基于XLNet-CBGRU 的双模态音乐情感识别
2023-10-24董晓斌
董晓斌,王 亮
(沈阳化工大学 计算机科学与技术学院,辽宁 沈阳 110020)
0 引 言
随着时代与互联网的快速发展,越来越多的音乐创作者能够在网络上尽情地展示自己的作品。音乐作为一个信息的载体,其中蕴含了丰富的情感信息。由于音乐的组成特性,创作者能够通过歌词、旋律、声调、海报等形式来传达自己想要表达的情感。传统的音乐情感识别采用单一的模态对音乐这种复杂的作品进行情感识别,这样往往会带来信息丢失、识别准确度不高等问题,因此多模态音乐情感识别逐渐成为学者们的研究重点。
本文提出一种XLNet-CBGRU 音乐歌词情感识别模型,首先通过XLNet 模型,充分考虑上下文位置信息,学习到文本的动态特征向量,之后通过双向GRU 网络学习文本的深层语义得到音乐歌词的情感特征。对于音乐音频使用卷积神经网络提取局部特征后再作为输入,输入到双向GRU 学习音频的时序信息得到音乐的音频情感特征。最后利用互注意力机制对歌词和音频特征进行加权融合,最终对音乐的情感类型进行预测。实验结果证明,本文所使用的方法在预测准确度上有一定的提升。
1 相关研究
1.1 音频情感识别
随着深度学习的不断发展,目前音乐音频情感识别的研究重心以从传统的机器学习转移到深度学习。Li 等人提出了一种基于DBLSTM-ELM 的动态音乐情感识别模型,该模型将LSTM 与极限学习机相结合,在DBLSTM 训练出结果后再由ELM 进行融合[1]。郑艳等人结合深度学习网络的特性,提出了一种新的模型CGRU,模型由CNN 与GRU 相结合,对MFCC 特征进行提取后再由随机深林进行特征的选取,提高了识别的精度[2]。Xie 等人提出了一种基于帧级音频特征并结合LSTM 的情感识别方法,用帧级特征代替传统的统计特征,并根据注意力机制传统的LSTM 进行改进,最终在模型性能上获得了提升[3]。王晶晶等人为了提高模型效率,提出了新的网络模型LSTM-BLS,该模型将深度学习与宽带学习相结合,利用宽带学习快速处理数据能力,将LSTM 当作BLS 的特征映射节点,提高了情感识别的效率[4]。钟智鹏等人针对LSTM 的效率低下以及长距离依赖问题,提成了一种新的网络模型CNN-BiLSTM-SA[5]。
1.2 文本情感识别
随着自然语言处理领域的快速发展,音乐的歌词情感识别也得到了学者的重视。吴迪等人针对传统文本情感识别模型不能根据上下文信息动态获取词向量问题,提出一种基于ELMo-CNN-BiGRU 的情感识别模型,对ELMo 和Glove 两种预训练模型生成的动态与静态词向量通过堆叠得到输入向量,再通过CNN 和BiGRU 提取局部特征和全局特征,最终完成情感识别[6]。Liu Ning 等人提出了一种基于BERT 的文本情感识别算法,该算法利用BERT 提取出句子级向量,再结合CNN 和对抗网络完成情感识别[7]。梁淑蓉等人针对BERT 模型上下游任务不一致的问题,提出一种基于XLNet-LSTM-Att 的文本情感识别模型,该模型首先通过XLNet 生成考虑上下文信息的特征向量,再通过LSTM 进一步提取上下文特征,最后结合注意力机制完成情感识别[8]。
