融合意图信息的小样本多意图识别
2023-10-24罗顺茺
罗顺茺,何 军
(四川大学 计算机学院,四川 成都 610065)
0 引言
意图识别是面向任务型对话系统的一个基本组成部分。近年来,随着诸如智能客服、人机对话等面向任务型对话系统的广泛使用,意图识别方面的需求越来越大。一般将意图对应标签,采用多标签文本分类的方法去构建解决方案。但目前普通的单意图型对话已经满足不了人们的需求,因为在自然场景中,一句话往往包含多个用户意图,并且对话任务总是在不同的领域之间迅速变化,新领域一般只有少量数据样本。因此多意图识别通常面临数据匮乏的问题。
近期小样本学习在应对数据稀缺挑战上取得丰硕成果,引起了很多学者的关注[1]。Bao Y[2]等人将少量数据的分布式标签映射为注意力分数,再用该分数对词汇表示进行加权,使用元学习框架训练,最后得到数据样本的原型表征。Ohashi S[3]等人结合标签表征之间的语义关联性,生成嵌入每个标签特定信息的标签表示,提升了小样本分类的性能;Luo Q[4]等人探索利用类标签信息从预训练语言模型中提取输入文本的更多鉴别性特征表示,并在样本稀少的情况下实现性能提升;Han C[5]等人提出一个新的与对抗性领域适应网络相结合的元学习框架,提升了模型适应新任务数据的能力。然而上述方法都旨在从单标签样本提炼标签的原型表征[6],更多地适应小样本单标签场景下的任务。在多标签场景下,支持集、查询句中每一个标签类别所包含的句子是多种多样的,并且包含不相关类别的噪声。例如,在支持集中,A句子的标签是{a,c},B句子的标签是{d,e,a}。对于a标签类来说,标签{c,d,e}都是噪声。上述方法忽略了包含多个标签样本的标签原型构建相互混淆的问题,因此很难在多标签任务中构建标签原型。
基于上述问题,Simon C[7]等人改进原型网络、关系网络等,使其适应多标签分类问题,并通过关系推理估计给定样本标签数量来间接预测样本分类阈值;Hu M[8]等人利用两个注意力机制来减小标签原型中不相关标签所带来的噪声,并通过策略网络进一步学习每个实例的动态阈值;Hou Y[9]等人将标签名嵌入到原型表征中,从而细化了不同类别的表示,然后通过核回归来校准阈值。然而,大多数研究者通过估计标签实例相关性得分侧重于研究阈值的动态选择策略,从输入文本的信息中建立元学习器,但忽略了短句子中类别标签的丰富语义信息,并且没有考虑到实例句很容易被与标签相关的语义信息混淆的问题,未能很好地在含有多个标签的实例句中提取分离式原型表征。
本文提出融合意图信息的小样本多意图识别方法,设计了意图融合特征提取机制,利用预训练语言模型将输入样本同标签信息一起建模,采用注意力机制捕获标签信息分离式样本表征;设计了原型意图分离机制,通过多头支持集注意力和查询集注意力提取分离式原型表征;利用多任务联合训练,动态选择阈值,实现了在区分标签相关语义信息的同时捕获分离式原型表征,缓解了原型标签与实例的相关性分数计算不准确的问题。在验证的数据集中,F1指标均有3%~10%的性能提升。
本文的主要贡献包括:
(1) 针对意图识别场景下短句话语容易与意图相关的语义混淆的问题,设计意图融合特征提取机制,通过嵌入意图信息来捕获更具鉴别性特征的语义表示。
(2) 针对多意图场景下意图原型表征容易受到不相关意图信息干扰的问题,设计了原型意图分离机制,通过两个注意力机制来计算相关意图的权重,凸显相关意图信息,弱化不相关意图信息。
(3) 提出了融合意图信息的小样本多意图识别方法,较现有的方法在F1指标上有一定程度上的提升。
1 相关原理
1.1 小样本学习
小样本学习[10]能够根据先前的知识经验,捕获不同领域或任务的元知识构建表征原型,例如,模型架构、不同领域任务之间的关联等,从而快速适应新领域的任务[11]。
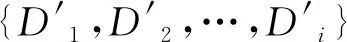
对于多意图识别来说,支持集采取k=1(每个意图包含一条话语)来模拟极少意图样本的情况,k=5模拟样本数较大的情况。查询句x为一句话,包含一组词x=(x1,x2,…,xj)。与普通小样本学习不同的是,本文不再预测单一标签,而是预测一组意图标签Y={y1,y2,…,ym}。
1.2 多标签文本分类
与单标签文本分类不同,多标签文本分类主要研究单一实例句同一组标签之间的联系。假设χ表示实例句空间,γ={y1,y2,…,yn}∈{0,1}表示有n个可能标签的标签空间,每个标签有{1,0}属性,分别代表相关与不相关。多标签文本分类的任务是学习一个函数H(·):χ→γ,从实例句空间到标签空间的一个映射。对于每个学习实例(xi,yi),xi∈χ是j维的输入,yi∈γ是相应的标签集,在测试阶段,对于一个从未见过的实例x,函数H(x)={y|h(x,y)>t,y∈γ}通过一个阈值t来预测该实例句的标签。大多数情况下h(x,y)是一个实值函数,评估标签与实例句相关性分数,它反映了y∈γ是x的真实标签的置信度。
2 融合意图信息的小样本多意图识别
本文设计了一种融合意图信息的小样本多意图识别方法,目标是通过融合意图标签所表示的丰富语义信息来提取构建具有分离式标签的原型表征,解决实例句很容易被与标签相关的语义混淆、小样本学习处理多标签问题时标签原型表征容易受到不相关标签影响等问题。
本文提出的模型主要分为三个模块: 意图融合特征提取机制(Intention Fusion Feature Extraction Mechanism, IFE)、原型意图分离机制(Prototype Intent Separation Mechanism, PIS)和多任务联合训练(Multitasking Training, MTT)(标签数量估计Hou Y[9])。模型总体框架如图1所示。
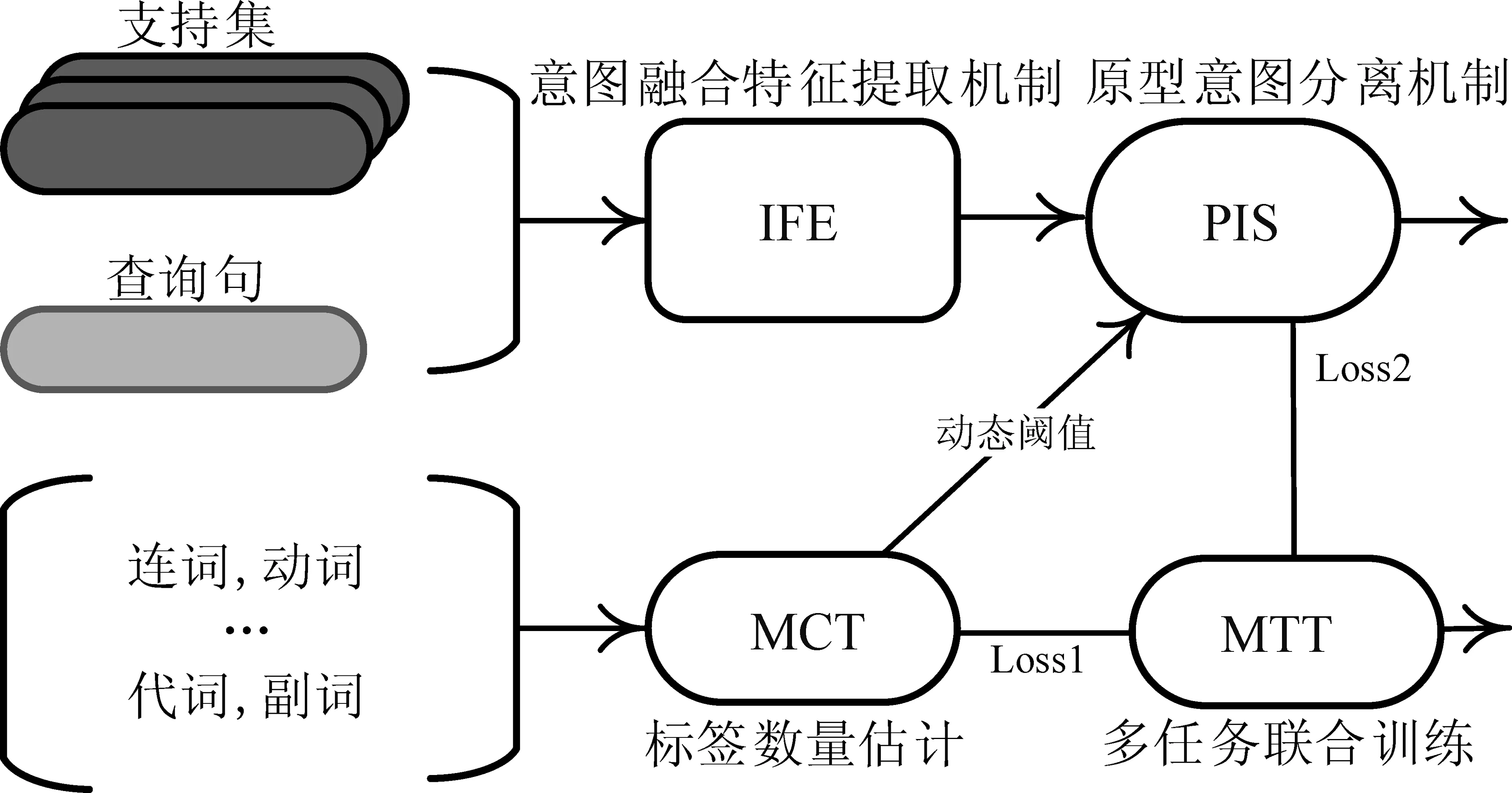
图1 模型总体框架
首先,在支持集和查询句中,设计将话语和标签按照{句子+标签}的模式,利用预训练语言模型BERT得到句子和标签的词向量,计算标签对每一个词的权重,按照权重加和得到句子向量;其次,在支持集部分,设计多头支持集注意力机制得到分离式标签原型表征。在查询集部分,设计查询集注意力机制计算多个特定的原型表征,其中相关方面被放大,不相关方面被缩小;最后通过预测查询句标签数量来间接得到动态阈值,并将其损失同模型损失一起联合训练。
