结合多模态和注意力机制的人脸活体检测算法
2023-10-29蔡茂国唐剑兰
周 航,蔡茂国,唐剑兰,徐 翔
(深圳大学电子与通信工程学院,广东 深圳 518000)
1 引言
人脸识别技术是身份识别的一种重要手段,已广泛应用于日常生活中,如工作考勤签到、人脸支付、公共刑事调查追踪、金融机构门禁、自动驾驶和机器人识别等。但与传统指纹、虹膜等生物识别技术相比,人脸图像由于网络的传播,在给生活带来便利的同时也带来了一定的安全风险,即摄像头识别的不是真实的活体人脸,而是人脸图像的二次采集,如人脸照片的高清打印[1],具有代表性的人脸视频重放攻击[1]和3D面具攻击[2],对识别系统的安全性构成严重威胁。
目前人脸活体检测技术为四大类:交互式人脸活体检测、额外硬件设备的人脸活体检测、传统手工提取的人脸活体检测,基于深度学习的人脸活体检测算法。其中交互式人脸活体检测算法主要利用活体人脸的宿主是有生命的人类,可以按照设备的指示做出点头、摇头、向左看、做表情等动作,甚至根据设备提示朗读任意一段文字等声音,而假体面孔则很难做到。Wang等人[3]通过检测人脸嘴部区域的二值变化范围进行唇语识别,辅以语音识别来获取用户反应的语音信息,共同判断用户是否按照要求读出随机给出的语句。Singh等人[4]通过眨眼和张嘴的动作来判断是否为活体,主要是计算眼睛和牙齿的HSV(色调、饱和度、值)以确定眼睛嘴巴是否做出相应动作。Ng等人[5]引导用户完成随机面部表情并通过计算多帧图像的SIFT流能量来判断是否完成指定面部表情。基于人机交互的方法通过精心设计的交互动作,可以有效降低类间差异对算法性能的影响。因此,它具有较高的识别率和良好的通用性,然而人脸防欺骗检测方法需要从多帧图像中识别用户是否完成了的动作,与基于单帧的算法相比,计算量大,所需时间长。而且它要求活体高度合作,检测过程繁琐,用户体验不好,因此违背了人脸识别技术的便利性和天然优势。
使用特定硬件或传感器的人脸活体检测算法主要依赖于3D结构光传感器、近红外(IR)传感器、热红外传感器等。通常,此类特定传感器极大促进了活体检测的精确性。例如,3D结构光可以通过检测深度图来区分3D人脸攻击和2D平面攻击[6],而IR传感器可以轻松检测视频重放攻击(因为电子显示器在IR照明下几乎呈现一致的黑暗)[7-9],热红外传感器可以检测活体面部的特征温度分布[10]。尽管这些算法的识别精度较高,但由于硬件传感器昂贵以及算法对硬件的适配成本导致此类算法在实际应用中并不具有普遍性。
