基于多模态学习的试题知识点分类方法
2023-10-24李洋洋陈艳平唐瑞雪唐向红
李洋洋,谭 曦,陈艳平,唐瑞雪,唐向红,林 川
(1. 公共大数据国家重点实验室,贵州 贵阳 550025;2. 贵州大学 计算机科学与技术学院,贵州 贵阳 550025;3. 贵州青朵科技有限公司,贵州 贵阳 550025)
0 引言
2018年,教育部发行了《教育信息化2.0行动计划》[1]以推动教育的现代化建设,培养创新型人才。在《2020年教育信息化和网络安全工作要点》中,国家又提出启动“百区千校万课”引领行动,树立区域性标杆,以此推动各地智慧教育建设水平的提升[2]。由此看出随着教育信息化的发展,智慧教育得到逐步推广。智慧教育作为一种全面、丰富、多元、综合的教育方式,既可以提高学生学习的趣味性,又可以调动学生学习的积极性、主动性;还可以突破传统教学模式中的时空限制。试题知识点分类作为智慧教育领域中的一项基础性工作,其主要任务是预测试题所考察的知识点。试题知识点是对试题考察内容的概括,如物理学科的知识点包括电磁学、力学、电学等。通过试题知识点分类并结合学生的学习记录,不仅可以了解学生对知识点的掌握情况,还可以为相似试题检测[3-4]、智能组卷[5-6]、试卷质量评估[7]、个性化试题推荐[8-9]等下游任务提供支撑。
试题是命题者按照一定的考核要求编写出来的题目。通过对初高中物理试题的分析可知以下两点: ①试题由题面、答案、解析等构成; ②试题中存在多源异构数据,如试题文本、图片等信息。试题信息如表1所示。