2.1 问题定义
在对话场景中,多意图识别的目的是针对说话人的一句话来识别话语中体现出的意图。在真实对话场景下,话语通常具有短句;涵盖多个意图信息;对话任务、话题、领域变化迅速;新任务、领域只包含少量数据等特点。小样本学习通过利用先前的经验,仅从少数样例中总结规律,获得较好的性能。因此将多意图识别任务抽象为小样本多标签文本分类(Qin L[12]等)任务,其中将意图抽象为标签形式。
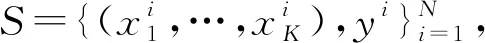
Y={y|H(E(x),E(y),S)>t,y∈γ}
(1)
其中,H(·)表示标签实例相关性分数的计算,E(·)为实例句、标签特征提取操作,Y=(y1,y2,…,)∈{0,1}表示预测的标签集,t为阈值。γ表示标签空间。
2.2 意图融合特征提取机制(IFE)
在低资源多意图识别场景下,仅使用每个意图类别的样例会导致解释类别定义时产生歧义。因此,意图融合特征提取机制的目的是利用标签信息,从像BERT这样的预训练语言模型中提取输入文本的更多判别性特征。
标签信息对于人类准确解释有限的训练样本中所传达的意义是至关重要的。本文考虑将BERT的输入进行修改,在支持集中,每个句子在一个[SEP]标记后附加相应的真实标签,得到xs=(x1,…,xs,lright);在查询句中,每个句子和一个[SEP]标记后附加标签空间中的所有标签,得到xq=(x1,…,xq,l1,…,ln)。如图2所示。
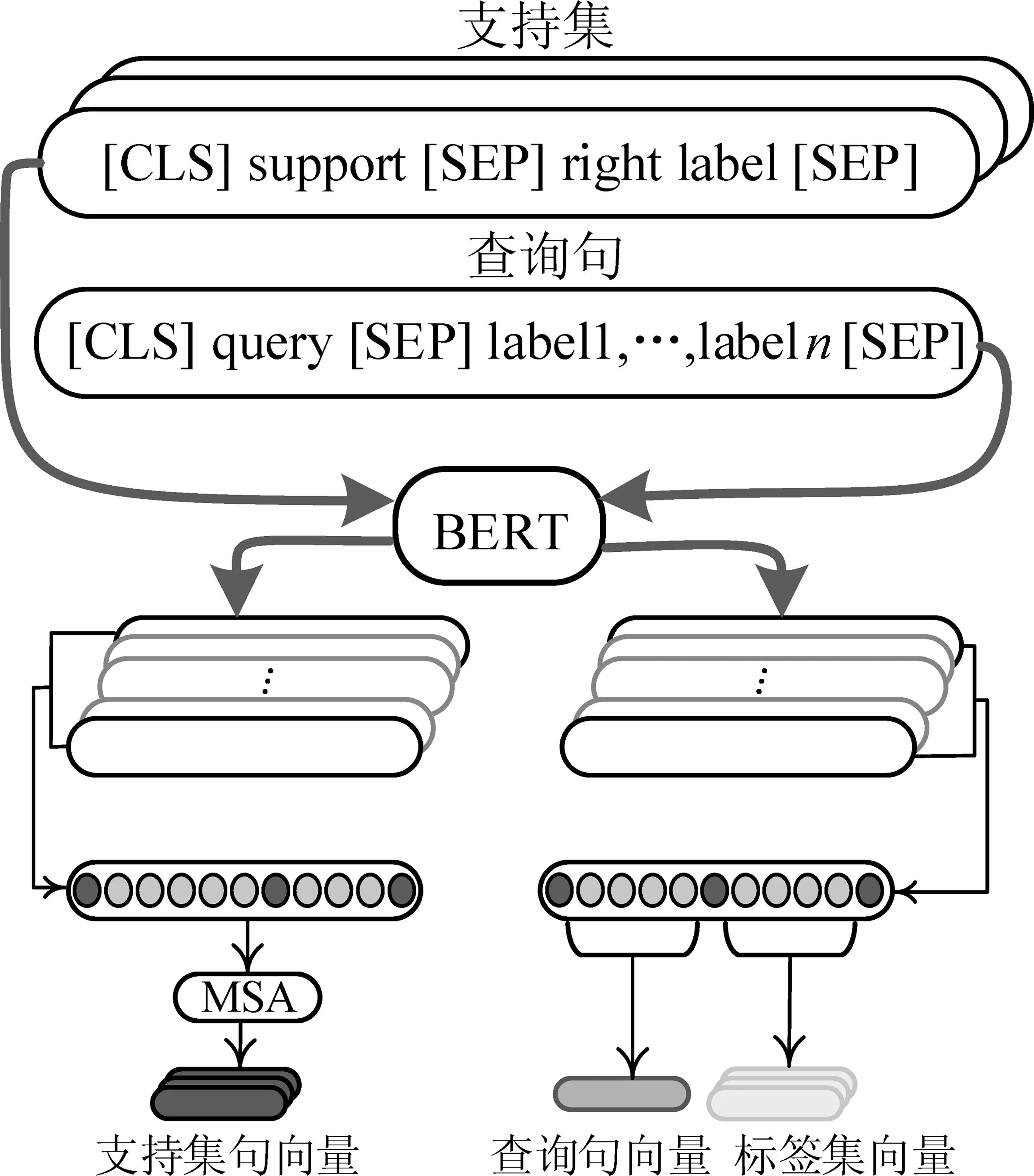
图2 意图融合特征提取机制
经过像BERT这样的预训练语言模型编码后得到12层隐藏层输出,考虑到基于[CLS]得到句向量表现性能不佳(Choi H[13]等),本文取第一层和最后一层的隐藏层输出之和作为BERT的输出得到支持集、查询句和标签集的词向量hBERT,如式(2)所示。
(2)
用标签附加到[SEP]之后,BERT能够从输入句子中提取与标签相关的信息,得到具有更多判别性特征的细粒度词向量。
在查询句中,将查询句对应的词向量相加求平均得到查询句的句向量。将查询句中的标签词向量分离得到标签集向量,如式(3)所示。
(3)
其中,ln表示标签向量,T(·)表示分离标签词向量操作,即将标签对应的词向量取出来,作为单个标签的标签向量。
在支持集中,通过将每个支持集中的标签向量相加求平均,然后分别和对应句子的词向量计算相似性得分,得出每个词对真实标签的贡献程度。最后加权求和得到支持集中句子的句向量,如式(4)所示。
(4)
其中,MSA(·)表示的是多头支持集注意力机制。
通过利用句子和意图标签信息构建意图融合特征提取机制,得到具有判别特征的支持集、查询句和标签集句向量,消除了类别定义时产生的歧义,使文本获得了更多的判别性特征,缓解实例句很容易被与标签相关的语义混淆的问题。
2.3 原型意图分离机制(PIS)