传统手工设计特征表达的人脸活体检测算法主要利用假体图像在二次采集的过程中会丢失信息,并夹杂一定的噪声。此类算法根据活体与假体的先验知识差异来提取特征,并将提取出的特征输入合适的分类器进行分类。常见的检测方法包括基于纹理的方法[11-15]、基于图像质量的方法[16-18]、基于生命信息的方法[19],文献[20-23] 利用远程光学体积描记术(Remote Photo plethysmo graphy,rPPG) 信号检测待测对象是否具有心率,并以此判断是否为活体人脸。虽然基于手工设计提取的方法在某些场景下也能取得不错的准确率,但由于手工设计特征作为浅层特征,表达能力一般,不能有效表征活体人脸和假体人脸之间的多重差异导致模型的泛化能力较弱。
近年来随着卷积神经网络、循环神经网络等特征提取器的日益强大,通过设计特定的网络结构直接从图片中提取可识别信息,然后利用训练好的模型直接区分有生命特征和无生命特征成为主流的方法。Yang等人[24]在2014首次将卷积神经网络应用到人脸活体检测上,他设计了十三层的卷积神经网络从单模RGB图片中抽取特征进行训练来判断活体真假,但该算法使用的数据集攻击类型单一,削弱了网络的泛化能力。Parkin等人[25]分别设计了18层、34层、50层残差网络来判断活体增加,虽然取得了不错的准确率,但是模型复杂度高,计算量大,实时性低,对终端设备要求较高。
为了提高人脸活体检测系统的准确度,同时减少计算量,增加实时性,本文提出了一个基于FeatherNet的改进活体检测模型,网络输入结构由Depth和IR图像组成多模态输入,并且在网络训练中进行特征级融合,增强了人脸活体特征的互补性,同时在网络中加入了注意力机制网络SENet,在提高活体检测精度的同时并不会降低检测的实时性,实验结果表明本文方法具有良好的检测效果。
2 相关工作
目前大部分深度神经网络算法都是使用单模态RGB图像作为网络输入,这种算法输入图像单一,在复杂环境中容易过拟合。为了克服单模态信息的局限性,本文将Depth图像和IR图像作为网络的输入,可以从多个不同模态的人脸图像中提取高层语义的特征表达,不仅能够提高活体检测的准确度,而且对于改善算法的泛化性和鲁棒性也有重大意义。
2.1 IR图像
真人在摄像头的成像实际是由皮肤反射的光线被摄像头的传感器所捕捉导致的,RGB图像对自然光的强弱变化比较敏感,而近红外图像具有光照不变性,不同强弱的自然光照对红外成像几无影响,针对此特性把IR图像作为算法网络的一端输入可有效提高不同光照场景下的人脸活体检测算法准确率。除此之外,近红外线还有在光滑表面例如油脂面,玻璃镜面无法成像的特性,此特性可以有效解决高清光滑打印图片攻击和电子屏幕重放攻击。图1为IR图像示例。
2.2 Depth图像
真实人脸和假体人脸在摄像机面前的本质区别在于假体人脸是真实人脸图像的二次采集产生的,这其中会造成人脸关键信息(如纹理,图像质量等)的损失以及噪声的增加。许多传统方法就是利用这种特性来设计算法的。此外不论是高清打印照片攻击还是视频重放攻击它在真实摄像头的成像都是二维,而真实人脸的成像是三维带有深度特征的图像,通过Depth模态图像作为网络的一端进行训练可以准确的提取出活体与假体人脸的深度特征差异。如图2。
