金融领域事件因果关系发现及事理图谱构建与应用
2023-10-24杨纪星朱剑林康怡琳
杨纪星,杨 波,2,朱剑林,2,康怡琳,2
(1. 中南民族大学 计算机科学学院,湖北 武汉 430074;2. 信息物理融合智能计算国家民委重点实验室,湖北 武汉 430074)
0 引言
在金融领域,事件发展动荡多变,在事件的逻辑衍生中,事件内部的复杂性决定多种事件直接或间接导致同一事件的发生,亦决定同一事件可直接或间接导致多种不同事件发生。因此,探究金融领域中事件的动态发展规律并实现事件发展脉络的可视化表达,是金融行业迫切需要解决的阶段性问题。
近年来对于知识图谱的研究及其构建领域的日渐成熟,单一的确定性静态知识类图谱构建模型已经难以满足业界的需求,特别在金融领域,事件具有动态发展性,静态的知识图谱难以全面地表现事件的逻辑规律。事理图谱(Eventic Graph,EG)是一个基于事理逻辑构建出来的知识库,以事件为节点,以事件关系为核心的有向有环图,刻画并记录事件之间的演化规律和模式,能够有效解决事件预测和事件分析的问题[1]。
Luo等人[2]于2016年首次从文本数据集中抽取出因果事件对,并将其构建成因果事件网络。Zhao等人[3]于2017年提出以规则模板的形式对事件因果进行抽取操作,即
2018年,Dasgupta等人[5]在计算机语言协会上提出一种基于语言的递归神经网络架构,用于自动提取文本深层信息,该架构使用词嵌入和语言特征的方式检测句子中提到的因果事件及其影响,并且以此为基础提出两个基线系统评估指标用于评估模型的性能。在研究过程中,发现添加额外语言层的双层LSTM模型表现出更好的性能。由此,2020年以后,多位研究者针对不同领域提出事理图谱构建方案,如面向热点话题的因果事理图谱[6],基于城市轨道交通运营突发事件的事理图谱[7]以及面向电信诈骗领域的事理图谱[8]。
然而,目前金融领域因果事理图谱的构建面临诸多挑战,如因金融事件的复杂多变性以及针对金融事件缺少明确的定义与划分标准,使得目前可用金融事件数据集较为匮乏;又如构建方案缺少对比实践,事件抽取任务精度较低,以致因果事理图谱难以适应数据量较大且精度要求较高的金融领域。
为此,本文提出了一种新的金融领域事件论元的定义,制定了ATT+SBV的句法分析方案,以此提出面向金融因果事件的序列标注标签定义,并在金融事件数据集中标注数据6 000条,然后提出了一种基于BERT+Bi-LSTM+CRF模型的信息抽取方案,并与不同神经网络模型做对比研究,以提升文本事件预测的准确性,通过Neo4j图数据库构建金融因果事理图谱,以可视化的方式揭示现实金融事件的演变逻辑规律,分析金融网络中风险传导扩散机制,为金融市场实现对市场环境的趋势把控提供数据支持。
1 金融事件论元定义
在以往的金融事理图谱中,作为节点的金融事件,具有广泛多样、知识粒度较粗的特点,使得事件实例的组成具有多样性和不确定性,在事理图谱的构建上存在事件准确度过低的问题。因此,本文对金融事件的实体概念作出划分,并定义金融事件本体的组成元素,从而提出更精确的金融事件本体。金融事件描述主要指金融领域中已发生的具有动态发展性质的热点事件,主要包括事件的实体及其属性和事件变化的具体形式,因此事件论元的组成成分包括事件实体、描述性客体、时间、地点等特殊要素[9]。在具体表现形式上,本文将其表现为式(1)所示。
e=
(1)