表1 试题信息
通过上述试题信息可知,该试题考查的一级知识点为电磁学,二级知识点为电磁学下的电场。随着知识点层数的增加,知识点的数量也在增加,这不仅会影响试题知识点的分类性能,而且还将加剧小样本试题占比的程度,导致分类器难以从小样本试题中学习到有用的特征。传统的试题知识点分类方法仅关注试题中的文本信息,而试题图片作为试题的组成部分,也包含直接的语义信息。由于不同模态的试题特征之间存在互补关系,为了使试题的特征信息更加丰富饱满,本文提出了一种基于多模态学习的试题知识点分类方法。本文主要工作如下:
(1) 结合试题图片提出了一个基于协同注意力机制的多模态融合模型,分别通过试题文本引导试题图片的注意力和试题图片引导试题文本的注意力来融合试题文本和试题图片的特征,以获取更丰富的试题语义信息;
(2) 在某教育机构提供的物理试题数据集上进行验证分析,表明本文所提模型既可有效提高试题知识点的分类性能,可有效缓解小样本试题知识点分类中的特征稀疏问题。
1 相关工作
针对多模态数据的试题知识点分类问题,其相关工作可分为以下两种,即试题知识点分类和多模态融合。
1.1 试题知识点分类
传统的知识点分类方法有两种,即手工标注方法[10]和基于机器学习的方法。基于手工标注的方法不仅耗时耗力,而且需要具备高水平的专业知识,同时由于不同专家标注标准的不同,因此存在标注主观性强、一致性低等问题。传统的基于机器学习的方法主要采用向量空间模型(Vector Space Model,VSM)[11]和支持向量机(Support Vector Machines,SVM)[12]。例如,植兆衍等人[13]设计了一个基于VSM的试题分类系统,对试题按知识点进行分类。朱刘影等人[14]借助TF-IDF提取试题中的关键词,然后将SVM作为分类器对地理试题知识点进行分类。郭崇慧等人[15]利用基于集成学习的方法来构建多个SVM基分类器以预测数学试题考查的知识点。以上方法虽然解决了标注一致性低的问题但仅关注试题文本的浅层特征。因此,梁圣[16]采用双向长短时记忆网络(Bidirectional Long Short-Term Memory,Bi-LSTM)对试题进行语义编码,然后通过分类器对试题知识点进行分类。胡国平等[17]提出了一种教研知识强化的卷积神经网络方法对试题知识点进行分类。上述研究均利用试题文本信息进行分类,忽略了试题图片与试题文本之间的深层语义关联,从而导致对试题的理解不充分。通过对数据集的统计分析可知,在物理试题数据集中约42%的试题均带有图片信息。因此,结合试题图片信息进行试题知识点分类是有必要的。以下将介绍多模态融合的研究现状。
1.2 多模态融合
多模态由两种或两种以上的不同模态数据组合而成。不同模态的数据虽然在本质上是异质的,但是在模态内部的特征中,模态之间又是相互关联的。多模态融合就是利用计算机进行多模态数据的综合处理[18],如文本和图片、视频和音频等。本文的多模态数据融合属于文本和图片的融合,许多学术专家在此方面进行了大量的研究。例如,Liu等人[19]提出了一个基于注意力机制的多模态神经网络模型,用于学习多模态试题数据的统一表示,然后将其应用于相似试题检测中。Yin等人[20]通过嵌入层将异构的试题数据映射到一个统一的空间中,然后采用层级预训练算法以无监督学习的方式获取试题的表示,并将其应用到试题难度评估和学生学习行为预测中。Truong等人[21]提出了一种视觉注意力网络VistaNet,用于对齐不同模态的情感信息,以将其应用于情感分类中。Huang等人[22]结合注意力机制,对文本和图片分别建模,然后对新生成的文本和图片特征进行融合,最后使用融合后的特征进行情感分类。Wang等人[23]提出了一个多模态图卷积网络来建模文本信息和图片信息以获取统一的语义表示,最后将其应用于假新闻检测中。
上述方法忽略了各模态内部信息与模态之间交互作用的结合,无法有效捕获不同模态之间的交互。
2 问题定义
给定试题文本T={t1,t2,…,tn}和试题图片I,其中n为试题文本信息的总长度,试题文本信息包括试题题面文本信息、试题答案和试题解析。试题知识点分类的目标是学习一个分类模型Ω,从中预测试题所考察的知识点Y,即
Ω(T,I)→Y
(1)
3 基于多模态学习的试题知识点分类模型
本文受Zhang等人[24]提出的应用于命名实体识别任务的自适应协同注意力网络的启发,提出了一个基于多模态学习的试题知识点分类模型。结合基于Transformer的双向编码器表示(Bidirectional Encoder Representation from Transformers,BERT)[25]、文本卷积神经网络(Text Convolutional Neural Network,TextCNN)[26]、深层卷积神经网络VGG-Net16[27]和协同注意力机制的特点,采用BERT预训练模型获取试题文本的词向量表示,并通过TextCNN捕获不同粒度的试题文本特征;然后采用深层卷积神经网络VGG-Net16捕获试题的图片特征;再将两者的特征通过协同注意力机制进行融合;最后采用全连接层输出试题知识点的分类结果。本文将从试题文本特征获取、试题图片特征获取、基于协同注意力的多模态试题数据融合和试题知识点分类四个方面介绍该模型。模型结构如图1所示。
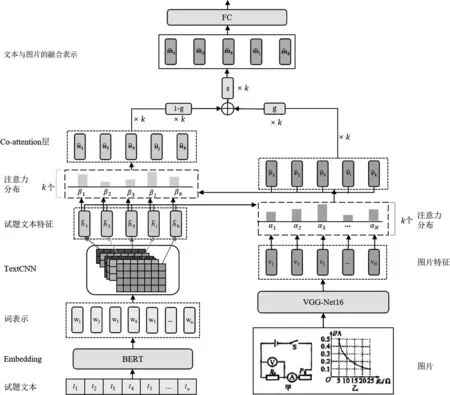
图1 基于多模态学习的试题知识点分类模型
3.1 试题文本特征获取
BERT因其在Transformer的基础上,采用大规模语料训练使之拥有强大的特征表示能力被广泛应用于预训练和下游任务中。因此,本文采用BERT预训练模型获取试题文本信息的词向量。令试题文本序列的词向量表示如式(2)所示。
w={w1,w2,…,wn}
(2)
其中,w∈n×d,d为词向量的维度,n为试题文本的长度,wi表示第i个字的词向量表示。
在分类任务中,TextCNN常被用于建立N-gram的语义特征,本文借助TextCNN的该特点捕获不同粒度的试题文本特征。令卷积核的窗口大小为[l1,l2,…,lk],卷积核为[H1,H2,…,Hk],Hj∈lj×d,经过卷积后所生成的试题文本特征图表示式(3)~式(5)所示。
其中,lj为卷积核的窗口大小,f为非线性激活函数,bci为偏置项。C表示所有卷积核对应的特征图。为了捕获试题文本中的重要特征,对卷积后得到的特征向量采取最大池化的操作,以输出试题文本中的重要特征表示如式(6)所示。
(6)
最后,我们将不同卷积核窗口对应的试题文本的重要特征进行拼接,作为试题文本特征表示。
(7)
其中,⊕表示拼接操作。
3.2 试题图片特征获取
CNN在图像处理领域拥有广泛的应用。为了获取图片信息的高阶特征表示,现有方法多采用深层卷积神经网络。本文借助ImageNet中预训练的VGG-Net16捕获试题的图片特征。VGG-Net16由五段卷积神经网络和三段全连接层组成。由于试题图片大小不一,因此首先将其处理为固定大小224×224 像素。为了获取试题图片的高阶特征表示,本文选取VGG-Net16最后一层(池化层)的输出作为试题的图片特征,其大小为7×7×512,其中512为图片特征向量的维度,7×7为特征图的数量。因此,试题图片可以被表示如式(8)所示。

