基于改进3D ResNet的视频人体行为识别方法研究*
2023-10-24牛为华翟瑞冰
牛为华,翟瑞冰
(1.华北电力大学计算机系,河北 保定 071003;2.华北电力大学复杂能源系统智能计算教育部工程研究中心,河北 保定 071003)
1 引言
视频人体行为识别研究是近些年图像识别领域的一个热门研究方向,同时也在社会各个行业得到了广泛应用,比如电厂工人规范化行为监控、智能医疗方面的AI康复训练等。相比较单幅图像的行为识别,基于视频的人体行为识别技术是在其基础上加入了人体行为时序信息,使得识别的准确率得到提升。但是,由于人体运动时背景的复杂性和多变性、视频图像在不同视角的差异性,以及存在遮挡抖动等客观因素的影响,该技术仍有很大的研究空间[1]。
视频分类领域发展至今,基于深度网络的视频人体行为识别研究方向由基于2D卷积的循环神经网络RNN(Recurrent Neural Network)、双流卷积神经网络Two-Stream CNN(Convolutional Neural Network)向3D卷积神经网络3D CNN转变。起初,在RNN发展过程中衍生了许多具有针对性的变体,比如长短期记忆神经网络LSTM(Long Short-Term Memory)。Liu等[2]在LSTM中加入了新的门控机制来保证顺序输入数据的可靠性,同时调整存储在记忆单元中的长期上下文信息的更新效果,以处理3D数据中的噪声和遮挡问题。Zhang等[3]设计了一个具有LSTM架构的自适应循环神经网络,使网络本身能够在一端到另一端之间寻找最合适的观察视点,当一个行为发生时可以自动调节观察视点。Meng等[4]提出了一种可解释的、易于插入的视频识别时空注意机制,以解决视频的信息冗余问题。在这个阶段,Simonyan等[5]提出了双流卷积网络并用于视频人体动作识别。之后,Ye等[6]提出将LSTM与基于RGB和光流的双流卷积网络结合起来,采用适当的融合位置和融合方法使模型达到最佳性能水平。
以上2种网络架构大多是使用2D卷积神经网络进行研究。针对视频人体行为的时空特征,使用3D卷积似乎能更好地表达。近些年来,随着对3D卷积的不断研究,3D CNN在动作识别领域的性能水平有了显著提高。3D卷积最早在2013年被提出并用于行为识别,Ji等[7]基于3D卷积在时间和空间3个维度获取特征,实现了利用3D卷积进行人体行为识别的方法。后经发展,C3D(Con-volutional 3D)作为一个通用的网络被提出来[8]。2018年,Hara等[9]通过实验研究发现,多个3D CNN需要由大量的标签视频来优化3D内核,才能使其发挥出更好的效果。同时,该文献在ResNet结构中引入多个3D CNN,3D ResNet(Residual Network)开始进入人们的视线。但是,目前传统的多3D CNN方法虽然可以获取时序信息,却需要大规模数据集预训练的支撑,并且,传统的3D卷积神经网络泛化性能差,相比2D卷积,计算量增加、内存占用更大,进而限制了网络深度,无法获取更加丰富、抽象的特征。