基于式(1),金融事件论元可由三元组表示,即将事件表示进行线性化,能够将文本中的事件记录表示为一个表达式,使金融事件在表示上有着严格的规范定义[10]。其中,D表示针对金融事件实体的描述性元素,如地理位置、产品名称等;E表示金融事件中的事件实体,对应事件描述中事件对象,如市场、产能、价格、猪瘟等;S表示体现金融事件对象的动态变化形式,如降低、停滞、分化、下跌等。以“国内汽柴油价格下调,导致炼油损耗逐月扩大、库存价格下跌”事件作为案例,其中可将其划分为三个事件论元,可认为“价格”“损耗”是事件的实体对象,而如“汽柴油”“炼油”和“库存”则认为是对实体对象的描述词,并将“下调”“扩大”和“下跌”认为是事件实体的动态形式。
2 金融事件抽取研究
2.1 文本预处理
本文研究的金融事件数据主要来源于CCKS-2021发布在数竞平台的金融因果事件数据集(1)https://www.biendata.net/competition /ccks_2021_task6_2/,其数据结构为金融因果事件的Json数据,数据样例为{“text_id”: ”123456”, “text”: “卡车需求不旺导致货运行业盈利水平大幅度缩水”},该数据集的数据主要来自金融领域的公开新闻、报道。为了使事件抽取模型准确度更高,本文爬取了《人民日报》金融板块近一年的事件标题作为扩充数据集。
数据源的新闻文本在提取后通过正则表达式或者人工操作,对其进行清洗操作,具体是将与事件抽取任务无关的组织、数据等进行剔除,使得事件抽取任务在精确性上得到进一步提升。
2.2 因果关联触发词定义
在自然语言句型模式匹配研究中,句子类型可以被划分为转折事件、顺承事件、并列事件、条件事件以及因果事件,以此确定不同句型的相应格式[11]。本文研究以金融因果事件作为主体,确定事件关系的因果触发词,通过先对事件触发词进行内容定义,在关系匹配函数中对句子内容进行关系模式匹配。
在本文研究的金融因果事件关系中,将以表1中的事件因果触发词作为内容定义。
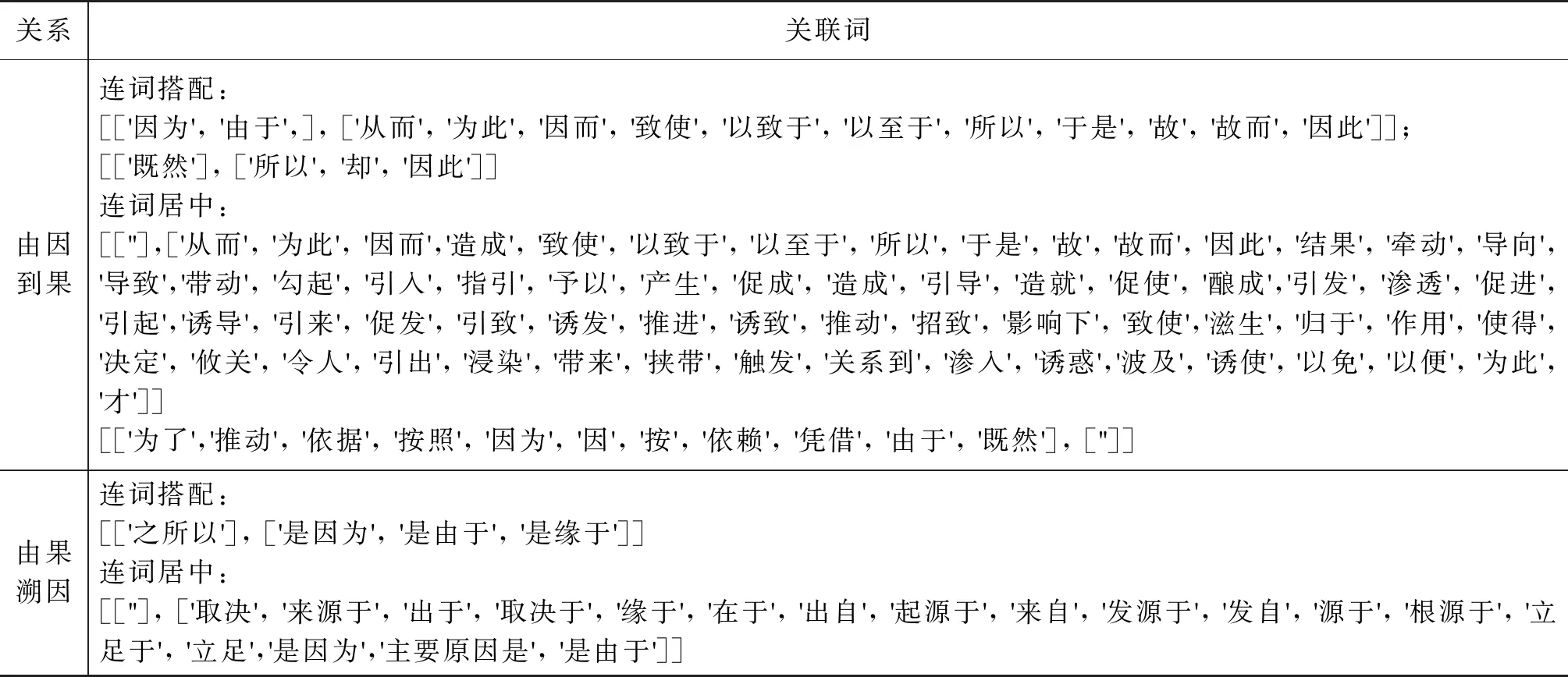
表1 因果关系触发词表
在对文本事件进行事件关系分析时,如“国内汽柴油价格下调,导致炼油损耗逐月扩大、库存价格下跌”,由以上关联触发词,可匹配此事件中因果触发词为“导致”。因此,通过模板对事件类型划分,可将“国内汽柴油价格下调”划分为原因事件,而“炼油损耗逐月扩大、库存价格下跌”则被划分为结果事件。
2.3 基于依存句法分析的事件抽取方案
2.3.1 依存句法分析
依存句法分析是在语法分析的基础上,根据其中依存关系,将其句法结构表达出来[12]。其中,LTP语言技术平台作为中文文本依存句法分析工具,相较于Stanford CoreNLP和SpaCy相关依存句法分析库而言,LTP使用简单,兼容性良好,标注的结果简单易分析,速度较快,可以满足大多数针对依存句法分析的应用要求,其使用的BH-SDP[13]中文标注方案更适用于中文文本数据的处理。本文为了清楚地匹配事件论元关系,以LTP的关系标签提出了ATT(定中)+SBV(主谓)句法分析形式(其在Stanford CoreNLP和SpaCy中的形式为NMOD+NSUBJ)来抽取事件。因此,此类表示事件的形式,可以使核心词汇和构成要素均在事件中得以体现。图1为基于上述研究对“国内汽柴油价格下调,导致炼油损耗逐月扩大、库存价格下跌”使用LTP语言技术平台进行依存句法分析的弧线图。

图1 事件文本依存句法分析弧线图
由上述事件抽取方案生成的事件结果,如表2所示。

表2 依存句法分析生成事件
由此看出,在事件表示上,此种方案具有设计简单、性能良好、事件简洁等特点,并体现事件变化的动态要求。
2.3.2 金融事件抽取结果与分析