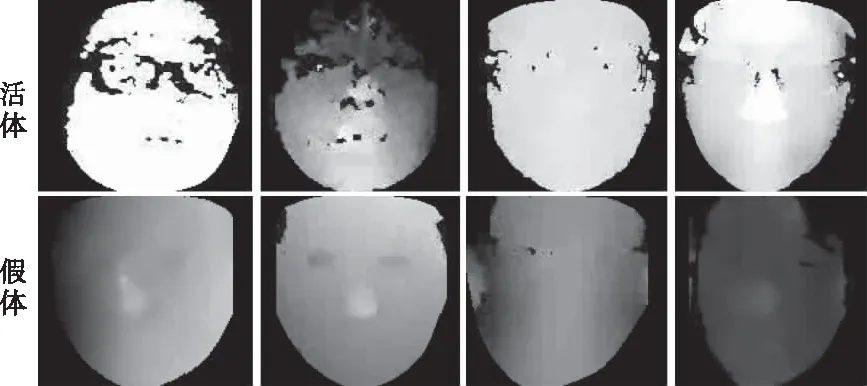
图2 Depth图像
2.3 注意力机制SEBlock
注意力机制[26](Attention Mechanism)模仿人类视觉机制,忽略相对无关区域特征,在活体检测中让网络学习更加值得关注的特征,如眼睛,嘴巴,鼻子等区域。SEBlock模块旨在通过使网络能够动态调制各通道的权重,从而重新校准特征来提高网络的表征能力。图3为SEBlock原理图。
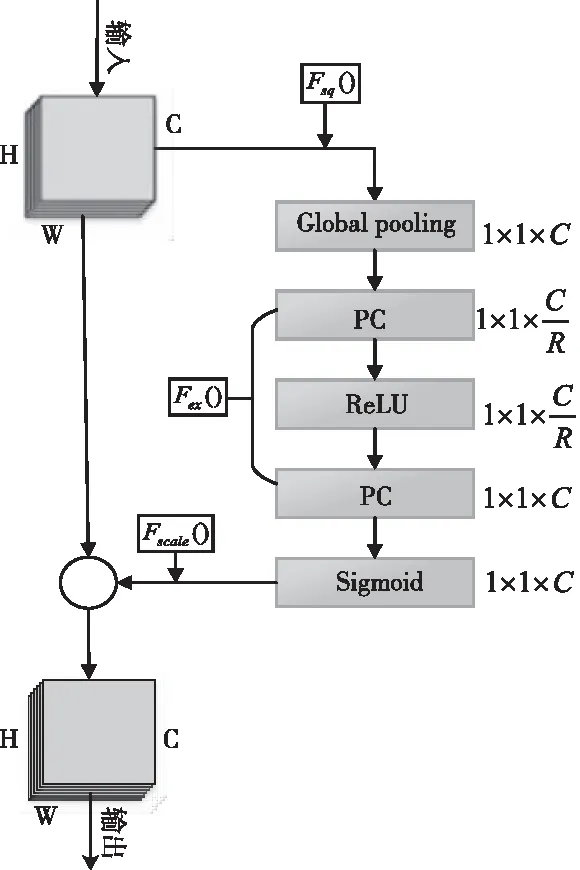
图3 SEBlock图像
2.4 网络结构
SE-FeatherNet网络结构主要综合了以下几种思想,利用Depth和IR图像的特性提取特征并进行特征融合以获得更加泛化多样的特征,基于squeeze and excitation结构的轻量级注意力机制以及FeatherNet的Stream module(流模块),在许多目标检测中许多网络算法如ResNets、DenseNet、MobileNetV2为了降低特征图的维度,减少计算量防止过拟合都是使用全局平均池化层(global average pool,GAP)。但在活体检测分类中使用GAP会对准确性产生不利影响,因为与目标检测不同,跟人脸相关的图像中心区域的特征权重应高于边缘区域,尤其是鼻子,眼睛,嘴巴等地方。一种可以区分区域权重的常见做法是使用全连接层,但是如今应用在手机等嵌入式设备的算法对网络实时性要求较高,而且参数的增多也会降低网络的泛化性,流模块(Stream module)能够较好的解决这个问题。Stream Module由深度可分离卷积[27](depthwise convolution,DWConv)和1×1的卷积层组成,先使用步长大于1的DWconv层进行下采样后展平变成一维的特征图,如下式
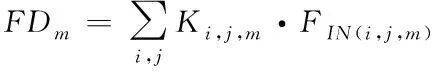
(1)
其中FDm展平后的一维特征图,K为深度可分离卷积核,F为输入特征映射图,尺度大小为,H×W×M(H,W,M分别为高度,宽度和通道数),i,j表示核K的空间位置。然后通过1×1卷积进行线性激活作为特征输出层,最后通过Softmax函数激活从而真假分类,图4为具体网络结构图。
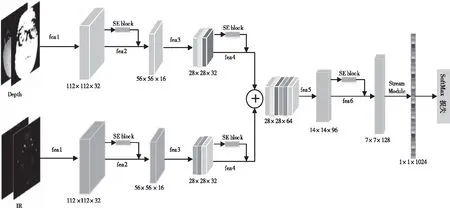
图4 SE-FeatherNet结构图
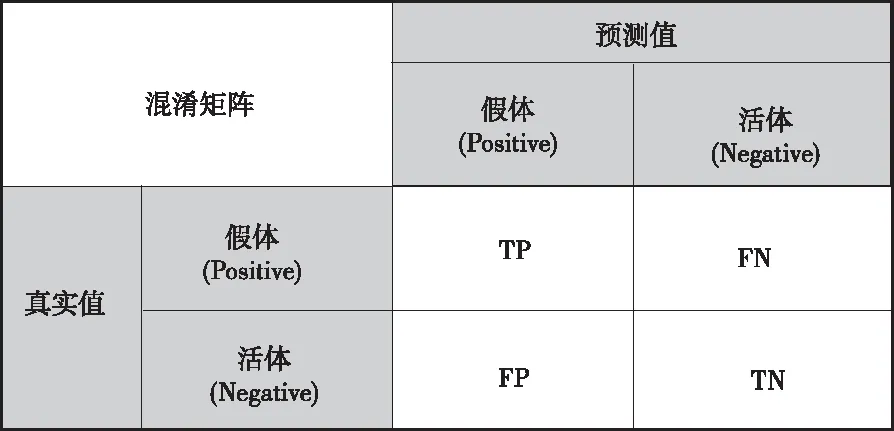
图5 混淆矩阵
3 实验与分析
3.1 数据集介绍