针对以上现有方法存在的问题,本文提出一种基于改进3D ResNet的视频人体行为识别方法。该方法使用3D ResNet-50作为主干网络,将3D ResNet-50内的较大卷积核拆分为2个非对称卷积核的串联;并在改进网络的平均池化层之后加入CBR(Convolution-Batch normalization-ReLU)模块,对行为特征进行更深入和更充分的提取和分析。连续的视频图像数据输入网络,先经过2次3D卷积进行时间和空间上的3D特征提取,再通过4个基础模块Layer对特征进行进一步的分析和处理,之后连接自适应全局平均池化层和CBR模块,再将输出数据展为一维并在全连接层FC(Fully Connected layers)进行特征映射。该改进方法既提高了视频人体行为识别的准确率,又优化了网络的泛化能力,且能够克服识别过程中的遮挡、光线、相似人体干扰等问题。
2 3D ResNet网络结构
2.1 3D卷积
传统的2D卷积输入数据为单帧图像,内部核心是2D卷积核(i×i)。由于2D卷积的卷积计算只涉及空间维度,即以单帧图像的高度和宽度为维度进行计算,所以当待处理问题涉及时序信息时会在很大程度上由于丢失时序信息而无法进行精确分类[10]。在3D卷积中,输入数据是多帧连续的图像。在计算时,3D卷积将2D卷积的卷积核由i×i改进为i×i×i的形式,这也是3D卷积同2D卷积的本质区别。多个视频连续帧按照时序依次通过3D卷积层进行计算,即获得了具备时序性的运动特征信息。整个计算过程如式(1)所示[11]:
(1)
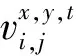
2.2 3D ResNet网络
3D ResNet网络的内部卷积核采用3D卷积,其网络结构同2D ResNet网络的类似,由一个个基础模块Layer构成,这些Layer内部又包含若干残差块。残差块按照结构的不同分为2类:BasicBlock和Bottleneck[12]。残差块的核心为残差结构,即每隔几层卷积增加一个Skip-Layer。在传统神经网络每层顺序连接的基础上,Skip-Layer会将残差块的顶部连接到块中最后一个ReLU激活函数之前的网络层,即输入数据不仅顺序通过网络,同时还会经历一次跳跃连接(Skip Connection)。
3D ResNet-18和3D ResNet-34网络采BasicBlock残差块。BasicBlock[13]由2个3×3×3卷积层组成,每个卷积层之后是批归一化BN(Batch Normalization)层以及ReLU激活函数层。BasicBlock结构如图1所示。

Figure 1 Structure of Basicblock
若想加深网络深度以处理更复杂的问题,则使用另一种残差块——Bottleneck[13],比如3D ResNet-50网络、3D ResNet-101网络等。更深的网络对显存和算力有更高的要求,在算力有限的情况下,深层网络中的残差块应当减少算力消耗,因此在Bottleneck中会使用2个1×1×1卷积层和1个3×3×3卷积层[14]。该类卷积层的优势是可以在更深的网络中用较小的参数量处理通道数很大的输入数据。深层次的3D残差网络更适合处理具备时序信息的人体行为识别问题[15]。Bottleneck结构如图2所示。