依存句法分析进行事件抽取的方案基于预处理的文本数据,通过因果关联词匹配确定事件因果划分,经过分词、词性标注以及依存句法分析,依照事件论元定义,最终以ATT(定中)+SBV(主谓)的形式构建出金融事件,基本完成了构建事理图谱的数据要求。
基于上述实验,通过对关系抽取和事件抽取的结果进行统计,并对数据进行准确性分析,统计结果如表3所示。
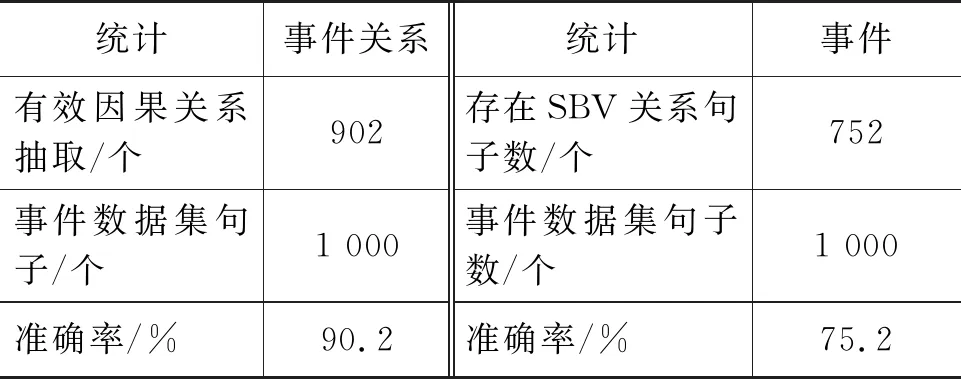
表3 因果事件及关系抽取统计表
通过以上数据可知,在因果关系抽取任务上,准确率达到了90.2%,性能较为优秀,但在基于依存句法分析的事件抽取中,发现存在SBV句法形式的句子个数偏少,事件抽取准确率只有75.2%,在性能上略低,此类基于依存句法分析进行事件抽取的方案在准确性和可持续性上不太适合进行大规模的数据处理以及对事件精度要求较高的金融领域。
2.4 基于深度学习模型的事件抽取方案
为弥补通过依存句法分析进行事件抽取中精度不高及可持续性无法满足规模较大数据处理的不足,本文通过对数据集进行手动标注,构建多种信息抽取模型,对比实验对序列标注数据集进行训练,以提高事件抽取任务的准确性。
2.4.1 文本向量化及预训练模型
文本向量化实际上是将文本内容通过算法技术使其转换成机器能够理解的向量形式。Word2Vec在由Google于2013年作为用于训练词向量模型的工具以来,其使用神经网络机制,对数量规模较大的文本数据进行训练,其训练结果可很好地度量词与词之间相似性[14]。2018年,Google提出聚焦于学习上下文关系的词向量表示的预训练模型,即BERT预训练模型,其能够挖掘文本的深层次信息并强化单词的特征表示[15]。
2.4.2 序列标注
序列标注(Sequence Labeling),即基于给定的输入序列,通过一定规则对此序列的每个位置标注上一个相应的标签的过程[16]。事件抽取即信息提取,可将其认为是一个序列标注任务。本文通过采用BMOES标注体系,对金融事件数据源进行人工标注,BMOES金融因果事件标注体系定义如表4所示。
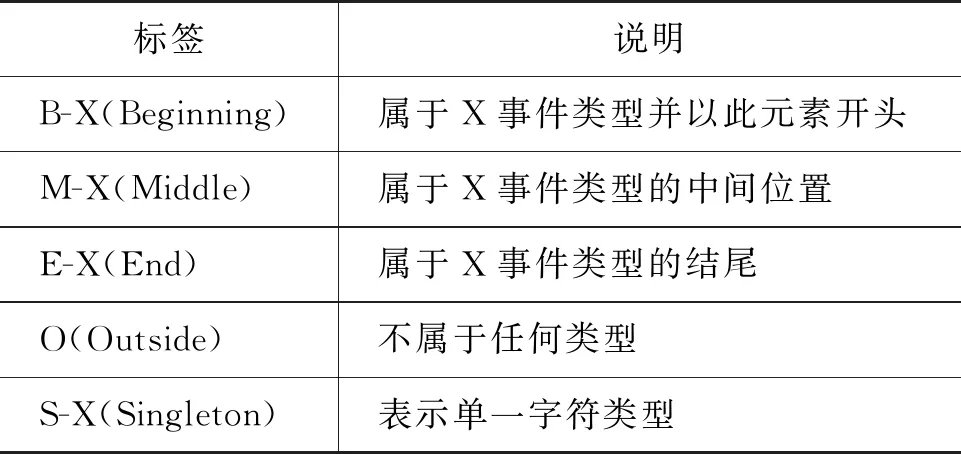
表4 BMOES序列标注说明
基于以上序列标注规范,将标签序列规定为{O,B-cause,M-cause,E-cause,B-effect,M-effect,E-effect,B-trigger,M-trigger,E-trigger,S-trigger},其中O标签表示不属于事件提取的任意事件,B-cause,M-cause,E-cause可分别表示文本属于原因事件的开始、中间和结束,而B-effect,M-effect,E-effect则表示文本属于结果事件的开始、中间和结束,B-trigger,M-trigger,E-trigger表示文本属于因果触发词的开始、中间和结束,最后的S-trigger则表示为单个因果触发词。基于以上规范,通过序列标注工具YEDDA对事件进行标注任务,如图2所示。

图2 YEDDA序列标注工具
通过以上标签规范,本文对金融因果事件进行粗略标注,并基于金融事件论元定义及ATT+SBV句法规则进行精确修整,共标注6 000条,并按照 3∶1∶1 的比例将其分为训练集、测试集和验证集,以下则是根据标签规范进行事件标注的事例。