(8)

为了获得相同维度的图片特征和文本特征,本文借助一个简单的线性层对图片特征向量进行转换,如式(9)所示。
(9)

3.3 基于协同注意力的多模态试题数据融合
由于试题知识点类别繁多,导致小样本试题知识点分类性能较差。为了捕获更丰富的试题语义信息,本文采用协同注意力机制,分别通过试题文本引导的试题图片的注意力和试题图片引导的试题文本的注意力来融合试题文本和试题图片的特征。
3.3.1 试题文本引导的注意力机制
通过对试题文本和试题图片的分析可知,试题文本和试题图片之间存在一定的关联。因此,直接利用试题文本特征与图片特征预测试题考查的知识点将引入更多的噪声,导致性能下降。通过试题文本引导试题图片的注意力将会使注意力更多地关注与试题文本相关的区域。
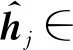
3.3.2 试题图片引导的注意力机制
通过试题文本引导的注意力机制将会使注意力更多地关注与试题文本相关的区域。通过试题图片引导的注意力机制可以将注意力更多地关注到与试题图片相关的试题文本。因此,采用更新后的试题图片特征引导的注意力机制获取与试题图片相关的试题文本的表示,相关计算如式(13)~式(15)所示。
其中,hT为重要的试题文本特征。Wvj、WT、Wβj都为权重矩阵,βj∈k,表示在试题文本中的重要特征的注意力分布,其值在[0-1]之间。为更新后的试题文本特征表示。
3.3.3 多模态试题数据融合
通过上述的协同注意力机制可以得到新生成的试题图片特征表示和试题文本特征表示。为了获取更丰富的试题语义信息,本文借助一个多模态门控机制对更新后的试题文本特征和试题图片特征动态融合,以选择更适合于试题知识点分类的特征。最后,由于并非所有试题文本中的重要特征都与试题图片关联,因此在多模态融合特征中可能会引入一些冗余信息和噪声。为了解决该问题,本文通过一个过滤门对试题文本与图片的融合特征中的噪声进行过滤。多模态融合门的相关公式如式(16)~式(19)所示。

过滤门的相关公式如式(20)~式(22)所示。

3.4 试题知识点分类
经过基于协同注意力机制的多模态试题数据融合模块后,本文获得了试题文本和试题图片特征的融合表示。最后通过一个全连接层输出试题知识点的分类结果,如式(23)所示。
(23)
其中,y为每类知识点对应的分类概率,Wy为全连接层的权重矩阵。
4 实验
4.1 数据集介绍
本文所用数据集由贵州青朵科技有限公司提供。该数据集为物理学科试题数据集。试题知识点由该学科教育学领域专家确定,并在其指导下由一线任课教师进行人工标注,对于标注不一致的试题再由任课教师和学科专家共同讨论确定。由于并非所有试题都有图片信息,因此本文从10 000道初高中物理试题中抽取出带有图片信息的4 279道试题作为该文的数据集,并将其按照8∶1∶1的比例切分为训练集、验证集和测试集。在该数据集中一级知识点有12个,二级知识点有54个。以一级知识点“力学”为例,该教育机构的试题知识点体系结构如表2所示。

表2 知识点体系结构
图2为试题样本分布图,为了便于统计,图中将样本量小于100的知识点归为其他类。通过分析可知,随着知识点层数的增加,知识点的数量也在增加,这将导致每类二级知识点对应的试题样本量减少,即小样本试题占比增加。

