基于YOLOv5s的密集多人脸检测算法*
2023-10-24董子平陈世国廖国清
董子平,陈世国,廖国清
(贵州师范大学物理与电子科学学院,贵州 贵阳 550025)
1 引言
人脸检测作为人脸识别的重要环节,一直受到研究人员广泛关注。在教室、银行大堂、超市等人员密集场所,同一视频图像中汇集了众多人脸,人脸遮挡、人脸成像较小会大大增加人脸检测的难度,导致分辨率下降。人脸检测已经成为研究人员关注的热点。
近年来,基于深度学习的人脸检测算法不断创新,能够在不同人脸尺度、不同光照强度下检测人脸。文献[1]提出了一种基于深度残差网络和注意力机制的人脸检测算法,通过使用深度残差网络并在网络中添加注意力机制,增强了特征图在通道上的表达能力,利用IoU(Intersection over Union)损失函数提升了人脸检测的性能。文献[2]提出了以Faster-RCNN(Faster Region-based Convolutional Neural Network)[3]改进的人脸检测算法,采用ResNet-50(Residual Network-50)作为主干网络,使用多尺度融合技术和软非极大值抑制方法解决漏检重叠人脸的问题。文献[4]提出一个以YOLOv3(YouOnly Look Once version3)[5]改进的轻量化人脸检测算法,使用MobileNet[6]作为主干网络,加快检测速度;将Self-attention[7]机制与特征金字塔网络FPN(Feature Pyramid Networks)[8]机制相融合,降低环境对人脸检测任务的影响。文献[9]提出了一种基于全卷积头部检测器FCHD(Fast and aCcurate Head Detector)[10]人脸检测的改进算法,增加3个卷积层分别对图像所有位置进行检测、预测目标所在位置和判断目标是否为人脸,在20~30人的课堂中能够达到67.1%的精度,但在人数较多的教室中精度并不如意。
考虑到在人脸检测任务中需要达到实时检测的目的,本文选择近年来在目标检测任务上表现良好的YOLO系列算法。其中,YOLOv5s算法与其他版本相比,在保证检测精度的同时检测速度更快。所以,本文对其进行改进,期望得到更好的多人脸检测效果。
2 YOLOv5s结构
YOLOv5s算法的网络结构由输入(Input)、主干网络(Backbone)、特征融合(Neck)、训练(Training)和预测(Prediction)等部分组成,具体结构如图1所示。其中,Input为一幅640×640×3的RGB图像;Backbone部分交替使用CBS与C3模块(具体结构见图1),其中C3借鉴了跨阶段局部网络CSPNet(Cross Stage Partial Network)[11]结构,用于提取图像中人脸特征;Neck部分将FPN结构与路径聚合网络PANet(Path Aggregation Network)[12]相结合,将不同层的人脸特征进行融合;Training部分是在训练中先将正负样本按照采样策略进行划分,接着计算预测结果与人脸目标的损失。这种损失在本文任务中分为2部分:(1)定位损失,采用CIoU(Complete-IoU)函数;(2)置信度损失,采用BCELogits(Binary Cross Entropy Logits)函数,然后将损失回传给模型并更新参数。Prediction部分是训练完成后将不同层的预测结果进行整合,结果采用非极大值抑制NMS(Non-Maximum Suppression)算法排除冗余框,最终输出预测结果。

