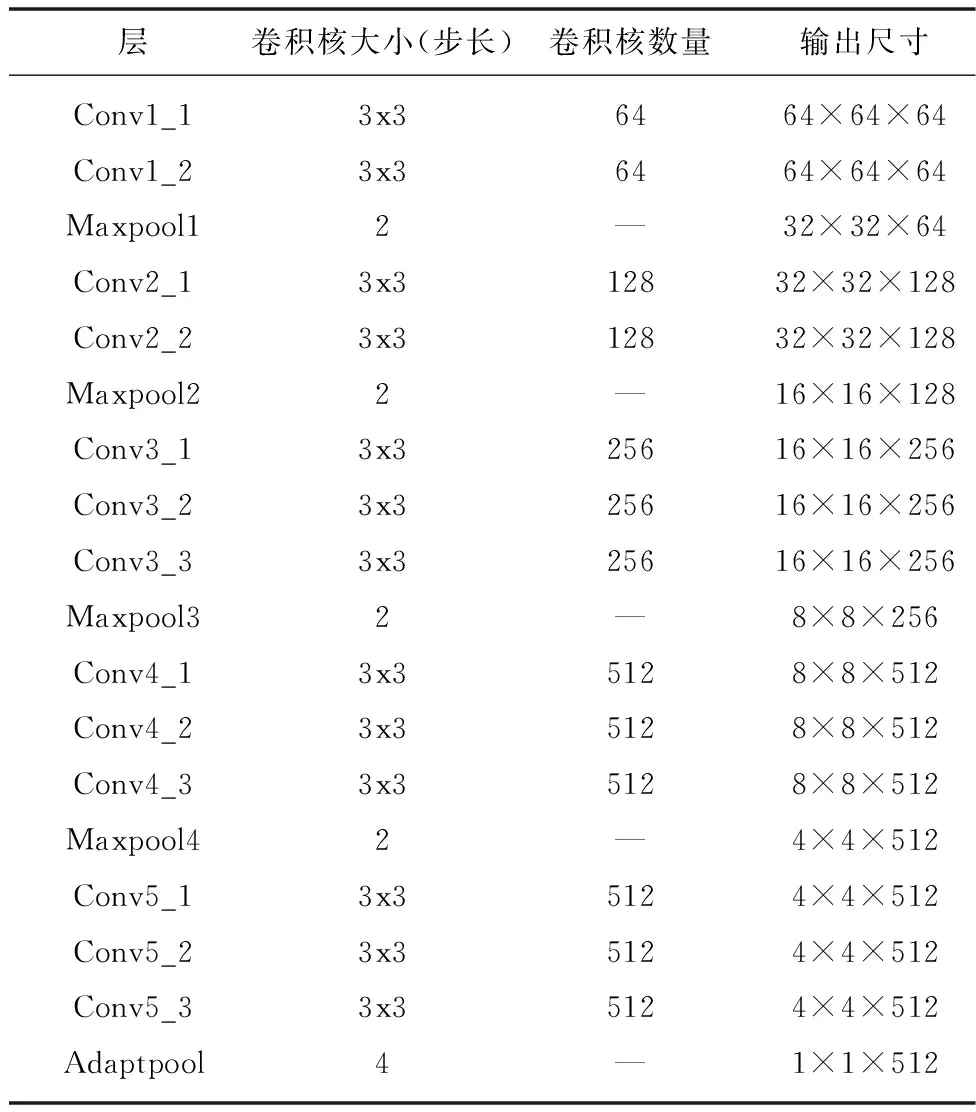
表1 改进的VGG16结构
2.2 时域子网络
对于视频帧中的表情识别,需要观察表情和时间变化之间的关系。由于VGG神经网络对于时序变化的表达能力不足,因此需要引入其它网络来解决该问题。长短时记忆网络能够通过隐藏状态来记录先前序列的内容,从而解决时序问题。
GRU网络中重置门rt与更新门zt(t代表当前时刻)具有重要要作用,如图1所示。rt与zt都能接收当前时刻输入xt和先前时刻隐藏层状态ht-1输入,对应的权值分别是Wr与Wz。根据图1的GRU内部结构图,网络的主要操作过程如下式所示

图1 GRU内部结构
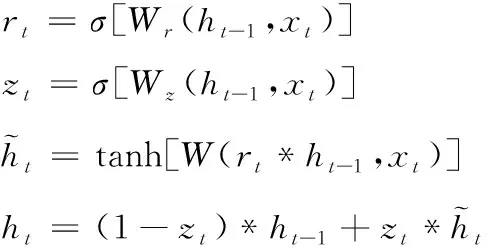
(1)
模型训练过程中,将一组序列中的视频帧当成一批次输入,空域子网络提取该批次的特征再经过AAP层,得到n个大小为1*1,通道数为512的特征向量。然后把这些向量输入时域子网络里,GRU读取视频的时间变化获得大小为n×512特征矩阵,随后将特征矩阵进行平铺处理成1×512n的特征矩阵,最后输入到混合注意力模块中。
2.3 混合注意力模块
本文设计的混合注意力主要为了有效提取通道特征与表情变化的时间特征。通道注意力采用自学习的方式获得各个特征通道的权重,并按照权重大小增强对表情分类有用的通道,抑制非相关的通道,提高了网络对显著性特征的提取性能。时间注意力通过判别帧间的表情强度,赋予表情强度大的视频帧更高的权重,使网络更关注于表情峰值帧。根据文献[9]的实验原理,本文将两个注意力模块按照串联的方式排列。设计完成后混合注意力如图2所示。
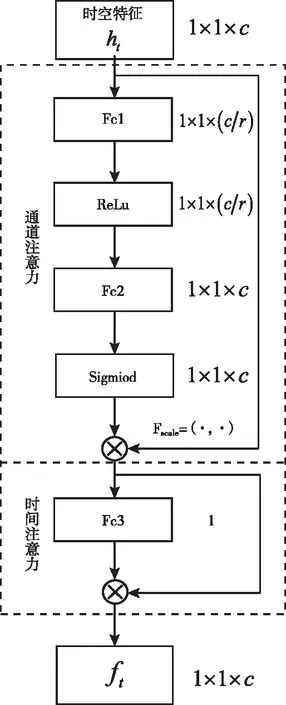
图2 混合注意力模块
2.3.1 通道注意力原理
通道注意力主要有激励和特征通道赋值这两个过程。其中激励操作的原理如式(2)所示