Figure 2 Structure of Bottleneck
3 改进的3D ResNet
基于3D ResNet在处理人体行为识别问题中的优势,本文在此网络基础上提出了一种基于改进3D ResNet的视频人体行为识别方法。该方法使用3D ResNet-50作为主干网络,首先结合非对称卷积的思想对网络中的较大3D卷积核进行拆分;其次构建CBR模块,置于网络的最大池化层之后。该方法的整体网络结构如图3所示,其中,A模块指网络中的若干对3D非对称卷积串联的结构,包括用于特征提取的1×7×7卷积层和7×1×1卷积层的串联以及各Layer内1×3×3卷积层和3×1×1卷积层的串联。

Figure 3 Structure of improved 3D ResNet
本文方法所提出的改进3D ResNet网络结构包含4个基础模块Layer,每个Layer内包含若干个Bottleneck。Bottleneck内部具体结构如图4所示。

Figure 4 Structure of improved Bottleneck
本文方法对主干网络3D ResNet-50的具体改进如下:
(1)对网络中的大卷积核进行拆分。首先,将用于特征提取的7×7×7卷积层改为1个1×7×7卷积层和1个7×1×1卷积层的串联;其次,将Bottleneck中3×3×3卷积层改为1个1×3×3卷积层和1个3×1×1卷积层的串联。
(2)在模型的全连接层(FC)之前插入CBR模块。CBR模块包括1层1×1×1卷积(Convolution,Conv)、1层BN和1层ReLU激活函数。
改进的3D ResNet网络结构的内部参数设置具体如下:首先,该网络结构的输入数据为RGB类型,输入尺寸为[3,16,112,112]。
其次,该网络对输入的连续多帧视频图像进行时间和空间上的3D特征提取,依次进行2次3D卷积、必要的BN、ReLU和1次全局最大池化操作,其中卷积和池化的具体参数设置如下所示:
(1)第1次卷积采用大小为1×7×7的卷积核,卷积核数目为110,步长为[2,1,1],Padding为[0,3,3],输出RGB网络尺寸为[110,8,112,112];
(2)第2次卷积采用大小为7×1×1的卷积核,卷积核数目为64,步长为[1,2,2],Padding为[3,0,0],输出RGB网络尺寸为[64,8,56,56];
(3)最大池化的卷积核大小为3×3×3,步长为[2,2,2],Padding为[1,1,1],输出RGB网络尺寸为[64,4,28,28]。
提取到的特征数据会通过4个Layer进行进一步分析和处理。对于任一Layer内的首个Bottleneck,会通过跳跃连接对获得的特征进行下采样(Downsample),而剩下的Bottleneck只进行顺序连接,不会通过跳跃连接。每个Bottleneck包含若干个必要的BN层和ReLU层。针对网络中的下采样部分,第1个基础模块Layer1内的首个Bottleneck内置1个步长为[1,1,1]的1×1×1卷积层和1个BN层,余下基础模块内的首个Bottleneck内置1个步长为[2,2,2]的1×1×1卷积层和1个BN层。此外,每个Layer内的Bottleneck在顺序连接路径上会依次经过:
(1)1次1×1×1卷积操作:步长为[1,1,1],Padding为[0,0,0],输出RGB网络尺寸为[256,4,28,28];
(2)1次1×3×3卷积操作:步长为[1,1,1],Padding为[0,1,1],输出RGB网络尺寸为[512,2,14,14];
(3)1次3×1×1卷积操作:步长为[1,1,1],Padding为[1,0,0],输出RGB网络尺寸为[1 024,1,7,7];
(4)1次1×1×1卷积操作:步长为[1,1,1],Padding为[0,0,0],输出RGB网络尺寸为[2 048,1,4,4]。
上述4次卷积操作中的具体卷积核数目如表1所示,表内Kernel Num列数据代表Layer中每一层卷积的卷积核数目,其中每个Layer内的Bottleneck包含3个大小为1×1×1的卷积层,对应3个不同的卷积核数目。

Table 1 Internal parameters of each layer of the model
经过4个Layer之后的输出数据会进行一次自适应全局平均池化操作,然后进入CBR模块。CBR模块包含1个卷积核大小为1×1×1的卷积层,该卷积层步长为[1,1,1],Padding为[0,0,0],除此之外还包含1个BN层和1个ReLU层。CBR模块的输出RGB网络尺寸为[2 048,1,1,1]。
最后将CBR模块的输出数据展为一维并经过全连接层FC进行特征映射,输入大小为2 048,输出大小为101,输出即为类别数量。
4 实验及结果分析
4.1 数据集与预处理
UCF101数据集是人体行为识别研究领域的一个公用数据集。该数据集主要从视频网站获取特定类别的人体行为视频,共分为101个动作类别,比如击剑、爬行、打篮球等。UCF101数据集规定每一类行为都由25个实例构成,且每个实例有4~7组视频数据[16],因此该数据集共有13 320段视频作为人体行为实例。UCF101数据集因其视频内容都是人体实例在无限制和无预先排练的前提下,在真实环境中随机拍摄的网络视频,在人体外观、视频背景、动作幅度和表现形式方面具有很大的多样性[17]。另外在摄像机类型、视频光线、视频分辨率等方面也存在较大的差异。
在数据预处理阶段,首先,将视频数据集划分为训练集和测试集,划分结果如表2所示。划分方式采用UCF101 Train TestSplits Recognition Task内的testlist01方式。其次,将数据集内的每个视频转换为图像序列,按照原始帧率每一帧提取一幅视频图像,并将图像分辨率大小固定为240×240。接着,保持图像中心点不变,对图像进行裁剪,Sample size设为112。采用这种数据预处理方式可以最大程度地保留原始数据的信息,以便对数据进行更充分的特征提取。按照一定的规律对这些图像帧序列进行间隔抽取,最终得到的输入数据大小可表示为[batch size,3,16,112,112],其中batch size为批处理大小;3为图像通道个数;16表示一次处理的连续且不重叠的图像帧数;而图像大小为112×112。