Figure 1 Network structure of YOLOv5s
图1中,Bottleneck结构为经过2次普通卷积的残差结构;C3×n中n为C3中含有Bottleneck残差结构的个数;Pi表示FPN结构对应的层数;Concat模块是将2个基础模块进行拼接(维度相加);Up模块是对特征图进行上采样(最近邻插)。
3 YOLOv5s算法改进
3.1 Neck结构改进
原YOLOv5s模型将8,16和32倍下采样的特征图P′1、P′2和P′3(见图1)输入Prediction部分进行预测。但是,本次任务所用数据集WIDER FACE包含了大量难以检测的小尺度人脸,将图像缩放为640×640后,其中边长小于8的人脸标签大约有64 000个,这些人脸标签在特征图P′1、P′2和P′3中所占像素并不足以表达其特征。这是因为高倍下采样特征图中的人脸语义信息丰富,但分辨率低、定位信息不足,并不利于检测小尺度人脸。
为解决以上问题,本文在Neck结构中增加4倍下采样的检测尺度,并引入FTT(Feature Texture Transfer)[13]模块。
FFT模块的结构如图2所示。FTT模块的核心思想是使用超分辨率模块将高层特征图转为分辨率更高的低层特征图,以丰富小尺度人脸的纹理特征,最终提高小尺度人脸的检测性能。

Figure 2 Structure of FTT
该模块首先使用内容提取器(Content Extractor)对模型中P2层特征图的内容特征进行提取,内容提取器使用残差模块,在不失去原有人脸特征的基础上进一步提取其内容。残差模块采用1×1卷积,目的为尽可能地保持低计算量。其次,使用亚像素卷积(Sub-Pixel Convolution)对其内容特征图进行分辨率的加倍(如图2中Sub-Pixel Conv模块)。在此部分中,本文将特征图通道数减为原有的1/4,高和宽为原有的2倍,通过分流通道维度上的像素,对宽度和高度维度上的像素进行增强。接着,对与P1层拼接后的特征图使用纹理提取器(Texture Extractor)进行纹理特征的提取。纹理提取器与内容提取器类似,也使用残差模块,目的是从主要特征和参考特征中选择可信的区域纹理。残差模块采用1×1卷积,也是为了尽可能地保持低计算量。最后,将内容提取后的特征与纹理提取后的特征相加,这样有助于融合超分辨内容特征与纹理特征。本文实验结果表明,FTT模块产生的特征图有利于检测小尺度人脸。
FTT模块的具体过程如式(1)所示:
FTT=ET(P1‖EC(P2)↑2×)+EC(P2)↑2×
(1)
其中,ET(·)代表纹理提取器;EC(·)代表内容提取器;‖表示对2个特征图进行拼接(通道维度的合并);↑2×表示对特征图高和宽进行2倍放大的亚像素卷积。
改进后的Neck结构如图3所示。其中,P′0是由Backbone中P0层特征图与Neck结构中的L层特征图先后经过FTT模块、Upsample操作后拼接产生的。此特征图包含了小尺度人脸更丰富的定位信息和纹理特征,能够提升小尺度人脸的检测效果。图3中每个平行四边形为不同卷积层的特征图大小;向上箭头为卷积操作;向下箭头为上采样操作。
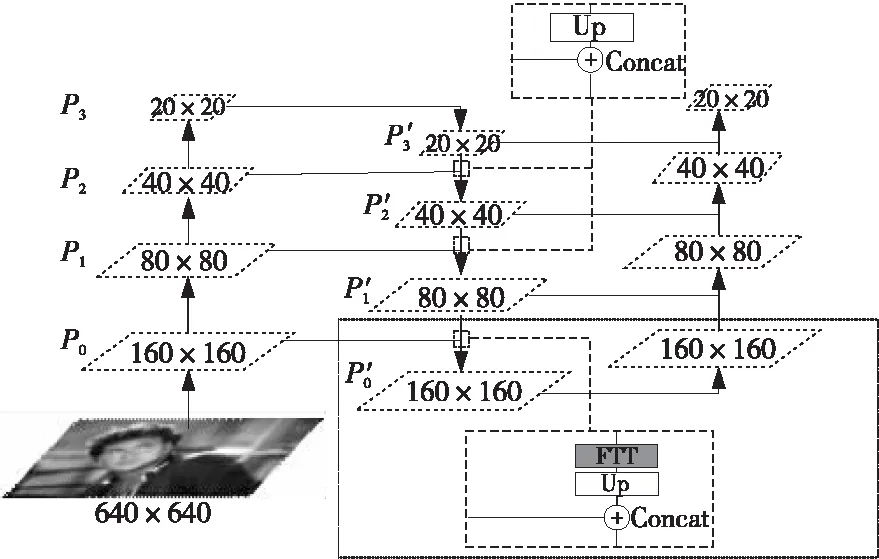
Figure 3 Structure of improved Neck
3.2 正负样本采样策略改进