s=Fex(ht,WcATT)=δ(WcATT2σ(WcATT1ht))
(2)
其中ht为序列表情的时空特征,δ与σ为ReLU激活函数和Sigmoid激活函数,Fex为激励处理,WcATT1、WcATT2分别代表通道注意力中两个全连接层的权值。激励操作中,先采用第一个全连接层WcATT1与时空特征ht相乘,WcATT1的维度是C/r*C,r表示缩减倍数,即为了减少运算量,对原特征通道总数进行压缩,根据文献[10],r取16。此时WcATT1ht的维度为[1,1,C/r]。激活函数使用ReLU函数,保持输出维度不变;随后经过全连接处理,将结果和WcATT2相乘,并利用sigmoid激活函数进行非线性转换。得到数值范围为0到1的通道权重值sc。此时sc的维度大小为[1,1,C]。最后进行特征通道赋值操作,即将权重sc与注意力机制前的时空特征ht进行相乘,通道赋值公式如式所示
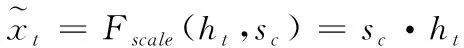
(3)
通道赋值中,对应的权值sc表示为各个特征通道对表情的相关性大小。模型训练时,通过sc的大小对相应的特征进行增强或者抑制。通过这种方式,能够实现对最具鉴别性表情特征的聚焦,提升模型的性能。
2.3.2 时间注意力原理
在视频序列的识别任务中,并不是每一时刻的表情都对识别的贡献相同。因此本文提出一种时间注意力机制,赋予表情峰值帧更多的权重,以生成更有判别性的特征。在时间注意力中,提出了一种比较帧强度的方法,即通过一个全连接层,将每个帧特征映射为时间注意力分数。公式如下
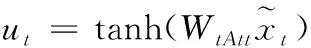
(4)
式中,WtAtt为时间注意力模块中可学习的参数矩阵。ut表示序列第t帧图片时间注意力分数;然后,通过Softmax函数归一化每帧的注意力分数
(5)
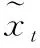