1.3 多模态情感识别
音乐作为一种人类情感的载体,它是由多个部分共同组成的。一首歌曲的曲调、歌词、海报、演唱者的声调等都在传递着情感信息。多模态融合主要有早期融合和晚期融合两大类型。早期融合是在数据级和特征级的融合,而晚期融合是在决策级的融合。决策级融合存在忽略了模态之间的关联性以及不能对不同类别赋予不同权重的问题。王兰馨等人提出一种结合Bi-LSTM-CNN 的双模态情感识别模型,该模型包括基于文本的Bi-LSTM-CNN 模型和CNN 模型,并分别验证了特征级融合和决策级融合的效果[9]。张昱等人提出一种基于双向掩码注意力的多模态情感分析模型BMAM,该模型通过掩码注意力动态地调整不同模态间的权重,继而获得更准确的模态表示[10]。文献[11]是从不同模态中提取数据并使用数据级的融合完成情感识别。奚晨是在特征级融合的基础上引入互注意力机制,通过计算自动为不同模态添加权重以体现模态间的重要性程度[12]。
2 基于深度学习的多模态音乐情感识别
2.1 基于CNN-BiGRU 的音乐音频情感识别
音频信号是一组在8 ~44.1 kHz 频率范围内的离散时间序列。与其他的机器学习任务一样,音频信号的特征提取在音乐情感识别(MER)中也非常的重要。大多数情况下,音频特征可分为时域特征、频域特征、倒谱域特征和其他特征。语谱图(Spectrogram)是频谱分析视图,横坐标为时间,纵坐标为频率,是音频在时域和频域特性上的综合描述。Spectrogram 本身包含了音乐信号的所有频谱信息,没有经过任何加工,所以Spectrogram 关于音乐的信息是无损的。
本文采用的音频情感识别模型如图1 所示。该模型主要包括卷积层、BiGRU 层、全连接层和分类层。
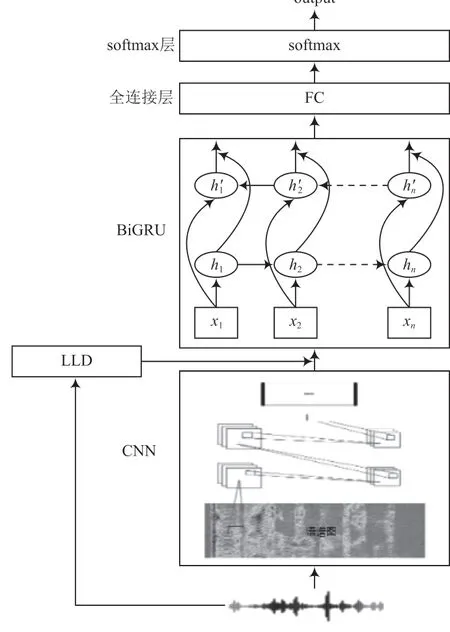
图1 音频情感识别模型图
(1)卷积层
卷积层的输入为音频的语谱图IT×N(T为时间,N为频率),利用CNN 的局部数据处理能力,对语谱图进行特性提取。通过卷积、池化、dropout 等操作后,得到了时间乘以特征数目的频率面情感特征。
(2)BiGRU 层
RNN 是处理序列数据的神经网络,可以有效地学习序列信息。传统的RNN 难以捕获长距离依赖信息且在反向传播时经常会出现梯度消失,而LSTM 在内部门控制机制下有效地解决了这些问题。GRU 是LSTM 的优化版本,简化了其内部结果,在提升训练效率的同时保持了几乎相同的效果。GRU 结构如图2 所示。