图2 试题样本分布图
4.2 实验评价指标
为了评价本文所提方法对试题知识点的分类效果。本文使用准确率(Accuracy,Acc)、宏平均精准率(Macro_P)、宏平均召回率(Macro_R)、宏平均F1值(Macro_F)作为评价指标。其公式分别为:
其中n为试题总数。P、R、F的表示如下:
令试题所考察的知识点原本为y,则TP表示试题所考察的知识点被正确预测为y的试题数量;FN表示试题所考察的知识点被错误预测的试题数量;FP表示试题所考察的知识点本来不是y,但被错误预测为y的试题数量;TN表示试题所考察的知识点本来不是y,预测的知识点也不是y的试题数量。
4.3 模型设置
本文分别将RoBERTa和TAL-EduBERT作为预训练模型训练试题文本的词向量。由于试题文本的平均长度为217,因此本文将试题文本长度设置为220,如果试题文本超过该长度,则截断;反之,则填充。设卷积核的窗口大小为[2,2,3,3,4,4],每个尺寸对应的卷积核数量为256。由于试题中图片的尺寸大小不一,因此将试题图片大小处理为固定尺寸224×224×3。图片特征的维度设置为512,图片特征图的数量为7×7。
如果使用预训练模型提取试题文本词向量表示,则模型的学习率设置为0.000 01;如果选用随机生成的词向量表示,则模型的学习率设置为0.001。损失函数选用交叉熵损失函数,训练批次为16,Dropout设置为0.5。
4.4 实验结果及分析
为了验证本文所提模型的有效性,本文选用TextCNN、Bi-LSTM、FastText、RoBERTa、RoBERTa+TextCNN、TAL-EduBERT+TextCNN作为基线模型。这些模型均仅利用单一的试题文本信息进行分类。一级知识点的实验结果如表3所示,二级知识点的实验结果如表4所示。

表3 一级知识点的实验结果 (单位:%)