在多人脸检测任务中,正样本是图像中算法感兴趣的人脸标记区域;负样本是人脸区域之外的背景区域。大多数情况下,在一幅图像中的人数不会超过100,但YOLOv5s的3层检测器会固定产生大量的待检测框(25 600个),这时正负样本数目极度不平衡,YOLOv5s训练时会严重偏向负样本,影响泛化性能。在2.1节中增加了4倍下采样特征图P′0,待检测框个数变为102 400个,这进一步增加了正负样本不平衡的程度。所以,为缓解正负样本不平衡问题,本文对正负样本的采样策略进行改进。
从图3可以看出,P′1、P′2和P′33个特征图的大小分别为80×80,40×40和20×20。YOLOv5s将这3个特征图按照上述划分方格,并使用真实框的中心点坐标在3个特征图所对应方格中的位置来判别使用哪些方格来预测物体。例如,若真实框中心点x、y坐标距离方格左上角顶点距离均小于0.5,则用左侧、上侧和中间的方格作为正样本预测人脸目标,如图4所示。

Figure 4 Sampling strategy of YOLOv5s
图4中,C为真实框的中心点,灰色区域为YOLOv5s选择的正样本。
从图4可以看出,YOLOv5s模型在正负样本采样策略中有以下2个缺点:(1)当x与y坐标较为接近方格的中心点时,下侧和右侧方格也会与真实框产生一定的交集,上侧和左侧方格也有可能作为正样本预测人脸;人脸框与预测框的长宽比大于某一个阈值时,上侧、下侧或左侧、右侧的方格都会与真实框发生一定的交集,应该根据一定的约束条件来对正样本进行采样。
根据以上2种情况,为增加正样本的数量,缓解正负样本不均衡所带来的影响,本文进行了如改进:当真实框宽中心点x、y坐标在方格中心点的[0.4,0.6]内时,将用上侧、下侧、左侧、右侧和中间方格同时预测真实目标,如图5a所示;当真实框与预测框的宽之比wgt/w>2且中心点纵坐标y<0.4(y>0.6)时,用上侧、右侧和中间(下侧、右侧和中间)的方格预测真实目标,如图5b所示(真实框与预测框的长之比大于2且中心点横坐标x<0.4(x>0.6)的情形可根据图4b同理得到)。

Figure 5 New sampling strategy for positive samples and negative samples
图5a中,虚框区域为真实框中心点x、y坐标在方格中心点坐标的[0.4,0.6]内,灰色区域为模型选择的正样本。图5b中,大的虚框区域为预测框,灰色区域为选择的正样本。
本文通过以上方式改进人脸正负样本采样策略,增加了能够有效检测人脸的正样本,提升了正样本在训练中的影响,增强了YOLOv5s的泛化能力。
3.3 定位损失函数改进
在YOLOv5s算法中,共包含3种损失:定位损失(Localization Loss)、置信度损失(Confidence Loss)和分类损失(Classification Loss)。其中,定位损失使用CIoU Loss[14]函数,CIoU Loss函数相关公式如式(2)~式(4)所示:
(2)
(3)
(4)
其中,IoU为预测框与真实框的交并比;ρ2(x1,x2)是x1和x2的欧氏距离平方,表示预测框与真实框的中心点距离差;c为覆盖预测框和真实框的最小外接框的对角线长度;b和bgt分别表示预测框和真实框的中心点坐标;w和wgt为分别表示预测框和真实框宽;h和hgt为分别表示预测框和真实框高;α是一个平衡参数,不参与梯度计算;v是用来衡量宽高比相似性的参数,当预测框与真实框宽高比不一致时,模型会通过v对预测框的宽和高进行调整。
v与w、h的梯度计算分别如式(5)和式(6)所示:
(5)
(6)
CIoU Loss函数综合考虑了预测框与真实框之间的重叠面积、中心点距离、宽高比3种回归要素。但是,CIoU Loss函数是通过式中的v来反映预测框与真实框的宽高比的差异,而不是计算预测框与其真实框的宽高的真实差异,所以有时会阻碍检测框的回归。例如,当预测框w/h的值与真实框wgt/hgt的值相等时,惩罚项αv=0,在训练过程中并不起作用,在本次模型训练中不更新参数,但真实情况中真实框与预测框的长和宽仍然存在差异。并且,从式(5)和式(6)可以算出∂v/∂w=-(h/w)×(∂v/∂h),表明模型在任意时刻只要h与w中一方增加或减少,另一方则会朝着相反的方向进行优化。这在w>wgt,h>hgt和w 考虑以上原因,本文将预测框与真实框宽高的欧氏距离平方作为惩罚项的Focal-EIoU Loss(Focal and EfficientIoU Loss)[15]函数,来代替CIoU Loss函数作为本文算法的定位损失函数。Focal-EIoU Loss公式如式(7)~式(11)所示: LFocal-EIoU=IoUγLEIoU (7) LEIoU=LIoU+Ldis+Lasp (8) LIoU=1-IoU (9) (10) (11) 其中,c、w、h、wgt、hgt与CIoU Loss函数相关公式中的含义一致;Cw为覆盖预测框和真实框的最小外接框的宽;Ch为覆盖预测框和真实框的最小的外接框的高;γ为抑制异常程度的一个参数。 Focal-EIoU Loss函数将定位损失分成了3个部分:重叠程度IoU损失LIoU、中心点距离损失Ldis和预测框与真实框边长损失Lasp。其中,LIoU和Ldis部分与CIoU Loss函数的相同,Lasp是直接将预测框与真实框边长的欧氏距离平方作为惩罚项,使得目标框回归过程中收敛速度更快,精度更高。 在YOLOv5s算法的正负样本中蕴含大量预测框与真实框的重叠程度不高的正样本(如图6所示,左侧和上侧的正样本与真实框的IoU基本为0,事实上并不能够作为正样本来影响训练),基于这些样本获得的模型会关注这些并不真正重要的正样本。而Focal-EIoU Loss函数中的Focal能够很好地解决这一问题。其与传统的Focal Loss有一定的区别,传统的Focal Loss函数在面对困难的样本时会给出更大的权重,训练时更加关注困难样本。从式(7)可知:预测框和真实框的IoU越高,预测框损失越大,相当于加权作用,给更接近真实框的预测框更大的权重,这有助于提高回归精度。因此,本文选用Focal-EIoU Loss作为预测框回归的损失函数。 本文对YOLOv5s算法进行改进,提出多人脸检测IYOLOv5s-MF(Improved YOLOv5s-Multi-Face)算法。IYOLOv5s-MF网络结构如图7所示。 Figure 7 Network structure of IYOLOv5s-MF 本文通过在Neck结构中加入FTT模块,提升了YOLOv5s对小尺度人脸的检测能力;通过改进正负样本采样策略,增加有效正样本,提升了正样本在YOLOv5s中的影响,增强了其泛化能力;使用Focal-EIoU Loss函数作为定位损失函数,进一步提高预测框的回归精度。从以上3点对YOLOv5s算法进行改进,提出了多人脸检测IYOLOv5s-MF算法。 本文所有实验均在Python 3.7和PyTorch 1.10.0搭建的深度学习框架上进行,GPU为 NVIDIA TESLA P100,显存为16 GB。 