“非 B-cause/洲 M-cause/猪 M-cause/瘟 E-cause/对 O/我 O/国 O/猪O/肉 O/全 O/产 O/业 O/链 O/影 O/响 O/导 B-trigger/致 E-trigger/实 O/际 O/产 B-effect/能 M-effect/减 M-effect/少 E-effect/、 O/猪 B-effect/肉 M-effect/价 M-effect/格 M-effect/严 O/重 O/分 M-effect/化 E-effect/、O/跨 B-effect/省 M-effect/运M-effect/输 M-effect/停 M-effect/滞 E-effect/,O/北 O/方 O/生 B-effect/猪 M-effect/养 M-effect/殖 M-effect/企 M-effect/业 M-effect/大 O/面 O/积 O/亏 M-effect/损 E-effect/。”
2.4.3 Bi-LSTM双向长短时记忆网络
为处理事件序列问题,循环神经网络(Recurrent Neural Network, RNN)既考虑前一时刻的输入,又赋予网络对以往内容的“记忆”能力。而双向结构的RNN不仅可从前向后保留给更前面的内容,对其后面的内容也进行了相应保留,即双向RNN便是由两个RNN上下叠加而成的。
但由于RNN本身基于时间反向传播的特点仍会带来如梯度消失或者是梯度爆炸的问题,因此并不能解决长距离依赖问题,引入长短时记忆网络(Long Short Term Memory Network, LSTM),其可通过梯度裁剪技术来克服梯度爆炸的相关问题,并由于其特殊的存储“记忆”方式,也在一定程度上克服了梯度消失的问题。RNN的重复模块包含单一的层,LSTM的重复模块包含四个交互的层[17]。三个神经单元模块的LSTM内部结构如图3所示。
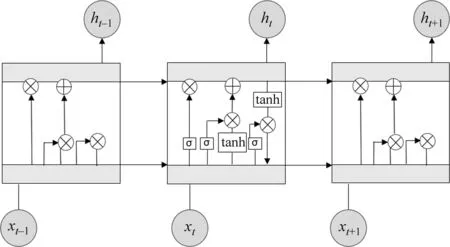
图3 三个神经单元模块的LSTM内部结构
在LSTM神经网络中,使用门结构实现了对序列数据的遗忘和记忆,基于大量的文本序列数据对LSTM模型进行训练之后,其可以捕捉文本上下文之间的依赖关系。通过训练好的模型可直接根据指定的文本生成后续的预测内容。因此在信息抽取研究中,采用LSTM模型解决序列标注任务。而双向Bi-LSTM模型由文献[18]提出,将LSTM模型进行双层叠加,以形成双向LSTM模型,使得上下文的信息得以连接起来。Bi-LSTM结构如图4所示。
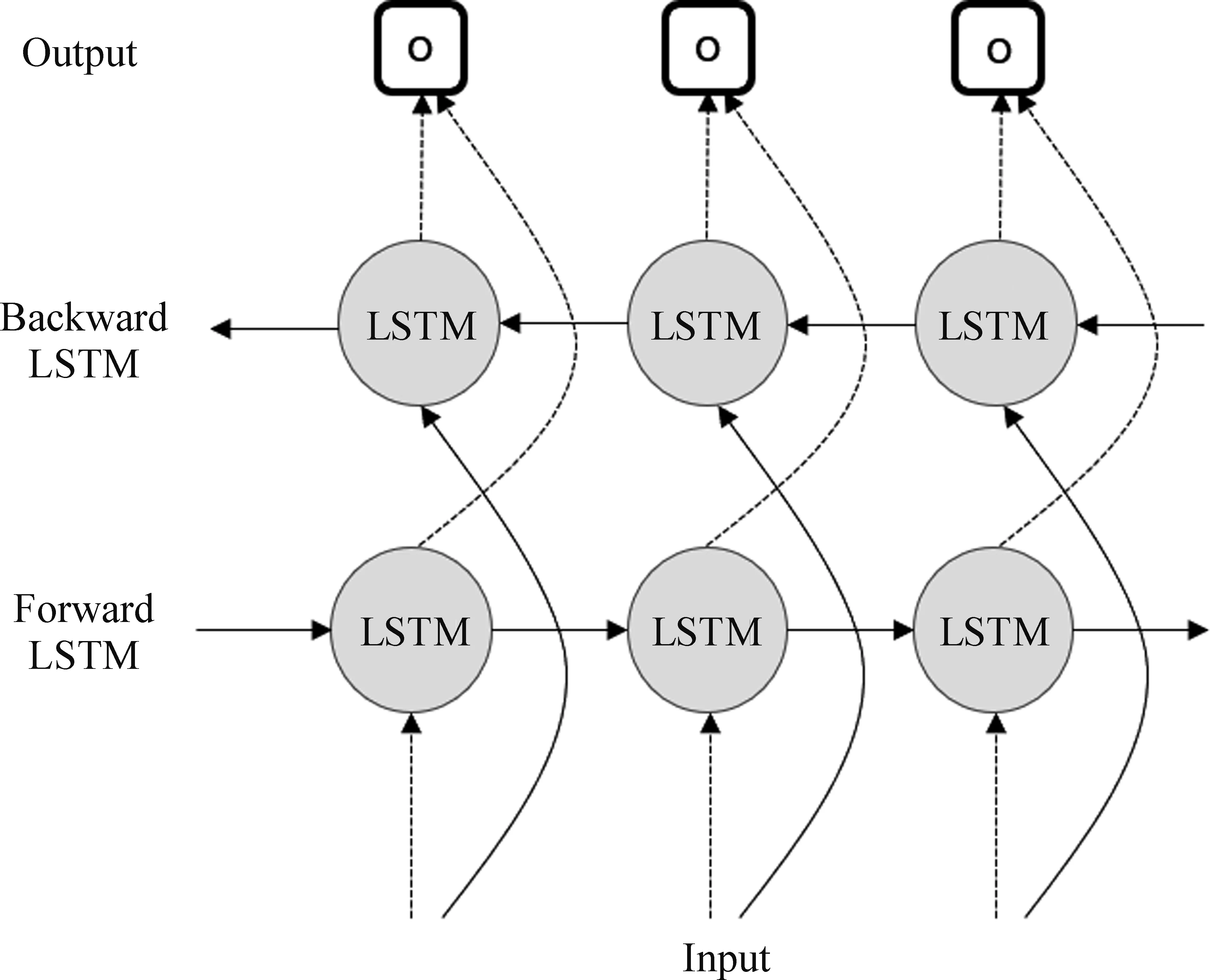
图4 Bi-LSTM结构
2.4.4 条件随机场
Bi-LSTM模型解决上下文的关联问题,但在实际的序列建模过程中,Bi-LSTM只考虑了输入序列的信息,并没有对标签的转移关系进行建模,以本文的BMOES序列标注为例,输入序列为“炼油损耗扩大”,理想的标注结果为“B-effect M-effect M-effect M-effect M-effect E-effect”,但实际上可能出现的情况为“B-effect B-trigger M-effect O M-effect E-cause”。这是由于在建模的过程中,未对标签的转移关系进行条件约束,使得模型输出一个错误的序列,因此引入条件随机场(Conditional Random Field,CRF),即CRF层,通过引入标签转移矩阵,解决序列标注前后标签不匹配的问题[19]。在这个过程中,Bi-LSTM与CRF取长补短,巧妙结合。
线性链式条件随机场通过两个特征函数学习边界。设P(y|x)为线性链式条件随机场,则在随机变量X取值为x的条件下,随机变量Y取值为y的条件概率具有如式(2)所示的参数化表示形式。
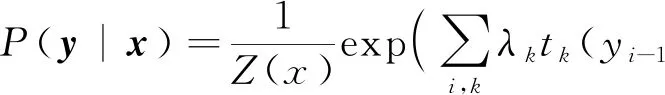