表4 二级知识点的实验结果 (单位:%)
表中“Ours”表示TextCNN的多模态融合模型;“Ours+Ro”表示RoBERTa+TextCNN的多模态融合模型;“Ours+Edu”表示TAL-EduBERT+TextCNN的多模态融合模型。实验结果表明,本文所提方法在一级知识点和二级知识点上均优于上述基线模型。与TextCNN模型的实验结果相比,本文所提方法的准确率在一级知识点上提高了3.5%,在二级知识点上提高了4.91%;宏平均F1值在一级知识点上提高了10.51%,在二级知识点上提高了13.47%。这表明结合试题图片信息可以捕获更丰富的试题语义信息。
为了证明本文所提方法可以有效提高小样本试题知识点的分类性能,本文分别选取5个典型的一级知识点和6个典型的二级知识点。在所选一级知识点中,能量、运动和相互作用的试题样本较多,物质居中,力学和电磁学对应的试题样本较少。在所选的二级知识点中,知识点欧姆定律和电流与电路的试题样本占比较高,其余四种占比较低。图3为五种典型的一级知识点的分类结果, 图4为六种典型的二级知识点的分类结果。由图可知,本文所提方法可以显著提高小样本试题知识点的分类性能,从而进一步提高总体性能。
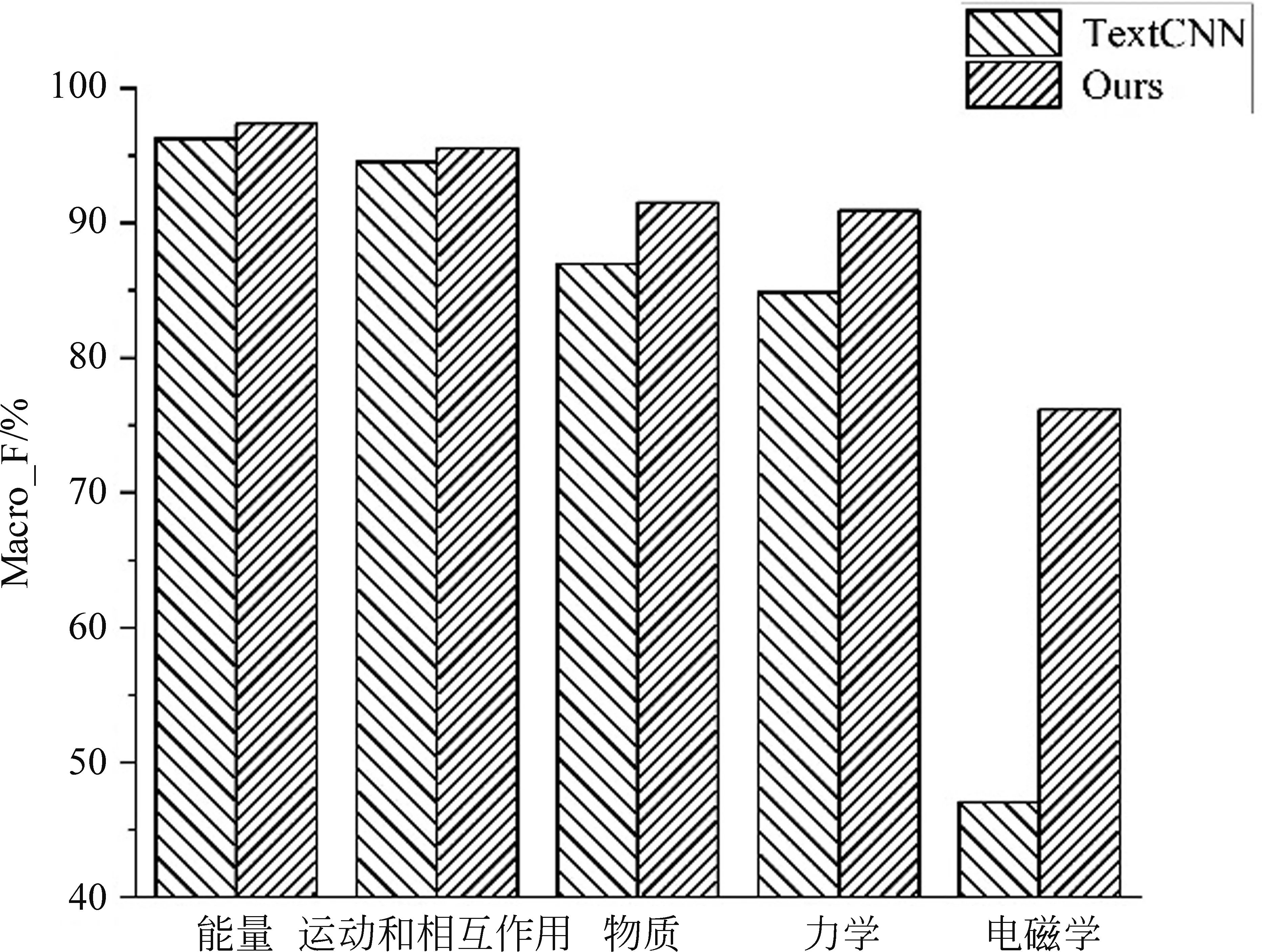
图3 五种典型的一级知识点的分类结果
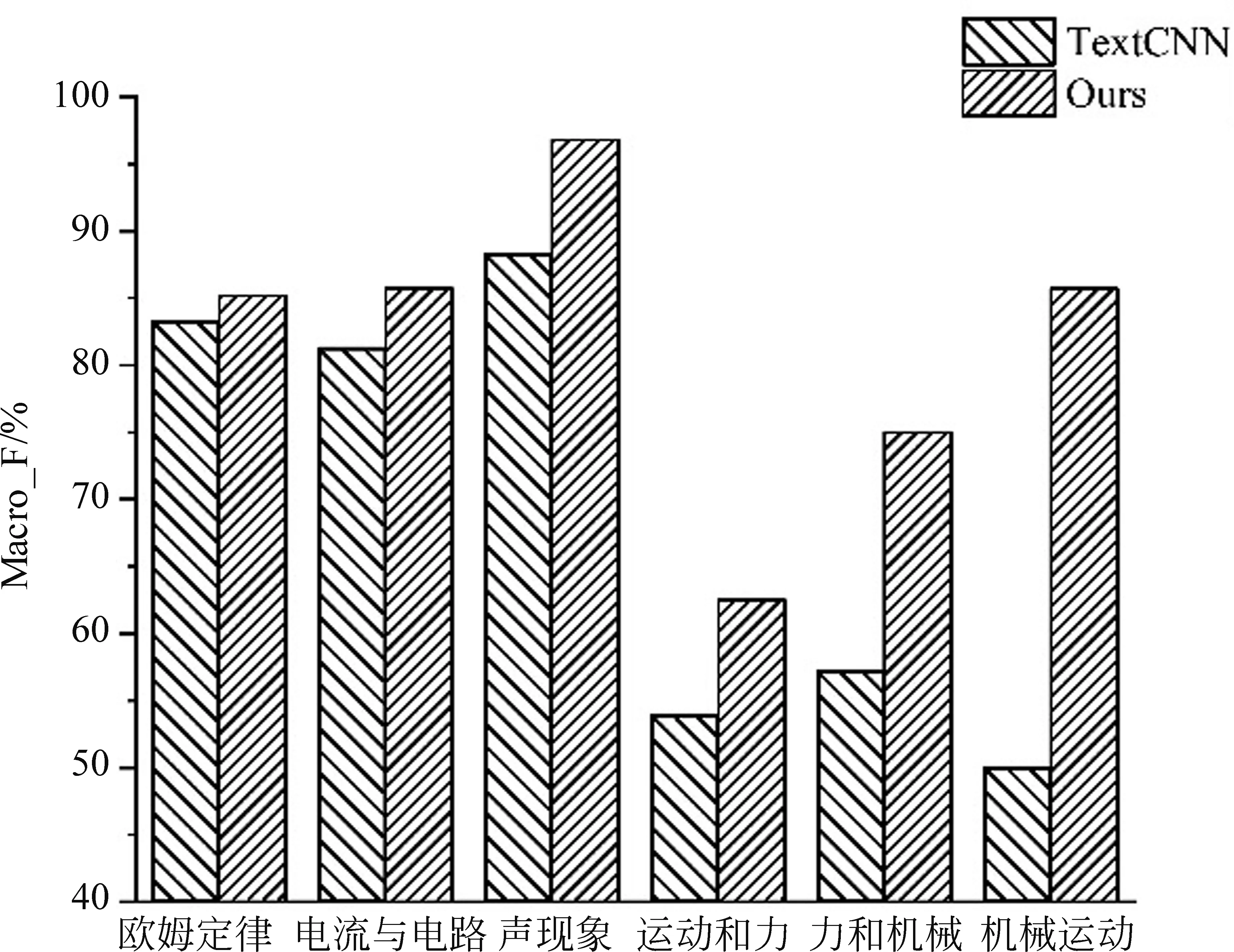
图4 六种典型的二级知识点的分类结果
为了进一步验证本文所提方法的有效性,本文进行了消融分析,即在未使用预训练模型的基础上分别去除协同注意力层、多模态融合门、过滤门。Co-att表示去除协同注意力层;Fus-gate表示去除多模态融合门;Fil-gate表示去除过滤门。表5为一级知识点消融实验的结果,表6为二级知识点消融实验的结果。通过分析可知,去除协同注意力层、多模态融合门、过滤门中的任意一个都将导致试题知识点分类性能下降。对实验结果影响最大的为过滤门,其次为多模态融合门,最后为协同注意力层。且过滤门对二级知识点的实验结果影响最大。原因可能是二级知识点类别繁多,导致试题知识点分类难度较大,通过过滤门可以很好地过滤掉与该类别无关的冗余信息,从而提高细粒度知识点的分类性能。