图2 GRU 内部结构
在GRU 内部有重置门rt和更新门zt,前向的计算公式如下:
式中:wr、wz和w分别为重置门、更新门和候选特征的参数矩阵;σ为sigmoid 激活函数;ht为t时刻的隐藏状态;ht-1为上一时刻的隐藏状态;为t时刻的候选信息。
本层的输入为CNN 层提取出的情感局部关键特征和低水平特征(MFCC、RP)。在文献[13]中已证明RP 能够与MFCC 实现信息的互补。通过两个独立的隐藏层,分别学习前向和后向序列信息。最终将提取出的语谱图中和LLD 中的情感特征进行全连接后输入到softmax 层进行分类。
2.2 基于XLNet-BiGRU 的歌词情感识别
目前主流的文本情感识别主要是使用预训练语言模型。BERT 模型是在谷歌大脑于2018 年提出的一种基于Encoder-Decoder 架构的语言模型,在NLP 各项领域取得了优异的成绩;但其也存在上下游任务不一致、忽略了预测词之间的依赖关系的问题。于是谷歌大脑于2019 年发布了XLNet 模型,在多个任务上超越了BERT 的性能。
XLNet-BiGRU 模型主要由XLNet 层和BiGRU 层组成,其具体结构如图3 所示。

图3 基于XLNet-BiGRU 的模型结构图
现阶段的预训练语言模型有自回归语言模型(Auto Regressive Language Model, ARLM)和自编码语言模型(Auto Encoder Language Model, AELM)。ARLM 不能同时学习前后文的信息,但是其考虑到了单词之间的依赖关系,而AELM 可以同时学习到前后文的信息,但忽略了单词之间的依赖关系,同时存在预训练阶段和微调阶段的不一致问题。XLNet 结合了ARLM 和AELM 的优点,提出了排列语言模型(Permutation Language Model, PLM)方法,对句子中的Token 进行全排列,通过采样不同的序列顺序进行预测。
该模型的工作流程如下:
(1)将歌词数据Xn(n=1, 2, ...,N)输入到XLNet 层,Xi表示为歌词中第i个单词。
(2)将文本数据转化为在字典中对应的编码,利用XLNet 模型学习到文本的动态特征向量Tn,向量T充分地利用了上下文的位置关系,能够很好地表现单词在不同句子中的含义。
(3)将特征向量Tn作为输入矩阵,输入到BiGRU 层,分别通过正向BiGRU 层和反向BiGRU 层得到hli和hri,加权连接后得到深层语义特征hi。
(4)通过全连接层对hi进行全连接,输出的维度为情感标签的种类数量。
(5)最后在softmax 层对全连接层的输出结果归一化处理,得到音乐的情感类别。
2.3 多模态音乐情感识别