WIDER FACE数据集是一个人脸检测基准数据集,其中的图像是从公开可用的WIDER数据集中选择的。数据集中有32 203幅图像,共标记了393 703幅在比例、姿势和遮挡方面具有高度可变性的人脸图像。WIDER FACE数据集基于61个事件类进行选择,对于每个事件类,随机选择40%,10%和50%的数据分别作为训练集、验证集和测试集。每一个子集都包含3个级别的检测难度:Easy、Medium和Hard,这3个级别是根据EdgeBox[16]的检出率来规定的。其中,Easy难度的主要指尺度较大、无遮挡情形、正常光照下的人脸图像;Medium难度的主要指尺度适中、遮挡较小的人脸图像;Hard难度的图像主要指密集人脸、模糊人脸、遮挡人脸和小尺度人脸。所以,WIDER FACE数据集适合用来测试本文算法在真实场景下多人脸检测的应用效果。 4.2.1 Mosaic数据增强 本文使用原YOLOv5s算法的Mosaic数据增强方法。该方法每次将数据集中的4幅图像拼接成1幅大图,然后经过随机放缩、左右翻转和随机剪切等操作,最后放缩为640×640大小的图像(如图8所示),以此增加数据多样性,最后将增强后的数据输入IYOLOv5s-MF模型中。 Figure 8 Mosaic data enhancement 4.2.2 参数设置 本文设置训练图像大小为640×640;训练最小批次为40;总共训练200个epoch;优化器选择随机梯度下降法SGD(Stochastic Gradient Descent)[17];采用余弦退火算法进行学习率的更新;使用K-means聚类算法为WIDER FACE数据集计算锚框大小,如表1所示。 Table 1 Sizes of new anchor 4.2.3 模型评估指标 本文评估指标包括浮点运算次数GFlops(Giga Floating-point Operations)、参数量和平均精度AP(Average Precision)。其中,AP值与精确率P(Precision)和召回率R(Recall)有关,P是指预测数据集中预测正确的正样本个数与模型预测为正样本的个数的百分比;R是指预测数据集中预测正确的正样本个数占实际为正样本的个数的百分比。上述衡量指标的计算分别如式(12)~式(14)所示: (12) (13) (14) 其中,TP、FP和FN分别表示预测正确的正样本个数、预测错误的正样本个数和实际正样本却预测为负样本的个数。 YOLOv5s模型和IYOLOv5s-MF模型的训练均使用WIDER FACE数据集和预训练模型YOLOv5s.pt。为证明IYOLOv5s-MF模型的有效性,本文进行了消融实验与对比实验。 消融实验是为了验证每步改进都是可行且有效的,实验结果如表2所示。 Table 2 Ablation experiments 从表2中实验2的数据可以看出,加入FTT模块后,与原YOLOv5s模型相比,在WIDER FACE数据集的Easy子集上AP值降低了0.24%,在Medium子集上AP值提高了0.2%,在Hard子集上AP值提高了2.42%,参数量和模型复杂度略有增加;从实验3的数据可以看出,与原YOLOv5s模型相比,使用改进正负样本抽样策略后,在Easy子集上AP值增加了0.32%,在Medium子集上AP值提高了0.40%,在Hard子集上AP值提高了1.03%,参数量和模型复杂度与实验1的持平;实验4中将定位损失函数改为Focal-EIoU后,与原YOLOv5s模型相比,在Easy子集上AP值增加了0.33%,在Medium子集上AP值提高了0.44%,在Hard子集上AP值提高了1.16%,参数量和模型复杂度与实验1的持平。 