Table 2 Partition results of UCF101 dataset
4.2 实验环境
本文实验采用深度学习框架PyTorch 1.1.0版本作为实现平台,GPU规格为NVIDIA®Tesla®P40 24 GB。模型训练超参数设置如表3所示。

Table 3 Super parameters setting of model training
4.3 实验结果分析
为验证本文方法所提出的非对称卷积A模块和CBR模块在3D ResNet网络中的改进能提高人体行为识别的准确率,进行了4组消融实验。在超参数和实验环境不变的情况下,分别使用3D ResNet-50、3D ResNet-50+A模块、3D ResNet-50+CBR模块和本文方法所提出的改进模型,即3D ResNet-50+A模块+CBR模块在UCF101数据集上进行训练和测试。本文实验对各个网络从头开始进行训练,即无预训练。
图5和图6为200轮迭代过程中各个模型每一轮测试时的Top1准确率、Top5准确率变化情况。Top1准确率和Top5准确率是公认的图像分类评价标准,具有普遍性和可参照性。从图5和图6可以看出,在200次迭代中,分别结合A模块和CBR模块后原始3D ResNet模型均有准确率上的提升,而融合A模块和CBR模块的改进方式,不但增强了卷积层对图像帧时序信息的特征提取,也加深了网络层数,进而可以对特征进行更充分的分析,所以其准确率提升最大。

Figure 5 Change of Top1 accuracy rate in 200 iterations
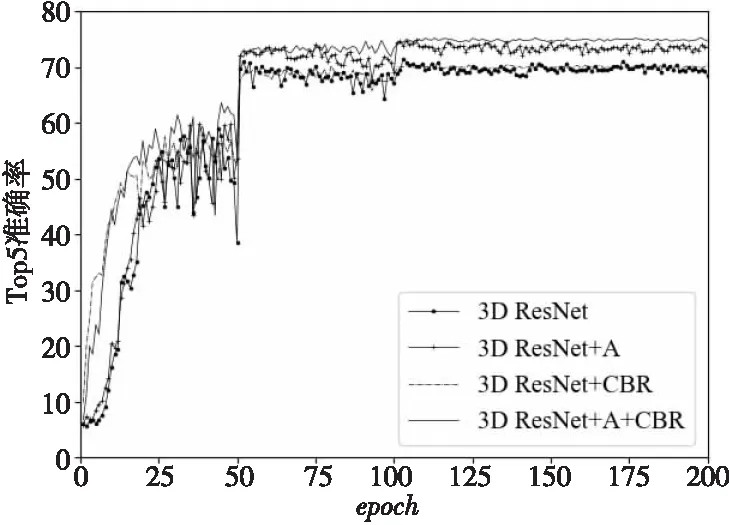
Figure 6 Change of Top5 accuracy rate in 200 iterations
表4为消融实验中各组模型在200次迭代后的Top1准确率和Top5准确率。本文方法在200次迭代后的Top1准确率趋于50%左右,Top5准确率趋于75%左右。相比较原始3D ResNet模型,本文方法在Top1准确率上高出了4.03%,Top5准确率上高出了4.99%。
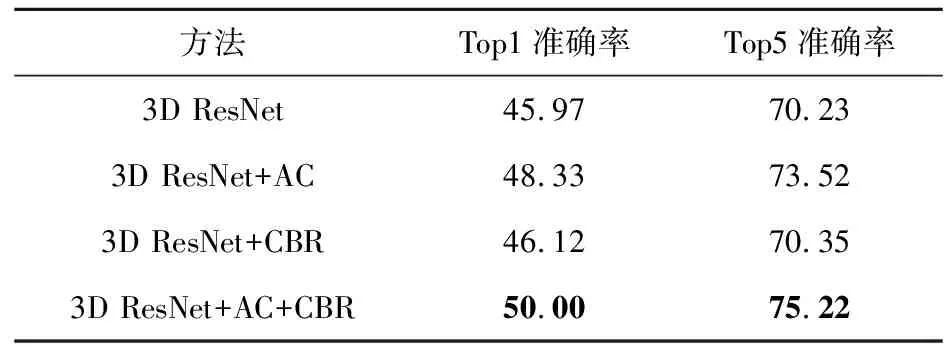
Table 4 Comparison of accuracy of Top1 and Top5 of each method
损失函数Loss越小,模型的鲁棒性就越好。图7为200轮迭代过程中各个模型每一轮Loss数值变化的情形。从图7可以明显看出,在迭代过程中,3D ResNet-50+A模块+CBR模块的Loss数值远远小于原始3D ResNet的,也小于其它3组实验的。在迭代100轮后,Loss值趋于平稳。此时3D ResNet-50+A模块+CBR模块的Loss值比原始3D ResNet的低大约0.5,表明与原始网络相比,本文方法鲁棒性更好,泛化能力更强,可以有效解决人体行为识别过程中因数据集的复杂背景和遮挡等造成的训练不充分问题。
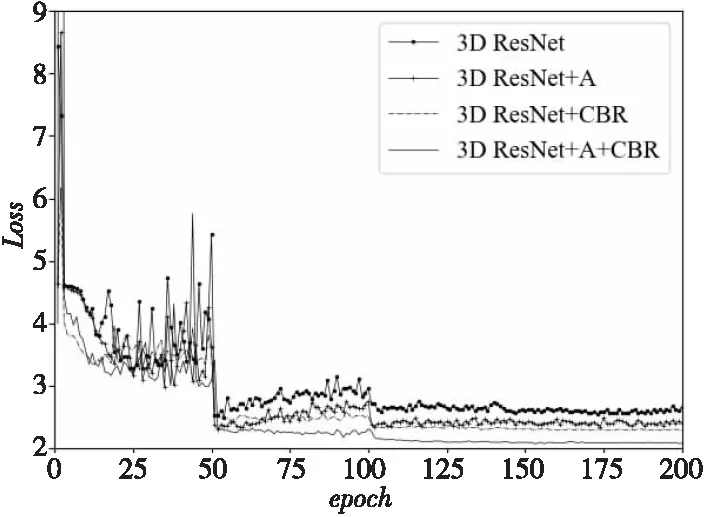
Figure 7 Loss value change in 200 iterations