小样本学习是通过先前经验来捕捉标签原型表征,然后用查询句计算相似度,相似度最高的标签作为查询句的预测标签。单标签样本中,{N-way,K-shot}的训练片段有n个标签类别,k个样本存在标签与样本一一对应关系。因此,提取标签原型表征的时候不存在不相关标签信息干扰的问题。然而,在多标签样本中,一个样本对应多个标签,训练片段中的标签样本关系非常复杂,标签对应的样本往往含有其他不相关标签信息,如图3(上部分)所示。直接构建标签原型含有太多噪声,没有区分度。无独有偶,查询句也受到不相关信息的干扰。针对这个问题,通过设计多头支持集注意力机制(Multi-head Support Attention mechanism,MSA)和查询集注意力机制(Query Attention Mechanism,QAM)来构建原型意图分离机制,旨在捕获分离式标签原型表征和具有互信息的查询句表征。
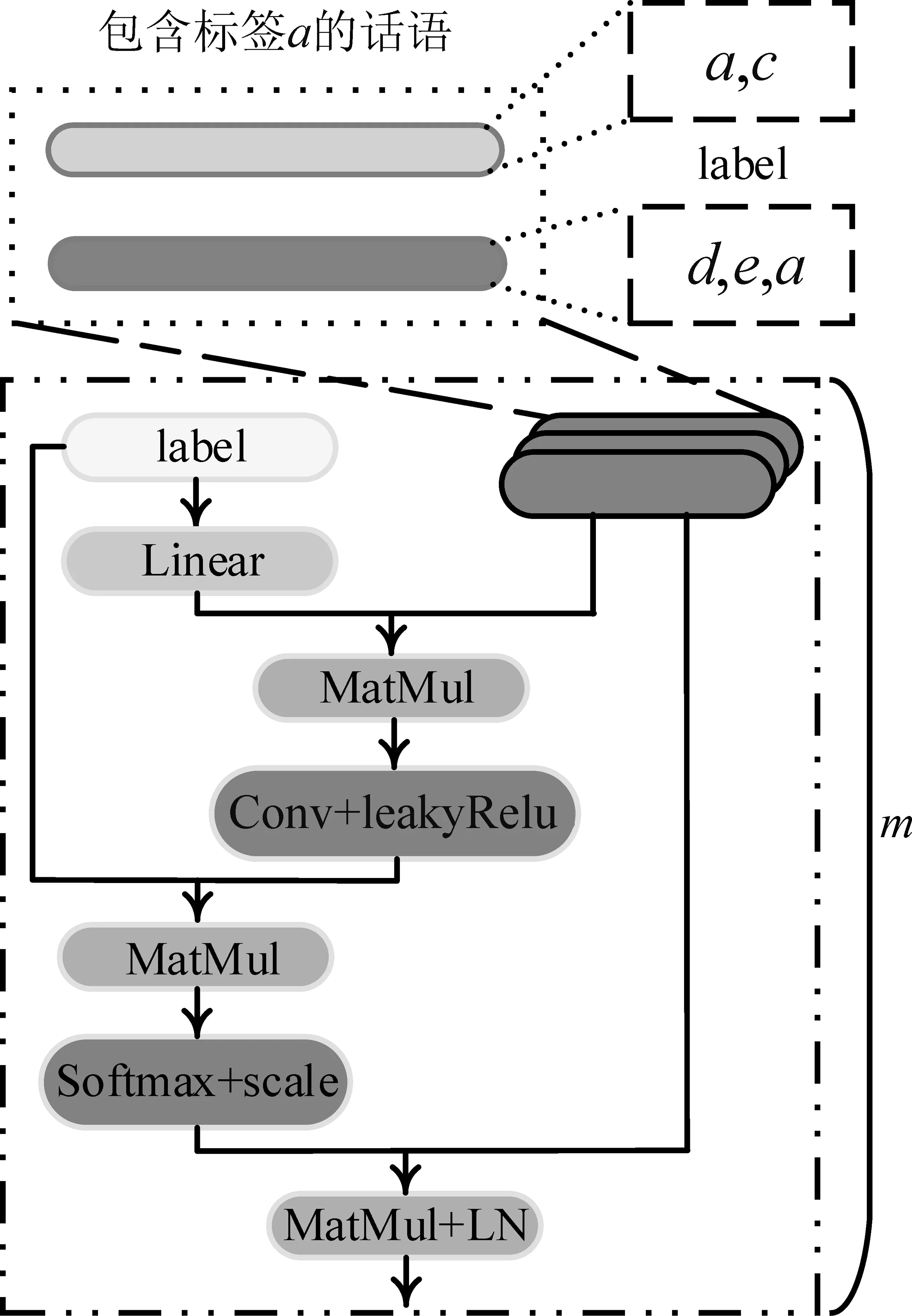
图3 多头支持集注意力机制
2.3.1 多头支持集注意力机制(MSA)
假设现在要提取标签a的原型表征,如图3所示。给定标签a的标签向量li∈1×d,其中li∈el,d表示向量维度。给定训练片段支持集中所有含有标签a的样本t∈n×d,其中t∈es,n表示样本条数。
为了从不同视角了解标签向量,复制z次标签向量,再进行线性变换,利用样本t得到标签的注意力矩阵Watt∈n×d。如式(5)所示。
Watt=t·Ws(li⊗z)
(5)
其中,Ws∈d×z是权重矩阵。⊗为复制操作。
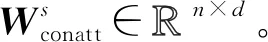
(6)
其中,conv表示卷积操作。
然后,利用标签向量和样本同卷积注意力矩阵计算得到标签对样本的相关性分数socre∈1×n,如式(7)所示。
(7)
由于Softmax会将大部分概率错误地分配给值大的一处,因此对乘积进行缩放操作。
最后,将得到的相关性分数分配到样本中,得到最终的标签原型表征,如式(8)所示,其中LN表示层归一化。
pm=LN(socre·t)
(8)
为了从多个方面把握标签和样本的信息,采用多头机制并行操作,最后取平均得到初始标签原型表征,如式(9)所示。
pi=mean(p1,..,pm)
(9)
由于注意力机制很难将不相关标签方面的相关性分数置为0,因此此时获得的初始标签原型表征p={pi,…,pn}仍然存在部分噪声。采用动态融合标签表征的方式进一步加强相关方面,弱化不相关方面,如式(10)所示。
(10)
其中,动态体现在参数α,β在训练过程中自动调整,不需要人为干预。
最终得到具有分离式标签原型表征P∈n×d。
2.3.2 查询集注意力机制(QAM)
对于查询句来说,不仅可能存在多个标签,而且句向量中还存在不相关词语向量的表征带来的噪声。直接使用查询向量表征eq和标签原型P计算得到的相似度不准确。
为了解决这个问题,本文计算查询句向量对原型表征的贡献度来凸显重要特征,尽可能的排除不相关方面,如图4所示。
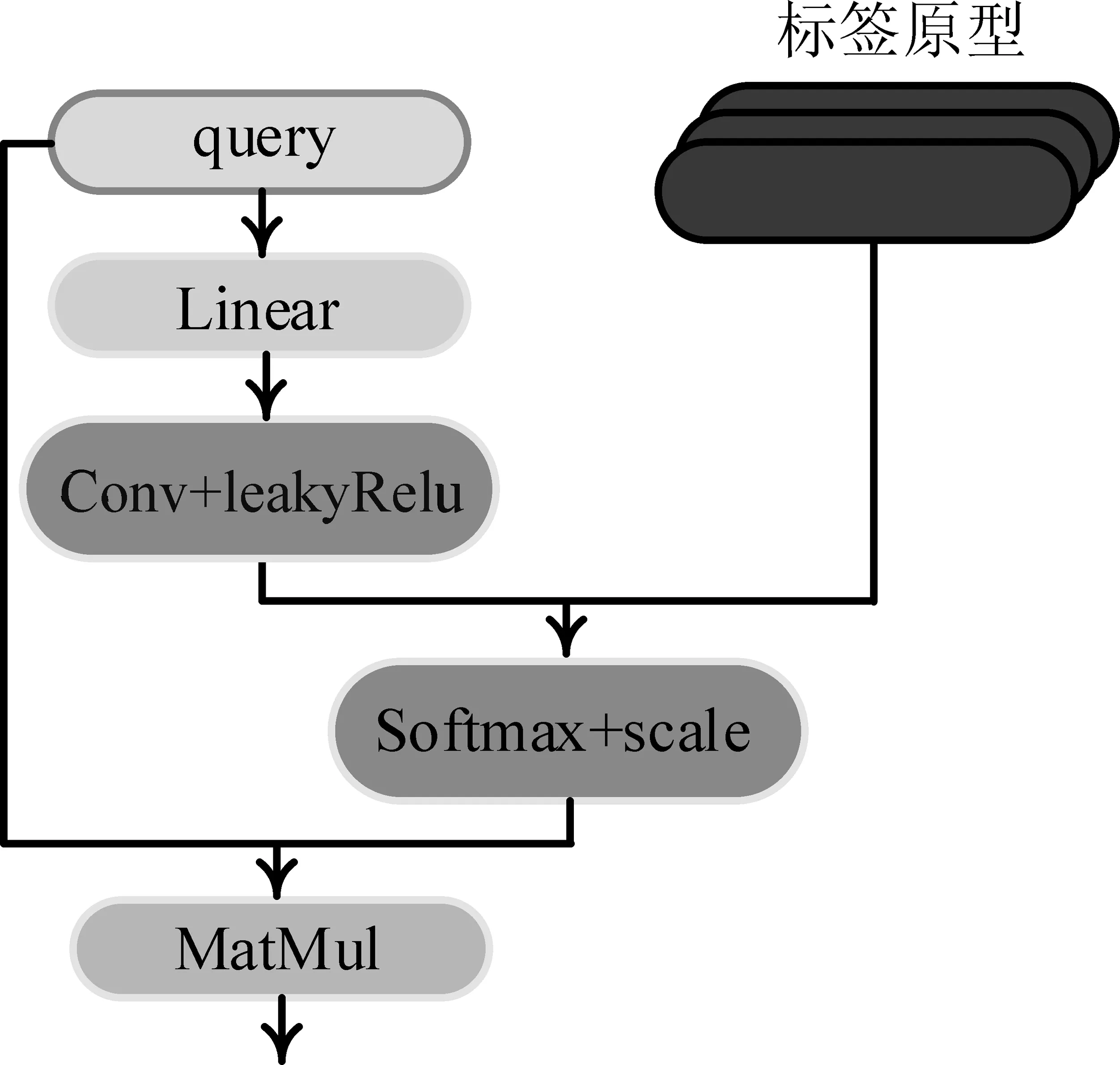
图4 查询集注意力机制
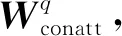