目前网络上公开的大部分人脸反欺骗照片数据集不论是受试人员数量(≤170)、模态(≤2)以及攻击种类方式都是比较匮乏单一的,这不利于活体检测的算法的研究发展,尤其是数据集规模太小会存在算法性能的偶然性判断。本文使用的CASIA-SURF[28]数据集是目前网络公开最大的一个图像数据集,它收集了由Intel RealSense SR300 拍摄的1000名不同年龄段受试者的21,000个视频。对视频每10帧采样1帧作为样本共计得到得到96584张人脸图像,其中假体29393张,活体67191张,每张图像都有RGB,IR,Depth3种模态。共有6中攻击类型:分别为
1) 将抠除了眼睛的A4纸平铺在脸上。
2) 将抠除了眼睛的A4纸弯曲的放在脸上。
3) 将抠除了眼睛和鼻子的A4纸平铺在脸上。
4) 将抠除了眼睛和鼻子的A4纸弯曲的放在脸上。
5) 将抠除了眼睛和鼻子和嘴巴的A4纸平铺在脸上。
6) 将抠除了眼睛和鼻子和嘴巴的A4纸弯曲的放在脸上。
3.2 模型评价标准
人脸活体检测本质是一个二分类问题,活体为负例(negative,阴性),假体为正例(positive,阳性),常用混淆矩阵来表示:
TN表示实际为活体预测也为活体的数量,TP表示实际为假体预测也为假体的数量,FP表示实际为活体预测为假体的数量,FN表示实际为假体预测为活体的数量,检测正确率(Accurary,ACCR)是最常见的评价指标,通常ACCR越高,性能越好:定义如下
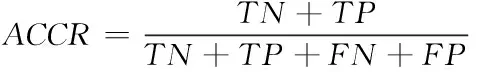
(2)
错误接受率(False Acceptance Rate,FAR)表示被错误分类的假体占所有假体样本的比例;错误拒绝率(False Rejection Rate,FRR)表示被错误分类的活体占所有活体样本的比例;等错误率(Equal Error Rate,EER)表示利用像本数据进行测试得到的ROC受试曲线上FAR和FRR相等时的值;半错误率(Half Total Error Rate,HTER)为FRR与FAR的均值;定义如下
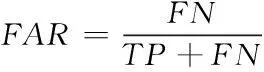
(3)
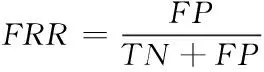
(4)
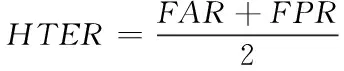
(5)
真正类率TPR(True Positive Rate)表示把假体样本正确判断为假体的比例,与错误接受率成反比,TPR@10e-2FRR表示当FRR为10e-2级别时TPR的数值,之所以采用这种形式是因为在不同的FRR度量下的TPR值是不同的,这个数值越大,算法性能越强。
3.2 结果分析