(2)
其中两个特征函数分为转移特征函数和节点特征函数,且取值只能为0或1。转移特征函数依赖于当前节点i和上一个节点i-1,记为tk(yi-1,yi,x,i),节点特征函数只依赖于当前节点i,记为sl(yi,x,i)。
其中,转移特征函数对应的权重值为λk,节点特征函数的权重值为μl,Z(x)为规范化因子,计算方法如式(3)所示。
(3)
整个序列标注过程可简单描述为: 基于给定的序列标注数据集,通过将标注集进行排列组合以构成多个可选标注列表,利用特征函数集合对每个标注结果进行打分,并将所有特征函数的分数进行加权求和,最后选择分数最高的结果,即可信度最高的序列标注结果。图5为线性链式条件随机场的结构。
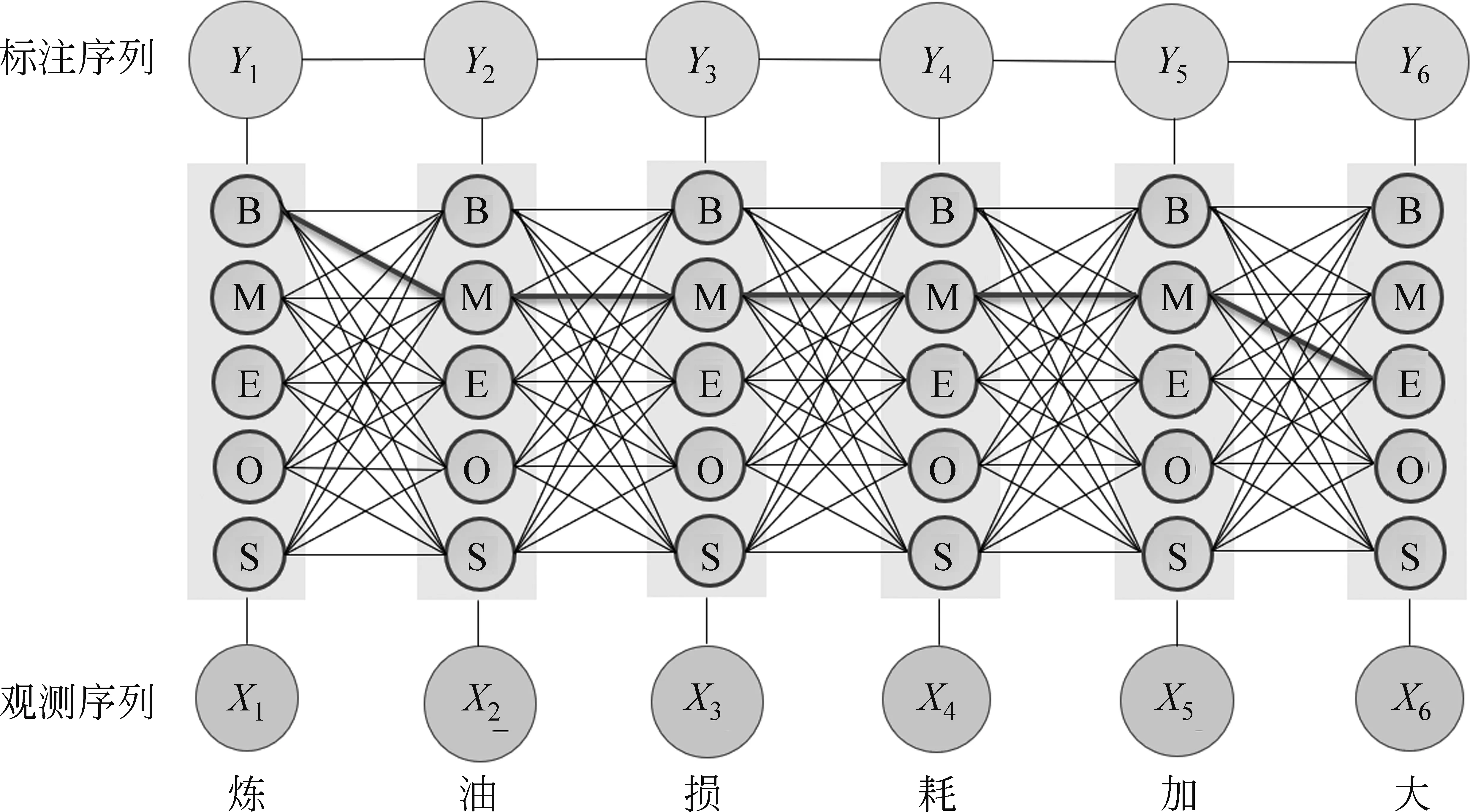
图5 线性链式条件随机场的结构
2.4.5 基于Bi-LSTM+CRF的信息抽取模型
模型分为词嵌入层即Embedding层、Bi-LSTM层以及CRF输出层。
在Embedding层,接受中文文本词的输入并将其转换为词向量形式。
在Bi-LSTM层,接受Embedding层的输出,输出为文本词对应的每个实体种类的Score。此处对“炼B-cause 油M-cause 损M-cause 耗E-cause”进行分析,其中Score(x,y)由转移特征概率和状态特征概率两部分组成,此时x为word index序列,y为label index序列。转移特征概率是指在前面的输出标记是B的情况下,当前的输出标记是一个特定的数值,例如M的概率大小。而状态特征是指在当前输入的词为“油”的条件下,当前输出标记是一个特定的数值,例如M的概率大小,则Score(x,y)如式(4)所示。
(4)
此处的h指代Bi-LSTM的输出,代表序列标注标签的状态特征分数值,P则是转移特征矩阵,表示第i标签从yi-1转移到yi的转移得分值。Bi-LSTM层内部通过线性层将数据类型映射为(单次传递给程序用以训练的参数,句子长度,实体总数)的类型,得出Score。
在CRF层,接收Bi-LSTM的Score的输出作为输入,输入通过了一个维度变换后的相加操作作为输出。CRF的损失函数由真实路径的分数和所有路径的总分数组成,每种可能的路径的分数为Pi,共有N条路径,路径的总分可由式(5)所示。
Ptotal=P1+P2+…+PN=eS1+eS2+…+eSN
(5)
其中,eSi表示第i条路径的分数,因此损失函数可由式(6)表示。在训练过程中,Bi-LSTM+CRF模型的参数值将随着训练过程的迭代不断更新,使得真实路径所占的比值越来越大。
(6)
在计算了每个字词(token)归一化概率矩阵和转移概率矩阵之后,最后根据维特比算法得到整个文本句子的最优概率输出。
基于上述Bi-LSTM+CRF模型设计,在参数设置上,基于词嵌入,设置Embedding层的维度为256,隐藏层维度为256,设置单次传递给程序用以训练的参数个数为16,在学习速率的设置上,设置学习率lr为5e-4,使得在学习过程中避免损失函数震荡和学习难以收敛的问题。经多次实验发现,将Epoch次数设置为12次可得最佳数据。
2.4.6 基于BERT+Bi-LSTM+CRF的信息抽取模型
为再次提高模型性能以及获取字词深层次特征的能力,将Bi-LSTM+CRF中的Embedding层换成BERT。BERT模型与Word2Vec不同,其通过联合调节所有层中的上下文来预训练深度进行双向表示,语义编码更加精确,图6所示。

图6 Bi-LSTM+CRF模型结构