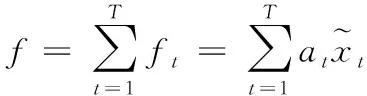
(6)
最后,使用两个全连接层降维,并使用Softmax函数分类得出六种表情结果。
3 实验与分析
3.1 表情数据集预处理
为了验证本文算法在视频序列表情识别的效果,本文选取了公开主流数据库:CK+数据库与Oulu-CASIA数据库。
在实验过程中使用dlib库提供的人脸检测器对眼睛、眉毛、鼻子、嘴巴和面部轮廓在内的68个人脸关键点进行检测。利用68个点位置,计算脸部中间点的信息。根据视频第一帧的位置信息,利用仿射变换矩阵调整后续图像,使后续人脸脸部对齐。最后将脸部图片裁剪成64x64尺寸,图3为裁剪后的表情图像。

图3 部分裁剪后图像样本
由于两个数据集中序列表情图片较少,为了保证模型的泛化性与鲁棒性,本文实验对数据集采取了数据扩充的方法。具体地,首先将裁剪到的所有人脸区域图片进行水平反转得到翻转图像数据集;然后,将原数据集与反转图像数据集分别偏移-10°、-5°、5°、10°得到偏移数据集,最后获得10倍于原先的实验数据量。因为各个视频的帧数都不同,而模型的输入维度是不变的,因此对CK+与Oulu-CASIA中每个表情视频序列均从起始帧按照时间序列连续采样16帧,作为神经网络的输入。此外,如果视频序列帧数少于16帧的长度,则复制最后一帧直至每个序列变为平均长度。
3.2 实验设置
本文实验软件框架为Pytorch1.8.1。实验在训练时采用随机梯度下降法优化模型在模型训练时,CK+的训练集损失函数变化情况如图4所示,当迭代到150个epoch后,损失函数已基本收敛,损失函数值接近0.1,因此实验中epoch取160。为了能更好地体现出算法的实验效果,本次实验使用十折交叉验证方法得到最后的准确率。
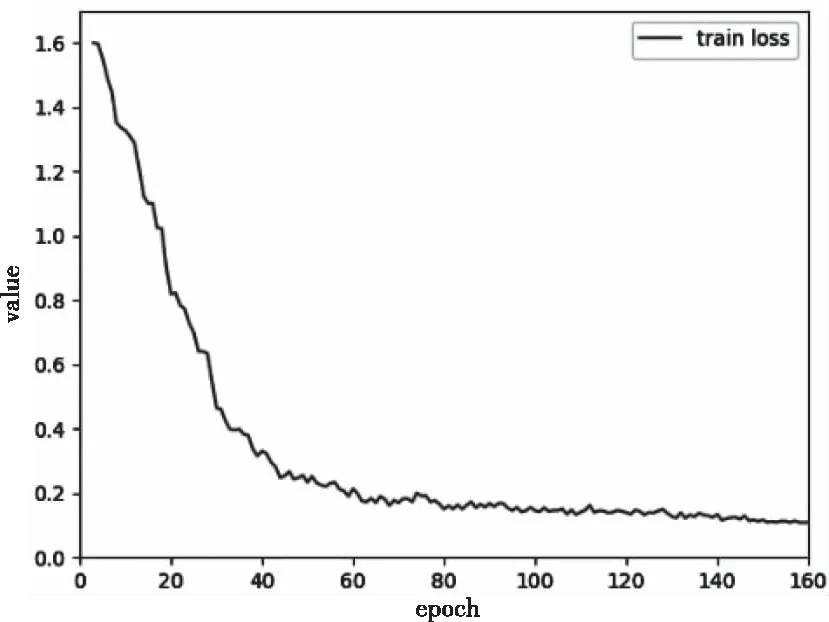