最后,将3种改进方法同时加入模型(IYOLOv5s-MF),从实验5的数据可以看出,与原YOLOv5s模型相比,在Easy子集上AP值增加了0.22%,在Medium子集上AP值提高了0.48%,在Hard子集上AP值提高了3.46%,参数量和模型复杂度略有增加。实验5的数据表明,IYOLOv5s-MF模型对小尺度人脸和人员密集有遮挡情形图像的检测性能有一定的提升。此外,本文在同等情况下对模型速度进行了测试,改进后的模型平均检测时间虽然有一定增加,但仍然满足实时性要求。 为了更直观地观察IYOLOv5s-MF模型的优势,本文选取了一些图像对原YOLOv5s模型与IYOLOv5s-MF模型的检测效果进行对比,如图9所示。 Figure 9 Effect contrast 从图9可以看出,YOLOv5s算法在人员密集的地方有发生错检和漏检的情况,在图9a中用圆圈画出,而图9b中的结果表明,本文算法在一定程度上改善了漏检和错检的情况。 对比实验是与其他先进算法进行对比,以更好地展现IYOLOv5s-MF算法的优势,验证其有效性。本文对比实验是使用DSFD(Dual Shot Face Detector)算法[18]、RetinaFace[19]算法和TinaFace[20]算法在人脸检测任务上进行对比。这些算法均使用WIDER FACE数据集进行训练和验证,如表3所示。表3展示了各算法在3个难度数据子集上的AP值、参数量和模型复杂度。 Table 3 Comparative experiments 从表3可以看出,本文算法相较于DSFD算法和RetinaFace(ResNet50)算法具有较大优势,能够在保证算法复杂度较低的同时在3种难度子集上的检测精度更高;而RetinaFace(MobileNet 0.25)算法虽然算法复杂度较低,但检测精度却远远低于以上几种算法的;相较于TinaFace算法,本文算法在Easy、Medium难度子集上的AP值略低于TinaFace算法的,但本文算法在困难样本上的表现却比TinaFace算法的好一些,而且本文算法的参数量是TinaFace算法的1/5,在模型复杂度方面远远低于TinaFace算法的。综上所述,本文算法能够在模型复杂度较低的情况下保证在密集环境中多人脸检测的精确性。 本文对YOLOv5s的3个方面进行改进,以提升多人脸检测精度。在YOLOv5s的Neck结构中应用FTT结构,以提升小尺度人脸检测精度;针对正负样本不平衡的问题,在原有正负样本抽样策略上进行改进,增加了有效正样本;针对CIoU Loss函数无法有效反映预测框与真实框的宽高损失,使用Focal-EIoU Loss函数进行人脸框的定位。实验结果表明,相较于原YOLOv5s,虽然改进后的算法在复杂度、平均检测消耗时间上略有增加,但仍然满足了实时性要求,并且在WIDER FACE数据集3个不同难度的子集上分别达到了94.90%,92.99%和83.55%的平均精度,说明能够应用于密集场景中。3.4 IYOLOv5s-MF结构

4 实验与结果分析
4.1 实验环境及数据集介绍
4.2 数据预处理及参数设置



4.3 消融实验


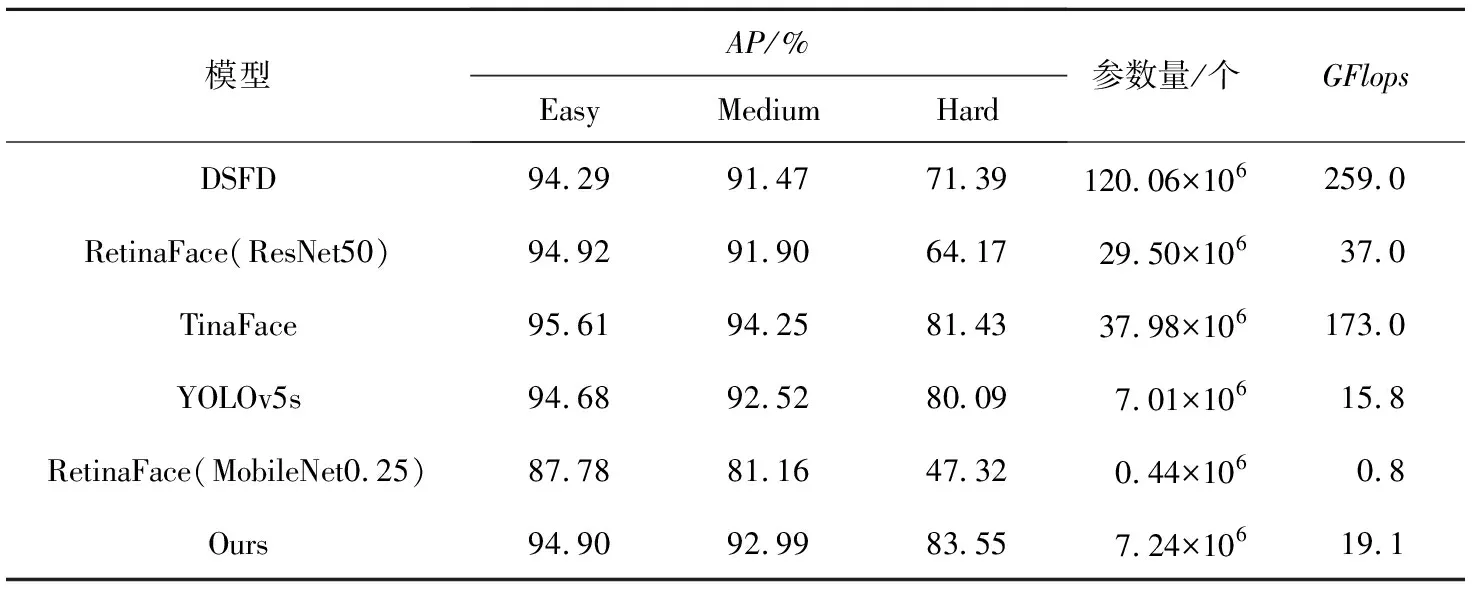
4.4 对比实验
5 结束语