本文采用谷歌提供的BERT-base版本的中文模型,隐藏层维度为768。BERT初始学习率设置为 1e-5,Bi-LSTM层维度设置为128,Drop-rate设置为0.1,优化器采用Adam算法。
基于上述模型,执行模型优化策略。首先进行Epoch训练优化,统一训练监控指标和评估指标,将监控指标由字词(token)更改为实体级别F1值,在每个Epoch结束之后,计算验证集的F1值,基于现有的Epoch的F1值与以往保存的最佳F1值进行比较,决定是否保存当前训练模型,如若后续Epoch训练的性能指标未有显著变化,则执行学习率的衰减策略。
其次,进行分层学习率优化。在模型构建过程中,LSTM层是随机初始化的,意味着学习的次数不够或者学习率太小,随机初始化的参数在反向传播过程中并不能得到一个较大幅度的优化,需进行分层封装的学习率设置,实验参照Su等人[20]的分层设置学习率方法,对模型每一层进行封装,并分层设置学习率,此处BERT层初始学习率设置为1e-5,对Bi-LSTM层进行初始学习率的倍数操作。
2.4.7 基于BERT+Bi-LSTM+CRF模型的事件预测任务
基于构建完成的BERT+Bi-LSTM+CRF模型,对金融事件文本执行信息抽取任务,实验结果如表5所示。
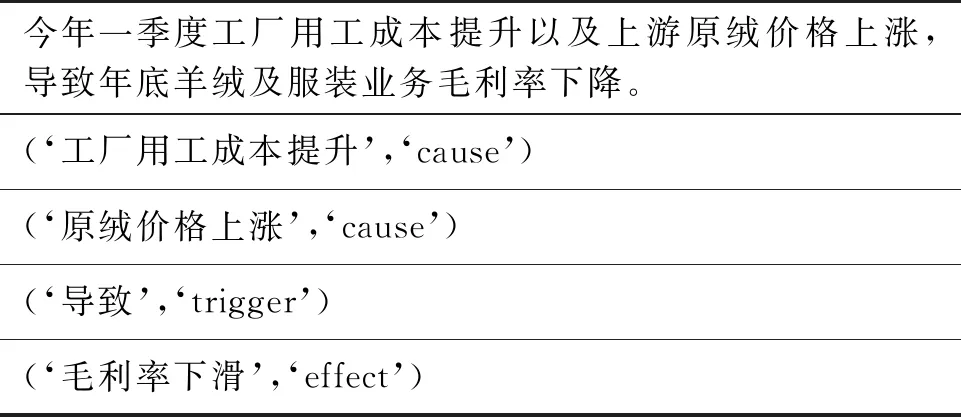
表5 事件预测
2.4.8 金融事件抽取结果与分析
为评估深度学习模型的信息抽取性能,本文采用F1-Score[21]作为序列标注任务的性能评估指标,其是精确率(Precision)、召回率(Recall)的调和平均数。其计算式如式(7)~式(9)所示。
其中,TP指代分类器预测结果为正样本,实际也为正样本,即正样本被正确识别的标签数量;FP指代分类器预测结果为正样本,实际为负样本,即误报的负样本数量,FN是分类器预测结果为负样本,实际为正样本,即漏报的正样本数量。
根据上述性能评估指标研究,实验结果如表6所示。

表6 不同模型结果对比
由表6可以看出,加入了BERT预训练模型的Bi-LSTM+CRF模型获得了更好的识别效果,其F1-Score达到了95.78%。与Word2Vec相比,BERT成功地将这种表达能力强,并且易于优化的深层网络应用到了掩码语言模型这个任务上,BERT每个位置经过多次Transformer层输出后的词向量都有语境信息,BERT能直接地建模距离更远的词和词之间的依赖关系,这是Word2Vec所不具备的[22]。实验表明,在对数据的自标注过程中,依据金融事件论元定义和ATT+SBV的文本句法定义对金融事件元素做出的分析,在序列标注中可准确地标注出金融因果事件及其触发词,从而使得大量的序列标注数据能够对CRF的转移概率的学习效果有着显著的提升,使得标签能有更合理的转移方式。同时依据金融领域因果的事件数据具有明显的事件主语和动态变化趋势,在特征提取时引入注意力机制,事件抽取的准确性较传统的依存句法分析进行事件抽取的方案更能胜任复杂多样的金融事件领域,并且BERT预训练模型在词之间具有长距离依赖优势,在抽取事件文本的深度特征上比其他信息抽取模型更加准确。因此,此模型在理论上可在数据集的渐续增加中提高性能,更具有可持续性。
3 金融事件融合
3.1 事件三元组生成
根据事理图谱构建的任务定义,即从在结构上看,事理图谱是一个以节点代表事件,以边代表事件关系且包含事件词的结构化多元组。因此本节研究工作基于上述事件抽取及事件关系匹配结果,将同一事件文本中的原因事件和结果事件以<因事件,事件关系,果事件>的三元组形式进行笛卡尔积式组合。表7为生成的部分事件三元组结果。