图4 CK+训练损失函数图
3.3 消融实验
为了体现加入了混合注意力机制的效果提升,对其进行了消融实验。其中,Baseline是指改进的VGG16与GRU的级联网络,CA代表通道注意力模块,TA代表时间注意力模块,HA代表CA与TA相结合的混合注意力模块。
表2为消融实验中各个模型的准确率。单独加入通道注意力模块与单独加入时间注意力的网络在两个主流数据集上所得的准确率相对于Baseline都有明显的提高。
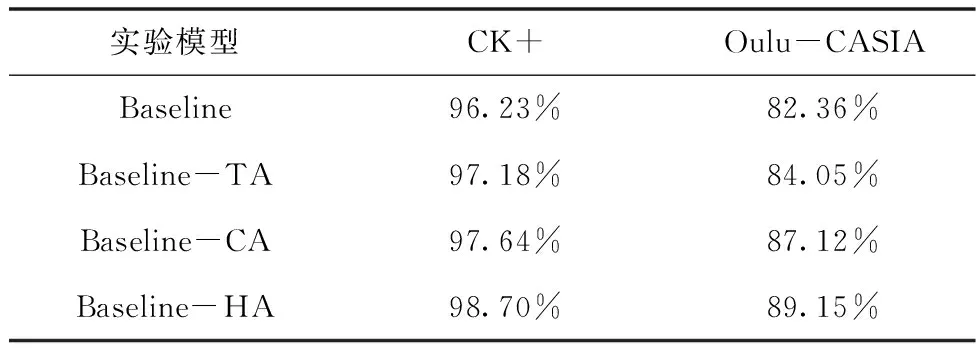
表2 各个模型准确率
对于CK+数据集,单个时间与单个通道注意力模块的加入分别比Baseline提高0.95%和1.41%。在Oulu-CASIA的实验中,分别提高了1.69%与4.76%。由此可得,通道注意力的性能略优于时间注意力的识别性能,说明在视频表情识别中全局通道维度比全局时间维度提供更多的信息。此外,Baseline-HA模型在CK+与Oulu-CASIA的准确率分别比Baseline高出2.47%和6.75%,这表明混合注意力模块能够有效地将两个注意力模块的性能进行互补,不仅能够在视频序列中给予表情峰值帧更多的关注,而且能抑制无关通道干扰,提取更具显著性的脸部纹理特征。
3.4 混淆矩阵分析
图5与图6展示了本文方法在两个数据集上的混淆矩阵。混淆矩阵的行表示当前表情的真正类别,列为模型的分类表情。不难得知,CK+数据库的整体表情识别准确率比Oulu-CASIA的要高,这是因为CK+中大多数为清晰的人物正脸图像;而Oulu-CASIA中图像分辨率不够高,而且部分人物有眼镜和围巾的遮挡,导致识别率较低。
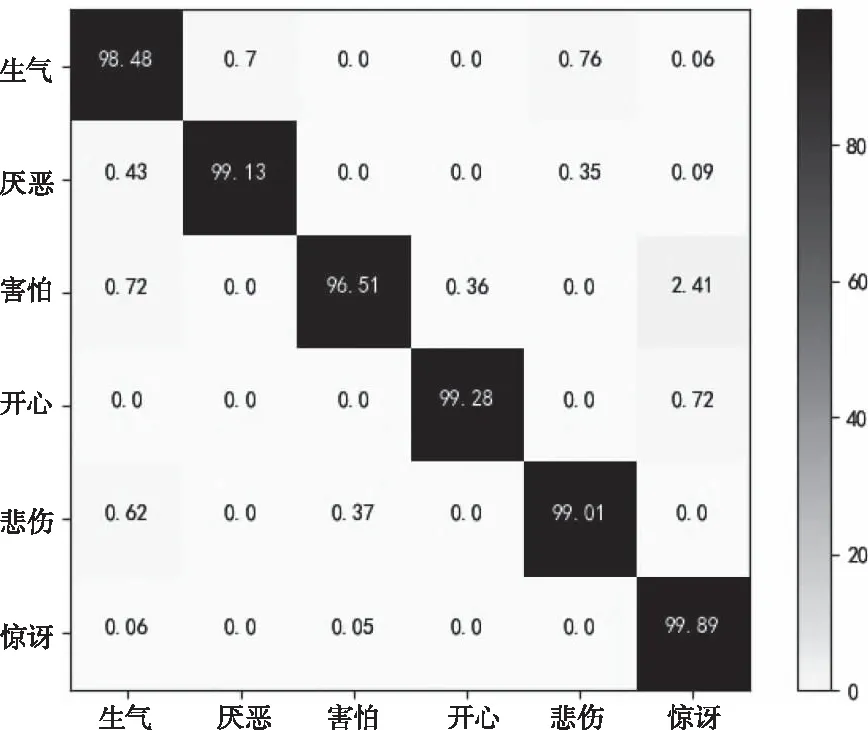
图5 CK+识别结果混淆矩阵
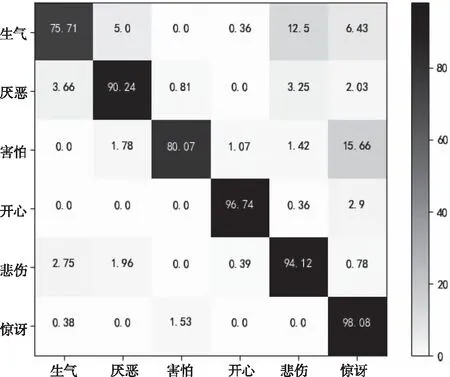
图6 Oulu-CASIA识别结果混淆矩阵