(11)
其中,Wq∈d×d是权重矩阵。
再利用原型表征同卷积注意力矩阵计算相关性分数s∈N×1,如式(12)所示。其中,d表示样本的维度,P∈n×d为分离式标签原型表征。
(12)
最后,将相关性分数分配到查询句向量中去,得到最终的查询句表征Q,如式(13)所示。
Q=mean(s·eq)
(13)
2.4 多任务联合训练(MTT)
得到标签原型表征P和查询句表征Q之后,采用点积相似度来计算它们之间的相似性,如式(14)所示。
H(x,yi,S)=SIM(P,Q)
(14)
其中,SIM表示点积相似度。
使用元校准阈值(Meta Calibrated Threshold,MCT)通过间接估计标签数量得到动态阈值。与Hou Y[9]不同的是因考虑到与标签数量相关的特征远远不止MCT中所提到的五种,因此本文将MCT的输入修改为{句子长度,连词,标点符号,动词,代词,副词,名词,数字}八种特征,并且将预测标签数量的过程与模型协同训练,构建一个多任务联合训练的模式。
2.5 损失函数
本文通过一系列的训练片段来训练模型,其中每一个训练片段都包含K-shot的支持集和一个查询句。在数据丰富的领域上模拟低资源场景,并在不同的领域进行交叉优化,确保训练和低资源场景的一致性。
本文使用二元交叉熵损失(Binary Cross Entropy Loss,BCE)作为模型损失函数,以最小化的方式来进一步优化模型,如式(15)所示。
(15)
其中,n为查询句的数量,N为标签的数量,fij∈[0,1],yij∈{0,1}分别表示第i个实例的第j个标签的预测标签和真实标签。
标签数量预测任务使用均方误差(Mean Square Error,MSE)作为损失函数,如式(16)所示。
(16)
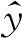
最后,利用线性插值来平衡两个任务,进行联合训练,如式(17)所示。
L=(1-λ)L1+λL2
(17)
其中,λ表示的是插值率,是一个超参数。
3 实验与分析
为了模拟低资源场景,设置了1-shot/5-shot多意图识别任务,实验将经验知识从只包含1-shot/5-shot的源域(训练)转移到未知标签的目标域(测试)。
3.1 数据集
本文在两个基准多意图识别数据集上进行实验: TourSG、StanfordLU[14]。这两个数据集都包含多个领域数据,因此可以模拟未知领域上的低资源多意图识别场景。其中,TourSG数据集包含25 751条话语,带有六个关于新加坡旅游信息的独立领域: 行程(It)、住宿(Ac)、景点(At)、食物(Fo)、交通(Tr)、购物(Sh)。StanfordLU是斯坦福对话数据集的重新注释版本,包含来自三个领域的8 038条用户话语: 日程(Sc)、导航(Na)、天气(We)。
3.2 小样本数据构建
为了模拟低资源多领域交互的多意图识别场景,本文将数据集采样为小样本学习形式,其中每个训练片段是一个查询实例(xq,yq)和相应的K-shot支持集S的组合。