表7 事件三元组结果
通过信息抽取任务形成以<因事件,事件关系,果事件>为形式的事件三元组,再对其中所含的相似事件进行事件合并,也称为事件融合。事件融合任务的必要性为得到精确完整的因果事件三元组,以提高整个事件抽取和事件关系匹配任务的数据质量[23]。
3.2 事件相似度计算
在事件三元组构建完成后,需针对相似语句进行替换处理,涉及文本相似度计算的问题,因此引入Jaccard系数进行文本相似度计算。对给定的两个文本集合A和B,Jaccard系数被定义为A与B交集大小与A与B并集大小的比值,是计算机领域中实现文本相似度计算时常用的一种方法[24]。Jaccard系数值越大,文本之间相似度越高。其计算方法如式(10)所示。
(10)
3.3 事件合并处理
通过式(10)求得的Jaccard系数,针对事件三元组的因果事件进行分析,本文基于单建芳的事件相似度计算算法思想[25],采用相似文本算法将前置定语和主语(ATT)一致且相似度超过设定阈值(0.5)的事件进行列表合并。此时的事件相似度阈值设置是基于金融事件论元的元素定义,在事件主语及其前置宾语元素一致的共同前提下,通过计算金融事件论元中的共同事件主语及其描述词元素在整个事件文本的相似度所得到的,能够保证其事件语法相似和语义相似的合理性。同时,以首位事件作为第一优先级事件,用其依次替换掉后续相似事件,并将缺少因事件或者果事件的三元组进行删除处理。此工作合并结果如表8所示。

表8 “非洲猪瘟”事件合并结果
4 基于Neo4j图数据库的事理图谱分析与可视化
4.1 基于Neo4j图数据库的事理图谱可视化
图数据库是使用节点、边和属性来表示和存储数据的非关系型数据库,在复杂数据的关联查询上相较于传统关系型数据库具有明显的性能优势,并且事理图谱可表示为事件关系组成的有向有环图,图数据库通过属性图模型可轻易创建多关系相连的事理图谱。因此,本文选择Neo4j图数据库[26]进行持久化存储事件及事件关系数据,并利用Neo4j自带的可视化工具展现出金融因果事理图谱。针对信息抽取结果,将事件存储入Neo4j图数据库,将事件三元组的节点和关系依次导入Neo4j图数据库,基于Neo4j图数据库的金融因果事理图谱存储与可视化如图7所示。
图7 基于Neo4j图数据库金融因果事理图谱存储与可视化
针对某一事件无法进行单方面查询研究的缺陷,Neo4j的查询语言Cypher提供了可实现描述关系查询的方案,例如,对“非洲猪瘟影响”事件进行单一事件分析,说明了事件发展的广泛性。
4.2 基于金融事理图谱的事件演化案例分析
金融事理图谱可分析金融事件之间的逻辑关系,并揭示其发展规律。其中,事件作为事理图谱中的节点承载着事件描述的重要信息,金融事件抽取是整个金融事理图谱构建的基础,金融事件的完整性关系到金融事理图谱构建的有效性和可读性。金融事件论元基于金融事件的显要特征,除完整保留事件实体及其描述性信息外,将事件发展态势作为事件论元的相关要素,并与依存句法分析结合,从语义语法上准确描述金融事件的实体信息和发展路径,丰富了事理图谱中事件间事理特征的表达。同时,它基于事件实体之间直接或间接的关联性,扩展了事件间的事理逻辑链[27]。
本文选取飓风事件进行案例研究,以论证金融网络中的风险传导特点和扩散形式。2021年9月,飓风“艾达”和“尼古拉斯”席卷美国东南部,导致当地石油开采设备损坏, 对原油开采和运输产生了较大的阻碍,英国基准布伦特原油和美国西德克萨斯中质油的价格上涨至近十年来的最高点,导致市场经济通胀等一系列突发事件,引起市场对非金融事件产生金融风险传播的警惕。