本实验将RGB图剔除,在数据集中选取70%的图片作为验证和测试的集合,其次在集合中按照相同的方式随机抽取10%的图片作验证集,剩下的作为测试集,所以整个训练集、测试集以及验证集所占比例为0.3:0.6:0.1。模型训练的硬件环境为Intel Xeon E3-1225处理器,内存16G,搭载Tesla K40C显卡,显存为12G,软件环境为在系统中搭建Pytorch的Python3.6环境进行训练,batch size为32,学习率为0.01,使用SGD优化算法,总共迭代100个epoch。具体实验环境配置见表1。

表1 本文环境配置
在实验中本文算法与FishNet150、FeatherNet、MobileNetV2、MobileLiteNet54模型进行对比实验,训练集的准确率与Loss如下图6、7,验证集的准确率如图8。
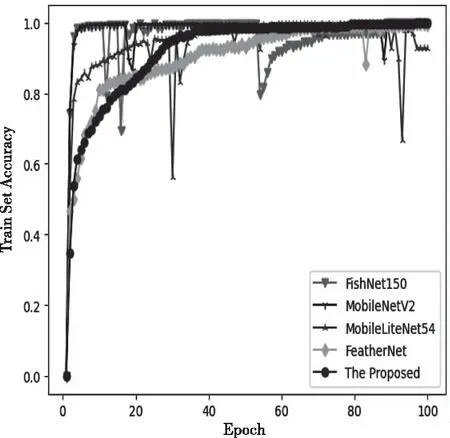
图6 训练集准确率
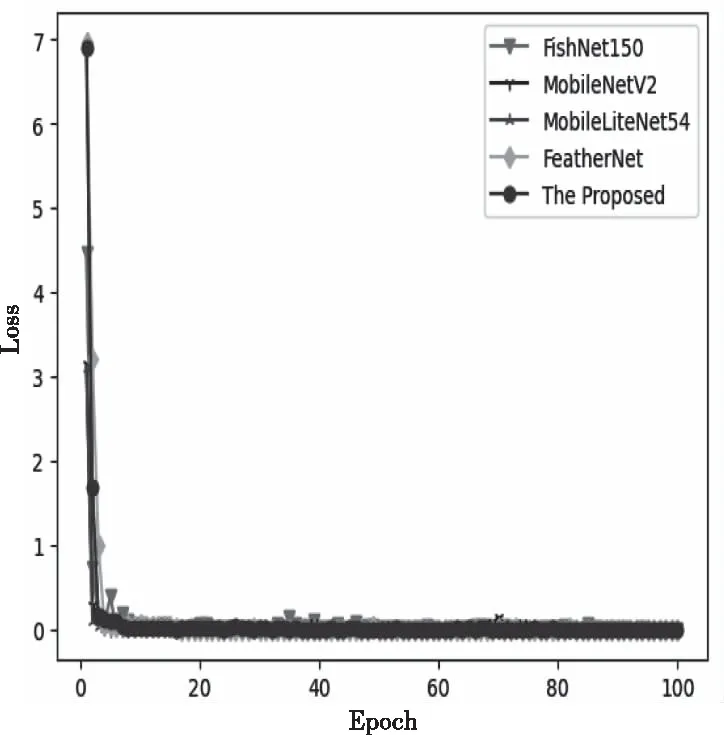
图7 训练集损失

图8 验证集准确率
从训练集准确率曲线和损失函数曲线可以得到,尽管本文所提出的方法收敛速度并没有其它几种方法快,但是其它模型或多或少会有一些比较大的抖动,鲁棒性并不高,而这种鲁棒性对于活体检测复杂多变的环境影响是非常大的。
从验证集准确率曲线图可以看出尽管每种方法在训练集上的准确率都比较高,但是在验证集的上却不尽相同,比如MobileLiteNet54网络收敛较快,但是准确率不高并且产生了过拟合,其它网络不论是准确率还是稳定性都跟本文方法有一定的差距。为了进一步比较各模型的性能,本文选取各模型在验证集上准确率最好的参数模型,分别在测试集上进行验证,结果如表2。

表2 各模型测试集数据
由表2数据可知,本文算法在各个评价标准都比较均衡,在准确率ACC、半错误率EER、HTER相比其它算法都要较好的表现,但真正类率TPR@FRR这一数值上与MobileNetV2仍有细微的差距,但较其它算法仍然一定的优越性。
4 结束语
由于在复杂环境下单RGB模态的图像不能很好的表征活体与假体人脸之间的差异性,本文在FeatherNet的基础上提出了一种IR、Depth多模态融合的深度卷积神经网络算法,有效增强提取特征的互补性以及增强了网络的泛化能力,并针对人脸图像中心区域的特征权重应当高于边缘区域,使用Stream module代替GAP的同时降低了网络的参数量,可以满足移动手机等嵌入式设备算力低和实时性高的要求,并在网络中增加了自注意力机制模块SEBlock进一步提取人脸特征。通过对比实验,不论是准确率、泛化性还是参数大小都有一定的优势。
但受限于数据集的种类和算力,针对3D打印面具的攻击,本文算法的准确率并不高,在今后的研究中会加强这一部分的研究并设计出更实用的算法模型。