由于多意图识别数据集中一条话语往往包含多个意图,因此不能采用单标签小样本数据抽样方法。为了解决这个问题,本文采用最小包含算法近似构造了K-shot支持集[15]。该算法构造支持集遵循两个标准: ①领域中的所有标签在支持集中至少出现k次。②如果从其中删除任何实例句,则至少有一个标签在支持集中出现的次数少于k次。
每个领域中,采样Ns个不同的K-shot支持集,对于每个支持集,采样Nq个实例作为查询集(查询集实例不包含在支持集中)。每个{支持集,查询集}构成一个训练片段。最终,得到Ns个训练片段,每个领域Ns×Nq个实例。
具体来说,对于TourSG数据集,构建了Ns=100个训练片段作为训练集,Nt=50个测试片段作为测试集,查询集的大小为Nq=16。由于StanfordLU数据集中领域偏少,构建了Ns=200个训练片段作为训练集,Nt=50个测试片段作为测试集,查询集大小为Nq=32。
具体的数据集细节,如表1所示。其中,P.ML表示多意图句子的比例;Ave表示平均支持集大小。由表1可知,相较于数据集StanfordLU,TourSG平均支持集尺寸大、多意图句子数多、多意图句子比例更加均衡。数据集StanfordLU有三个领域,并且领域之间相互独立,数据集TourSG有六个领域,领域之间相互交叉,有相似领域。
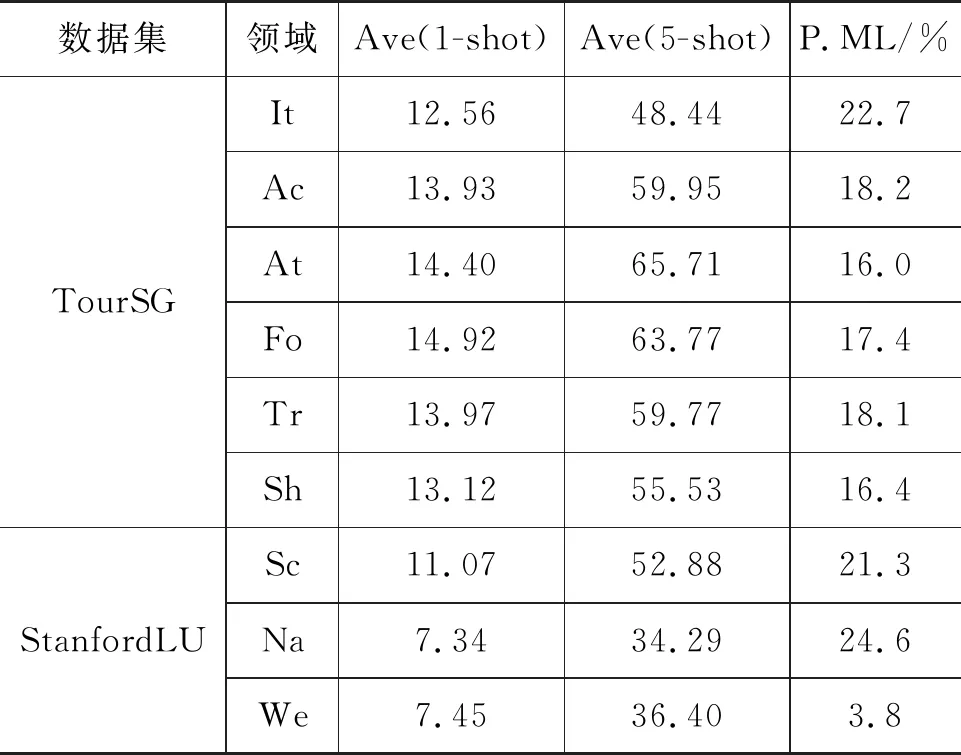
表1 实验数据集信息
3.3 实验环境及细节
本文的实验环境如表2所示。
表2 实验环境配置信息
实验过程中,本文遵循元学习训练模式,使用uncased BERT-Base[16]预训练模型;采用768维的词向量;Dropout设置为0.1;训练时采用Adam优化器,学习率设置为0.000 01;插值率λ为0.2。
为了提高测试结果的鲁棒性,本文设置在不同的领域进行交叉验证。其中,一个领域作为验证集,一个领域作为测试集,其余领域作为训练集。最后,报告三个随机种子[17]4 000、4 001、4 002的平均值作为最终结果。
3.4 实验评价指标
本文使用MicroF1分数来评估所提出方法的预测表现;使用准确率(Accuracy)来评估预测标签数量的表现。首先将所有类别直接放到一起来计算精确率和召回率,如式(18)、式(19)所示。
其中,TP表示实际为正例且被分类器判定为正例的样本数;FP表示实际为负例且被分类器判定为正例的样本数;FN表示实际为正例但被分类器判定为负例的样本数;TN表示实际为负例且被分类器判定为负例的样本数。L表示标签类别的数量。
然后,再计算MicroF1分数,如式(20)所示。
(20)
3.5 实验对照方法
为了验证方法的有效性,本文评估了3个方法:
(1) 多标签原型网络(Multi-label Prototypical Network,MPN): 基于相似性的小样本模型。通过原型网络[18]计算实例与标签原型之间的相关性得分,使用固定的阈值在源域上训练,并直接在目标域上测试。
(2) 多标签匹配网络(Multi-label Matching Network,MMN): 基于相似性的小样本模型。通过匹配网络[19]计算实例与标签原型之间的相关性得分。