表5 一级知识点消融实验结果 (单位:%)
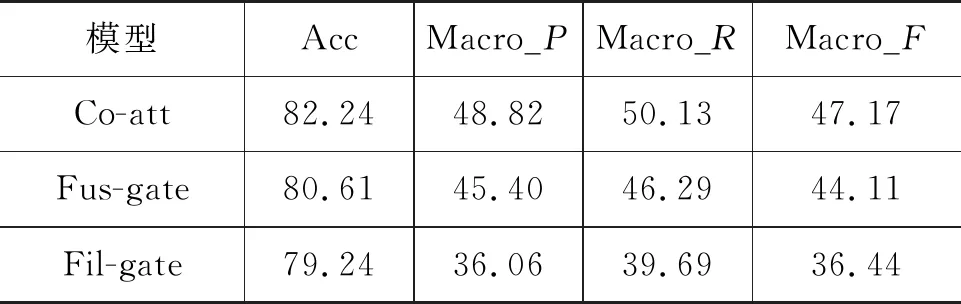
表6 二级知识点消融实验结果 (单位:%)
5 结语
本文针对小样本试题知识点分类性能较差的问题,考虑到试题图片作为试题的一部分,其包含直接的语义信息,因此提出了一个基于多模态学习的试题知识点分类模型。通过结合试题图片使试题的特征信息更加丰富饱满。在某教育机构提供的初高中物理试题数据集上进行验证,相比仅使用试题文本信息的方法,本文所提方法可以捕获更丰富的试题语义信息,以提高小样本知识点的分类性能,从而进一步提高总体性能。由于本文试题知识点体系结构为两层,因此下一步将考虑如何构建级联模型,同时输出一级知识点和二级知识点。