为进一步研究人体行为识别过程中因数据集的复杂背景和遮挡等而造成的训练不充分问题,在UCF101数据集上选取了部分动作类别的混淆矩阵,如图8所示,主要研究在光线、遮挡、复杂背景和相似人体干扰情况下,本文方法对人体行为识别的效果。由图8可以看出,本文方法对具有明显遮挡的行为(冲浪)识别效果突出,对光线影响较大的行为(击鼓、荡秋千)和相似人体干扰(投篮、扣球)的行为识别效果相对良好,但对复杂背景(卧推)的识别稍显不足,因其背景的复杂性,很容易将其识别为具有强烈光线变化的击鼓行为。
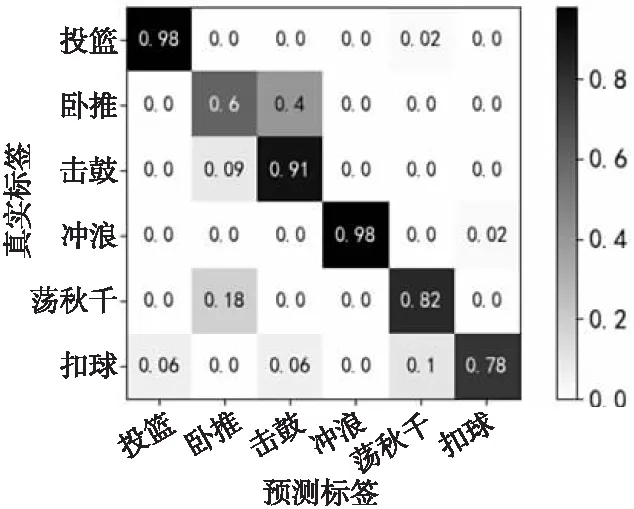
Figure 8 Confusion matrix of UCF101 dataset
将本文方法与 C3D[18]、I3D(two-stream Inflated 3D ConvNets)[19]、3D ResNet、3D DenseNet[20]以及将通道注意力机制SE(Squeeze-and-Excitation)[21]与3D ResNet结合的 SE-ResNet在UCF101数据集上进行比较,实验结果如表5所示。
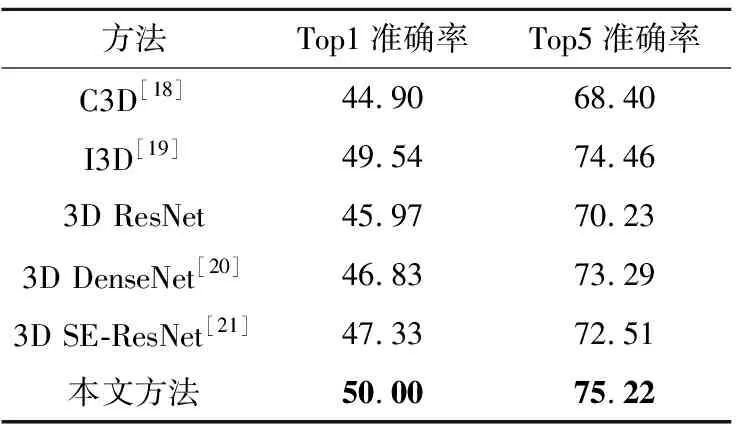
Table 5 Comparison of experimental results
文献[18]中的C3D是用于人体行为识别的一个通用网络,是人体识别领域3D研究的基础。文献[19]中的I3D网络将膨胀卷积应用到视频研究领域。文献[20]中的3D DenseNet是在3D ResNet基础上的改进网络,其明确区分了添加到网络中的信息和保存的信息,具有更好的参数效率。文献[21]提出了通道注意力机制并将其作为一个模块插入到网络中。从表5可看出,本文所提出的在3D ResNet基础上,融合非对称卷积A模块和CBR模块的视频人体行为识别方法准确率更高。相比较主流方法C3D、I3D和3D ResNet,其Top1准确率分别提高了5.10%,0.46%和4.03%,Top5准确率分别提高了6.82%,0.76%和4.99%。相比较基于3D ResNet的改进网络3D DenseNet和3D SE-ResNet,准确率也均有提高。
5 结束语
本文提出了一种基于3D ResNet,融合非对称卷积A模块和CBR模块的视频人体行为识别方法。首先,将3D ResNet网络中卷积层拆分为一个卷积层和一个卷积层的串联对图像帧序列进行下采样获取图像特征;然后,将Bottleneck中的卷积层拆分为一个卷积层和一个卷积层的串联,以减少资源的消耗并对图像特征融合时空信息进行处理分析;最后,通过增加CBR模块来加深网络层数,以获取更复杂的特征。实验结果表明,本文提出的视频人体行为识别方法能够提高识别准确率,且有较好的泛化能力,能够克服光线、遮挡、相似人体干扰等识别中的问题,但对复杂背景的处理还需进一步研究。在接下来的工作中,要考虑如何弱化复杂背景的干扰;考虑重定位人体位置、缩小运动区域,或者模糊背景等方法;同时还考虑在无预训练、小规模的数据集上如何更进一步地提升准确率、减少模型参数量、降低训练时间。