(3) 小样本多意图识别模型(Meta Calibrated Threshold-Anchored Label Representation,MCT-ALR)[9]: 基于相似性的小样本模型。通过使用MCT预测标签数量来确定动态阈值,使用ALR捕获瞄点标签原型表示。采用点积相似度来计算实例与标签原型之间的相关性得分。
3.6 对比实验分析
对比实验主要分为两个部分: 不同数据集中MicroF1指标评分分析和时间复杂度分析。
3.6.1 指标评价分析
实验结果如表3~表5所示。表中每列分别表示将该列中的领域作为测试集,其他领域作为验证集、训练集的MicroF1分数(%)。其中Ave.表示均值。

表3 TourSG 1-shot数据集Micro F1分数
对于数据集TourSG(表3: 1-shot设置,表4: 5-shot设置),MCT-ALR方法相比MPN和MMN方法F1指标提升30%~40%左右,主要是因为MPN和MMN方法是由单标签模型方法改进而来,它们并没有很好地处理实例句很容易被与标签相关的语义混淆和多标签话语带来的不相关标签信息干扰的问题。而MCT-ALR方法采用瞄点标签构造标签原型表征去除了部分不相关的标签信息,使得预测准确度大幅提升。选择MPN和MMN方法,一方面可以反映出在多标签小样本意图识别和单标签小样本意图识别之间的差距巨大;另一方面反映了多标签小样本领域中实例句与标签相关的语义混淆和多标签话语带来的不相关标签信息干扰问题的严重性。

表4 TourSG 5-shot数据集Micro F1分数
不论在1-shot设置中,还是5-shot设置中,本文所提出的方法较MCT-ALR方法提升2.8%~3.5% 左右。原因主要有两点: 第一,TourSG数据集中领域之间差距比较小,不同领域的标签比较相似,标签原型中不相关标签信息带来的噪声非常复杂,难以区分,使得分离式标签原型表征的构建难度极大。得益于所设计的原型意图分离机制,采用注意力的方式融合标签信息进一步去除不相关标签信息;第二,由于TourSG数据集是由自然场景下的对话组成,具有非正式话语,且一句话包含较少的单词(极端情况下有一两个单词构成的话语)。得益于所设计的意图融合特征提取机制,缓解了实例句很容易被与标签相关的语义混淆的问题。
对于数据集StanfordLU(表5左: 1-shot设置,表5右: 5-shot设置),相较于数据集TourSG来说,涵盖的领域只有三个,模拟了在低领域场景下的低资源意图识别任务。本文提出的方法较MCT-ALR方法提升7%~10%左右,尤其是在5-shot设置中。这是因为StanfordLU数据集领域较少,且领域之间不太相似,使得原型意图分离机制可以更容易区分不同领域信息,从而更好地去除不相关标签信息。

表5 StanfordLU数据集Micro F1分数
3.6.2 时间复杂度分析
表6是本文提出方法在TourSG、StanfordLU数据集1-shot/5-shot设置上训练到收敛所消耗的时间对比。
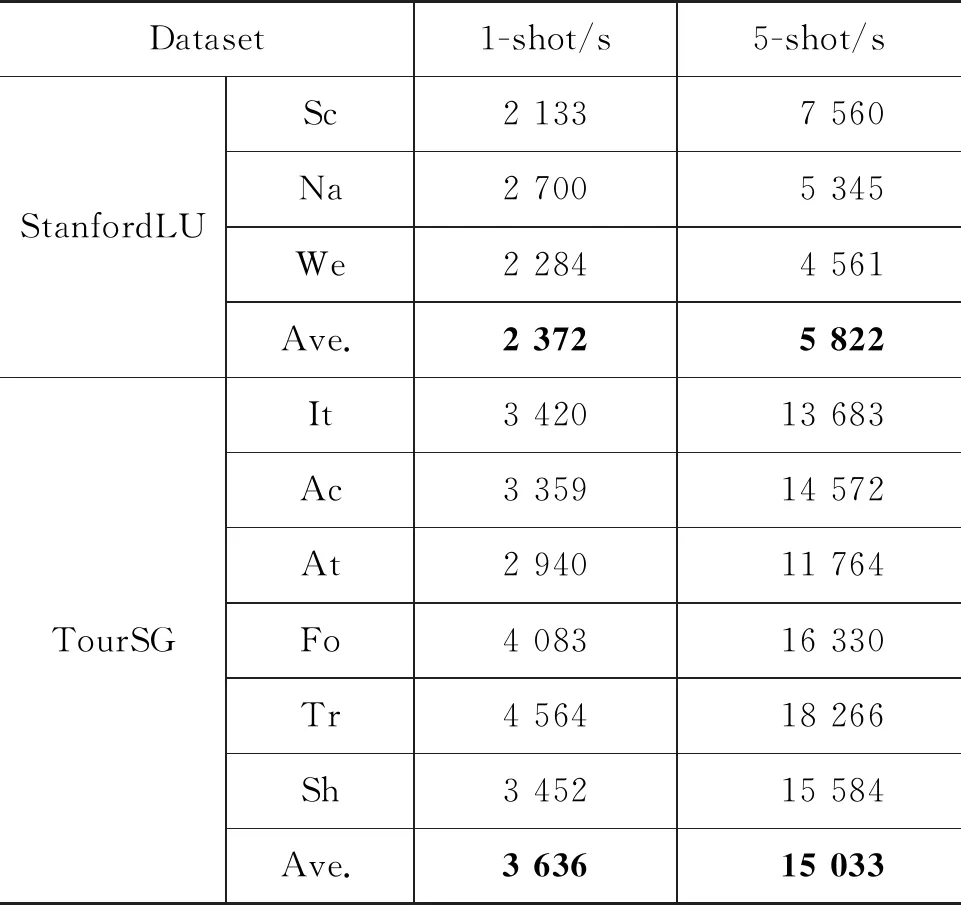