图8为利用Cypher查询“飓风”事件所产生的一系列事件影响的金融因果事理图谱,其中飓风作为事件发展的扩散原点,导致如原油价格上涨、石油生产中断、铁矿石全年供应下降等一系列金融事件。金融事件论元在将“原油价格”“石油生产”等事件实体信息正确表示出的同时,并表现价格的“上涨”态势和生产的“中断”现状,体现了事件信息的简要可读性,揭示了事件的变化方向。对“飓风”引发的金融因果事理图谱做分析,“飓风”带动的连锁反应,依赖金融事件网络,金融风险由传导逐步发展为扩散态势。在时序演化中,“飓风”引发石油矿石开采影响和运输阻碍,其中原油价格上涨看似与飓风事件关联甚小,但与其存在直接或间接的因果关联性,并在风险传染能力上高于风险传导源头事件,表现出较高的敏感性,提高了整个金融风险传播网络的复杂程度。因此,金融风险并非仅由金融事件的变化衍生传导出来。
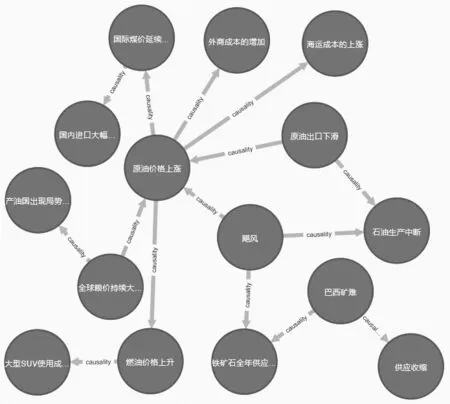
图8 “飓风”事件因果事理图谱
同时,“飓风”到原油价格完成扩散反应,不断引起外商成本、海运成本和国际煤价等实体的变化,形成“网链式”的发展路径。金融因果事理图谱形成的金融风险网络对与之相关的部分金融事件实体引发“涟漪”反应,导致金融风险的扩散,金融因果事理图谱揭露了事件实体广泛存在的各种关联。在事件演化中还出现产油国局势动荡的政治事件。在“飓风”事件所形成的金融因果事理图谱中,不同事件实体通过其发展态势相互作用、相互影响,形成复杂广泛的事件逻辑关系链条。
通过上述实验,使用Neo4j图数据库的可视化工具对事理图谱进行了可视化展示。基于Neo4j图数据库构建的金融因果事理图谱具有驱动性的事件指向,揭露事件发生的多种原因及其次生影响,并在事件的走向上衍生出相关金融事件或非金融事件。针对某一事件的异常市场反应,基于金融事理图谱,市场主体通过金融风险网络之间的层层关联,对网络中事件节点进行建模分析和多层逻辑推理,从事件关联的视角揭示金融事件的演变规律和动因,实现事件逻辑发展的关键路径探索,可较为迅速地进行事件溯源,以达到整个市场经济局势变化的把握。同时,在面对金融市场的走向或者外部环境的突变上,当事件突发形成常态化时,可提前了解事件实体之间的关联,依据金融事件论元中的发展态势要素,提前把握事件变化引发的金融风险传导和扩散方向以及事件突发性带来的风险影响,从而减少由市场经验主义带来的不利影响,提高金融市场的应变能力。
5 结论
本文重点针对面向金融领域的事理图谱进行研究,在收集的金融事件数据集的基础上,提出了适用于金融领域的事件表示方法,设计了一套适用于金融领域事件的序列标注方案,并标注了一套面向金融领域的因果事理图谱语料库;同时,在对事件抽取和事件关系研究方案上提出将依存句法分析方案和基于深度学习的多种神经网络模型方案进行了实践对比,并针对模型性能进行了多种优化策略,最终以BERT+Bi-LSTM+CRF模型在信息抽取的F1值为95.78%,具有显著优势,更能胜任复杂多样的金融领域事件,成为信息抽取的主要手段;最后,以Neo4j图数据库用作数据的持久化存储,实现金融事理图谱的结构化存储、查询等功能,并通过金融因果事理图谱可视化,分析金融风险网络的传导扩散机制,揭示金融风险并非仅由金融事件所引起,金融风险网络中高敏感度的事件会产生“涟漪”反应,提升市场应对金融风险的能力,为各类突发事件应急预案的制定与响应提供辅助数据,辅助相关监管部门研判事件发展的关键路径,及时规避相关衍生事件带来的金融风险,提高政府机构的治理水平。