多模态融合方式一般可以分为早期融合和晚期融合。早期融合是对不同模态间特征的融合,这种融合方式可以较好地考虑到不同模态间信息的互相补充。晚期融合是指决策的融合,不同模态的数据分别通过不同的模型得到分类决策,然后对不同的结果进行融合。
一般的特征融合是对不同模态的特征向量进行直接的拼接,这样不能很好地考虑不同模态之间的差异性,以及在决策中模态之间不同的权重。因此,本文采用互注意力机制的特征融合,具体公式如下:
式中:Fa为音频的特征;Ft为文本的特征;Wa和Wt为参数矩阵。通过计算后分别得到语音关于文本的互注意力特征Fat和文本关于语音的互注意力特征Fta,最后通过向量的级联得到音频-文本互注意力特征Fat。
3 实验结果与分析
3.1 数据集
本文针对音乐情感识别实验的数据集来自Million Song Dataset(百万音乐数据集)。在其标签子集Last.fm,根据愤怒、悲伤、快乐、放松四种情绪类别,抽取音乐2 000 首。具体分类情况见表1 所列。

表1 实验数据集
由于整首音乐存在重复的部分,且一般音乐的副歌部分是整首歌曲的情感爆发点,因此选取每首歌的15 ~45 s 之间的30 s 作为音频数据,并按照8 ∶2 的比例随机划分训练集和测试集。
3.2 实验结果
在本次实验中,分别采取了不同特征选取、不同分类模型和不同融合方法进行了实验。实验具体结果见表2 所列。
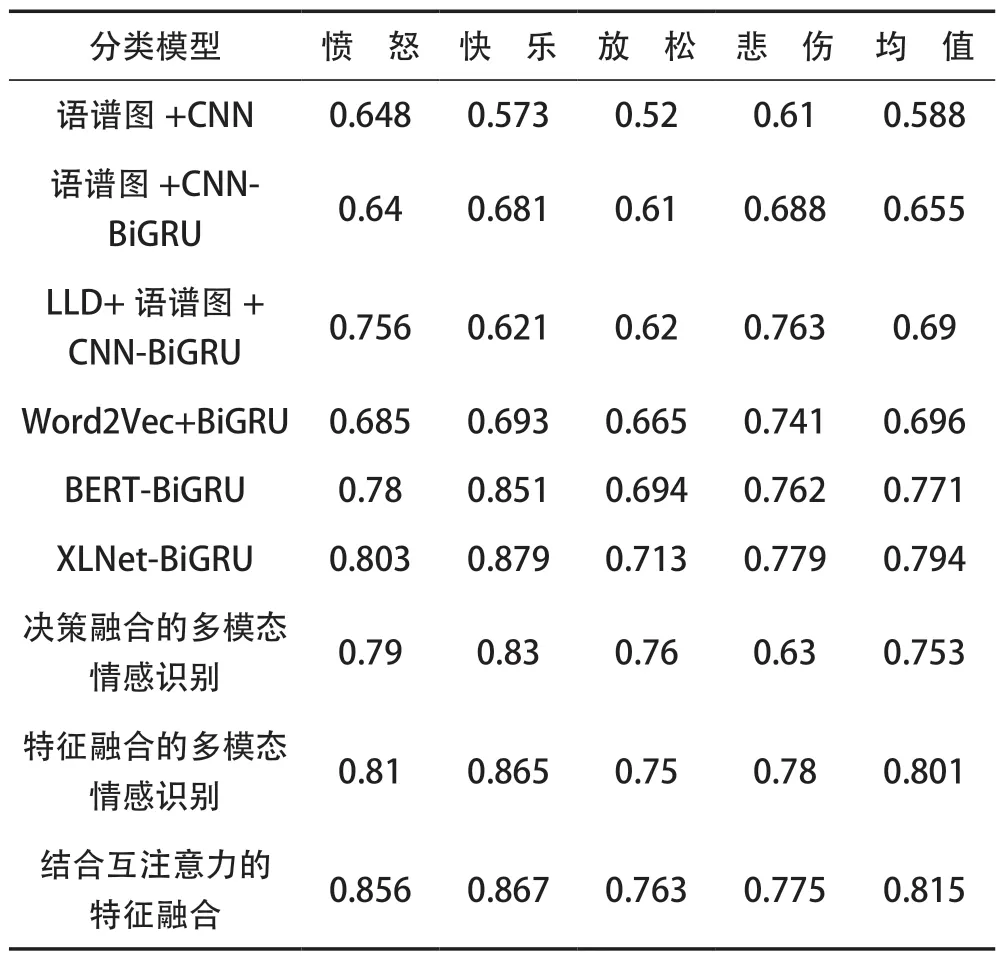
表2 实验对比结果
由表2 可见,在音频情感识别部分把语谱图作为二维特征输入到CNN,取得0.588 的准确率,通过CNN 和GRU的组合方式,准确率有一定的提升,而本文中所使用模型对LLD 和语谱图中感情信息的融合进一步提升了分类的准确率,达到了0.69。在歌词情感识别部分,本文使用的XLNet语言模型,相对于之前的Word2Vec 和BERT 有2%~9%的提升,准确率达到了0.794。在多模态情感识别部分可以看出,决策级的融合对比单一的模态准确率并没有提升,是因为不同的决策具有相同的权重,对最终分类结果造成了负面的影响。而在考虑了互注意力机制的特征融合下,分类效果提升了3%左右。
4 结 语
本文针对音乐情感识别领域,提出了一种基于XLNet-CNN-BiGRU 的音乐情感识别模型。在音频部分,采用MFCC 与RP 相互融合,再结合语谱图以获得更加丰富的情感信息,模型充分利用了CNN 的局部特征提取能力和GRU的结合上下文的序列特征提取能力。在歌词文本部分,首先利用预训练模型XLNet 动态获取包含上下文语义的特征向量,再利用双向GRU 网络再次提取上下文相关信息。最后在模态融合部分,结合互注意力机制对不同特征加权,对歌曲情感进行识别。经过对比实验,该方法在一定程度上提高了分类的准确度。日后的工作中,对音频更加高效的特征提取是研究的重点。