表6 本文提出方法StanfordLU、TourSG 训练时间对比
从表6可以看出,5-shot比1-shot设置所使用的时间更多,原因是样本数增加(表1)特征提取IFE、原型意图分离机制PIS所需的成本也增加。数据集TourSG比StanfordLU所使用的时间更多,一方面因为在数据集TourSG中多标签话语比StanfordLU多,给原型意图分离机制PIS带来了巨大的压力;另一方面因为在数据集TourSG中支持集比StanfordLU普遍大,所需要的成本自然增加。
3.7 消融实验
本文提出的方法可以看作是由IFE、MSA、QAM、MTT组件构成。为了更好地理解每个组件对所提出方法的贡献程度,本文在1-shot设置上,通过移除组件的方式来构建消融实验。实验结果如表7、图5所示。其中,图5折线图显示的是两个数据集中指标Ave.的可视化结果。
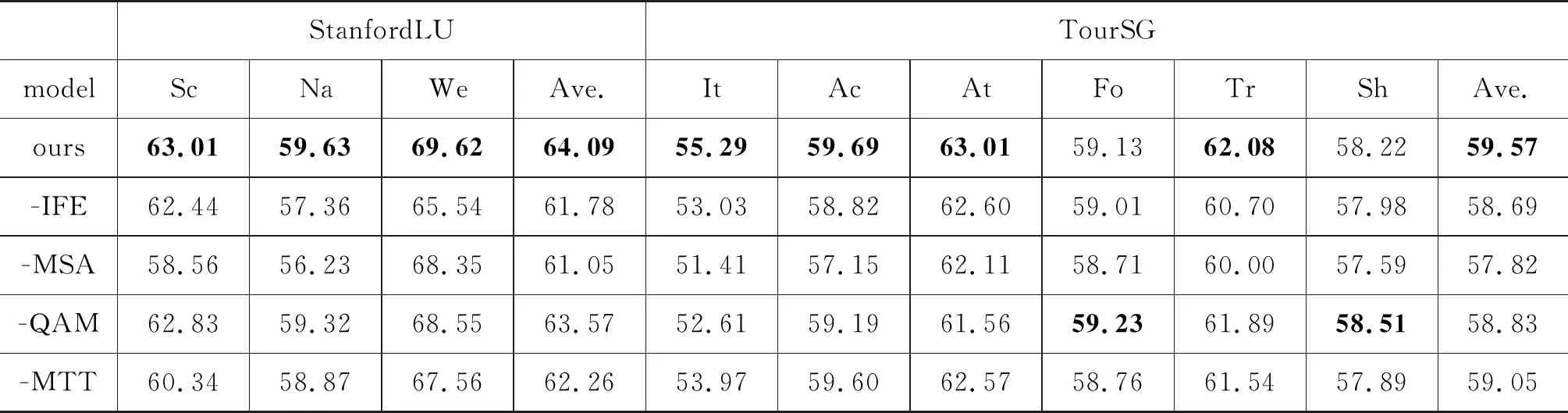
表7 消融实验1-shot Micro F1分数
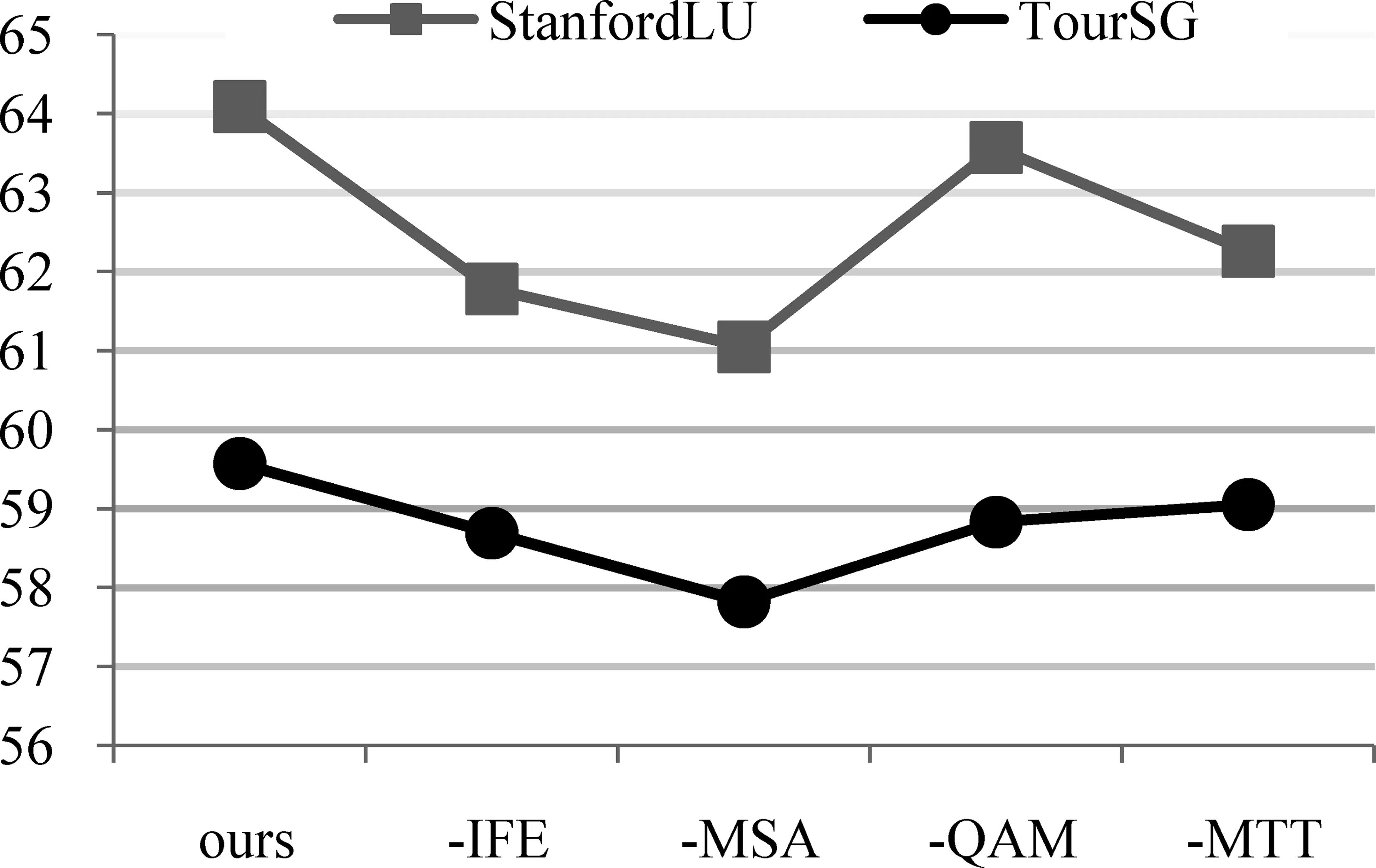
图5 StanfordLU、TourSG移除组件的平均性能
从表7和图5中可以看到,组件MSA对模型的贡献最大,一方面可以说明采用注意力机制的MSA可以降低不相关意图信息带来的噪声,另一方面也体现出了不相关意图噪声对构建标签原型表征所带来的严峻挑战。其次是IFE,这是因为所使用的两个数据集中都含有大量短句,直接对短句提取表征不能很好体现出意图。IFE结合意图信息很好地捕获具有判别性特征的语义表征。
组件QAM对模型的影响最小,这是因为QAM组件主要是为了去除与意图信息无关的噪声,保留所有的意图信息,而数据集中短句居多,与意图不相关的信息本来就不多。
为了验证采用8个特征的MCT的输入和联合模型一起训练的方式更具表现力。本文分别在两个数据集的1-shot中采用准确率(Accuracy)的评估标准预测标签的数量。实验结果如表8所示。

表8 StanfordLU、TourSG 1-shot标签数量预测
由表8中可以发现,采用8个特征联合模型一起训练更容易预测句子标签数量。一方面是因为使用特征数多,信息量越大模型预测能力越好;另一方面连词、副词和代词等词是更具代表性的特征,可以使模型更具区分度。
4 总结
本文提出一种融合意图信息的小样本多意图识别方法。首先,设计意图融合特征提取机制,结合话语和意图信息利用预训练语言模型提取支持集、查询集和标签集表征, 缓解短话语往往遭遇标签相关信息的语义混淆的问题;其次,设计原型意图分离机制,利用意图信息作为基点,计算所属标签话语对该标签原型的相关程度,联合标签权重得到分离式标签原型表征,进一步细化标签原型特征,解决了多标签小样本学习中标签原型表征容易受到不相关标签影响的问题。最后,采用模型训练和动态阈值预测联合训练的方式优化模型。实验结果表明,本文提出的方法可有效提高低资源场景下意图识别任务的效果。
未来将继续进行低资源场景下自然语言处理研究,例如,将融合标签信息的小样本学习方法应用到低资源场景下的语音识别等领域。