比较两个混淆矩阵的数据可知,文中模型对惊讶与开心两个表情取得了优异的识别效果。模型对于生气和害怕两个表情识别性能较弱,主要原因是,数据集中害怕与惊讶大部分都是瞪眼和张嘴的动作,而生气与悲伤都伴随着锁眉和撇嘴的动作。具体而言,表情的相似导致模型出现混淆分类的情况。
3.5 与现有方法对比
表3展示了本文所提模型与其它主流模型在所选数据集上实验的对比结果。

表3 不同方法的准确率对比
从中可得,本文所提出模型对CK+与Oulu-CASIA这两个数据集的识别准确率仅次于MGLN-GRU,而优于其它方法。值得注意的是,本文模型只关注于表情特征,而识别准确率高于同时利用表情特征和几何路标点的PHRNN-MSCNN。而MGLN-GRU利用复杂的多任务模型实现了99.08%与90.40%的识别率,比文中模型分别高了0.38%和1.25%,但是MGLN-GRU模型与本文的实验设置不同,该模型的输入是选取视频序列的第一帧、中间帧和最后一帧来表示表情演化,这种离散帧的识别方法会造成峰值信息缺失。本文提出模型将视频的连续多帧作为输入,使文中模型注重于连续帧之间的表情依赖性,较好地适应了表情强度的变化,更符合现实生活人脸表情变化过程。
4 结束语
本文设计了一种混合注意力机制视频序列表情识别模型。该方法的主体为改进的卷积神经网络与GRU网络的级联网络,可以提取序列时空信息的同时减少特征提取的计算量。其次,提出了由通道与时间注意力组成的混合注意力模块,更关注于表情峰值帧中与表情相关性高的特征通道。通过数据扩充方法,解决目前表情数据规模较小的难题,保证模型的泛化性。实验结果表明,嵌入混合注意力模块使得模型在CK+与Oulu-CASIA两个数据集上的识别准确率分别提高2.47%与6.79%。最后,通过与其它研究方法对比,该模型在表情识别准确率有明显优势。验证了本文提出的方法能够有效地提取最具表达能力的特征,提高识别准确率。
